
1. Übersicht
Cloud Dataproc ist ein verwalteter Spark- und Hadoop-Dienst, mit dem Sie Open-Source-Datentools für Batchverarbeitungen, Abfragen, Streaming und maschinelles Lernen verwenden können. Mithilfe der Cloud Dataproc-Automatisierung lassen sich Cluster schnell erstellen, einfach verwalten und Kosten senken, weil Sie nicht mehr benötigte Cluster deaktivieren können. Außerdem haben Sie so die Möglichkeit sich stärker auf Jobs und Daten zu konzentrieren.
Diese Anleitung basiert auf https://cloud.google.com/dataproc/overview.
Lerninhalte
- Einen verwalteten Cloud Dataproc-Cluster (bei dem Apache Spark vorinstalliert ist) erstellen
- Spark-Job senden
- Größe eines Clusters anpassen
- SSH-Verbindung zum Masterknoten eines Dataproc-Clusters herstellen
- Cluster, Jobs und Firewallregeln mit gcloud untersuchen
- Cluster beenden
Voraussetzungen
Wie werden Sie diese Anleitung verwenden?
Wie würden Sie Ihre Erfahrungen mit der Verwendung von Google Cloud Platform-Diensten bewerten?
2. Einrichtung und Anforderungen
Umgebung zum selbstbestimmten Lernen einrichten
- Melden Sie sich in der Cloud Console an und erstellen Sie ein neues Projekt oder verwenden Sie ein vorhandenes Projekt. Wenn Sie noch kein Gmail- oder G Suite-Konto haben, müssen Sie eines erstellen.



Notieren Sie sich die Projekt-ID, also den projektübergreifend nur einmal vorkommenden Namen eines Google Cloud-Projekts. Der oben angegebene Name ist bereits vergeben und kann leider nicht mehr verwendet werden. Sie wird später in diesem Codelab als PROJECT_ID bezeichnet.
- Als Nächstes müssen Sie die Abrechnung in der Cloud Console aktivieren, um Google Cloud-Ressourcen verwenden zu können.
Die Durchführung dieses Codelabs sollte keine oder nur geringe Kosten verursachen. Folgen Sie bitte der Anleitung im Abschnitt „Bereinigen“, in der Sie erfahren, wie Sie Ressourcen herunterfahren können, damit nach Abschluss dieser Anleitung keine Gebühren anfallen. Neue Nutzer von Google Cloud kommen für das Programm für den kostenlosen Testzeitraum mit einem Guthaben von 300$ infrage.
3. Cloud Dataproc API und Google Compute Engine API aktivieren
Klicken Sie auf das Menüsymbol oben links auf dem Bildschirm.

Wählen Sie im Drop-down-Menü „API Manager“ aus.

Klicken Sie auf APIs und Dienste aktivieren.

Suchen Sie im Suchfeld nach „Compute Engine“. Klicken Sie in der angezeigten Ergebnisliste auf „Google Compute Engine API“.

Klicken Sie auf der Seite „Google Compute Engine“ auf Aktivieren.

Wenn die Funktion aktiviert ist, klicken Sie auf den Pfeil nach links, um zurückzugehen.
Suchen Sie nun nach „Google Cloud Dataproc API“ und aktivieren Sie sie ebenfalls.

4. Cloud Shell starten
Diese Debian-basierte virtuelle Maschine verfügt über alle Entwicklungstools, die Sie benötigen. Sie bietet ein Basisverzeichnis mit 5 GB nichtflüchtigem Speicher und läuft in Google Cloud, was die Netzwerkleistung und Authentifizierung erheblich verbessert. Für dieses Codelab benötigen Sie also nur einen Browser (es funktioniert auch auf einem Chromebook).
- Klicken Sie zum Aktivieren von Cloud Shell in der Cloud Console einfach auf Cloud Shell aktivieren
. Die Bereitstellung und Verbindung mit der Umgebung sollte nur wenige Augenblicke dauern.
Sobald die Verbindung mit der Cloud Shell hergestellt ist, sehen Sie, dass Sie bereits authentifiziert sind und für das Projekt schon Ihre PROJECT_ID eingestellt ist.
gcloud auth list
Befehlsausgabe
Credentialed accounts: - <myaccount>@<mydomain>.com (active)
gcloud config list project
Befehlsausgabe
[core] project = <PROJECT_ID>
Wenn das Projekt aus irgendeinem Grund nicht festgelegt ist, führen Sie einfach den folgenden Befehl aus:
gcloud config set project <PROJECT_ID>
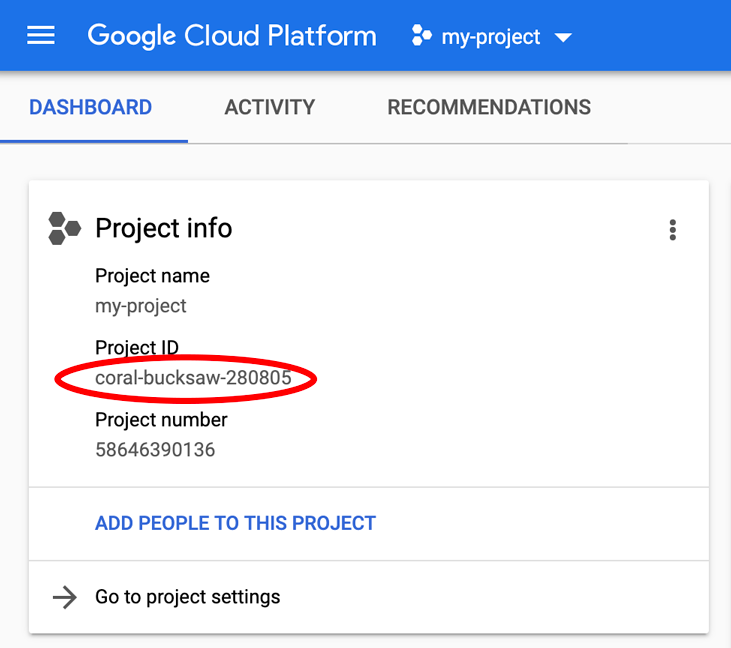
Suchst du nach deinem PROJECT_ID? Sehen Sie nach, welche ID Sie in den Einrichtungsschritten verwendet haben, oder suchen Sie sie im Cloud Console-Dashboard:
In Cloud Shell werden auch einige Umgebungsvariablen standardmäßig festgelegt, die für zukünftige Befehle nützlich sein können.
echo $GOOGLE_CLOUD_PROJECT
Befehlsausgabe
<PROJECT_ID>
- Legen Sie zum Schluss die Standardzone und die Projektkonfiguration fest.
gcloud config set compute/zone us-central1-f
Sie können verschiedene Zonen auswählen. Weitere Informationen finden Sie unter Regionen und Zonen.
5. Cloud Dataproc-Cluster erstellen
Nach dem Start von Cloud Shell können Sie mit der Befehlszeile den Cloud SDK-Befehl „gcloud“ oder andere Tools aufrufen, die auf der VM-Instanz verfügbar sind.
Wählen Sie einen Clusternamen für dieses Lab aus:
$ CLUSTERNAME=${USER}-dplab
Erstellen Sie zuerst einen neuen Cluster:
$ gcloud dataproc clusters create ${CLUSTERNAME} \
--region=us-central1 \
--scopes=cloud-platform \
--tags codelab \
--zone=us-central1-c
Die Standardclustereinstellungen mit zwei Worker-Knoten sollten für dieses Lab ausreichend sein. Der obige Befehl enthält die Option --zone, um die geografische Zone anzugeben, in der der Cluster erstellt wird, sowie zwei erweiterte Optionen, --scopes und --tags, die unten beschrieben werden, wenn Sie die von ihnen aktivierten Funktionen verwenden. Weitere Informationen dazu, wie Sie mit Befehlszeilen-Flags Clustereinstellungen anpassen können, finden Sie im Cloud SDK-Befehl gcloud dataproc clusters create.
6. Spark-Job an Cluster senden
Sie können einen Job über eine Cloud Dataproc API-Anfrage jobs.submit, mit dem Befehlszeilentool gcloud oder über die Google Cloud Console einreichen. Sie können auch über SSH eine Verbindung zu einer Maschineninstanz in Ihrem Cluster herstellen und dann einen Job über die Instanz ausführen.
Wir senden einen Job mit dem gcloud-Tool über die Cloud Shell-Befehlszeile:
$ gcloud dataproc jobs submit spark --cluster ${CLUSTERNAME} \
--class org.apache.spark.examples.SparkPi \
--jars file:///usr/lib/spark/examples/jars/spark-examples.jar -- 1000
Während der Ausführung des Jobs wird die Ausgabe in Ihrem Cloud Shell-Fenster angezeigt.
Unterbrechen Sie die Ausgabe, indem Sie Strg+C eingeben. Dadurch wird der Befehl gcloud beendet, der Job wird aber weiterhin im Dataproc-Cluster ausgeführt.
7. Jobs auflisten und Verbindung wiederherstellen
So drucken Sie eine Liste von Jobs:
$ gcloud dataproc jobs list --cluster ${CLUSTERNAME}
Der zuletzt eingereichte Job befindet sich oben in der Liste. Kopieren Sie die Job-ID und fügen Sie sie anstelle von „jobId“ in den folgenden Befehl ein. Der Befehl stellt eine neue Verbindung zum angegebenen Job her und zeigt seine Ausgabe an:
$ gcloud dataproc jobs wait jobId
Wenn der Job abgeschlossen ist, enthält die Ausgabe eine Näherung des Werts von Pi.

8. Größe des Clusters anpassen
Wenn Sie umfangreichere Berechnungen ausführen möchten, können Sie Ihrem Cluster weitere Knoten hinzufügen, um die Geschwindigkeit zu erhöhen. Mit Dataproc können Sie Ihrem Cluster jederzeit Knoten hinzufügen und daraus entfernen.
Clusterkonfiguration prüfen:
$ gcloud dataproc clusters describe ${CLUSTERNAME}
Fügen Sie dem Cluster einige Knoten auf Abruf hinzu, um ihn zu vergrößern:
$ gcloud dataproc clusters update ${CLUSTERNAME} --num-secondary-workers=2
Untersuchen Sie den Cluster noch einmal:
$ gcloud dataproc clusters describe ${CLUSTERNAME}
Zusätzlich zu den workerConfig aus der ursprünglichen Clusterbeschreibung gibt es jetzt auch ein secondaryWorkerConfig mit zwei instanceNames für die präemptiven Worker. Dataproc zeigt den Clusterstatus als „Bereit“ an, während die neuen Knoten hochfahren.
Da Sie mit zwei Knoten begonnen haben und jetzt vier haben, sollten Ihre Spark-Jobs etwa doppelt so schnell ausgeführt werden.
9. SSH-Verbindung zum Cluster herstellen
Stellen Sie über SSH eine Verbindung zum Masterknoten her. Der Instanzname ist immer der Clustername mit angehängtem -m:
$ gcloud compute ssh ${CLUSTERNAME}-m --zone=us-central1-c
Wenn Sie zum ersten Mal einen SSH-Befehl in Cloud Shell ausführen, werden dort SSH-Schlüssel für Ihr Konto generiert. Sie können eine Passphrase auswählen oder vorerst eine leere Passphrase verwenden und sie später über ssh-keygen ändern.
Prüfen Sie den Hostnamen auf der Instanz:
$ hostname
Da Sie beim Erstellen des Clusters --scopes=cloud-platform angegeben haben, können Sie gcloud-Befehle für den Cluster ausführen. Cluster in Ihrem Projekt auflisten:
$ gcloud dataproc clusters list
Melden Sie sich nach Abschluss der Arbeiten von der SSH-Verbindung ab:
$ logout
10. Tags untersuchen
Beim Erstellen des Clusters haben Sie die Option --tags verwendet, um jedem Knoten im Cluster ein Tag hinzuzufügen. Mit Tags werden Firewallregeln an jeden Knoten angehängt. In diesem Codelab haben Sie keine entsprechenden Firewallregeln erstellt. Sie können sich aber trotzdem die Tags für einen Knoten und die Firewallregeln für das Netzwerk ansehen.
Geben Sie die Beschreibung des Masterknotens aus:
$ gcloud compute instances describe ${CLUSTERNAME}-m --zone us-central1-c
Suchen Sie in der Nähe des Endes der Ausgabe nach tags: und prüfen Sie, ob codelab enthalten ist.
Firewallregeln ausdrucken:
$ gcloud compute firewall-rules list
Beachten Sie die Spalten SRC_TAGS und TARGET_TAGS. Wenn Sie ein Tag an eine Firewallregel anhängen, können Sie festlegen, dass sie auf allen Knoten mit diesem Tag verwendet werden soll.
11. Cluster herunterfahren
Sie können einen Cluster über eine clusters.delete-Anfrage an die Cloud Dataproc API, über die Befehlszeile mit der ausführbaren Datei gcloud dataproc clusters delete oder über die Google Cloud Console herunterfahren.
Beenden wir den Cluster über die Cloud Shell-Befehlszeile:
$ gcloud dataproc clusters delete ${CLUSTERNAME} --region us-central1
12. Glückwunsch!
Sie haben gelernt, wie Sie einen Dataproc-Cluster erstellen, einen Spark-Job senden, die Größe eines Clusters ändern, sich mit SSH in Ihrem Masterknoten anmelden, Cluster, Jobs und Firewallregeln mit gcloud untersuchen und Ihren Cluster mit gcloud herunterfahren.
Weitere Informationen
- Dataproc-Dokumentation: https://cloud.google.com/dataproc/overview
- Codelab: Erste Schritte mit Dataproc über die Console
Lizenz
Dieses Werk ist unter einer Creative Commons Attribution 3.0 Generic License und einer Apache 2.0-Lizenz lizenziert.