
1. 개요
BigQuery는 Google의 완전 관리형 페타바이트급 규모의 저비용 분석 데이터 웨어하우스입니다. BigQuery는 NoOps입니다. 관리할 인프라가 없고 데이터베이스 관리자가 필요 없으므로 데이터 분석에 집중하여 의미 있는 정보를 찾을 수 있습니다. 또한 친숙한 SQL을 사용하고 종량제 모델을 활용할 수 있습니다.
이 Codelab에서는 Google Cloud BigQuery 클라이언트 라이브러리를 사용하여 Node.js로 BigQuery 공개 데이터 세트를 쿼리합니다.
학습할 내용
- Cloud Shell 사용 방법
- BigQuery API 사용 설정 방법
- API 요청 인증 방법
- Node.js용 BigQuery 클라이언트 라이브러리를 설치하는 방법
- 셰익스피어 작품을 쿼리하는 방법
- GitHub 데이터 세트를 쿼리하는 방법
- 캐싱 및 통계 표시 조정 방법
필요한 항목
설문조사
이 튜토리얼을 어떻게 사용하실 계획인가요?
Node.js 사용 경험을 어떻게 평가하시겠어요?
귀하의 Google Cloud Platform 서비스 사용 경험을 평가해 주세요.
2. 설정 및 요구사항
자습형 환경 설정
- Cloud Console에 로그인하고 새 프로젝트를 만들거나 기존 프로젝트를 다시 사용합니다. (Gmail 또는 G Suite 계정이 없으면 만들어야 합니다.)


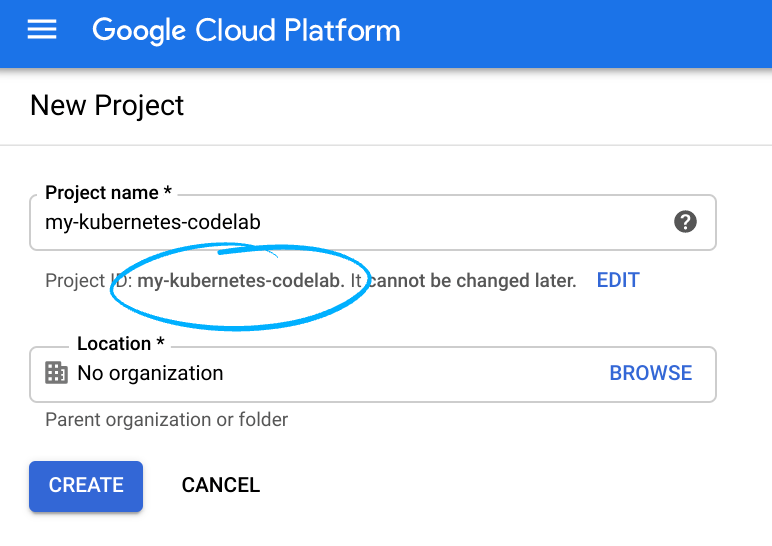
모든 Google Cloud 프로젝트에서 고유한 이름인 프로젝트 ID를 기억하세요(위의 이름은 이미 사용되었으므로 사용할 수 없습니다). 이 ID는 나중에 이 Codelab에서 PROJECT_ID라고 부릅니다.
- 그런 후 Google Cloud 리소스를 사용할 수 있도록 Cloud Console에서 결제를 사용 설정해야 합니다.
이 Codelab 실행에는 많은 비용이 들지 않습니다. 이 가이드를 마친 후 비용이 결제되지 않도록 리소스 종료 방법을 알려주는 '삭제' 섹션의 안내를 따르세요. Google Cloud 새 사용자에게는 $300USD 상당의 무료 체험판 프로그램 참여 자격이 부여됩니다.
Cloud Shell 시작
Cloud SDK 명령줄 도구를 노트북에서 원격으로 실행할 수 있지만, 이 Codelab에서는 클라우드에서 실행되는 명령줄 환경인 Google Cloud Shell을 사용합니다.
Cloud Shell 활성화
- Cloud Console에서 Cloud Shell 활성화
를 클릭합니다.

이전에 Cloud Shell을 시작하지 않았으면 설명이 포함된 중간 화면 (스크롤해야 볼 수 있는 부분)이 제공됩니다. 이 경우 계속을 클릭합니다 (이후 다시 표시되지 않음). 이 일회성 화면은 다음과 같습니다.

Cloud Shell을 프로비저닝하고 연결하는 작업은 몇 분이면 끝납니다.

이 가상 머신에는 필요한 개발 도구가 모두 포함되어 로드됩니다. 영구적인 5GB 홈 디렉터리를 제공하고 Google Cloud에서 실행되므로 네트워크 성능과 인증이 크게 개선됩니다. 이 Codelab에서 대부분의 작업은 브라우저나 Chromebook만 사용하여 수행할 수 있습니다.
Cloud Shell에 연결되면 인증이 완료되었고 프로젝트가 해당 프로젝트 ID로 이미 설정된 것을 볼 수 있습니다.
- Cloud Shell에서 다음 명령어를 실행하여 인증되었는지 확인합니다.
gcloud auth list
명령어 결과
Credentialed Accounts
ACTIVE ACCOUNT
* <my_account>@<my_domain.com>
To set the active account, run:
$ gcloud config set account `ACCOUNT`
gcloud config list project
명령어 결과
[core] project = <PROJECT_ID>
또는 다음 명령어로 설정할 수 있습니다.
gcloud config set project <PROJECT_ID>
명령어 결과
Updated property [core/project].
3. BigQuery API 사용 설정
BigQuery API는 모든 Google Cloud 프로젝트에서 기본적으로 사용 설정되어야 합니다. Cloud Shell에서 다음 명령어를 사용하여 이를 확인할 수 있습니다.
gcloud services list
BigQuery가 다음과 같이 표시됩니다.
NAME TITLE
bigquery-json.googleapis.com BigQuery API
...
BigQuery API가 사용 설정되지 않은 경우 Cloud Shell에서 다음 명령어를 사용하여 사용 설정할 수 있습니다.
gcloud services enable bigquery-json.googleapis.com
4. API 요청 인증
BigQuery API에 요청을 수행하려면 서비스 계정을 사용해야 합니다. 서비스 계정은 프로젝트에 속하며 Google BigQuery Node.js 클라이언트 라이브러리에서 BigQuery API 요청을 수행하는 데 사용합니다. 다른 사용자 계정과 마찬가지로 서비스 계정은 이메일 주소로 표현됩니다. 이 섹션에서는 Cloud SDK를 사용하여 서비스 계정을 만든 후 서비스 계정으로 인증하는 데 필요한 사용자 인증 정보를 만듭니다.
먼저 이 Codelab 전체에서 사용할 PROJECT_ID로 환경 변수를 설정합니다.
export GOOGLE_CLOUD_PROJECT=$(gcloud config get-value core/project)
그런 후, 다음을 사용하여 BigQuery API에 액세스할 새 서비스 계정을 만듭니다.
gcloud iam service-accounts create my-bigquery-sa --display-name "my bigquery codelab service account"
다음으로, Node.js 코드가 새 서비스 계정으로 로그인할 때 사용할 사용자 인증 정보를 만듭니다. 이러한 사용자 인증 정보를 만들고, 다음 명령어를 사용하여 JSON 파일 '~/key.json'으로 저장합니다.
gcloud iam service-accounts keys create ~/key.json --iam-account my-bigquery-sa@${GOOGLE_CLOUD_PROJECT}.iam.gserviceaccount.com
마지막으로, 다음 단계에서 설명하는 BigQuery API C# 라이브러리에서 사용자 인증 정보를 찾는 데 사용하는 GOOGLE_APPLICATION_CREDENTIALS 환경 변수를 설정합니다. 환경 변수는 앞에서 만든 사용자 인증 정보 JSON 파일의 전체 경로로 설정해야 합니다. 다음 명령어를 사용하여 환경 변수를 설정합니다.
export GOOGLE_APPLICATION_CREDENTIALS="/home/${USER}/key.json"
BigQuery API 인증에 대해 자세히 알아보세요.
5. 액세스 제어 설정
BigQuery는 Identity and Access Management (IAM)를 사용하여 리소스에 대한 액세스를 관리합니다. BigQuery에는 이전 단계에서 만든 서비스 계정에 할당할 수 있는 여러 사전 정의된 역할 (사용자, dataOwner, dataViewer 등)이 있습니다. BigQuery 문서에서 액세스 제어에 대해 자세히 알아보세요.
공개 데이터 세트를 쿼리하려면 서비스 계정에 최소한 bigquery.user 역할이 있어야 합니다. Cloud Shell에서 다음 명령어를 실행하여 서비스 계정에 bigquery.user 역할을 할당합니다.
gcloud projects add-iam-policy-binding ${GOOGLE_CLOUD_PROJECT} --member "serviceAccount:my-bigquery-sa@${GOOGLE_CLOUD_PROJECT}.iam.gserviceaccount.com" --role "roles/bigquery.user"
다음 명령어를 실행하여 서비스 계정에 사용자 역할이 할당되었는지 확인할 수 있습니다.
gcloud projects get-iam-policy $GOOGLE_CLOUD_PROJECT
6. Node.js용 BigQuery 클라이언트 라이브러리 설치
먼저 BigQueryDemo 폴더를 만들고 해당 폴더로 이동합니다.
mkdir BigQueryDemo
cd BigQueryDemo
다음으로 BigQuery 클라이언트 라이브러리 샘플을 실행하는 데 사용할 Node.js 프로젝트를 만듭니다.
npm init -y
생성된 Node.js 프로젝트가 표시됩니다.
{
"name": "BigQueryDemo",
"version": "1.0.0",
"description": "",
"main": "index.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"keywords": [],
"author": "",
"license": "ISC"
}
BigQuery 클라이언트 라이브러리를 설치합니다.
npm install --save @google-cloud/bigquery
npm notice created a lockfile as package-lock.json. You should commit this file.
npm WARN BigQueryDemo@1.0.0 No description
npm WARN BigQueryDemo@1.0.0 No repository field.
+ @google-cloud/bigquery@2.1.0
added 69 packages from 105 contributors and audited 147 packages in 4.679s
found 0 vulnerabilities
이제 BigQuery Node.js 클라이언트 라이브러리를 사용할 수 있습니다.
7. 셰익스피어 작품 쿼리
공개 데이터 세트는 BigQuery에 저장되고 일반 대중이 사용할 수 있는 모든 데이터 세트입니다. 쿼리할 수 있는 공개 데이터세트는 많이 있습니다. 그 중 일부는 Google에서 호스팅되지만 타사에서 호스팅되는 데이터세트가 더 많습니다. 자세한 내용은 공개 데이터 세트 페이지를 참고하세요.
공개 데이터 세트 외에 BigQuery는 쿼리할 수 있는 샘플 테이블을 제한적으로 제공합니다. 이러한 테이블은 bigquery-public-data:samples dataset에 포함되어 있습니다. 이러한 테이블 중 하나는 shakespeare.입니다. 여기에는 셰익스피어 작품의 단어 색인이 포함되어 있으며 각 전집에서 각 단어가 등장하는 횟수가 제공됩니다.
이 단계에서는 shakespeare 테이블을 쿼리합니다.
먼저 Cloud Shell 오른쪽 상단에서 코드 편집기를 엽니다.
BigQueryDemo 폴더 내에 queryShakespeare.js 파일을 만듭니다.
touch queryShakespeare.js
queryShakespeare.js 파일로 이동하여 다음 코드를 삽입합니다.
'use strict';
function main() {
// Import the Google Cloud client library
const {BigQuery} = require('@google-cloud/bigquery');
async function queryShakespeare() {
// Queries a public Shakespeare dataset.
// Create a client
const bigqueryClient = new BigQuery();
// The SQL query to run
const sqlQuery = `SELECT word, word_count
FROM \`bigquery-public-data.samples.shakespeare\`
WHERE corpus = @corpus
AND word_count >= @min_word_count
ORDER BY word_count DESC`;
const options = {
query: sqlQuery,
// Location must match that of the dataset(s) referenced in the query.
location: 'US',
params: {corpus: 'romeoandjuliet', min_word_count: 250},
};
// Run the query
const [rows] = await bigqueryClient.query(options);
console.log('Rows:');
rows.forEach(row => console.log(row));
}
queryShakespeare();
}
main();
잠시 시간을 내어 코드를 살펴보고 테이블이 어떻게 쿼리되는지 확인하세요.
Cloud Shell로 돌아가서 앱을 실행합니다.
node queryShakespeare.js
단어 목록과 단어의 발생 횟수가 표시됩니다.
Rows:
{ word: 'the', word_count: 614 }
{ word: 'I', word_count: 577 }
{ word: 'and', word_count: 490 }
{ word: 'to', word_count: 486 }
{ word: 'a', word_count: 407 }
{ word: 'of', word_count: 367 }
{ word: 'my', word_count: 314 }
{ word: 'is', word_count: 307 }
...
8. GitHub 데이터 세트 쿼리
이제 BigQuery에 대해 자세히 알아보기 위해 GitHub 공개 데이터 세트에 대해 쿼리를 실행합니다. GitHub에서 가장 일반적인 커밋 메시지를 확인할 수 있습니다. BigQuery의 웹 UI를 사용하여 비정형 쿼리를 미리 보고 실행합니다.
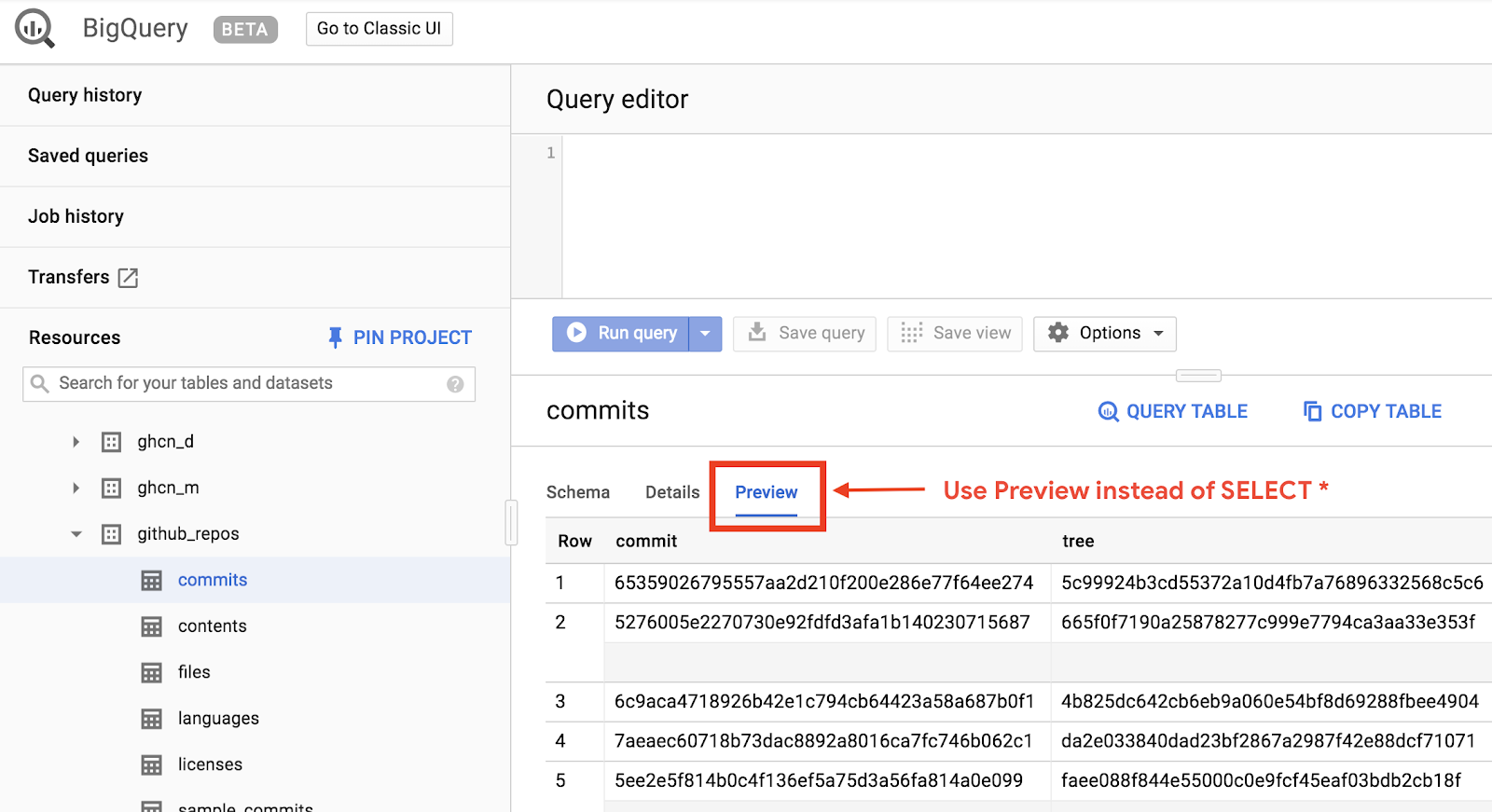
데이터를 보려면 BigQuery 웹 UI에서 GitHub 데이터세트를 여세요.
https://console.cloud.google.com/bigquery?p=bigquery-public-data&d=github_repos&t=commits&page=table
데이터가 어떻게 표시되는지 빠르게 미리 보려면 미리보기 탭을 클릭합니다.
BigQueryDemo 폴더 내에 queryGitHub.js 파일을 만듭니다.
touch queryGitHub.js
queryGitHub.js 파일로 이동하여 다음 코드를 삽입합니다.
'use strict';
function main() {
// Import the Google Cloud client library
const {BigQuery} = require('@google-cloud/bigquery');
async function queryGitHub() {
// Queries a public GitHub dataset.
// Create a client
const bigqueryClient = new BigQuery();
// The SQL query to run
const sqlQuery = `SELECT subject AS subject, COUNT(*) AS num_duplicates
FROM \`bigquery-public-data.github_repos.commits\`
GROUP BY subject
ORDER BY num_duplicates
DESC LIMIT 10`;
const options = {
query: sqlQuery,
// Location must match that of the dataset(s) referenced in the query.
location: 'US',
};
// Run the query
const [rows] = await bigqueryClient.query(options);
console.log('Rows:');
rows.forEach(row => console.log(`${row.subject}: ${row.num_duplicates}`));
}
queryGitHub();
}
main();
잠시 시간을 내어 코드를 살펴보고 가장 일반적인 커밋 메시지에 대해 테이블이 어떻게 쿼리되는지 확인하세요.
Cloud Shell로 돌아가서 앱을 실행합니다.
node queryGitHub.js
커밋 메시지 목록과 발생 횟수가 표시됩니다.
Rows:
Update README.md: 2572220
: 1985733
Initial commit: 1940228
Mirroring from Micro.blog.: 646772
update: 592520
Update data.json: 548730
Update data.js: 548354
...
9. 캐싱 및 통계
쿼리를 실행하면 BigQuery에서 결과를 캐시합니다. 따라서 후속 동일한 쿼리는 시간이 훨씬 적게 걸립니다. 쿼리 옵션을 사용하여 캐싱을 사용 중지할 수 있습니다. BigQuery는 생성 시간, 종료 시간, 총 처리된 바이트 수와 같은 쿼리에 관한 일부 통계도 추적합니다.
이 단계에서는 캐싱을 사용 중지하고 쿼리에 관한 일부 통계를 표시합니다.
BigQueryDemo 폴더 내의 queryShakespeare.js 파일로 이동하여 코드를 다음으로 바꿉니다.
'use strict';
function main() {
// Import the Google Cloud client library
const {BigQuery} = require('@google-cloud/bigquery');
async function queryShakespeareDisableCache() {
// Queries the Shakespeare dataset with the cache disabled.
// Create a client
const bigqueryClient = new BigQuery();
const sqlQuery = `SELECT word, word_count
FROM \`bigquery-public-data.samples.shakespeare\`
WHERE corpus = @corpus
AND word_count >= @min_word_count
ORDER BY word_count DESC`;
const options = {
query: sqlQuery,
// Location must match that of the dataset(s) referenced in the query.
location: 'US',
params: {corpus: 'romeoandjuliet', min_word_count: 250},
useQueryCache: false,
};
// Run the query as a job
const [job] = await bigqueryClient.createQueryJob(options);
console.log(`Job ${job.id} started.`);
// Wait for the query to finish
const [rows] = await job.getQueryResults();
// Print the results
console.log('Rows:');
rows.forEach(row => console.log(row));
// Print job statistics
console.log('JOB STATISTICS:')
console.log(`Status: ${job.metadata.status.state}`);
console.log(`Creation time: ${job.metadata.statistics.creationTime}`);
console.log(`Start time: ${job.metadata.statistics.startTime}`);
console.log(`Statement type: ${job.metadata.statistics.query.statementType}`);
}
queryShakespeareDisableCache();
}
main();
코드에 관해 몇 가지 참고할 사항이 있습니다. 먼저 options 객체 내에서 UseQueryCache을 false로 설정하여 캐싱을 사용 중지합니다. 두 번째로 작업 객체에서 쿼리에 관한 통계에 액세스했습니다.
Cloud Shell로 돌아가서 앱을 실행합니다.
node queryShakespeare.js
커밋 메시지 목록과 발생 횟수가 표시됩니다. 또한 쿼리에 관한 통계도 표시됩니다.
Rows:
{ word: 'the', word_count: 614 }
{ word: 'I', word_count: 577 }
{ word: 'and', word_count: 490 }
{ word: 'to', word_count: 486 }
{ word: 'a', word_count: 407 }
{ word: 'of', word_count: 367 }
{ word: 'my', word_count: 314 }
{ word: 'is', word_count: 307 }
{ word: 'in', word_count: 291 }
{ word: 'you', word_count: 271 }
{ word: 'that', word_count: 270 }
{ word: 'me', word_count: 263 }
JOB STATISTICS:
Status: RUNNING
Creation time: 1554309220660
Start time: 1554309220793
Statement type: SELECT
10. BigQuery에 데이터 로드
자체 데이터를 쿼리하려면 먼저 BigQuery에 데이터를 로드해야 합니다. BigQuery는 Google Cloud Storage, 기타 Google 서비스, 읽을 수 있는 로컬 소스와 같은 다양한 소스에서 데이터 로드를 지원합니다. 데이터를 스트리밍할 수도 있습니다. BigQuery에 데이터 로드 페이지에서 자세히 알아보세요.
이 단계에서는 Google Cloud Storage에 저장된 JSON 파일을 BigQuery 테이블에 로드합니다. JSON 파일은 gs://cloud-samples-data/bigquery/us-states/us-states.json에 있습니다.
JSON 파일의 내용이 궁금하다면 gsutil 명령줄 도구를 사용하여 Cloud Shell에서 다운로드하면 됩니다.
gsutil cp gs://cloud-samples-data/bigquery/us-states/us-states.json .
Copying gs://cloud-samples-data/bigquery/us-states/us-states.json...
/ [1 files][ 2.0 KiB/ 2.0 KiB]
Operation completed over 1 objects/2.0 KiB.
미국 주 목록이 포함되어 있으며 각 주는 별도의 줄에 있는 JSON 객체입니다.
less us-states.json
{"name": "Alabama", "post_abbr": "AL"}
{"name": "Alaska", "post_abbr": "AK"}
...
이 JSON 파일을 BigQuery에 로드하려면 BigQueryDemo 폴더 내에 createDataset.js 파일과 loadBigQueryJSON.js 파일을 만드세요.
touch createDataset.js
touch loadBigQueryJSON.js
Google Cloud Storage Node.js 클라이언트 라이브러리를 설치합니다.
npm install --save @google-cloud/storage
createDataset.js 파일로 이동하여 다음 코드를 삽입합니다.
'use strict';
function main() {
// Import the Google Cloud client libraries
const {BigQuery} = require('@google-cloud/bigquery');
async function createDataset() {
const datasetId = "my_states_dataset3";
const bigqueryClient = new BigQuery();
// Specify the geographic location where the dataset should reside
const options = {
location: 'US',
};
// Create a new dataset
const [dataset] = await bigqueryClient.createDataset(datasetId, options);
console.log(`Dataset ${dataset.id} created.`);
}
createDataset();
}
main();
그런 다음 loadBigQueryJSON.js 파일로 이동하여 다음 코드를 삽입합니다.
'use strict';
function main() {
// Import the Google Cloud client libraries
const {BigQuery} = require('@google-cloud/bigquery');
const {Storage} = require('@google-cloud/storage');
const datasetId = "my_states_dataset3";
const tableId = "my_states_table";
async function createTable(datasetId, tableId) {
// Creates a new table
// Create a client
const bigqueryClient = new BigQuery();
const options = {
location: 'US',
};
// Create a new table in the dataset
const [table] = await bigqueryClient
.dataset(datasetId)
.createTable(tableId, options);
console.log(`Table ${table.id} created.`);
}
async function loadJSONFromGCS(datasetId, tableId) {
// Import a GCS file into a table with manually defined schema.
// Instantiate clients
const bigqueryClient = new BigQuery();
const storageClient = new Storage();
const bucketName = 'cloud-samples-data';
const filename = 'bigquery/us-states/us-states.json';
// Configure the load job.
const metadata = {
sourceFormat: 'NEWLINE_DELIMITED_JSON',
schema: {
fields: [
{name: 'name', type: 'STRING'},
{name: 'post_abbr', type: 'STRING'},
],
},
location: 'US',
};
// Load data from a Google Cloud Storage file into the table
const [job] = await bigqueryClient
.dataset(datasetId)
.table(tableId)
.load(storageClient.bucket(bucketName).file(filename), metadata);
// load() waits for the job to finish
console.log(`Job ${job.id} completed.`);
// Check the job's status for errors
const errors = job.status.errors;
if (errors && errors.length > 0) {
throw errors;
}
}
// createDataset(datasetId);
createTable(datasetId, tableId);
loadJSONFromGCS(datasetId, tableId);
}
main();
잠시 시간을 내어 코드가 JSON 파일을 로드하고 데이터 세트에 스키마가 있는 테이블을 만드는 방법을 살펴봅니다.
Cloud Shell로 돌아가서 앱을 실행합니다.
node createDataset.js
node loadBigQueryJSON.js
BigQuery에 데이터 세트와 테이블이 생성됩니다.
Table my_states_table created.
Job [JOB ID] completed.
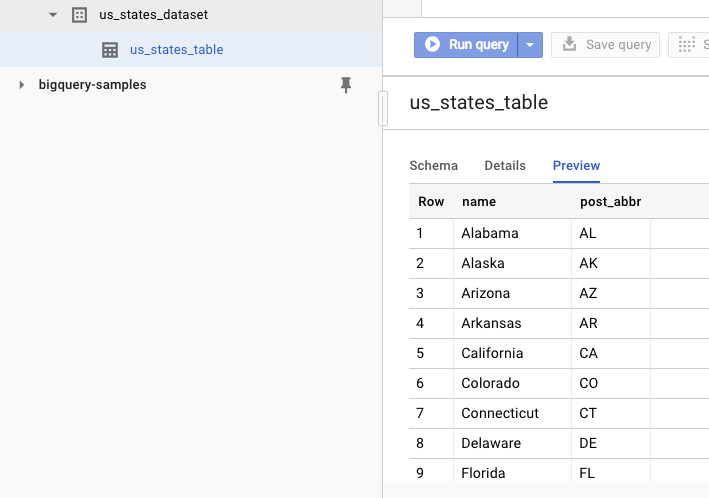
데이터 세트가 생성되었는지 확인하려면 BigQuery 웹 UI로 이동하면 됩니다. 새 데이터 세트와 테이블이 표시됩니다. 표의 미리보기 탭으로 전환하면 실제 데이터를 확인할 수 있습니다.
11. 축하합니다.
Node.js를 사용하여 BigQuery를 사용하는 방법을 배웠습니다.
삭제
이 빠른 시작에서 사용한 리소스 비용이 Google Cloud Platform 계정에 청구되지 않도록 하는 방법은 다음과 같습니다.
- Cloud Platform 콘솔로 이동합니다.
- 종료하려는 프로젝트를 선택한 다음 상단의 '삭제'를 클릭합니다. 그러면 프로젝트가 삭제 예약됩니다.
자세히 알아보기
- Google BigQuery: https://cloud.google.com/bigquery/docs/
- Google Cloud Platform의 Node.js: https://cloud.google.com/nodejs/
- Google BigQuery Node.js 클라이언트 라이브러리: https://github.com/googleapis/nodejs-bigquery
라이선스
이 작업물은 Creative Commons Attribution 2.0 일반 라이선스에 따라 사용이 허가되었습니다.