
1. खास जानकारी
BigQuery, Google का पूरी तरह से मैनेज किया गया डेटा वेयरहाउस है. इसमें, कम-लागत में कई पेटाबाइट डेटा के विश्लेषण की सुविधा मिलती है. BigQuery एक NoOps (ऑपरेशन के लिए किसी भी तरह के मानवीय हस्तक्षेप की ज़रूरत नहीं होती) सेवा है. इसमें किसी इंफ़्रास्ट्रक्चर को मैनेज करने की ज़रूरत नहीं होती. साथ ही, आपको डेटाबेस एडमिन की भी ज़रूरत नहीं होती. इसलिए, डेटा का विश्लेषण करके अपने काम की अहम जानकारी ढूंढने पर ध्यान दें. इसके लिए, जाने-पहचाने SQL का इस्तेमाल करें. साथ ही, इस्तेमाल के हिसाब से पेमेंट करने वाले हमारे मॉडल का फ़ायदा पाएं.
इस कोडलैब में, Node.js की मदद से BigQuery के सार्वजनिक डेटासेट को क्वेरी करने के लिए, Google Cloud BigQuery Client Library का इस्तेमाल किया जाएगा.
आपको क्या सीखने को मिलेगा
- Cloud Shell का इस्तेमाल कैसे करें
- BigQuery API को चालू करने का तरीका
- एपीआई अनुरोधों की पुष्टि करने का तरीका
- Node.js के लिए BigQuery क्लाइंट लाइब्रेरी इंस्टॉल करने का तरीका
- शेक्सपियर की रचनाओं के बारे में क्वेरी करने का तरीका
- GitHub के डेटासेट से क्वेरी करने का तरीका
- कैश मेमोरी में सेव होने और आंकड़ों को दिखाने की सेटिंग में बदलाव करने का तरीका
आपको इन चीज़ों की ज़रूरत होगी
- Google Cloud Platform प्रोजेक्ट
- कोई ब्राउज़र, जैसे कि Chrome या Firefox
- Node.js का इस्तेमाल करने की जानकारी
सर्वे
इस ट्यूटोरियल का इस्तेमाल कैसे किया जाएगा?
Node.js के साथ अपने अनुभव को आप क्या रेटिंग देंगे?
Google Cloud Platform की सेवाओं को इस्तेमाल करने के अपने अनुभव को आप क्या रेटिंग देंगे?
2. सेटअप और ज़रूरी शर्तें
अपने हिसाब से एनवायरमेंट सेट अप करना
- Cloud Console में साइन इन करें. इसके बाद, नया प्रोजेक्ट बनाएं या किसी मौजूदा प्रोजेक्ट का फिर से इस्तेमाल करें. (अगर आपके पास पहले से Gmail या G Suite खाता नहीं है, तो आपको एक खाता बनाना होगा.)


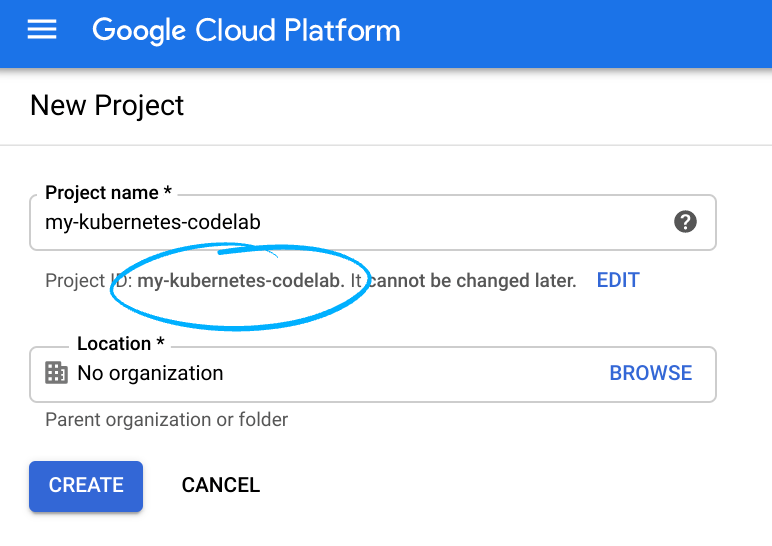
प्रोजेक्ट आईडी याद रखें. यह सभी Google Cloud प्रोजेक्ट के लिए एक यूनीक नाम होता है. ऊपर दिया गया नाम पहले ही इस्तेमाल किया जा चुका है. इसलिए, यह आपके लिए काम नहीं करेगा. माफ़ करें! इस कोड लैब में इसे बाद में PROJECT_ID के तौर पर दिखाया जाएगा.
- इसके बाद, Google Cloud संसाधनों का इस्तेमाल करने के लिए, आपको Cloud Console में बिलिंग चालू करनी होगी.
इस कोडलैब को पूरा करने में ज़्यादा खर्च नहीं आएगा. "सफ़ाई करना" सेक्शन में दिए गए निर्देशों का पालन करना न भूलें. इसमें बताया गया है कि संसाधनों को कैसे बंद किया जाए, ताकि इस ट्यूटोरियल के बाद आपको बिलिंग न करनी पड़े. Google Cloud के नए उपयोगकर्ता, मुफ़्त में आज़माने के लिए 300 डॉलर के प्रोग्राम में शामिल हो सकते हैं.
Cloud Shell शुरू करें
Cloud SDK कमांड-लाइन टूल को अपने लैपटॉप से रिमोटली चलाया जा सकता है. हालांकि, इस कोडलैब में Google Cloud Shell का इस्तेमाल किया जाएगा. यह क्लाउड में चलने वाला कमांड लाइन एनवायरमेंट है.
Cloud Shell चालू करें
- Cloud Console में, Cloud Shell चालू करें
पर क्लिक करें.

अगर आपने पहले कभी Cloud Shell का इस्तेमाल नहीं किया है, तो आपको एक इंटरमीडिएट स्क्रीन दिखेगी. इसमें Cloud Shell के बारे में जानकारी दी गई होगी. अगर ऐसा है, तो जारी रखें पर क्लिक करें. इसके बाद, आपको यह स्क्रीन कभी नहीं दिखेगी. एक बार दिखने वाली स्क्रीन ऐसी दिखती है:

Cloud Shell से कनेक्ट होने में कुछ ही सेकंड लगेंगे.

इस वर्चुअल मशीन में, डेवलपमेंट के लिए ज़रूरी सभी टूल पहले से मौजूद होते हैं. यह 5 जीबी की होम डायरेक्ट्री उपलब्ध कराता है और Google Cloud में चलता है. इससे नेटवर्क की परफ़ॉर्मेंस और पुष्टि करने की प्रोसेस बेहतर होती है. इस कोडलैब में ज़्यादातर काम, सिर्फ़ ब्राउज़र या Chromebook की मदद से किया जा सकता है.
Cloud Shell से कनेक्ट होने के बाद, आपको दिखेगा कि आपकी पुष्टि पहले ही हो चुकी है और प्रोजेक्ट को आपके प्रोजेक्ट आईडी पर पहले ही सेट कर दिया गया है.
- पुष्टि करें कि आपने Cloud Shell में पुष्टि कर ली है. इसके लिए, यह कमांड चलाएं:
gcloud auth list
कमांड आउटपुट
Credentialed Accounts
ACTIVE ACCOUNT
* <my_account>@<my_domain.com>
To set the active account, run:
$ gcloud config set account `ACCOUNT`
gcloud config list project
कमांड आउटपुट
[core] project = <PROJECT_ID>
अगर ऐसा नहीं है, तो इस कमांड का इस्तेमाल करके इसे सेट किया जा सकता है:
gcloud config set project <PROJECT_ID>
कमांड आउटपुट
Updated property [core/project].
3. BigQuery API चालू करना
BigQuery API, सभी Google Cloud प्रोजेक्ट में डिफ़ॉल्ट रूप से चालू होना चाहिए. Cloud Shell में यह कमांड डालकर, पुष्टि की जा सकती है कि यह सही है या नहीं:
gcloud services list
आपको BigQuery की सूची दिखेगी:
NAME TITLE
bigquery-json.googleapis.com BigQuery API
...
अगर BigQuery API चालू नहीं है, तो इसे चालू करने के लिए Cloud Shell में यह कमांड इस्तेमाल करें:
gcloud services enable bigquery-json.googleapis.com
4. एपीआई अनुरोधों की पुष्टि करना
BigQuery API से अनुरोध करने के लिए, आपको सेवा खाते का इस्तेमाल करना होगा. सेवा खाता आपके प्रोजेक्ट से जुड़ा होता है. इसका इस्तेमाल Google BigQuery Node.js क्लाइंट लाइब्रेरी, BigQuery API के अनुरोध करने के लिए करती है. किसी अन्य उपयोगकर्ता खाते की तरह, सेवा खाते को भी एक ईमेल पते से दिखाया जाता है. इस सेक्शन में, Cloud SDK का इस्तेमाल करके एक सेवा खाता बनाया जाएगा. इसके बाद, ऐसे क्रेडेंशियल बनाए जाएंगे जिनकी ज़रूरत आपको सेवा खाते के तौर पर पुष्टि करने के लिए होगी.
सबसे पहले, अपने PROJECT_ID के साथ एक एनवायरमेंट वैरिएबल सेट करें. इसका इस्तेमाल इस कोडलैब में किया जाएगा:
export GOOGLE_CLOUD_PROJECT=$(gcloud config get-value core/project)
इसके बाद, BigQuery API को ऐक्सेस करने के लिए नया सेवा खाता बनाएं. इसके लिए, इनका इस्तेमाल करें:
gcloud iam service-accounts create my-bigquery-sa --display-name "my bigquery codelab service account"
इसके बाद, ऐसे क्रेडेंशियल बनाएं जिनका इस्तेमाल आपका Node.js कोड, नए सेवा खाते के तौर पर लॉगिन करने के लिए करेगा. इन क्रेडेंशियल को बनाएं और इन्हें JSON फ़ाइल "~/key.json" के तौर पर सेव करें. इसके लिए, यह निर्देश इस्तेमाल करें:
gcloud iam service-accounts keys create ~/key.json --iam-account my-bigquery-sa@${GOOGLE_CLOUD_PROJECT}.iam.gserviceaccount.com
आखिर में, GOOGLE_APPLICATION_CREDENTIALS एनवायरमेंट वैरिएबल सेट करें. इसका इस्तेमाल BigQuery API C# लाइब्रेरी करती है. इसके बारे में अगले चरण में बताया गया है. इससे आपकी क्रेडेंशियल का पता चलता है. एनवायरमेंट वैरिएबल को क्रेडेंशियल की उस JSON फ़ाइल के पूरे पाथ पर सेट किया जाना चाहिए जिसे आपने बनाया है. इस कमांड का इस्तेमाल करके, एनवायरमेंट वैरिएबल सेट करें:
export GOOGLE_APPLICATION_CREDENTIALS="/home/${USER}/key.json"
BigQuery API की पुष्टि करने के बारे में ज़्यादा जानें.
5. ऐक्सेस कंट्रोल सेट अप करना
BigQuery, संसाधनों के ऐक्सेस को मैनेज करने के लिए, Identity and Access Management (IAM) का इस्तेमाल करता है. BigQuery में पहले से तय की गई कई भूमिकाएं (उपयोगकर्ता, dataOwner, dataViewer वगैरह) होती हैं. इन्हें उस सेवा खाते को असाइन किया जा सकता है जिसे आपने पिछले चरण में बनाया था. BigQuery के दस्तावेज़ में, ऐक्सेस कंट्रोल के बारे में ज़्यादा जानकारी दी गई है.
सार्वजनिक डेटासेट को क्वेरी करने से पहले, आपको यह पक्का करना होगा कि सेवा खाते के पास कम से कम bigquery.user की भूमिका हो. Cloud Shell में, सेवा खाते को bigquery.user की भूमिका असाइन करने के लिए, यहां दिया गया कमांड चलाएं:
gcloud projects add-iam-policy-binding ${GOOGLE_CLOUD_PROJECT} --member "serviceAccount:my-bigquery-sa@${GOOGLE_CLOUD_PROJECT}.iam.gserviceaccount.com" --role "roles/bigquery.user"
यह पुष्टि करने के लिए कि सेवा खाते को उपयोगकर्ता की भूमिका असाइन की गई है, यहां दी गई कमांड चलाएं:
gcloud projects get-iam-policy $GOOGLE_CLOUD_PROJECT
6. Node.js के लिए BigQuery क्लाइंट लाइब्रेरी इंस्टॉल करना
सबसे पहले, BigQueryDemo फ़ोल्डर बनाएं और उस पर जाएं:
mkdir BigQueryDemo
cd BigQueryDemo
इसके बाद, एक Node.js प्रोजेक्ट बनाएं. इसका इस्तेमाल, BigQuery client library के सैंपल चलाने के लिए किया जाएगा:
npm init -y
आपको बनाया गया Node.js प्रोजेक्ट दिखना चाहिए:
{
"name": "BigQueryDemo",
"version": "1.0.0",
"description": "",
"main": "index.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"keywords": [],
"author": "",
"license": "ISC"
}
BigQuery क्लाइंट लाइब्रेरी इंस्टॉल करें:
npm install --save @google-cloud/bigquery
npm notice created a lockfile as package-lock.json. You should commit this file.
npm WARN BigQueryDemo@1.0.0 No description
npm WARN BigQueryDemo@1.0.0 No repository field.
+ @google-cloud/bigquery@2.1.0
added 69 packages from 105 contributors and audited 147 packages in 4.679s
found 0 vulnerabilities
अब, BigQuery Node.js क्लाइंट लाइब्रेरी का इस्तेमाल किया जा सकता है!
7. शेक्सपियर की रचनाओं के बारे में क्वेरी करना
सार्वजनिक डेटासेट, BigQuery में सेव किया गया ऐसा डेटासेट होता है जिसे आम लोगों के लिए उपलब्ध कराया जाता है. आपके पास क्वेरी करने के लिए, कई अन्य सार्वजनिक डेटासेट उपलब्ध हैं. इनमें से कुछ को Google होस्ट करता है, लेकिन कई अन्य को तीसरे पक्ष होस्ट करते हैं. सार्वजनिक डेटासेट पेज पर जाकर, इस बारे में ज़्यादा जानकारी पाई जा सकती है.
सार्वजनिक डेटासेट के अलावा, BigQuery में सैंपल टेबल की सीमित संख्या उपलब्ध होती है. इन पर क्वेरी की जा सकती है. ये टेबल, bigquery-public-data:samples dataset में मौजूद हैं. उनमें से एक टेबल को shakespeare. कहा जाता है. इसमें शेक्सपियर की रचनाओं का शब्द इंडेक्स होता है. इससे पता चलता है कि हर कॉर्पस में हर शब्द कितनी बार आया है.
इस चरण में, आपको शेक्सपियर टेबल के लिए क्वेरी करनी होगी.
सबसे पहले, Cloud Shell में सबसे ऊपर दाईं ओर मौजूद कोड एडिटर खोलें:
BigQueryDemo फ़ोल्डर में queryShakespeare.js फ़ाइल बनाने के लिए :
touch queryShakespeare.js
queryShakespeare.js फ़ाइल पर जाएं और यह कोड डालें:
'use strict';
function main() {
// Import the Google Cloud client library
const {BigQuery} = require('@google-cloud/bigquery');
async function queryShakespeare() {
// Queries a public Shakespeare dataset.
// Create a client
const bigqueryClient = new BigQuery();
// The SQL query to run
const sqlQuery = `SELECT word, word_count
FROM \`bigquery-public-data.samples.shakespeare\`
WHERE corpus = @corpus
AND word_count >= @min_word_count
ORDER BY word_count DESC`;
const options = {
query: sqlQuery,
// Location must match that of the dataset(s) referenced in the query.
location: 'US',
params: {corpus: 'romeoandjuliet', min_word_count: 250},
};
// Run the query
const [rows] = await bigqueryClient.query(options);
console.log('Rows:');
rows.forEach(row => console.log(row));
}
queryShakespeare();
}
main();
कोड को समझने के लिए एक या दो मिनट का समय लें. साथ ही, देखें कि टेबल को कैसे क्वेरी किया जाता है.
Cloud Shell में वापस जाकर, ऐप्लिकेशन चलाएं:
node queryShakespeare.js
आपको शब्दों की सूची और उनके इस्तेमाल की संख्या दिखेगी:
Rows:
{ word: 'the', word_count: 614 }
{ word: 'I', word_count: 577 }
{ word: 'and', word_count: 490 }
{ word: 'to', word_count: 486 }
{ word: 'a', word_count: 407 }
{ word: 'of', word_count: 367 }
{ word: 'my', word_count: 314 }
{ word: 'is', word_count: 307 }
...
8. GitHub डेटासेट को क्वेरी करना
BigQuery के बारे में ज़्यादा जानने के लिए, अब GitHub के सार्वजनिक डेटासेट के लिए क्वेरी जारी करें. आपको GitHub पर सबसे ज़्यादा इस्तेमाल होने वाले कमिट मैसेज मिलेंगे. आपको BigQuery के वेब यूज़र इंटरफ़ेस (यूआई) का इस्तेमाल करके, ऐड-हॉक क्वेरी का पूर्वावलोकन करना होगा और उन्हें चलाना होगा.
डेटा देखने के लिए, BigQuery के वेब यूज़र इंटरफ़ेस (यूआई) में GitHub डेटासेट खोलें:
https://console.cloud.google.com/bigquery?p=bigquery-public-data&d=github_repos&t=commits&page=table
डेटा कैसा दिखता है, इसकी झलक देखने के लिए, 'झलक देखें' टैब पर क्लिक करें:
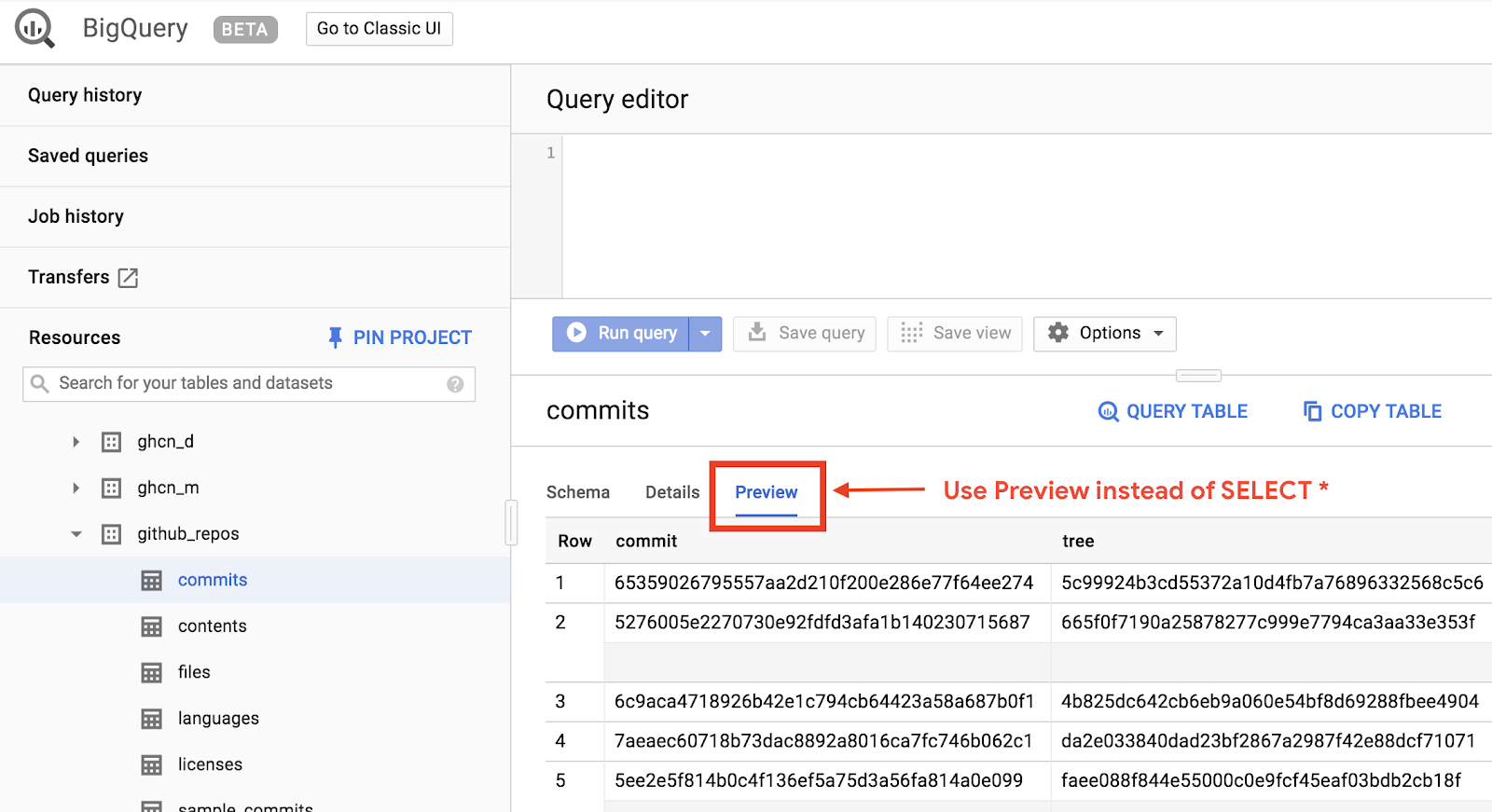
BigQueryDemo फ़ोल्डर में queryGitHub.js फ़ाइल बनाएं:
touch queryGitHub.js
queryGitHub.js फ़ाइल पर जाएं और यह कोड डालें:
'use strict';
function main() {
// Import the Google Cloud client library
const {BigQuery} = require('@google-cloud/bigquery');
async function queryGitHub() {
// Queries a public GitHub dataset.
// Create a client
const bigqueryClient = new BigQuery();
// The SQL query to run
const sqlQuery = `SELECT subject AS subject, COUNT(*) AS num_duplicates
FROM \`bigquery-public-data.github_repos.commits\`
GROUP BY subject
ORDER BY num_duplicates
DESC LIMIT 10`;
const options = {
query: sqlQuery,
// Location must match that of the dataset(s) referenced in the query.
location: 'US',
};
// Run the query
const [rows] = await bigqueryClient.query(options);
console.log('Rows:');
rows.forEach(row => console.log(`${row.subject}: ${row.num_duplicates}`));
}
queryGitHub();
}
main();
कोड को समझने के लिए, एक या दो मिनट का समय लें. साथ ही, देखें कि सबसे ज़्यादा इस्तेमाल किए जाने वाले कमिट मैसेज के लिए, टेबल को कैसे क्वेरी किया जाता है.
Cloud Shell में वापस जाकर, ऐप्लिकेशन चलाएं:
node queryGitHub.js
आपको कमिट मैसेज और उनके दिखने की संख्या की सूची दिखेगी:
Rows:
Update README.md: 2572220
: 1985733
Initial commit: 1940228
Mirroring from Micro.blog.: 646772
update: 592520
Update data.json: 548730
Update data.js: 548354
...
9. कैश मेमोरी में सेव करना और आंकड़े
क्वेरी चलाने पर, BigQuery नतीजों को कैश मेमोरी में सेव कर लेता है. इस वजह से, बाद में की जाने वाली एक जैसी क्वेरी में बहुत कम समय लगता है. क्वेरी के विकल्पों का इस्तेमाल करके, कैश मेमोरी में सेव होने की सुविधा को बंद किया जा सकता है. BigQuery, क्वेरी के बारे में कुछ आंकड़ों को भी ट्रैक करता है. जैसे, क्वेरी बनाने का समय, क्वेरी खत्म होने का समय, और प्रोसेस किए गए कुल बाइट.
इस चरण में, आपको कैश मेमोरी की सुविधा बंद करनी होगी. साथ ही, क्वेरी के बारे में कुछ आंकड़े दिखाने होंगे.
BigQueryDemo फ़ोल्डर में मौजूद queryShakespeare.js फ़ाइल पर जाएं और कोड की जगह यह कोड डालें:
'use strict';
function main() {
// Import the Google Cloud client library
const {BigQuery} = require('@google-cloud/bigquery');
async function queryShakespeareDisableCache() {
// Queries the Shakespeare dataset with the cache disabled.
// Create a client
const bigqueryClient = new BigQuery();
const sqlQuery = `SELECT word, word_count
FROM \`bigquery-public-data.samples.shakespeare\`
WHERE corpus = @corpus
AND word_count >= @min_word_count
ORDER BY word_count DESC`;
const options = {
query: sqlQuery,
// Location must match that of the dataset(s) referenced in the query.
location: 'US',
params: {corpus: 'romeoandjuliet', min_word_count: 250},
useQueryCache: false,
};
// Run the query as a job
const [job] = await bigqueryClient.createQueryJob(options);
console.log(`Job ${job.id} started.`);
// Wait for the query to finish
const [rows] = await job.getQueryResults();
// Print the results
console.log('Rows:');
rows.forEach(row => console.log(row));
// Print job statistics
console.log('JOB STATISTICS:')
console.log(`Status: ${job.metadata.status.state}`);
console.log(`Creation time: ${job.metadata.statistics.creationTime}`);
console.log(`Start time: ${job.metadata.statistics.startTime}`);
console.log(`Statement type: ${job.metadata.statistics.query.statementType}`);
}
queryShakespeareDisableCache();
}
main();
कोड के बारे में कुछ बातें ध्यान में रखें. सबसे पहले, options ऑब्जेक्ट में UseQueryCache को false पर सेट करके, कैश मेमोरी में सेव होने की सुविधा बंद की जाती है. दूसरा, आपने नौकरी के ऑब्जेक्ट से क्वेरी के बारे में आंकड़े ऐक्सेस किए.
Cloud Shell में वापस जाकर, ऐप्लिकेशन चलाएं:
node queryShakespeare.js
आपको कमिट मैसेज और उनके दिखने की संख्या की सूची दिखेगी. इसके अलावा, आपको क्वेरी के बारे में कुछ आंकड़े भी दिखेंगे:
Rows:
{ word: 'the', word_count: 614 }
{ word: 'I', word_count: 577 }
{ word: 'and', word_count: 490 }
{ word: 'to', word_count: 486 }
{ word: 'a', word_count: 407 }
{ word: 'of', word_count: 367 }
{ word: 'my', word_count: 314 }
{ word: 'is', word_count: 307 }
{ word: 'in', word_count: 291 }
{ word: 'you', word_count: 271 }
{ word: 'that', word_count: 270 }
{ word: 'me', word_count: 263 }
JOB STATISTICS:
Status: RUNNING
Creation time: 1554309220660
Start time: 1554309220793
Statement type: SELECT
10. BigQuery में डेटा लोड करना
अगर आपको अपने डेटा के बारे में क्वेरी करनी है, तो पहले आपको अपना डेटा BigQuery में लोड करना होगा. BigQuery, Google Cloud Storage, अन्य Google सेवाओं या स्थानीय, पढ़ने लायक सोर्स जैसे कई सोर्स से डेटा लोड करने की सुविधा देता है. आपके पास डेटा को स्ट्रीम करने का विकल्प भी है. BigQuery में डेटा लोड करना पेज पर जाकर, इस बारे में ज़्यादा जानकारी पाई जा सकती है.
इस चरण में, Google Cloud Storage में सेव की गई JSON फ़ाइल को BigQuery टेबल में लोड किया जाएगा. JSON फ़ाइल यहां मौजूद है: gs://cloud-samples-data/bigquery/us-states/us-states.json
अगर आपको JSON फ़ाइल के कॉन्टेंट के बारे में जानना है, तो Cloud Shell में इसे डाउनलोड करने के लिए, gsutil कमांड लाइन टूल का इस्तेमाल करें:
gsutil cp gs://cloud-samples-data/bigquery/us-states/us-states.json .
Copying gs://cloud-samples-data/bigquery/us-states/us-states.json...
/ [1 files][ 2.0 KiB/ 2.0 KiB]
Operation completed over 1 objects/2.0 KiB.
इसमें अमेरिका के राज्यों की सूची शामिल है. साथ ही, हर राज्य एक अलग लाइन में JSON ऑब्जेक्ट के तौर पर मौजूद है:
less us-states.json
{"name": "Alabama", "post_abbr": "AL"}
{"name": "Alaska", "post_abbr": "AK"}
...
इस JSON फ़ाइल को BigQuery में लोड करने के लिए, BigQueryDemo फ़ोल्डर में createDataset.js और loadBigQueryJSON.js फ़ाइल बनाएं:
touch createDataset.js
touch loadBigQueryJSON.js
Google Cloud Storage Node.js क्लाइंट लाइब्रेरी इंस्टॉल करें:
npm install --save @google-cloud/storage
createDataset.js फ़ाइल पर जाएं और यह कोड डालें:
'use strict';
function main() {
// Import the Google Cloud client libraries
const {BigQuery} = require('@google-cloud/bigquery');
async function createDataset() {
const datasetId = "my_states_dataset3";
const bigqueryClient = new BigQuery();
// Specify the geographic location where the dataset should reside
const options = {
location: 'US',
};
// Create a new dataset
const [dataset] = await bigqueryClient.createDataset(datasetId, options);
console.log(`Dataset ${dataset.id} created.`);
}
createDataset();
}
main();
इसके बाद, loadBigQueryJSON.js फ़ाइल पर जाएं और यह कोड डालें:
'use strict';
function main() {
// Import the Google Cloud client libraries
const {BigQuery} = require('@google-cloud/bigquery');
const {Storage} = require('@google-cloud/storage');
const datasetId = "my_states_dataset3";
const tableId = "my_states_table";
async function createTable(datasetId, tableId) {
// Creates a new table
// Create a client
const bigqueryClient = new BigQuery();
const options = {
location: 'US',
};
// Create a new table in the dataset
const [table] = await bigqueryClient
.dataset(datasetId)
.createTable(tableId, options);
console.log(`Table ${table.id} created.`);
}
async function loadJSONFromGCS(datasetId, tableId) {
// Import a GCS file into a table with manually defined schema.
// Instantiate clients
const bigqueryClient = new BigQuery();
const storageClient = new Storage();
const bucketName = 'cloud-samples-data';
const filename = 'bigquery/us-states/us-states.json';
// Configure the load job.
const metadata = {
sourceFormat: 'NEWLINE_DELIMITED_JSON',
schema: {
fields: [
{name: 'name', type: 'STRING'},
{name: 'post_abbr', type: 'STRING'},
],
},
location: 'US',
};
// Load data from a Google Cloud Storage file into the table
const [job] = await bigqueryClient
.dataset(datasetId)
.table(tableId)
.load(storageClient.bucket(bucketName).file(filename), metadata);
// load() waits for the job to finish
console.log(`Job ${job.id} completed.`);
// Check the job's status for errors
const errors = job.status.errors;
if (errors && errors.length > 0) {
throw errors;
}
}
// createDataset(datasetId);
createTable(datasetId, tableId);
loadJSONFromGCS(datasetId, tableId);
}
main();
एक या दो मिनट में यह समझें कि कोड, JSON फ़ाइल को कैसे लोड करता है और डेटासेट में टेबल (स्कीमा के साथ) कैसे बनाता है.
Cloud Shell में वापस जाकर, ऐप्लिकेशन चलाएं:
node createDataset.js
node loadBigQueryJSON.js
BigQuery में एक डेटासेट और एक टेबल बनाई जाती है:
Table my_states_table created.
Job [JOB ID] completed.
डेटासेट बन गया है या नहीं, यह देखने के लिए BigQuery के वेब यूज़र इंटरफ़ेस (यूआई) पर जाएं. आपको एक नया डेटासेट और टेबल दिखेगी. टेबल के 'झलक देखें' टैब पर स्विच करने से, आपको असल डेटा दिखेगा:
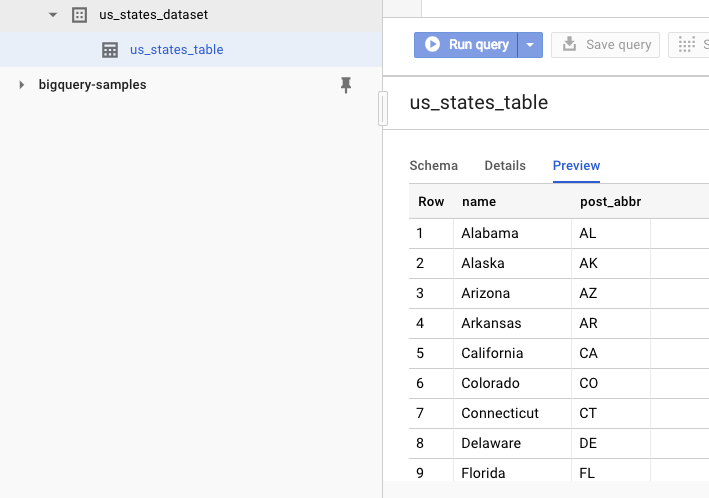
11. बधाई हो!
आपने Node.js का इस्तेमाल करके BigQuery का इस्तेमाल करने का तरीका जान लिया है!
व्यवस्थित करें
इस क्विकस्टार्ट में इस्तेमाल की गई संसाधनों के लिए, अपने Google Cloud Platform खाते से शुल्क न लिए जाने के लिए:
- Cloud Platform Console पर जाएं.
- वह प्रोजेक्ट चुनें जिसे बंद करना है. इसके बाद, सबसे ऊपर मौजूद ‘मिटाएं' पर क्लिक करें: इससे प्रोजेक्ट को मिटाने के लिए शेड्यूल कर दिया जाता है.
ज़्यादा जानें
- Google BigQuery: https://cloud.google.com/bigquery/docs/
- Google Cloud Platform पर Node.js: https://cloud.google.com/nodejs/
- Google BigQuery Node.js क्लाइंट लाइब्रेरी: https://github.com/googleapis/nodejs-bigquery
लाइसेंस
इस काम के लिए, Creative Commons एट्रिब्यूशन 2.0 जेनेरिक लाइसेंस के तहत लाइसेंस मिला है.