
1. Introduzione
In questo codelab, imparerai a utilizzare Cloud Bigtable con il client Java HBase.
Imparerai a
- Evita gli errori comuni nella progettazione dello schema
- Importa i dati in un file di sequenza
- Eseguire query sui dati
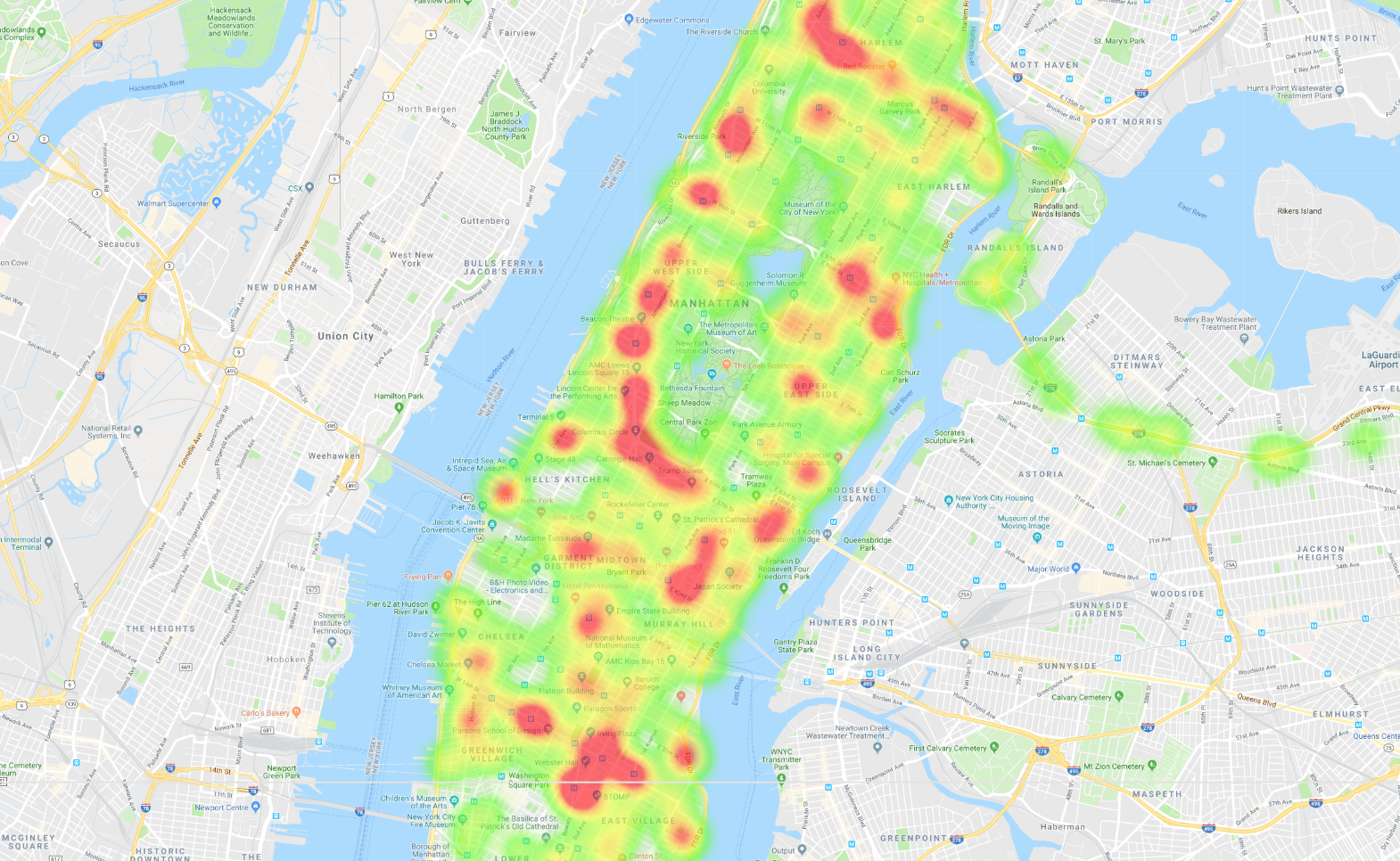
Quando hai finito, avrai a disposizione più mappe in cui vengono visualizzati i dati degli autobus di New York. Ad esempio, creerai questa mappa termica dei viaggi in autobus a Manhattan:
Come giudichi la tua esperienza di utilizzo della piattaforma Google Cloud?
Come utilizzerai questo tutorial?
2. Informazioni sul set di dati
Stai esaminando un set di dati sugli autobus di New York. Ci sono più di 300 linee di autobus e 5.800 veicoli che seguono questi percorsi. Il nostro set di dati è un log che include il nome della destinazione, l'ID del veicolo, la latitudine, la longitudine, l'ora di arrivo prevista e l'ora di arrivo prevista. Il set di dati è composto da snapshot acquisiti ogni 10 minuti circa per giugno 2017.
3. Progettazione di uno schema
Per ottenere le migliori prestazioni da Cloud Bigtable, devi prestare attenzione quando progetti lo schema. I dati in Cloud Bigtable vengono ordinati automaticamente in modo grammaticale, quindi se progetti bene lo schema, l'esecuzione di query sui dati correlati è molto efficiente. Cloud Bigtable consente di eseguire query che utilizzano ricerche per punto per chiave di riga o scansioni di intervalli di righe che restituiscono un insieme contiguo di righe. Tuttavia, se lo schema non è ben strutturato, potresti dover eseguire più ricerche di righe o, peggio ancora, eseguire scansioni complete delle tabelle, operazioni estremamente lente.
Pianificare le query
I nostri dati contengono una serie di informazioni, ma per questo codelab utilizzerai location e destination dell'autobus.
Con queste informazioni, potresti eseguire queste query:
- Visualizza la posizione di un singolo autobus in una determinata ora.
- Ottieni i dati relativi a una giornata di dati per una linea di autobus o un autobus specifico.
- Trova tutti gli autobus in un rettangolo su una mappa.
- Ottieni le posizioni attuali di tutti gli autobus (se stai importando questi dati in tempo reale).
Questo insieme di query non può essere eseguito insieme in modo ottimale. Ad esempio, se ordini i dati in base all'ora, non puoi eseguire una scansione basata su una località senza eseguire una scansione completa della tabella. Devi assegnare la priorità in base alle query che esegui più di frequente.
In questo codelab, ti concentrerai sull'ottimizzazione e sull'esecuzione del seguente insieme di query:
- Ottieni le posizioni di un veicolo specifico in un'ora.
- Ottieni le posizioni di un'intera linea di autobus in un'ora.
- Ottieni le posizioni di tutti gli autobus a Manhattan in un'ora.
- Ottieni le posizioni più recenti di tutti gli autobus a Manhattan in un'ora.
- Visualizza le posizioni di un'intera linea di autobus nel corso del mese.
- Ottieni le posizioni di un'intera linea di autobus con una determinata destinazione in un'ora.
Progettare la chiave di riga
Per questo codelab lavorerai con un set di dati statico, ma progetterai uno schema per la scalabilità. Progetterai uno schema che ti consenta di trasmettere più dati di bus nella tabella senza compromettere il rendimento.
Ecco lo schema proposto per la chiave di riga:
[Azienda di autobus/linea dell'autobus/Timestamp arrotondati per difetto all'ora/ID veicolo]. Ogni riga contiene un'ora di dati e ogni cella contiene più versioni con timestamp dei dati.
Per questo codelab, utilizzerai una famiglia di colonne per semplificare le cose. Ecco un esempio di come si presentano i dati. I dati vengono ordinati per chiave di riga.
Chiave di riga | cf:VehicleLocation.Latitude | cf:VeicoliLocation.Longitude | … |
MTA/M86-SBS/1496275200000/NYCT_5824 | 40.781212 @20:52:54.0040.776163 @20:43:19.0040.778714 @20:33:46.00 | -73.961942 @20:52:54.00-73.946949 @20:43:19.00-73.953731 @20:33:46.00 | … |
MTA/M86-SBS/1496275200000/NYCT_5840 | 40.780664 @20:13:51.0040.788416 @20:03:40.00 | -73.958357 @20:13:51.00 -73.976748 @20:03:40.00 | … |
MTA/M86-SBS/1496275200000/NYCT_5867 | 40.780281 @20:51:45.0040.779961 @20:43:15.0040.788416 @20:33:44.00 | -73.946890 @20:51:45.00-73.959465 @20:43:15.00-73.976748 @20:33:44.00 | … |
… | … | … | … |
4. Crea istanza, tabella e famiglia
Successivamente, creerai una tabella Cloud Bigtable.
Per prima cosa, crea un nuovo progetto. Usa Cloud Shell integrato, che puoi aprire facendo clic su "Attiva Cloud Shell" nell'angolo in alto a destra.
Imposta le seguenti variabili di ambiente per semplificare l'operazione di copia e incolla dei comandi del codelab:
INSTANCE_ID="bus-instance" CLUSTER_ID="bus-cluster" TABLE_ID="bus-data" CLUSTER_NUM_NODES=3 CLUSTER_ZONE="us-central1-c"
Cloud Shell include gli strumenti che utilizzerai in questo codelab, lo strumento a riga di comando gcloud, l'interfaccia a riga di comando cbt e Maven, già installati.
Abilita le API Cloud Bigtable eseguendo questo comando.
gcloud services enable bigtable.googleapis.com bigtableadmin.googleapis.com
Crea un'istanza eseguendo questo comando:
gcloud bigtable instances create $INSTANCE_ID \
--cluster=$CLUSTER_ID \
--cluster-zone=$CLUSTER_ZONE \
--cluster-num-nodes=$CLUSTER_NUM_NODES \
--display-name=$INSTANCE_ID
Dopo aver creato l'istanza, compila il file di configurazione cbt, quindi crea una famiglia di tabelle e colonne eseguendo questi comandi:
echo project = $GOOGLE_CLOUD_PROJECT > ~/.cbtrc echo instance = $INSTANCE_ID >> ~/.cbtrc cbt createtable $TABLE_ID cbt createfamily $TABLE_ID cf
5. Importa dati
Importa un insieme di file di sequenza per questo codelab da gs://cloud-bigtable-public-datasets/bus-data seguendo questi passaggi:
Abilita l'API Cloud Dataflow eseguendo questo comando.
gcloud services enable dataflow.googleapis.com
Esegui questi comandi per importare la tabella.
NUM_WORKERS=$(expr 3 \* $CLUSTER_NUM_NODES) gcloud beta dataflow jobs run import-bus-data-$(date +%s) \ --gcs-location gs://dataflow-templates/latest/GCS_SequenceFile_to_Cloud_Bigtable \ --num-workers=$NUM_WORKERS --max-workers=$NUM_WORKERS \ --parameters bigtableProject=$GOOGLE_CLOUD_PROJECT,bigtableInstanceId=$INSTANCE_ID,bigtableTableId=$TABLE_ID,sourcePattern=gs://cloud-bigtable-public-datasets/bus-data/*
Monitorare l'importazione
Puoi monitorare il job nell'interfaccia utente di Cloud Dataflow. Inoltre, puoi visualizzare il carico sull'istanza Cloud Bigtable con la relativa UI di monitoraggio. L'intera importazione dovrebbe richiedere 5 minuti.
6. Ottieni il codice
git clone https://github.com/googlecodelabs/cbt-intro-java.git cd cbt-intro-java
Passa a Java 11 eseguendo questi comandi:
sudo update-java-alternatives -s java-1.11.0-openjdk-amd64 && export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64/
7. Esegui una ricerca
La prima query da eseguire è una semplice ricerca di riga. Riceverai i dati per un autobus sulla linea M86-SBS il 1° giugno 2017 dalle 00:00 all'01:00. Allora un veicolo con ID NYCT_5824 si trova sulla linea dell'autobus.
Con queste informazioni e conoscendo la progettazione dello schema (azienda di autobus/linea di autobus/timestamp arrotondati per difetto all'ora/ID veicolo), puoi dedurre che la chiave di riga è:
MTA/M86-SBS/1496275200000/NYCT_5824
BusQueries.java
private static final byte[] COLUMN_FAMILY_NAME = Bytes.toBytes("cf");
private static final byte[] LAT_COLUMN_NAME = Bytes.toBytes("VehicleLocation.Latitude");
private static final byte[] LONG_COLUMN_NAME = Bytes.toBytes("VehicleLocation.Longitude");
String rowKey = "MTA/M86-SBS/1496275200000/NYCT_5824";
Result getResult =
table.get(
new Get(Bytes.toBytes(rowKey))
.addColumn(COLUMN_FAMILY_NAME, LAT_COLUMN_NAME)
.addColumn(COLUMN_FAMILY_NAME, LONG_COLUMN_NAME));
Il risultato dovrebbe contenere la posizione più recente dell'autobus in quell'ora. Tuttavia, se vuoi visualizzare tutte le località, imposta il numero massimo di versioni per la richiesta get.
BusQueries.java
Result getResult =
table.get(
new Get(Bytes.toBytes(rowKey))
.setMaxVersions(Integer.MAX_VALUE)
.addColumn(COLUMN_FAMILY_NAME, LAT_COLUMN_NAME)
.addColumn(COLUMN_FAMILY_NAME, LONG_COLUMN_NAME));
In Cloud Shell, esegui questo comando per visualizzare un elenco di latitudini e longitudini dell'autobus nell'arco dell'ora:
mvn package exec:java -Dbigtable.projectID=$GOOGLE_CLOUD_PROJECT \ -Dbigtable.instanceID=$INSTANCE_ID -Dbigtable.table=$TABLE_ID \ -Dquery=lookupVehicleInGivenHour
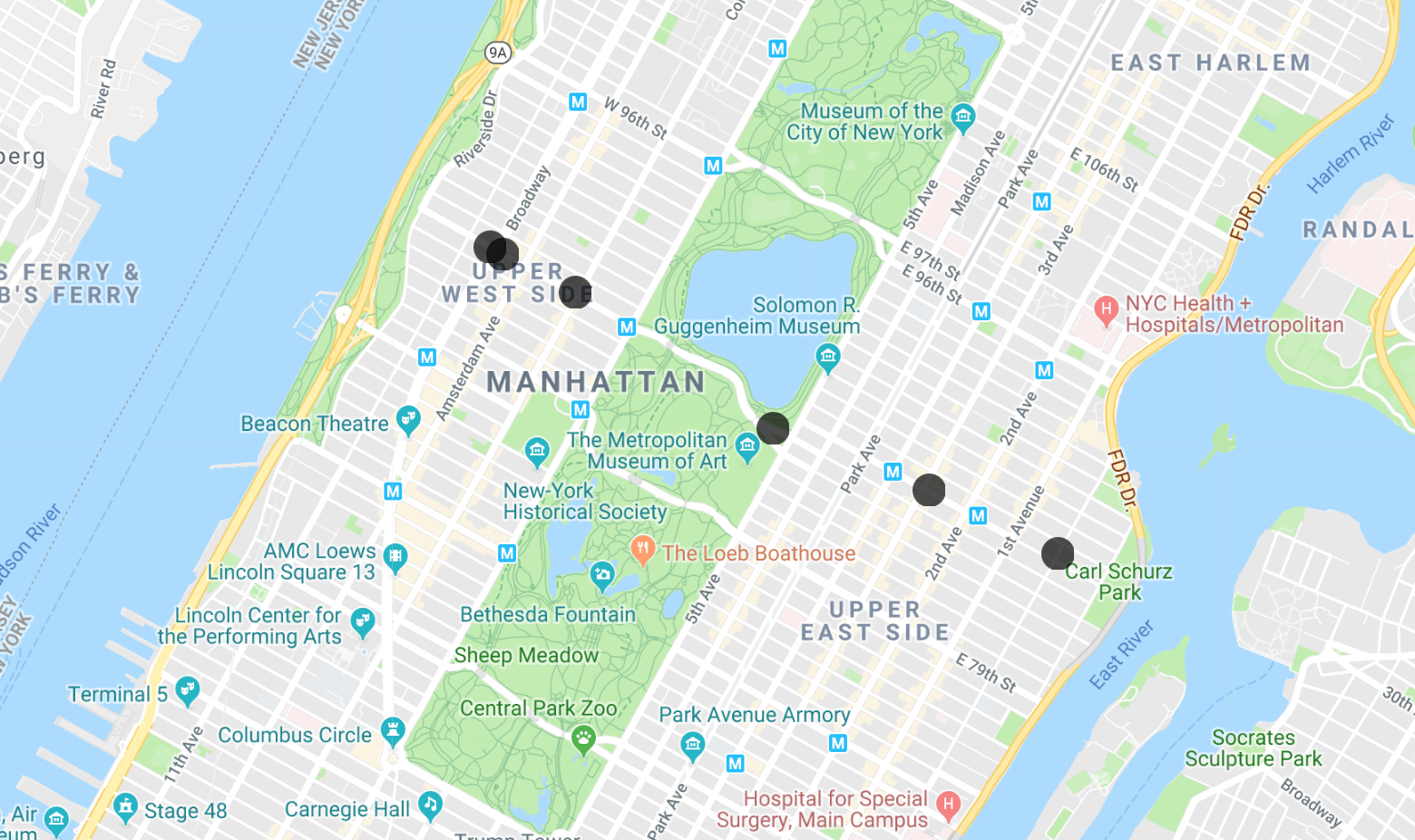
Puoi copiare e incollare le latitudini e le longitudini nell'app MapMaker per visualizzare i risultati. Dopo alcuni livelli, ti verrà chiesto di creare un account senza costi. Puoi creare un account o eliminare semplicemente i livelli esistenti. Se vuoi continuare, questo codelab include una visualizzazione per ogni passaggio. Ecco il risultato per questa prima query:
8. Esegui una scansione
Ora, visualizziamo tutti i dati relativi alla linea di autobus per quell'ora. Il codice di scansione è molto simile al codice GET. Imposti una posizione iniziale allo scanner e poi indichi che desideri solo righe per la linea di autobus M86-SBS entro l'ora indicata dal timestamp 1496275200000.
BusQueries.java
Scan scan;
scan = new Scan();
scan.setMaxVersions(Integer.MAX_VALUE)
.addColumn(COLUMN_FAMILY_NAME, LAT_COLUMN_NAME)
.addColumn(COLUMN_FAMILY_NAME, LONG_COLUMN_NAME)
.withStartRow(Bytes.toBytes("MTA/M86-SBS/1496275200000"))
.setRowPrefixFilter(Bytes.toBytes("MTA/M86-SBS/1496275200000"));
ResultScanner scanner = table.getScanner(scan);
Esegui questo comando per ottenere i risultati.
mvn package exec:java -Dbigtable.projectID=$GOOGLE_CLOUD_PROJECT \ -Dbigtable.instanceID=$INSTANCE_ID -Dbigtable.table=$TABLE_ID \ -Dquery=scanBusLineInGivenHour
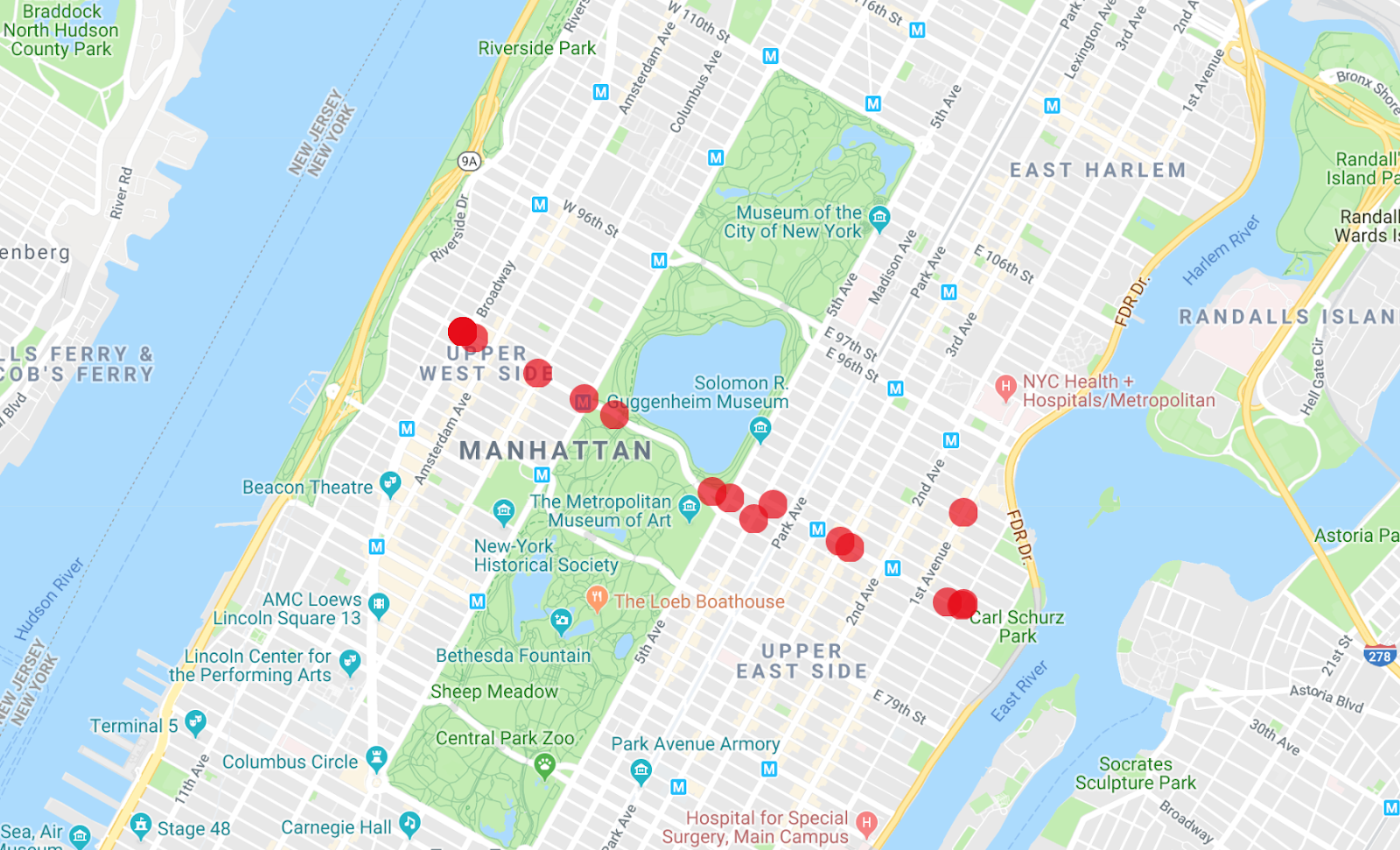
L'app Map Maker può visualizzare più elenchi contemporaneamente, in modo che tu possa vedere quali degli autobus sono il veicolo dalla prima query che hai eseguito.
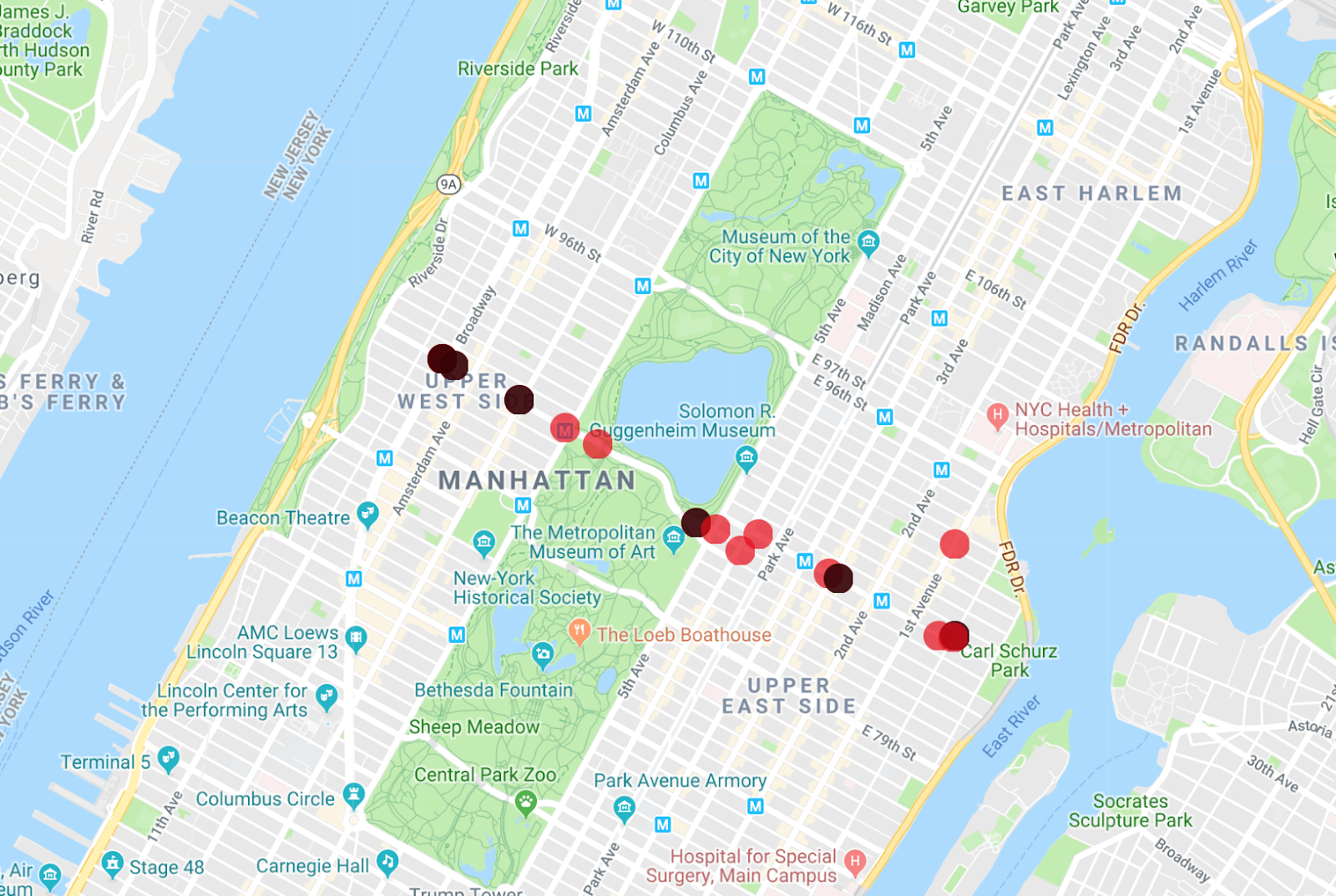
Una modifica interessante a questa query è la visualizzazione dei dati dell'intero mese relativi alla linea di autobus M86-SBS, operazione molto semplice da eseguire. Rimuovi il timestamp dal filtro della riga iniziale e del prefisso per ottenere il risultato.
BusQueries.java
scan.withStartRow(Bytes.toBytes("MTA/M86-SBS/"))
.setRowPrefixFilter(Bytes.toBytes("MTA/M86-SBS/"));
// Optionally, reduce the results to receive one version per column
// since there are so many data points.
scan.setMaxVersions(1);
Esegui questo comando per ottenere i risultati. L'elenco dei risultati sarà molto lungo.
mvn package exec:java -Dbigtable.projectID=$GOOGLE_CLOUD_PROJECT \ -Dbigtable.instanceID=$INSTANCE_ID -Dbigtable.table=$TABLE_ID \ -Dquery=scanEntireBusLine
Se copi i risultati in MapMaker, puoi visualizzare una mappa termica del percorso in autobus. Le macchie arancioni indicano le fermate, mentre le macchie rosse vivaci indicano l'inizio e la fine del percorso.
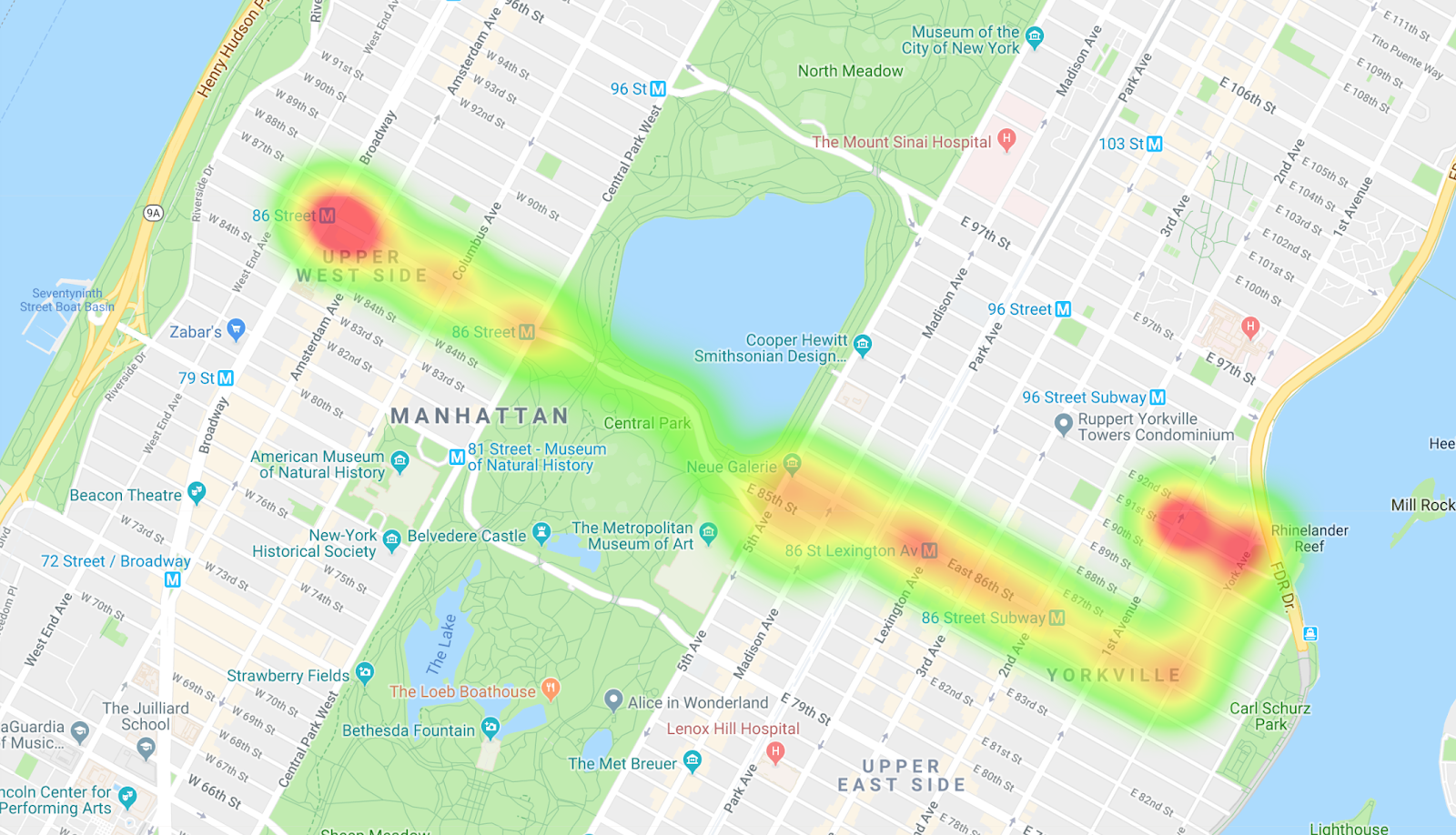
9. Introduci i filtri
Successivamente, filtrerai gli autobus diretti a est e quelli diretti a ovest e creerai una mappa termica separata per ciascuno.
BusQueries.java
Scan scan;
ResultScanner scanner;
scan = new Scan();
SingleColumnValueFilter valueFilter =
new SingleColumnValueFilter(
COLUMN_FAMILY_NAME,
Bytes.toBytes("DestinationName"),
CompareOp.EQUAL,
Bytes.toBytes("Select Bus Service Yorkville East End AV"));
scan.setMaxVersions(1)
.addColumn(COLUMN_FAMILY_NAME, LAT_COLUMN_NAME)
.addColumn(COLUMN_FAMILY_NAME, LONG_COLUMN_NAME);
scan.withStartRow(Bytes.toBytes("MTA/M86-SBS/"))
.setRowPrefixFilter(Bytes.toBytes("MTA/M86-SBS/"));
scan.setFilter(valueFilter);
scanner = table.getScanner(scan);
Esegui questo comando per visualizzare i risultati per gli autobus diretti a est.
mvn package exec:java -Dbigtable.projectID=$GOOGLE_CLOUD_PROJECT \ -Dbigtable.instanceID=$INSTANCE_ID -Dbigtable.table=$TABLE_ID \ -Dquery=filterBusesGoingEast
Per portare gli autobus verso ovest, modifica la stringa in valueFilter:
BusQueries.java
SingleColumnValueFilter valueFilter =
new SingleColumnValueFilter(
COLUMN_FAMILY_NAME,
Bytes.toBytes("DestinationName"),
CompareOp.EQUAL,
Bytes.toBytes("Select Bus Service Westside West End AV"));
Esegui questo comando per ottenere i risultati per gli autobus diretti a ovest.
mvn package exec:java -Dbigtable.projectID=$GOOGLE_CLOUD_PROJECT \ -Dbigtable.instanceID=$INSTANCE_ID -Dbigtable.table=$TABLE_ID \ -Dquery=filterBusesGoingWest
Autobus in direzione est
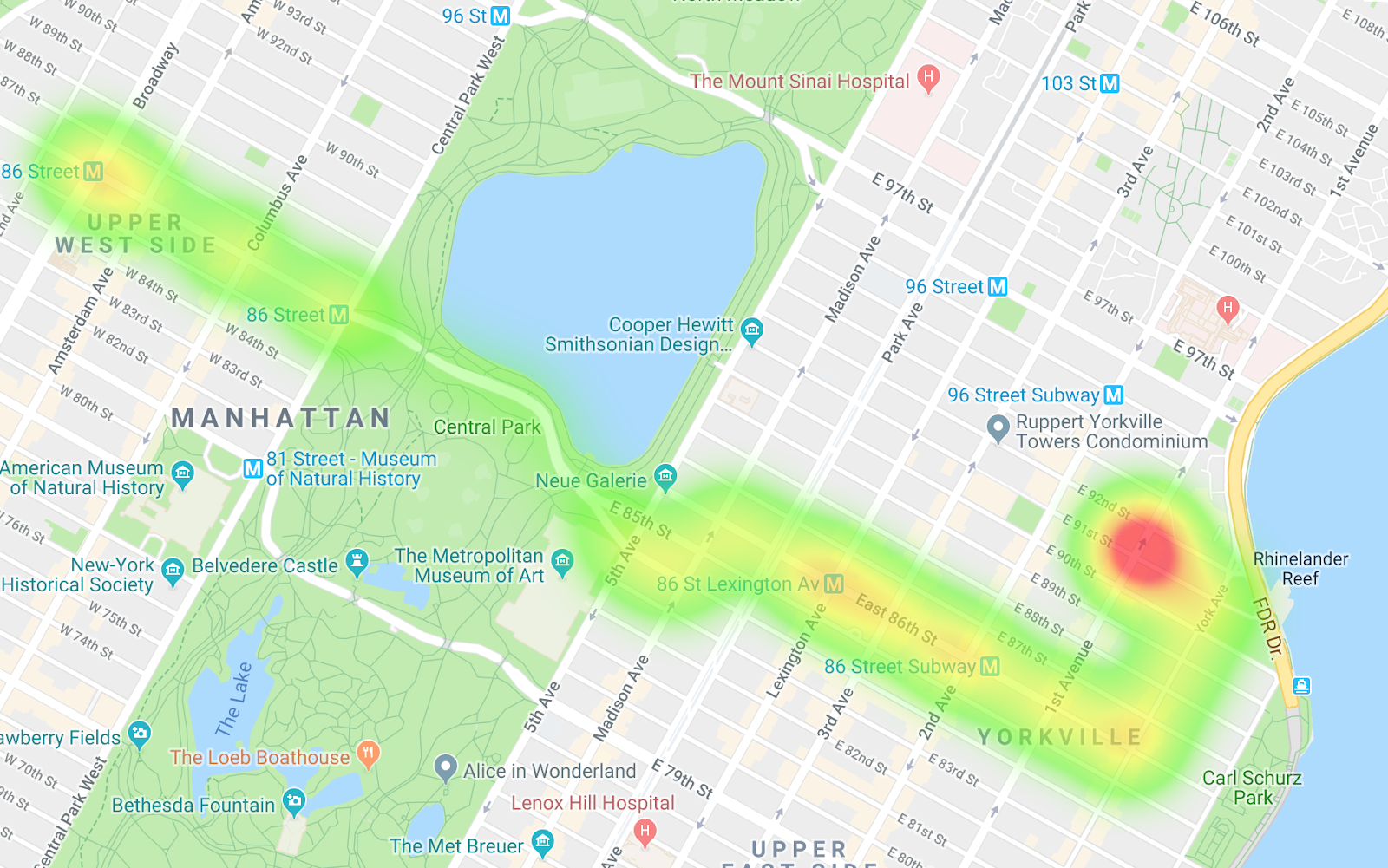
Autobus in direzione ovest
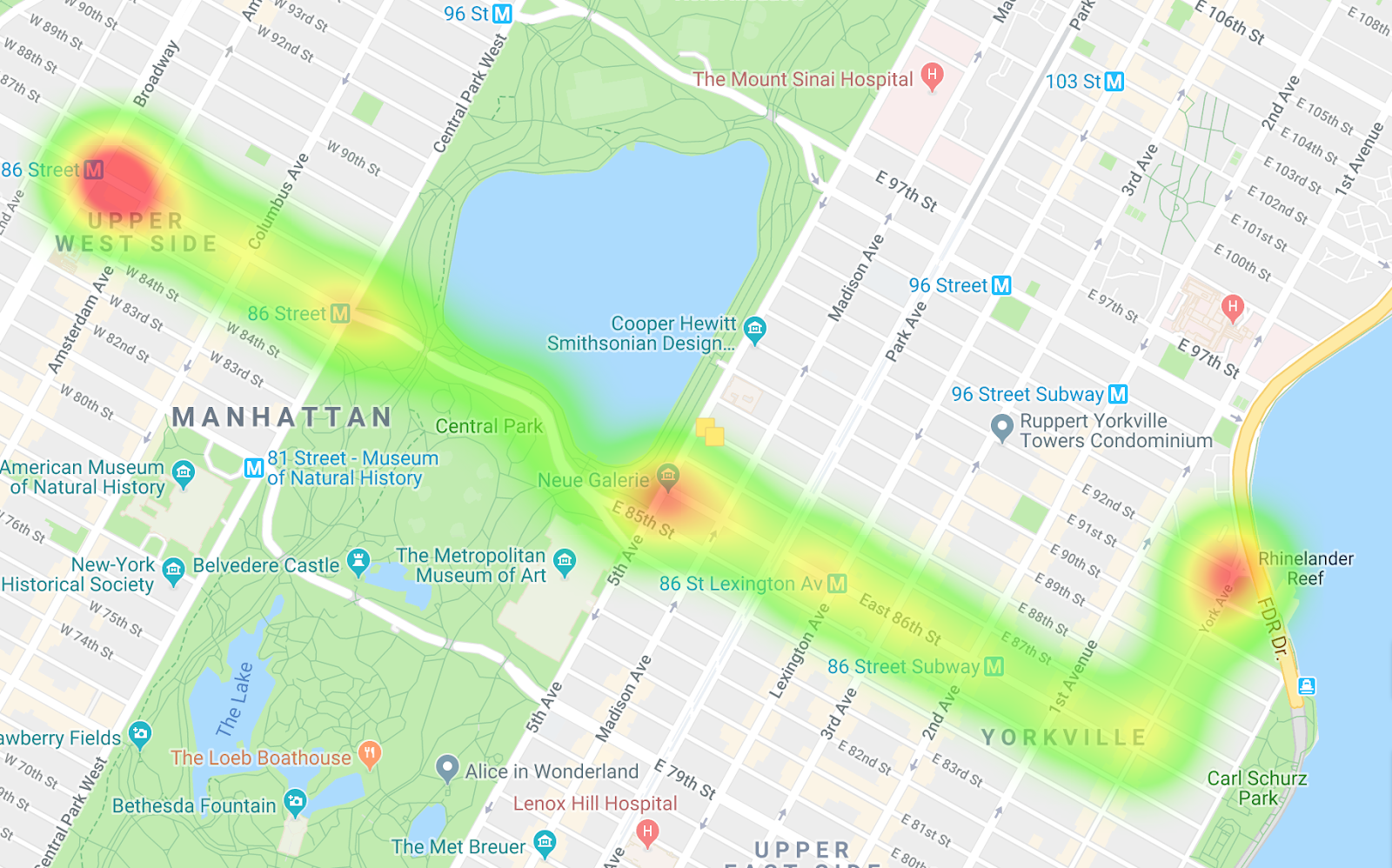
Confrontando le due mappe termiche, puoi vedere le differenze nei percorsi e le differenze nel pacing. Un'interpretazione dei dati è che, lungo il percorso in direzione ovest, gli autobus si fermano maggiormente, soprattutto quando entrano a Central Park. E sugli autobus diretti a est, non ci sono molti punti di strozzamento.
10. Esegui una scansione multiintervallo
Per l'ultima query, dovrai rispondere al caso quando ti interessano molte linee di autobus in una zona:
BusQueries.java
private static final String[] MANHATTAN_BUS_LINES = {"M1","M2","M3",...
Scan scan;
ResultScanner scanner;
List<RowRange> ranges = new ArrayList<>();
for (String busLine : MANHATTAN_BUS_LINES) {
ranges.add(
new RowRange(
Bytes.toBytes("MTA/" + busLine + "/1496275200000"), true,
Bytes.toBytes("MTA/" + busLine + "/1496275200001"), false));
}
Filter filter = new MultiRowRangeFilter(ranges);
scan = new Scan();
scan.setFilter(filter);
scan.setMaxVersions(Integer.MAX_VALUE)
.addColumn(COLUMN_FAMILY_NAME, LAT_COLUMN_NAME)
.addColumn(COLUMN_FAMILY_NAME, LONG_COLUMN_NAME);
scan.withStartRow(Bytes.toBytes("MTA/M")).setRowPrefixFilter(Bytes.toBytes("MTA/M"));
scanner = table.getScanner(scan);
Esegui questo comando per ottenere i risultati.
mvn package exec:java -Dbigtable.projectID=$GOOGLE_CLOUD_PROJECT \ -Dbigtable.instanceID=$INSTANCE_ID -Dbigtable.table=$TABLE_ID \ -Dquery=scanManhattanBusesInGivenHour
11. Completa la configurazione
Eseguire la pulizia per evitare addebiti
Per evitare che al tuo account Google Cloud Platform vengano addebitati costi relativi alle risorse utilizzate in questo codelab, devi eliminare la tua istanza.
gcloud bigtable instances delete $INSTANCE_ID
Argomenti trattati
- Progettazione di uno schema
- Configurazione di un'istanza, una tabella e una famiglia
- Importazione di file di sequenza con Dataflow
- Esecuzione di query con una ricerca, una scansione, una scansione con un filtro e una scansione multiintervallo
Passaggi successivi
- Scopri di più su Cloud Bigtable nella documentazione.
- Prova le altre funzioni di Google Cloud Platform. Dai un'occhiata ai nostri tutorial.
- Scopri come monitorare i dati delle serie temporali con l'integrazione OpenTSDB.