
1. Introduction
In this codelab, you'll get introduced to using Cloud Bigtable with the Java HBase client.
You'll learn how to
- Avoid common mistakes with schema design
- Import data in a sequence file
- Query your data
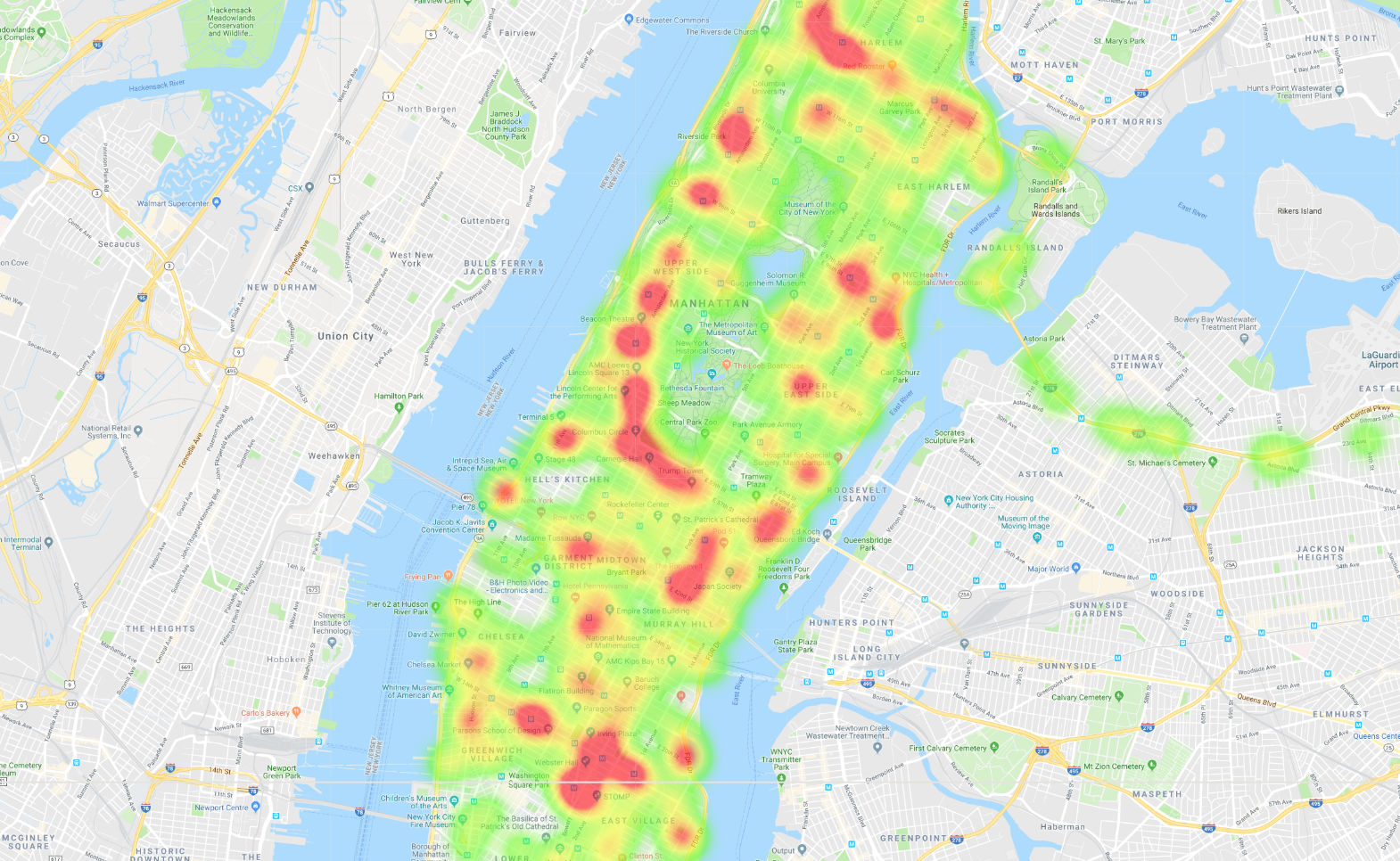
When you're done, you'll have several maps that show New York City bus data. For example, you'll create this heatmap of bus trips in Manhattan:
How would you rate your experience with using Google Cloud Platform?
How will you use this tutorial?
2. About the dataset
You'll be looking at a dataset about New York City buses. There are more than 300 bus routes and 5,800 vehicles following those routes. Our dataset is a log that includes destination name, vehicle id, latitude, longitude, expected arrival time, and scheduled arrival time. The dataset is made up of snapshots taken around every 10 minutes for June 2017.
3. Schema design
To get the best performance from Cloud Bigtable, you have to be thoughtful when you design your schema. Data in Cloud Bigtable is automatically sorted lexicographically, so if you design your schema well, querying for related data is very efficient. Cloud Bigtable allows for queries using point lookups by row key or row-range scans that return a contiguous set of rows. However, if your schema isn't well thought out, you might find yourself piecing together multiple row lookups, or worse, doing full table scans, which are extremely slow operations.
Plan out the queries
Our data has a variety of information, but for this codelab, you will use the location and destination of the bus.
With that information, you could perform these queries:
- Get the location of a single bus over a given hour.
- Get a day's worth of data for a bus line or specific bus.
- Find all the buses in a rectangle on a map.
- Get the current locations of all the buses (if you were ingesting this data in real time).
This set of queries can't all be done together optimally. For example, if you are sorting by time, you can't do a scan based on a location without doing a full table scan. You need to prioritize based on the queries you most commonly run.
For this codelab, you'll focus on optimizing and executing the following set of queries:
- Get the locations of a specific vehicle over an hour.
- Get the locations of an entire bus line over an hour.
- Get the locations of all buses in Manhattan in an hour.
- Get the most recent locations of all buses in Manhattan in an hour.
- Get the locations of an entire bus line over the month.
- Get the locations of an entire bus line with a certain destination over an hour.
Design the row key
For this codelab, you will be working with a static dataset, but you will design a schema for scalability. You'll design a schema that allows you to stream more bus data into the table and still perform well.
Here is the proposed schema for the row key:
[Bus company/Bus line/Timestamp rounded down to the hour/Vehicle ID]. Each row has an hour of data, and each cell holds multiple time-stamped versions of the data.
For this codelab, you will use one column family to keep things simple. Here is an example view of what the data looks like. The data is sorted by row key.
Row key | cf:VehicleLocation.Latitude | cf:VehicleLocation.Longitude | ... |
MTA/M86-SBS/1496275200000/NYCT_5824 | 40.781212 @20:52:54.0040.776163 @20:43:19.0040.778714 @20:33:46.00 | -73.961942 @20:52:54.00-73.946949 @20:43:19.00-73.953731 @20:33:46.00 | ... |
MTA/M86-SBS/1496275200000/NYCT_5840 | 40.780664 @20:13:51.0040.788416 @20:03:40.00 | -73.958357 @20:13:51.00 -73.976748 @20:03:40.00 | ... |
MTA/M86-SBS/1496275200000/NYCT_5867 | 40.780281 @20:51:45.0040.779961 @20:43:15.0040.788416 @20:33:44.00 | -73.946890 @20:51:45.00-73.959465 @20:43:15.00-73.976748 @20:33:44.00 | ... |
... | ... | ... | ... |
4. Create instance, table, and family
Next, you'll create a Cloud Bigtable table.
First, create a new project. Use the built-in Cloud Shell, which you can open by clicking the "Activate Cloud Shell" button in the upper-righthand corner.
Set the following environment variables to make copying and pasting the codelab commands easier:
INSTANCE_ID="bus-instance" CLUSTER_ID="bus-cluster" TABLE_ID="bus-data" CLUSTER_NUM_NODES=3 CLUSTER_ZONE="us-central1-c"
Cloud Shell comes with the tools that you'll use in this codelab, the gcloud command-line tool, the cbt command-line interface, and Maven, already installed.
Enable the Cloud Bigtable APIs by running this command.
gcloud services enable bigtable.googleapis.com bigtableadmin.googleapis.com
Create an instance by running the following command:
gcloud bigtable instances create $INSTANCE_ID \
--cluster=$CLUSTER_ID \
--cluster-zone=$CLUSTER_ZONE \
--cluster-num-nodes=$CLUSTER_NUM_NODES \
--display-name=$INSTANCE_ID
After you create the instance, populate the cbt configuration file and then create a table and column family by running the following commands:
echo project = $GOOGLE_CLOUD_PROJECT > ~/.cbtrc echo instance = $INSTANCE_ID >> ~/.cbtrc cbt createtable $TABLE_ID cbt createfamily $TABLE_ID cf
5. Import data
Import a set of sequence files for this codelab from gs://cloud-bigtable-public-datasets/bus-data with the following steps:
Enable the Cloud Dataflow API by running this command.
gcloud services enable dataflow.googleapis.com
Run the following commands to import the table.
NUM_WORKERS=$(expr 3 \* $CLUSTER_NUM_NODES) gcloud beta dataflow jobs run import-bus-data-$(date +%s) \ --gcs-location gs://dataflow-templates/latest/GCS_SequenceFile_to_Cloud_Bigtable \ --num-workers=$NUM_WORKERS --max-workers=$NUM_WORKERS \ --parameters bigtableProject=$GOOGLE_CLOUD_PROJECT,bigtableInstanceId=$INSTANCE_ID,bigtableTableId=$TABLE_ID,sourcePattern=gs://cloud-bigtable-public-datasets/bus-data/*
Monitor the import
You can monitor the job in the Cloud Dataflow UI. Also, you can view the load on your Cloud Bigtable instance with its monitoring UI. It should take 5 minutes for the entire import.
6. Get the code
git clone https://github.com/googlecodelabs/cbt-intro-java.git cd cbt-intro-java
Change to Java 11 by running the following commands:
sudo update-java-alternatives -s java-1.11.0-openjdk-amd64 && export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64/
7. Perform a lookup
The first query you'll perform is a simple row lookup. You'll get the data for a bus on the M86-SBS line on June 1, 2017 from 12:00 am to 1:00 am. A vehicle with id NYCT_5824 is on the bus line then.
With that information, and knowing the schema design (Bus company/Bus line/Timestamp rounded down to the hour/Vehicle ID,) you can deduce that the row key is:
MTA/M86-SBS/1496275200000/NYCT_5824
BusQueries.java
private static final byte[] COLUMN_FAMILY_NAME = Bytes.toBytes("cf");
private static final byte[] LAT_COLUMN_NAME = Bytes.toBytes("VehicleLocation.Latitude");
private static final byte[] LONG_COLUMN_NAME = Bytes.toBytes("VehicleLocation.Longitude");
String rowKey = "MTA/M86-SBS/1496275200000/NYCT_5824";
Result getResult =
table.get(
new Get(Bytes.toBytes(rowKey))
.addColumn(COLUMN_FAMILY_NAME, LAT_COLUMN_NAME)
.addColumn(COLUMN_FAMILY_NAME, LONG_COLUMN_NAME));
The result should contain the most recent location of the bus within that hour. But you want to see all the locations, so set the maximum number of versions on the get request.
BusQueries.java
Result getResult =
table.get(
new Get(Bytes.toBytes(rowKey))
.setMaxVersions(Integer.MAX_VALUE)
.addColumn(COLUMN_FAMILY_NAME, LAT_COLUMN_NAME)
.addColumn(COLUMN_FAMILY_NAME, LONG_COLUMN_NAME));
In the Cloud Shell, run the following command to get a list of latitudes and longitudes for that bus over the hour:
mvn package exec:java -Dbigtable.projectID=$GOOGLE_CLOUD_PROJECT \ -Dbigtable.instanceID=$INSTANCE_ID -Dbigtable.table=$TABLE_ID \ -Dquery=lookupVehicleInGivenHour
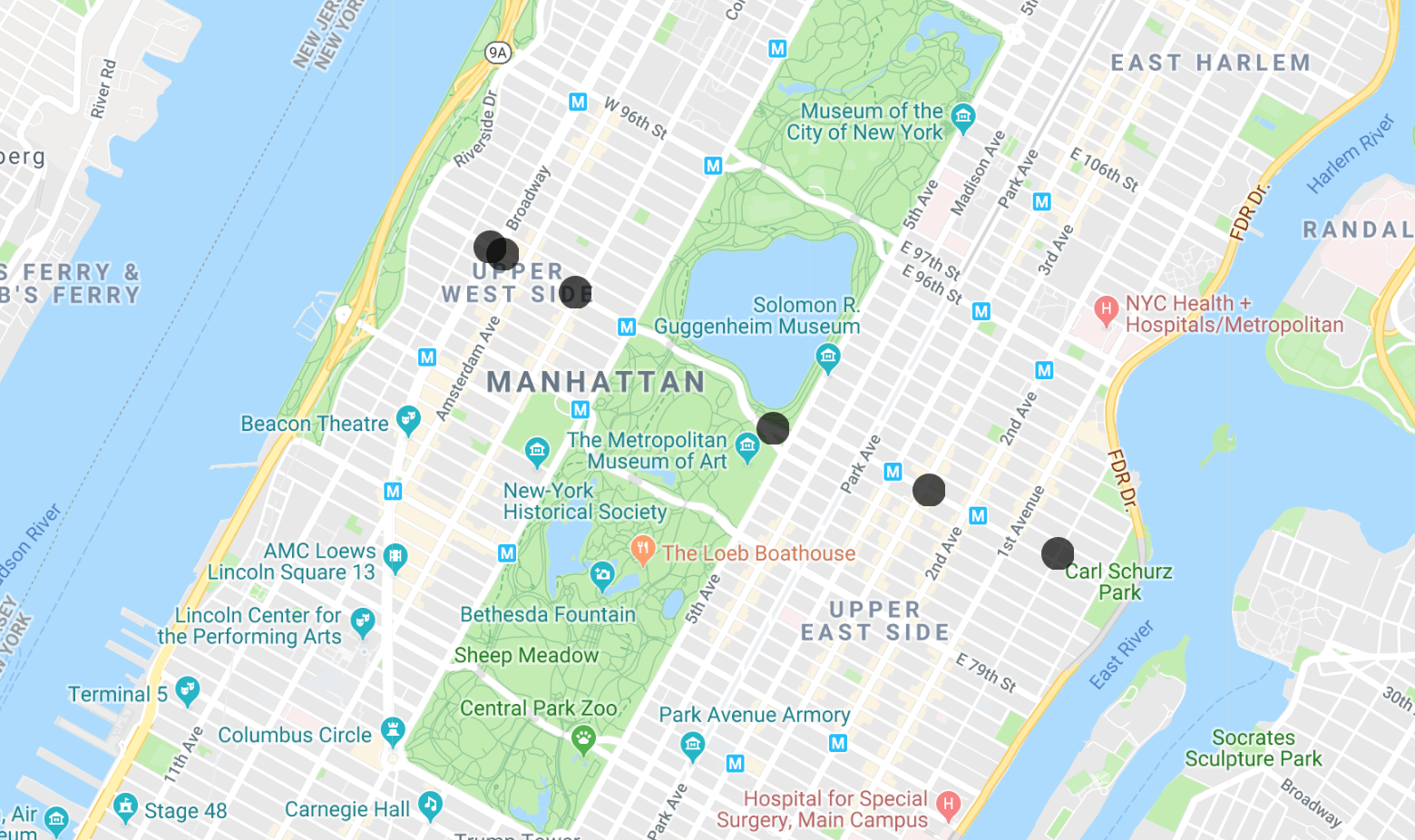
You can copy and paste the latitudes and longitudes into MapMaker App to visualize the results. After a few layers, it will tell you to create a free account. You can create an account or just delete the existing layers you have. This codelab includes a visualization for each step, if you just want to follow along. Here is the result for this first query:
8. Perform a scan
Now, let's view all the data for the bus line for that hour. The scan code looks pretty similar to the get code. You give the scanner a starting position and then indicate you only want rows for the M86-SBS bus line within the hour denoted by the timestamp 1496275200000.
BusQueries.java
Scan scan;
scan = new Scan();
scan.setMaxVersions(Integer.MAX_VALUE)
.addColumn(COLUMN_FAMILY_NAME, LAT_COLUMN_NAME)
.addColumn(COLUMN_FAMILY_NAME, LONG_COLUMN_NAME)
.withStartRow(Bytes.toBytes("MTA/M86-SBS/1496275200000"))
.setRowPrefixFilter(Bytes.toBytes("MTA/M86-SBS/1496275200000"));
ResultScanner scanner = table.getScanner(scan);
Run the following command to get the results.
mvn package exec:java -Dbigtable.projectID=$GOOGLE_CLOUD_PROJECT \ -Dbigtable.instanceID=$INSTANCE_ID -Dbigtable.table=$TABLE_ID \ -Dquery=scanBusLineInGivenHour
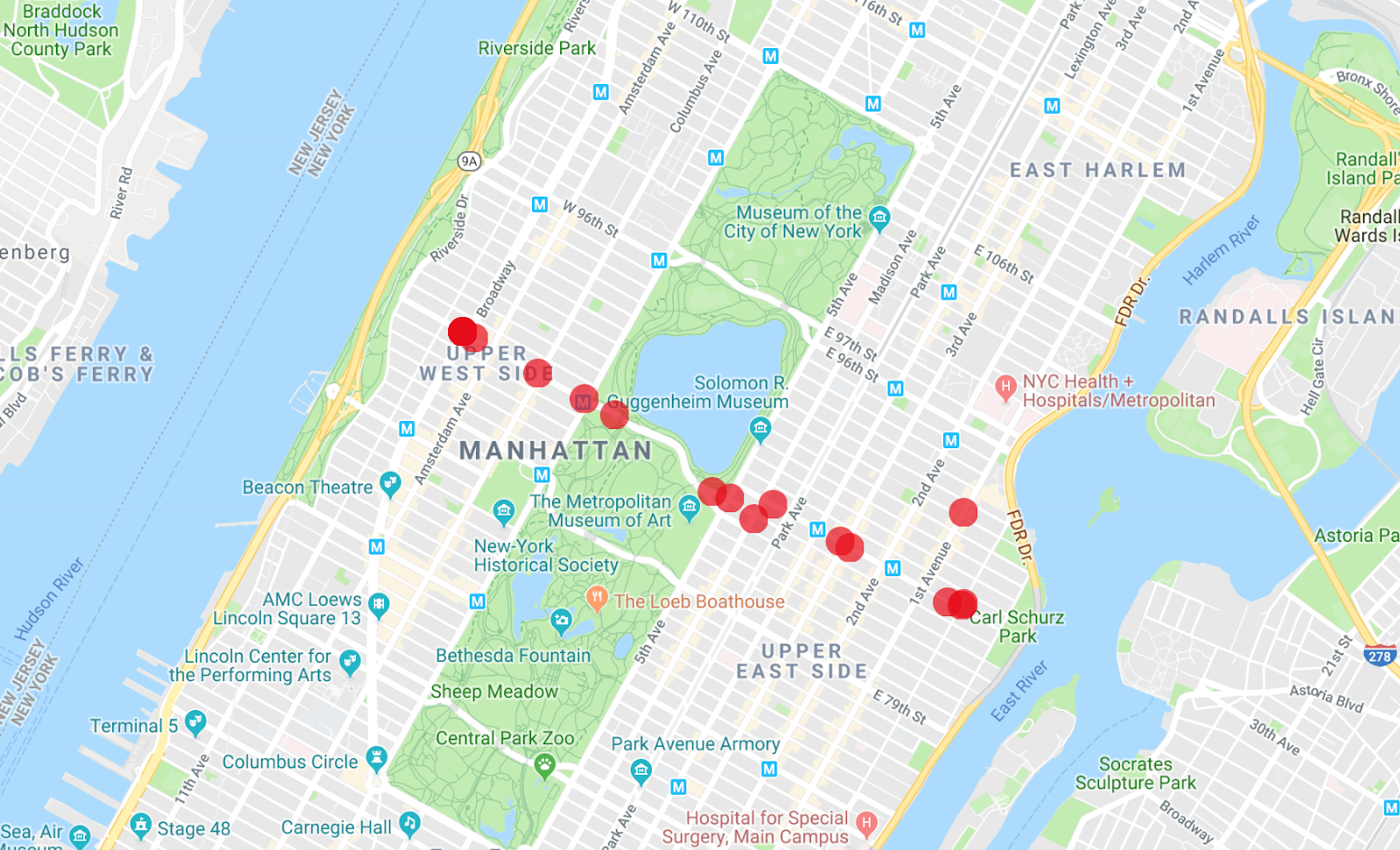
The Map Maker app can display multiple lists at once, so you can see which of the buses are the vehicle from the first query you ran.
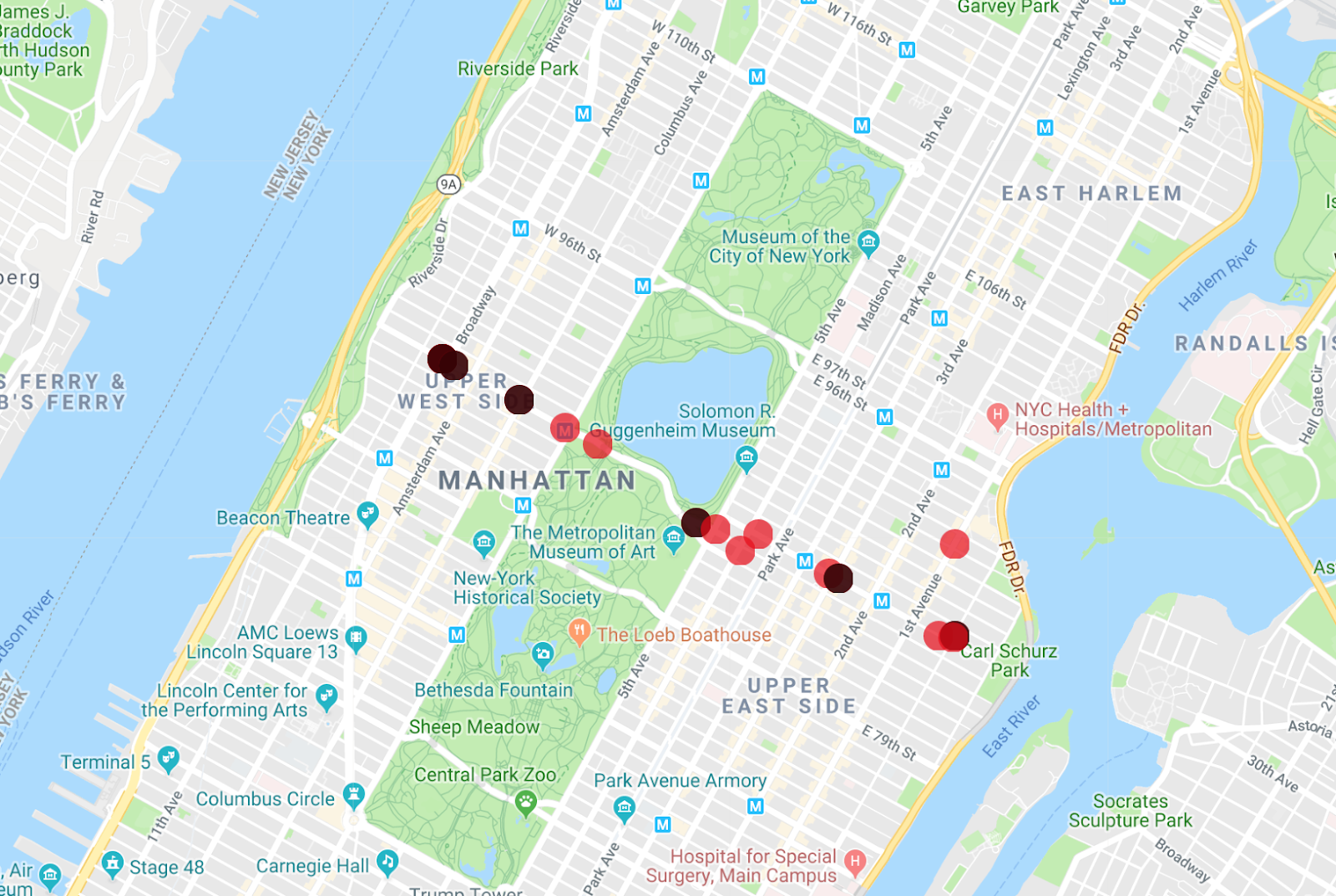
An interesting modification to this query is to view the entire month of data for the M86-SBS bus line, and this is very easy to do. Remove the timestamp from the start row and prefix filter to get the result.
BusQueries.java
scan.withStartRow(Bytes.toBytes("MTA/M86-SBS/"))
.setRowPrefixFilter(Bytes.toBytes("MTA/M86-SBS/"));
// Optionally, reduce the results to receive one version per column
// since there are so many data points.
scan.setMaxVersions(1);
Run the following command to get the results. (There will be a long list of results.)
mvn package exec:java -Dbigtable.projectID=$GOOGLE_CLOUD_PROJECT \ -Dbigtable.instanceID=$INSTANCE_ID -Dbigtable.table=$TABLE_ID \ -Dquery=scanEntireBusLine
If you copy the results into MapMaker, you can view a heatmap of the bus route. The orange blobs indicate the stops, and the bright red blobs are the start and end of the route.
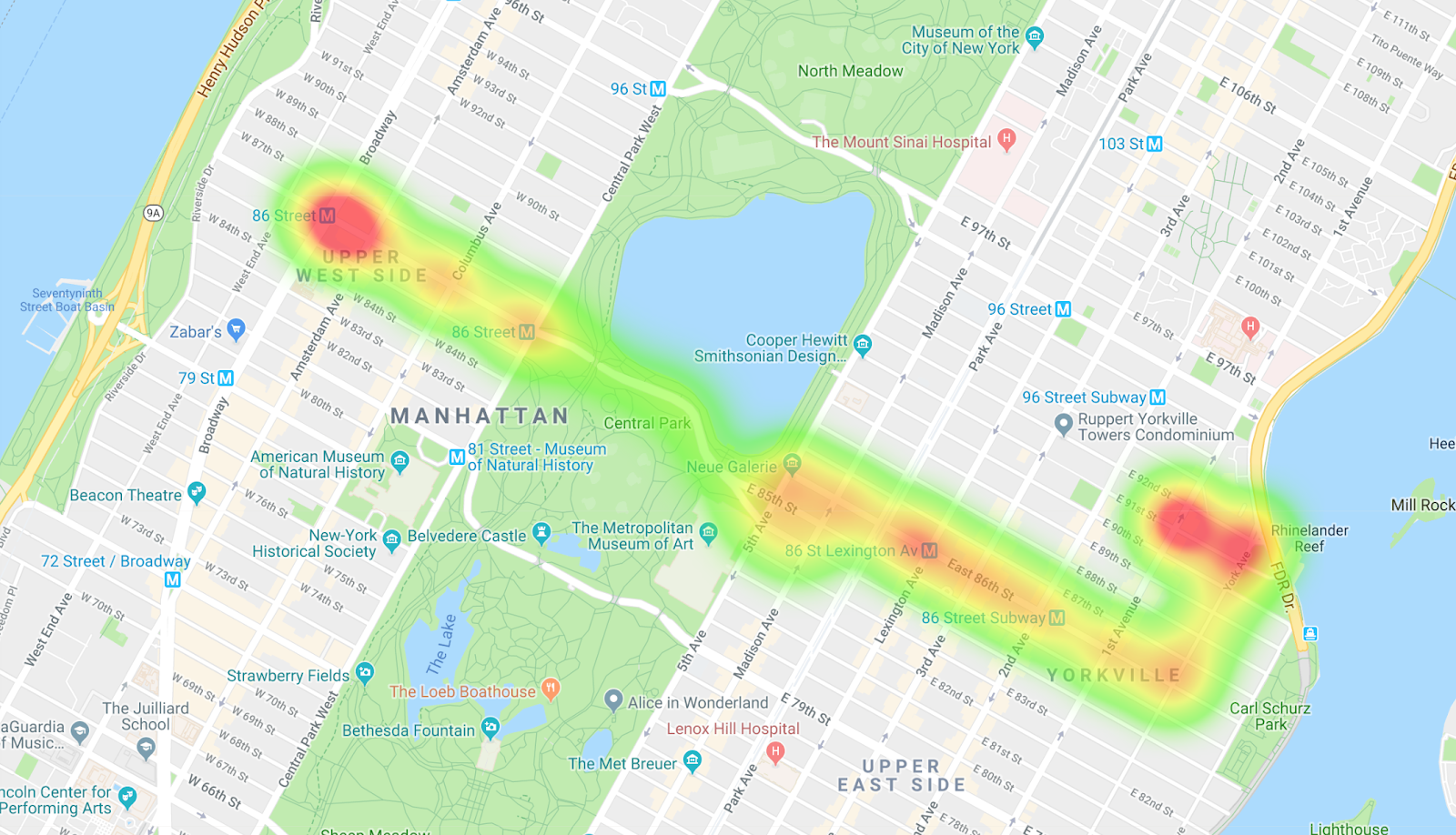
9. Introduce filters
Next, you will filter on buses heading east and buses heading west, and create a separate heatmap for each.
BusQueries.java
Scan scan;
ResultScanner scanner;
scan = new Scan();
SingleColumnValueFilter valueFilter =
new SingleColumnValueFilter(
COLUMN_FAMILY_NAME,
Bytes.toBytes("DestinationName"),
CompareOp.EQUAL,
Bytes.toBytes("Select Bus Service Yorkville East End AV"));
scan.setMaxVersions(1)
.addColumn(COLUMN_FAMILY_NAME, LAT_COLUMN_NAME)
.addColumn(COLUMN_FAMILY_NAME, LONG_COLUMN_NAME);
scan.withStartRow(Bytes.toBytes("MTA/M86-SBS/"))
.setRowPrefixFilter(Bytes.toBytes("MTA/M86-SBS/"));
scan.setFilter(valueFilter);
scanner = table.getScanner(scan);
Run the following command to get the results for buses going east.
mvn package exec:java -Dbigtable.projectID=$GOOGLE_CLOUD_PROJECT \ -Dbigtable.instanceID=$INSTANCE_ID -Dbigtable.table=$TABLE_ID \ -Dquery=filterBusesGoingEast
To get the buses going west, change the string in the valueFilter:
BusQueries.java
SingleColumnValueFilter valueFilter =
new SingleColumnValueFilter(
COLUMN_FAMILY_NAME,
Bytes.toBytes("DestinationName"),
CompareOp.EQUAL,
Bytes.toBytes("Select Bus Service Westside West End AV"));
Run the following command to get the results for buses going west.
mvn package exec:java -Dbigtable.projectID=$GOOGLE_CLOUD_PROJECT \ -Dbigtable.instanceID=$INSTANCE_ID -Dbigtable.table=$TABLE_ID \ -Dquery=filterBusesGoingWest
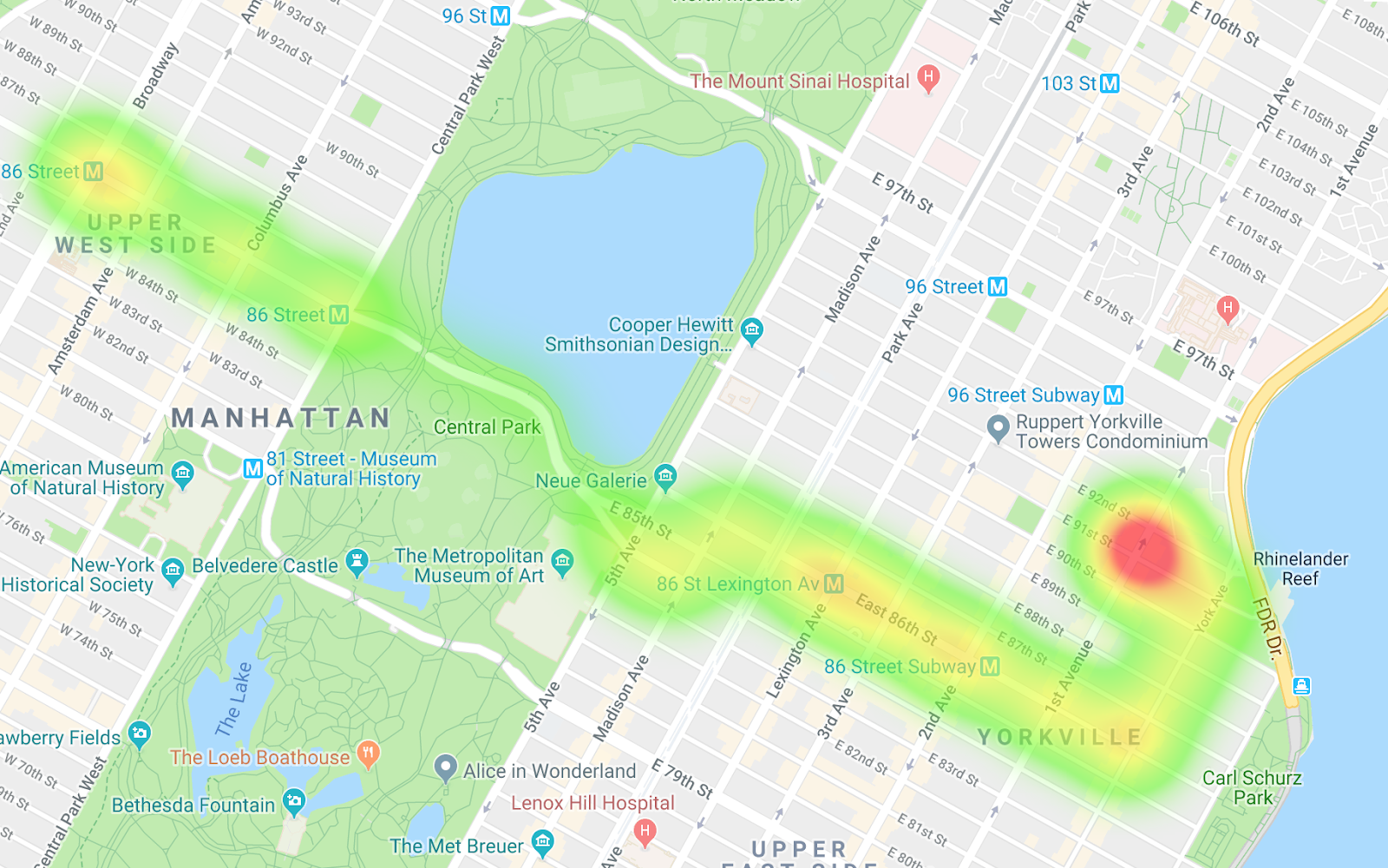
Buses heading east
Buses heading west
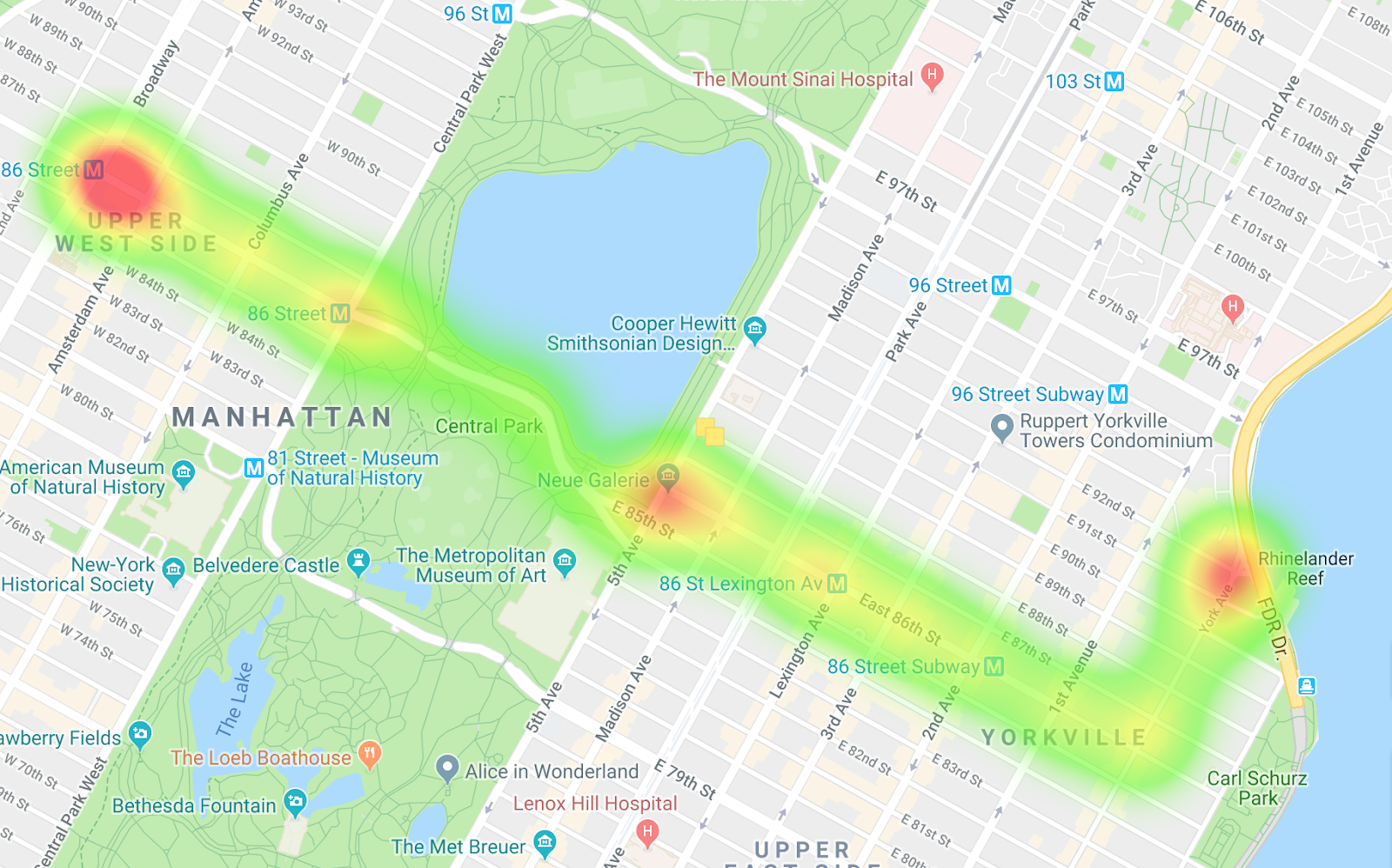
By comparing the two heatmaps, you can see the differences in the routes as well as notice differences in the pacing. One interpretation of the data is that on the route heading west, the buses are getting stopped more, especially when entering Central Park. And on the buses heading east, you don't really see many choke points.
10. Perform a multi-range scan
For the final query, you'll address the case when you care about many bus lines in an area:
BusQueries.java
private static final String[] MANHATTAN_BUS_LINES = {"M1","M2","M3",...
Scan scan;
ResultScanner scanner;
List<RowRange> ranges = new ArrayList<>();
for (String busLine : MANHATTAN_BUS_LINES) {
ranges.add(
new RowRange(
Bytes.toBytes("MTA/" + busLine + "/1496275200000"), true,
Bytes.toBytes("MTA/" + busLine + "/1496275200001"), false));
}
Filter filter = new MultiRowRangeFilter(ranges);
scan = new Scan();
scan.setFilter(filter);
scan.setMaxVersions(Integer.MAX_VALUE)
.addColumn(COLUMN_FAMILY_NAME, LAT_COLUMN_NAME)
.addColumn(COLUMN_FAMILY_NAME, LONG_COLUMN_NAME);
scan.withStartRow(Bytes.toBytes("MTA/M")).setRowPrefixFilter(Bytes.toBytes("MTA/M"));
scanner = table.getScanner(scan);
Run the following command to get the results.
mvn package exec:java -Dbigtable.projectID=$GOOGLE_CLOUD_PROJECT \ -Dbigtable.instanceID=$INSTANCE_ID -Dbigtable.table=$TABLE_ID \ -Dquery=scanManhattanBusesInGivenHour
11. Finish up
Clean up to avoid charges
To avoid incurring charges to your Google Cloud Platform account for the resources used in this codelab you should delete your instance.
gcloud bigtable instances delete $INSTANCE_ID
What we've covered
- Schema design
- Setting up an instance, table, and family
- Importing sequence files with dataflow
- Querying with a lookup, a scan, a scan with a filter, and a multi-range scan
Next steps
- Learn more about Cloud Bigtable in the documentation.
- Try out other Google Cloud Platform features for yourself. Have a look at our tutorials.
- Learn how to monitor time-series data with the OpenTSDB integration