
1. Przegląd
BigQuery to ekonomiczna, w pełni zarządzana analityczna baza danych Google typu NoOps. Z BigQuery możesz przeszukiwać wiele terabajtów danych bez konieczności zarządzania infrastrukturą czy wyznaczania administratora bazy danych. Usługa BigQuery opiera się na znanym języku SQL i jest dostępna w modelu płatności według wykorzystania. Pracując w BigQuery, możesz skoncentrować się na analizowaniu danych i wyciąganiu z nich znaczących wniosków.
W tym module dowiesz się, jak eksplorować zbiór danych Wikipedii za pomocą BigQuery.
Czego się nauczysz
- Jak korzystać z BigQuery
- Wczytywanie rzeczywistego zbioru danych do BigQuery
- Jak napisać zapytanie, aby uzyskać wgląd w duży zbiór danych
Czego potrzebujesz
- projekt Google Cloud,
- przeglądarka, np. Google Chrome lub Firefox;
Ankieta
Jak zamierzasz korzystać z tego samouczka?
Jak oceniasz korzystanie z Google Cloud?
2. Konfiguracja i wymagania
Włączanie BigQuery
Jeśli nie masz jeszcze konta Google, musisz je utworzyć.
- Zaloguj się w konsoli Google Cloud i otwórz BigQuery. Możesz też otworzyć internetowy interfejs BigQuery bezpośrednio, wpisując w przeglądarce ten adres URL:
https://console.cloud.google.com/bigquery
- Zaakceptuj Warunki korzystania z usługi.
- Zanim zaczniesz korzystać z BigQuery, musisz utworzyć projekt. Postępuj zgodnie z instrukcjami, aby utworzyć nowy projekt.
Wybierz nazwę projektu i zanotuj identyfikator projektu. 
Identyfikator projektu to unikalna nazwa w ramach wszystkich projektów Google Cloud. W dalszej części tego laboratorium będzie on nazywany PROJECT_ID.
W tym module wykorzystywane są zasoby BigQuery w ramach limitów piaskownicy BigQuery. Konto rozliczeniowe nie jest wymagane. Jeśli później zechcesz usunąć limity piaskownicy, możesz dodać konto rozliczeniowe, rejestrując się w bezpłatnym okresie próbnym Google Cloud.
W następnej sekcji wczytasz zbiór danych z Wikipedii.
3. Tworzenie zbioru danych
Najpierw utwórz w projekcie nowy zbiór danych. Zbiór danych składa się z wielu tabel.
- Aby utworzyć zbiór danych, kliknij nazwę projektu w panelu zasobów, a potem kliknij Utwórz zbiór danych:
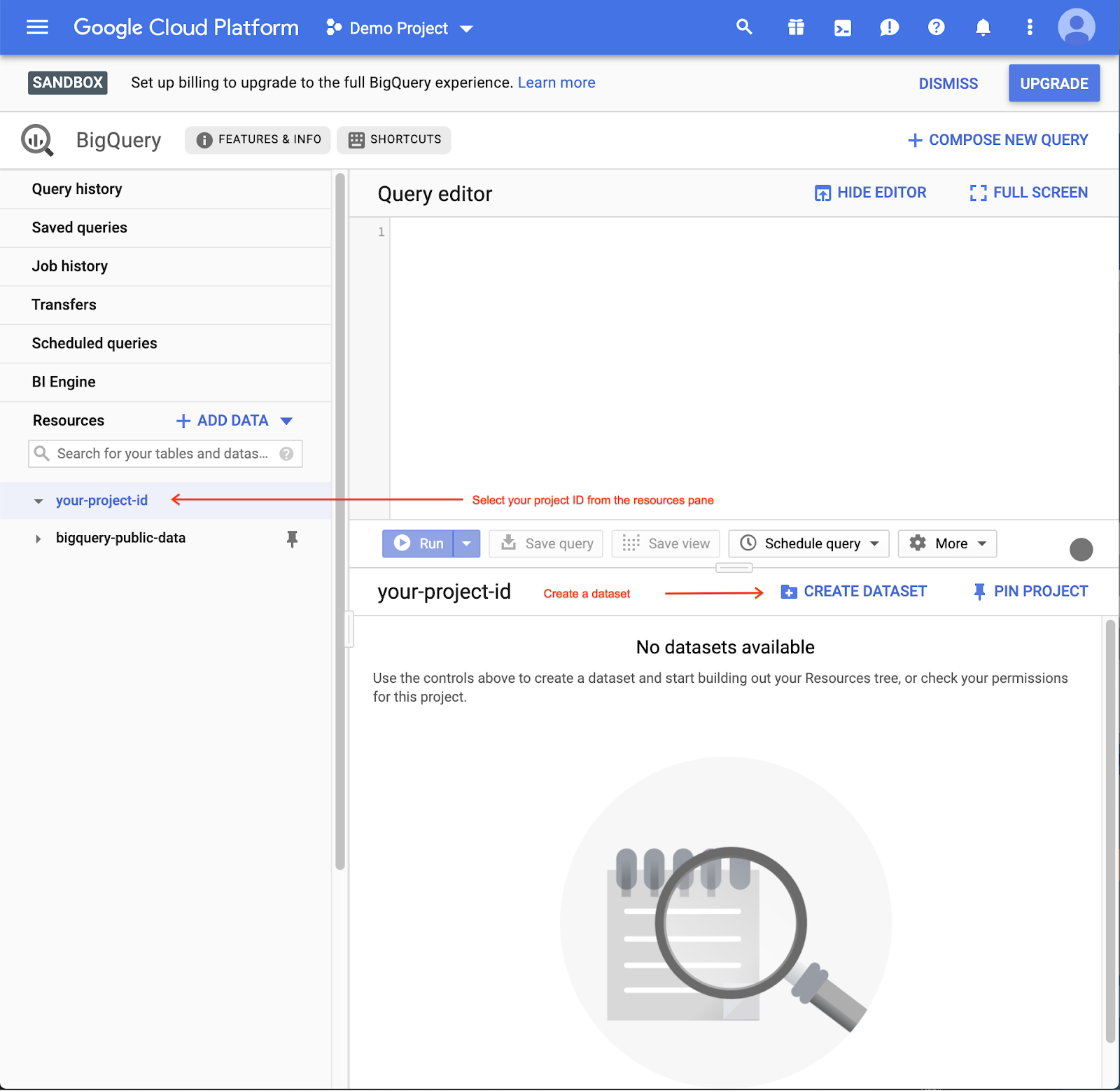
- Jako identyfikator zbioru danych wpisz
lab:

- Aby utworzyć pusty zbiór danych, kliknij Utwórz zbiór danych.
4. Wczytywanie danych za pomocą programu wiersza poleceń bq
Aktywowanie Cloud Shell
- W konsoli Cloud kliknij Aktywuj Cloud Shell
 .
.

Jeśli uruchamiasz Cloud Shell po raz pierwszy, zobaczysz ekran pośredni (część strony widoczna po przewinięciu) z opisem tego środowiska. W takim przypadku kliknij Dalej, a ten ekran nie będzie się już wyświetlać. Ten wyświetlany jednorazowo ekran wygląda tak:
Uzyskanie dostępu do środowiska Cloud Shell i połączenie się z nim powinno zająć tylko kilka chwil.

Ta maszyna wirtualna zawiera wszystkie potrzebne narzędzia dla programistów. Zawiera również stały katalog domowy o pojemności 5 GB i działa w Google Cloud, co znacznie zwiększa wydajność sieci i usprawnia proces uwierzytelniania. Większość zadań w tym module, a być może wszystkie, możesz wykonać w przeglądarce lub na Chromebooku.
Po połączeniu z Cloud Shell zobaczysz, że uwierzytelnianie zostało już przeprowadzone, a projekt jest już ustawiony na Twój identyfikator projektu.
- Aby potwierdzić, że uwierzytelnianie zostało przeprowadzone, uruchom w Cloud Shell to polecenie:
gcloud auth list
Wynik polecenia
Credentialed Accounts
ACTIVE ACCOUNT
* <my_account>@<my_domain.com>
To set the active account, run:
$ gcloud config set account `ACCOUNT`
- Aby potwierdzić, że polecenie gcloud zna Twój projekt, uruchom w Cloud Shell to polecenie:
gcloud config list project
Wynik polecenia
[core] project = <PROJECT_ID>
Jeśli nie, możesz go ustawić za pomocą tego polecenia:
gcloud config set project <PROJECT_ID>
Wynik polecenia
Updated property [core/project].
Wczytywanie danych do BigQuery
Dla Twojej wygody część danych z 10 kwietnia 2019 r. z zbioru danych wyświetleń stron w Wikipedii jest dostępna w Google Cloud Storage pod adresem gs://cloud-samples-data/third-party/wikimedia/pageviews/pageviews-20190410-140000.gz. Plik danych to skompresowany plik CSV. Możesz załadować ten plik bezpośrednio za pomocą narzędzia wiersza poleceń bq. W ramach polecenia wczytywania opisujesz też schemat pliku.
bq load \
--source_format CSV \
--field_delimiter " " \
--allow_jagged_rows \
--quote "" \
--max_bad_records 3 \
$GOOGLE_CLOUD_PROJECT:lab.pageviews_20190410_140000 \
gs://cloud-samples-data/third-party/wikimedia/pageviews/pageviews-20190410-140000.gz \
wiki,title,requests:integer,zero:integer
Do wczytania pliku odsłon użyto kilku opcji zaawansowanych:
- Ustaw wartość
--source_format CSV, aby wskazać, że plik ma być analizowany jako plik CSV. Ten krok jest opcjonalny, ponieważ CSV to format domyślny. - Ustaw wartość
--field_delimiter " ", aby wskazać, że do rozdzielania pól używana jest pojedyncza spacja. - Ustaw wartość
--allow_jagged_rows, aby uwzględnić wiersze z mniejszą liczbą kolumn i zignorować błędy podczas wczytywania pliku CSV. - Ustaw wartość
--quote "", aby wskazać, że ciągi tekstowe nie są ujęte w cudzysłów. - Ustaw wartość
--max_bad_records 3, aby zignorować maksymalnie 3 błędy podczas analizowania pliku CSV.
Więcej informacji o wierszu poleceń bq znajdziesz w dokumentacji.
5. Wyświetlanie podglądu zbioru danych
W konsoli BigQuery otwórz jedną z tabel, które zostały właśnie wczytane.
- Rozwiń projekt.
- Rozwiń zbiór danych.
- Wybierz tabelę.

Schemat tabeli możesz wyświetlić na karcie Schemat. 4. Aby sprawdzić, ile danych zawiera tabela, otwórz kartę Szczegóły:
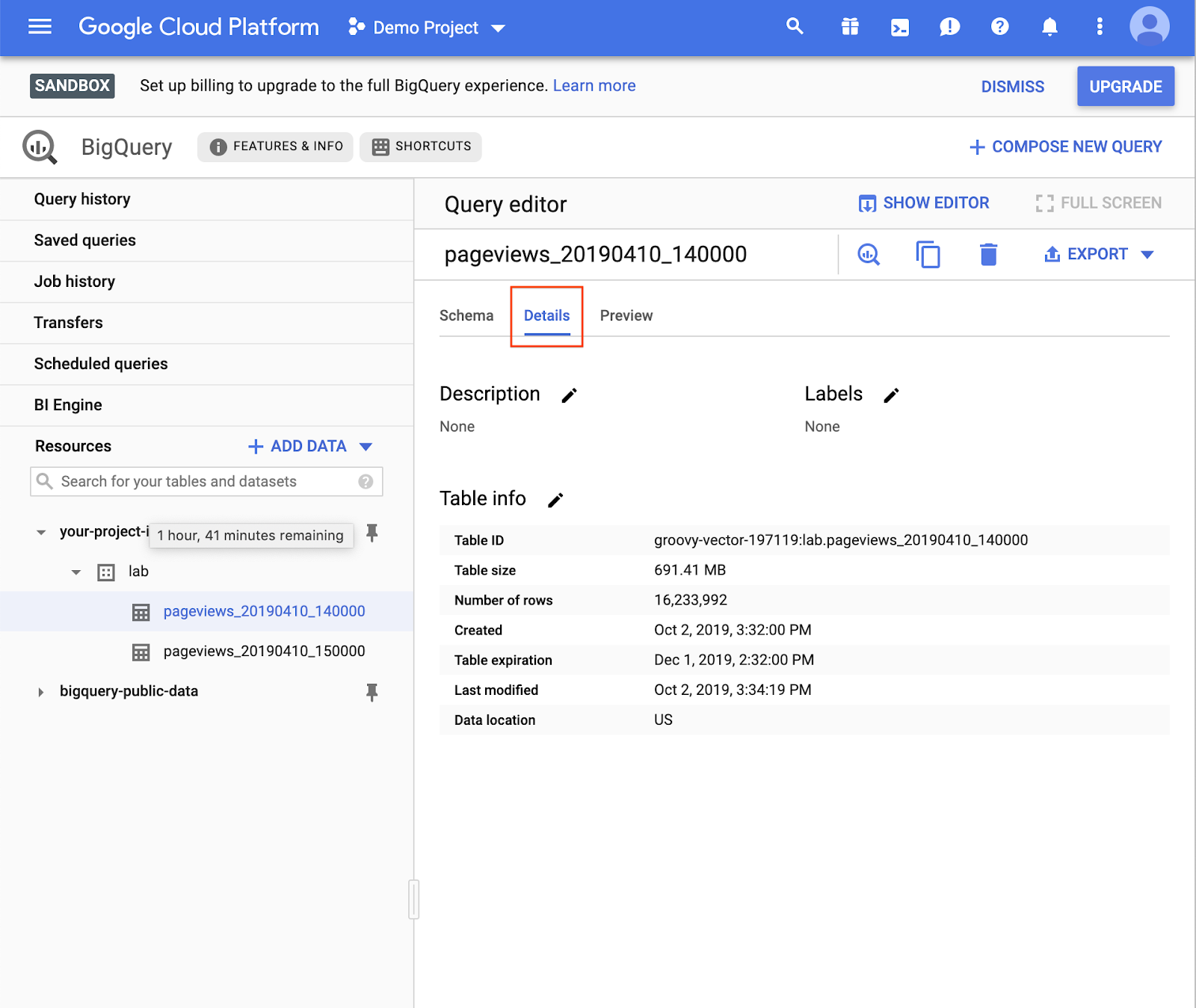
- Otwórz kartę Podgląd, aby wyświetlić wybrane wiersze z tabeli.

6. Tworzenie zapytania
- Kliknij Utwórz nowe zapytanie:

Otworzy się edytor zapytań:
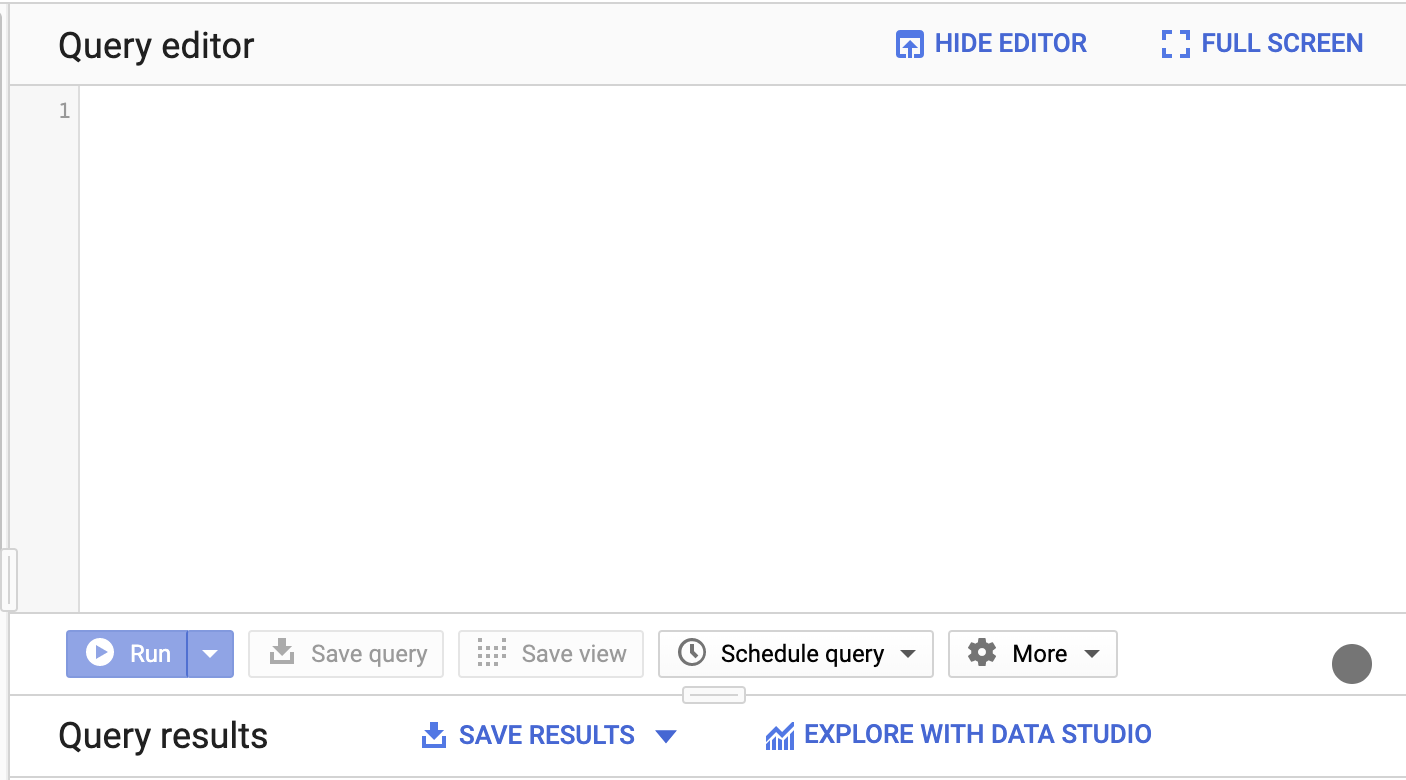
- Aby znaleźć łączną liczbę wyświetleń w Wikipedii między 14:00 a 15:00 10 kwietnia 2019 roku, wpisz to zapytanie:
SELECT SUM(requests) FROM `lab.pageviews_20190410_140000`
- Kliknij Uruchom:
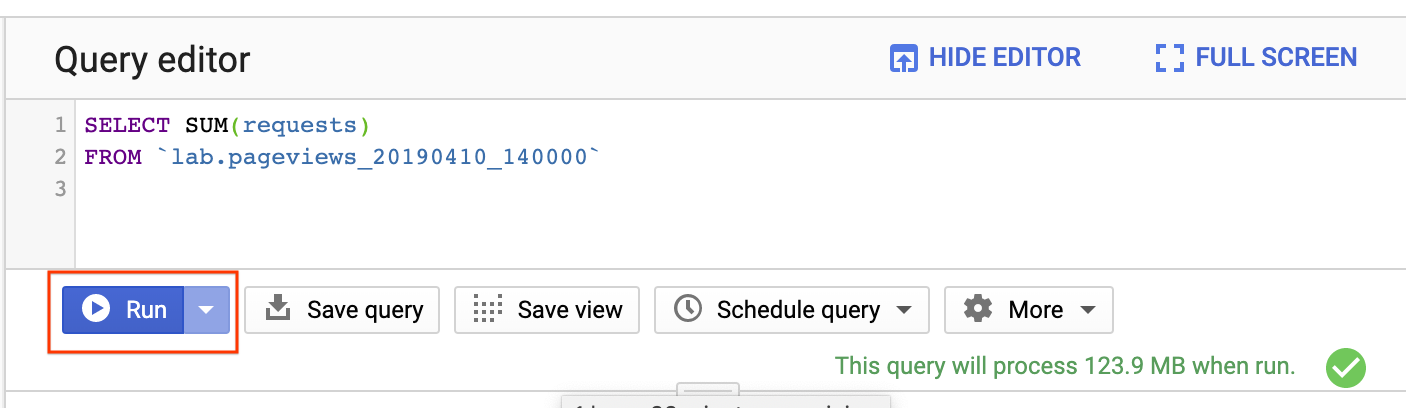
Po kilku sekundach wynik pojawi się u dołu. Zobaczysz też, ile danych zostało przetworzonych:

To zapytanie przetworzyło 123,9 MB, mimo że tabela ma 691,4 MB. BigQuery przetwarza tylko bajty z kolumn używanych w zapytaniu, więc łączna ilość przetworzonych danych może być znacznie mniejsza niż rozmiar tabeli. Dzięki klastrowaniu i partycjonowaniu ilość przetwarzanych danych można jeszcze bardziej zmniejszyć.
7. Bardziej zaawansowane zapytania
Sprawdzanie wyświetleń stron w Wikipedii
Zbiór danych Wikimedia zawiera wyświetlenia stron wszystkich projektów Wikimedia (w tym Wikipedii, Wikisłownika, Wikibooks i Wikicytatów). Ogranicz zapytanie do stron Wikipedii w języku angielskim, dodając instrukcję WHERE:
SELECT SUM(requests), wiki FROM `lab.pageviews_20190410_140000` WHERE wiki = "en" GROUP BY wiki

Zwróć uwagę, że w wyniku zapytania o dodatkową kolumnę wiki ilość przetworzonych danych wzrosła ze 124 MB do 204 MB.
BigQuery obsługuje wiele znanych klauzul SQL, takich jak CONTAINS, GROUP BY, ORDER BY i szereg funkcji agregacji. Możesz też używać wyrażeń regularnych do wysyłania zapytań dotyczących pól tekstowych. Wypróbuj jedną z tych opcji:
SELECT title, SUM(requests) requests FROM `lab.pageviews_20190410_140000` WHERE wiki = "en" AND REGEXP_CONTAINS(title, 'Red.*t') GROUP BY title ORDER BY requests DESC
Wysyłanie zapytań do wielu tabel
Możesz wybrać zakres tabel, aby utworzyć sumę zbiorów, używając tabeli według symboli wieloznacznych.
- Najpierw utwórz drugą tabelę, w której będziesz wykonywać zapytania, wczytując do niej wyświetlenia strony z następnej godziny:
bq load \
--source_format CSV \
--field_delimiter " " \
--quote "" \
$GOOGLE_CLOUD_PROJECT:lab.pageviews_20190410_150000 \
gs://cloud-samples-data/third-party/wikimedia/pageviews/pageviews-20190410-150000.gz \
wiki,title,requests:integer,zero:integer
- W edytorze zapytań utwórz zapytanie dotyczące obu załadowanych tabel, używając prefiksu „
pageviews_2019”:
SELECT title, SUM(requests) requests FROM `lab.pageviews_2019*` WHERE wiki = "en" AND REGEXP_CONTAINS(title, 'Red.*t') GROUP BY title ORDER BY requests DESC
Możesz bardziej selektywnie filtrować tabele za pomocą pseudokolumny _TABLE_SUFFIX. To zapytanie ogranicza się do tabel odpowiadających 10 kwietnia.
SELECT title, SUM(requests) requests FROM `lab.pageviews_2019*` WHERE _TABLE_SUFFIX BETWEEN '0410' AND '0410_9999999' AND wiki = "en" AND REGEXP_CONTAINS(title, 'Red.*t') GROUP BY title ORDER BY requests DESC
8. Czyszczę dane
Opcjonalnie możesz usunąć zbiór danych utworzony za pomocą polecenia bq rm. Aby usunąć wszystkie tabele, które zawiera, użyj flagi -r.
bq rm -r lab
9. Gratulacje!
Udało Ci się utworzyć zapytanie do rzeczywistego zbioru danych o wyświetleniach stron Wikipedii przy użyciu BigQuery i SQL. Możesz teraz wysyłać zapytania do zbiorów danych o rozmiarze petabajtów.
Więcej informacji
- Sprawdź subreddit BigQuery, aby dowiedzieć się, jak inni użytkownicy korzystają obecnie z BigQuery.
- Znajdź publiczne zbiory danych dostępne w BigQuery.
- Dowiedz się, jak wczytywać dane do BigQuery.