
1. 소개
이 Codelab에서는 Java HBase 클라이언트와 함께 Cloud Bigtable을 사용하는 방법을 알아봅니다.
학습 목표
- 스키마 설계 시 흔히 발생하는 실수 방지
- 시퀀스 파일에서 데이터 가져오기
- 데이터 쿼리
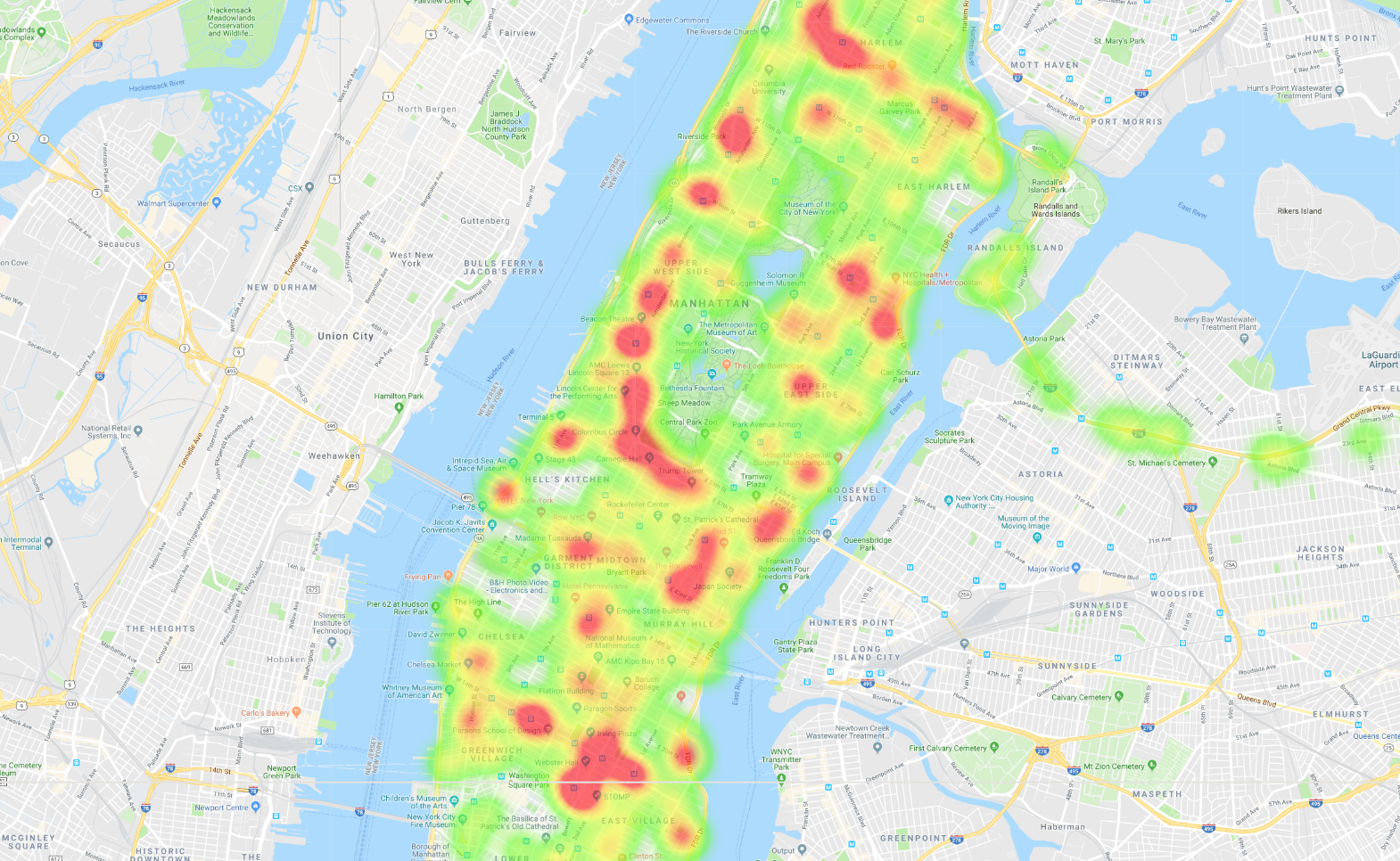
완료되면 뉴욕시 버스 데이터를 보여주는 지도가 여러 개 표시됩니다. 예를 들어 맨해튼의 버스 이동에 관한 다음 히트맵을 만듭니다.
귀하의 Google Cloud Platform 사용 경험을 평가해 주세요.
본 가이드를 어떻게 사용하실 계획인가요?
2. 데이터 세트 정보
뉴욕시 버스에 관한 데이터 세트를 살펴보게 됩니다. 300개가 넘는 버스 노선과 해당 노선을 따르는 5,800대의 차량이 있습니다. Google 데이터 세트는 목적지 이름, 차량 ID, 위도, 경도, 예상 도착 시간, 예정 도착 시간을 포함하는 로그입니다. 데이터 세트는 2017년 6월에 약 10분마다 촬영된 스냅샷으로 구성됩니다.
3. 스키마 설계
Cloud Bigtable에서 최고의 성능을 얻으려면 스키마를 설계할 때 신중해야 합니다. Cloud Bigtable의 데이터는 사전순으로 자동 정렬되므로 스키마를 잘 설계하면 관련 데이터를 매우 효율적으로 쿼리할 수 있습니다. Cloud Bigtable에서는 행 키를 사용한 포인트 조회 또는 연속된 행 집합을 반환하는 행 범위 스캔을 사용한 쿼리가 허용됩니다. 하지만 스키마가 제대로 설계되지 않은 경우 여러 행 조회를 조합하거나 전체 테이블 스캔을 실행해야 할 수 있으며, 이는 매우 느린 작업입니다.
쿼리 계획하기
데이터에는 다양한 정보가 있지만 이 Codelab에서는 버스의 위치와 목적지를 사용합니다.
이 정보를 사용하여 다음 쿼리를 실행할 수 있습니다.
- 특정 시간 동안 단일 버스의 위치를 가져옵니다.
- 버스 노선 또는 특정 버스의 하루치 데이터를 가져옵니다.
- 지도에서 직사각형 안에 있는 모든 버스를 찾습니다.
- 모든 버스의 현재 위치를 가져옵니다 (이 데이터를 실시간으로 수집한 경우).
이 쿼리 집합은 모두 최적으로 함께 실행할 수 없습니다. 예를 들어 시간별로 정렬하는 경우 전체 테이블 스캔을 실행하지 않고는 위치를 기반으로 스캔할 수 없습니다. 가장 일반적으로 실행하는 쿼리를 기반으로 우선순위를 지정해야 합니다.
이 Codelab에서는 다음 쿼리 집합을 최적화하고 실행하는 데 중점을 둡니다.
- 한 시간 동안 특정 차량의 위치를 가져옵니다.
- 한 시간 동안 전체 버스 노선의 위치를 가져옵니다.
- 한 시간 안에 맨해튼에 있는 모든 버스의 위치를 알려 줘.
- 맨해튼에 있는 모든 버스의 가장 최근 위치를 1시간 안에 가져와 줘.
- 한 달 동안 전체 버스 노선의 위치를 가져옵니다.
- 특정 목적지가 있는 전체 버스 노선의 위치를 1시간 동안 가져옵니다.
row key 설계
이 Codelab에서는 정적 데이터 세트로 작업하지만 확장성을 위한 스키마를 설계합니다. 테이블로 더 많은 버스 데이터를 스트리밍하면서도 성능을 유지할 수 있는 스키마를 설계합니다.
다음은 행 키에 제안된 스키마입니다.
[버스 회사/버스 노선/시간으로 반내림된 타임스탬프/차량 ID] 각 행에는 한 시간 분량의 데이터가 있으며 각 셀에는 타임스탬프가 적용된 여러 버전의 데이터가 포함됩니다.
이 Codelab에서는 간단하게 하나의 열 패밀리를 사용합니다. 다음은 데이터의 예시 뷰입니다. 데이터가 행 키로 정렬됩니다.
row key | cf:VehicleLocation.Latitude | cf:VehicleLocation.Longitude | ... |
MTA/M86-SBS/1496275200000/NYCT_5824 | 40.781212 @20:52:54.0040.776163 @20:43:19.0040.778714 @20:33:46.00 | -73.961942 @20:52:54.00-73.946949 @20:43:19.00-73.953731 @20:33:46.00 | ... |
MTA/M86-SBS/1496275200000/NYCT_5840 | 40.780664 @20:13:51.0040.788416 @20:03:40.00 | -73.958357 @20:13:51.00 -73.976748 @20:03:40.00 | ... |
MTA/M86-SBS/1496275200000/NYCT_5867 | 40.780281 @20:51:45.0040.779961 @20:43:15.0040.788416 @20:33:44.00 | -73.946890 @20:51:45.00-73.959465 @20:43:15.00-73.976748 @20:33:44.00 | ... |
... | ... | ... | ... |
4. 인스턴스, 테이블, 패밀리 만들기
다음으로 Cloud Bigtable 테이블을 만듭니다.
먼저 새 프로젝트를 만듭니다. 오른쪽 상단에 있는 'Cloud Shell 활성화' 버튼을 클릭하여 열 수 있는 내장 Cloud Shell을 사용합니다.
다음 환경 변수를 설정하여 Codelab 명령어를 더 쉽게 복사하여 붙여넣습니다.
INSTANCE_ID="bus-instance" CLUSTER_ID="bus-cluster" TABLE_ID="bus-data" CLUSTER_NUM_NODES=3 CLUSTER_ZONE="us-central1-c"
Cloud Shell에는 이 Codelab에서 사용할 도구인 gcloud 명령줄 도구, cbt 명령줄 인터페이스, Maven이 이미 설치되어 있습니다.
다음 명령어를 실행하여 Cloud Bigtable API를 사용 설정합니다.
gcloud services enable bigtable.googleapis.com bigtableadmin.googleapis.com
다음 명령어를 실행하여 인스턴스를 만듭니다.
gcloud bigtable instances create $INSTANCE_ID \
--cluster=$CLUSTER_ID \
--cluster-zone=$CLUSTER_ZONE \
--cluster-num-nodes=$CLUSTER_NUM_NODES \
--display-name=$INSTANCE_ID
인스턴스를 만든 후 cbt 구성 파일을 채우고 다음 명령어를 실행하여 테이블과 column family를 만듭니다.
echo project = $GOOGLE_CLOUD_PROJECT > ~/.cbtrc echo instance = $INSTANCE_ID >> ~/.cbtrc cbt createtable $TABLE_ID cbt createfamily $TABLE_ID cf
5. 데이터 가져오기
다음 단계에 따라 gs://cloud-bigtable-public-datasets/bus-data에서 이 Codelab의 일련의 시퀀스 파일을 가져옵니다.
다음 명령어를 실행하여 Cloud Dataflow API를 사용 설정합니다.
gcloud services enable dataflow.googleapis.com
다음 명령어를 실행하여 테이블을 가져옵니다.
NUM_WORKERS=$(expr 3 \* $CLUSTER_NUM_NODES) gcloud beta dataflow jobs run import-bus-data-$(date +%s) \ --gcs-location gs://dataflow-templates/latest/GCS_SequenceFile_to_Cloud_Bigtable \ --num-workers=$NUM_WORKERS --max-workers=$NUM_WORKERS \ --parameters bigtableProject=$GOOGLE_CLOUD_PROJECT,bigtableInstanceId=$INSTANCE_ID,bigtableTableId=$TABLE_ID,sourcePattern=gs://cloud-bigtable-public-datasets/bus-data/*
가져오기 모니터링
Cloud Dataflow UI에서 작업을 모니터링할 수 있습니다. 또한 모니터링 UI를 사용하여 Cloud Bigtable 인스턴스의 부하를 확인할 수 있습니다. 전체 가져오기에는 5분 정도 걸립니다.
6. 코드 가져오기
git clone https://github.com/googlecodelabs/cbt-intro-java.git cd cbt-intro-java
다음 명령어를 실행하여 Java 11로 변경합니다.
sudo update-java-alternatives -s java-1.11.0-openjdk-amd64 && export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64/
7. 조회 실행
처음 실행할 쿼리는 간단한 행 조회입니다. 2017년 6월 1일 오전 12시부터 오전 1시까지 M86-SBS 노선의 버스 데이터를 가져옵니다. ID가 NYCT_5824인 차량이 해당 버스 노선에 있습니다.
이 정보와 스키마 설계 (버스 회사/버스 노선/시간으로 반내림된 타임스탬프/차량 ID)를 알면 행 키가 다음과 같음을 추론할 수 있습니다.
MTA/M86-SBS/1496275200000/NYCT_5824
BusQueries.java
private static final byte[] COLUMN_FAMILY_NAME = Bytes.toBytes("cf");
private static final byte[] LAT_COLUMN_NAME = Bytes.toBytes("VehicleLocation.Latitude");
private static final byte[] LONG_COLUMN_NAME = Bytes.toBytes("VehicleLocation.Longitude");
String rowKey = "MTA/M86-SBS/1496275200000/NYCT_5824";
Result getResult =
table.get(
new Get(Bytes.toBytes(rowKey))
.addColumn(COLUMN_FAMILY_NAME, LAT_COLUMN_NAME)
.addColumn(COLUMN_FAMILY_NAME, LONG_COLUMN_NAME));
결과에는 해당 시간 내 버스의 가장 최근 위치가 포함되어야 합니다. 하지만 모든 위치를 확인하고 싶으므로 가져오기 요청에서 최대 버전 수를 설정합니다.
BusQueries.java
Result getResult =
table.get(
new Get(Bytes.toBytes(rowKey))
.setMaxVersions(Integer.MAX_VALUE)
.addColumn(COLUMN_FAMILY_NAME, LAT_COLUMN_NAME)
.addColumn(COLUMN_FAMILY_NAME, LONG_COLUMN_NAME));
Cloud Shell에서 다음 명령어를 실행하여 한 시간 동안 해당 버스의 위도와 경도 목록을 가져옵니다.
mvn package exec:java -Dbigtable.projectID=$GOOGLE_CLOUD_PROJECT \ -Dbigtable.instanceID=$INSTANCE_ID -Dbigtable.table=$TABLE_ID \ -Dquery=lookupVehicleInGivenHour
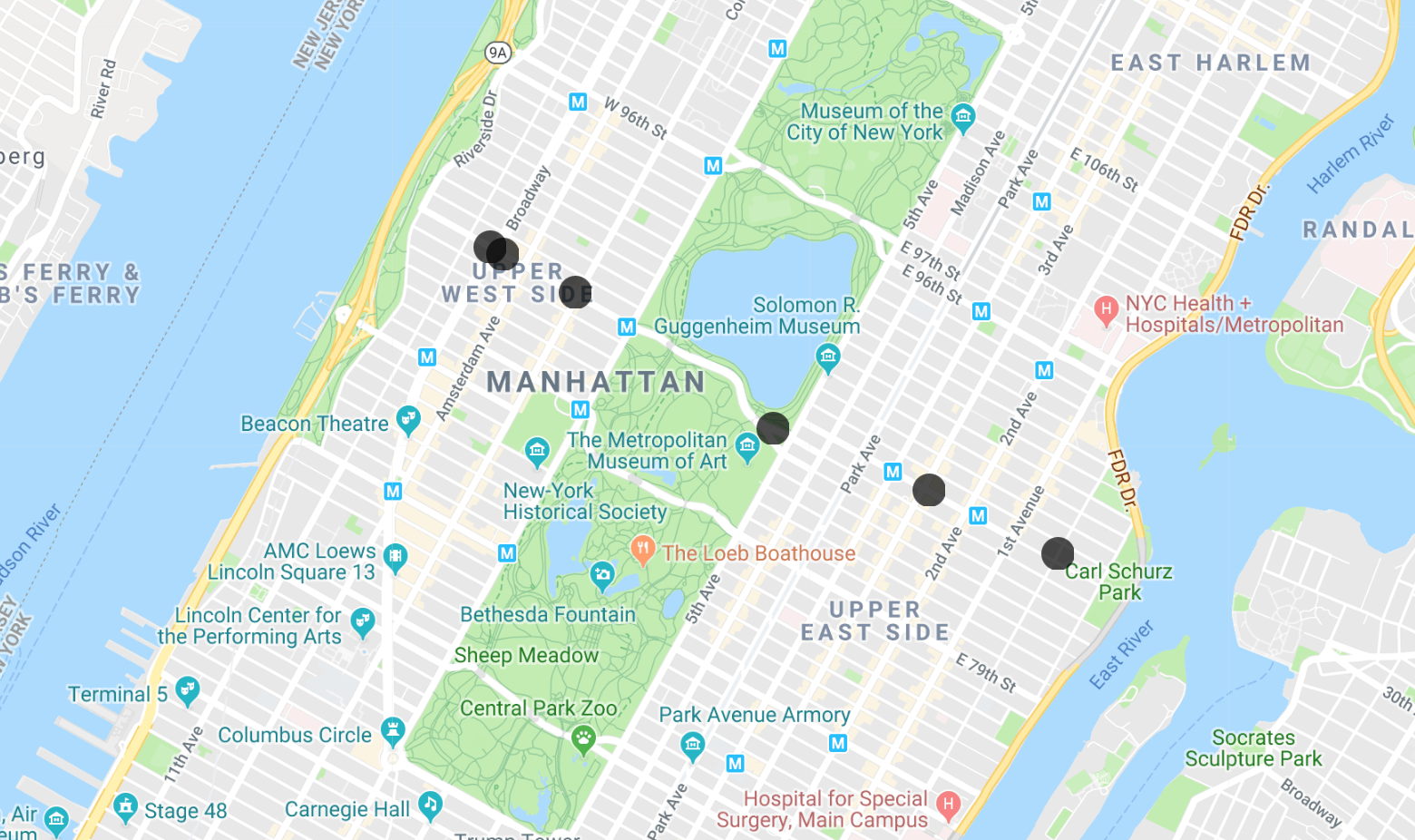
위도와 경도를 복사하여 MapMaker 앱에 붙여넣어 결과를 시각화할 수 있습니다. 몇 개의 레이어를 거치면 무료 계정을 만들라는 메시지가 표시됩니다. 계정을 만들거나 기존 레이어를 삭제할 수 있습니다. 이 Codelab에는 각 단계의 시각화가 포함되어 있으므로 따라하기만 하면 됩니다. 첫 번째 쿼리의 결과는 다음과 같습니다.
8. 스캔 실행
이제 해당 시간의 버스 노선에 대한 모든 데이터를 확인해 보겠습니다. 스캔 코드는 가져오기 코드와 매우 유사합니다. 스캐너에 시작 위치를 지정한 다음 타임스탬프 1496275200000으로 표시된 시간 내에 M86-SBS 버스 노선의 행만 원한다고 표시합니다.
BusQueries.java
Scan scan;
scan = new Scan();
scan.setMaxVersions(Integer.MAX_VALUE)
.addColumn(COLUMN_FAMILY_NAME, LAT_COLUMN_NAME)
.addColumn(COLUMN_FAMILY_NAME, LONG_COLUMN_NAME)
.withStartRow(Bytes.toBytes("MTA/M86-SBS/1496275200000"))
.setRowPrefixFilter(Bytes.toBytes("MTA/M86-SBS/1496275200000"));
ResultScanner scanner = table.getScanner(scan);
다음 명령어를 실행하여 결과를 가져옵니다.
mvn package exec:java -Dbigtable.projectID=$GOOGLE_CLOUD_PROJECT \ -Dbigtable.instanceID=$INSTANCE_ID -Dbigtable.table=$TABLE_ID \ -Dquery=scanBusLineInGivenHour
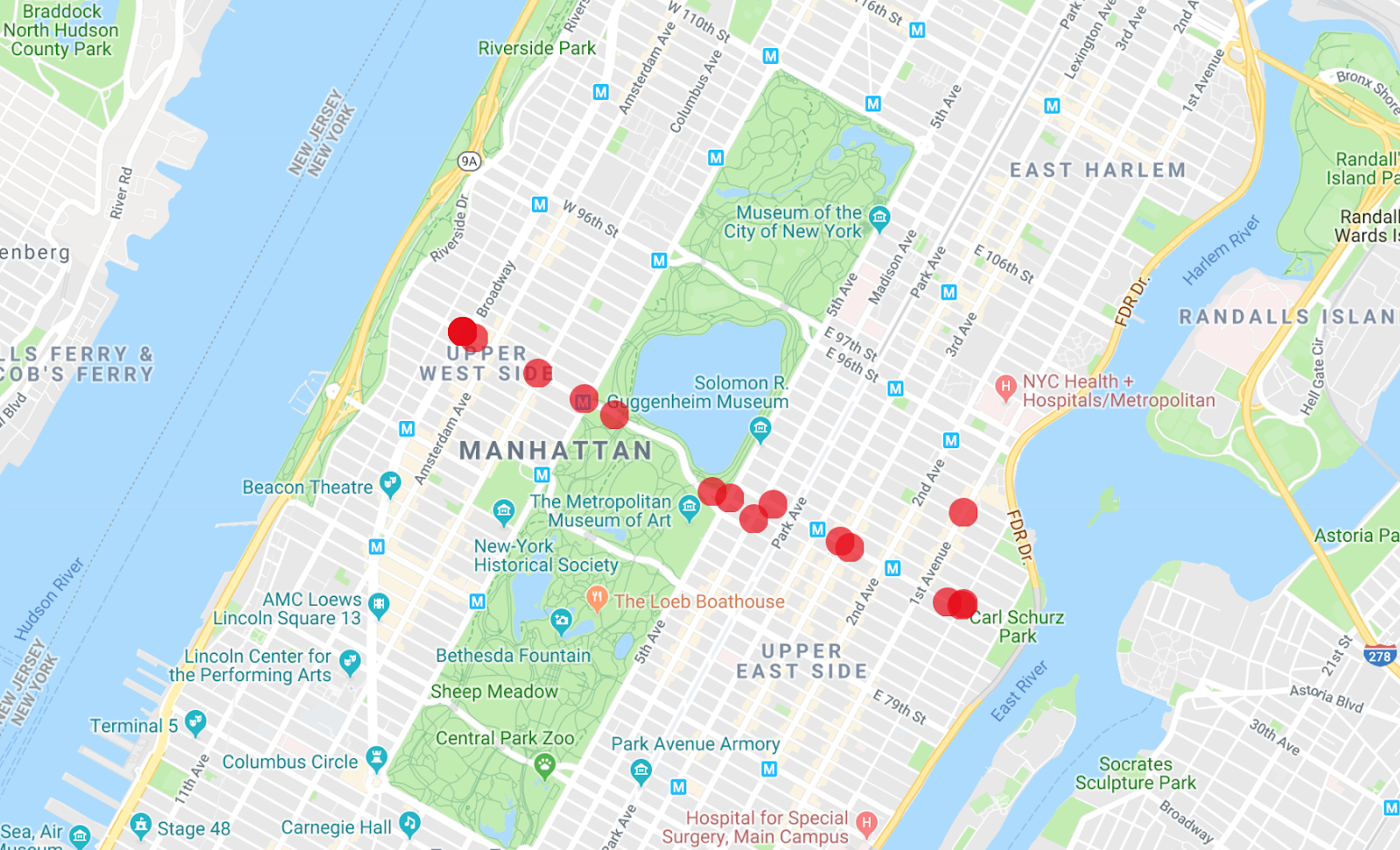
Map Maker 앱은 여러 목록을 한 번에 표시할 수 있으므로 실행한 첫 번째 쿼리의 차량이 어떤 버스인지 확인할 수 있습니다.
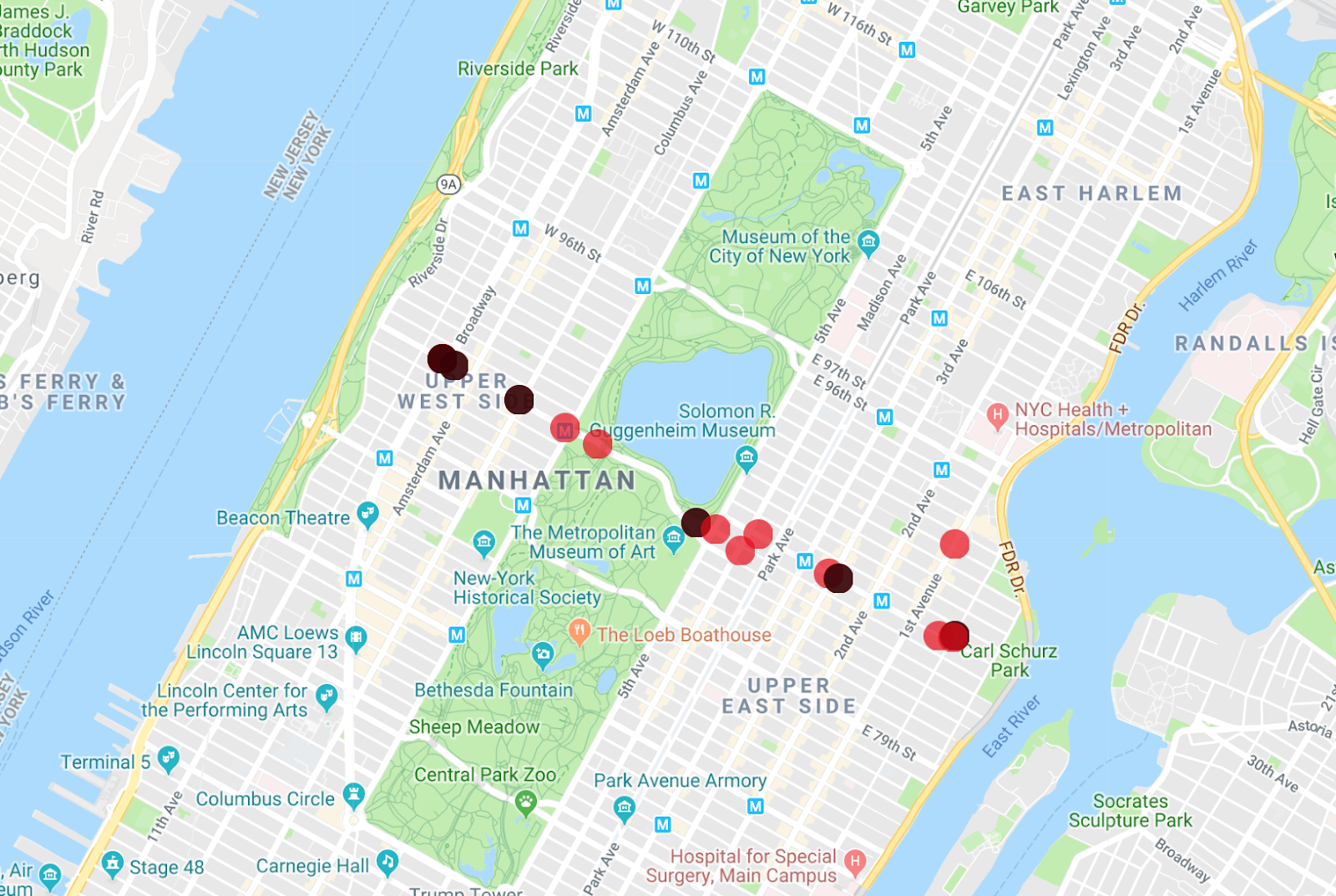
이 쿼리의 흥미로운 수정사항은 M86-SBS 버스 노선의 전체 월 데이터를 보는 것입니다. 이는 매우 간단합니다. 시작 행과 접두사 필터에서 타임스탬프를 삭제하면 결과를 얻을 수 있습니다.
BusQueries.java
scan.withStartRow(Bytes.toBytes("MTA/M86-SBS/"))
.setRowPrefixFilter(Bytes.toBytes("MTA/M86-SBS/"));
// Optionally, reduce the results to receive one version per column
// since there are so many data points.
scan.setMaxVersions(1);
다음 명령어를 실행하여 결과를 가져옵니다. (결과 목록이 길게 표시됩니다.)
mvn package exec:java -Dbigtable.projectID=$GOOGLE_CLOUD_PROJECT \ -Dbigtable.instanceID=$INSTANCE_ID -Dbigtable.table=$TABLE_ID \ -Dquery=scanEntireBusLine
결과를 MapMaker에 복사하면 버스 노선의 히트맵을 볼 수 있습니다. 주황색 블롭은 정류장을 나타내고 밝은 빨간색 블롭은 경로의 시작과 끝을 나타냅니다.
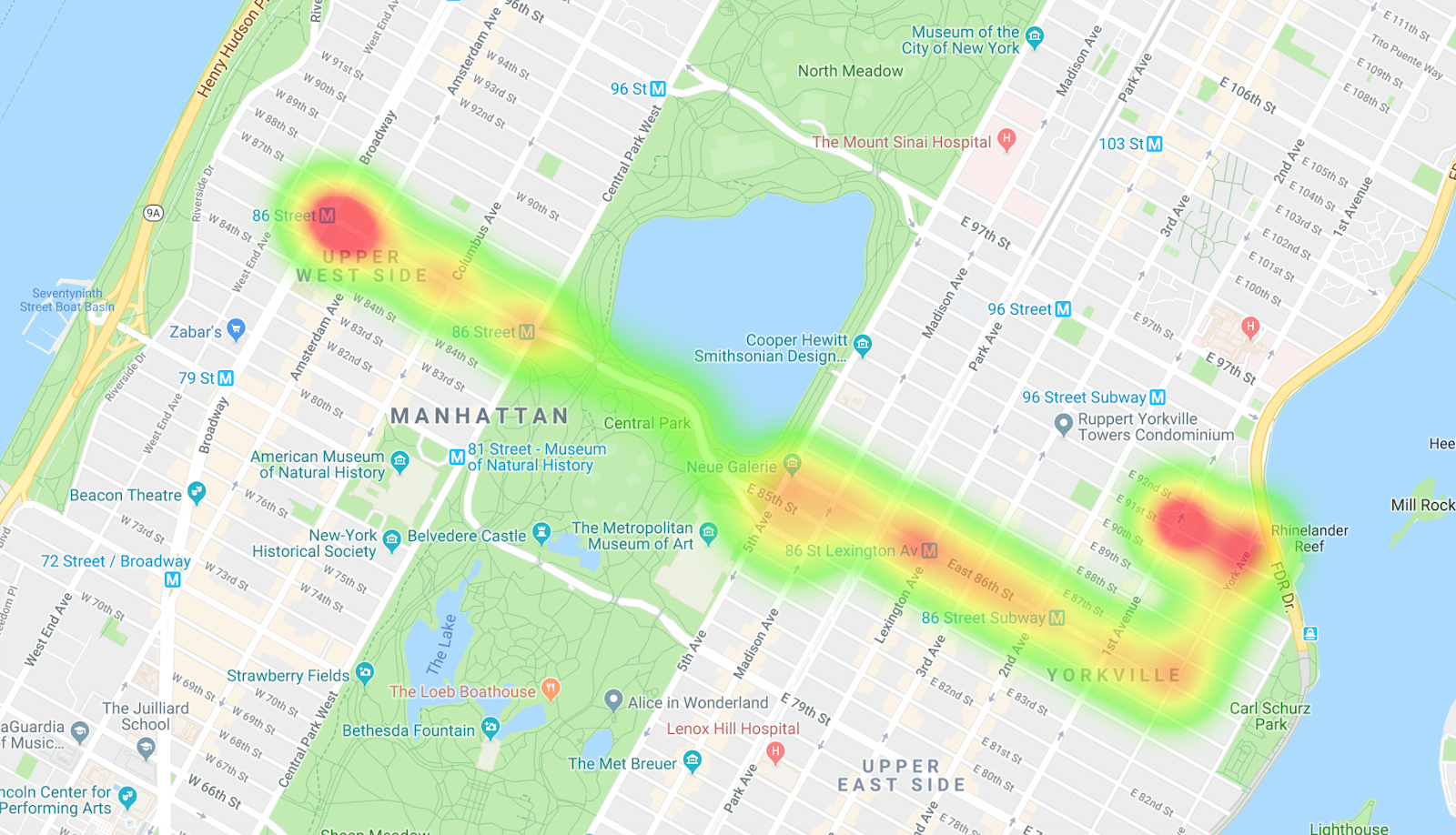
9. 필터 소개
다음으로 동쪽으로 향하는 버스와 서쪽으로 향하는 버스를 필터링하고 각각에 대해 별도의 히트맵을 만듭니다.
BusQueries.java
Scan scan;
ResultScanner scanner;
scan = new Scan();
SingleColumnValueFilter valueFilter =
new SingleColumnValueFilter(
COLUMN_FAMILY_NAME,
Bytes.toBytes("DestinationName"),
CompareOp.EQUAL,
Bytes.toBytes("Select Bus Service Yorkville East End AV"));
scan.setMaxVersions(1)
.addColumn(COLUMN_FAMILY_NAME, LAT_COLUMN_NAME)
.addColumn(COLUMN_FAMILY_NAME, LONG_COLUMN_NAME);
scan.withStartRow(Bytes.toBytes("MTA/M86-SBS/"))
.setRowPrefixFilter(Bytes.toBytes("MTA/M86-SBS/"));
scan.setFilter(valueFilter);
scanner = table.getScanner(scan);
다음 명령어를 실행하여 동쪽으로 가는 버스의 결과를 가져옵니다.
mvn package exec:java -Dbigtable.projectID=$GOOGLE_CLOUD_PROJECT \ -Dbigtable.instanceID=$INSTANCE_ID -Dbigtable.table=$TABLE_ID \ -Dquery=filterBusesGoingEast
서쪽으로 가는 버스를 가져오려면 valueFilter의 문자열을 변경하세요.
BusQueries.java
SingleColumnValueFilter valueFilter =
new SingleColumnValueFilter(
COLUMN_FAMILY_NAME,
Bytes.toBytes("DestinationName"),
CompareOp.EQUAL,
Bytes.toBytes("Select Bus Service Westside West End AV"));
다음 명령어를 실행하여 서쪽으로 가는 버스의 결과를 가져옵니다.
mvn package exec:java -Dbigtable.projectID=$GOOGLE_CLOUD_PROJECT \ -Dbigtable.instanceID=$INSTANCE_ID -Dbigtable.table=$TABLE_ID \ -Dquery=filterBusesGoingWest
동쪽으로 향하는 버스
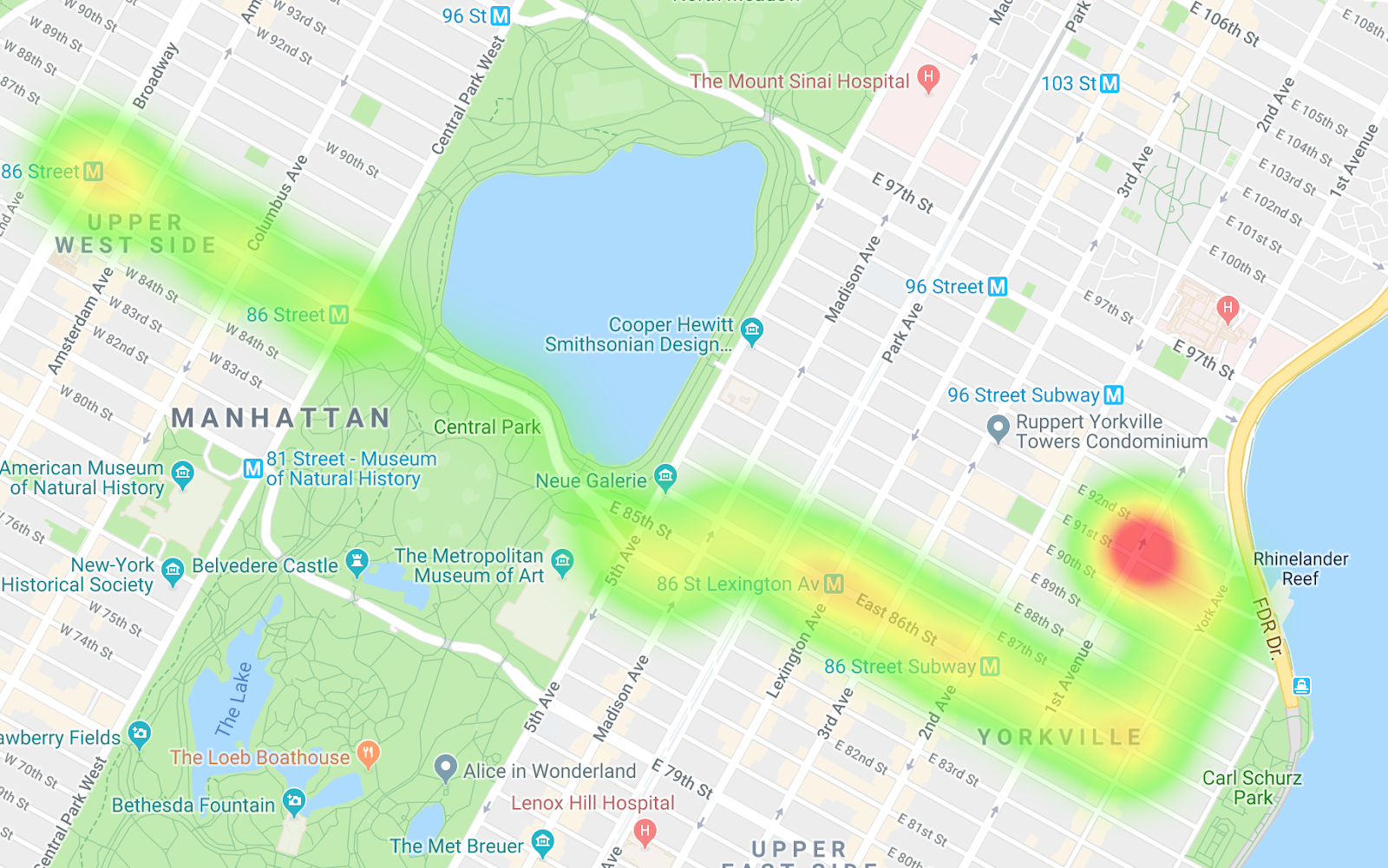
서쪽으로 향하는 버스
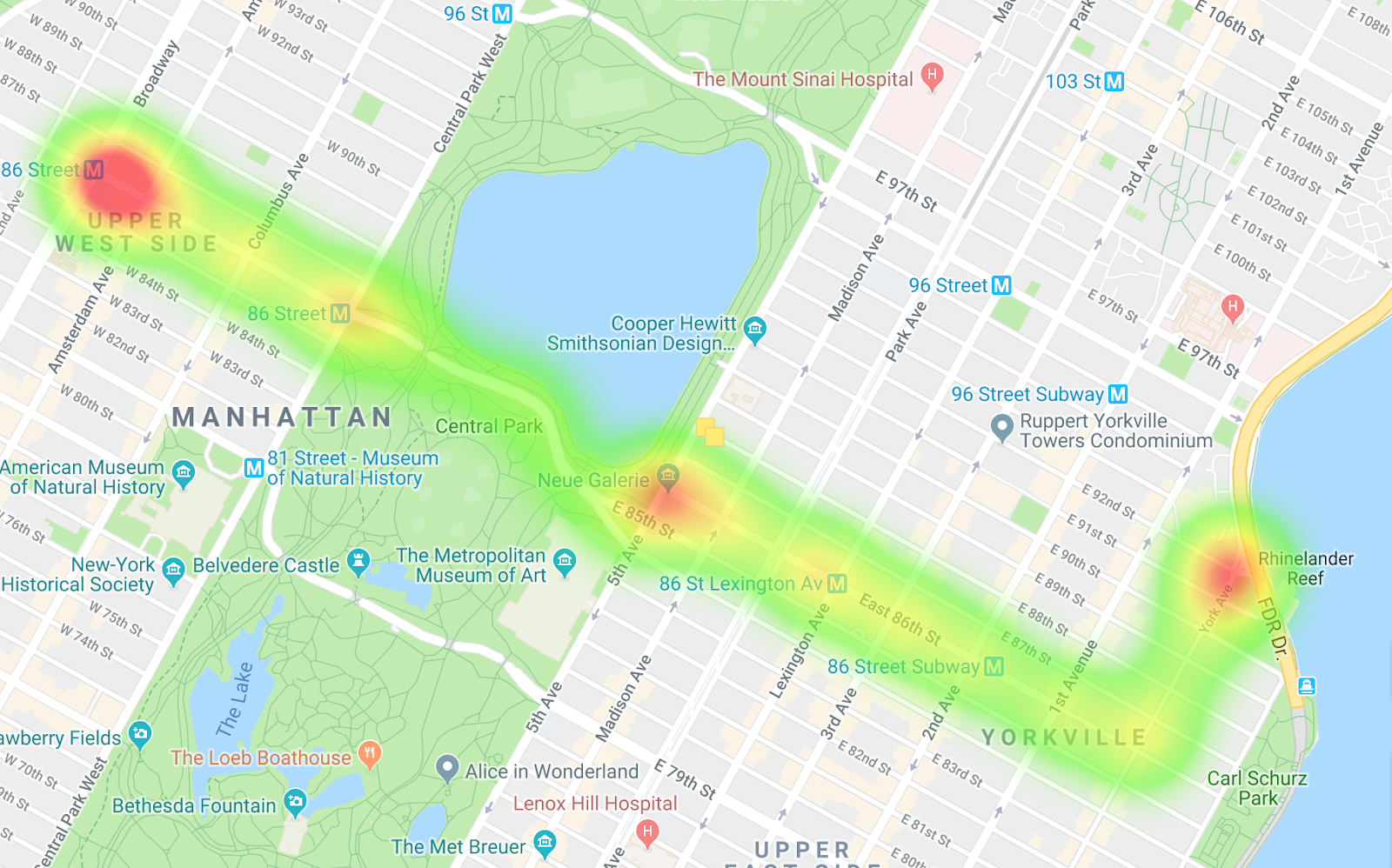
두 히트맵을 비교하면 경로의 차이뿐만 아니라 페이스의 차이도 확인할 수 있습니다. 데이터를 해석하면 서쪽으로 향하는 경로에서 버스가 더 많이 정차하는 것으로 나타납니다. 특히 센트럴파크에 진입할 때 정차하는 경우가 많습니다. 동쪽으로 향하는 버스에서는 병목 현상이 많이 발생하지 않습니다.
10. 다중 범위 스캔 실행
마지막 질문에서는 특정 지역의 여러 버스 노선에 관심이 있는 경우를 다룹니다.
BusQueries.java
private static final String[] MANHATTAN_BUS_LINES = {"M1","M2","M3",...
Scan scan;
ResultScanner scanner;
List<RowRange> ranges = new ArrayList<>();
for (String busLine : MANHATTAN_BUS_LINES) {
ranges.add(
new RowRange(
Bytes.toBytes("MTA/" + busLine + "/1496275200000"), true,
Bytes.toBytes("MTA/" + busLine + "/1496275200001"), false));
}
Filter filter = new MultiRowRangeFilter(ranges);
scan = new Scan();
scan.setFilter(filter);
scan.setMaxVersions(Integer.MAX_VALUE)
.addColumn(COLUMN_FAMILY_NAME, LAT_COLUMN_NAME)
.addColumn(COLUMN_FAMILY_NAME, LONG_COLUMN_NAME);
scan.withStartRow(Bytes.toBytes("MTA/M")).setRowPrefixFilter(Bytes.toBytes("MTA/M"));
scanner = table.getScanner(scan);
다음 명령어를 실행하여 결과를 가져옵니다.
mvn package exec:java -Dbigtable.projectID=$GOOGLE_CLOUD_PROJECT \ -Dbigtable.instanceID=$INSTANCE_ID -Dbigtable.table=$TABLE_ID \ -Dquery=scanManhattanBusesInGivenHour
11. 완료
요금이 청구되지 않도록 정리하기
이 Codelab에서 사용한 리소스 비용이 Google Cloud Platform 계정에 청구되지 않도록 하려면 인스턴스를 삭제해야 합니다.
gcloud bigtable instances delete $INSTANCE_ID
학습한 내용
- 스키마 설계
- 인스턴스, 테이블, 패밀리 설정
- Dataflow를 사용하여 시퀀스 파일 가져오기
- 조회, 스캔, 필터링된 스캔, 다중 범위 스캔으로 쿼리
다음 단계
- 문서에서 Cloud Bigtable에 대해 자세히 알아보세요.
- 다른 Google Cloud Platform 기능 직접 사용하기. 튜토리얼을 살펴보세요.
- OpenTSDB 통합으로 시계열 데이터를 모니터링하는 방법을 알아봅니다.