
1. Tổng quan
BigQuery là kho dữ liệu phân tích cỡ petabyte, tiết kiệm chi phí và do Google toàn quyền quản lý. BigQuery là NoOps (không cần quản lý cơ sở hạ tầng và bạn không cần quản trị viên cơ sở dữ liệu) nên bạn có thể tập trung vào việc phân tích dữ liệu để tìm thông tin chi tiết có ý nghĩa, sử dụng SQL quen thuộc và tận dụng mô hình trả tiền theo mức dùng của chúng tôi.
Trong lớp học lập trình này, bạn sẽ sử dụng Thư viện ứng dụng Google Cloud BigQuery để truy vấn tập dữ liệu công khai BigQuery bằng Node.js.
Kiến thức bạn sẽ học được
- Cách sử dụng Cloud Shell
- Cách bật BigQuery API
- Cách xác thực các yêu cầu API
- Cách cài đặt thư viện ứng dụng BigQuery cho Node.js
- Cách truy vấn các tác phẩm của Shakespeare
- Cách truy vấn tập dữ liệu trên GitHub
- Cách điều chỉnh bộ nhớ đệm và số liệu thống kê hiển thị
Bạn cần có
- Một dự án trên Google Cloud Platform
- Một trình duyệt, chẳng hạn như Chrome hoặc Firefox
- Làm quen với cách sử dụng Node.js
Bản khảo sát
Bạn sẽ sử dụng hướng dẫn này như thế nào?
Bạn đánh giá thế nào về trải nghiệm của mình với Node.js?
Bạn đánh giá thế nào về trải nghiệm sử dụng các dịch vụ của Google Cloud Platform?
2. Thiết lập và yêu cầu
Thiết lập môi trường theo tốc độ của riêng bạn
- Đăng nhập vào Cloud Console rồi tạo một dự án mới hoặc sử dụng lại một dự án hiện có. (Nếu chưa có tài khoản Gmail hoặc G Suite, bạn phải tạo một tài khoản.)


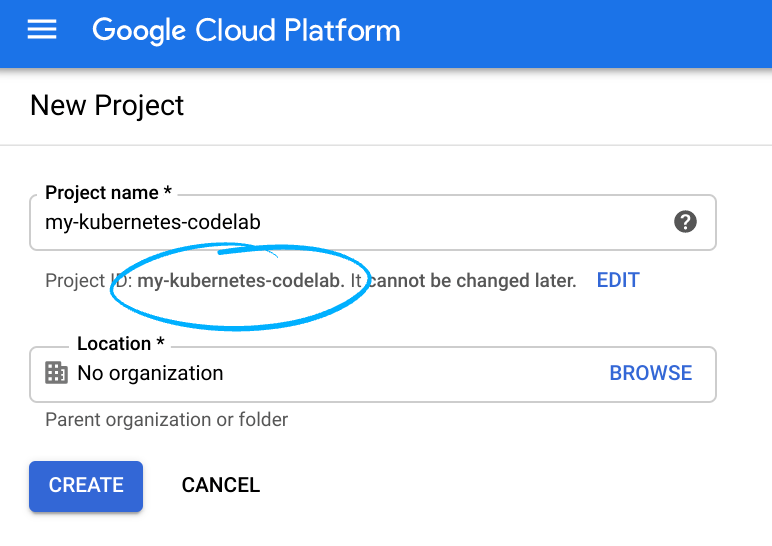
Hãy nhớ mã dự án, một tên duy nhất trên tất cả các dự án trên Google Cloud (tên ở trên đã được sử dụng và sẽ không hoạt động đối với bạn, xin lỗi!). Sau này trong lớp học lập trình này, chúng ta sẽ gọi nó là PROJECT_ID.
- Tiếp theo, bạn cần bật tính năng thanh toán trong Cloud Console để sử dụng các tài nguyên của Google Cloud.
Việc thực hiện lớp học lập trình này sẽ không tốn nhiều chi phí, nếu có. Hãy nhớ làm theo mọi hướng dẫn trong phần "Dọn dẹp" để biết cách tắt các tài nguyên nhằm tránh bị tính phí ngoài phạm vi hướng dẫn này. Người dùng mới của Google Cloud đủ điều kiện tham gia chương trình Dùng thử miễn phí trị giá 300 USD.
Khởi động Cloud Shell
Mặc dù có thể vận hành công cụ dòng lệnh Cloud SDK từ xa trên máy tính xách tay, nhưng trong lớp học lập trình này, bạn sẽ sử dụng Google Cloud Shell, một môi trường dòng lệnh chạy trên đám mây.
Kích hoạt Cloud Shell
- Trong Cloud Console, hãy nhấp vào Kích hoạt Cloud Shell
.

Nếu chưa từng khởi động Cloud Shell, bạn sẽ thấy một màn hình trung gian (bên dưới phần hiển thị đầu tiên) mô tả về Cloud Shell. Nếu vậy, hãy nhấp vào Tiếp tục (và bạn sẽ không bao giờ thấy màn hình này nữa). Sau đây là giao diện của màn hình xuất hiện một lần:

Quá trình cung cấp và kết nối với Cloud Shell chỉ mất vài giây.

Máy ảo này được trang bị tất cả các công cụ phát triển mà bạn cần. Nền tảng này cung cấp một thư mục chính có dung lượng 5 GB và chạy trong Google Cloud, giúp tăng cường đáng kể hiệu suất mạng và hoạt động xác thực. Bạn có thể thực hiện hầu hết, nếu không muốn nói là tất cả, công việc trong lớp học lập trình này chỉ bằng một trình duyệt hoặc Chromebook.
Sau khi kết nối với Cloud Shell, bạn sẽ thấy rằng mình đã được xác thực và dự án đã được đặt thành mã dự án của bạn.
- Chạy lệnh sau trong Cloud Shell để xác nhận rằng bạn đã được xác thực:
gcloud auth list
Đầu ra của lệnh
Credentialed Accounts
ACTIVE ACCOUNT
* <my_account>@<my_domain.com>
To set the active account, run:
$ gcloud config set account `ACCOUNT`
gcloud config list project
Đầu ra của lệnh
[core] project = <PROJECT_ID>
Nếu không, bạn có thể đặt nó bằng lệnh sau:
gcloud config set project <PROJECT_ID>
Đầu ra của lệnh
Updated property [core/project].
3. Bật BigQuery API
Theo mặc định, BigQuery API sẽ được bật trong tất cả các dự án trên Google Cloud. Bạn có thể kiểm tra xem điều này có đúng hay không bằng lệnh sau trong Cloud Shell:
gcloud services list
Bạn sẽ thấy BigQuery trong danh sách:
NAME TITLE
bigquery-json.googleapis.com BigQuery API
...
Nếu BigQuery API chưa được bật, bạn có thể dùng lệnh sau trong Cloud Shell để bật API này:
gcloud services enable bigquery-json.googleapis.com
4. Xác thực các yêu cầu API
Để đưa ra yêu cầu cho BigQuery API, bạn cần sử dụng Tài khoản dịch vụ. Tài khoản dịch vụ thuộc về dự án của bạn và được thư viện ứng dụng Google BigQuery Node.js dùng để thực hiện các yêu cầu BigQuery API. Giống như mọi tài khoản người dùng khác, tài khoản dịch vụ được biểu thị bằng một địa chỉ email. Trong phần này, bạn sẽ sử dụng Cloud SDK để tạo một tài khoản dịch vụ, sau đó tạo thông tin đăng nhập mà bạn cần để xác thực dưới dạng tài khoản dịch vụ.
Trước tiên, hãy đặt một biến môi trường bằng PROJECT_ID mà bạn sẽ sử dụng trong suốt lớp học lập trình này:
export GOOGLE_CLOUD_PROJECT=$(gcloud config get-value core/project)
Tiếp theo, hãy tạo một tài khoản dịch vụ mới để truy cập vào BigQuery API bằng cách sử dụng:
gcloud iam service-accounts create my-bigquery-sa --display-name "my bigquery codelab service account"
Tiếp theo, hãy tạo thông tin đăng nhập mà mã Node.js sẽ dùng để đăng nhập dưới dạng tài khoản dịch vụ mới. Tạo thông tin đăng nhập này và lưu dưới dạng tệp JSON "~/key.json" bằng lệnh sau:
gcloud iam service-accounts keys create ~/key.json --iam-account my-bigquery-sa@${GOOGLE_CLOUD_PROJECT}.iam.gserviceaccount.com
Cuối cùng, hãy đặt biến môi trường GOOGLE_APPLICATION_CREDENTIALS. Thư viện BigQuery API C# sẽ dùng biến này (được đề cập trong bước tiếp theo) để tìm thông tin đăng nhập của bạn. Bạn nên đặt biến môi trường thành đường dẫn đầy đủ của tệp JSON thông tin đăng nhập mà bạn đã tạo. Đặt biến môi trường bằng cách dùng lệnh sau:
export GOOGLE_APPLICATION_CREDENTIALS="/home/${USER}/key.json"
Bạn có thể đọc thêm về cách xác thực BigQuery API.
5. Thiết lập tính năng kiểm soát quyền truy cập
BigQuery sử dụng dịch vụ Quản lý danh tính và quyền truy cập (IAM) để quản lý quyền truy cập vào các tài nguyên. BigQuery có một số vai trò được xác định trước (user, dataOwner, dataViewer, v.v.) mà bạn có thể chỉ định cho tài khoản dịch vụ mà bạn đã tạo ở bước trước. Bạn có thể đọc thêm về Kiểm soát quyền truy cập trong tài liệu về BigQuery.
Trước khi có thể truy vấn các tập dữ liệu công khai, bạn cần đảm bảo tài khoản dịch vụ có ít nhất vai trò bigquery.user. Trong Cloud Shell, hãy chạy lệnh sau để chỉ định vai trò bigquery.user cho tài khoản dịch vụ:
gcloud projects add-iam-policy-binding ${GOOGLE_CLOUD_PROJECT} --member "serviceAccount:my-bigquery-sa@${GOOGLE_CLOUD_PROJECT}.iam.gserviceaccount.com" --role "roles/bigquery.user"
Bạn có thể chạy lệnh sau để xác minh rằng tài khoản dịch vụ được chỉ định vai trò người dùng:
gcloud projects get-iam-policy $GOOGLE_CLOUD_PROJECT
6. Cài đặt thư viện ứng dụng BigQuery cho Node.js
Trước tiên, hãy tạo một thư mục BigQueryDemo rồi chuyển đến thư mục đó:
mkdir BigQueryDemo
cd BigQueryDemo
Tiếp theo, hãy tạo một dự án Node.js mà bạn sẽ dùng để chạy các mẫu thư viện ứng dụng BigQuery:
npm init -y
Bạn sẽ thấy dự án Node.js đã được tạo:
{
"name": "BigQueryDemo",
"version": "1.0.0",
"description": "",
"main": "index.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"keywords": [],
"author": "",
"license": "ISC"
}
Cài đặt thư viện ứng dụng BigQuery:
npm install --save @google-cloud/bigquery
npm notice created a lockfile as package-lock.json. You should commit this file.
npm WARN BigQueryDemo@1.0.0 No description
npm WARN BigQueryDemo@1.0.0 No repository field.
+ @google-cloud/bigquery@2.1.0
added 69 packages from 105 contributors and audited 147 packages in 4.679s
found 0 vulnerabilities
Giờ đây, bạn đã sẵn sàng sử dụng thư viện ứng dụng BigQuery Node.js!
7. Truy vấn các tác phẩm của Shakespeare
Tập dữ liệu công khai là tập dữ liệu được lưu trữ trong BigQuery và được cung cấp cho công chúng. Có nhiều tập dữ liệu công khai khác mà bạn có thể truy vấn, một số tập dữ liệu cũng do Google lưu trữ, nhưng nhiều tập dữ liệu khác do bên thứ ba lưu trữ. Bạn có thể đọc thêm thông tin trên trang Tập dữ liệu công khai.
Ngoài các tập dữ liệu công khai, BigQuery còn cung cấp một số lượng hạn chế bảng mẫu mà bạn có thể truy vấn. Các bảng này nằm trong bigquery-public-data:samples dataset. Một trong những bảng đó có tên là shakespeare.. Bảng này chứa một chỉ mục từ của các tác phẩm của Shakespeare, cho biết số lần mỗi từ xuất hiện trong mỗi ngữ liệu.
Trong bước này, bạn sẽ truy vấn bảng shakespeare.
Trước tiên, hãy mở trình soạn thảo mã ở phía trên cùng bên phải của Cloud Shell:
Tạo tệp queryShakespeare.js bên trong thư mục BigQueryDemo :
touch queryShakespeare.js
Chuyển đến tệp queryShakespeare.js rồi chèn đoạn mã sau:
'use strict';
function main() {
// Import the Google Cloud client library
const {BigQuery} = require('@google-cloud/bigquery');
async function queryShakespeare() {
// Queries a public Shakespeare dataset.
// Create a client
const bigqueryClient = new BigQuery();
// The SQL query to run
const sqlQuery = `SELECT word, word_count
FROM \`bigquery-public-data.samples.shakespeare\`
WHERE corpus = @corpus
AND word_count >= @min_word_count
ORDER BY word_count DESC`;
const options = {
query: sqlQuery,
// Location must match that of the dataset(s) referenced in the query.
location: 'US',
params: {corpus: 'romeoandjuliet', min_word_count: 250},
};
// Run the query
const [rows] = await bigqueryClient.query(options);
console.log('Rows:');
rows.forEach(row => console.log(row));
}
queryShakespeare();
}
main();
Hãy dành một hoặc hai phút để nghiên cứu mã và xem cách truy vấn bảng.
Trong Cloud Shell, hãy chạy ứng dụng:
node queryShakespeare.js
Bạn sẽ thấy danh sách các từ và số lần xuất hiện của chúng:
Rows:
{ word: 'the', word_count: 614 }
{ word: 'I', word_count: 577 }
{ word: 'and', word_count: 490 }
{ word: 'to', word_count: 486 }
{ word: 'a', word_count: 407 }
{ word: 'of', word_count: 367 }
{ word: 'my', word_count: 314 }
{ word: 'is', word_count: 307 }
...
8. Truy vấn tập dữ liệu trên GitHub
Để làm quen hơn với BigQuery, giờ đây, bạn sẽ đưa ra một truy vấn đối với tập dữ liệu công khai của GitHub. Bạn sẽ tìm thấy những thông báo xác nhận phổ biến nhất trên GitHub. Bạn cũng sẽ sử dụng giao diện người dùng trên web của BigQuery để xem trước và chạy các truy vấn đặc biệt.
Để xem dữ liệu, hãy mở tập dữ liệu GitHub trong giao diện người dùng web BigQuery:
https://console.cloud.google.com/bigquery?p=bigquery-public-data&d=github_repos&t=commits&page=table
Để xem nhanh dữ liệu trông như thế nào, hãy nhấp vào thẻ Xem trước:
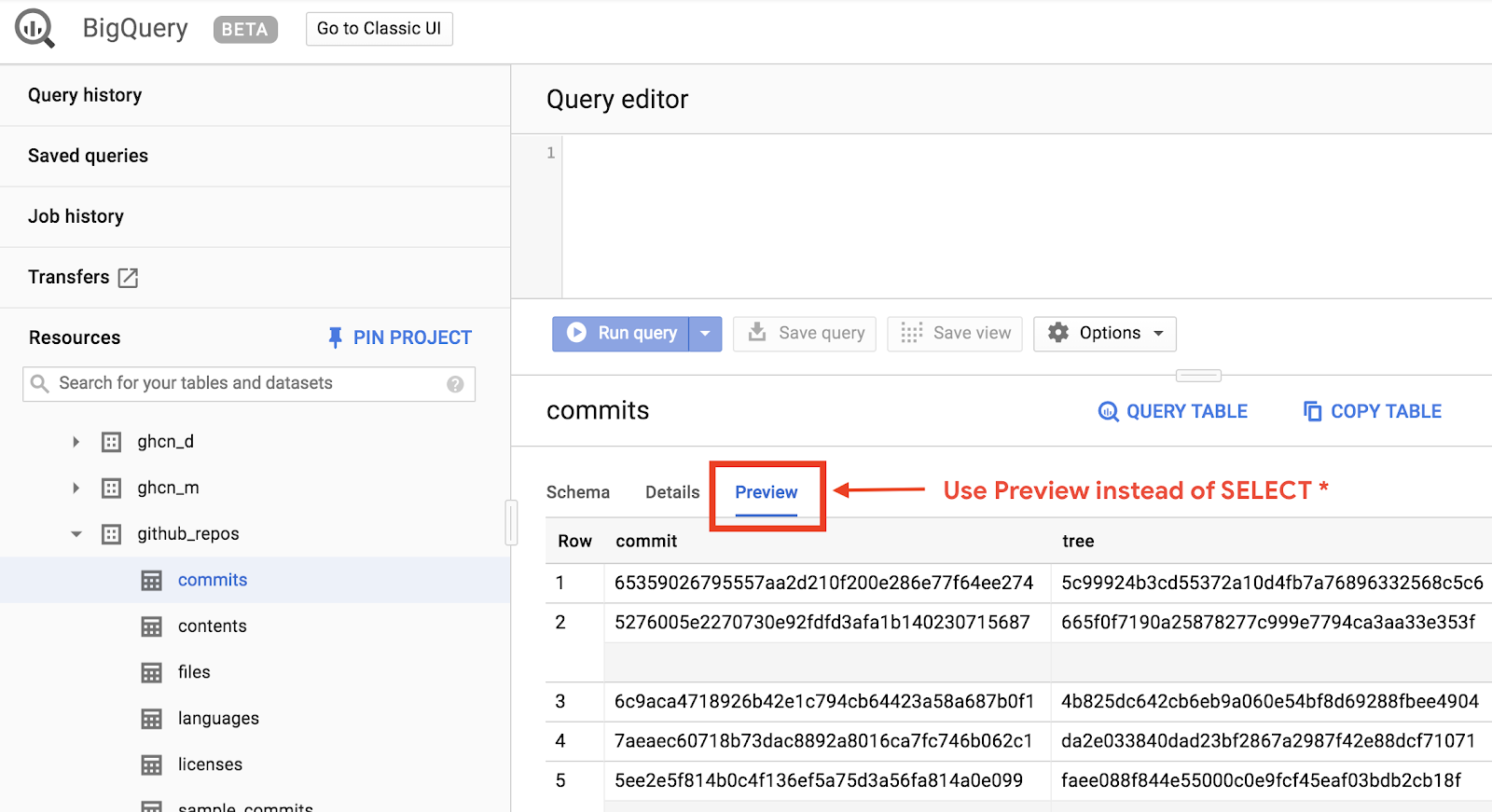
Tạo tệp queryGitHub.js bên trong thư mục BigQueryDemo:
touch queryGitHub.js
Chuyển đến tệp queryGitHub.js rồi chèn đoạn mã sau:
'use strict';
function main() {
// Import the Google Cloud client library
const {BigQuery} = require('@google-cloud/bigquery');
async function queryGitHub() {
// Queries a public GitHub dataset.
// Create a client
const bigqueryClient = new BigQuery();
// The SQL query to run
const sqlQuery = `SELECT subject AS subject, COUNT(*) AS num_duplicates
FROM \`bigquery-public-data.github_repos.commits\`
GROUP BY subject
ORDER BY num_duplicates
DESC LIMIT 10`;
const options = {
query: sqlQuery,
// Location must match that of the dataset(s) referenced in the query.
location: 'US',
};
// Run the query
const [rows] = await bigqueryClient.query(options);
console.log('Rows:');
rows.forEach(row => console.log(`${row.subject}: ${row.num_duplicates}`));
}
queryGitHub();
}
main();
Dành một hoặc hai phút để nghiên cứu mã và xem cách truy vấn bảng cho các thông báo cam kết phổ biến nhất.
Trong Cloud Shell, hãy chạy ứng dụng:
node queryGitHub.js
Bạn sẽ thấy danh sách các thông báo cam kết và số lần xuất hiện của chúng:
Rows:
Update README.md: 2572220
: 1985733
Initial commit: 1940228
Mirroring from Micro.blog.: 646772
update: 592520
Update data.json: 548730
Update data.js: 548354
...
9. Lưu vào bộ nhớ đệm và số liệu thống kê
Khi bạn chạy một truy vấn, BigQuery sẽ lưu kết quả vào bộ nhớ đệm. Do đó, các truy vấn giống hệt nhau sau đó sẽ mất ít thời gian hơn nhiều. Bạn có thể tắt tính năng lưu vào bộ nhớ đệm bằng cách sử dụng các lựa chọn truy vấn. BigQuery cũng theo dõi một số số liệu thống kê về các truy vấn, chẳng hạn như thời gian tạo, thời gian kết thúc và tổng số byte được xử lý.
Trong bước này, bạn sẽ tắt tính năng lưu vào bộ nhớ đệm và hiển thị một số số liệu thống kê về các truy vấn.
Chuyển đến tệp queryShakespeare.js bên trong thư mục BigQueryDemo rồi thay thế mã bằng đoạn mã sau:
'use strict';
function main() {
// Import the Google Cloud client library
const {BigQuery} = require('@google-cloud/bigquery');
async function queryShakespeareDisableCache() {
// Queries the Shakespeare dataset with the cache disabled.
// Create a client
const bigqueryClient = new BigQuery();
const sqlQuery = `SELECT word, word_count
FROM \`bigquery-public-data.samples.shakespeare\`
WHERE corpus = @corpus
AND word_count >= @min_word_count
ORDER BY word_count DESC`;
const options = {
query: sqlQuery,
// Location must match that of the dataset(s) referenced in the query.
location: 'US',
params: {corpus: 'romeoandjuliet', min_word_count: 250},
useQueryCache: false,
};
// Run the query as a job
const [job] = await bigqueryClient.createQueryJob(options);
console.log(`Job ${job.id} started.`);
// Wait for the query to finish
const [rows] = await job.getQueryResults();
// Print the results
console.log('Rows:');
rows.forEach(row => console.log(row));
// Print job statistics
console.log('JOB STATISTICS:')
console.log(`Status: ${job.metadata.status.state}`);
console.log(`Creation time: ${job.metadata.statistics.creationTime}`);
console.log(`Start time: ${job.metadata.statistics.startTime}`);
console.log(`Statement type: ${job.metadata.statistics.query.statementType}`);
}
queryShakespeareDisableCache();
}
main();
Một số điều cần lưu ý về mã này. Trước tiên, hãy tắt tính năng lưu vào bộ nhớ đệm bằng cách đặt UseQueryCache thành false bên trong đối tượng options. Thứ hai, bạn đã truy cập vào số liệu thống kê về truy vấn từ đối tượng công việc.
Trong Cloud Shell, hãy chạy ứng dụng:
node queryShakespeare.js
Bạn sẽ thấy danh sách các thông báo cam kết và số lần xuất hiện của chúng. Ngoài ra, bạn cũng sẽ thấy một số số liệu thống kê về cụm từ tìm kiếm:
Rows:
{ word: 'the', word_count: 614 }
{ word: 'I', word_count: 577 }
{ word: 'and', word_count: 490 }
{ word: 'to', word_count: 486 }
{ word: 'a', word_count: 407 }
{ word: 'of', word_count: 367 }
{ word: 'my', word_count: 314 }
{ word: 'is', word_count: 307 }
{ word: 'in', word_count: 291 }
{ word: 'you', word_count: 271 }
{ word: 'that', word_count: 270 }
{ word: 'me', word_count: 263 }
JOB STATISTICS:
Status: RUNNING
Creation time: 1554309220660
Start time: 1554309220793
Statement type: SELECT
10. Tải dữ liệu vào BigQuery
Nếu muốn truy vấn dữ liệu của riêng mình, trước tiên, bạn cần tải dữ liệu lên BigQuery. BigQuery hỗ trợ tải dữ liệu từ nhiều nguồn, chẳng hạn như Google Cloud Storage, các dịch vụ khác của Google hoặc một nguồn cục bộ có thể đọc được. Bạn thậm chí có thể truyền trực tuyến dữ liệu của mình. Bạn có thể đọc thêm trên trang Tải dữ liệu vào BigQuery.
Trong bước này, bạn sẽ tải một tệp JSON được lưu trữ trong Google Cloud Storage vào một bảng BigQuery. Tệp JSON nằm ở: gs://cloud-samples-data/bigquery/us-states/us-states.json
Nếu muốn biết nội dung của tệp JSON, bạn có thể dùng công cụ dòng lệnh gsutil để tải tệp này xuống trong Cloud Shell:
gsutil cp gs://cloud-samples-data/bigquery/us-states/us-states.json .
Copying gs://cloud-samples-data/bigquery/us-states/us-states.json...
/ [1 files][ 2.0 KiB/ 2.0 KiB]
Operation completed over 1 objects/2.0 KiB.
Bạn có thể thấy rằng tệp này chứa danh sách các tiểu bang của Hoa Kỳ và mỗi tiểu bang là một đối tượng JSON trên một dòng riêng biệt:
less us-states.json
{"name": "Alabama", "post_abbr": "AL"}
{"name": "Alaska", "post_abbr": "AK"}
...
Để tải tệp JSON này vào BigQuery, hãy tạo một tệp createDataset.js và một tệp loadBigQueryJSON.js bên trong thư mục BigQueryDemo:
touch createDataset.js
touch loadBigQueryJSON.js
Cài đặt thư viện ứng dụng Google Cloud Storage Node.js:
npm install --save @google-cloud/storage
Chuyển đến tệp createDataset.js rồi chèn đoạn mã sau:
'use strict';
function main() {
// Import the Google Cloud client libraries
const {BigQuery} = require('@google-cloud/bigquery');
async function createDataset() {
const datasetId = "my_states_dataset3";
const bigqueryClient = new BigQuery();
// Specify the geographic location where the dataset should reside
const options = {
location: 'US',
};
// Create a new dataset
const [dataset] = await bigqueryClient.createDataset(datasetId, options);
console.log(`Dataset ${dataset.id} created.`);
}
createDataset();
}
main();
Sau đó, chuyển đến tệp loadBigQueryJSON.js rồi chèn đoạn mã sau:
'use strict';
function main() {
// Import the Google Cloud client libraries
const {BigQuery} = require('@google-cloud/bigquery');
const {Storage} = require('@google-cloud/storage');
const datasetId = "my_states_dataset3";
const tableId = "my_states_table";
async function createTable(datasetId, tableId) {
// Creates a new table
// Create a client
const bigqueryClient = new BigQuery();
const options = {
location: 'US',
};
// Create a new table in the dataset
const [table] = await bigqueryClient
.dataset(datasetId)
.createTable(tableId, options);
console.log(`Table ${table.id} created.`);
}
async function loadJSONFromGCS(datasetId, tableId) {
// Import a GCS file into a table with manually defined schema.
// Instantiate clients
const bigqueryClient = new BigQuery();
const storageClient = new Storage();
const bucketName = 'cloud-samples-data';
const filename = 'bigquery/us-states/us-states.json';
// Configure the load job.
const metadata = {
sourceFormat: 'NEWLINE_DELIMITED_JSON',
schema: {
fields: [
{name: 'name', type: 'STRING'},
{name: 'post_abbr', type: 'STRING'},
],
},
location: 'US',
};
// Load data from a Google Cloud Storage file into the table
const [job] = await bigqueryClient
.dataset(datasetId)
.table(tableId)
.load(storageClient.bucket(bucketName).file(filename), metadata);
// load() waits for the job to finish
console.log(`Job ${job.id} completed.`);
// Check the job's status for errors
const errors = job.status.errors;
if (errors && errors.length > 0) {
throw errors;
}
}
// createDataset(datasetId);
createTable(datasetId, tableId);
loadJSONFromGCS(datasetId, tableId);
}
main();
Hãy dành một hoặc hai phút để nghiên cứu cách mã tải tệp JSON và tạo một bảng (có giản đồ) trong một tập dữ liệu.
Trong Cloud Shell, hãy chạy ứng dụng:
node createDataset.js
node loadBigQueryJSON.js
Một tập dữ liệu và một bảng được tạo trong BigQuery:
Table my_states_table created.
Job [JOB ID] completed.
Để xác minh rằng tập dữ liệu đã được tạo, bạn có thể chuyển đến giao diện người dùng web của BigQuery. Bạn sẽ thấy một tập dữ liệu và một bảng mới. Nếu chuyển sang thẻ Xem trước của bảng, bạn có thể xem dữ liệu thực tế:
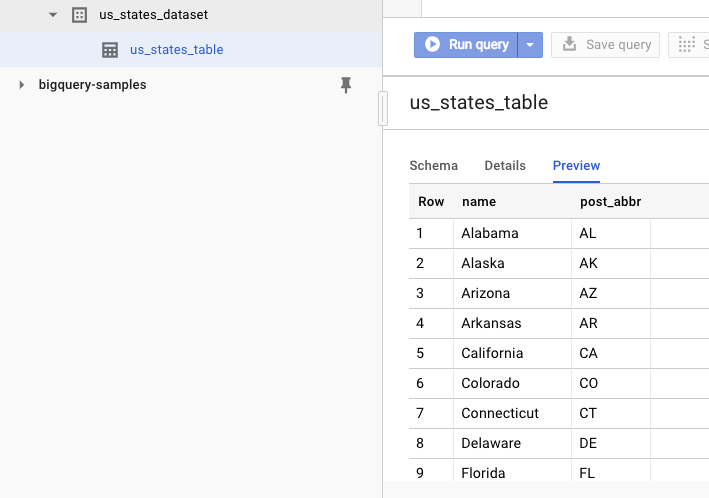
11. Xin chúc mừng!
Bạn đã tìm hiểu cách sử dụng BigQuery bằng Node.js!
Dọn dẹp
Để tránh bị tính phí cho tài khoản Google Cloud Platform đối với các tài nguyên được dùng trong hướng dẫn bắt đầu nhanh này, hãy làm như sau:
- Truy cập vào Cloud Platform Console.
- Chọn dự án mà bạn muốn tắt, sau đó nhấp vào "Xoá" ở trên cùng: thao tác này sẽ lên lịch xoá dự án.
Tìm hiểu thêm
- Google BigQuery: https://cloud.google.com/bigquery/docs/
- Node.js trên Google Cloud Platform: https://cloud.google.com/nodejs/
- Thư viện ứng dụng Node.js của Google BigQuery: https://github.com/googleapis/nodejs-bigquery
Giấy phép
Tác phẩm này được cấp phép theo giấy phép Ghi công theo Creative Commons 2.0 Chung.