
1. Descripción general
Cloud Dataproc es un servicio administrado de Spark y Hadoop con el que puedes aprovechar herramientas de datos de código abierto para procesamientos por lotes, consultas, transmisiones y aprendizaje automático. Con la automatización de Cloud Dataproc, podrás crear clústeres rápidamente, administrarlos con facilidad y ahorrar dinero desactivándolos cuando no los necesites. Al invertir menos tiempo y dinero en tareas de administración, podrás enfocarte en tus trabajos y datos.
Este instructivo se adaptó de https://cloud.google.com/dataproc/overview.
Qué aprenderás
- Cómo crear un clúster de Cloud Dataproc administrado (con Apache Spark preinstalado).
- Cómo enviar un trabajo de Spark
- Cómo cambiar el tamaño de un clúster
- Cómo establecer una conexión SSH al nodo principal de un clúster de Dataproc
- Cómo usar gcloud para examinar clústeres, trabajos y reglas de firewall
- Cómo cerrar tu clúster
Requisitos
¿Cómo usarás este instructivo?
¿Cómo calificarías tu experiencia con el uso de los servicios de Google Cloud Platform?
2. Configuración y requisitos
Configuración del entorno de autoaprendizaje
- Accede a la consola de Cloud y crea un proyecto nuevo o reutiliza uno existente. (Si todavía no tienes una cuenta de Gmail o de G Suite, debes crear una).



Recuerde el ID de proyecto, un nombre único en todos los proyectos de Google Cloud (el nombre anterior ya se encuentra en uso y no lo podrá usar). Se mencionará más adelante en este codelab como PROJECT_ID.
- A continuación, deberás habilitar la facturación en la consola de Cloud para usar los recursos de Google Cloud recursos.
Ejecutar este codelab no debería costar mucho, tal vez nada. Asegúrate de seguir las instrucciones de la sección “Realiza una limpieza”, en la que se aconseja cómo cerrar recursos para que no se te facture más allá de este instructivo. Los usuarios nuevos de Google Cloud son aptos para participar en el programa Prueba gratuita de $300.
3. Habilita las APIs de Cloud Dataproc y Google Compute Engine
Haz clic en el ícono de menú ubicado en la parte superior izquierda de la pantalla.

Selecciona API Manager en el menú desplegable.
Haz clic en Habilitar APIs y servicios.

Busca "Compute Engine" en el cuadro de búsqueda. Haz clic en "API de Google Compute Engine" en la lista de resultados que aparece.
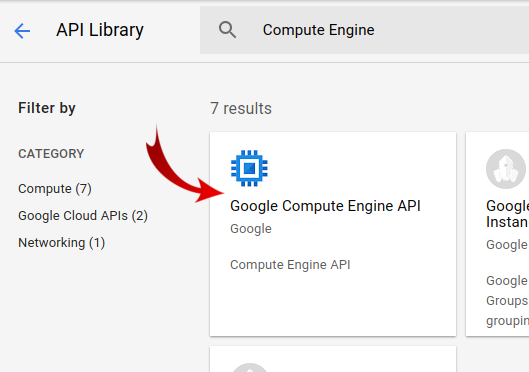
En la página de Google Compute Engine, haz clic en Habilitar.

Una vez habilitada, haz clic en la flecha que apunta hacia la izquierda para volver.
Ahora busca la "API de Google Cloud Dataproc" y habilítala también.
4. Inicie Cloud Shell
Esta máquina virtual basada en Debian está cargada con todas las herramientas de desarrollo que necesitarás. Ofrece un directorio principal persistente de 5 GB y se ejecuta en Google Cloud, lo que permite mejorar considerablemente el rendimiento de la red y la autenticación. Esto significa que todo lo que necesitarás para este Codelab es un navegador (sí, funciona en una Chromebook).
- Para activar Cloud Shell desde la consola de Cloud, solo haz clic en Activar Cloud Shell
(el aprovisionamiento y la conexión al entorno debería llevar solo unos minutos).
Una vez conectado a Cloud Shell, debería ver que ya se autenticó y que el proyecto ya se configuró con tu PROJECT_ID:
gcloud auth list
Resultado del comando
Credentialed accounts: - <myaccount>@<mydomain>.com (active)
gcloud config list project
Resultado del comando
[core] project = <PROJECT_ID>
Si, por algún motivo, el proyecto no está configurado, solo emite el siguiente comando:
gcloud config set project <PROJECT_ID>
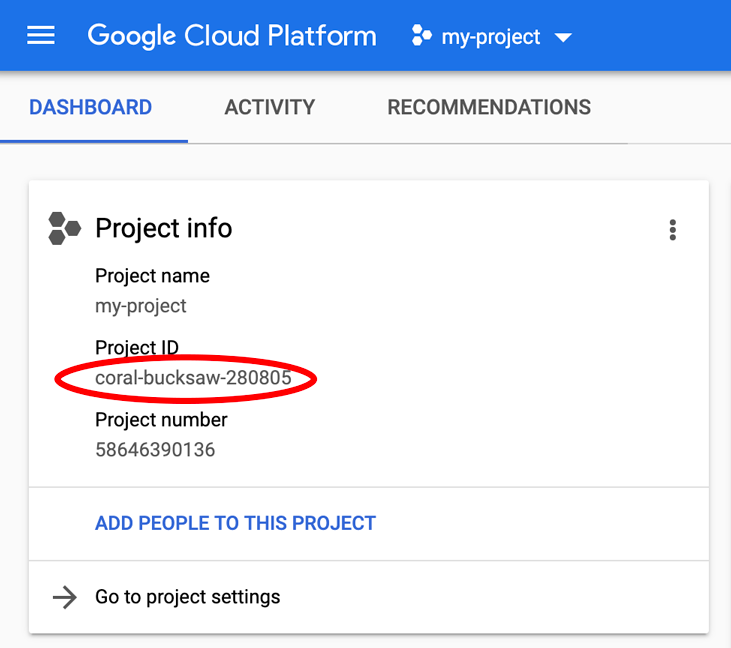
Si no conoce su PROJECT_ID, Observa el ID que usaste en los pasos de configuración o búscalo en el panel de la consola de Cloud:
Cloud Shell también configura algunas variables de entorno de forma predeterminada, lo que puede resultar útil cuando ejecutas comandos futuros.
echo $GOOGLE_CLOUD_PROJECT
Resultado del comando
<PROJECT_ID>
- Establece la zona predeterminada y la configuración del proyecto.
gcloud config set compute/zone us-central1-f
Puedes elegir una variedad de zonas diferentes. Para obtener más información, consulta Regiones y zonas.
5. Crea un clúster de Cloud Dataproc
Después de que se inicie Cloud Shell, puedes usar la línea de comandos para invocar el comando gcloud del SDK de Cloud o cualquier otra herramienta disponible en la instancia de la máquina virtual.
Elige un nombre de clúster para usar en este lab:
$ CLUSTERNAME=${USER}-dplab
Comencemos por crear un clúster nuevo:
$ gcloud dataproc clusters create ${CLUSTERNAME} \
--region=us-central1 \
--scopes=cloud-platform \
--tags codelab \
--zone=us-central1-c
La configuración predeterminada del clúster, que incluye dos nodos trabajadores, debería ser suficiente para este instructivo. El comando anterior incluye la opción --zone para especificar la zona geográfica en la que se creará el clúster y dos opciones avanzadas, --scopes y --tags, que se explican a continuación cuando uses las funciones que habilitan. Consulta el comando gcloud dataproc clusters create del SDK de Cloud para obtener información sobre cómo usar marcas de línea de comandos para personalizar la configuración del clúster.
6. Envía un trabajo de Spark a tu clúster
Puedes enviar un trabajo a través de una solicitud jobs.submit de la API de Cloud Dataproc, con la herramienta de línea de comandos gcloud o desde Google Cloud Platform Console. También puedes conectarte a una instancia de máquina en tu clúster con SSH y, luego, ejecutar un trabajo desde la instancia.
Enviemos un trabajo con la herramienta gcloud desde la línea de comandos de Cloud Shell:
$ gcloud dataproc jobs submit spark --cluster ${CLUSTERNAME} \
--class org.apache.spark.examples.SparkPi \
--jars file:///usr/lib/spark/examples/jars/spark-examples.jar -- 1000
A medida que se ejecute el trabajo, verás el resultado en la ventana de Cloud Shell.
Interrumpe el resultado ingresando Control-C. Esto detendrá el comando gcloud, pero el trabajo seguirá ejecutándose en el clúster de Dataproc.
7. Enumera trabajos y vuelve a conectar
Imprime una lista de trabajos:
$ gcloud dataproc jobs list --cluster ${CLUSTERNAME}
El trabajo enviado más recientemente se encuentra en la parte superior de la lista. Copia el ID del trabajo y pégalo en lugar de "jobId" en el siguiente comando. El comando se volverá a conectar al trabajo especificado y mostrará su resultado:
$ gcloud dataproc jobs wait jobId
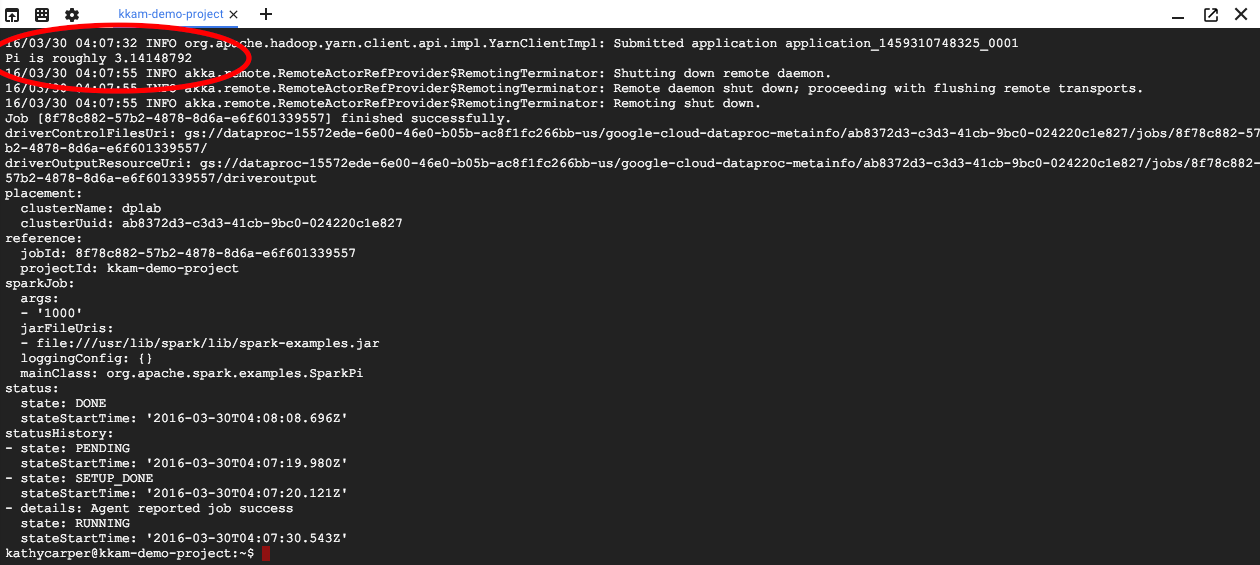
Cuando finalice el trabajo, el resultado incluirá una aproximación del valor de Pi.
8. Cambiar el tamaño del clúster
Para ejecutar cálculos más grandes, es posible que desees agregar más nodos a tu clúster para acelerarlo. Dataproc te permite agregar y quitar nodos de tu clúster en cualquier momento.
Examina la configuración del clúster:
$ gcloud dataproc clusters describe ${CLUSTERNAME}
Para agrandar el clúster, agrega algunos nodos interrumpibles:
$ gcloud dataproc clusters update ${CLUSTERNAME} --num-secondary-workers=2
Vuelve a examinar el clúster:
$ gcloud dataproc clusters describe ${CLUSTERNAME}
Ten en cuenta que, además del workerConfig de la descripción original del clúster, ahora también hay un secondaryWorkerConfig que incluye dos instanceNames para los trabajadores interrumpibles. Dataproc muestra el estado del clúster como listo mientras se inician los nodos nuevos.
Como comenzaste con dos nodos y ahora tienes cuatro, tus trabajos de Spark deberían ejecutarse aproximadamente el doble de rápido.
9. Establece una conexión SSH con el clúster
Conéctate a través de SSH al nodo principal, cuyo nombre de instancia siempre es el nombre del clúster con -m agregado:
$ gcloud compute ssh ${CLUSTERNAME}-m --zone=us-central1-c
La primera vez que ejecutes un comando ssh en Cloud Shell, se generarán claves ssh para tu cuenta allí. Puedes elegir una frase de contraseña o usar una en blanco por ahora y cambiarla más adelante con ssh-keygen si lo deseas.
En la instancia, verifica el nombre de host:
$ hostname
Como especificaste --scopes=cloud-platform cuando creaste el clúster, puedes ejecutar comandos gcloud en él. Enumera los clústeres de tu proyecto:
$ gcloud dataproc clusters list
Cuando termines, sal de la conexión SSH:
$ logout
10. Cómo examinar etiquetas
Cuando creaste el clúster, incluiste una opción --tags para agregar una etiqueta a cada nodo del clúster. Las etiquetas se usan para adjuntar reglas de firewall a cada nodo. No creaste ninguna regla de firewall coincidente en este codelab, pero aún puedes examinar las etiquetas en un nodo y las reglas de firewall en la red.
Imprime la descripción del nodo principal:
$ gcloud compute instances describe ${CLUSTERNAME}-m --zone us-central1-c
Busca tags: cerca del final del resultado y verifica que incluya codelab.
Imprime las reglas de firewall:
$ gcloud compute firewall-rules list
Observa las columnas SRC_TAGS y TARGET_TAGS. Si adjuntas una etiqueta a una regla de firewall, puedes especificar que se debe usar en todos los nodos que tengan esa etiqueta.
11. Cierra el clúster
Puedes apagar un clúster a través de una solicitud clusters.delete de la API de Cloud Dataproc, desde la línea de comandos con el ejecutable gcloud dataproc clusters delete o desde la consola de Google Cloud.
Cerraremos el clúster con la línea de comandos de Cloud Shell:
$ gcloud dataproc clusters delete ${CLUSTERNAME} --region us-central1
12. ¡Felicitaciones!
Aprendiste a crear un clúster de Dataproc, enviar un trabajo de Spark, cambiar el tamaño de un clúster, usar SSH para acceder a tu nodo principal, usar gcloud para examinar clústeres, trabajos y reglas de firewall, y cerrar tu clúster con gcloud.
Más información
- Documentación de Dataproc: https://cloud.google.com/dataproc/overview
- Codelab Comienza a usar Dataproc con la consola
Licencia
Esta obra se ofrece bajo una licencia Creative Commons Atribución 3.0 genérica y una licencia Apache 2.0.