
1. Introducción
En este codelab, se te presentará el uso de Cloud Bigtable con el cliente de HBase de Java.
Obtendrás información para hacer las siguientes acciones
- Evita errores comunes en el diseño de esquemas
- Importa datos en un archivo de secuencia
- Consulta tus datos
Cuando termines, tendrás varios mapas que mostrarán los datos de los autobuses de la ciudad de Nueva York. Por ejemplo, crearás este mapa de calor de los viajes en autobús en Manhattan:

¿Cómo calificarías tu experiencia con el uso de Google Cloud Platform?
¿Cómo usarás este instructivo?
2. Acerca del conjunto de datos
Verás un conjunto de datos sobre los autobuses de la ciudad de Nueva York. Hay más de 300 rutas de autobús y 5,800 vehículos que las siguen. Nuestro conjunto de datos es un registro que incluye el nombre del destino, el ID del vehículo, la latitud, la longitud, la hora de llegada esperada y la hora de llegada programada. El conjunto de datos se compone de instantáneas tomadas cada 10 minutos aproximadamente durante junio de 2017.
3. Diseño de esquemas
Para obtener el mejor rendimiento de Cloud Bigtable, debes ser cuidadoso cuando diseñes tu esquema. Los datos en Cloud Bigtable se ordenan automáticamente de forma lexicográfica, por lo que, si diseñas bien tu esquema, la consulta de datos relacionados es muy eficiente. Cloud Bigtable permite realizar consultas con búsquedas de puntos por clave de fila o análisis de rangos de filas que devuelven un conjunto contiguo de filas. Sin embargo, si tu esquema no está bien pensado, es posible que debas unir varias búsquedas de filas o, peor aún, realizar análisis de tablas completas, que son operaciones extremadamente lentas.
Planifica las consultas
Nuestros datos contienen una gran variedad de información, pero, para este codelab, usarás la ubicación y el destino del autobús.
Con esa información, podrías realizar las siguientes búsquedas:
- Obtén la ubicación de un solo autobús durante una hora determinada.
- Obtén datos de un día para una línea de autobús o un autobús específico.
- Encuentra todos los autobuses que se encuentran dentro de un rectángulo en un mapa.
- Obtener las ubicaciones actuales de todos los autobuses (si estuvieras transfiriendo estos datos en tiempo real)
Este conjunto de consultas no se puede realizar de forma óptima en conjunto. Por ejemplo, si ordenas por hora, no puedes realizar un análisis basado en una ubicación sin realizar un análisis de tabla completo. Debes priorizar en función de las consultas que ejecutas con mayor frecuencia.
En este codelab, te enfocarás en optimizar y ejecutar el siguiente conjunto de consultas:
- Obtén las ubicaciones de un vehículo específico durante una hora.
- Obtener las ubicaciones de toda una línea de autobús durante una hora
- Obtener las ubicaciones de todos los autobuses de Manhattan en una hora
- Obtener las ubicaciones más recientes de todos los autobuses de Manhattan en una hora
- Obtener las ubicaciones de toda una línea de autobús durante el mes
- Obtener las ubicaciones de toda una línea de autobús con un destino determinado durante una hora
Diseña la clave de fila
En este codelab, trabajarás con un conjunto de datos estático, pero diseñarás un esquema para la escalabilidad. Diseñarás un esquema que te permita transmitir más datos de autobuses a la tabla y seguir teniendo un buen rendimiento.
A continuación, se muestra el esquema propuesto para la clave de fila:
[Empresa de autobús/Línea de autobús/Marca de tiempo redondeada a la hora/ID del vehículo]. Cada fila tiene una hora de datos, y cada celda contiene varias versiones de los datos con marca de tiempo.
En este codelab, usarás una familia de columnas para simplificar las cosas. A continuación, se muestra un ejemplo de cómo se ven los datos. Los datos se ordenan por clave de fila.
Clave de fila | cf:VehicleLocation.Latitude | cf:VehicleLocation.Longitude | … |
MTA/M86-SBS/1496275200000/NYCT_5824 | 40.781212 @20:52:54.0040.776163 @20:43:19.0040.778714 @20:33:46.00 | -73.961942 @20:52:54.00-73.946949 @20:43:19.00-73.953731 @20:33:46.00 | … |
MTA/M86-SBS/1496275200000/NYCT_5840 | 40.780664 @20:13:51.0040.788416 @20:03:40.00 | -73.958357 @20:13:51.00 -73.976748 @20:03:40.00 | … |
MTA/M86-SBS/1496275200000/NYCT_5867 | 40.780281 @20:51:45.0040.779961 @20:43:15.0040.788416 @20:33:44.00 | -73.946890 @20:51:45.00-73.959465 @20:43:15.00-73.976748 @20:33:44.00 | … |
… | … | … | … |
4. Crea una instancia, una tabla y una familia
A continuación, crearás una tabla de Cloud Bigtable.
Primero, crea un proyecto nuevo. Usa Cloud Shell integrado, que puedes abrir haciendo clic en el botón "Activar Cloud Shell" en la esquina superior derecha.

Configura las siguientes variables de entorno para facilitar la copia y el pegado de los comandos del codelab:
INSTANCE_ID="bus-instance" CLUSTER_ID="bus-cluster" TABLE_ID="bus-data" CLUSTER_NUM_NODES=3 CLUSTER_ZONE="us-central1-c"
Cloud Shell ya viene instalado con las herramientas que usarás en este codelab, la herramienta de línea de comandos de gcloud, la interfaz de línea de comandos de cbt y Maven.
Ejecuta este comando para habilitar las APIs de Cloud Bigtable.
gcloud services enable bigtable.googleapis.com bigtableadmin.googleapis.com
Ejecuta el siguiente comando para crear una instancia:
gcloud bigtable instances create $INSTANCE_ID \
--cluster=$CLUSTER_ID \
--cluster-zone=$CLUSTER_ZONE \
--cluster-num-nodes=$CLUSTER_NUM_NODES \
--display-name=$INSTANCE_ID
Después de crear la instancia, propaga el archivo de configuración de cbt y, luego, crea una tabla y una familia de columnas ejecutando los siguientes comandos:
echo project = $GOOGLE_CLOUD_PROJECT > ~/.cbtrc echo instance = $INSTANCE_ID >> ~/.cbtrc cbt createtable $TABLE_ID cbt createfamily $TABLE_ID cf
5. Importar datos
Importa un conjunto de archivos de secuencia para este codelab desde gs://cloud-bigtable-public-datasets/bus-data con los siguientes pasos:
Ejecuta este comando para habilitar la API de Cloud Dataflow.
gcloud services enable dataflow.googleapis.com
Ejecuta los siguientes comandos para importar la tabla.
NUM_WORKERS=$(expr 3 \* $CLUSTER_NUM_NODES) gcloud beta dataflow jobs run import-bus-data-$(date +%s) \ --gcs-location gs://dataflow-templates/latest/GCS_SequenceFile_to_Cloud_Bigtable \ --num-workers=$NUM_WORKERS --max-workers=$NUM_WORKERS \ --parameters bigtableProject=$GOOGLE_CLOUD_PROJECT,bigtableInstanceId=$INSTANCE_ID,bigtableTableId=$TABLE_ID,sourcePattern=gs://cloud-bigtable-public-datasets/bus-data/*
Supervisa la importación
Puedes supervisar el trabajo en la IU de Cloud Dataflow. Además, puedes ver la carga en tu instancia de Cloud Bigtable con su IU de supervisión. La importación completa debería tardar 5 minutos.
6. Obtén el código
git clone https://github.com/googlecodelabs/cbt-intro-java.git cd cbt-intro-java
Ejecuta los siguientes comandos para cambiar a Java 11:
sudo update-java-alternatives -s java-1.11.0-openjdk-amd64 && export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64/
7. Cómo realizar una búsqueda
La primera consulta que realizarás es una simple búsqueda de filas. Obtendrás los datos de un autobús de la línea M86-SBS el 1 de junio de 2017, de las 12:00 a.m. a la 1:00 a.m. En ese momento, un vehículo con el ID NYCT_5824 se encuentra en la línea de autobús.
Con esa información y conociendo el diseño del esquema (Empresa de autobús/Línea de autobús/Marca de tiempo redondeada a la hora/ID del vehículo), puedes deducir que la clave de fila es la siguiente:
MTA/M86-SBS/1496275200000/NYCT_5824
BusQueries.java
private static final byte[] COLUMN_FAMILY_NAME = Bytes.toBytes("cf");
private static final byte[] LAT_COLUMN_NAME = Bytes.toBytes("VehicleLocation.Latitude");
private static final byte[] LONG_COLUMN_NAME = Bytes.toBytes("VehicleLocation.Longitude");
String rowKey = "MTA/M86-SBS/1496275200000/NYCT_5824";
Result getResult =
table.get(
new Get(Bytes.toBytes(rowKey))
.addColumn(COLUMN_FAMILY_NAME, LAT_COLUMN_NAME)
.addColumn(COLUMN_FAMILY_NAME, LONG_COLUMN_NAME));
El resultado debe contener la ubicación más reciente del autobús dentro de esa hora. Sin embargo, quieres ver todas las ubicaciones, por lo que debes establecer la cantidad máxima de versiones en la solicitud get.
BusQueries.java
Result getResult =
table.get(
new Get(Bytes.toBytes(rowKey))
.setMaxVersions(Integer.MAX_VALUE)
.addColumn(COLUMN_FAMILY_NAME, LAT_COLUMN_NAME)
.addColumn(COLUMN_FAMILY_NAME, LONG_COLUMN_NAME));
En Cloud Shell, ejecuta el siguiente comando para obtener una lista de las latitudes y longitudes de ese autobús durante la hora:
mvn package exec:java -Dbigtable.projectID=$GOOGLE_CLOUD_PROJECT \ -Dbigtable.instanceID=$INSTANCE_ID -Dbigtable.table=$TABLE_ID \ -Dquery=lookupVehicleInGivenHour
Puedes copiar y pegar las latitudes y longitudes en la app de MapMaker para visualizar los resultados. Después de algunas capas, te pedirá que crees una cuenta gratuita. Puedes crear una cuenta o simplemente borrar las capas existentes que tengas. Este codelab incluye una visualización para cada paso, en caso de que solo quieras seguir el proceso. Este es el resultado de la primera búsqueda:

8. Cómo realizar un análisis
Ahora, veamos todos los datos de la línea de autobús para esa hora. El código de escaneo se parece bastante al código de obtención. Le indicas al escáner una posición inicial y, luego, le indicas que solo quieres filas para la línea de autobús M86-SBS dentro de la hora indicada por la marca de tiempo 1496275200000.
BusQueries.java
Scan scan;
scan = new Scan();
scan.setMaxVersions(Integer.MAX_VALUE)
.addColumn(COLUMN_FAMILY_NAME, LAT_COLUMN_NAME)
.addColumn(COLUMN_FAMILY_NAME, LONG_COLUMN_NAME)
.withStartRow(Bytes.toBytes("MTA/M86-SBS/1496275200000"))
.setRowPrefixFilter(Bytes.toBytes("MTA/M86-SBS/1496275200000"));
ResultScanner scanner = table.getScanner(scan);
Ejecuta el siguiente comando para obtener los resultados.
mvn package exec:java -Dbigtable.projectID=$GOOGLE_CLOUD_PROJECT \ -Dbigtable.instanceID=$INSTANCE_ID -Dbigtable.table=$TABLE_ID \ -Dquery=scanBusLineInGivenHour
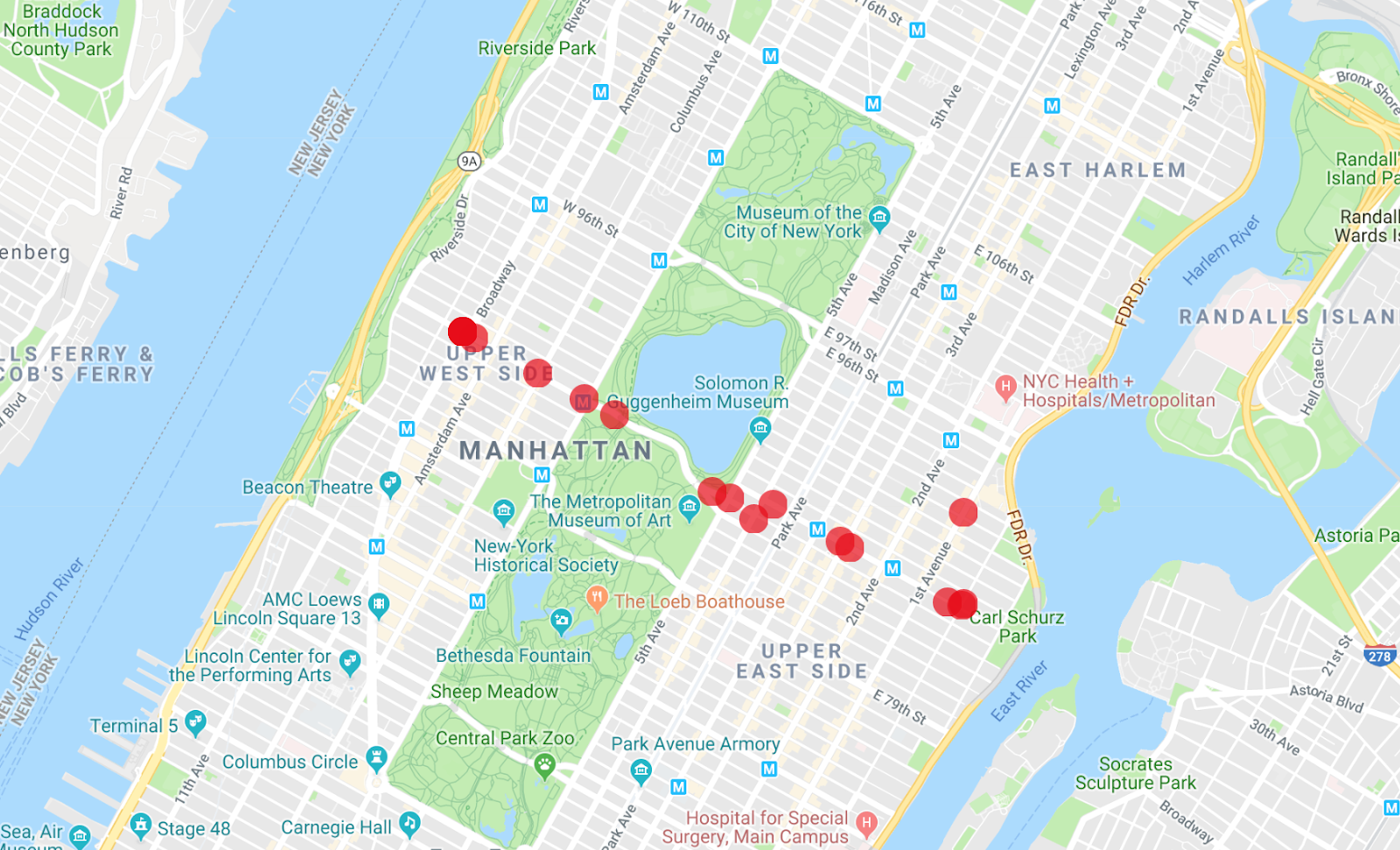
La app de Map Maker puede mostrar varias listas a la vez, por lo que puedes ver cuáles de los autobuses son el vehículo de la primera búsqueda que realizaste.

Una modificación interesante de esta consulta es ver el mes completo de datos de la línea de autobús M86-SBS, lo que es muy fácil de hacer. Quita la marca de tiempo del filtro de prefijo y de la fila inicial para obtener el resultado.
BusQueries.java
scan.withStartRow(Bytes.toBytes("MTA/M86-SBS/"))
.setRowPrefixFilter(Bytes.toBytes("MTA/M86-SBS/"));
// Optionally, reduce the results to receive one version per column
// since there are so many data points.
scan.setMaxVersions(1);
Ejecuta el siguiente comando para obtener los resultados. (Aparecerá una larga lista de resultados).
mvn package exec:java -Dbigtable.projectID=$GOOGLE_CLOUD_PROJECT \ -Dbigtable.instanceID=$INSTANCE_ID -Dbigtable.table=$TABLE_ID \ -Dquery=scanEntireBusLine
Si copias los resultados en Map Maker, puedes ver un mapa de calor de la ruta de autobús. Las manchas naranjas indican las paradas, y las manchas rojas brillantes son el inicio y el final de la ruta.

9. Presentamos los filtros
A continuación, filtrarás los autobuses que se dirigen hacia el este y los que se dirigen hacia el oeste, y crearás un mapa de calor independiente para cada uno.
BusQueries.java
Scan scan;
ResultScanner scanner;
scan = new Scan();
SingleColumnValueFilter valueFilter =
new SingleColumnValueFilter(
COLUMN_FAMILY_NAME,
Bytes.toBytes("DestinationName"),
CompareOp.EQUAL,
Bytes.toBytes("Select Bus Service Yorkville East End AV"));
scan.setMaxVersions(1)
.addColumn(COLUMN_FAMILY_NAME, LAT_COLUMN_NAME)
.addColumn(COLUMN_FAMILY_NAME, LONG_COLUMN_NAME);
scan.withStartRow(Bytes.toBytes("MTA/M86-SBS/"))
.setRowPrefixFilter(Bytes.toBytes("MTA/M86-SBS/"));
scan.setFilter(valueFilter);
scanner = table.getScanner(scan);
Ejecuta el siguiente comando para obtener los resultados de los autobuses que van hacia el este.
mvn package exec:java -Dbigtable.projectID=$GOOGLE_CLOUD_PROJECT \ -Dbigtable.instanceID=$INSTANCE_ID -Dbigtable.table=$TABLE_ID \ -Dquery=filterBusesGoingEast
Para obtener los autobuses que van hacia el oeste, cambia la cadena en valueFilter:
BusQueries.java
SingleColumnValueFilter valueFilter =
new SingleColumnValueFilter(
COLUMN_FAMILY_NAME,
Bytes.toBytes("DestinationName"),
CompareOp.EQUAL,
Bytes.toBytes("Select Bus Service Westside West End AV"));
Ejecuta el siguiente comando para obtener los resultados de los autobuses que van hacia el oeste.
mvn package exec:java -Dbigtable.projectID=$GOOGLE_CLOUD_PROJECT \ -Dbigtable.instanceID=$INSTANCE_ID -Dbigtable.table=$TABLE_ID \ -Dquery=filterBusesGoingWest
Autobuses con dirección al este

Autobuses con dirección al oeste

Si comparas los dos mapas de calor, puedes ver las diferencias en las rutas y en el ritmo. Una interpretación de los datos es que, en la ruta hacia el oeste, los autobuses se detienen más, especialmente cuando ingresan a Central Park. Y en los autobuses que se dirigen hacia el este, no se ven muchos puntos de congestión.
10. Realiza un análisis de varios rangos
Para la consulta final, abordarás el caso en el que te interesan muchas líneas de autobús en un área:
BusQueries.java
private static final String[] MANHATTAN_BUS_LINES = {"M1","M2","M3",...
Scan scan;
ResultScanner scanner;
List<RowRange> ranges = new ArrayList<>();
for (String busLine : MANHATTAN_BUS_LINES) {
ranges.add(
new RowRange(
Bytes.toBytes("MTA/" + busLine + "/1496275200000"), true,
Bytes.toBytes("MTA/" + busLine + "/1496275200001"), false));
}
Filter filter = new MultiRowRangeFilter(ranges);
scan = new Scan();
scan.setFilter(filter);
scan.setMaxVersions(Integer.MAX_VALUE)
.addColumn(COLUMN_FAMILY_NAME, LAT_COLUMN_NAME)
.addColumn(COLUMN_FAMILY_NAME, LONG_COLUMN_NAME);
scan.withStartRow(Bytes.toBytes("MTA/M")).setRowPrefixFilter(Bytes.toBytes("MTA/M"));
scanner = table.getScanner(scan);
Ejecuta el siguiente comando para obtener los resultados.
mvn package exec:java -Dbigtable.projectID=$GOOGLE_CLOUD_PROJECT \ -Dbigtable.instanceID=$INSTANCE_ID -Dbigtable.table=$TABLE_ID \ -Dquery=scanManhattanBusesInGivenHour
11. Finaliza la tarea
Realiza una limpieza para evitar cargos
Para evitar que se apliquen cargos a tu cuenta de Google Cloud Platform por los recursos que usaste en este codelab, debes borrar la instancia.
gcloud bigtable instances delete $INSTANCE_ID
Temas abordados
- Diseño de esquemas
- Cómo configurar una instancia, una tabla y una familia
- Cómo importar archivos de secuencias con Dataflow
- Consultas con una búsqueda, un análisis, un análisis con un filtro y un análisis de varios rangos
Próximos pasos
- Obtén más información sobre Cloud Bigtable en la documentación.
- Prueba otras características de Google Cloud Platform tú mismo. Revisa nuestros instructivos.
- Aprende a supervisar datos de series temporales con la integración de OpenTSDB