
1. Overview
BigQuery is Google's fully managed, NoOps, low-cost analytics database. With BigQuery, you can query terabytes and terabytes of data without having any infrastructure to manage, and don't need a database administrator. BigQuery uses familiar SQL and it can take advantage of a pay-as-you-go model. BigQuery allows you to focus on analyzing data to find meaningful insights.
In this codelab, you explore the Wikipedia dataset using BigQuery.
What you'll learn
- How to use BigQuery
- How to load a real-world dataset into BigQuery
- How to write a query to gain insight into a large dataset
What you'll need
- A Google Cloud project
- A browser, such as Google Chrome or Firefox
Survey
How will you use this tutorial?
How would rate your experience with Google Cloud?
2. Setup and requirements
Enable BigQuery
If you don't already have a Google Account, you must create one.
- Sign in to Google Cloud Console and navigate to BigQuery. You can also open the BigQuery web UI directly by entering the following URL in your browser.
https://console.cloud.google.com/bigquery
- Accept the terms of service.
- Before you can use BigQuery, you must create a project. Follow the prompts to create your new project.
Choose a project name and make note of the project ID. 
The project ID is a unique name across all Google Cloud projects. It will be referred to later in this codelab as PROJECT_ID.
This codelab uses BigQuery resources within the BigQuery sandbox limits. A billing account is not required. If you later want to remove the sandbox limits, you can add a billing account by signing up for the Google Cloud free trial.
You load the Wikipedia dataset in the next section.
3. Create a dataset
First, create a new dataset in the project. A dataset is composed of multiple tables.
- To create a dataset, click the project name under the resources pane, then click Create dataset:

- Enter
labas the Dataset ID:

- Click Create dataset to create an empty dataset.
4. Load data with the bq command-line program
Activate Cloud Shell
- From the Cloud Console, click Activate Cloud Shell
 .
.

If you've never started Cloud Shell before, you're presented with an intermediate screen (below the fold) describing what it is. If that's the case, click Continue (and you won't ever see it again). Here's what that one-time screen looks like:

It should only take a few moments to provision and connect to Cloud Shell.

This virtual machine is loaded with all the development tools you need. It offers a persistent 5GB home directory and runs in Google Cloud, greatly enhancing network performance and authentication. Much, if not all, of your work in this codelab can be done with simply a browser or your Chromebook.
Once connected to Cloud Shell, you should see that you are already authenticated and that the project is already set to your project ID.
- Run the following command in Cloud Shell to confirm that you are authenticated:
gcloud auth list
Command output
Credentialed Accounts
ACTIVE ACCOUNT
* <my_account>@<my_domain.com>
To set the active account, run:
$ gcloud config set account `ACCOUNT`
- Run the following command in Cloud Shell to confirm that the gcloud command knows about your project:
gcloud config list project
Command output
[core] project = <PROJECT_ID>
If it is not, you can set it with this command:
gcloud config set project <PROJECT_ID>
Command output
Updated property [core/project].
Load data into BigQuery
For your convenience, some of the data for April 10, 2019, from the Wikimedia pageviews dataset is available on Google Cloud Storage at gs://cloud-samples-data/third-party/wikimedia/pageviews/pageviews-20190410-140000.gz. The data file is a GZip'ed CSV file. You can load this file directly using the bq command-line utility. As part of the load command, you also describe the schema of the file.
bq load \
--source_format CSV \
--field_delimiter " " \
--allow_jagged_rows \
--quote "" \
--max_bad_records 3 \
$GOOGLE_CLOUD_PROJECT:lab.pageviews_20190410_140000 \
gs://cloud-samples-data/third-party/wikimedia/pageviews/pageviews-20190410-140000.gz \
wiki,title,requests:integer,zero:integer
You used a few advanced options to load the page-views file:
- Set
--source_format CSVto indicate the file should be parsed as a CSV file. This step is optional because CSV is the default format. - Set
--field_delimiter " "to indicate that a single space is used to delimit fields. - Set
--allow_jagged_rowsto include the rows with fewer number of columns and ignore the errors while loading the CSV file. - Set
--quote ""to indicate that strings are unquoted. - Set
--max_bad_records 3to ignore at most 3 errors while parsing the CSV file.
You can learn more about the bq command line in the documentation.
5. Preview the Dataset
In the BigQuery console, open one of the tables that you just loaded.
- Expand the project.
- Expand the dataset.
- Select the table.

You can see the table schema in the Schema tab. 4. Find out how much data is in the table by navigating to the Details tab:

- Open the Preview tab to see a selection of rows from the table.

6. Compose a query
- Click Compose new query:

This brings up the Query editor:

- Find the total number of Wikimedia views between 2 and 3 PM on April 10, 2019, by writing this query:
SELECT SUM(requests) FROM `lab.pageviews_20190410_140000`
- Click Run:

In a few seconds, the result is listed in the bottom and it also tells you how much data was processed:

This query processed 123.9MB, even though the table is 691.4MB. BigQuery only processes the bytes from the columns which are used in the query, so the total amount of data processed can be significantly less than the table size. With clustering and partitioning, the amount of data processed can be reduced even further.
7. More advanced queries
Find Wikipedia page views
The Wikimedia dataset contains page views for all of the Wikimedia projects (including Wikipedia, Wiktionary, Wikibooks, and Wikiquotes). Narrow the query to just English Wikipedia pages by adding a WHERE statement:
SELECT SUM(requests), wiki FROM `lab.pageviews_20190410_140000` WHERE wiki = "en" GROUP BY wiki
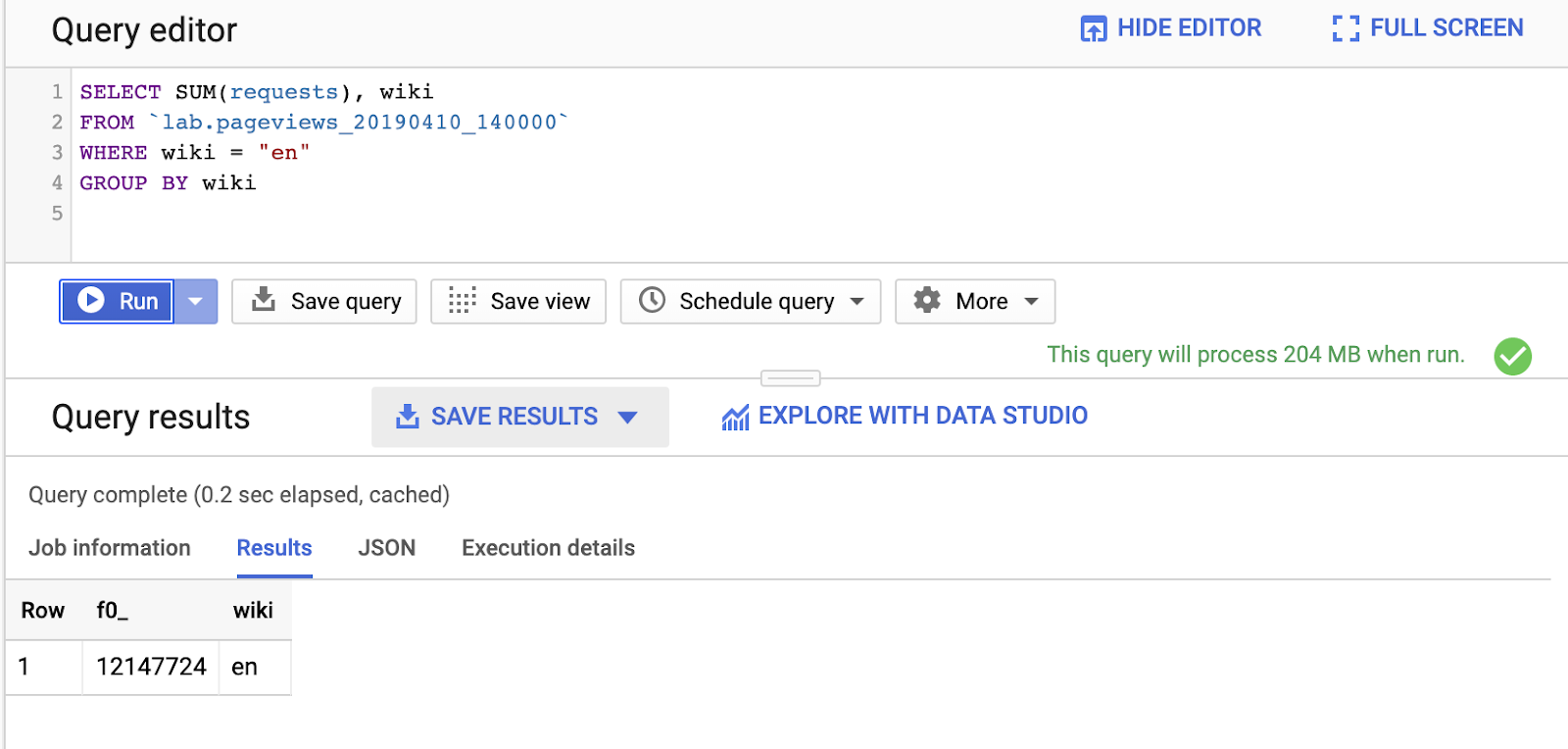
Notice that, by querying an additional column, wiki, the amount of data processed increased from 124MB to 204MB.
BigQuery supports many of the familiar SQL clauses, such as CONTAINS, GROUP BY, ORDER BY, and a number of aggregation functions. In addition, you can also use regular expressions to query text fields! Try one:
SELECT title, SUM(requests) requests FROM `lab.pageviews_20190410_140000` WHERE wiki = "en" AND REGEXP_CONTAINS(title, 'Red.*t') GROUP BY title ORDER BY requests DESC
Query across multiple tables
You can select a range of tables to form the union using a wildcard table.
- First, create a second table to query over by loading the next hour's page views into a new table:
bq load \
--source_format CSV \
--field_delimiter " " \
--quote "" \
$GOOGLE_CLOUD_PROJECT:lab.pageviews_20190410_150000 \
gs://cloud-samples-data/third-party/wikimedia/pageviews/pageviews-20190410-150000.gz \
wiki,title,requests:integer,zero:integer
- In the Query editor, query over both tables you loaded by querying tables with "
pageviews_2019" as a prefix:
SELECT title, SUM(requests) requests FROM `lab.pageviews_2019*` WHERE wiki = "en" AND REGEXP_CONTAINS(title, 'Red.*t') GROUP BY title ORDER BY requests DESC
You can filter the tables more selectively with the _TABLE_SUFFIX pseudo column. This query limits to tables corresponding to April 10.
SELECT title, SUM(requests) requests FROM `lab.pageviews_2019*` WHERE _TABLE_SUFFIX BETWEEN '0410' AND '0410_9999999' AND wiki = "en" AND REGEXP_CONTAINS(title, 'Red.*t') GROUP BY title ORDER BY requests DESC
8. Cleaning up
Optionally, delete the dataset you created with the bq rm command. Use the -r flag to remove any tables it contains.
bq rm -r lab
9. Congratulations!
You used BigQuery and SQL to query the real-world Wikipedia page-views dataset. You have the power to query petabyte-scale datasets!
Learn more
- Check out the BigQuery subreddit for how others use BigQuery today.
- Find public datasets available in BigQuery.
- Learn how to load data into BigQuery.