
1. סקירה כללית
Cloud Dataproc הוא שירות מנוהל ל-Spark ול-Hadoop שמאפשר לכם להשתמש בכלים לנתונים בקוד פתוח לעיבוד ברצף (batch processing), לשליחת שאילתות, להעברת נתונים בסטרימינג וללמידת מכונה. אוטומציה ב-Cloud Dataproc עוזרת ליצור אשכולות במהירות, לנהל אותם בקלות ולחסוך כסף על ידי השבתת אשכולות כשלא צריך אותם. כך תוכלו להשקיע פחות זמן וכסף באדמיניסטרציה ולהתמקד בעבודה ובנתונים שלכם.
המדריך הזה מבוסס על המאמר https://cloud.google.com/dataproc/overview
מה תלמדו
- איך יוצרים אשכול מנוהל של Cloud Dataproc (עם Apache Spark מותקן מראש).
- איך שולחים עבודת Spark
- איך משנים את הגודל של אשכול
- איך מתחברים באמצעות SSH לצומת הראשי של אשכול Dataproc
- איך משתמשים ב-gcloud כדי לבדוק אשכולות, עבודות וכללים של חומת אש
- איך משביתים את האשכול
מה תצטרכו
איך תשתמש במדריך הזה?
איזה דירוג מגיע לדעתך לחוויית השימוש שלך בשירותים של Google Cloud Platform?
2. הגדרה ודרישות
הגדרת סביבה בקצב אישי
- נכנסים אל Cloud Console ויוצרים פרויקט חדש או משתמשים בפרויקט קיים. (אם עדיין אין לכם חשבון Gmail או G Suite, אתם צריכים ליצור חשבון).



חשוב לזכור את מזהה הפרויקט, שהוא שם ייחודי בכל הפרויקטים ב-Google Cloud (השם שלמעלה כבר תפוס ולא יתאים לכם, מצטערים!). בהמשך ה-codelab הזה נתייחס אליו כאל PROJECT_ID.
- לאחר מכן, תצטרכו להפעיל את החיוב ב-Cloud Console כדי להשתמש במשאבים של Google Cloud.
העלות של התרגול הזה לא אמורה להיות גבוהה, ואולי אפילו לא תצטרכו לשלם בכלל. חשוב לפעול לפי ההוראות בקטע 'ניקוי' כדי להשבית את המשאבים, וכך לא תחויבו אחרי שתסיימו את המדריך הזה. משתמשים חדשים ב-Google Cloud זכאים לתוכנית תקופת ניסיון בחינם בשווי 300$.
3. הפעלת ממשקי ה-API של Cloud Dataproc ו-Google Compute Engine
לוחצים על סמל התפריט בפינה השמאלית העליונה.

בתפריט הנפתח, בוחרים באפשרות 'API Manager'.

לוחצים על Enable APIs and Services.

בתיבת החיפוש, מחפשים את Compute Engine. לוחצים על Google Compute Engine API ברשימת התוצאות שמופיעה.

בדף Google Compute Engine לוחצים על הפעלה.

אחרי שמפעילים את האפשרות, לוחצים על החץ שמצביע ימינה כדי לחזור.
עכשיו מחפשים את Google Cloud Dataproc API ומפעילים אותו.

4. הפעלת Cloud Shell
המכונה הווירטואלית הזו מבוססת על Debian, וטעונים בה כל הכלים הדרושים למפתחים. יש בה ספריית בית בנפח מתמיד של 5GB והיא פועלת ב-Google Cloud, מה שמשפר מאוד את הביצועים והאימות ברשת. כלומר, כל מה שצריך כדי לבצע את ההוראות במאמר הזה הוא דפדפן (כן, זה עובד ב-Chromebook).
- כדי להפעיל את Cloud Shell ממסוף Cloud, פשוט לוחצים על הפעלת Cloud Shell
(הקצאת המשאבים והחיבור לסביבה אמורים להימשך רק כמה רגעים).
אחרי שמתחברים ל-Cloud Shell, אמור להופיע אימות שכבר בוצע, ושהפרויקט כבר הוגדר ל-PROJECT_ID.
gcloud auth list
פלט הפקודה
Credentialed accounts: - <myaccount>@<mydomain>.com (active)
gcloud config list project
פלט הפקודה
[core] project = <PROJECT_ID>
אם מסיבה כלשהי הפרויקט לא מוגדר, פשוט מריצים את הפקודה הבאה:
gcloud config set project <PROJECT_ID>
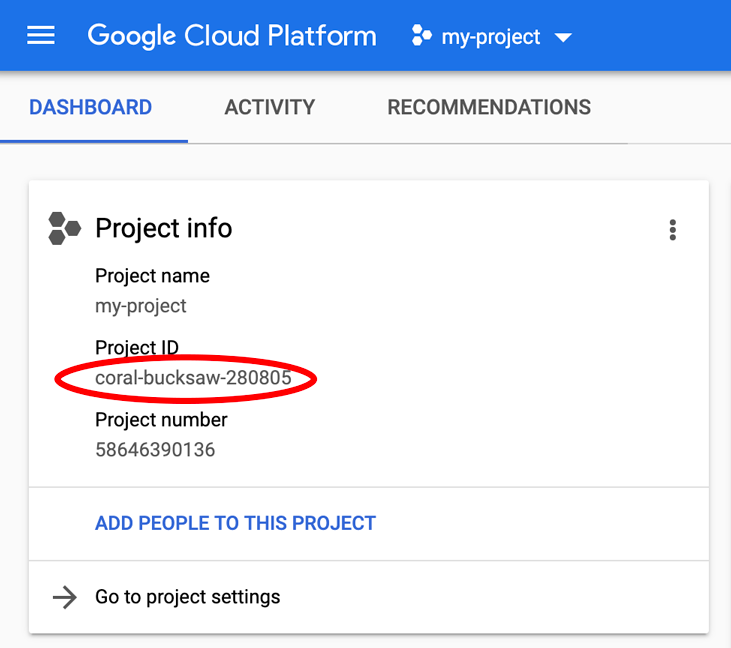
מחפש את PROJECT_ID? כדאי לבדוק באיזה מזהה השתמשתם בשלבי ההגדרה, או לחפש אותו בלוח הבקרה של Cloud Console:
ב-Cloud Shell מוגדרים גם כמה משתני סביבה כברירת מחדל, שיכולים להיות שימושיים כשמריצים פקודות בעתיד.
echo $GOOGLE_CLOUD_PROJECT
פלט הפקודה
<PROJECT_ID>
- לבסוף, מגדירים את אזור ברירת המחדל ואת הגדרת הפרויקט.
gcloud config set compute/zone us-central1-f
אפשר לבחור מתוך מגוון אזורים שונים. מידע נוסף זמין במאמר בנושא אזורים ותחומים.
5. יצירת אשכול Cloud Dataproc
אחרי שמפעילים את Cloud Shell, אפשר להשתמש בשורת הפקודה כדי להפעיל את הפקודה gcloud של Cloud SDK או כלים אחרים שזמינים במכונה הווירטואלית.
בוחרים שם לאשכול שבו רוצים להשתמש במעבדה הזו:
$ CLUSTERNAME=${USER}-dplab
כדי להתחיל, יוצרים אשכול חדש:
$ gcloud dataproc clusters create ${CLUSTERNAME} \
--region=us-central1 \
--scopes=cloud-platform \
--tags codelab \
--zone=us-central1-c
ההגדרות של אשכול ברירת המחדל, שכוללות שני צמתי עובדים, אמורות להספיק למדריך הזה. הפקודה שלמעלה כוללת את האפשרות --zone לציין את האזור הגיאוגרפי שבו ייווצר האשכול, ושתי אפשרויות מתקדמות, --scopes ו---tags, שמוסברות בהמשך כשמשתמשים בתכונות שהן מאפשרות. במאמר על הפקודה Cloud SDK gcloud dataproc clusters create מוסבר איך משתמשים בסימונים של שורת הפקודה כדי להתאים אישית את הגדרות האשכול.
6. שליחת משימת Spark לאשכול
אפשר לשלוח עבודה באמצעות בקשת Cloud Dataproc API jobs.submit, באמצעות כלי שורת הפקודה gcloud או מתוך קונסולת Google Cloud Platform. אפשר גם להתחבר למכונה באשכול באמצעות SSH, ואז להריץ עבודה מהמכונה.
נשלח עכשיו עבודה באמצעות הכלי gcloud משורת הפקודה של Cloud Shell:
$ gcloud dataproc jobs submit spark --cluster ${CLUSTERNAME} \
--class org.apache.spark.examples.SparkPi \
--jars file:///usr/lib/spark/examples/jars/spark-examples.jar -- 1000
במהלך הרצת המשימה, הפלט יוצג בחלון Cloud Shell.
מקישים על Control-C כדי להפסיק את הפלט. הפעולה הזו תעצור את הפקודה gcloud, אבל העבודה עדיין תפעל באשכול Dataproc.
7. הצגת רשימת המשימות וחיבור מחדש
כדי להדפיס רשימת משרות:
$ gcloud dataproc jobs list --cluster ${CLUSTERNAME}
המשימה שנשלחה לאחרונה מופיעה בראש הרשימה. מעתיקים את מזהה העבודה ומדביקים אותו במקום jobId בפקודה שלמטה. הפקודה תתחבר מחדש לעבודה שצוינה ותציג את הפלט שלה:
$ gcloud dataproc jobs wait jobId
כשהעבודה תסתיים, הפלט יכלול קירוב של הערך של פאי.

8. שינוי הגודל של האשכול
כדי להריץ חישובים גדולים יותר, כדאי להוסיף עוד צמתים לאשכול כדי להאיץ את התהליך. ב-Dataproc אפשר להוסיף צמתים לאשכול ולהסיר צמתים ממנו בכל שלב.
בודקים את הגדרות האשכול:
$ gcloud dataproc clusters describe ${CLUSTERNAME}
כדי להגדיל את האשכול, מוסיפים כמה צמתים שניתן לקטוע את הפעולה שלהם:
$ gcloud dataproc clusters update ${CLUSTERNAME} --num-secondary-workers=2
בודקים שוב את האשכול:
$ gcloud dataproc clusters describe ${CLUSTERNAME}
שימו לב: בנוסף ל-workerConfig מתיאור האשכול המקורי, יש עכשיו גם secondaryWorkerConfig שכולל שני instanceNames לעובדים שניתן לקטוע את הפעולה שלהם. Dataproc מציג את סטטוס האשכול כ'מוכן' בזמן שהצמתים החדשים מופעלים.
מכיוון שהתחלתם עם שני צמתים ועכשיו יש לכם ארבעה, עבודות Spark אמורות לפעול בערך פי שניים יותר מהר.
9. חיבור SSH לאשכול
מתחברים באמצעות SSH לצומת הראשי, ששם המופע שלו הוא תמיד שם האשכול עם התוספת -m:
$ gcloud compute ssh ${CLUSTERNAME}-m --zone=us-central1-c
בפעם הראשונה שמריצים פקודת SSH ב-Cloud Shell, המערכת יוצרת מפתחות SSH לחשבון שלכם. אתם יכולים לבחור ביטוי סיסמה, או להשתמש בביטוי סיסמה ריק כרגע ולשנות אותו מאוחר יותר באמצעות ssh-keygen אם תרצו.
במופע, בודקים את שם המארח:
$ hostname
מכיוון שציינתם --scopes=cloud-platform כשיצרתם את האשכול, אתם יכולים להריץ פקודות gcloud באשכול. מציגים ברשימה את האשכולות בפרויקט:
$ gcloud dataproc clusters list
בסיום, יוצאים מהחיבור ל-SSH:
$ logout
10. בדיקת התגים
כשיוצרים את האשכול, כוללים את האפשרות --tags להוספת תג לכל צומת באשכול. התגים משמשים לצירוף כללי חומת אש לכל צומת. לא יצרתם כללי חומת אש תואמים ב-codelab הזה, אבל עדיין תוכלו לבדוק את התגים בצומת ואת כללי חומת האש ברשת.
מדפיסים את התיאור של הצומת הראשי:
$ gcloud compute instances describe ${CLUSTERNAME}-m --zone us-central1-c
מחפשים את tags: לקראת סוף הפלט ומוודאים שהוא כולל את codelab.
מדפיסים את הכללים של חומת האש:
$ gcloud compute firewall-rules list
שימו לב לעמודות SRC_TAGS ו-TARGET_TAGS. אם מצרפים תג לכלל חומת אש, אפשר לציין שהתג ישמש בכל הצמתים שמוגדר בהם התג הזה.
11. כיבוי האשכול
אפשר להשבית אשכול באמצעות בקשת Cloud Dataproc API clusters.delete, משורת הפקודה באמצעות קובץ ההפעלה gcloud dataproc clusters delete או ממסוף Google Cloud Platform.
בואו נסגור את האשכול באמצעות שורת הפקודה של Cloud Shell:
$ gcloud dataproc clusters delete ${CLUSTERNAME} --region us-central1
12. מעולה!
למדתם איך ליצור אשכול Dataproc, לשלוח עבודת Spark, לשנות את גודל האשכול, להשתמש ב-SSH כדי להתחבר לצומת הראשי, להשתמש ב-gcloud כדי לבדוק אשכולות, עבודות וכללי חומת אש, ולסגור את האשכול באמצעות gcloud.
מידע נוסף
- מסמכי התיעוד של Dataproc: https://cloud.google.com/dataproc/overview
- Codelab בנושא תחילת העבודה עם Dataproc באמצעות המסוף
רישיון
עבודה זו מורשית תחת רישיון Creative Commons שמותנה בייחוס 3.0 גנרי, ורישיון Apache 2.0.