
1. סקירה כללית
BigQuery הוא מחסן נתונים לצורכי ניתוח מנוהל במלואו של Google, בקנה מידה של פטה-בייט ובעלות נמוכה. BigQuery הוא NoOps – אין תשתית לניהול ולא צריך מנהל מסד נתונים – כך שאתם יכולים להתמקד בניתוח נתונים כדי למצוא תובנות משמעותיות, להשתמש ב-SQL מוכר ולנצל את היתרונות של המודל שלנו של תשלום לפי שימוש.
ב-codelab הזה תשתמשו בספריות לקוח של Google Cloud ל-Python כדי לשלוח שאילתות למערכי נתונים ציבוריים של BigQuery באמצעות Python.
מה תלמדו
- איך משתמשים ב-Cloud Shell?
- איך מפעילים את BigQuery API
- איך מאמתים בקשות API
- איך מתקינים את ספריית הלקוח של Python
- איך שולחים שאילתות לגבי יצירות של שייקספיר
- איך מריצים שאילתות בקבוצת הנתונים של GitHub
- איך משנים את הגדרות השמירה במטמון ואת הנתונים הסטטיסטיים שמוצגים
מה תצטרכו
סקר
איך תשתמשו במדריך הזה?
איך היית מדרג את חוויית השימוש שלך ב-Python?
איזה דירוג מתאים לדעתך לחוויית השימוש שלך בשירותי Google Cloud?
2. הגדרה ודרישות
הגדרת סביבה בקצב אישי
- נכנסים ל-מסוף Google Cloud ויוצרים פרויקט חדש או משתמשים בפרויקט קיים. אם עדיין אין לכם חשבון Gmail או Google Workspace, אתם צריכים ליצור חשבון.



- שם הפרויקט הוא השם המוצג של הפרויקט הזה למשתתפים. זו מחרוזת של תווים שלא נמצאת בשימוש ב-Google APIs, ואפשר לעדכן אותה בכל שלב.
- מזהה הפרויקט חייב להיות ייחודי בכל הפרויקטים ב-Google Cloud, והוא קבוע (אי אפשר לשנות אותו אחרי שמגדירים אותו). מסוף Cloud יוצר באופן אוטומטי מחרוזת ייחודית. בדרך כלל לא צריך להתייחס אליה. ברוב סדנאות ה-Codelab, צריך להפנות למזהה הפרויקט (ובדרך כלל הוא מזוהה כ-
PROJECT_ID), אז אם לא מוצא חן בעיניכם, אפשר ליצור מזהה אקראי אחר, או לנסות מזהה משלכם ולבדוק אם הוא זמין. אחרי שהפרויקט נוצר, הוא 'קפוא'. - יש ערך שלישי, מספר פרויקט, שחלק מממשקי ה-API משתמשים בו. במאמרי העזרה מפורט מידע נוסף על שלושת הערכים האלה.
- בשלב הבא, תצטרכו להפעיל את החיוב במסוף Cloud כדי להשתמש במשאבי Cloud או בממשקי API. העלות של התרגול הזה לא אמורה להיות גבוהה, ואולי אפילו לא תצטרכו לשלם בכלל. כדי לכבות את המשאבים ולא לחייב אתכם מעבר למה שמוסבר במדריך הזה, צריך לפעול לפי ההוראות לניקוי שמופיעות בסוף ה-Codelab. משתמשים חדשים ב-Google Cloud זכאים לתוכנית תקופת ניסיון בחינם בשווי 300$.
מפעילים את Cloud Shell
אפשר להפעיל את Google Cloud מרחוק מהמחשב הנייד, אבל ב-codelab הזה תשתמשו ב-Google Cloud Shell, סביבת שורת פקודה שפועלת בענן.
הפעלת Cloud Shell
- ב-Cloud Console, לוחצים על Activate Cloud Shell
 .
.

אם זו הפעם הראשונה שאתם מפעילים את Cloud Shell, יוצג לכם מסך ביניים (מתחת לקו הקיפול) עם תיאור של הכלי. במקרה כזה, לוחצים על המשך (והמסך הזה לא יוצג לכם יותר). כך נראה המסך החד-פעמי:

הקצאת המשאבים והחיבור ל-Cloud Shell נמשכים רק כמה רגעים.

המכונה הווירטואלית הזו כוללת את כל הכלים שדרושים למפתחים. יש בה ספריית בית בנפח מתמיד של 5GB והיא פועלת ב-Google Cloud, מה שמשפר מאוד את הביצועים והאימות ברשת. אפשר לבצע את רוב העבודה ב-codelab הזה, אם לא את כולה, באמצעות דפדפן או Chromebook.
אחרי שמתחברים ל-Cloud Shell, אמור להופיע אימות שכבר בוצע ושהפרויקט כבר הוגדר לפי מזהה הפרויקט.
- מריצים את הפקודה הבאה ב-Cloud Shell כדי לוודא שעברתם אימות:
gcloud auth list
פלט הפקודה
Credentialed Accounts
ACTIVE ACCOUNT
* <my_account>@<my_domain.com>
To set the active account, run:
$ gcloud config set account `ACCOUNT`
- מריצים את הפקודה הבאה ב-Cloud Shell כדי לוודא שפקודת gcloud מכירה את הפרויקט:
gcloud config list project
פלט הפקודה
[core] project = <PROJECT_ID>
אם לא, אפשר להגדיר אותו באמצעות הפקודה הבאה:
gcloud config set project <PROJECT_ID>
פלט הפקודה
Updated property [core/project].
3. הפעלת ה-API
BigQuery API אמור להיות מופעל כברירת מחדל בכל פרויקט ב-Google Cloud. כדי לבדוק אם זה נכון, מריצים את הפקודה הבאה ב-Cloud Shell: אתם אמורים להופיע ברשימה של BigQuery:
gcloud services list
האפשרות BigQuery אמורה להופיע ברשימה:
NAME TITLE bigquery.googleapis.com BigQuery API ...
אם BigQuery API לא מופעל, אפשר להשתמש בפקודה הבאה ב-Cloud Shell כדי להפעיל אותו:
gcloud services enable bigquery.googleapis.com
4. אימות בקשות API
כדי לשלוח בקשות ל-BigQuery API, צריך להשתמש בחשבון שירות. חשבון שירות שייך לפרויקט שלכם, וספריית הלקוח של Google Cloud Python משתמשת בו כדי לשלוח בקשות ל-BigQuery API. בדומה לכל חשבון משתמש אחר, חשבון שירות מיוצג על ידי כתובת אימייל. בקטע הזה נשתמש ב-Cloud SDK כדי ליצור חשבון שירות, ואז ניצור פרטי כניסה שיידרשו לאימות בתור חשבון השירות.
קודם כל, מגדירים את משתנה הסביבה PROJECT_ID:
export PROJECT_ID=$(gcloud config get-value core/project)
לאחר מכן, יוצרים חשבון שירות חדש כדי לגשת אל BigQuery API באמצעות:
gcloud iam service-accounts create my-bigquery-sa \ --display-name "my bigquery service account"
בשלב הבא, יוצרים פרטי כניסה שקוד Python ישתמש בהם כדי להתחבר בתור חשבון השירות החדש. יוצרים את פרטי הכניסה ושומרים אותם כקובץ JSON ~/key.json באמצעות הפקודה הבאה:
gcloud iam service-accounts keys create ~/key.json \
--iam-account my-bigquery-sa@${PROJECT_ID}.iam.gserviceaccount.com
לבסוף, מגדירים את משתנה הסביבה GOOGLE_APPLICATION_CREDENTIALS, שספריית הלקוח של BigQuery Python משתמשת בו כדי למצוא את פרטי הכניסה שלכם. צריך להגדיר את משתנה הסביבה לנתיב המלא של קובץ ה-JSON עם פרטי הכניסה שיצרתם, באמצעות הפקודה:
export GOOGLE_APPLICATION_CREDENTIALS=~/key.json
5. הגדרת בקרת גישה
ב-BigQuery נעשה שימוש בניהול זהויות והרשאות גישה (IAM) כדי לנהל את הגישה למשאבים. ל-BigQuery יש מספר תפקידים מוגדרים מראש (משתמש, בעל נתונים, צופה בנתונים וכו') שאפשר להקצות לחשבון השירות שיצרתם בשלב הקודם. מידע נוסף על בקרת גישה זמין במסמכי BigQuery.
כדי לשלוח שאילתות למערכי נתונים ציבוריים, צריך לוודא שלחשבון השירות יש לפחות את התפקיד roles/bigquery.user. ב-Cloud Shell, מריצים את הפקודה הבאה כדי להקצות את תפקיד המשתמש לחשבון השירות:
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member "serviceAccount:my-bigquery-sa@${PROJECT_ID}.iam.gserviceaccount.com" \
--role "roles/bigquery.user"
כדי לוודא שלחשבון השירות יש את תפקיד המשתמש, מריצים את הפקודה הבאה:
gcloud projects get-iam-policy $PROJECT_ID
אתם אמורים לראות את הנתונים הבאים:
bindings: - members: - serviceAccount:my-bigquery-sa@<PROJECT_ID>.iam.gserviceaccount.com role: roles/bigquery.user ...
6. התקנת ספריית הלקוח
מתקינים את ספריית הלקוח של BigQuery Python:
pip3 install --user --upgrade google-cloud-bigquery
עכשיו אתם מוכנים לכתוב קוד באמצעות BigQuery API.
7. שליחת שאילתות לגבי יצירות של שייקספיר
מערך נתונים ציבורי הוא כל מערך נתונים שמאוחסן ב-BigQuery וזמין לציבור הרחב. יש עוד הרבה מערכי נתונים ציבוריים שתוכלו להריץ עליהם שאילתות. חלק ממערכי הנתונים מאוחסנים ב-Google, אבל רובם מאוחסנים על ידי צדדים שלישיים. מידע נוסף זמין בדף מערכי נתונים ציבוריים.
בנוסף למערכי נתונים ציבוריים, BigQuery מספק מספר מוגבל של טבלאות לדוגמה שאפשר להריץ עליהן שאילתות. הטבלאות האלה נמצאות במערך הנתונים bigquery-public-data:samples. טבלת shakespeare במערך הנתונים samples מכילה אינדקס מילים של יצירות שייקספיר. הוא מציג את מספר הפעמים שכל מילה מופיעה בכל מאגר.
בשלב הזה תריצו שאילתה על הטבלה shakespeare.
קודם, ב-Cloud Shell, יוצרים אפליקציית Python פשוטה שתשמש להרצת דוגמאות של Translation API.
mkdir bigquery-demo cd bigquery-demo touch app.py
פותחים את עורך הקוד בפינה השמאלית העליונה של Cloud Shell:

עוברים לקובץ app.py בתוך התיקייה bigquery-demo ומחליפים את הקוד בקוד הבא.
from google.cloud import bigquery
client = bigquery.Client()
query = """
SELECT corpus AS title, COUNT(word) AS unique_words
FROM `bigquery-public-data.samples.shakespeare`
GROUP BY title
ORDER BY unique_words
DESC LIMIT 10
"""
results = client.query(query)
for row in results:
title = row['title']
unique_words = row['unique_words']
print(f'{title:<20} | {unique_words}')
כדאי להקדיש דקה או שתיים כדי לבדוק את הקוד ולראות איך מתבצעת השאילתה בטבלה.
חוזרים ל-Cloud Shell ומריצים את האפליקציה:
python3 app.py
אמורה להופיע רשימה של מילים והמופעים שלהן:
hamlet | 5318 kinghenryv | 5104 cymbeline | 4875 troilusandcressida | 4795 kinglear | 4784 kingrichardiii | 4713 2kinghenryvi | 4683 coriolanus | 4653 2kinghenryiv | 4605 antonyandcleopatra | 4582
8. הרצת שאילתה בקבוצת הנתונים של GitHub
כדי להכיר טוב יותר את BigQuery, נריץ עכשיו שאילתה על מערך הנתונים הציבורי של GitHub. אפשר למצוא את הודעות הקומיט הנפוצות ביותר ב-GitHub. תשתמשו גם במסוף האינטרנט של BigQuery כדי להציג תצוגה מקדימה של שאילתות אד-הוק ולהריץ אותן.
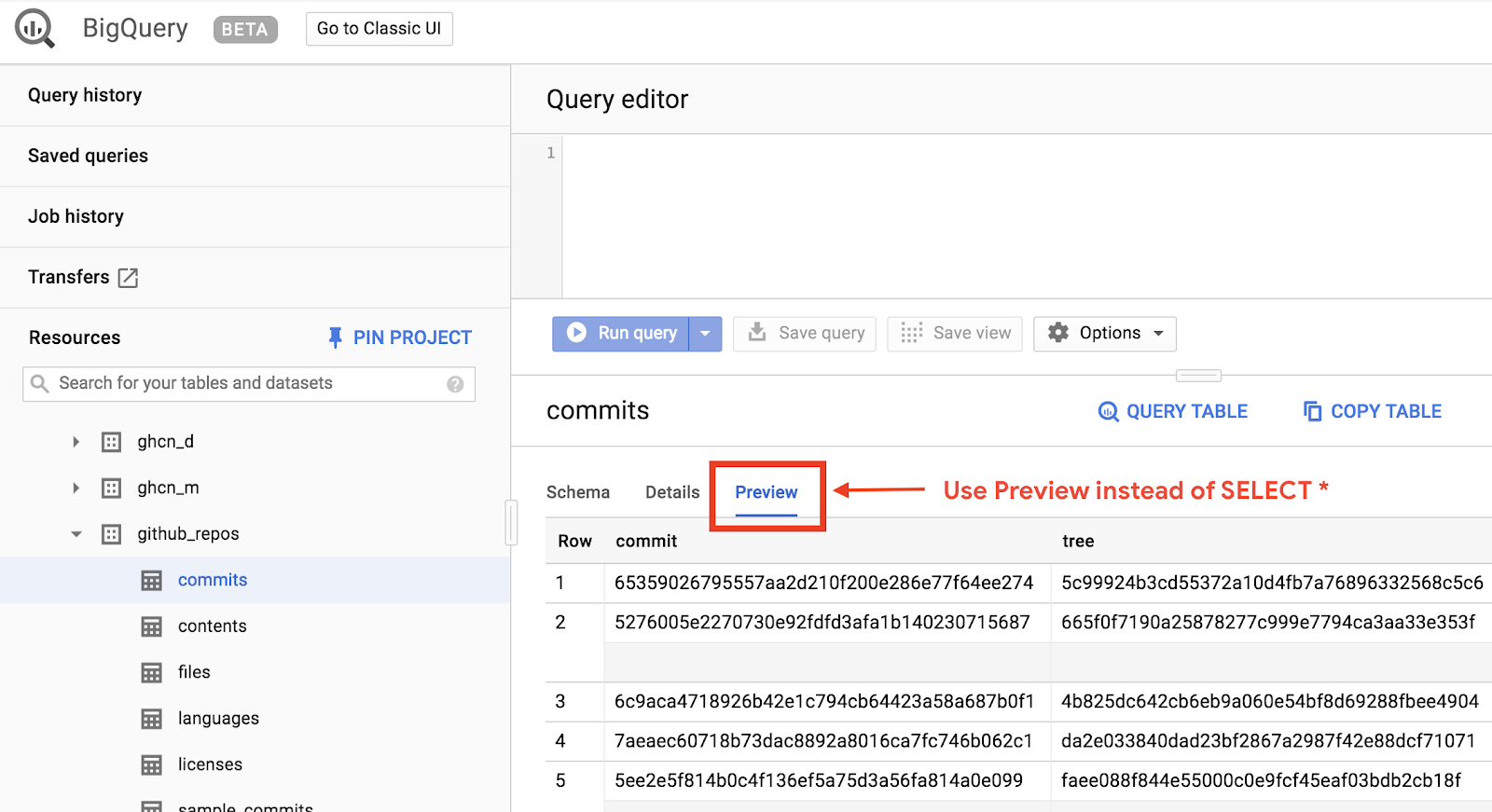
כדי לראות איך הנתונים נראים, פותחים את מערך הנתונים של GitHub בממשק המשתמש האינטרנטי של BigQuery:
לוחצים על הלחצן 'תצוגה מקדימה' כדי לראות איך הנתונים נראים:
עוברים לקובץ app.py בתוך התיקייה bigquery_demo ומחליפים את הקוד בקוד הבא.
from google.cloud import bigquery
client = bigquery.Client()
query = """
SELECT subject AS subject, COUNT(*) AS num_duplicates
FROM bigquery-public-data.github_repos.commits
GROUP BY subject
ORDER BY num_duplicates
DESC LIMIT 10
"""
results = client.query(query)
for row in results:
subject = row['subject']
num_duplicates = row['num_duplicates']
print(f'{subject:<20} | {num_duplicates:>9,}')
כדאי להקדיש דקה או שתיים ללימוד הקוד ולראות איך מתבצעת שאילתה בטבלה כדי למצוא את הודעות הקומיט הנפוצות ביותר.
חוזרים ל-Cloud Shell ומריצים את האפליקציה:
python3 app.py
אמורה להופיע רשימה של הודעות על ביצוע שינויים והמופעים שלהן:
Update README.md | 1,685,515
Initial commit | 1,577,543
update | 211,017
| 155,280
Create README.md | 153,711
Add files via upload | 152,354
initial commit | 145,224
first commit | 110,314
Update index.html | 91,893
Update README | 88,862
9. שמירה במטמון ונתונים סטטיסטיים
מערכת BigQuery שומרת במטמון את תוצאות השאילתות. כתוצאה מכך, השאילתות הבאות ייקחו פחות זמן. אפשר להשבית את השמירה במטמון באמצעות אפשרויות שאילתה. בנוסף, ב-BigQuery מתבצע מעקב אחרי נתונים סטטיסטיים לגבי שאילתות, כמו זמן היצירה, זמן הסיום והמספר הכולל של בייטים שעברו עיבוד.
בשלב הזה, משביתים את השמירה במטמון ומציגים נתונים סטטיסטיים לגבי השאילתות.
עוברים לקובץ app.py בתוך התיקייה bigquery_demo ומחליפים את הקוד בקוד הבא.
from google.cloud import bigquery
client = bigquery.Client()
query = """
SELECT subject AS subject, COUNT(*) AS num_duplicates
FROM bigquery-public-data.github_repos.commits
GROUP BY subject
ORDER BY num_duplicates
DESC LIMIT 10
"""
job_config = bigquery.job.QueryJobConfig(use_query_cache=False)
results = client.query(query, job_config=job_config)
for row in results:
subject = row['subject']
num_duplicates = row['num_duplicates']
print(f'{subject:<20} | {num_duplicates:>9,}')
print('-'*60)
print(f'Created: {results.created}')
print(f'Ended: {results.ended}')
print(f'Bytes: {results.total_bytes_processed:,}')
כמה דברים שכדאי לשים לב אליהם בקוד. קודם כול, ההטמעה של QueryJobConfig וההגדרה של use_query_cache כ-false משביתות את השמירה במטמון. שנית, ניגשתם לנתונים הסטטיסטיים לגבי השאילתה מאובייקט המשרה.
חוזרים ל-Cloud Shell ומריצים את האפליקציה:
python3 app.py
כמו קודם, תופיע רשימה של הודעות על ביצוע שינויים והמופעים שלהן. בנוסף, בסוף השאילתה אמורים להופיע נתונים סטטיסטיים לגביה:
Update README.md | 1,685,515
Initial commit | 1,577,543
update | 211,017
| 155,280
Create README.md | 153,711
Add files via upload | 152,354
initial commit | 145,224
first commit | 110,314
Update index.html | 91,893
Update README | 88,862
------------------------------------------------------------
Created: 2020-04-03 13:30:08.801000+00:00
Ended: 2020-04-03 13:30:15.334000+00:00
Bytes: 2,868,251,894
10. טעינת נתונים לתוך BigQuery
אם רוצים להריץ שאילתות על נתונים משלכם, צריך לטעון את הנתונים ל-BigQuery. BigQuery תומך בטעינת נתונים ממקורות רבים, כולל Cloud Storage, שירותים אחרים של Google ומקורות אחרים שניתן לקרוא מהם. אפשר אפילו להזרים את הנתונים באמצעות הוספות של נתונים בהזרמה. מידע נוסף זמין בדף טעינת נתונים לתוך BigQuery.
בשלב הזה, תטענו קובץ JSON שמאוחסן ב-Cloud Storage לטבלה ב-BigQuery. קובץ ה-JSON נמצא במיקום gs://cloud-samples-data/bigquery/us-states/us-states.json
אם אתם רוצים לדעת מה התוכן של קובץ ה-JSON, אתם יכולים להשתמש בכלי gsutil של שורת הפקודה כדי להוריד אותו ב-Cloud Shell:
gsutil cp gs://cloud-samples-data/bigquery/us-states/us-states.json .
אפשר לראות שהוא מכיל את רשימת המדינות בארה"ב, וכל מדינה היא מסמך JSON בשורה נפרדת:
head us-states.json
{"name": "Alabama", "post_abbr": "AL"}
{"name": "Alaska", "post_abbr": "AK"}
...
כדי לטעון את קובץ ה-JSON הזה ל-BigQuery, עוברים לקובץ app.py בתיקייה bigquery_demo ומחליפים את הקוד בקוד הבא.
from google.cloud import bigquery
client = bigquery.Client()
gcs_uri = 'gs://cloud-samples-data/bigquery/us-states/us-states.json'
dataset = client.create_dataset('us_states_dataset')
table = dataset.table('us_states_table')
job_config = bigquery.job.LoadJobConfig()
job_config.schema = [
bigquery.SchemaField('name', 'STRING'),
bigquery.SchemaField('post_abbr', 'STRING'),
]
job_config.source_format = bigquery.SourceFormat.NEWLINE_DELIMITED_JSON
load_job = client.load_table_from_uri(gcs_uri, table, job_config=job_config)
print('JSON file loaded to BigQuery')
כדאי להקדיש דקה או שתיים כדי להבין איך הקוד טוען את קובץ ה-JSON ויוצר טבלה עם סכימה מתחת למערך נתונים.
חוזרים ל-Cloud Shell ומריצים את האפליקציה:
python3 app.py
מערך נתונים וטבלה נוצרים ב-BigQuery.
כדי לוודא שמערך הנתונים נוצר, עוברים אל מסוף BigQuery. יוצגו לכם מערך נתונים וטבלה חדשים. כדי לראות את הנתונים, עוברים לכרטיסיית התצוגה המקדימה של הטבלה:

11. מעולה!
למדתם איך להשתמש ב-BigQuery עם Python.
פינוי נפח
כדי להימנע מחיובים בחשבון Google Cloud בגלל השימוש במשאבים שנעשה במסגרת המדריך הזה:
- במסוף Cloud, נכנסים לדף Manage resources.
- ברשימת הפרויקטים, בוחרים את הפרויקט ולוחצים על מחיקה.
- כדי למחוק את הפרויקט, כותבים את מזהה הפרויקט בתיבת הדו-שיח ולוחצים על Shut down.
מידע נוסף
- Google BigQuery: https://cloud.google.com/bigquery/docs/
- Python ב-Google Cloud: https://cloud.google.com/python/
- ספריות לקוח של Cloud ל-Python: https://googleapis.github.io/google-cloud-python/
רישיון
עבודה זו מורשית תחת רישיון Creative Commons שמותנה בייחוס 2.0 כללי.