
1. ภาพรวม
BigQuery คือคลังข้อมูลการวิเคราะห์ที่มีการจัดการอย่างเต็มรูปแบบ มีความจุระดับเพทาไบต์ และมีต้นทุนต่ำของ Google BigQuery เป็น NoOps ซึ่งไม่มีโครงสร้างพื้นฐานที่ต้องจัดการและคุณไม่จำเป็นต้องมีผู้ดูแลฐานข้อมูล คุณจึงมุ่งเน้นที่การวิเคราะห์ข้อมูลเพื่อค้นหาข้อมูลเชิงลึกที่มีความหมาย ใช้ SQL ที่คุ้นเคย และใช้ประโยชน์จากโมเดลการชำระเงินตามการใช้งาน
ในโค้ดแล็บนี้ คุณจะได้ใช้คลังไคลเอ็นต์ Google Cloud BigQuery เพื่อค้นหาชุดข้อมูลสาธารณะของ BigQuery ด้วย Node.js
สิ่งที่คุณจะได้เรียนรู้
- วิธีใช้ Cloud Shell
- วิธีเปิดใช้ BigQuery API
- วิธีตรวจสอบสิทธิ์คำขอ API
- วิธีติดตั้งไลบรารีของไคลเอ็นต์ BigQuery สำหรับ Node.js
- วิธีค้นหาผลงานของเชกสเปียร์
- วิธีค้นหาชุดข้อมูล GitHub
- วิธีปรับสถิติการแคชและการแสดงผล
สิ่งที่คุณต้องมี
แบบสำรวจ
คุณจะใช้บทแนะนำนี้อย่างไร
คุณจะให้คะแนนประสบการณ์การใช้งาน Node.js เท่าใด
คุณจะให้คะแนนประสบการณ์การใช้บริการ Google Cloud Platform เท่าใด
2. การตั้งค่าและข้อกำหนด
การตั้งค่าสภาพแวดล้อมแบบเรียนรู้ด้วยตนเอง
- ลงชื่อเข้าใช้ Cloud Console แล้วสร้างโปรเจ็กต์ใหม่หรือใช้โปรเจ็กต์ที่มีอยู่ซ้ำ (หากยังไม่มีบัญชี Gmail หรือ G Suite คุณต้องสร้างบัญชี)


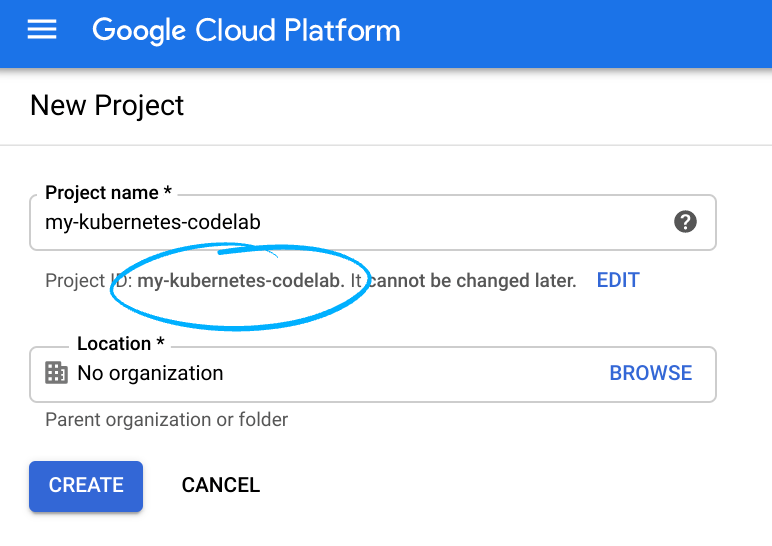
โปรดจดจำรหัสโปรเจ็กต์ ซึ่งเป็นชื่อที่ไม่ซ้ำกันในโปรเจ็กต์ Google Cloud ทั้งหมด (ชื่อด้านบนมีผู้ใช้แล้วและจะใช้ไม่ได้ ขออภัย) ซึ่งจะเรียกว่า PROJECT_ID ในภายหลังใน Codelab นี้
- จากนั้นคุณจะต้องเปิดใช้การเรียกเก็บเงินใน Cloud Console เพื่อใช้ทรัพยากร Google Cloud
การทำตาม Codelab นี้ไม่ควรมีค่าใช้จ่ายมากนัก หรืออาจไม่มีเลย โปรดทำตามวิธีการในส่วน "การล้างข้อมูล" ซึ่งจะแนะนำวิธีปิดทรัพยากรเพื่อไม่ให้มีการเรียกเก็บเงินนอกเหนือจากบทแนะนำนี้ ผู้ใช้ Google Cloud รายใหม่มีสิทธิ์เข้าร่วมโปรแกรมช่วงทดลองใช้ฟรีมูลค่า$300 USD
เริ่มต้น Cloud Shell
แม้ว่าเครื่องมือบรรทัดคำสั่ง Cloud SDK จะใช้งานจากแล็ปท็อประยะไกลได้ แต่ใน Codelab นี้คุณจะใช้ Google Cloud Shell ซึ่งเป็นสภาพแวดล้อมบรรทัดคำสั่งที่ทำงานในระบบคลาวด์
เปิดใช้งาน Cloud Shell
- จาก Cloud Console ให้คลิกเปิดใช้งาน Cloud Shell


หากไม่เคยเริ่มใช้ Cloud Shell มาก่อน คุณจะเห็นหน้าจอระดับกลาง (ด้านล่าง) ที่อธิบายว่า Cloud Shell คืออะไร ในกรณีนี้ ให้คลิกต่อไป (และคุณจะไม่เห็นหน้าจอนี้อีก) หน้าจอแบบครั้งเดียวจะมีลักษณะดังนี้

การจัดสรรและเชื่อมต่อกับ Cloud Shell จะใช้เวลาไม่นาน

เครื่องเสมือนนี้มีเครื่องมือพัฒนาซอฟต์แวร์ทั้งหมดที่คุณต้องการ โดยมีไดเรกทอรีหลักแบบถาวรขนาด 5 GB และทำงานใน Google Cloud ซึ่งช่วยเพิ่มประสิทธิภาพเครือข่ายและการตรวจสอบสิทธิ์ได้อย่างมาก คุณสามารถทำงานในโค้ดแล็บนี้ได้โดยใช้เพียงเบราว์เซอร์หรือ Chromebook
เมื่อเชื่อมต่อกับ Cloud Shell แล้ว คุณควรเห็นว่าคุณได้รับการตรวจสอบสิทธิ์แล้วและโปรเจ็กต์ได้รับการตั้งค่าเป็นรหัสโปรเจ็กต์ของคุณแล้ว
- เรียกใช้คำสั่งต่อไปนี้ใน Cloud Shell เพื่อยืนยันว่าคุณได้รับการตรวจสอบสิทธิ์แล้ว
gcloud auth list
เอาต์พุตของคำสั่ง
Credentialed Accounts
ACTIVE ACCOUNT
* <my_account>@<my_domain.com>
To set the active account, run:
$ gcloud config set account `ACCOUNT`
gcloud config list project
เอาต์พุตของคำสั่ง
[core] project = <PROJECT_ID>
หากไม่ได้ตั้งค่าไว้ คุณตั้งค่าได้ด้วยคำสั่งนี้
gcloud config set project <PROJECT_ID>
เอาต์พุตของคำสั่ง
Updated property [core/project].
3. เปิดใช้ BigQuery API
ควรเปิดใช้ BigQuery API โดยค่าเริ่มต้นในโปรเจ็กต์ Google Cloud ทั้งหมด คุณตรวจสอบได้ว่าข้อความนี้เป็นจริงหรือไม่ด้วยคำสั่งต่อไปนี้ใน Cloud Shell
gcloud services list
คุณควรเห็น BigQuery แสดงอยู่
NAME TITLE
bigquery-json.googleapis.com BigQuery API
...
หากไม่ได้เปิดใช้ BigQuery API คุณสามารถใช้คำสั่งต่อไปนี้ใน Cloud Shell เพื่อเปิดใช้ได้
gcloud services enable bigquery-json.googleapis.com
4. ตรวจสอบสิทธิ์คำขอ API
หากต้องการส่งคำขอไปยัง BigQuery API คุณต้องใช้บัญชีบริการ บัญชีบริการเป็นของโปรเจ็กต์ของคุณ และใช้โดยไลบรารีไคลเอ็นต์ Node.js ของ Google BigQuery เพื่อส่งคำขอ BigQuery API บัญชีบริการจะแสดงด้วยอีเมลเช่นเดียวกับบัญชีผู้ใช้อื่นๆ ในส่วนนี้ คุณจะใช้ Cloud SDK เพื่อสร้างบัญชีบริการ จากนั้นสร้างข้อมูลเข้าสู่ระบบที่คุณจะต้องใช้เพื่อตรวจสอบสิทธิ์ในฐานะบัญชีบริการ
ก่อนอื่น ให้ตั้งค่าตัวแปรสภาพแวดล้อมด้วย PROJECT_ID ที่คุณจะใช้ตลอดทั้งโค้ดแล็บนี้
export GOOGLE_CLOUD_PROJECT=$(gcloud config get-value core/project)
จากนั้นสร้างบัญชีบริการใหม่เพื่อเข้าถึง BigQuery API โดยใช้ข้อมูลต่อไปนี้
gcloud iam service-accounts create my-bigquery-sa --display-name "my bigquery codelab service account"
จากนั้นสร้างข้อมูลเข้าสู่ระบบที่โค้ด Node.js จะใช้เพื่อเข้าสู่ระบบในฐานะบัญชีบริการใหม่ สร้างข้อมูลเข้าสู่ระบบเหล่านี้และบันทึกเป็นไฟล์ JSON "~/key.json" โดยใช้คำสั่งต่อไปนี้
gcloud iam service-accounts keys create ~/key.json --iam-account my-bigquery-sa@${GOOGLE_CLOUD_PROJECT}.iam.gserviceaccount.com
สุดท้าย ให้ตั้งค่าตัวแปรสภาพแวดล้อม GOOGLE_APPLICATION_CREDENTIALS ซึ่งไลบรารี C# ของ BigQuery API ใช้ (จะกล่าวถึงในขั้นตอนถัดไป) เพื่อค้นหาข้อมูลเข้าสู่ระบบ ควรตั้งค่าตัวแปรสภาพแวดล้อมเป็นเส้นทางแบบเต็มของไฟล์ JSON ข้อมูลเข้าสู่ระบบที่คุณสร้างขึ้น ตั้งค่าตัวแปรสภาพแวดล้อมโดยใช้คำสั่งต่อไปนี้
export GOOGLE_APPLICATION_CREDENTIALS="/home/${USER}/key.json"
คุณอ่านข้อมูลเพิ่มเติมเกี่ยวกับการตรวจสอบสิทธิ์ BigQuery API ได้
5. ตั้งค่าการควบคุมการเข้าถึง
BigQuery ใช้ Identity and Access Management (IAM) เพื่อจัดการการเข้าถึงทรัพยากร BigQuery มีบทบาทที่กำหนดไว้ล่วงหน้าหลายบทบาท (ผู้ใช้, dataOwner, dataViewer ฯลฯ) ที่คุณสามารถกำหนดให้กับบัญชีบริการที่สร้างในขั้นตอนก่อนหน้า ดูข้อมูลเพิ่มเติมเกี่ยวกับการควบคุมการเข้าถึงได้ในเอกสารประกอบของ BigQuery
ก่อนที่จะค้นหาชุดข้อมูลสาธารณะได้ คุณต้องตรวจสอบว่าบัญชีบริการมีบทบาท bigquery.user อย่างน้อย ใน Cloud Shell ให้เรียกใช้คำสั่งต่อไปนี้เพื่อมอบหมายบทบาท bigquery.user ให้กับบัญชีบริการ
gcloud projects add-iam-policy-binding ${GOOGLE_CLOUD_PROJECT} --member "serviceAccount:my-bigquery-sa@${GOOGLE_CLOUD_PROJECT}.iam.gserviceaccount.com" --role "roles/bigquery.user"
คุณเรียกใช้คำสั่งต่อไปนี้เพื่อยืนยันว่าบัญชีบริการได้รับมอบหมายบทบาทผู้ใช้แล้ว
gcloud projects get-iam-policy $GOOGLE_CLOUD_PROJECT
6. ติดตั้งไลบรารีของไคลเอ็นต์ BigQuery สำหรับ Node.js
ก่อนอื่น ให้สร้างBigQueryDemoโฟลเดอร์และไปที่โฟลเดอร์นั้นโดยทำดังนี้
mkdir BigQueryDemo
cd BigQueryDemo
จากนั้นสร้างโปรเจ็กต์ Node.js ที่จะใช้เรียกใช้ตัวอย่างไลบรารีของไคลเอ็นต์ BigQuery โดยทำดังนี้
npm init -y
คุณควรเห็นโปรเจ็กต์ Node.js ที่สร้างขึ้น
{
"name": "BigQueryDemo",
"version": "1.0.0",
"description": "",
"main": "index.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"keywords": [],
"author": "",
"license": "ISC"
}
ติดตั้งไลบรารีของไคลเอ็นต์ BigQuery
npm install --save @google-cloud/bigquery
npm notice created a lockfile as package-lock.json. You should commit this file.
npm WARN BigQueryDemo@1.0.0 No description
npm WARN BigQueryDemo@1.0.0 No repository field.
+ @google-cloud/bigquery@2.1.0
added 69 packages from 105 contributors and audited 147 packages in 4.679s
found 0 vulnerabilities
ตอนนี้คุณก็พร้อมใช้ไลบรารีของไคลเอ็นต์ BigQuery Node.js แล้ว
7. ค้นหางานของเชกสเปียร์
ชุดข้อมูลสาธารณะคือชุดข้อมูลที่จัดเก็บไว้ใน BigQuery และพร้อมให้บริการแก่บุคคลทั่วไป นอกจากนี้ ยังมีชุดข้อมูลสาธารณะอื่นๆ อีกมากมายที่คุณสามารถค้นหาได้ ซึ่งบางชุดข้อมูลก็โฮสต์โดย Google แต่ส่วนใหญ่โฮสต์โดยบุคคลที่สาม อ่านเพิ่มเติมได้ในหน้าชุดข้อมูลสาธารณะ
นอกจากชุดข้อมูลสาธารณะแล้ว BigQuery ยังมีตารางตัวอย่างจำนวนจำกัดที่คุณค้นหาได้ ตารางเหล่านี้อยู่ใน bigquery-public-data:samples dataset ตารางหนึ่งในนั้นเรียกว่า shakespeare. ซึ่งมีดัชนีคำของผลงานของเชกสเปียร์ โดยระบุจำนวนครั้งที่แต่ละคำปรากฏในแต่ละคลัง
ในขั้นตอนนี้ คุณจะค้นหาตาราง shakespeare
ก่อนอื่น ให้เปิดเครื่องมือแก้ไขโค้ดจากด้านขวาบนของ Cloud Shell โดยทำดังนี้
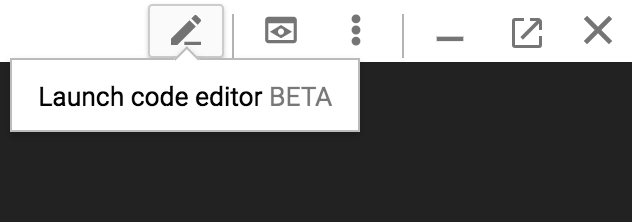
สร้างไฟล์ queryShakespeare.js ในโฟลเดอร์ BigQueryDemo โดยทำดังนี้
touch queryShakespeare.js
ไปที่ไฟล์ queryShakespeare.js แล้วแทรกโค้ดต่อไปนี้
'use strict';
function main() {
// Import the Google Cloud client library
const {BigQuery} = require('@google-cloud/bigquery');
async function queryShakespeare() {
// Queries a public Shakespeare dataset.
// Create a client
const bigqueryClient = new BigQuery();
// The SQL query to run
const sqlQuery = `SELECT word, word_count
FROM \`bigquery-public-data.samples.shakespeare\`
WHERE corpus = @corpus
AND word_count >= @min_word_count
ORDER BY word_count DESC`;
const options = {
query: sqlQuery,
// Location must match that of the dataset(s) referenced in the query.
location: 'US',
params: {corpus: 'romeoandjuliet', min_word_count: 250},
};
// Run the query
const [rows] = await bigqueryClient.query(options);
console.log('Rows:');
rows.forEach(row => console.log(row));
}
queryShakespeare();
}
main();
ใช้เวลาสักครู่เพื่อศึกษาโค้ดและดูวิธีค้นหาตาราง
กลับไปที่ Cloud Shell แล้วเรียกใช้แอปโดยทำดังนี้
node queryShakespeare.js
คุณจะเห็นรายการคำและจำนวนครั้งที่คำนั้นๆ ปรากฏ ดังนี้
Rows:
{ word: 'the', word_count: 614 }
{ word: 'I', word_count: 577 }
{ word: 'and', word_count: 490 }
{ word: 'to', word_count: 486 }
{ word: 'a', word_count: 407 }
{ word: 'of', word_count: 367 }
{ word: 'my', word_count: 314 }
{ word: 'is', word_count: 307 }
...
8. ค้นหาชุดข้อมูล GitHub
ตอนนี้คุณจะออกการค้นหากับชุดข้อมูลสาธารณะของ GitHub เพื่อทำความคุ้นเคยกับ BigQuery มากขึ้น คุณจะเห็นข้อความคอมมิตที่พบบ่อยที่สุดใน GitHub นอกจากนี้ คุณยังใช้เว็บ UI ของ BigQuery เพื่อแสดงตัวอย่างและเรียกใช้การค้นหาเฉพาะกิจได้ด้วย
หากต้องการดูข้อมูล ให้เปิดชุดข้อมูล GitHub ในเว็บ UI ของ BigQuery โดยทำดังนี้
https://console.cloud.google.com/bigquery?p=bigquery-public-data&d=github_repos&t=commits&page=table
หากต้องการดูตัวอย่างลักษณะของข้อมูลอย่างรวดเร็ว ให้คลิกแท็บแสดงตัวอย่าง
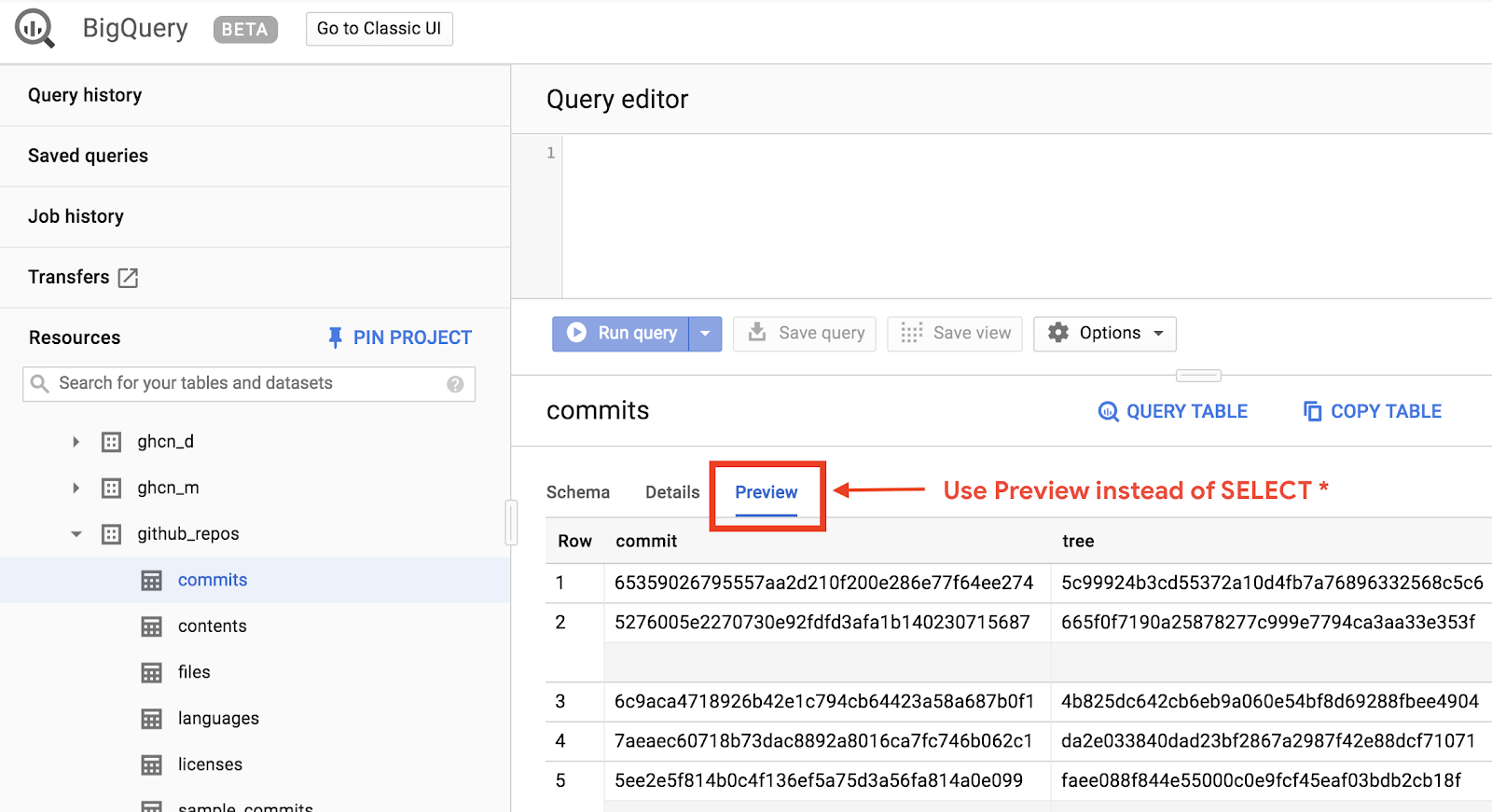
สร้างไฟล์ queryGitHub.js ในโฟลเดอร์ BigQueryDemo โดยทำดังนี้
touch queryGitHub.js
ไปที่ไฟล์ queryGitHub.js แล้วแทรกโค้ดต่อไปนี้
'use strict';
function main() {
// Import the Google Cloud client library
const {BigQuery} = require('@google-cloud/bigquery');
async function queryGitHub() {
// Queries a public GitHub dataset.
// Create a client
const bigqueryClient = new BigQuery();
// The SQL query to run
const sqlQuery = `SELECT subject AS subject, COUNT(*) AS num_duplicates
FROM \`bigquery-public-data.github_repos.commits\`
GROUP BY subject
ORDER BY num_duplicates
DESC LIMIT 10`;
const options = {
query: sqlQuery,
// Location must match that of the dataset(s) referenced in the query.
location: 'US',
};
// Run the query
const [rows] = await bigqueryClient.query(options);
console.log('Rows:');
rows.forEach(row => console.log(`${row.subject}: ${row.num_duplicates}`));
}
queryGitHub();
}
main();
โปรดใช้เวลาสักครู่เพื่อศึกษาโค้ดและดูวิธีค้นหาข้อความคอมมิตที่พบบ่อยที่สุดในตาราง
กลับไปที่ Cloud Shell แล้วเรียกใช้แอปโดยทำดังนี้
node queryGitHub.js
คุณควรเห็นรายการข้อความคอมมิตและเหตุการณ์ที่เกิดขึ้นดังนี้
Rows:
Update README.md: 2572220
: 1985733
Initial commit: 1940228
Mirroring from Micro.blog.: 646772
update: 592520
Update data.json: 548730
Update data.js: 548354
...
9. การแคชและสถิติ
เมื่อเรียกใช้การค้นหา BigQuery จะแคชผลลัพธ์ ด้วยเหตุนี้ คำค้นหาที่เหมือนกันในภายหลังจึงใช้เวลาน้อยลงมาก คุณปิดใช้การแคชได้โดยใช้ตัวเลือกการค้นหา นอกจากนี้ BigQuery ยังติดตามสถิติบางอย่างเกี่ยวกับการค้นหา เช่น เวลาสร้าง เวลาสิ้นสุด และไบต์ทั้งหมดที่ประมวลผล
ในขั้นตอนนี้ คุณจะปิดใช้การแคชและแสดงสถิติบางอย่างเกี่ยวกับคำค้นหา
ไปที่ไฟล์ queryShakespeare.js ในโฟลเดอร์ BigQueryDemo แล้วแทนที่โค้ดด้วยโค้ดต่อไปนี้
'use strict';
function main() {
// Import the Google Cloud client library
const {BigQuery} = require('@google-cloud/bigquery');
async function queryShakespeareDisableCache() {
// Queries the Shakespeare dataset with the cache disabled.
// Create a client
const bigqueryClient = new BigQuery();
const sqlQuery = `SELECT word, word_count
FROM \`bigquery-public-data.samples.shakespeare\`
WHERE corpus = @corpus
AND word_count >= @min_word_count
ORDER BY word_count DESC`;
const options = {
query: sqlQuery,
// Location must match that of the dataset(s) referenced in the query.
location: 'US',
params: {corpus: 'romeoandjuliet', min_word_count: 250},
useQueryCache: false,
};
// Run the query as a job
const [job] = await bigqueryClient.createQueryJob(options);
console.log(`Job ${job.id} started.`);
// Wait for the query to finish
const [rows] = await job.getQueryResults();
// Print the results
console.log('Rows:');
rows.forEach(row => console.log(row));
// Print job statistics
console.log('JOB STATISTICS:')
console.log(`Status: ${job.metadata.status.state}`);
console.log(`Creation time: ${job.metadata.statistics.creationTime}`);
console.log(`Start time: ${job.metadata.statistics.startTime}`);
console.log(`Statement type: ${job.metadata.statistics.query.statementType}`);
}
queryShakespeareDisableCache();
}
main();
ข้อควรทราบเกี่ยวกับโค้ดมีดังนี้ ก่อนอื่น ให้ปิดใช้การแคชโดยตั้งค่า UseQueryCache เป็น false ภายในออบเจ็กต์ options ประการที่ 2 คุณเข้าถึงสถิติเกี่ยวกับคำค้นหาจากออบเจ็กต์งาน
กลับไปที่ Cloud Shell แล้วเรียกใช้แอปโดยทำดังนี้
node queryShakespeare.js
คุณควรเห็นรายการข้อความคอมมิตและเหตุการณ์ที่เกิดขึ้น นอกจากนี้ คุณควรเห็นสถิติบางอย่างเกี่ยวกับคำค้นหาด้วย
Rows:
{ word: 'the', word_count: 614 }
{ word: 'I', word_count: 577 }
{ word: 'and', word_count: 490 }
{ word: 'to', word_count: 486 }
{ word: 'a', word_count: 407 }
{ word: 'of', word_count: 367 }
{ word: 'my', word_count: 314 }
{ word: 'is', word_count: 307 }
{ word: 'in', word_count: 291 }
{ word: 'you', word_count: 271 }
{ word: 'that', word_count: 270 }
{ word: 'me', word_count: 263 }
JOB STATISTICS:
Status: RUNNING
Creation time: 1554309220660
Start time: 1554309220793
Statement type: SELECT
10. การโหลดข้อมูลลงใน BigQuery
หากต้องการค้นหาข้อมูลของคุณเอง คุณต้องโหลดข้อมูลลงใน BigQuery ก่อน BigQuery รองรับการโหลดข้อมูลจากแหล่งที่มาต่างๆ เช่น Google Cloud Storage, บริการอื่นๆ ของ Google หรือแหล่งที่มาในเครื่องที่อ่านได้ คุณยังสตรีมข้อมูลได้ด้วย ดูข้อมูลเพิ่มเติมได้ที่หน้าการโหลดข้อมูลลงใน BigQuery
ในขั้นตอนนี้ คุณจะโหลดไฟล์ JSON ที่จัดเก็บไว้ใน Google Cloud Storage ลงในตาราง BigQuery ไฟล์ JSON อยู่ที่ gs://cloud-samples-data/bigquery/us-states/us-states.json
หากต้องการทราบเนื้อหาของไฟล์ JSON คุณสามารถใช้gsutilเครื่องมือบรรทัดคำสั่งเพื่อดาวน์โหลดไฟล์ใน Cloud Shell ได้โดยทำดังนี้
gsutil cp gs://cloud-samples-data/bigquery/us-states/us-states.json .
Copying gs://cloud-samples-data/bigquery/us-states/us-states.json...
/ [1 files][ 2.0 KiB/ 2.0 KiB]
Operation completed over 1 objects/2.0 KiB.
คุณจะเห็นว่ามีรายการรัฐในสหรัฐอเมริกา และแต่ละรัฐเป็นออบเจ็กต์ JSON ในบรรทัดแยกกัน
less us-states.json
{"name": "Alabama", "post_abbr": "AL"}
{"name": "Alaska", "post_abbr": "AK"}
...
หากต้องการโหลดไฟล์ JSON นี้ลงใน BigQuery ให้สร้างไฟล์ createDataset.js และไฟล์ loadBigQueryJSON.js ภายในโฟลเดอร์ BigQueryDemo
touch createDataset.js
touch loadBigQueryJSON.js
ติดตั้งไลบรารีของไคลเอ็นต์ Node.js สำหรับ Google Cloud Storage โดยใช้คำสั่งต่อไปนี้
npm install --save @google-cloud/storage
ไปที่ไฟล์ createDataset.js แล้วแทรกโค้ดต่อไปนี้
'use strict';
function main() {
// Import the Google Cloud client libraries
const {BigQuery} = require('@google-cloud/bigquery');
async function createDataset() {
const datasetId = "my_states_dataset3";
const bigqueryClient = new BigQuery();
// Specify the geographic location where the dataset should reside
const options = {
location: 'US',
};
// Create a new dataset
const [dataset] = await bigqueryClient.createDataset(datasetId, options);
console.log(`Dataset ${dataset.id} created.`);
}
createDataset();
}
main();
จากนั้นไปที่ไฟล์ loadBigQueryJSON.js แล้วแทรกโค้ดต่อไปนี้
'use strict';
function main() {
// Import the Google Cloud client libraries
const {BigQuery} = require('@google-cloud/bigquery');
const {Storage} = require('@google-cloud/storage');
const datasetId = "my_states_dataset3";
const tableId = "my_states_table";
async function createTable(datasetId, tableId) {
// Creates a new table
// Create a client
const bigqueryClient = new BigQuery();
const options = {
location: 'US',
};
// Create a new table in the dataset
const [table] = await bigqueryClient
.dataset(datasetId)
.createTable(tableId, options);
console.log(`Table ${table.id} created.`);
}
async function loadJSONFromGCS(datasetId, tableId) {
// Import a GCS file into a table with manually defined schema.
// Instantiate clients
const bigqueryClient = new BigQuery();
const storageClient = new Storage();
const bucketName = 'cloud-samples-data';
const filename = 'bigquery/us-states/us-states.json';
// Configure the load job.
const metadata = {
sourceFormat: 'NEWLINE_DELIMITED_JSON',
schema: {
fields: [
{name: 'name', type: 'STRING'},
{name: 'post_abbr', type: 'STRING'},
],
},
location: 'US',
};
// Load data from a Google Cloud Storage file into the table
const [job] = await bigqueryClient
.dataset(datasetId)
.table(tableId)
.load(storageClient.bucket(bucketName).file(filename), metadata);
// load() waits for the job to finish
console.log(`Job ${job.id} completed.`);
// Check the job's status for errors
const errors = job.status.errors;
if (errors && errors.length > 0) {
throw errors;
}
}
// createDataset(datasetId);
createTable(datasetId, tableId);
loadJSONFromGCS(datasetId, tableId);
}
main();
ใช้เวลาสักครู่เพื่อศึกษาว่าโค้ดโหลดไฟล์ JSON และสร้างตาราง (ที่มีสคีมา) ในชุดข้อมูลอย่างไร
กลับไปที่ Cloud Shell แล้วเรียกใช้แอปโดยทำดังนี้
node createDataset.js
node loadBigQueryJSON.js
ระบบจะสร้างชุดข้อมูลและตารางใน BigQuery ดังนี้
Table my_states_table created.
Job [JOB ID] completed.
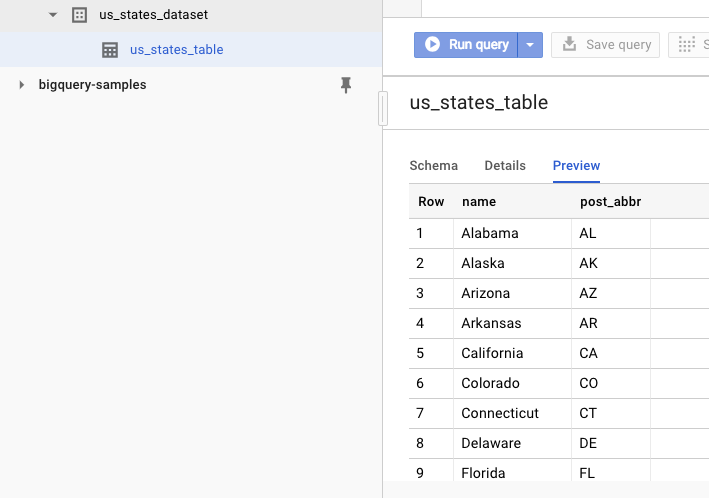
หากต้องการยืนยันว่าสร้างชุดข้อมูลแล้ว ให้ไปที่เว็บ UI ของ BigQuery คุณควรเห็นชุดข้อมูลและตารางใหม่ หากเปลี่ยนไปที่แท็บตัวอย่างของตาราง คุณจะเห็นข้อมูลจริง
11. ยินดีด้วย
คุณได้เรียนรู้วิธีใช้ BigQuery โดยใช้ Node.js แล้ว
ล้างข้อมูล
เพื่อเลี่ยงไม่ให้เกิดการเรียกเก็บเงินกับบัญชี Google Cloud Platform สำหรับทรัพยากรที่ใช้ในการเริ่มต้นอย่างรวดเร็วนี้ ควรทำดังนี้
- ไปที่คอนโซล Cloud Platform
- เลือกโปรเจ็กต์ที่ต้องการปิด แล้วคลิก "ลบ" ที่ด้านบน ซึ่งจะเป็นการกำหนดเวลาให้ลบโปรเจ็กต์
ดูข้อมูลเพิ่มเติม
- Google BigQuery: https://cloud.google.com/bigquery/docs/
- Node.js ใน Google Cloud Platform: https://cloud.google.com/nodejs/
- ไลบรารีไคลเอ็นต์ Node.js ของ Google BigQuery: https://github.com/googleapis/nodejs-bigquery
ใบอนุญาต
ผลงานนี้ได้รับอนุญาตภายใต้สัญญาอนุญาตครีเอทีฟคอมมอนส์สำหรับยอมรับสิทธิของผู้สร้าง (Creative Commons Attribution License) 2.0 แบบทั่วไป