
1. Einführung
In diesem Codelab erhalten Sie eine Einführung in die Verwendung von Cloud Bigtable mit dem Java HBase-Client.
Du lernst, wie du
- Häufige Fehler beim Schemadesign vermeiden
- Daten in eine Sequenzdatei importieren
- Daten abfragen
Wenn Sie fertig sind, haben Sie mehrere Karten mit den Busdaten von New York City. Sie erstellen beispielsweise diese Heatmap mit Busfahrten in Manhattan:
Wie würden Sie Ihre Erfahrungen im Umgang mit der Google Cloud Platform bewerten?
<ph type="x-smartling-placeholder">Wie möchten Sie diese Anleitung nutzen?
<ph type="x-smartling-placeholder">2. Über das Dataset
Sie sehen sich ein Dataset zu Bussen in New York City an. Auf diesen Strecken fahren mehr als 300 Buslinien und 5.800 Fahrzeuge. Unser Dataset ist ein Protokoll, das den Zielnamen, die Fahrzeug-ID, den Breitengrad, den Längengrad, die voraussichtliche Ankunftszeit und die geplante Ankunftszeit enthält. Das Dataset besteht aus Snapshots, die für Juni 2017 etwa alle 10 Minuten aufgenommen werden.
3. Schemadesign
Um mit Cloud Bigtable die beste Leistung zu erzielen, müssen Sie beim Entwerfen Ihres Schemas vorsichtig sein. Daten in Cloud Bigtable werden lexikografisch lexikografisch automatisch sortiert. Wenn Sie Ihr Schema also gut entwerfen, ist das Abfragen verwandter Daten sehr effizient. Cloud Bigtable ermöglicht Abfragen mit Punktsuchen nach Zeilenschlüssel oder Zeilenbereichsscans, die eine zusammenhängende Gruppe von Zeilen zurückgeben. Wenn Ihr Schema jedoch nicht gut durchdacht ist, kann es vorkommen, dass Sie Suchvorgänge in mehreren Zeilen zusammensetzen oder sogar vollständige Tabellenscans ausführen, was extrem langsame Vorgänge ist.
Abfragen planen
Unsere Daten enthalten verschiedene Informationen, aber für dieses Codelab verwenden Sie den Standort und das Ziel des Busses.
Mit diesen Informationen können Sie folgende Abfragen durchführen:
- Standort eines einzelnen Busses über eine bestimmte Stunde abrufen.
- Rufen Sie die Daten eines Tages für eine Buslinie oder einen bestimmten Bus ab.
- Alle Busse werden in einem Rechteck auf einer Karte angezeigt.
- Rufen Sie die aktuellen Standorte aller Busse ab (wenn Sie diese Daten in Echtzeit aufgenommen haben).
Diese Gruppe von Abfragen lässt sich nicht alle optimal zusammen ausführen. Wenn Sie beispielsweise nach Zeit sortieren, können Sie nur dann einen Scan basierend auf einem Standort durchführen, wenn Sie einen vollständigen Tabellenscan ausführen. Sie müssen Prioritäten basierend auf den Abfragen festlegen, die Sie am häufigsten ausführen.
In diesem Codelab konzentrieren Sie sich auf die Optimierung und Ausführung der folgenden Abfragen:
- Rufen Sie die Standorte eines bestimmten Fahrzeugs über eine Stunde ab.
- Rufen Sie die Standorte einer kompletten Buslinie über eine Stunde ab.
- Rufen Sie die Standorte aller Busse in Manhattan in einer Stunde ab.
- Hier findest du die letzten Standorte aller Busse in Manhattan in einer Stunde.
- Rufen Sie die Standorte einer gesamten Buslinie im Verlauf eines Monats ab.
- Rufen Sie die Standorte einer vollständigen Buslinie mit einem bestimmten Ziel über eine Stunde ab.
Zeilenschlüssel entwerfen
In diesem Codelab werden Sie mit einem statischen Dataset arbeiten, aber Sie entwerfen ein Schema, um Skalierbarkeit zu gewährleisten. Sie entwerfen ein Schema, mit dem Sie mehr Busdaten in die Tabelle streamen und dennoch eine gute Leistung erzielen können.
Hier ist das vorgeschlagene Schema für den Zeilenschlüssel:
[Busunternehmen/Buslinie/Zeitstempel abgerundet auf die Stunde/Fahrzeug-ID]. Jede Zeile enthält die Daten einer Stunde und jede Zelle enthält mehrere Versionen der Daten mit Zeitstempel.
Zur Vereinfachung verwenden Sie für dieses Codelab eine Spaltenfamilie. Hier ist eine Beispielansicht, wie die Daten aussehen. Die Daten werden nach Zeilenschlüssel sortiert.
Zeilenschlüssel | cf:VehicleLocation.Latitude | cf:VehicleLocation.Longitude | … |
MTA/M86-SBS/1496275200000/NYCT_5824 | 40.781212 @20:52:54.0040.776163 @20:43:19.0040.778714 @20:33:46.00 | -73.961942 @20:52:54.00–73.946949 @20:43:19.00–73.953731 @20:33:46.00 | … |
MTA/M86-SBS/1496275200000/NYCT_5840 | 40.780664 @20:13:51.0040.788416 @20:03:40.00 | -73.958357 @20:13:51.00 -73.976748 @20:03:40.00 | … |
MTA/M86-SBS/1496275200000/NYCT_5867 | 40.780281 @20:51:45.0040.779961 @20:43:15.0040.788416 @20:33:44.00 | -73.946890 @20:51:45.00–73.959465 @20:43:15.00–73.976748 @20:33:44.00 | … |
… | … | … | … |
4. Instanz, Tabelle und Familie erstellen
Als Nächstes erstellen Sie eine Cloud Bigtable-Tabelle.
Erstellen Sie zuerst ein neues Projekt. Verwenden Sie die integrierte Cloud Shell, die Sie durch Klicken auf die Schaltfläche "Cloud Shell aktivieren" oben rechts.
Legen Sie die folgenden Umgebungsvariablen fest, um das Kopieren und Einfügen der Codelab-Befehle zu vereinfachen:
INSTANCE_ID="bus-instance" CLUSTER_ID="bus-cluster" TABLE_ID="bus-data" CLUSTER_NUM_NODES=3 CLUSTER_ZONE="us-central1-c"
Die Tools für dieses Codelab, das gcloud-Befehlszeilentool und die cbt-Befehlszeile sowie Maven sind in Cloud Shell bereits installiert.
Aktivieren Sie die Cloud Bigtable APIs mit diesem Befehl.
gcloud services enable bigtable.googleapis.com bigtableadmin.googleapis.com
Erstellen Sie mit dem folgenden Befehl eine Instanz:
gcloud bigtable instances create $INSTANCE_ID \
--cluster=$CLUSTER_ID \
--cluster-zone=$CLUSTER_ZONE \
--cluster-num-nodes=$CLUSTER_NUM_NODES \
--display-name=$INSTANCE_ID
Nachdem Sie die Instanz erstellt haben, füllen Sie die cbt-Konfigurationsdatei aus und erstellen dann eine Tabelle und eine Spaltenfamilie, indem Sie die folgenden Befehle ausführen:
echo project = $GOOGLE_CLOUD_PROJECT > ~/.cbtrc echo instance = $INSTANCE_ID >> ~/.cbtrc cbt createtable $TABLE_ID cbt createfamily $TABLE_ID cf
5. Daten importieren
Importieren Sie eine Reihe von Sequenzdateien für dieses Codelab mit den folgenden Schritten aus gs://cloud-bigtable-public-datasets/bus-data:
Aktivieren Sie die Cloud Dataflow API mit diesem Befehl.
gcloud services enable dataflow.googleapis.com
Führen Sie die folgenden Befehle aus, um die Tabelle zu importieren.
NUM_WORKERS=$(expr 3 \* $CLUSTER_NUM_NODES) gcloud beta dataflow jobs run import-bus-data-$(date +%s) \ --gcs-location gs://dataflow-templates/latest/GCS_SequenceFile_to_Cloud_Bigtable \ --num-workers=$NUM_WORKERS --max-workers=$NUM_WORKERS \ --parameters bigtableProject=$GOOGLE_CLOUD_PROJECT,bigtableInstanceId=$INSTANCE_ID,bigtableTableId=$TABLE_ID,sourcePattern=gs://cloud-bigtable-public-datasets/bus-data/*
Import überwachen
Sie können den Job in der Cloud Dataflow-UI überwachen. Sie können sich auch die Auslastung Ihrer Cloud Bigtable-Instanz mithilfe der zugehörigen Monitoring-UI ansehen. Der gesamte Import dauert etwa 5 Minuten.
6. Code abrufen
git clone https://github.com/googlecodelabs/cbt-intro-java.git cd cbt-intro-java
Wechseln Sie zu Java 11, indem Sie die folgenden Befehle ausführen:
sudo update-java-alternatives -s java-1.11.0-openjdk-amd64 && export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64/
7. Suche durchführen
Die erste Abfrage, die Sie durchführen, ist eine einfache Zeilensuche. Sie erhalten die Daten für einen Bus der Linie M86-SBS am 1. Juni 2017 von 00:00 bis 1:00 Uhr. Dann fährt ein Fahrzeug mit der ID NYCT_5824 auf der Buslinie.
Mit diesen Informationen und wenn Sie das Schemadesign kennen (Busunternehmen/Buslinie/Zeitstempel abgerundet auf die Stunde/Fahrzeug-ID), können Sie daraus ableiten, dass der Zeilenschlüssel wie folgt lautet:
MTA/M86-SBS/1496275200000/NYCT_5824
BusQueries.java
private static final byte[] COLUMN_FAMILY_NAME = Bytes.toBytes("cf");
private static final byte[] LAT_COLUMN_NAME = Bytes.toBytes("VehicleLocation.Latitude");
private static final byte[] LONG_COLUMN_NAME = Bytes.toBytes("VehicleLocation.Longitude");
String rowKey = "MTA/M86-SBS/1496275200000/NYCT_5824";
Result getResult =
table.get(
new Get(Bytes.toBytes(rowKey))
.addColumn(COLUMN_FAMILY_NAME, LAT_COLUMN_NAME)
.addColumn(COLUMN_FAMILY_NAME, LONG_COLUMN_NAME));
Das Ergebnis sollte den letzten Standort des Busses innerhalb dieser Stunde enthalten. Sie möchten jedoch alle Speicherorte sehen. Legen Sie daher die maximale Anzahl von Versionen in der get-Anfrage fest.
BusQueries.java
Result getResult =
table.get(
new Get(Bytes.toBytes(rowKey))
.setMaxVersions(Integer.MAX_VALUE)
.addColumn(COLUMN_FAMILY_NAME, LAT_COLUMN_NAME)
.addColumn(COLUMN_FAMILY_NAME, LONG_COLUMN_NAME));
Führen Sie in Cloud Shell den folgenden Befehl aus, um eine Liste der Breiten- und Längengrade für diesen Bus über eine Stunde abzurufen:
mvn package exec:java -Dbigtable.projectID=$GOOGLE_CLOUD_PROJECT \ -Dbigtable.instanceID=$INSTANCE_ID -Dbigtable.table=$TABLE_ID \ -Dquery=lookupVehicleInGivenHour
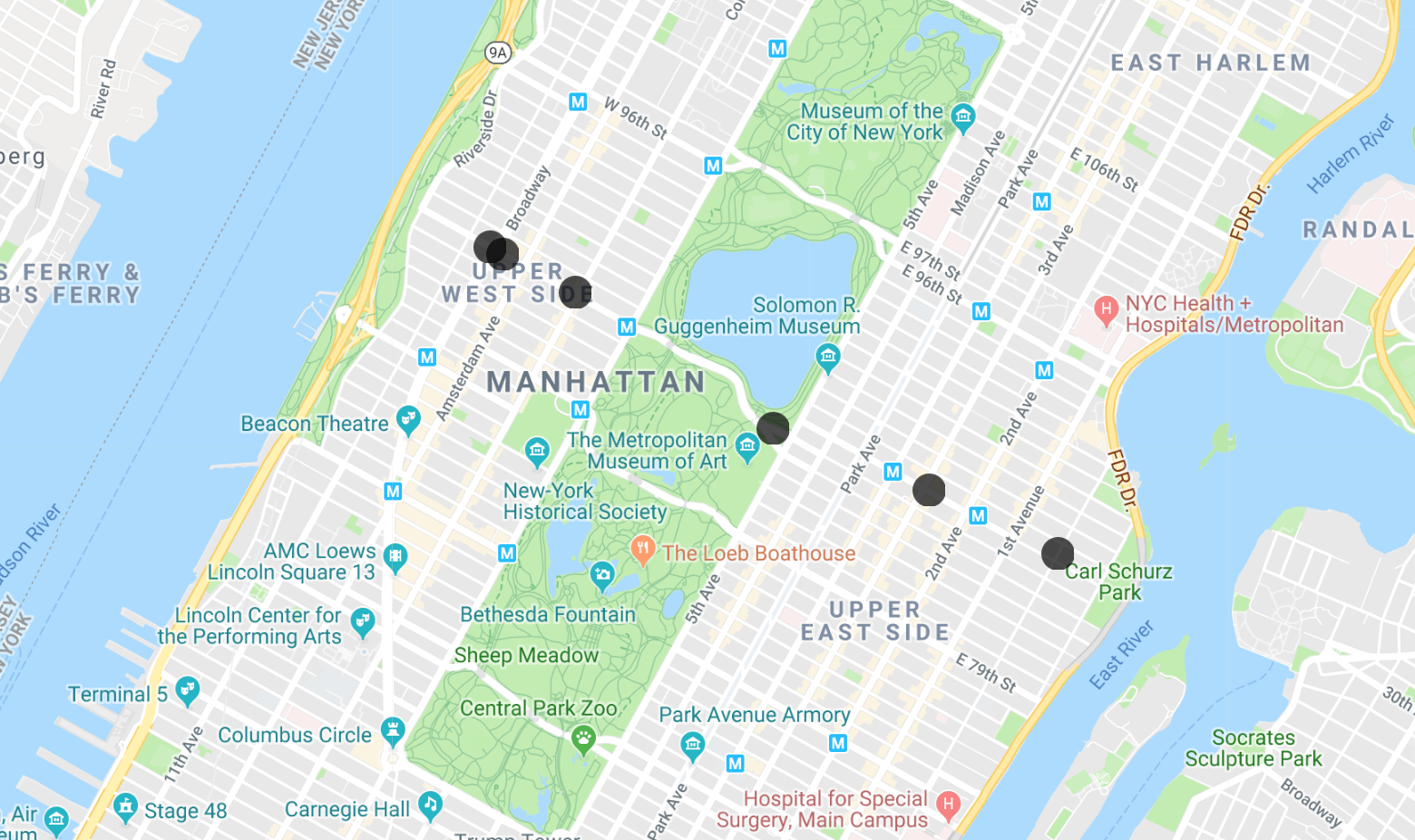
Sie können die Längen- und Breitengrade kopieren und in die MapMaker App einfügen, um die Ergebnisse zu visualisieren. Nach einigen Ebenen werden Sie aufgefordert, ein kostenloses Konto zu erstellen. Sie können ein Konto erstellen oder einfach Ihre vorhandenen Ebenen löschen. Dieses Codelab enthält für jeden Schritt eine Visualisierung, wenn Sie nur dem Ablauf folgen möchten. Hier ist das Ergebnis für diese erste Abfrage:
8. Scan durchführen
Sehen wir uns nun alle Daten für die Buslinie für diese Stunde an. Der Scan-Code sieht dem get-Code ziemlich ähnlich. Sie geben dem Scanner eine Startposition und geben dann an, dass nur Zeilen für die Buslinie M86-SBS innerhalb der Stunde mit dem Zeitstempel 1496275200000 angezeigt werden sollen.
BusQueries.java
Scan scan;
scan = new Scan();
scan.setMaxVersions(Integer.MAX_VALUE)
.addColumn(COLUMN_FAMILY_NAME, LAT_COLUMN_NAME)
.addColumn(COLUMN_FAMILY_NAME, LONG_COLUMN_NAME)
.withStartRow(Bytes.toBytes("MTA/M86-SBS/1496275200000"))
.setRowPrefixFilter(Bytes.toBytes("MTA/M86-SBS/1496275200000"));
ResultScanner scanner = table.getScanner(scan);
Führen Sie den folgenden Befehl aus, um die Ergebnisse abzurufen.
mvn package exec:java -Dbigtable.projectID=$GOOGLE_CLOUD_PROJECT \ -Dbigtable.instanceID=$INSTANCE_ID -Dbigtable.table=$TABLE_ID \ -Dquery=scanBusLineInGivenHour
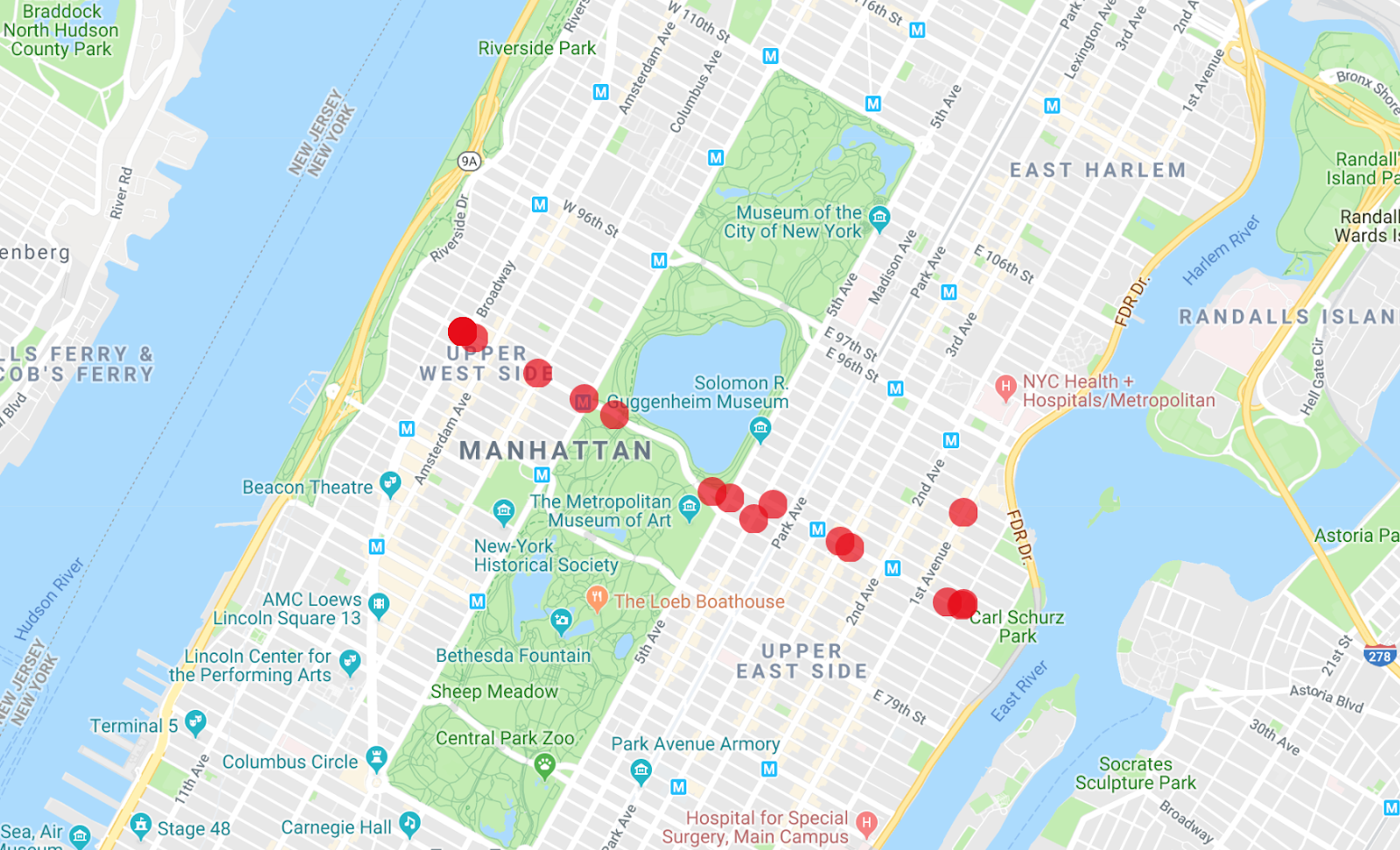
In der Map Maker App können mehrere Listen gleichzeitig angezeigt werden, sodass Sie sehen können, welche Busse das Fahrzeug aus der ersten Abfrage sind, die Sie ausgeführt haben.
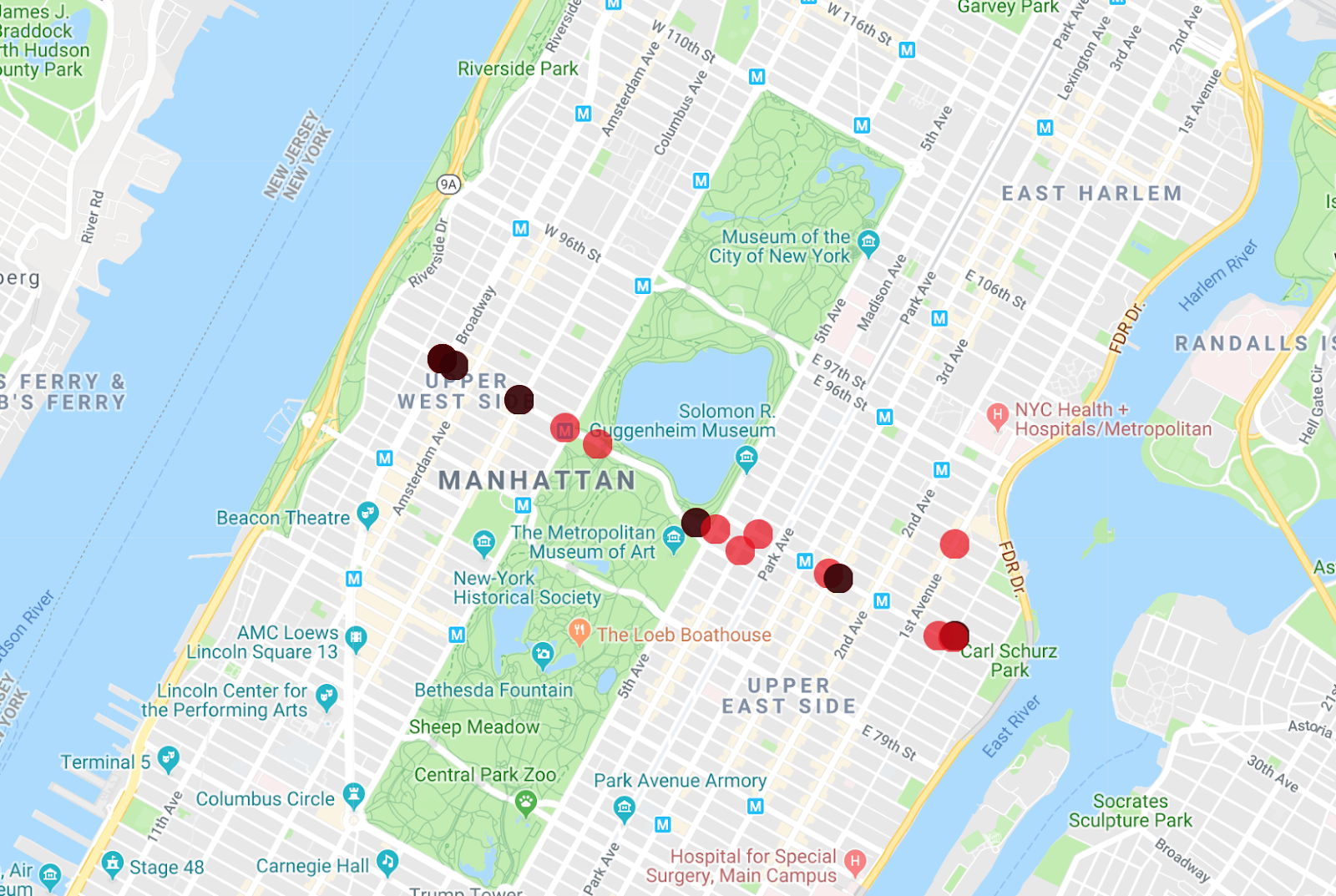
Eine interessante Änderung an dieser Abfrage besteht darin, die Daten des gesamten Monats für die Buslinie M86-SBS anzuzeigen, und dies ist sehr einfach. Entfernen Sie den Zeitstempel aus der Startzeile und dem Präfixfilter, um das Ergebnis zu erhalten.
BusQueries.java
scan.withStartRow(Bytes.toBytes("MTA/M86-SBS/"))
.setRowPrefixFilter(Bytes.toBytes("MTA/M86-SBS/"));
// Optionally, reduce the results to receive one version per column
// since there are so many data points.
scan.setMaxVersions(1);
Führen Sie den folgenden Befehl aus, um die Ergebnisse abzurufen. Die Ergebnisliste ist lang.
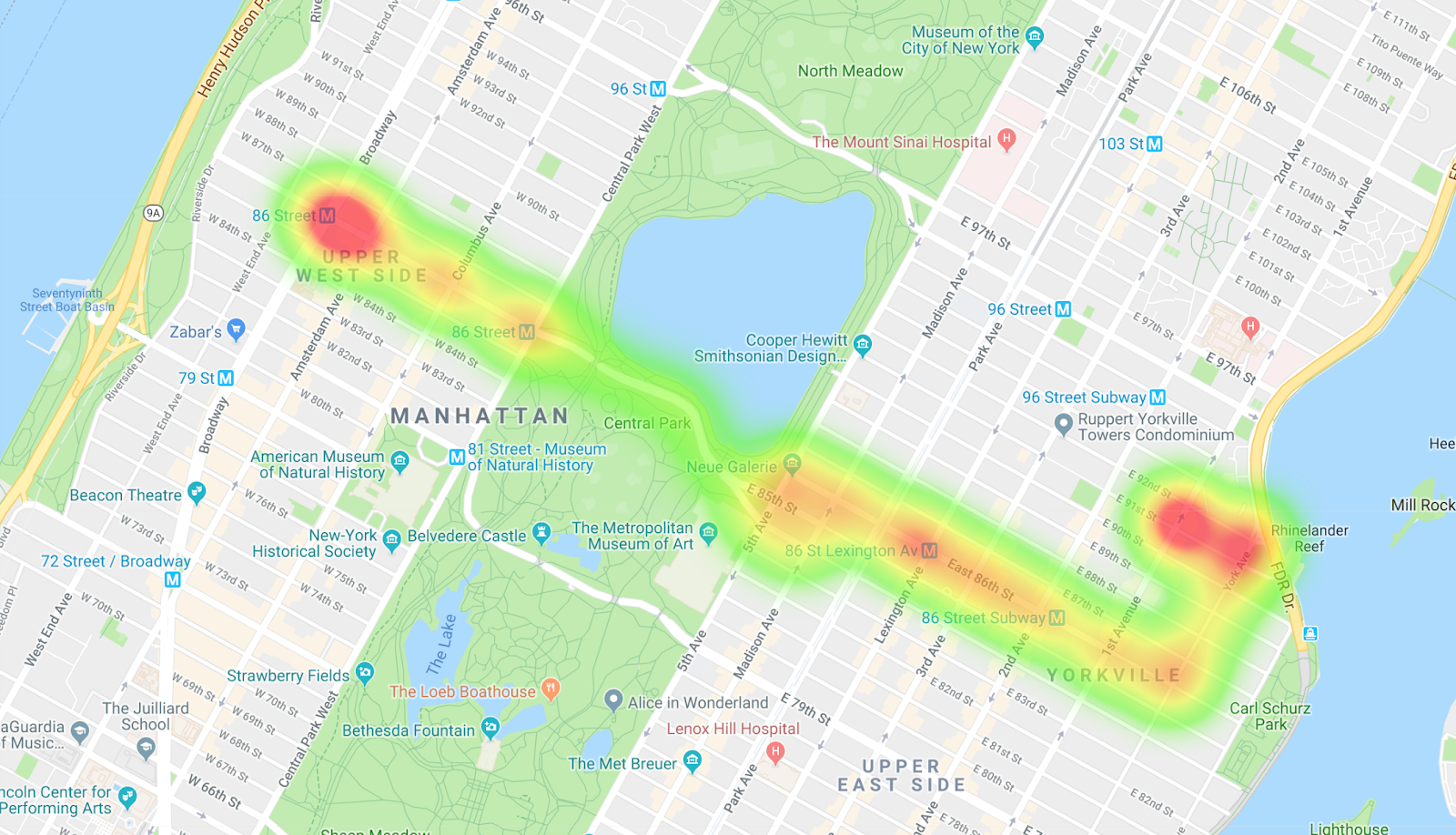
mvn package exec:java -Dbigtable.projectID=$GOOGLE_CLOUD_PROJECT \ -Dbigtable.instanceID=$INSTANCE_ID -Dbigtable.table=$TABLE_ID \ -Dquery=scanEntireBusLine
Wenn Sie die Ergebnisse in MapMaker kopieren, können Sie eine Heatmap der Buslinie aufrufen. Die orangefarbenen Flecken kennzeichnen die Haltestellen und die leuchtend roten Blobs den Anfang und das Ende der Route.
9. Filter einführen
Als Nächstes filtern Sie nach Buslinien nach Osten und nach Westen und erstellen für jeden eine separate Heatmap.
BusQueries.java
Scan scan;
ResultScanner scanner;
scan = new Scan();
SingleColumnValueFilter valueFilter =
new SingleColumnValueFilter(
COLUMN_FAMILY_NAME,
Bytes.toBytes("DestinationName"),
CompareOp.EQUAL,
Bytes.toBytes("Select Bus Service Yorkville East End AV"));
scan.setMaxVersions(1)
.addColumn(COLUMN_FAMILY_NAME, LAT_COLUMN_NAME)
.addColumn(COLUMN_FAMILY_NAME, LONG_COLUMN_NAME);
scan.withStartRow(Bytes.toBytes("MTA/M86-SBS/"))
.setRowPrefixFilter(Bytes.toBytes("MTA/M86-SBS/"));
scan.setFilter(valueFilter);
scanner = table.getScanner(scan);
Führen Sie den folgenden Befehl aus, um die Ergebnisse für Busse in Richtung Osten abzurufen.
mvn package exec:java -Dbigtable.projectID=$GOOGLE_CLOUD_PROJECT \ -Dbigtable.instanceID=$INSTANCE_ID -Dbigtable.table=$TABLE_ID \ -Dquery=filterBusesGoingEast
Um die Busse in Richtung Westen zu fahren, ändern Sie den String in valueFilter:
BusQueries.java
SingleColumnValueFilter valueFilter =
new SingleColumnValueFilter(
COLUMN_FAMILY_NAME,
Bytes.toBytes("DestinationName"),
CompareOp.EQUAL,
Bytes.toBytes("Select Bus Service Westside West End AV"));
Führen Sie den folgenden Befehl aus, um die Ergebnisse für Busse in Richtung Westen abzurufen.
mvn package exec:java -Dbigtable.projectID=$GOOGLE_CLOUD_PROJECT \ -Dbigtable.instanceID=$INSTANCE_ID -Dbigtable.table=$TABLE_ID \ -Dquery=filterBusesGoingWest
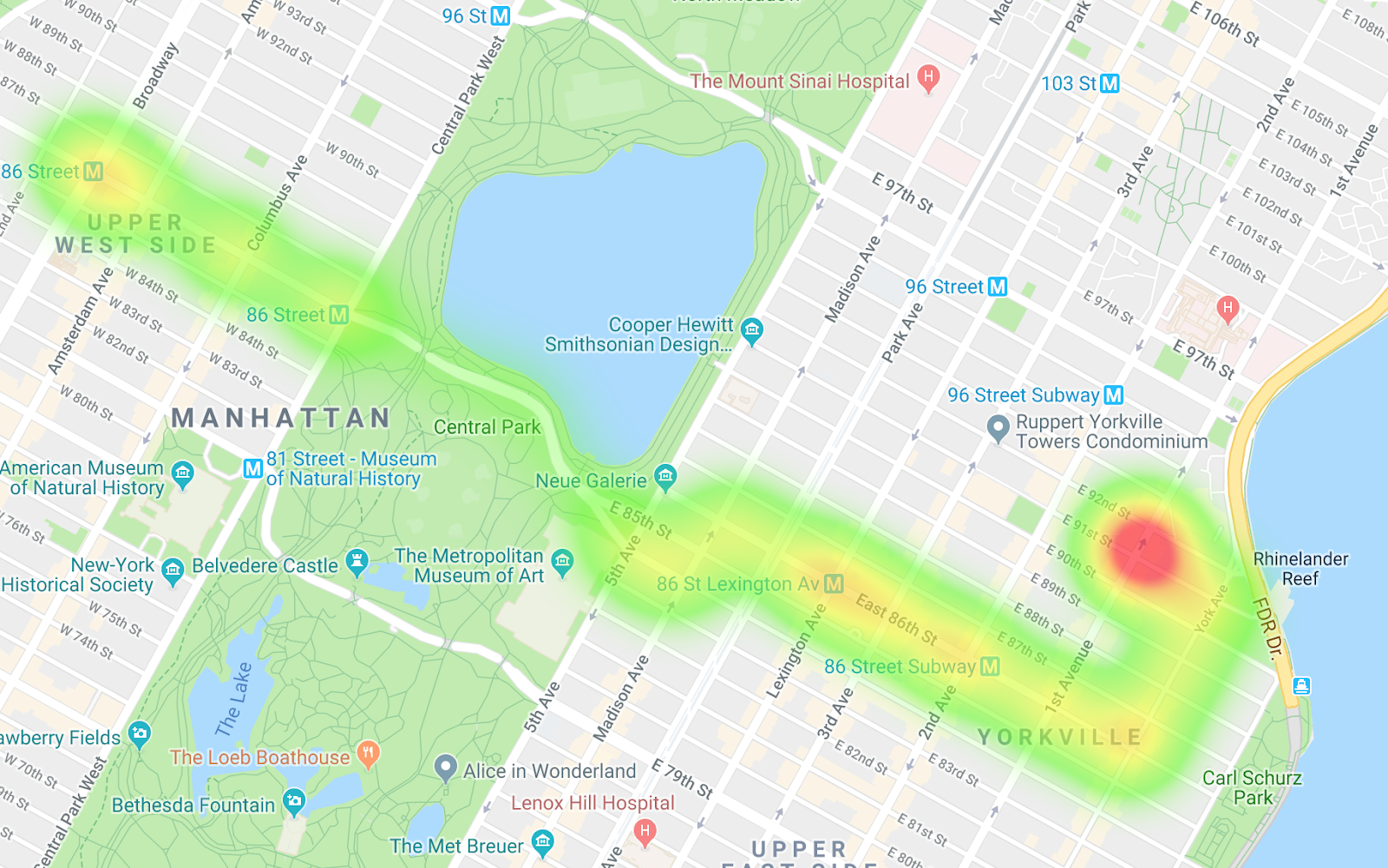
Busse in Richtung Osten
Busse in Richtung Westen
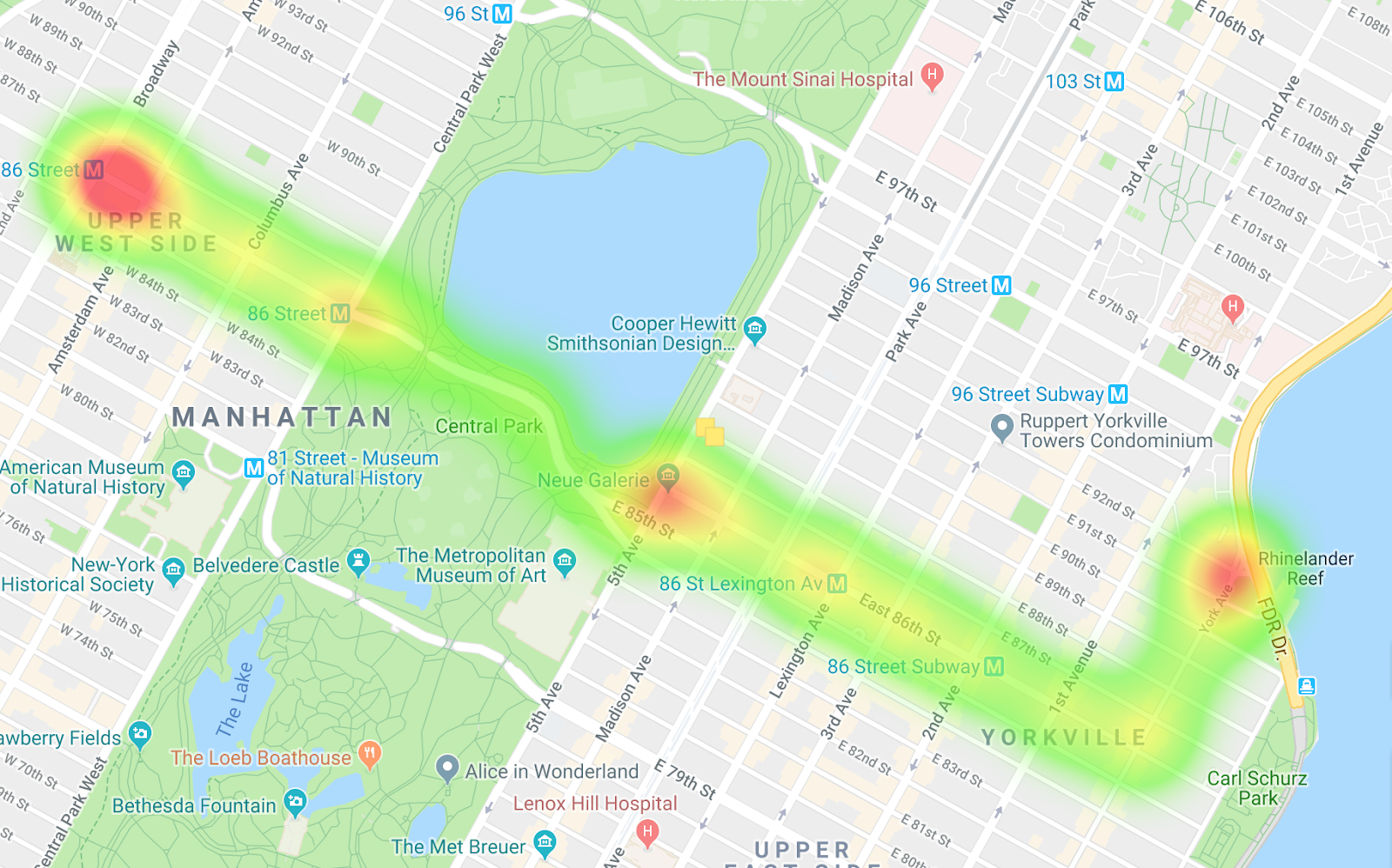
Durch den Vergleich der beiden Heatmaps können Sie die Unterschiede zwischen den Routen und die Unterschiede bei der Taktung erkennen. Eine Interpretation der Daten ist, dass auf der Route in Richtung Westen die Busse häufiger angehalten werden, vor allem, wenn sie in den Central Park einsteigen. In den Bussen in Richtung Osten gibt es nur wenige Engpässe.
10. Mehrbereich-Scan durchführen
Bei der letzten Abfrage widmen Sie sich dem Fall, wenn Ihnen viele Buslinien in einem Gebiet wichtig sind:
BusQueries.java
private static final String[] MANHATTAN_BUS_LINES = {"M1","M2","M3",...
Scan scan;
ResultScanner scanner;
List<RowRange> ranges = new ArrayList<>();
for (String busLine : MANHATTAN_BUS_LINES) {
ranges.add(
new RowRange(
Bytes.toBytes("MTA/" + busLine + "/1496275200000"), true,
Bytes.toBytes("MTA/" + busLine + "/1496275200001"), false));
}
Filter filter = new MultiRowRangeFilter(ranges);
scan = new Scan();
scan.setFilter(filter);
scan.setMaxVersions(Integer.MAX_VALUE)
.addColumn(COLUMN_FAMILY_NAME, LAT_COLUMN_NAME)
.addColumn(COLUMN_FAMILY_NAME, LONG_COLUMN_NAME);
scan.withStartRow(Bytes.toBytes("MTA/M")).setRowPrefixFilter(Bytes.toBytes("MTA/M"));
scanner = table.getScanner(scan);
Führen Sie den folgenden Befehl aus, um die Ergebnisse abzurufen.
mvn package exec:java -Dbigtable.projectID=$GOOGLE_CLOUD_PROJECT \ -Dbigtable.instanceID=$INSTANCE_ID -Dbigtable.table=$TABLE_ID \ -Dquery=scanManhattanBusesInGivenHour
11. Fertigstellen
Bereinigen Sie Ihre Daten, um Gebühren zu vermeiden
Löschen Sie die Instanz, damit Ihrem Google Cloud Platform-Konto die in diesem Codelab verwendeten Ressourcen nicht in Rechnung gestellt werden.
gcloud bigtable instances delete $INSTANCE_ID
Behandelte Themen
- Schemadesign
- Instanz, Tabelle und Familie einrichten
- Sequenzdateien mit Dataflow importieren
- Abfragen mit einer Suche, einem Scan, einem Scan mit einem Filter und einem Mehrbereichsscan
Weiteres Vorgehen
- Weitere Informationen zu Cloud Bigtable finden Sie in der Dokumentation.
- Weitere Google Cloud Platform-Funktionen testen: mit unseren Anleitungen ausprobieren
- Informationen zum Überwachen von Zeitreihendaten mit der OpenTSDB-Integration