
1. Genel Bakış

Dataflow nedir?
Dataflow, çeşitli veri işleme kalıplarını yürütmek için kullanılan yönetilen bir hizmettir. Bu sitedeki dokümanlarda, hizmet özelliklerinin kullanımıyla ilgili talimatlar da dahil olmak üzere, Dataflow'u kullanarak toplu ve akış veri işleme ardışık düzenlerinizi nasıl dağıtacağınız gösterilmektedir.
Apache Beam SDK, hem toplu işleme hem de akış ardışık düzenleri geliştirmenize olanak tanıyan açık kaynaklı bir programlama modelidir. Ardışık düzenlerinizi Apache Beam programıyla oluşturur ve ardından Dataflow hizmetinde çalıştırırsınız. Apache Beam dokümanlarında, Apache Beam programlama modeli, SDK'lar ve diğer çalıştırıcılar hakkında ayrıntılı kavramsal bilgiler ve referans materyalleri yer alır.
Hızlı akış verisi analizi
Dataflow daha düşük veri gecikmesiyle hızlı, basitleştirilmiş akış veri ardışık düzeni geliştirilebilmesini sağlar.
İşlemleri ve yönetimi basitleştirin
Dataflow'un sunucusuz yaklaşımı, veri mühendisliği iş yüklerindeki ek işlem yükünü ortadan kaldırır. Böylece ekiplerin sunucu kümelerini yönetmek yerine programlamaya zaman ayırabilmesini sağlayabilirsiniz.
Toplam mülkiyet maliyetini düşürme
Otomatik kaynak ölçeklendirme ile maliyet açısından optimize edilmiş toplu işlem özelliğinin bir arada sunulması, Dataflow'un sezonluk ve ani artışlar gösteren iş yüklerinizi aşırı harcama yapmadan yönetme konusunda neredeyse sınırsız bir kapasite sunduğu anlamına gelir.
Temel özellikler
Otomatik kaynak yönetimi ve dinamik iş dengeleme
Dataflow, gecikme süresini azaltmak ve kullanımı en üst düzeye çıkarmak için kaynak işleme süreçlerinin sağlanmasını ve yönetimini otomatik hale getirir. Böylece örnekleri hızla başlatmanıza veya elle ayırmanıza gerek kalmaz. İş bölümlendirme, geciken işleri dinamik olarak yeniden dengelemek için otomatik hale getirilmiş ve optimize edilmiştir. "Kısayol tuşları" aramanıza veya giriş verilerini önceden işlemenize gerek yoktur.
Yatay otomatik ölçeklendirme
Optimum işleme hızı için çalışan kaynaklarının yatay olarak otomatik ölçeklendirilmesi, genel fiyat-performans oranını iyileştirir.
Toplu işlem için esnek kaynak planlama fiyatlandırması
Gece devam etmesi gereken işlerde olduğu gibi iş planlama süresinde esneklik ile işlem yapmak için esnek kaynak planlama (FlexRS) imkanı, toplu işlem için daha düşük bir fiyat sunar. Bu esnek işler, altı saatlik süre içinde yürütmeye alınacakları garantisiyle bir kuyruğa yerleştirilir.
Bu eğitim, https://cloud.google.com/dataflow/docs/quickstarts/quickstart-java-maven adresinden uyarlanmıştır.
Neler öğreneceksiniz?
- Java SDK'yı kullanarak Apache Beam ile Maven projesi oluşturma
- Google Cloud Platform Console'u kullanarak örnek bir ardışık düzen çalıştırma
- İlişkili Cloud Storage paketini ve içeriklerini silme
Gerekenler
Bu eğitimi nasıl kullanacaksınız?
Google Cloud Platform hizmetlerini kullanma deneyiminizi nasıl değerlendirirsiniz?
2. Kurulum ve Gereksinimler
Yönlendirmesiz ortam kurulumu
- Cloud Console'da oturum açın ve yeni bir proje oluşturun veya mevcut bir projeyi yeniden kullanın. (Gmail veya G Suite hesabınız yoksa hesap oluşturmanız gerekir.)



Proje kimliğini unutmayın. Bu kimlik, tüm Google Cloud projelerinde benzersiz bir addır (Yukarıdaki ad zaten alınmış olduğundan sizin için çalışmayacaktır). Bu codelab'in ilerleyen kısımlarında PROJECT_ID olarak adlandırılacaktır.
- Ardından, Google Cloud kaynaklarını kullanmak için Cloud Console'da faturalandırmayı etkinleştirmeniz gerekir.
Bu codelab'i tamamlamak neredeyse hiç maliyetli değildir. Bu eğitimin ötesinde faturalandırma ücreti alınmaması için kaynakları nasıl kapatacağınız konusunda size tavsiyelerde bulunan "Temizleme" bölümündeki talimatları uyguladığınızdan emin olun. Google Cloud'un yeni kullanıcıları 300 ABD doları değerinde ücretsiz deneme programından yararlanabilir.
API'leri etkinleştirme
Ekranın sol üst kısmındaki menü simgesini tıklayın.

Açılır menüden API'ler ve Hizmetler > Kontrol Paneli'ni seçin.

+ API'leri ve Hizmetleri Etkinleştir'i seçin.

Arama kutusuna "Compute Engine" yazın. Görünen sonuç listesinde "Compute Engine API"yi tıklayın.

Google Compute Engine sayfasında Etkinleştir'i tıklayın.

Etkinleştirildikten sonra geri gitmek için oku tıklayın.
Şimdi aşağıdaki API'leri arayın ve bunları da etkinleştirin:
- Cloud Dataflow
- Stackdriver
- Cloud Storage
- Cloud Storage JSON
- BigQuery
- Cloud Pub/Sub
- Cloud Datastore
- Cloud Resource Manager API'leri
3. Yeni bir Cloud Storage paketi oluşturma
Google Cloud Platform Console'da ekranın sol üst kısmındaki Menü simgesini tıklayın:
Aşağı kaydırıp Storage alt bölümünde Cloud Storage > Tarayıcı'yı seçin:

Şimdi Cloud Storage Tarayıcısı'nı görmeniz gerekir. Şu anda Cloud Storage paketi içermeyen bir proje kullandığınızı varsayarsak yeni bir paket oluşturma daveti görürsünüz. Oluşturmak için Paket oluştur düğmesine basın:
Paketiniz için bir ad girin. İletişim kutusunda belirtildiği gibi, paket adları Cloud Storage'ın tamamında benzersiz olmalıdır. Bu nedenle, "test" gibi belirgin bir ad seçerseniz büyük olasılıkla başka bir kullanıcının bu adla bir paket oluşturduğunu görür ve hata mesajı alırsınız.
Paket adlarında hangi karakterlere izin verildiğiyle ilgili de bazı kurallar vardır. Paket adınızın başına ve sonuna harf veya rakam ekleyip ortasında yalnızca kısa çizgi kullanırsanız sorun yaşamazsınız. Özel karakterler kullanmaya veya paket adınızı harf ya da sayı dışında bir karakterle başlatmaya ya da bitirmeye çalışırsanız iletişim kutusunda kurallar hatırlatılır.

Paketiniz için benzersiz bir ad girin ve Oluştur'a basın. Zaten kullanımda olan bir öğe seçerseniz yukarıda gösterilen hata mesajını görürsünüz. Bir paketi başarıyla oluşturduğunuzda tarayıcıda yeni ve boş paketinize yönlendirilirsiniz:

Gördüğünüz paket adı, tüm projelerde benzersiz olması gerektiğinden farklı olacaktır.
4. Cloud Shell'i Başlatma
Cloud Shell'i etkinleştirme
- Cloud Console'da Cloud Shell'i etkinleştir 'i
tıklayın.

Cloud Shell'i daha önce hiç başlatmadıysanız ne olduğunu açıklayan bir ara ekran (ekranın alt kısmı) gösterilir. Bu durumda Devam'ı tıkladığınızda bu ekranı bir daha görmezsiniz. Bu tek seferlik ekran aşağıdaki gibi görünür:

Cloud Shell'in temel hazırlığı ve bağlanması yalnızca birkaç dakikanızı alır.

Bu sanal makine, ihtiyaç duyacağınız tüm geliştirme araçlarını içerir. 5 GB boyutunda kalıcı bir ana dizin bulunur ve Google Cloud'da çalışır. Bu sayede ağ performansı ve kimlik doğrulama önemli ölçüde güçlenir. Bu codelab'deki çalışmalarınızın neredeyse tamamını yalnızca bir tarayıcı veya Chromebook'unuzla yapabilirsiniz.
Cloud Shell'e bağlandıktan sonra kimliğinizin doğrulandığını ve projenin, proje kimliğinize ayarlandığını görürsünüz.
- Kimliğinizin doğrulandığını onaylamak için Cloud Shell'de şu komutu çalıştırın:
gcloud auth list
Komut çıkışı
Credentialed Accounts
ACTIVE ACCOUNT
* <my_account>@<my_domain.com>
To set the active account, run:
$ gcloud config set account `ACCOUNT`
gcloud config list project
Komut çıkışı
[core] project = <PROJECT_ID>
Değilse şu komutla ayarlayabilirsiniz:
gcloud config set project <PROJECT_ID>
Komut çıkışı
Updated property [core/project].
5. Maven projesi oluşturma
Cloud Shell başlatıldıktan sonra Apache Beam için Java SDK'yı kullanarak bir Maven projesi oluşturarak başlayalım.
Apache Beam, veri ardışık düzenleri için bir açık kaynak programlama modelidir. Bu ardışık düzenleri Apache Beam programıyla tanımlar ve ardışık düzeninizi yürütmek için Dataflow gibi bir çalıştırıcı seçebilirsiniz.
Kabuğunuzda mvn archetype:generate komutunu aşağıdaki gibi çalıştırın:
mvn archetype:generate \
-DarchetypeGroupId=org.apache.beam \
-DarchetypeArtifactId=beam-sdks-java-maven-archetypes-examples \
-DarchetypeVersion=2.46.0 \
-DgroupId=org.example \
-DartifactId=first-dataflow \
-Dversion="0.1" \
-Dpackage=org.apache.beam.examples \
-DinteractiveMode=false
Komutu çalıştırdıktan sonra mevcut dizininizde first-dataflow adlı yeni bir dizin görmeniz gerekir. first-dataflow, Java için Cloud Dataflow SDK'sını ve örnek ardışık düzenleri içeren bir Maven projesi içerir.
6. Cloud Dataflow'da metin işleme ardışık düzeni çalıştırma
Öncelikle proje kimliğimizi ve Cloud Storage paketi adlarımızı ortam değişkenleri olarak kaydedelim. Bu işlemi Cloud Shell'de yapabilirsiniz. <your_project_id> öğesini kendi proje kimliğinizle değiştirdiğinizden emin olun.
export PROJECT_ID=<your_project_id>
Şimdi Cloud Storage paketi için de aynı işlemi yapacağız. <your_bucket_name> ifadesini, önceki bir adımda paketinizi oluştururken kullandığınız benzersiz adla değiştirmeyi unutmayın.
export BUCKET_NAME=<your_bucket_name>
first-dataflow/ dizinine geçin.
cd first-dataflow
Metin okuyan, metin satırlarını tek tek kelime olarak sınıflandıran ve her bir kelimenin kaç kere geçtiğini sayan WordCount adlı bir ardışık düzen çalıştıracağız. Öncelikle işlem hattını çalıştıracağız ve çalışırken her adımda neler olduğuna bakacağız.
Kabuk veya terminal pencerenizde mvn compile exec:java komutunu çalıştırarak işlem hattını başlatın. --project, --stagingLocation, ve --output bağımsız değişkenleri için aşağıdaki komut, bu adımda daha önce ayarladığınız ortam değişkenlerine referans verir.
mvn compile exec:java \
-Pdataflow-runner compile exec:java \
-Dexec.mainClass=org.apache.beam.examples.WordCount \
-Dexec.args="--project=${PROJECT_ID} \
--stagingLocation=gs://${BUCKET_NAME}/staging/ \
--output=gs://${BUCKET_NAME}/output \
--runner=DataflowRunner \
--region=us-central1 \
--gcpTempLocation=gs://${BUCKET_NAME}/temp"
İş çalışırken iş listesinde işi bulalım.
Google Cloud Platform Console'da Cloud Dataflow web kullanıcı arayüzünü açın. Durumu Running olan wordcount işinizi görürsünüz:

Şimdi de işlem hattı parametrelerine bakalım. İşinizin adını tıklayarak başlayın:

Bir iş seçtiğinizde yürütme grafiğini görüntüleyebilirsiniz. Ardışık düzenin yürütme grafiği, ardışık düzendeki her dönüşümü, dönüşüm adını ve bazı durum bilgilerini içeren bir kutu olarak gösterir. Daha fazla ayrıntı görmek için her adımın sağ üst köşesindeki şapkayı tıklayabilirsiniz:
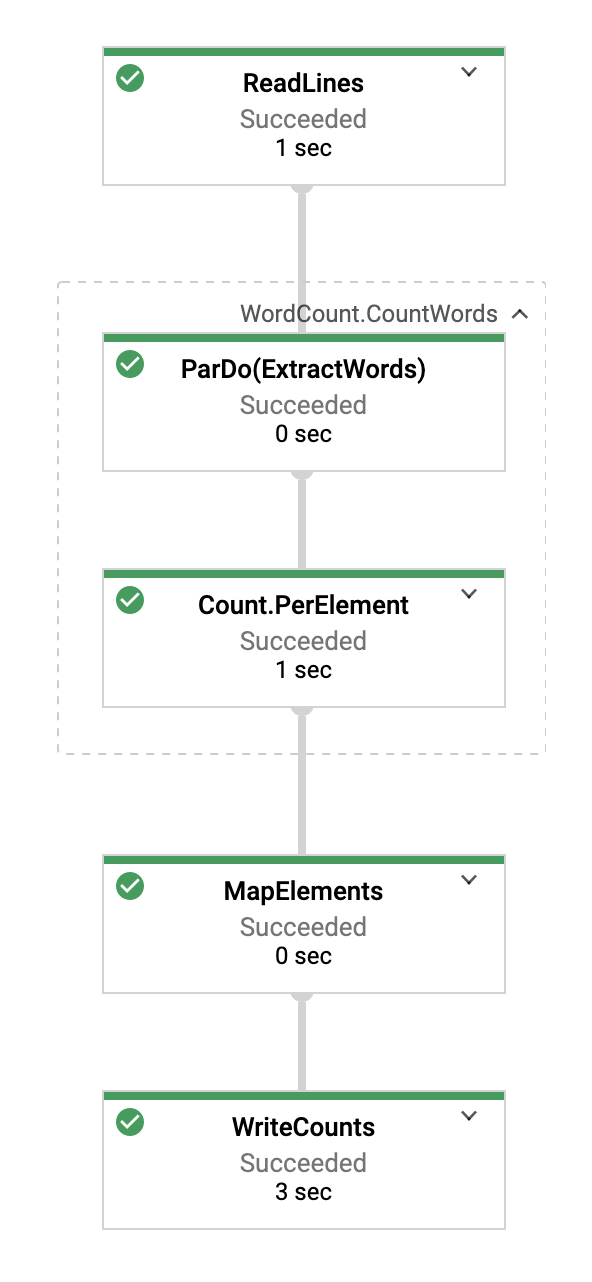
Dönüşüm hunisinin her adımında verilerin nasıl dönüştürüldüğüne bakalım:
- Okuma: Bu adımda ardışık düzen, bir giriş kaynağından okuma yapar. Bu örnekte, Shakespeare'in Kral Lear oyununun tamamını içeren bir Cloud Storage metin dosyası kullanılıyor. İşlem hattımız dosyayı satır satır okur ve her satır için bir
PCollectionçıktısı verir. Metin dosyamızdaki her satır, koleksiyondaki bir öğedir. - CountWords:
CountWordsadımının iki bölümü vardır. İlk olarak, her satırı ayrı kelimelere ayırmak içinExtractWordsadlı paralel do işlevini (ParDo) kullanır. ExtractWords'ün çıkışı, her öğenin bir kelime olduğu yeni bir PCollection'dır. Bir sonraki adım olanCount, Java SDK tarafından sağlanan ve anahtarın benzersiz bir kelime, değerin ise bu kelimenin kaç kez geçtiği anahtar/değer çiftlerini döndüren bir dönüşümü kullanır.CountWordsyönteminin uygulandığı kod aşağıda verilmiştir. WordCount.java dosyasının tamamını GitHub'da inceleyebilirsiniz:
/**
* A PTransform that converts a PCollection containing lines of text into a PCollection of
* formatted word counts.
*
* <p>Concept #3: This is a custom composite transform that bundles two transforms (ParDo and
* Count) as a reusable PTransform subclass. Using composite transforms allows for easy reuse,
* modular testing, and an improved monitoring experience.
*/
public static class CountWords
extends PTransform<PCollection<String>, PCollection<KV<String, Long>>> {
@Override
public PCollection<KV<String, Long>> expand(PCollection<String> lines) {
// Convert lines of text into individual words.
PCollection<String> words = lines.apply(ParDo.of(new ExtractWordsFn()));
// Count the number of times each word occurs.
PCollection<KV<String, Long>> wordCounts = words.apply(Count.perElement());
return wordCounts;
}
}
- MapElements: Bu, her anahtar/değer çiftini yazdırılabilir bir dize olarak biçimlendiren, aşağıda kopyalanmış
FormatAsTextFnişlevini çağırır.
/** A SimpleFunction that converts a Word and Count into a printable string. */
public static class FormatAsTextFn extends SimpleFunction<KV<String, Long>, String> {
@Override
public String apply(KV<String, Long> input) {
return input.getKey() + ": " + input.getValue();
}
}
- WriteCounts: Bu adımda, yazdırılabilir dizeleri birden fazla parçalanmış metin dosyasına yazarız.
Birkaç dakika içinde ardışık düzenden elde edilen çıkışa göz atacağız.
Şimdi de grafiğin sağındaki İş bilgileri sayfasına göz atın. Bu sayfada, mvn compile exec:java komutuna dahil ettiğimiz işlem hattı parametreleri yer alır.


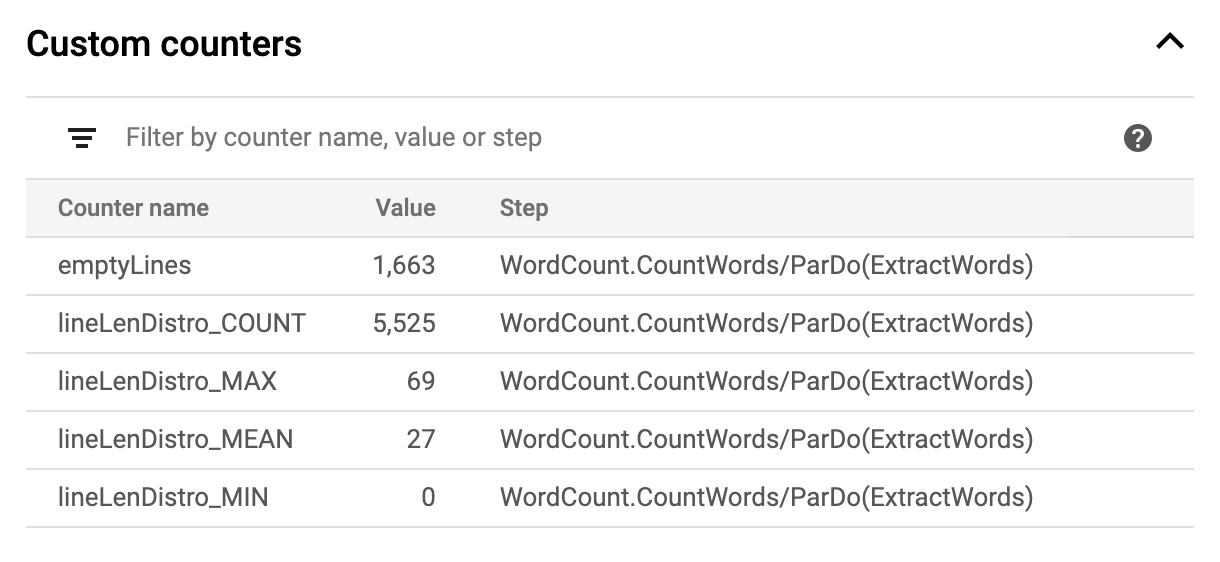
Ayrıca, işlem hattı için özel sayaçları da görebilirsiniz. Bu sayaçlar, yürütme sırasında şu ana kadar kaç boş satırla karşılaşıldığını gösterir. Uygulamaya özgü metrikleri izlemek için işlem hattınıza yeni sayaçlar ekleyebilirsiniz.
Belirli hata mesajlarını görüntülemek için konsolun alt kısmındaki Günlükler simgesini tıklayabilirsiniz.

Panel, varsayılan olarak işin durumunu bir bütün olarak bildiren İş Günlüğü mesajlarını gösterir. İş ilerleme durumu ve durum mesajlarını filtrelemek için Minimum Önem Derecesi seçicisini kullanabilirsiniz.

Grafikte bir ardışık düzen adımı seçtiğinizde görünüm, kodunuz tarafından oluşturulan günlükler ve ardışık düzen adımında çalışan oluşturulmuş kod olarak değişir.
İş günlüklerine geri dönmek için grafiğin dışını tıklayarak veya sağ taraftaki panelde Kapat düğmesini kullanarak adımın seçimini kaldırın.
Ardışık düzeninizi çalıştıran Compute Engine örneklerinin çalışan günlüklerini görüntülemek için günlükler sekmesindeki Çalışan Günlükleri düğmesini kullanabilirsiniz. Çalışan günlükleri, kodunuz tarafından oluşturulan günlük satırlarından ve kodu çalıştıran Dataflow tarafından oluşturulan koddan oluşur.
Ardışık düzenindeki bir hatayı ayıklamaya çalışıyorsanız genellikle Worker Logs'da sorunu çözmenize yardımcı olacak ek günlükler bulunur. Bu günlüklerin tüm çalışanlar arasında toplandığını, filtrelenebileceğini ve aranabileceğini unutmayın.

Dataflow İzleme Arayüzü yalnızca en son günlük mesajlarını gösterir. Günlük bölmesinin sağ tarafındaki Google Cloud Observability bağlantısını tıklayarak tüm günlükleri görüntüleyebilirsiniz.
İzleme→Günlükler sayfasında görüntülenebilen farklı günlük türlerinin özeti aşağıda verilmiştir:
- job-message günlükleri, Dataflow'un çeşitli bileşenleri tarafından oluşturulan iş düzeyindeki mesajları içerir. Örnekler arasında otomatik ölçeklendirme yapılandırması, çalışanların başlatılması veya kapatılması, iş adımındaki ilerleme ve iş hataları yer alır. Kullanıcı kodunun kilitlenmesinden kaynaklanan ve worker günlüklerinde bulunan çalışan düzeyindeki hatalar, job-message günlüklerine de yayılır.
- worker günlükleri, Dataflow çalışanları tarafından oluşturulur. Çalışanlar, ardışık düzen işinin büyük bir kısmını yapar (ör. ParDo'larınızı verilere uygulama). Worker günlükleri, kodunuz ve Dataflow tarafından kaydedilen mesajları içerir.
- worker-startup günlükleri çoğu Dataflow işinde bulunur ve başlatma süreciyle ilgili mesajları yakalayabilir. Başlatma işlemi, bir işin JAR dosyalarını Cloud Storage'dan indirmeyi ve ardından çalışanları başlatmayı içerir. Çalışan başlatmayla ilgili bir sorun varsa bu günlükler iyi bir başlangıç noktasıdır.
- shuffler günlükleri, paralel ardışık düzen işlemlerinin sonuçlarını birleştiren çalışanlardan gelen iletileri içerir.
- docker ve kubelet günlükleri, Dataflow çalışanlarında kullanılan bu herkese açık teknolojilerle ilgili mesajları içerir.
Sonraki adımda, işinizin başarılı olup olmadığını kontrol edeceğiz.
7. İşinizin başarılı olup olmadığını kontrol etme
Google Cloud Platform Console'da Cloud Dataflow web kullanıcı arayüzünü açın.
İlk olarak wordcount işinizin durumunun Çalışıyor, ardından Başarılı olduğunu göreceksiniz:

İşin çalışması yaklaşık 3-4 dakika sürer.
İşlem hattını çalıştırıp bir çıkış paketi belirttiğinizi hatırlıyor musunuz? Sonuca bakalım (çünkü Kral Lear'daki her kelimenin kaç kez geçtiğini görmek istemez misiniz?). Google Cloud Platform Console'da Cloud Storage Tarayıcısı'na geri dönün. Paketinizde, işinizin oluşturduğu çıkış dosyalarını ve hazırlama dosyalarını göreceksiniz:

8. Kaynaklarınızı kapatma
Kaynaklarınızı Google Cloud Platform Console'dan kapatabilirsiniz.
Google Cloud Platform Console'da Cloud Storage Tarayıcısı'nı açın.
Oluşturduğunuz paketin yanındaki onay kutusunu işaretleyin ve paketi ile içeriğini kalıcı olarak silmek için SİL'i tıklayın.


9. Tebrikler!
Cloud Dataflow SDK ile Maven projesi oluşturmayı, Google Cloud Platform Console'u kullanarak örnek bir ardışık düzen çalıştırmayı ve ilişkili Cloud Storage paketini ve içeriğini silmeyi öğrendiniz.
Daha Fazla Bilgi
- Dataflow Belgeleri: https://cloud.google.com/dataflow/docs/
Lisans
Bu çalışma, Creative Commons Attribution 3.0 Genel Amaçlı Lisans ve Apache 2.0 lisansı ile lisanslanmıştır.