
1. Descripción general
BigQuery es la base de datos de estadísticas de bajo costo, no-ops y completamente administrada de Google. Con BigQuery, puedes consultar muchos terabytes de datos sin tener que administrar ninguna infraestructura y sin la necesidad de un administrador de base de datos. BigQuery usa el lenguaje SQL conocido y puede aprovechar el modelo de pago por uso. BigQuery te permite enfocarte en el análisis de datos para buscar estadísticas valiosas.
En este codelab, explorarás el conjunto de datos de Wikipedia con BigQuery.
Qué aprenderás
- Cómo usar BigQuery
- Cómo cargar un conjunto de datos del mundo real en BigQuery
- Cómo escribir una consulta para obtener estadísticas sobre un gran conjunto de datos
Requisitos
- Un proyecto de Google Cloud
- Un navegador, como Google Chrome o Firefox
Encuesta
¿Cómo usarás este instructivo?
¿Cómo calificarías tu experiencia con Google Cloud?
2. Configuración y requisitos
Habilita BigQuery
Si aún no tienes una Cuenta de Google, debes crear una.
- Accede a Google Cloud Console y navega a BigQuery. También puedes abrir la IU web de BigQuery directamente si ingresas la siguiente URL en tu navegador.
https://console.cloud.google.com/bigquery
- Acepta las Condiciones del Servicio.
- Para poder usar BigQuery, debes crear un proyecto. Sigue las indicaciones para crear un proyecto nuevo.
Elige un nombre para el proyecto y toma nota del ID del proyecto. 
El ID del proyecto es un nombre único en todos los proyectos de Google Cloud. Se mencionará más adelante en este codelab como PROJECT_ID.
En este codelab, se usan recursos de BigQuery dentro de los límites de la zona de pruebas de BigQuery. No se requiere una cuenta de facturación. Si más adelante deseas quitar los límites del entorno de pruebas, puedes agregar una cuenta de facturación registrándote en la prueba gratuita de Google Cloud.
Cargarás el conjunto de datos de Wikipedia en la siguiente sección.
3. Crea un conjunto de datos
Primero, crea un conjunto de datos nuevo en el proyecto. Un conjunto de datos se compone de varias tablas.
- Para crear un conjunto de datos, haz clic en el nombre del proyecto en el panel de recursos y, luego, en Crear conjunto de datos:

- Ingresa
labcomo el ID del conjunto de datos:

- Haz clic en Crear conjunto de datos para crear un conjunto de datos vacío.
4. Carga datos con el programa de línea de comandos de bq
Activar Cloud Shell
- En la consola de Cloud, haz clic en Activar Cloud Shell
 .
.

Si nunca has iniciado Cloud Shell, aparecerá una pantalla intermedia (mitad inferior de la página) en la que se describirá qué es. Si ese es el caso, haz clic en Continuar (y no volverás a verla). Así es como se ve la pantalla única:

El aprovisionamiento y la conexión a Cloud Shell solo tomará unos minutos.

Esta máquina virtual está cargada con todas las herramientas de desarrollo que necesitas. Ofrece un directorio principal persistente de 5 GB y se ejecuta en Google Cloud, lo que permite mejorar considerablemente el rendimiento de la red y la autenticación. Gran parte de tu trabajo en este codelab, si no todo, se puede hacer simplemente con un navegador o tu Chromebook.
Una vez conectado a Cloud Shell, debería ver que ya se autenticó y que el proyecto ya se configuró con tu ID del proyecto.
- En Cloud Shell, ejecuta el siguiente comando para confirmar que está autenticado:
gcloud auth list
Resultado del comando
Credentialed Accounts
ACTIVE ACCOUNT
* <my_account>@<my_domain.com>
To set the active account, run:
$ gcloud config set account `ACCOUNT`
- En Cloud Shell, ejecuta el siguiente comando para confirmar que el comando gcloud conoce tu proyecto:
gcloud config list project
Resultado del comando
[core] project = <PROJECT_ID>
De lo contrario, puedes configurarlo con el siguiente comando:
gcloud config set project <PROJECT_ID>
Resultado del comando
Updated property [core/project].
Carga datos en BigQuery
Para tu comodidad, algunos de los datos del 10 de abril de 2019 del conjunto de datos de vistas de página de Wikimedia están disponibles en Google Cloud Storage en gs://cloud-samples-data/third-party/wikimedia/pageviews/pageviews-20190410-140000.gz. El archivo de datos es un archivo CSV comprimido con GZip. Puedes cargar este archivo directamente con la utilidad de línea de comandos bq. Como parte del comando de carga, también describes el esquema del archivo.
bq load \
--source_format CSV \
--field_delimiter " " \
--allow_jagged_rows \
--quote "" \
--max_bad_records 3 \
$GOOGLE_CLOUD_PROJECT:lab.pageviews_20190410_140000 \
gs://cloud-samples-data/third-party/wikimedia/pageviews/pageviews-20190410-140000.gz \
wiki,title,requests:integer,zero:integer
Usaste algunas opciones avanzadas para cargar el archivo de vistas de página:
- Establece
--source_format CSVpara indicar que el archivo se debe analizar como un archivo CSV. Este paso es opcional porque CSV es el formato predeterminado. - Establece
--field_delimiter " "para indicar que se usa un solo espacio para delimitar los campos. - Establece
--allow_jagged_rowspara incluir las filas con menos columnas y, luego, ignora los errores mientras cargas el archivo CSV. - Establece
--quote ""para indicar que las cadenas no están entre comillas. - Establece
--max_bad_records 3para ignorar hasta 3 errores mientras se analiza el archivo CSV.
Puedes obtener más información sobre la línea de comandos de bq en la documentación.
5. Obtén una vista previa del conjunto de datos
En la consola de BigQuery, abre una de las tablas que acabas de cargar.
- Expande el proyecto.
- Expande el conjunto de datos.
- Selecciona la tabla.
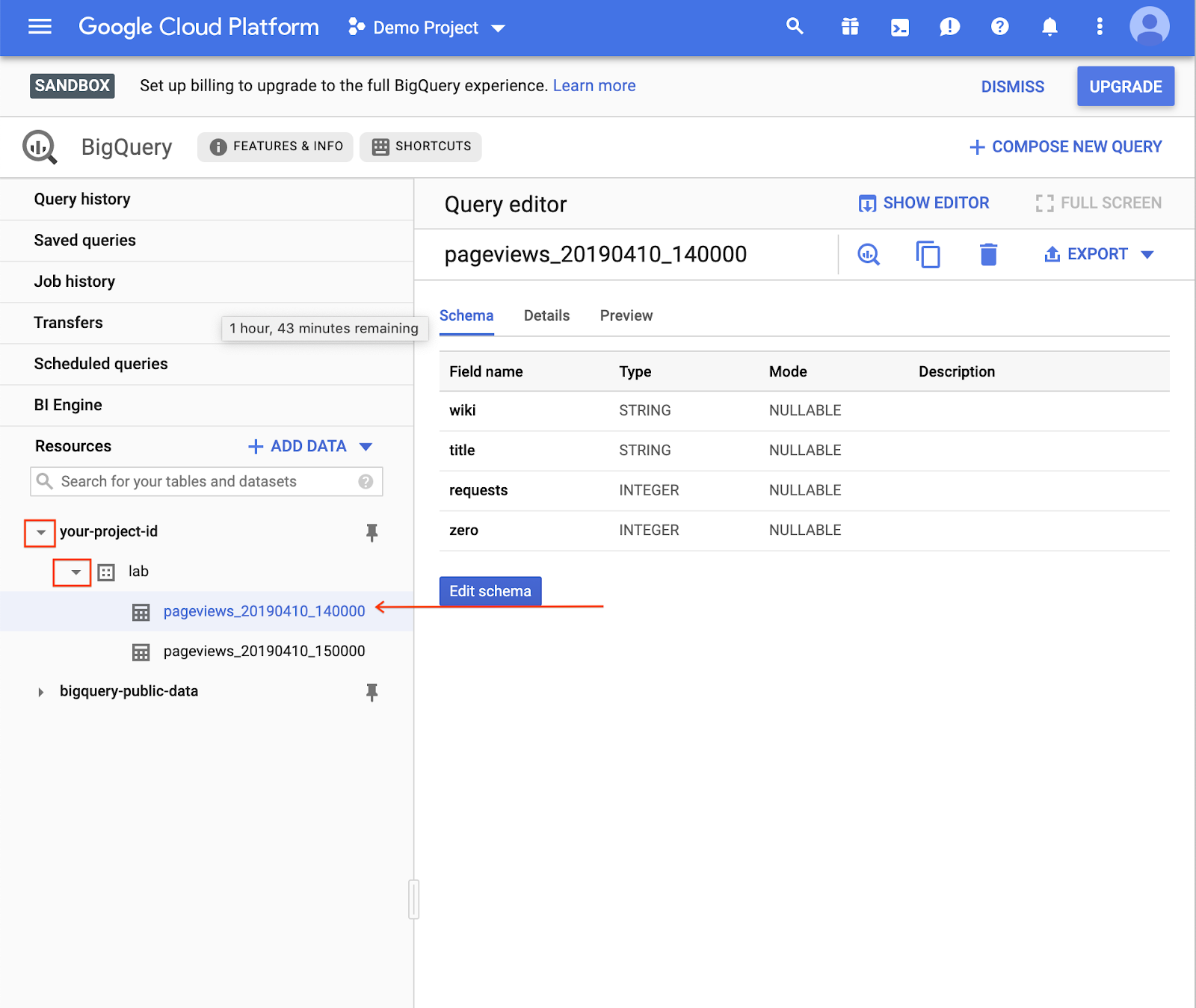
Puedes ver el esquema de la tabla en la pestaña Esquema. 4. Para saber cuántos datos hay en la tabla, navega a la pestaña Details:

- Abre la pestaña Vista previa para ver una selección de filas de la tabla.

6. Redacta una consulta
- Haz clic en Redactar consulta nueva:
Se abrirá el Editor de consultas:

- Para encontrar la cantidad total de vistas de Wikimedia entre las 2 p.m. y las 3 p.m. del 10 de abril de 2019, escribe la siguiente consulta:
SELECT SUM(requests) FROM `lab.pageviews_20190410_140000`
- Haz clic en Ejecutar:

En unos segundos, el resultado aparecerá en la parte inferior y también te indicará la cantidad de datos que se procesaron:
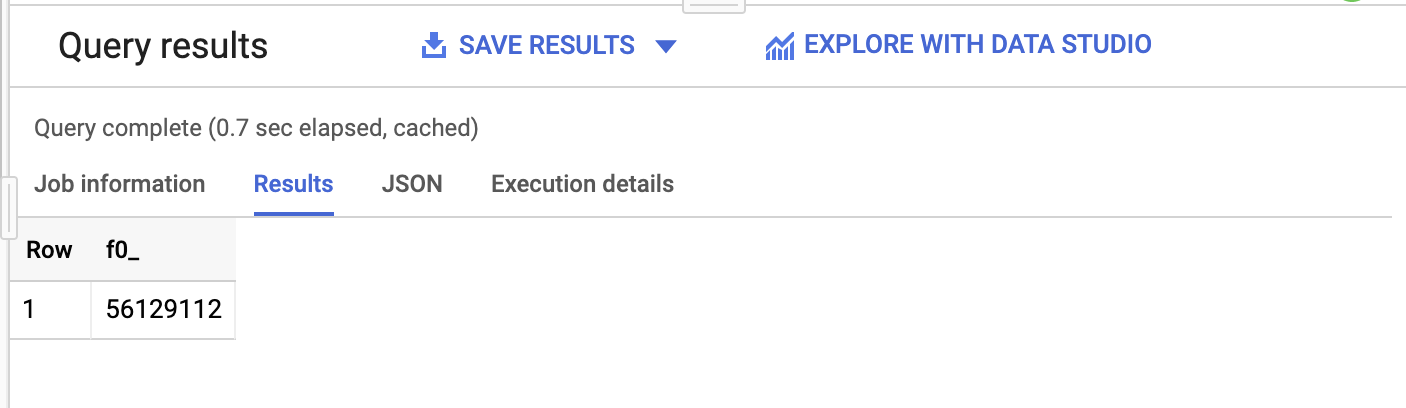
Esta consulta procesó 123.9 MB, aunque la tabla tiene 691.4 MB. BigQuery solo procesa los bytes de las columnas que se usan en la consulta, por lo que la cantidad total de datos procesados puede ser significativamente menor que el tamaño de la tabla. Con el agrupamiento en clústeres y el particionamiento, la cantidad de datos procesados se puede reducir aún más.
7. Consultas más avanzadas
Cómo encontrar las vistas de página de Wikipedia
El conjunto de datos de Wikimedia contiene las vistas de página de todos los proyectos de Wikimedia (incluidos Wikipedia, Wikcionario, Wikilibros y Wikiquote). Para limitar la búsqueda solo a las páginas de Wikipedia en inglés, agrega una instrucción WHERE:
SELECT SUM(requests), wiki FROM `lab.pageviews_20190410_140000` WHERE wiki = "en" GROUP BY wiki
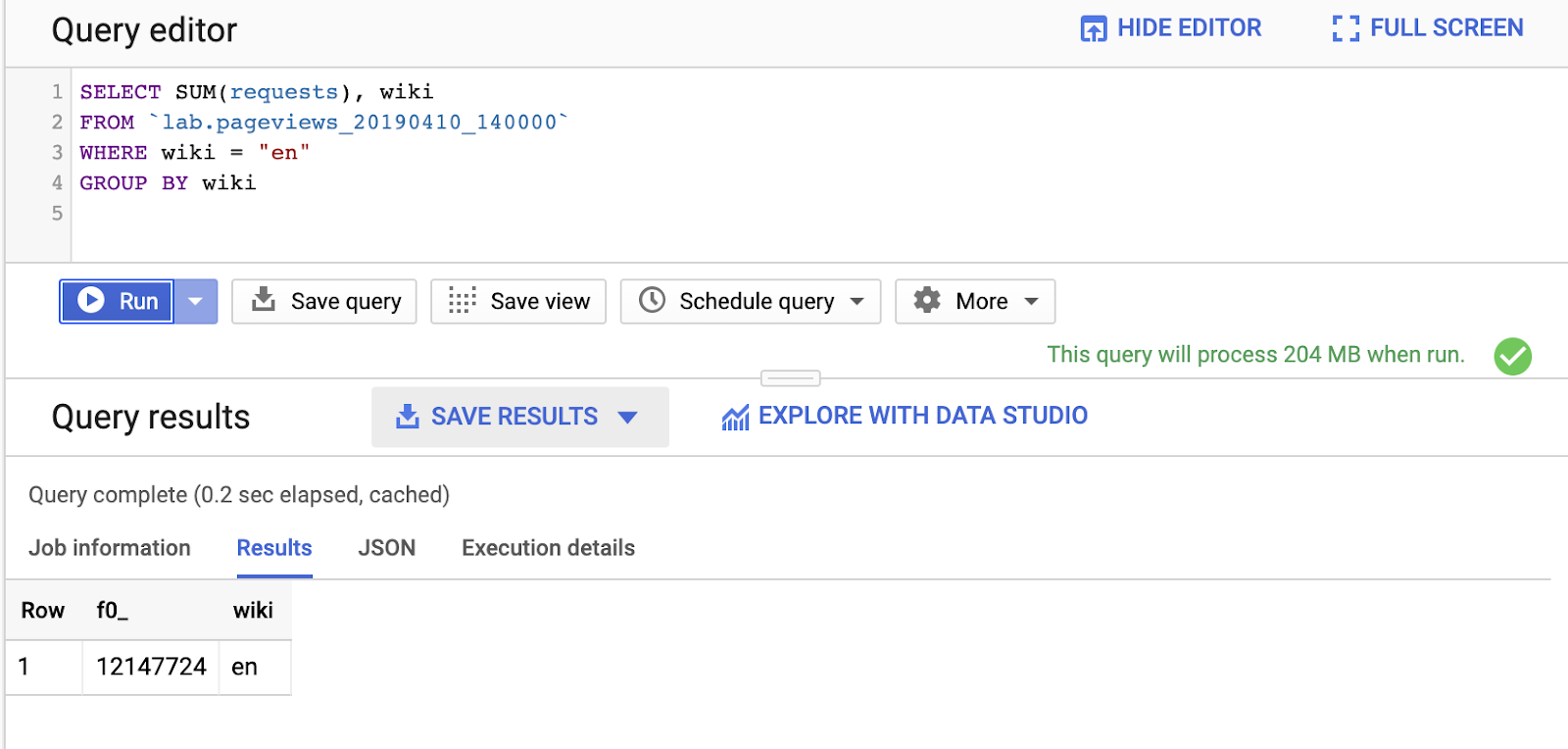
Ten en cuenta que, al consultar una columna adicional, wiki, la cantidad de datos procesados aumentó de 124 MB a 204 MB.
BigQuery admite muchas de las cláusulas de SQL conocidas, como CONTAINS, GROUP BY, ORDER BY y varias funciones de agregación. Además, también puedes usar expresiones regulares para consultar campos de texto. Prueba una de las siguientes opciones:
SELECT title, SUM(requests) requests FROM `lab.pageviews_20190410_140000` WHERE wiki = "en" AND REGEXP_CONTAINS(title, 'Red.*t') GROUP BY title ORDER BY requests DESC
Cómo realizar consultas en varias tablas
Puedes seleccionar un rango de tablas para formar la unión con una tabla comodín.
- Primero, crea una segunda tabla para consultar cargando las vistas de página de la próxima hora en una tabla nueva:
bq load \
--source_format CSV \
--field_delimiter " " \
--quote "" \
$GOOGLE_CLOUD_PROJECT:lab.pageviews_20190410_150000 \
gs://cloud-samples-data/third-party/wikimedia/pageviews/pageviews-20190410-150000.gz \
wiki,title,requests:integer,zero:integer
- En el Editor de consultas, realiza consultas en ambas tablas que cargaste con el prefijo "
pageviews_2019":
SELECT title, SUM(requests) requests FROM `lab.pageviews_2019*` WHERE wiki = "en" AND REGEXP_CONTAINS(title, 'Red.*t') GROUP BY title ORDER BY requests DESC
Puedes filtrar las tablas de forma más selectiva con la seudocolumna _TABLE_SUFFIX. Esta consulta se limita a las tablas correspondientes al 10 de abril.
SELECT title, SUM(requests) requests FROM `lab.pageviews_2019*` WHERE _TABLE_SUFFIX BETWEEN '0410' AND '0410_9999999' AND wiki = "en" AND REGEXP_CONTAINS(title, 'Red.*t') GROUP BY title ORDER BY requests DESC
8. Realiza una limpieza
De manera opcional, borra el conjunto de datos que creaste con el comando bq rm. Usa la marca -r para quitar las tablas que contiene.
bq rm -r lab
9. ¡Felicitaciones!
Usaste BigQuery y SQL para consultar el conjunto de datos de vistas de página de Wikipedia del mundo real. Tienes el poder de consultar conjuntos de datos a escala de petabytes.
Más información
- Consulta la subreddit de BigQuery para saber cómo otros utilizan este almacén de datos hoy en día.
- Encuentra conjuntos de datos públicos disponibles en BigQuery.
- Aprende a cargar datos en BigQuery.