
1. Обзор
BigQuery — это полностью управляемое, масштабируемое до петабайтов и недорогое хранилище аналитических данных от Google. BigQuery не требует управления инфраструктурой и не нуждается в администраторе базы данных, поэтому вы можете сосредоточиться на анализе данных для получения ценных выводов, использовать привычный SQL и воспользоваться преимуществами модели оплаты по мере использования.
В этом практическом занятии вы будете использовать клиентскую библиотеку Google Cloud BigQuery для выполнения запросов к общедоступным наборам данных BigQuery с помощью Node.js.
Что вы узнаете
- Как использовать Cloud Shell
- Как включить API BigQuery
- Как аутентифицировать запросы API
- Как установить клиентскую библиотеку BigQuery для Node.js
- Как задавать вопросы по поводу произведений Шекспира
- Как выполнить запрос к набору данных GitHub
- Как настроить кэширование и отображение статистики
Что вам понадобится
Опрос
Как вы будете использовать этот учебный материал?
Как бы вы оценили свой опыт работы с Node.js?
Как бы вы оценили свой опыт использования сервисов Google Cloud Platform?
2. Настройка и требования
Настройка среды для самостоятельного обучения
- Войдите в Cloud Console и создайте новый проект или используйте существующий. (Если у вас еще нет учетной записи Gmail или G Suite, вам необходимо ее создать .)


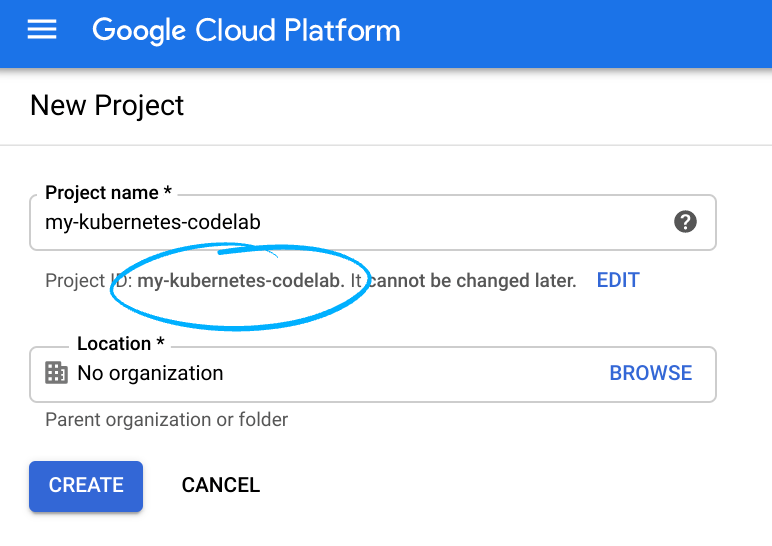
Запомните идентификатор проекта (Project ID) — уникальное имя для всех проектов Google Cloud (указанное выше имя уже занято и вам не подойдёт, извините!). В дальнейшем в этом практическом занятии оно будет обозначаться как PROJECT_ID .
- Далее вам потребуется включить оплату в Cloud Console, чтобы использовать ресурсы Google Cloud.
Выполнение этого практического задания не должно стоить дорого, если вообще что-либо. Обязательно следуйте инструкциям в разделе «Очистка», где указано, как отключить ресурсы, чтобы избежать дополнительных расходов после завершения этого урока. Новые пользователи Google Cloud имеют право на бесплатную пробную версию стоимостью 300 долларов США .
Запустить Cloud Shell
Хотя инструментом командной строки Cloud SDK можно управлять удаленно с ноутбука, в этом практическом занятии вы будете использовать Google Cloud Shell — среду командной строки, работающую в облаке.
Активировать Cloud Shell
- В консоли Cloud нажмите «Активировать Cloud Shell» .
.

Если вы никогда раньше не запускали Cloud Shell, вам будет показан промежуточный экран (внизу), описывающий его назначение. В этом случае нажмите «Продолжить» (и вы больше никогда его не увидите). Вот как выглядит этот одноразовый экран:

Подготовка и подключение к Cloud Shell займут всего несколько минут.

Эта виртуальная машина оснащена всеми необходимыми инструментами разработки. Она предоставляет постоянный домашний каталог размером 5 ГБ и работает в облаке Google, что значительно повышает производительность сети и аутентификацию. Большая часть, если не вся, работа в этом практическом задании может быть выполнена с помощью обычного браузера или вашего Chromebook.
После подключения к Cloud Shell вы увидите, что ваша аутентификация пройдена и что проект уже настроен на ваш идентификатор проекта.
- Выполните следующую команду в Cloud Shell, чтобы подтвердить свою аутентификацию:
gcloud auth list
вывод команды
Credentialed Accounts
ACTIVE ACCOUNT
* <my_account>@<my_domain.com>
To set the active account, run:
$ gcloud config set account `ACCOUNT`
gcloud config list project
вывод команды
[core] project = <PROJECT_ID>
Если это не так, вы можете установить это с помощью следующей команды:
gcloud config set project <PROJECT_ID>
вывод команды
Updated property [core/project].
3. Включите API BigQuery.
API BigQuery должен быть включен по умолчанию во всех проектах Google Cloud. Проверить это можно с помощью следующей команды в Cloud Shell:
gcloud services list
В списке должен отображаться BigQuery:
NAME TITLE
bigquery-json.googleapis.com BigQuery API
...
Если API BigQuery не включен, вы можете включить его с помощью следующей команды в Cloud Shell:
gcloud services enable bigquery-json.googleapis.com
4. Аутентификация API-запросов
Для отправки запросов к API BigQuery вам потребуется использовать сервисный аккаунт . Сервисный аккаунт принадлежит вашему проекту и используется клиентской библиотекой Google BigQuery Node.js для отправки запросов к API BigQuery. Как и любая другая учетная запись пользователя, сервисный аккаунт представлен адресом электронной почты. В этом разделе вы будете использовать Cloud SDK для создания сервисного аккаунта, а затем создадите учетные данные, необходимые для аутентификации в качестве сервисного аккаунта.
Сначала установите переменную окружения с вашим PROJECT_ID, которую вы будете использовать на протяжении всего этого практического занятия:
export GOOGLE_CLOUD_PROJECT=$(gcloud config get-value core/project)
Далее создайте новую учетную запись службы для доступа к API BigQuery, используя:
gcloud iam service-accounts create my-bigquery-sa --display-name "my bigquery codelab service account"
Далее создайте учетные данные, которые ваш код Node.js будет использовать для входа в систему под вашей новой учетной записью службы. Создайте эти учетные данные и сохраните их в виде JSON-файла " ~/key.json ", используя следующую команду:
gcloud iam service-accounts keys create ~/key.json --iam-account my-bigquery-sa@${GOOGLE_CLOUD_PROJECT}.iam.gserviceaccount.com
Наконец, установите переменную среды GOOGLE_APPLICATION_CREDENTIALS , которая используется библиотекой C# API BigQuery (описанной на следующем шаге), чтобы найти свои учетные данные. Переменная среды должна быть установлена на полный путь к созданному вами JSON-файлу с учетными данными. Установите переменную среды с помощью следующей команды:
export GOOGLE_APPLICATION_CREDENTIALS="/home/${USER}/key.json"
Вы можете узнать больше об аутентификации в API BigQuery .
5. Настройка контроля доступа
BigQuery использует систему управления идентификацией и доступом (IAM) для управления доступом к ресурсам. В BigQuery есть ряд предопределенных ролей (пользователь, владелец данных, пользователь данных и т. д.), которые вы можете назначить своей учетной записи службы, созданной на предыдущем шаге. Подробнее о контроле доступа можно узнать в документации BigQuery.
Прежде чем запрашивать общедоступные наборы данных, необходимо убедиться, что у учетной записи службы есть как минимум роль bigquery.user . В Cloud Shell выполните следующую команду, чтобы назначить учетной записи службы роль bigquery.user:
gcloud projects add-iam-policy-binding ${GOOGLE_CLOUD_PROJECT} --member "serviceAccount:my-bigquery-sa@${GOOGLE_CLOUD_PROJECT}.iam.gserviceaccount.com" --role "roles/bigquery.user"
Для проверки того, что учетной записи службы назначена роль пользователя, можно выполнить следующую команду:
gcloud projects get-iam-policy $GOOGLE_CLOUD_PROJECT
6. Установите клиентскую библиотеку BigQuery для Node.js.
Сначала создайте папку BigQueryDemo и перейдите в неё:
mkdir BigQueryDemo
cd BigQueryDemo
Далее создайте проект Node.js, который вы будете использовать для запуска примеров клиентской библиотеки BigQuery:
npm init -y
Вы должны увидеть созданный проект Node.js:
{
"name": "BigQueryDemo",
"version": "1.0.0",
"description": "",
"main": "index.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"keywords": [],
"author": "",
"license": "ISC"
}
Установите клиентскую библиотеку BigQuery:
npm install --save @google-cloud/bigquery
npm notice created a lockfile as package-lock.json. You should commit this file.
npm WARN BigQueryDemo@1.0.0 No description
npm WARN BigQueryDemo@1.0.0 No repository field.
+ @google-cloud/bigquery@2.1.0
added 69 packages from 105 contributors and audited 147 packages in 4.679s
found 0 vulnerabilities
Теперь вы готовы использовать клиентскую библиотеку BigQuery для Node.js!
7. Проанализируйте произведения Шекспира.
Общедоступный набор данных — это любой набор данных, хранящийся в BigQuery и доступный для широкой публики. Существует множество других общедоступных наборов данных, к которым вы можете обращаться с запросами, некоторые из которых также размещены Google, но гораздо больше тех, которые размещены сторонними организациями. Подробнее можно узнать на странице «Общедоступные наборы данных» .
Помимо общедоступных наборов данных, BigQuery предоставляет ограниченное количество примеров таблиц , к которым можно обращаться с запросами. Эти таблицы содержатся в bigquery-public-data:samples dataset . Одна из этих таблиц называется shakespeare. Она содержит указатель слов в произведениях Шекспира, показывающий количество раз, когда каждое слово встречается в каждом корпусе.
На этом этапе вы выполните запрос к таблице Шекспира.
Сначала откройте редактор кода в правом верхнем углу Cloud Shell:
Создайте файл queryShakespeare.js внутри папки BigQueryDemo :
touch queryShakespeare.js
Перейдите к файлу queryShakespeare.js и вставьте следующий код:
'use strict';
function main() {
// Import the Google Cloud client library
const {BigQuery} = require('@google-cloud/bigquery');
async function queryShakespeare() {
// Queries a public Shakespeare dataset.
// Create a client
const bigqueryClient = new BigQuery();
// The SQL query to run
const sqlQuery = `SELECT word, word_count
FROM \`bigquery-public-data.samples.shakespeare\`
WHERE corpus = @corpus
AND word_count >= @min_word_count
ORDER BY word_count DESC`;
const options = {
query: sqlQuery,
// Location must match that of the dataset(s) referenced in the query.
location: 'US',
params: {corpus: 'romeoandjuliet', min_word_count: 250},
};
// Run the query
const [rows] = await bigqueryClient.query(options);
console.log('Rows:');
rows.forEach(row => console.log(row));
}
queryShakespeare();
}
main();
Уделите минуту-две изучению кода и посмотрите, как выполняется запрос к таблице.
Вернувшись в Cloud Shell, запустите приложение:
node queryShakespeare.js
Вы должны увидеть список слов и количество их вхождений:
Rows:
{ word: 'the', word_count: 614 }
{ word: 'I', word_count: 577 }
{ word: 'and', word_count: 490 }
{ word: 'to', word_count: 486 }
{ word: 'a', word_count: 407 }
{ word: 'of', word_count: 367 }
{ word: 'my', word_count: 314 }
{ word: 'is', word_count: 307 }
...
8. Выполните запрос к набору данных GitHub.
Чтобы лучше познакомиться с BigQuery, вы сейчас выполните запрос к общедоступному набору данных GitHub . Наиболее часто встречающиеся сообщения коммитов вы найдете на GitHub. Вы также будете использовать веб-интерфейс BigQuery для предварительного просмотра и выполнения запросов по мере необходимости.
Для просмотра данных откройте набор данных GitHub в веб-интерфейсе BigQuery:
https://console.cloud.google.com/bigquery?p=bigquery-public-data&d=github_repos&t=commits&page=table
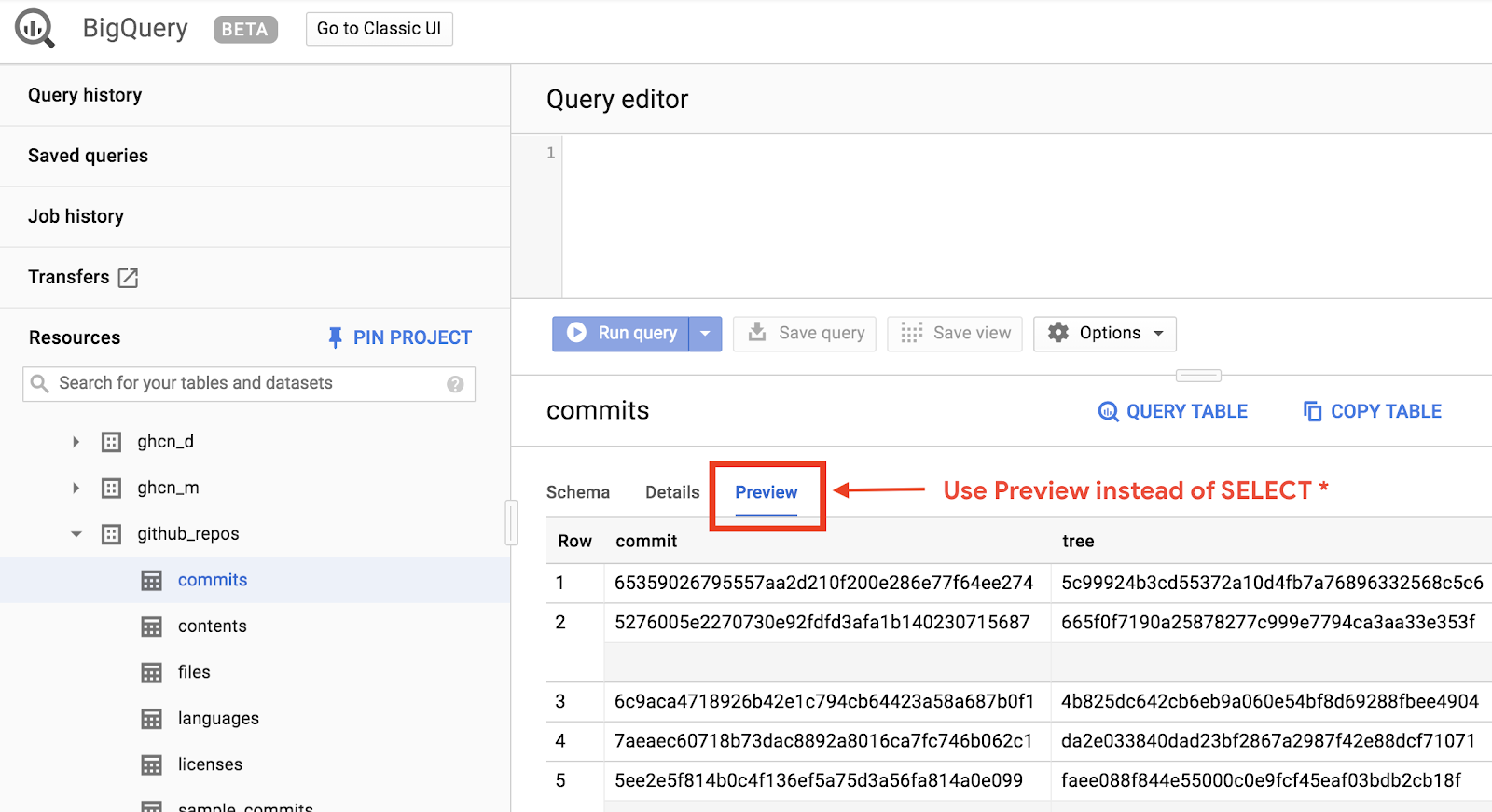
Чтобы быстро просмотреть, как выглядят данные, нажмите вкладку «Предварительный просмотр»:
Создайте файл queryGitHub.js внутри папки BigQueryDemo :
touch queryGitHub.js
Перейдите к файлу queryGitHub.js и вставьте следующий код:
'use strict';
function main() {
// Import the Google Cloud client library
const {BigQuery} = require('@google-cloud/bigquery');
async function queryGitHub() {
// Queries a public GitHub dataset.
// Create a client
const bigqueryClient = new BigQuery();
// The SQL query to run
const sqlQuery = `SELECT subject AS subject, COUNT(*) AS num_duplicates
FROM \`bigquery-public-data.github_repos.commits\`
GROUP BY subject
ORDER BY num_duplicates
DESC LIMIT 10`;
const options = {
query: sqlQuery,
// Location must match that of the dataset(s) referenced in the query.
location: 'US',
};
// Run the query
const [rows] = await bigqueryClient.query(options);
console.log('Rows:');
rows.forEach(row => console.log(`${row.subject}: ${row.num_duplicates}`));
}
queryGitHub();
}
main();
Уделите минуту-две изучению кода и посмотрите, как выполняется запрос к таблице для получения наиболее часто встречающихся сообщений коммитов.
Вернувшись в Cloud Shell, запустите приложение:
node queryGitHub.js
Вы должны увидеть список сообщений коммитов и их количество:
Rows:
Update README.md: 2572220
: 1985733
Initial commit: 1940228
Mirroring from Micro.blog.: 646772
update: 592520
Update data.json: 548730
Update data.js: 548354
...
9. Кэширование и статистика
При выполнении запроса BigQuery кэширует результаты. В результате последующие идентичные запросы выполняются значительно быстрее. Кэширование можно отключить с помощью параметров запроса. BigQuery также отслеживает некоторую статистику по запросам, такую как время создания, время завершения и общее количество обработанных байтов.
На этом шаге вы отключите кэширование и отобразите некоторую статистику по запросам.
Перейдите к файлу queryShakespeare.js в папке BigQueryDemo и замените в нём следующий код:
'use strict';
function main() {
// Import the Google Cloud client library
const {BigQuery} = require('@google-cloud/bigquery');
async function queryShakespeareDisableCache() {
// Queries the Shakespeare dataset with the cache disabled.
// Create a client
const bigqueryClient = new BigQuery();
const sqlQuery = `SELECT word, word_count
FROM \`bigquery-public-data.samples.shakespeare\`
WHERE corpus = @corpus
AND word_count >= @min_word_count
ORDER BY word_count DESC`;
const options = {
query: sqlQuery,
// Location must match that of the dataset(s) referenced in the query.
location: 'US',
params: {corpus: 'romeoandjuliet', min_word_count: 250},
useQueryCache: false,
};
// Run the query as a job
const [job] = await bigqueryClient.createQueryJob(options);
console.log(`Job ${job.id} started.`);
// Wait for the query to finish
const [rows] = await job.getQueryResults();
// Print the results
console.log('Rows:');
rows.forEach(row => console.log(row));
// Print job statistics
console.log('JOB STATISTICS:')
console.log(`Status: ${job.metadata.status.state}`);
console.log(`Creation time: ${job.metadata.statistics.creationTime}`);
console.log(`Start time: ${job.metadata.statistics.startTime}`);
console.log(`Statement type: ${job.metadata.statistics.query.statementType}`);
}
queryShakespeareDisableCache();
}
main();
Несколько замечаний по поводу кода. Во-первых, кэширование отключается путем установки UseQueryCache в false в объекте options . Во-вторых, вы получаете доступ к статистике запроса из объекта job.
Вернувшись в Cloud Shell, запустите приложение:
node queryShakespeare.js
Вы должны увидеть список сообщений коммитов и количество их вхождений. Кроме того, вы также должны увидеть некоторую статистику по запросу:
Rows:
{ word: 'the', word_count: 614 }
{ word: 'I', word_count: 577 }
{ word: 'and', word_count: 490 }
{ word: 'to', word_count: 486 }
{ word: 'a', word_count: 407 }
{ word: 'of', word_count: 367 }
{ word: 'my', word_count: 314 }
{ word: 'is', word_count: 307 }
{ word: 'in', word_count: 291 }
{ word: 'you', word_count: 271 }
{ word: 'that', word_count: 270 }
{ word: 'me', word_count: 263 }
JOB STATISTICS:
Status: RUNNING
Creation time: 1554309220660
Start time: 1554309220793
Statement type: SELECT
10. Загрузка данных в BigQuery
Если вы хотите запрашивать собственные данные, вам сначала нужно загрузить их в BigQuery. BigQuery поддерживает загрузку данных из множества источников, таких как Google Cloud Storage, другие сервисы Google или локальный, доступный для чтения источник. Вы даже можете передавать данные потоком. Подробнее об этом можно прочитать на странице «Загрузка данных в BigQuery» .
На этом шаге вы загрузите JSON-файл, хранящийся в Google Cloud Storage, в таблицу BigQuery. JSON-файл находится по адресу: gs://cloud-samples-data/bigquery/us-states/us-states.json
Если вам интересно содержимое JSON-файла, вы можете использовать инструмент командной строки gsutil для его загрузки в Cloud Shell:
gsutil cp gs://cloud-samples-data/bigquery/us-states/us-states.json .
Copying gs://cloud-samples-data/bigquery/us-states/us-states.json...
/ [1 files][ 2.0 KiB/ 2.0 KiB]
Operation completed over 1 objects/2.0 KiB.
Как видите, здесь представлен список штатов США, причём каждый штат представляет собой JSON-объект на отдельной строке:
less us-states.json
{"name": "Alabama", "post_abbr": "AL"}
{"name": "Alaska", "post_abbr": "AK"}
...
Для загрузки этого JSON-файла в BigQuery создайте файлы createDataset.js и loadBigQueryJSON.js в папке BigQueryDemo :
touch createDataset.js
touch loadBigQueryJSON.js
Установите клиентскую библиотеку Google Cloud Storage для Node.js:
npm install --save @google-cloud/storage
Перейдите к файлу createDataset.js и вставьте следующий код:
'use strict';
function main() {
// Import the Google Cloud client libraries
const {BigQuery} = require('@google-cloud/bigquery');
async function createDataset() {
const datasetId = "my_states_dataset3";
const bigqueryClient = new BigQuery();
// Specify the geographic location where the dataset should reside
const options = {
location: 'US',
};
// Create a new dataset
const [dataset] = await bigqueryClient.createDataset(datasetId, options);
console.log(`Dataset ${dataset.id} created.`);
}
createDataset();
}
main();
Затем перейдите к файлу loadBigQueryJSON.js и вставьте следующий код:
'use strict';
function main() {
// Import the Google Cloud client libraries
const {BigQuery} = require('@google-cloud/bigquery');
const {Storage} = require('@google-cloud/storage');
const datasetId = "my_states_dataset3";
const tableId = "my_states_table";
async function createTable(datasetId, tableId) {
// Creates a new table
// Create a client
const bigqueryClient = new BigQuery();
const options = {
location: 'US',
};
// Create a new table in the dataset
const [table] = await bigqueryClient
.dataset(datasetId)
.createTable(tableId, options);
console.log(`Table ${table.id} created.`);
}
async function loadJSONFromGCS(datasetId, tableId) {
// Import a GCS file into a table with manually defined schema.
// Instantiate clients
const bigqueryClient = new BigQuery();
const storageClient = new Storage();
const bucketName = 'cloud-samples-data';
const filename = 'bigquery/us-states/us-states.json';
// Configure the load job.
const metadata = {
sourceFormat: 'NEWLINE_DELIMITED_JSON',
schema: {
fields: [
{name: 'name', type: 'STRING'},
{name: 'post_abbr', type: 'STRING'},
],
},
location: 'US',
};
// Load data from a Google Cloud Storage file into the table
const [job] = await bigqueryClient
.dataset(datasetId)
.table(tableId)
.load(storageClient.bucket(bucketName).file(filename), metadata);
// load() waits for the job to finish
console.log(`Job ${job.id} completed.`);
// Check the job's status for errors
const errors = job.status.errors;
if (errors && errors.length > 0) {
throw errors;
}
}
// createDataset(datasetId);
createTable(datasetId, tableId);
loadJSONFromGCS(datasetId, tableId);
}
main();
Уделите минуту-две изучению того, как код загружает JSON-файл и создает таблицу (со схемой) в наборе данных.
Вернувшись в Cloud Shell, запустите приложение:
node createDataset.js
node loadBigQueryJSON.js
В BigQuery создаются набор данных и таблица:
Table my_states_table created.
Job [JOB ID] completed.
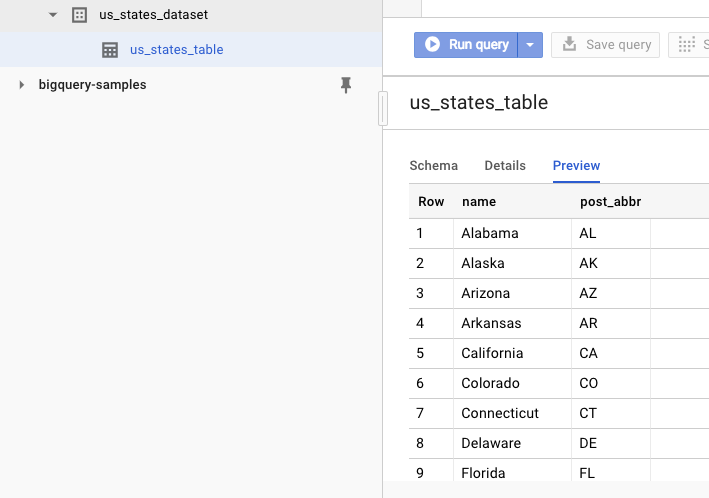
Чтобы убедиться, что набор данных создан, перейдите в веб-интерфейс BigQuery. Вы должны увидеть новый набор данных и таблицу. Если вы перейдете на вкладку «Предварительный просмотр» таблицы, вы сможете увидеть фактические данные:
11. Поздравляем!
Вы научились использовать BigQuery с помощью Node.js!
Уборка
Чтобы избежать списания средств с вашего счета Google Cloud Platform за ресурсы, использованные в этом кратком руководстве:
- Перейдите в консоль облачной платформы .
- Выберите проект, который хотите закрыть, затем нажмите кнопку «Удалить» вверху: это запланирует удаление проекта.
Узнать больше
- Google BigQuery: https://cloud.google.com/bigquery/docs/
- Node.js на платформе Google Cloud Platform: https://cloud.google.com/nodejs/
- Клиентская библиотека Google BigQuery для Node.js: https://github.com/googleapis/nodejs-bigquery
Лицензия
Данная работа распространяется под лицензией Creative Commons Attribution 2.0 Generic.