
1. Introduzione

Workflows è un servizio di orchestrazione completamente gestito che esegue servizi Google Cloud o esterni nell'ordine che definisci.
BigQuery è un data warehouse aziendale completamente gestito che ti aiuta a gestire e analizzare terabyte di dati con funzionalità integrate come machine learning, analisi geospaziale e business intelligence.
In questo codelab, eseguirai alcune query BigQuery sul set di dati pubblico di Wikipedia. Vedrai poi come eseguire più query BigQuery una dopo l'altra in modo seriale, nell'ambito di un'orchestrazione di Workflows. Infine, parallelizzerai le query utilizzando la funzionalità di iterazione parallela di Workflows per un miglioramento della velocità fino a 5 volte.
Obiettivi didattici
- Come eseguire query BigQuery sul set di dati di Wikipedia.
- Come eseguire più query in sequenza nell'ambito di un'orchestrazione di Workflows.
- Come parallelizzare le query utilizzando l'iterazione parallela di Workflows per un miglioramento della velocità fino a 5 volte.
2. Configurazione e requisiti
Configurazione dell'ambiente autonomo
- Accedi alla console Google Cloud e crea un nuovo progetto o riutilizzane uno esistente. Se non hai ancora un account Gmail o Google Workspace, devi crearne uno.

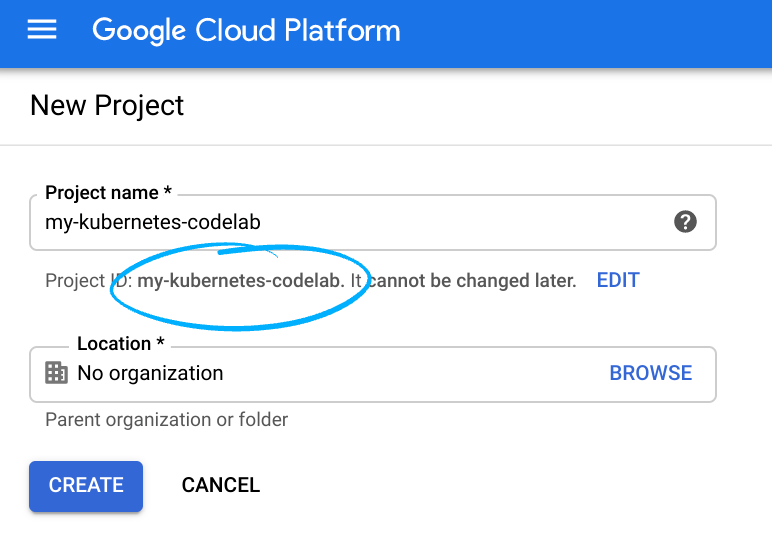
- Il nome del progetto è il nome visualizzato per i partecipanti a questo progetto. È una stringa di caratteri non utilizzata dalle API di Google. Puoi aggiornarlo in qualsiasi momento.
- L'ID progetto deve essere univoco in tutti i progetti Google Cloud ed è immutabile (non può essere modificato dopo essere stato impostato). La console Cloud genera automaticamente una stringa univoca, di solito non ti interessa di cosa si tratta. Nella maggior parte dei codelab, devi fare riferimento all'ID progetto (in genere è identificato come
PROJECT_ID). Se non ti piace l'ID generato, puoi generarne un altro casuale. In alternativa, puoi provare a crearne uno e vedere se è disponibile. Non può essere modificato dopo questo passaggio e rimarrà per tutta la durata del progetto. - Per tua informazione, esiste un terzo valore, un numero di progetto, utilizzato da alcune API. Scopri di più su tutti e tre questi valori nella documentazione.
- Successivamente, devi abilitare la fatturazione in Cloud Console per utilizzare le risorse/API Cloud. L'esecuzione di questo codelab non dovrebbe costare molto, se non nulla. Per arrestare le risorse in modo da non incorrere in costi di fatturazione al termine di questo tutorial, puoi eliminare le risorse che hai creato o l'intero progetto. I nuovi utenti di Google Cloud possono beneficiare del programma prova senza costi di 300$.
Avvia Cloud Shell
Sebbene Google Cloud possa essere gestito da remoto dal tuo laptop, in questo codelab utilizzerai Google Cloud Shell, un ambiente a riga di comando in esecuzione nel cloud.
Nella console Google Cloud, fai clic sull'icona di Cloud Shell nella barra degli strumenti in alto a destra:

Bastano pochi istanti per eseguire il provisioning e connettersi all'ambiente. Al termine, dovresti vedere un risultato simile a questo:

Questa macchina virtuale è caricata con tutti gli strumenti per sviluppatori di cui avrai bisogno. Offre una home directory permanente da 5 GB e viene eseguita su Google Cloud, migliorando notevolmente le prestazioni e l'autenticazione della rete. Tutto il lavoro in questo codelab può essere svolto all'interno di un browser. Non devi installare nulla.
3. Esplorare il set di dati di Wikipedia
Innanzitutto, esplora il set di dati di Wikipedia in BigQuery.
Vai alla sezione BigQuery della console Google Cloud:
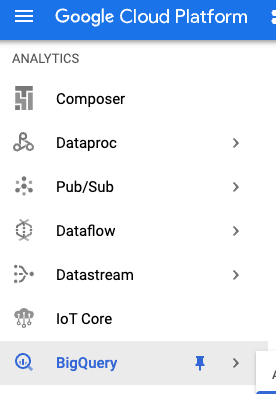
In bigquery-samples, dovresti visualizzare vari set di dati pubblici, tra cui alcuni set di dati correlati a Wikipedia:
Nel set di dati wikipedia_pageviews, puoi vedere varie tabelle per le visualizzazioni di pagina di anni diversi:
Puoi selezionare una delle tabelle (ad es. 201207) e visualizza l'anteprima dei dati:
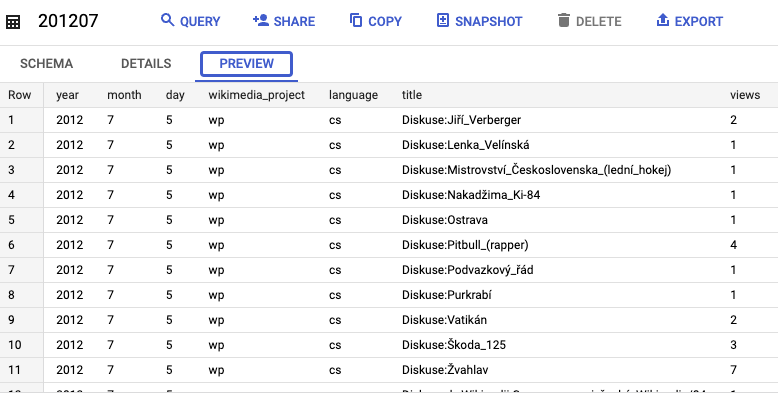
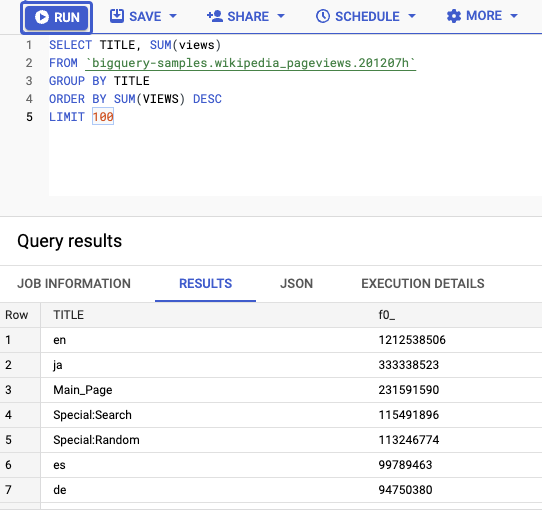
Puoi anche eseguire query sulla tabella. Ad esempio, questa query seleziona i primi 100 titoli con il maggior numero di visualizzazioni:
SELECT TITLE, SUM(views) FROM bigquery-samples.wikipedia_pageviews.201207h GROUP BY TITLE ORDER BY SUM(VIEWS) DESC LIMIT 100
Una volta eseguita la query, il caricamento dei dati richiede circa 20 secondi:
4. Definisci un flusso di lavoro per eseguire più query
Eseguire una query su una singola tabella è semplice. Tuttavia, l'esecuzione di più query su più tabelle e la raccolta dei risultati può diventare piuttosto noiosa. Per aiutarti, Workflows può utilizzare la sintassi di iterazione.
All'interno di Cloud Shell, crea un file workflow-serial.yaml per creare un flusso di lavoro per eseguire più query su più tabelle:
touch workflow-serial.yaml
A questo punto puoi modificare il file con l'editor in Cloud Shell:

All'interno del file workflow-serial.yaml, nel primo passaggio init, crea una mappa results per tenere traccia di ogni iterazione in base ai nomi delle tabelle. Definisci anche un array tables con l'elenco delle tabelle su cui vuoi eseguire le query. In questo caso, scegliamo 5 tabelle:
main:
steps:
- init:
assign:
- results : {}
- tables:
- 201201h
- 201202h
- 201203h
- 201204h
- 201205h
Poi, definisci un passaggio runQueries. Questo passaggio scorre ogni tabella e utilizza il connettore BigQuery di Workflows per eseguire una query per trovare i 100 titoli con il maggior numero di visualizzazioni di pagina in ogni tabella. Salva quindi il titolo e le visualizzazioni principali di ogni tabella nella mappa dei risultati:
- runQueries:
for:
value: table
in: ${tables}
steps:
- runQuery:
call: googleapis.bigquery.v2.jobs.query
args:
projectId: ${sys.get_env("GOOGLE_CLOUD_PROJECT_ID")}
body:
useLegacySql: false
useQueryCache: false
timeoutMs: 30000
# Find the top 100 titles with most views on Wikipedia
query: ${
"SELECT TITLE, SUM(views)
FROM `bigquery-samples.wikipedia_pageviews." + table + "`
WHERE LENGTH(TITLE) > 10
GROUP BY TITLE
ORDER BY SUM(VIEWS) DESC
LIMIT 100"
}
result: queryResult
- returnResult:
assign:
# Return the top title from each table
- results[table]: {}
- results[table].title: ${queryResult.rows[0].f[0].v}
- results[table].views: ${queryResult.rows[0].f[1].v}
Nell'ultimo passaggio, restituisci la mappa results:
- returnResults:
return: ${results}
5. Esegui più query con Workflows
Prima di poter eseguire il deployment e l'esecuzione del flusso di lavoro, devi assicurarti che l'API Workflows sia abilitata. Puoi attivarlo dalla console Google Cloud o utilizzando gcloud in Cloud Shell:
gcloud services enable workflows.googleapis.com
Crea un service account per Workflows:
SERVICE_ACCOUNT=workflows-bigquery-sa gcloud iam service-accounts create $SERVICE_ACCOUNT \ --display-name="Workflows BigQuery service account"
Assicurati che il service account disponga dei ruoli per registrare ed eseguire i job BigQuery:
PROJECT_ID=your-project-id gcloud projects add-iam-policy-binding $PROJECT_ID \ --role roles/logging.logWriter \ --role roles/bigquery.jobUser \ --member serviceAccount:$SERVICE_ACCOUNT@$PROJECT_ID.iam.gserviceaccount.com
Esegui il deployment del flusso di lavoro con il service account:
gcloud workflows deploy bigquery-serial \
--source=workflow-serial.yaml \
--service-account=$SERVICE_ACCOUNT@$PROJECT_ID.iam.gserviceaccount.com
Infine, puoi eseguire il workflow.
Trova il flusso di lavoro bigquery-serial nella sezione Workflows di Cloud Console e premi il pulsante Execute:
In alternativa, puoi eseguire il flusso di lavoro con gcloud in Cloud Shell:
gcloud workflows run bigquery-serial
Dovresti vedere l'esecuzione del flusso di lavoro durare circa 1 minuto (20 secondi per ciascuna delle 5 tabelle).
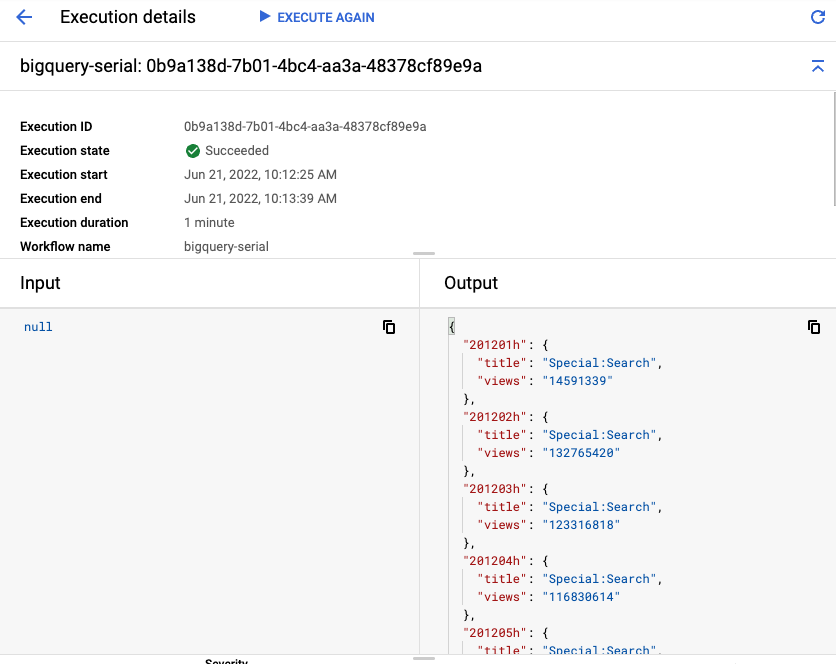
Alla fine, vedrai l'output di ogni tabella con i titoli e le visualizzazioni più popolari:
6. Parallelizzare più query con passaggi paralleli
Il flusso di lavoro del passaggio precedente ha richiesto circa 1 minuto perché sono state eseguite 5 query che hanno richiesto 20 secondi ciascuna. Poiché si tratta di query indipendenti, puoi eseguirle in parallelo utilizzando la funzionalità di iterazione parallela di Workflows.
Copia il file workflow-serial.yaml in un nuovo file workflow-parallel.yaml. Nel nuovo file, apporterai alcune modifiche per trasformare i passaggi seriali in passaggi paralleli.
Nel file workflow-parallel.yaml, modifica il passaggio runQueries. Innanzitutto, aggiungi la parola chiave parallel. In questo modo, ogni iterazione del ciclo for viene eseguita in parallelo. In secondo luogo, dichiara la variabile results come variabile shared. In questo modo, la variabile può essere scritta da un ramo. A questa variabile verrà aggiunto ogni risultato.
- runQueries:
parallel:
shared: [results]
for:
value: table
in: ${tables}
Esegui il deployment del workflow parallelo:
gcloud workflows deploy bigquery-parallel \
--source=workflow-parallel.yaml \
--service-account=$SERVICE_ACCOUNT@$PROJECT_ID.iam.gserviceaccount.com
Esegui il workflow:
gcloud workflows run bigquery-parallel
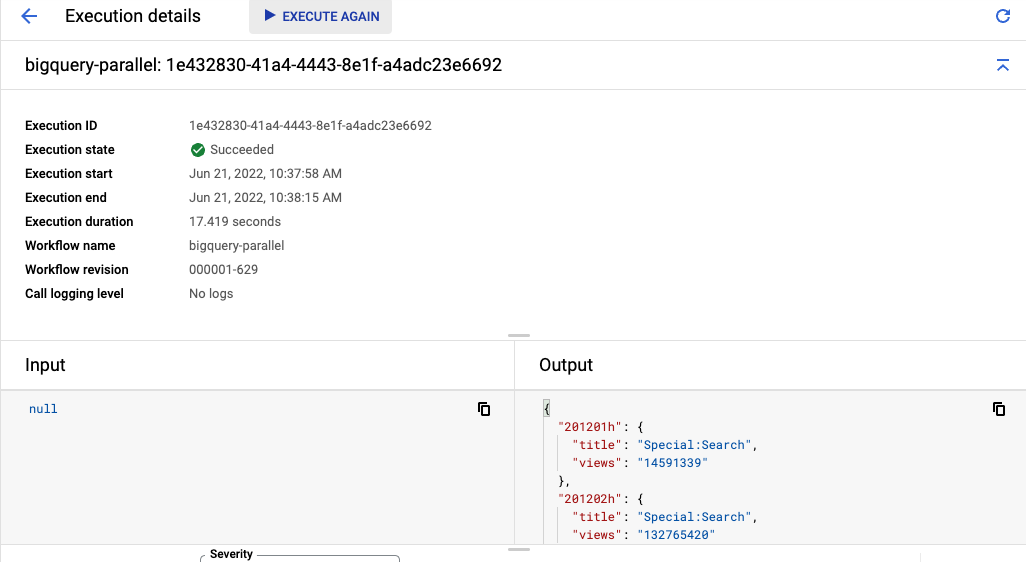
Dovresti vedere l'esecuzione del workflow durare circa 20 secondi. Ciò è dovuto all'esecuzione parallela di tutte e 5 le query. Miglioramento della velocità fino a 5 volte con solo un paio di righe di codice modificate.
Alla fine, vedrai lo stesso output di ogni tabella con i titoli e le visualizzazioni principali, ma con un tempo di esecuzione molto più breve:
7. Complimenti
Congratulazioni, hai completato il codelab. Per scoprire di più, consulta la documentazione di Workflows sui passaggi paralleli.
Argomenti trattati
- Come eseguire query BigQuery sul set di dati di Wikipedia.
- Come eseguire più query in sequenza nell'ambito di un'orchestrazione di Workflows.
- Come parallelizzare le query utilizzando l'iterazione parallela di Workflows per un miglioramento della velocità fino a 5 volte.