
1. Introdução
Neste codelab, você vai aprender a usar o Cloud Bigtable com o cliente Java HBase.
Você aprenderá como realizar as seguintes tarefas:
- Evitar erros comuns com o design de esquemas
- Importar dados em um arquivo de sequência
- Consultar dados
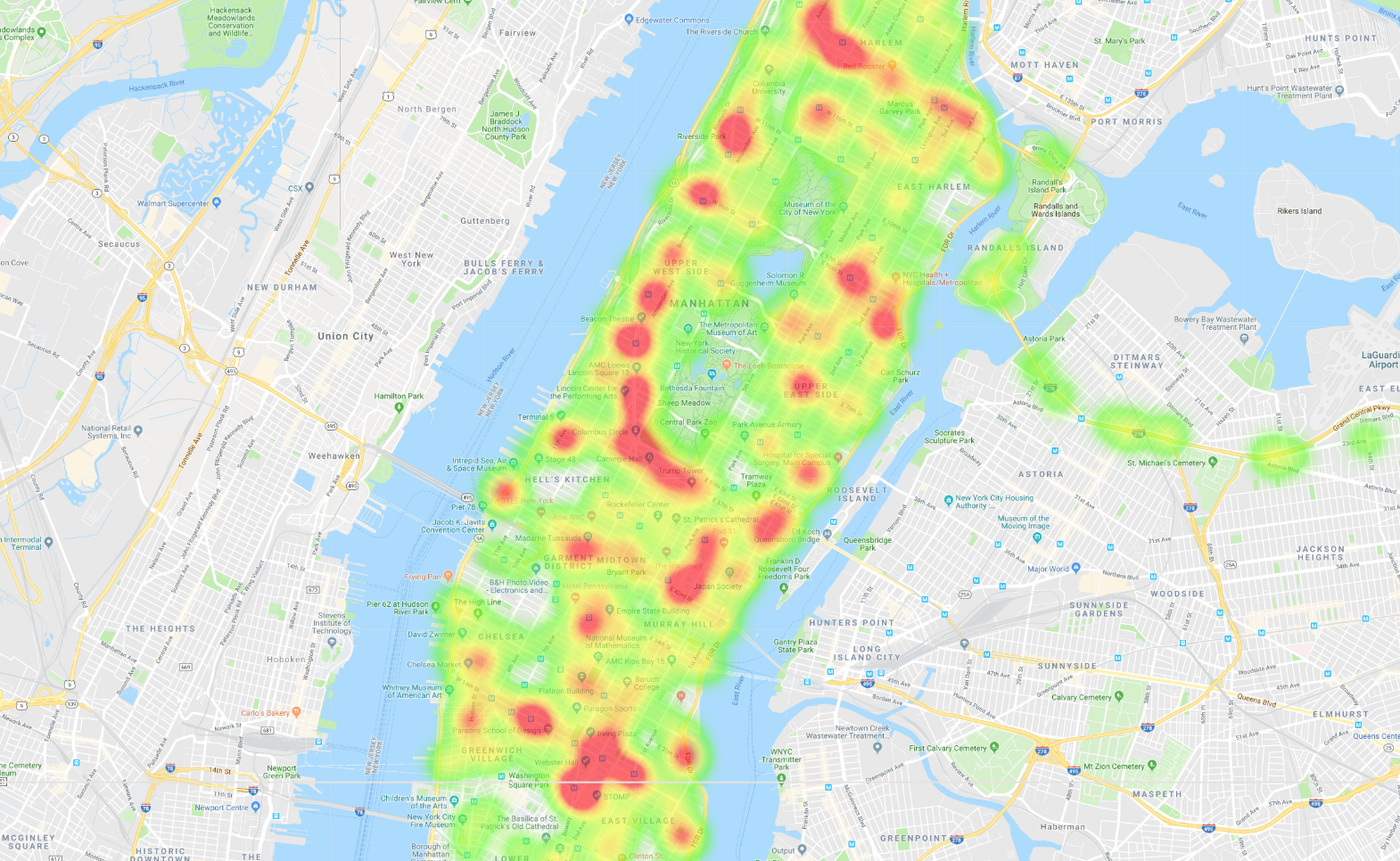
Quando terminar, você terá vários mapas que mostram dados de ônibus da cidade de Nova York. Por exemplo, você criará este mapa de calor de viagens de ônibus em Manhattan:
Como você classificaria sua experiência de uso do Google Cloud Platform?
Como você usará este tutorial?
2. Sobre o conjunto de dados
Você verá um conjunto de dados sobre ônibus da cidade de Nova York. Há mais de 300 trajetos de ônibus e 5.800 veículos seguindo esses trajetos. Nosso conjunto de dados é um registro que inclui nome do destino, ID do veículo, latitude, longitude, horário esperado de chegada e horário programado de chegada. O conjunto de dados é composto por snapshots tirados a cada 10 minutos em junho de 2017.
3. Design de esquema
Para ter o melhor desempenho do Cloud Bigtable, é preciso ter cuidado ao projetar o esquema. Os dados no Cloud Bigtable são classificados automaticamente lexicograficamente. Assim, se você projetar bem o esquema, a consulta de dados relacionados será muito eficiente. O Cloud Bigtable permite consultas usando pesquisas de pontos por chave de linha ou verificações de intervalos de linhas que retornam um conjunto contíguo de linhas. No entanto, se seu esquema não for bem pensado, você pode se encontrar juntando várias pesquisas de linha ou, pior ainda, fazendo verificações completas de tabela, que são operações extremamente lentas.
Planejar as consultas
Nossos dados têm várias informações, mas, neste codelab, você usará o local e o destino do ônibus.
Com essas informações, você poderia realizar estas consultas:
- Veja a localização de um único ônibus em uma determinada hora.
- Receba dados de um dia para uma linha de ônibus ou ônibus específico.
- Encontre todos os ônibus em um retângulo em um mapa.
- Descubra a localização atual de todos os ônibus (se você estiver processando esses dados em tempo real).
Esse conjunto de consultas não pode ser feito de maneira otimizada em conjunto. Por exemplo, se você estiver classificando por horário, não poderá fazer uma verificação com base em um local sem fazer uma verificação completa da tabela. Você precisa priorizar com base nas consultas que executa com mais frequência.
Neste codelab, o foco será otimizar e executar o seguinte conjunto de consultas:
- Confira a localização de um veículo específico ao longo de uma hora.
- Confira a localização de uma linha inteira de ônibus em mais de uma hora.
- Veja a localização de todos os ônibus em Manhattan em uma hora.
- Veja os locais mais recentes de todos os ônibus em Manhattan em uma hora.
- Conferir a localização de uma linha inteira de ônibus ao longo do mês.
- Confira as localizações de uma linha de ônibus inteira com um destino específico ao longo de uma hora.
Projetar a chave de linha
Neste codelab, você trabalhará com um conjunto de dados estático, mas criará um esquema para escalonabilidade. Você criará um esquema para transmitir mais dados de barramento para a tabela, mantendo um bom desempenho.
Este é o esquema proposto para a chave de linha:
[Empresa de ônibus/linha de ônibus/carimbo de data/hora arredondado para baixo para a hora/ID do veículo]. Cada linha tem uma hora de dados, e cada célula contém várias versões dos dados com o carimbo de data/hora.
Neste codelab, você usará um grupo de colunas para simplificar o processo. Este é um exemplo de visualização dos dados. Os dados são classificados por chave de linha.
Chave de linha | cf:VehicleLocation.Latitude (link em inglês) | cf:VehicleLocation.Longitude (link em inglês) | … |
MTA/M86-SBS/1496275200000/NYCT_5824 | 40.781212 @20:52:54.0040.776163 @20:43:19.0040.778714 @20:33:46.00 | -73.961942 @20:52:54.00-73.946949 @20:43:19.00-73.953731 @20:33:46.00 | … |
MTA/M86-SBS/1496275200000/NYCT_5840 | 40,780664 @20:13:51.0040,788416 @20:03:40.00 | -73.958357 @20:13:51.00 -73,976748 @20:03:40.00 | … |
MTA/M86-SBS/1496275200000/NYCT_5867 | 40.780281 @20:51:45.0040.779961 @20:43:15.0040.788416 @20:33:44.00 | -73.946890 @20:51:45.00-73.959465 @20:43:15.00-73.976748 @20:33:44.00 | … |
... | ... | ... | … |
4. Criar instância, tabela e família
Em seguida, você criará uma tabela do Cloud Bigtable.
Primeiro, crie um novo projeto. Use o Cloud Shell integrado, que pode ser aberto clicando no botão "Ativar o Cloud Shell" no canto superior direito.
Defina as variáveis de ambiente abaixo para facilitar a ação de copiar e colar os comandos do codelab:
INSTANCE_ID="bus-instance" CLUSTER_ID="bus-cluster" TABLE_ID="bus-data" CLUSTER_NUM_NODES=3 CLUSTER_ZONE="us-central1-c"
O Cloud Shell vem com as ferramentas que você vai usar neste codelab, a ferramenta de linha de comando gcloud, a interface de linha de comando cbt e o Maven, que já estão instalados.
Execute este comando para ativar as APIs do Cloud Bigtable.
gcloud services enable bigtable.googleapis.com bigtableadmin.googleapis.com
Crie uma instância executando o seguinte comando:
gcloud bigtable instances create $INSTANCE_ID \
--cluster=$CLUSTER_ID \
--cluster-zone=$CLUSTER_ZONE \
--cluster-num-nodes=$CLUSTER_NUM_NODES \
--display-name=$INSTANCE_ID
Após criar a instância, preencha o arquivo de configuração cbt e crie uma tabela e um grupo de colunas executando os seguintes comandos:
echo project = $GOOGLE_CLOUD_PROJECT > ~/.cbtrc echo instance = $INSTANCE_ID >> ~/.cbtrc cbt createtable $TABLE_ID cbt createfamily $TABLE_ID cf
5. Importar dados
Importe um conjunto de arquivos sequenciais do gs://cloud-bigtable-public-datasets/bus-data para este codelab, seguindo estas etapas:
Execute este comando para ativar a API Cloud Dataflow.
gcloud services enable dataflow.googleapis.com
Execute os comandos a seguir para importar a tabela.
NUM_WORKERS=$(expr 3 \* $CLUSTER_NUM_NODES) gcloud beta dataflow jobs run import-bus-data-$(date +%s) \ --gcs-location gs://dataflow-templates/latest/GCS_SequenceFile_to_Cloud_Bigtable \ --num-workers=$NUM_WORKERS --max-workers=$NUM_WORKERS \ --parameters bigtableProject=$GOOGLE_CLOUD_PROJECT,bigtableInstanceId=$INSTANCE_ID,bigtableTableId=$TABLE_ID,sourcePattern=gs://cloud-bigtable-public-datasets/bus-data/*
Monitorar a importação
É possível monitorar o job na IU do Cloud Dataflow. Além disso, é possível visualizar a carga na instância do Cloud Bigtable com a IU de monitoramento. A importação completa leva cinco minutos.
6. Acessar o código
git clone https://github.com/googlecodelabs/cbt-intro-java.git cd cbt-intro-java
Mude para o Java 11 executando os seguintes comandos:
sudo update-java-alternatives -s java-1.11.0-openjdk-amd64 && export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64/
7. Realizar uma pesquisa
A primeira consulta que você vai realizar é uma pesquisa de linha simples. Você receberá os dados de um ônibus da linha M86-SBS no dia 1o de junho de 2017, da 0h à 1h. Um veículo com o ID NYCT_5824 está na linha de ônibus.
Com essas informações e conhecendo o design do esquema (empresa de ônibus/linha de ônibus/carimbo de data/hora arredondado para a hora/ID do veículo), você pode deduzir que a chave de linha é:
MTA/M86-SBS/1496275200000/NYCT_5824
BusQueries.java
private static final byte[] COLUMN_FAMILY_NAME = Bytes.toBytes("cf");
private static final byte[] LAT_COLUMN_NAME = Bytes.toBytes("VehicleLocation.Latitude");
private static final byte[] LONG_COLUMN_NAME = Bytes.toBytes("VehicleLocation.Longitude");
String rowKey = "MTA/M86-SBS/1496275200000/NYCT_5824";
Result getResult =
table.get(
new Get(Bytes.toBytes(rowKey))
.addColumn(COLUMN_FAMILY_NAME, LAT_COLUMN_NAME)
.addColumn(COLUMN_FAMILY_NAME, LONG_COLUMN_NAME));
O resultado deve conter a localização mais recente do ônibus dentro desse horário. No entanto, você quer ver todos os locais. Portanto, defina o número máximo de versões na solicitação GET.
BusQueries.java
Result getResult =
table.get(
new Get(Bytes.toBytes(rowKey))
.setMaxVersions(Integer.MAX_VALUE)
.addColumn(COLUMN_FAMILY_NAME, LAT_COLUMN_NAME)
.addColumn(COLUMN_FAMILY_NAME, LONG_COLUMN_NAME));
No Cloud Shell, execute o seguinte comando para ver uma lista de latitudes e longitudes do ônibus em questão ao longo da hora:
mvn package exec:java -Dbigtable.projectID=$GOOGLE_CLOUD_PROJECT \ -Dbigtable.instanceID=$INSTANCE_ID -Dbigtable.table=$TABLE_ID \ -Dquery=lookupVehicleInGivenHour
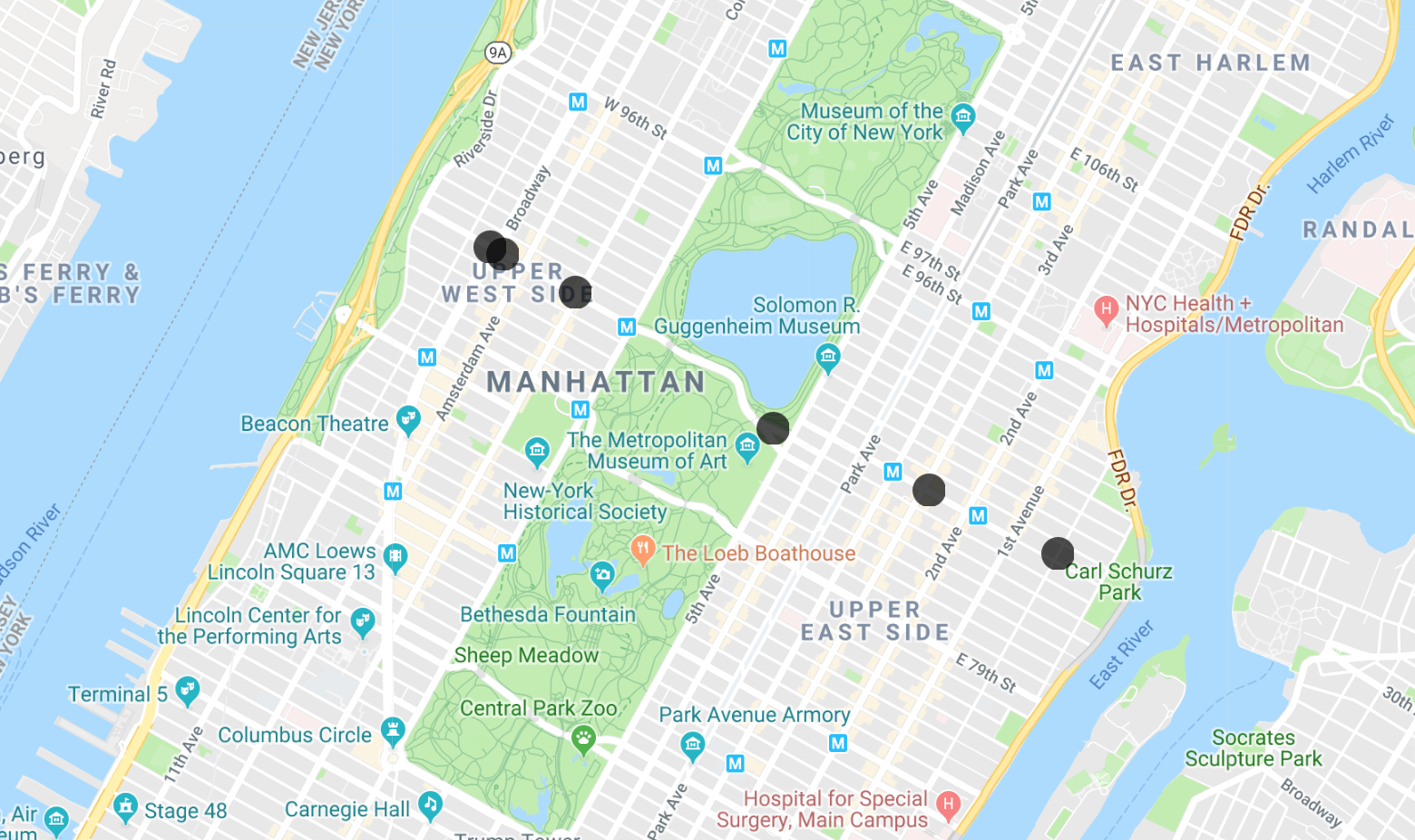
Você pode copiar e colar as latitudes e longitudes no app MapMaker para visualizar os resultados. Após algumas camadas, você receberá uma solicitação para criar uma conta sem custo financeiro. Você pode criar uma conta ou simplesmente excluir as camadas existentes. Este codelab inclui uma visualização de cada etapa, se você quiser apenas acompanhar. Aqui está o resultado para a primeira consulta:
8. Fazer uma verificação
Agora, vamos ver todos os dados da linha de ônibus referente a esse horário. O código de verificação é bastante semelhante ao código get. Você dá ao scanner uma posição inicial e depois indica que quer apenas linhas para a linha de ônibus M86-SBS dentro da hora indicada pelo carimbo de data/hora 1496275200000.
BusQueries.java
Scan scan;
scan = new Scan();
scan.setMaxVersions(Integer.MAX_VALUE)
.addColumn(COLUMN_FAMILY_NAME, LAT_COLUMN_NAME)
.addColumn(COLUMN_FAMILY_NAME, LONG_COLUMN_NAME)
.withStartRow(Bytes.toBytes("MTA/M86-SBS/1496275200000"))
.setRowPrefixFilter(Bytes.toBytes("MTA/M86-SBS/1496275200000"));
ResultScanner scanner = table.getScanner(scan);
Execute o comando a seguir para receber os resultados.
mvn package exec:java -Dbigtable.projectID=$GOOGLE_CLOUD_PROJECT \ -Dbigtable.instanceID=$INSTANCE_ID -Dbigtable.table=$TABLE_ID \ -Dquery=scanBusLineInGivenHour
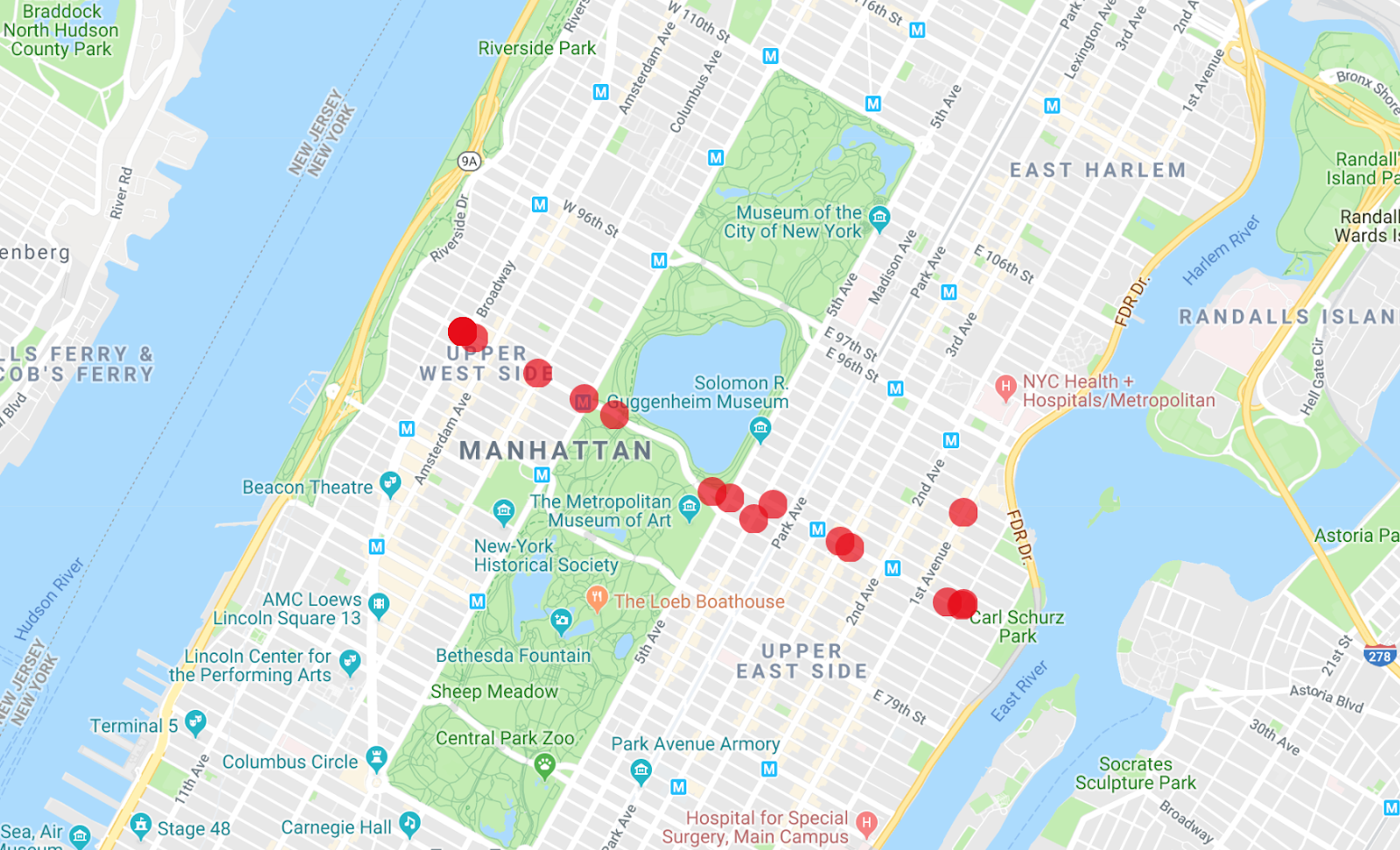
O aplicativo Map Maker pode exibir várias listas de uma só vez. Assim, você pode ver quais dos ônibus são o veículo da primeira consulta executada.
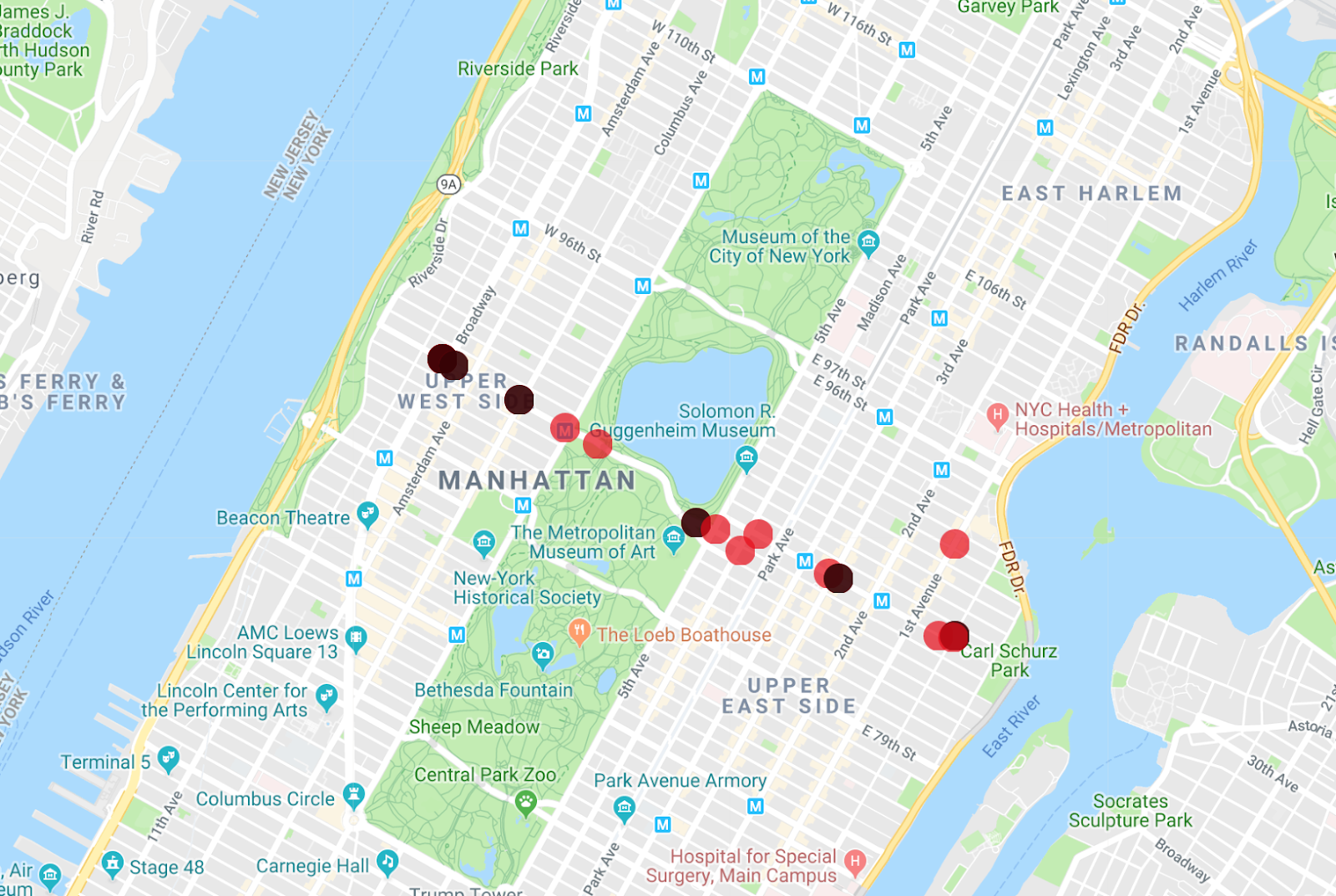
Uma modificação interessante nessa consulta é visualizar o mês inteiro de dados da linha de ônibus M86-SBS, e isso é muito fácil de fazer. Remova o carimbo de data/hora da linha inicial e o filtro de prefixo para conferir o resultado.
BusQueries.java
scan.withStartRow(Bytes.toBytes("MTA/M86-SBS/"))
.setRowPrefixFilter(Bytes.toBytes("MTA/M86-SBS/"));
// Optionally, reduce the results to receive one version per column
// since there are so many data points.
scan.setMaxVersions(1);
Execute o comando a seguir para receber os resultados. (Haverá uma longa lista de resultados.)
mvn package exec:java -Dbigtable.projectID=$GOOGLE_CLOUD_PROJECT \ -Dbigtable.instanceID=$INSTANCE_ID -Dbigtable.table=$TABLE_ID \ -Dquery=scanEntireBusLine
Se você copiar os resultados para o MapMaker, poderá ver um mapa de calor do trajeto de ônibus. Os pontos laranjas indicam as paradas e os vermelhos representam o início e o fim do trajeto.
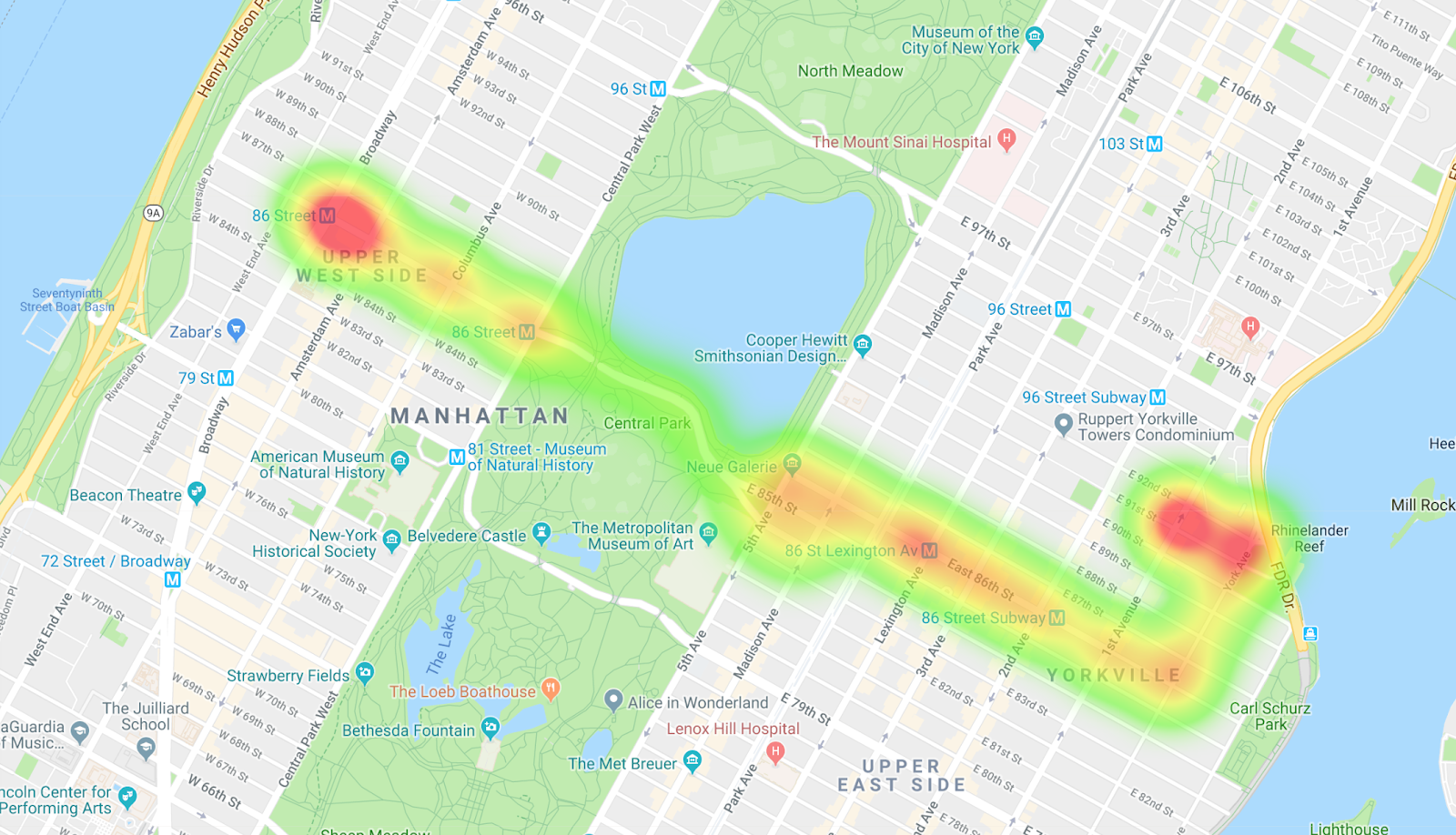
9. Implementar filtros
Em seguida, você vai filtrar os ônibus na direção leste e na direção oeste e criar um mapa de calor separado para cada um deles.
BusQueries.java
Scan scan;
ResultScanner scanner;
scan = new Scan();
SingleColumnValueFilter valueFilter =
new SingleColumnValueFilter(
COLUMN_FAMILY_NAME,
Bytes.toBytes("DestinationName"),
CompareOp.EQUAL,
Bytes.toBytes("Select Bus Service Yorkville East End AV"));
scan.setMaxVersions(1)
.addColumn(COLUMN_FAMILY_NAME, LAT_COLUMN_NAME)
.addColumn(COLUMN_FAMILY_NAME, LONG_COLUMN_NAME);
scan.withStartRow(Bytes.toBytes("MTA/M86-SBS/"))
.setRowPrefixFilter(Bytes.toBytes("MTA/M86-SBS/"));
scan.setFilter(valueFilter);
scanner = table.getScanner(scan);
Execute o comando a seguir para receber os resultados de ônibus na direção leste.
mvn package exec:java -Dbigtable.projectID=$GOOGLE_CLOUD_PROJECT \ -Dbigtable.instanceID=$INSTANCE_ID -Dbigtable.table=$TABLE_ID \ -Dquery=filterBusesGoingEast
Para que os ônibus sigam na direção oeste, altere a string em valueFilter:
BusQueries.java
SingleColumnValueFilter valueFilter =
new SingleColumnValueFilter(
COLUMN_FAMILY_NAME,
Bytes.toBytes("DestinationName"),
CompareOp.EQUAL,
Bytes.toBytes("Select Bus Service Westside West End AV"));
Execute o comando a seguir para receber os resultados de ônibus indo na direção oeste.
mvn package exec:java -Dbigtable.projectID=$GOOGLE_CLOUD_PROJECT \ -Dbigtable.instanceID=$INSTANCE_ID -Dbigtable.table=$TABLE_ID \ -Dquery=filterBusesGoingWest
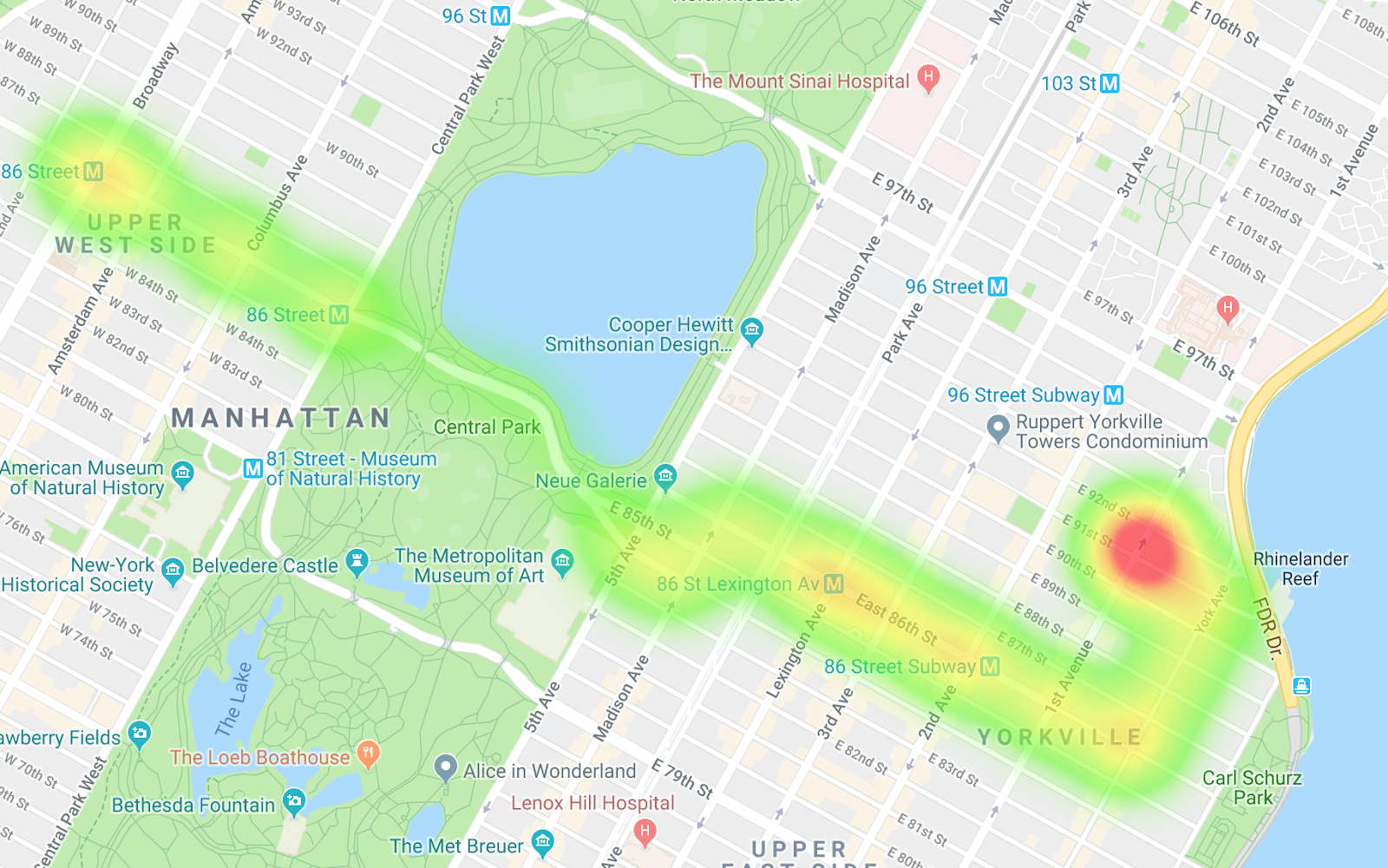
Ônibus indo para o leste
Ônibus indo na direção oeste
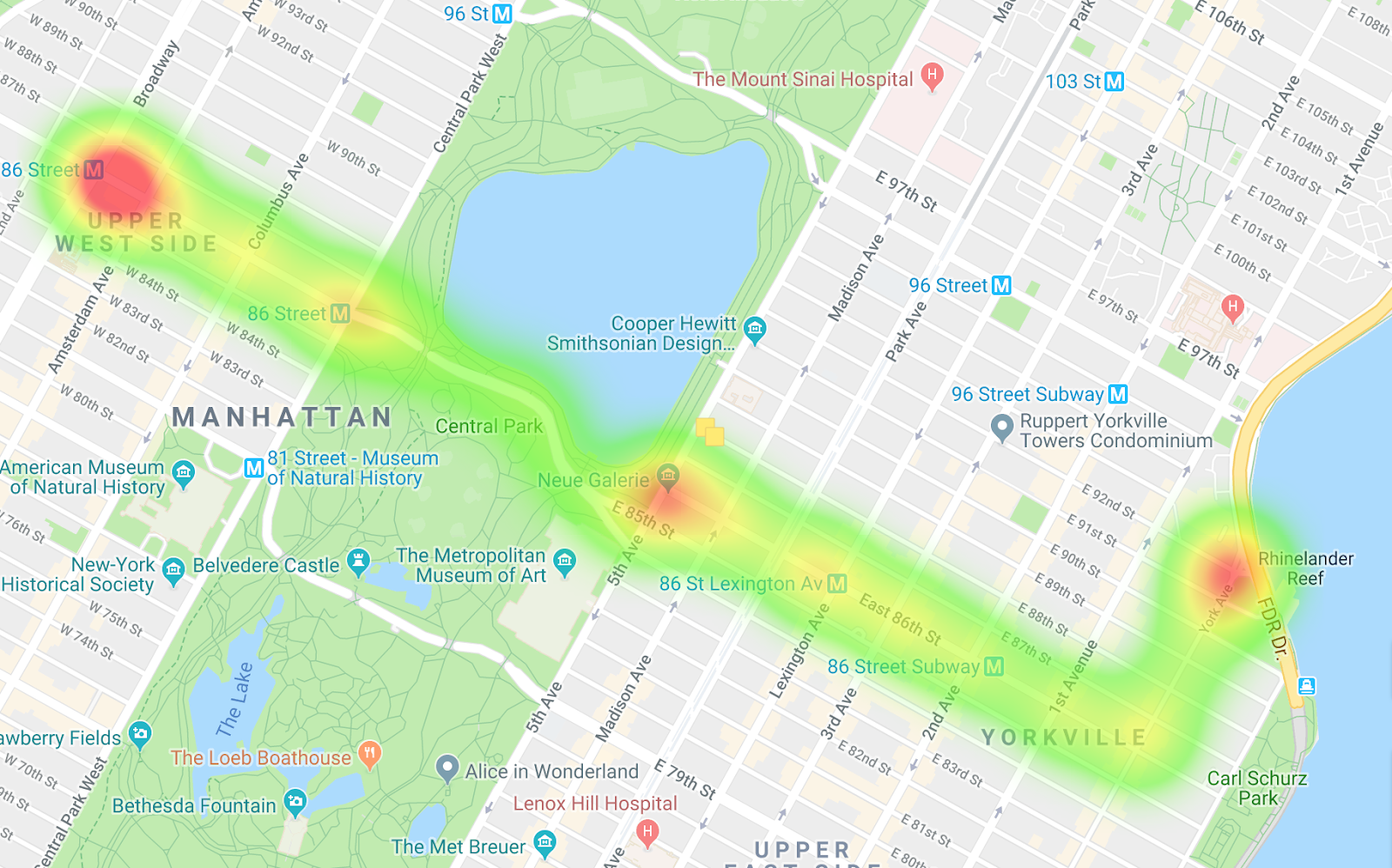
Ao comparar os dois mapas de calor, você pode ver as diferenças nos trajetos e no ritmo. Uma interpretação dos dados é que, no trajeto na direção oeste, os ônibus estão ficando mais parados, especialmente ao entrar no Central Park. Nos ônibus indo para o leste, não há muitos pontos de estrangulamento.
10. Executar uma verificação de vários intervalos
Na consulta final, você vai abordar o caso em que há muitas linhas de ônibus em uma área:
BusQueries.java
private static final String[] MANHATTAN_BUS_LINES = {"M1","M2","M3",...
Scan scan;
ResultScanner scanner;
List<RowRange> ranges = new ArrayList<>();
for (String busLine : MANHATTAN_BUS_LINES) {
ranges.add(
new RowRange(
Bytes.toBytes("MTA/" + busLine + "/1496275200000"), true,
Bytes.toBytes("MTA/" + busLine + "/1496275200001"), false));
}
Filter filter = new MultiRowRangeFilter(ranges);
scan = new Scan();
scan.setFilter(filter);
scan.setMaxVersions(Integer.MAX_VALUE)
.addColumn(COLUMN_FAMILY_NAME, LAT_COLUMN_NAME)
.addColumn(COLUMN_FAMILY_NAME, LONG_COLUMN_NAME);
scan.withStartRow(Bytes.toBytes("MTA/M")).setRowPrefixFilter(Bytes.toBytes("MTA/M"));
scanner = table.getScanner(scan);
Execute o comando a seguir para receber os resultados.
mvn package exec:java -Dbigtable.projectID=$GOOGLE_CLOUD_PROJECT \ -Dbigtable.instanceID=$INSTANCE_ID -Dbigtable.table=$TABLE_ID \ -Dquery=scanManhattanBusesInGivenHour
11. Concluir
Fazer uma limpeza para evitar cobranças
Para evitar cobranças na sua conta do Google Cloud Platform pelos recursos usados neste codelab, exclua sua instância.
gcloud bigtable instances delete $INSTANCE_ID
O que vimos
- Design de esquema
- Como configurar uma instância, tabela e família
- Como importar arquivos sequenciais com o Dataflow
- Consultas com uma pesquisa, uma verificação, uma verificação com um filtro e uma verificação de vários intervalos
Próximas etapas
- Saiba mais sobre o Cloud Bigtable na documentação.
- Teste outros recursos do Google Cloud Platform. Confira nossos tutoriais.
- Saiba como monitorar dados de séries temporais com a integração do OpenTSDB.