
۱. مرور کلی
Cloud Dataproc یک سرویس مدیریتشدهی Spark و Hadoop است که به شما امکان میدهد از ابزارهای دادهی متنباز برای پردازش دستهای، پرسوجو، استریمینگ و یادگیری ماشینی بهره ببرید. اتوماسیون Cloud Dataproc به شما کمک میکند تا خوشهها را به سرعت ایجاد کنید، آنها را به راحتی مدیریت کنید و با خاموش کردن خوشهها در مواقعی که به آنها نیازی ندارید، در هزینهها صرفهجویی کنید. با صرف زمان و هزینهی کمتر برای مدیریت، میتوانید روی کارها و دادههای خود تمرکز کنید.
این آموزش از https://cloud.google.com/dataproc/overview اقتباس شده است.
آنچه یاد خواهید گرفت
- نحوه ایجاد یک کلاستر مدیریتشده Cloud Dataproc (با نصب از پیش نصبشده Apache Spark ).
- نحوه ارسال یک کار Spark
- نحوه تغییر اندازه یک خوشه
- چگونه از طریق ssh به گره اصلی (master node) یک کلاستر Dataproc وارد شویم؟
- نحوه استفاده از gcloud برای بررسی خوشهها، کارها و قوانین فایروال
- چگونه کلاستر خود را خاموش کنیم
آنچه نیاز دارید
چگونه از این آموزش استفاده خواهید کرد؟
تجربه خود را در استفاده از خدمات پلتفرم ابری گوگل چگونه ارزیابی میکنید؟
۲. تنظیمات و الزامات
تنظیم محیط خودتنظیم
- وارد Cloud Console شوید و یک پروژه جدید ایجاد کنید یا از یک پروژه موجود دوباره استفاده کنید. (اگر از قبل حساب Gmail یا G Suite ندارید، باید یکی ایجاد کنید .)



شناسه پروژه را به خاطر بسپارید، یک نام منحصر به فرد در تمام پروژههای Google Cloud (نام بالا قبلاً گرفته شده و برای شما کار نخواهد کرد، متاسفیم!). بعداً در این آزمایشگاه کد به آن PROJECT_ID گفته خواهد شد.
- در مرحله بعد، برای استفاده از منابع گوگل کلود، باید پرداخت را در Cloud Console فعال کنید .
اجرای این آزمایشگاه کد، اگر اصلاً هزینهای نداشته باشد، نباید هزینه زیادی داشته باشد. حتماً دستورالعملهای بخش «پاکسازی» را که به شما نحوه خاموش کردن منابع را آموزش میدهد، دنبال کنید تا پس از این آموزش، متحمل هزینه نشوید. کاربران جدید Google Cloud واجد شرایط برنامه آزمایشی رایگان ۳۰۰ دلاری هستند.
۳. فعال کردن APIهای Cloud Dataproc و Google Compute Engine
روی آیکون منو در سمت چپ بالای صفحه کلیک کنید.

از منوی کشویی، گزینه API Manager را انتخاب کنید.

روی فعال کردن APIها و خدمات کلیک کنید.

در کادر جستجو عبارت "Compute Engine" را جستجو کنید. در لیست نتایج ظاهر شده، روی "Google Compute Engine API" کلیک کنید.

در صفحه Google Compute Engine روی Enable کلیک کنید.

پس از فعال شدن، برای بازگشت، روی فلش به سمت چپ کلیک کنید.
حالا عبارت «Google Cloud Dataproc API» را جستجو کنید و آن را نیز فعال کنید.

۴. شروع Cloud Shell
این ماشین مجازی مبتنی بر دبیان، تمام ابزارهای توسعه مورد نیاز شما را در خود جای داده است. این ماشین مجازی یک دایرکتوری خانگی ۵ گیگابایتی دائمی ارائه میدهد و در فضای ابری گوگل اجرا میشود که عملکرد شبکه و احراز هویت را تا حد زیادی بهبود میبخشد. این بدان معناست که تنها چیزی که برای این آزمایشگاه کد نیاز دارید یک مرورگر است (بله، روی کرومبوک هم کار میکند).
- برای فعال کردن Cloud Shell از کنسول Cloud، کافیست روی Activate Cloud Shell کلیک کنید.
(فقط چند لحظه طول میکشد تا آماده شود و به محیط متصل شود).
پس از اتصال به Cloud Shell، باید ببینید که از قبل احراز هویت شدهاید و پروژه از قبل روی PROJECT_ID شما تنظیم شده است.
gcloud auth list
خروجی دستور
Credentialed accounts: - <myaccount>@<mydomain>.com (active)
gcloud config list project
خروجی دستور
[core] project = <PROJECT_ID>
اگر به هر دلیلی پروژه تنظیم نشده باشد، کافیست دستور زیر را اجرا کنید:
gcloud config set project <PROJECT_ID>
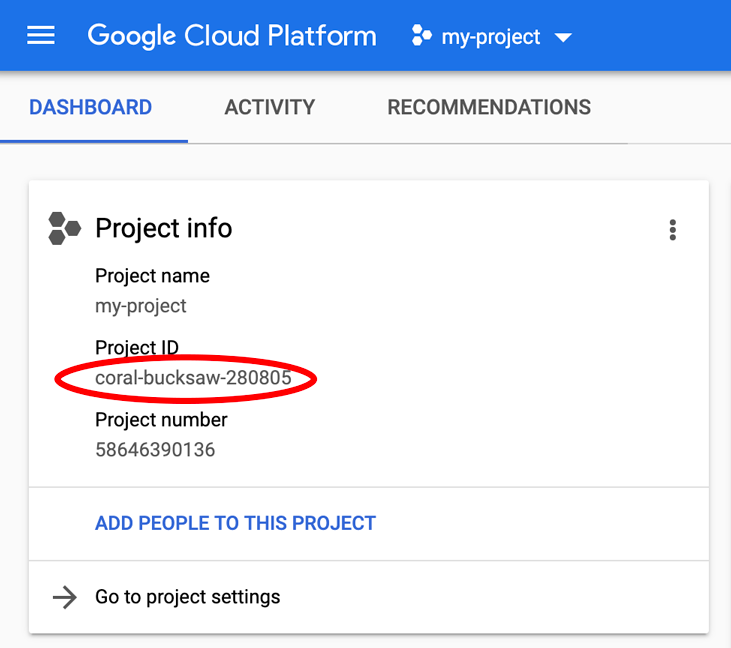
به دنبال PROJECT_ID خود هستید؟ بررسی کنید که در مراحل راهاندازی از چه شناسهای استفاده کردهاید یا آن را در داشبورد Cloud Console جستجو کنید:
Cloud Shell همچنین برخی از متغیرهای محیطی را به طور پیشفرض تنظیم میکند که ممکن است هنگام اجرای دستورات بعدی مفید باشند.
echo $GOOGLE_CLOUD_PROJECT
خروجی دستور
<PROJECT_ID>
- در نهایت، منطقه پیشفرض و پیکربندی پروژه را تنظیم کنید.
gcloud config set compute/zone us-central1-f
شما میتوانید مناطق مختلفی را انتخاب کنید. برای اطلاعات بیشتر، به بخش مناطق و نواحی مراجعه کنید.
۵. یک کلاستر Cloud Dataproc ایجاد کنید
پس از راهاندازی Cloud Shell، میتوانید از خط فرمان برای فراخوانی دستور gcloud مربوط به Cloud SDK یا سایر ابزارهای موجود در نمونه ماشین مجازی استفاده کنید.
یک نام خوشه برای استفاده در این آزمایشگاه انتخاب کنید:
$ CLUSTERNAME=${USER}-dplab
بیایید با ایجاد یک خوشه جدید شروع کنیم:
$ gcloud dataproc clusters create ${CLUSTERNAME} \
--region=us-central1 \
--scopes=cloud-platform \
--tags codelab \
--zone=us-central1-c
تنظیمات پیشفرض خوشه، که شامل گرههای دو کارگر است، باید برای این آموزش کافی باشد. دستور بالا شامل گزینه --zone برای مشخص کردن منطقه جغرافیایی که خوشه در آن ایجاد خواهد شد، و دو گزینه پیشرفته، --scopes و --tags است که در زیر توضیح داده شدهاند وقتی از ویژگیهایی که فعال میکنند استفاده میکنید. برای اطلاعات در مورد استفاده از پرچمهای خط فرمان برای سفارشیسازی تنظیمات خوشه، به دستور Cloud SDK gcloud dataproc clusters create مراجعه کنید.
۶. یک کار Spark را به کلاستر خود ارسال کنید
شما میتوانید یک کار را از طریق درخواست jobs.submit از API Cloud Dataproc، با استفاده از ابزار خط فرمان gcloud یا از کنسول پلتفرم Google Cloud ارسال کنید. همچنین میتوانید با استفاده از SSH به یک نمونه ماشین در کلاستر خود متصل شوید و سپس یک کار را از آن نمونه اجرا کنید.
بیایید با استفاده از ابزار gcloud از خط فرمان Cloud Shell یک کار ارسال کنیم:
$ gcloud dataproc jobs submit spark --cluster ${CLUSTERNAME} \
--class org.apache.spark.examples.SparkPi \
--jars file:///usr/lib/spark/examples/jars/spark-examples.jar -- 1000
همزمان با اجرای کار، خروجی را در پنجره Cloud Shell خود مشاهده خواهید کرد.
با وارد کردن Control-C، خروجی را قطع کنید. این کار دستور gcloud را متوقف میکند، اما کار همچنان در خوشه Dataproc در حال اجرا خواهد بود.
۷. فهرست مشاغل و ارتباط مجدد
چاپ لیست مشاغل:
$ gcloud dataproc jobs list --cluster ${CLUSTERNAME}
جدیدترین شغل ارسال شده در بالای لیست قرار دارد. شناسه شغل را کپی کرده و آن را به جای " jobId " در دستور زیر قرار دهید. دستور دوباره به شغل مشخص شده متصل شده و خروجی آن را نمایش میدهد:
$ gcloud dataproc jobs wait jobId
وقتی کار تمام شد، خروجی شامل تقریبی از مقدار Pi خواهد بود.

۸. تغییر اندازه خوشه
برای اجرای محاسبات بزرگتر، ممکن است بخواهید گرههای بیشتری به خوشه خود اضافه کنید تا سرعت آن افزایش یابد. Dataproc به شما امکان میدهد در هر زمان گرههایی را به خوشه خود اضافه یا از آن حذف کنید.
پیکربندی خوشه را بررسی کنید:
$ gcloud dataproc clusters describe ${CLUSTERNAME}
با اضافه کردن چند گرهی قابل قبضه کردن، کلاستر را بزرگتر کنید:
$ gcloud dataproc clusters update ${CLUSTERNAME} --num-secondary-workers=2
دوباره خوشه را بررسی کنید:
$ gcloud dataproc clusters describe ${CLUSTERNAME}
توجه داشته باشید که علاوه بر workerConfig از توضیحات اولیه کلاستر، اکنون یک secondaryWorkerConfig نیز وجود دارد که شامل دو instanceNames برای کارگران preemptible است. Dataproc وضعیت کلاستر را در حالی که گرههای جدید در حال بوت شدن هستند، به صورت آماده نشان میدهد.
از آنجایی که با دو گره شروع کردید و اکنون چهار گره دارید، کارهای Spark شما باید تقریباً دو برابر سریعتر اجرا شوند.
۹. اتصال SSH به کلاستر
از طریق ssh به گره اصلی (master node) متصل شوید، که نام نمونه آن همیشه نام خوشه با -m اضافه شده است:
$ gcloud compute ssh ${CLUSTERNAME}-m --zone=us-central1-c
اولین باری که یک دستور ssh را در Cloud Shell اجرا میکنید، کلیدهای ssh برای حساب شما در آنجا تولید میشود. میتوانید یک عبارت عبور انتخاب کنید، یا فعلاً از یک عبارت عبور خالی استفاده کنید و در صورت تمایل بعداً آن را با استفاده ssh-keygen تغییر دهید.
در این مورد، نام میزبان را بررسی کنید:
$ hostname
از آنجا که هنگام ایجاد خوشه --scopes=cloud-platform مشخص کردهاید، میتوانید دستورات gcloud روی خوشه خود اجرا کنید. خوشههای پروژه خود را فهرست کنید:
$ gcloud dataproc clusters list
وقتی کارتان تمام شد، از اتصال ssh خارج شوید:
$ logout
۱۰. برچسبها را بررسی کنید
وقتی خوشه خود را ایجاد کردید، گزینه --tags را برای اضافه کردن یک برچسب به هر گره در خوشه در نظر گرفتید. برچسبها برای اتصال قوانین فایروال به هر گره استفاده میشوند. شما هیچ قانون فایروال منطبقی را در این آزمایشگاه کد ایجاد نکردید، اما همچنان میتوانید برچسبهای روی یک گره و قوانین فایروال روی شبکه را بررسی کنید.
توضیحات گره اصلی را چاپ کن:
$ gcloud compute instances describe ${CLUSTERNAME}-m --zone us-central1-c
به دنبال tags: در نزدیکی انتهای خروجی بگردید و ببینید که شامل codelab میشود یا خیر.
قوانین فایروال را چاپ کنید:
$ gcloud compute firewall-rules list
به ستونهای SRC_TAGS و TARGET_TAGS توجه کنید. با اتصال یک تگ به یک قانون فایروال، میتوانید مشخص کنید که باید در تمام گرههایی که آن تگ را دارند، استفاده شود.
۱۱. کلاستر خود را خاموش کنید
شما میتوانید یک کلاستر را از طریق درخواست clusters.delete از API Cloud Dataproc، از طریق خط فرمان با استفاده از فایل اجرایی gcloud dataproc clusters delete یا از طریق کنسول پلتفرم Google Cloud خاموش کنید.
بیایید خوشه را با استفاده از خط فرمان Cloud Shell خاموش کنیم:
$ gcloud dataproc clusters delete ${CLUSTERNAME} --region us-central1
۱۲. تبریک میگویم!
شما یاد گرفتید که چگونه یک کلاستر Dataproc ایجاد کنید، یک کار Spark ارسال کنید، اندازه یک کلاستر را تغییر دهید، از ssh برای ورود به گره اصلی خود استفاده کنید، از gcloud برای بررسی کلاسترها، کارها و قوانین فایروال استفاده کنید و کلاستر خود را با استفاده از gcloud خاموش کنید!
اطلاعات بیشتر
- مستندات Dataproc: https://cloud.google.com/dataproc/overview
- شروع کار با Dataproc با استفاده از Console codelab
مجوز
این اثر تحت مجوز عمومی Creative Commons Attribution 3.0 و مجوز Apache 2.0 منتشر شده است.