
1. खास जानकारी
Cloud Dataproc, मैनेज की गई Spark और Hadoop सेवा है. इसकी मदद से, ओपन सोर्स डेटा टूल का इस्तेमाल किया जा सकता है. जैसे, बैच प्रोसेसिंग, क्वेरी करना, स्ट्रीमिंग, और मशीन लर्निंग. Cloud Dataproc में ऑटोमेशन की सुविधा की मदद से, क्लस्टर को तुरंत बनाया जा सकता है और उन्हें आसानी से मैनेज किया जा सकता है. साथ ही, जब आपको क्लस्टर की ज़रूरत न हो, तब उन्हें बंद करके पैसे बचाए जा सकते हैं. एडमिनिस्ट्रेशन पर कम समय और पैसा खर्च करके, अपने काम और डेटा पर फ़ोकस किया जा सकता है.
यह ट्यूटोरियल, https://cloud.google.com/dataproc/overview से लिया गया है
आपको क्या सीखने को मिलेगा
- मैनेज किया गया Cloud Dataproc क्लस्टर (जिसमें Apache Spark पहले से इंस्टॉल हो) बनाने का तरीका.
- Spark जॉब सबमिट करने का तरीका
- क्लस्टर का साइज़ बदलने का तरीका
- Dataproc क्लस्टर के मास्टर नोड में एसएसएच करने का तरीका
- क्लस्टर, नौकरियों, और फ़ायरवॉल के नियमों की जांच करने के लिए, gcloud का इस्तेमाल कैसे करें
- क्लस्टर बंद करने का तरीका
आपको इन चीज़ों की ज़रूरत होगी
इस ट्यूटोरियल का इस्तेमाल कैसे किया जाएगा?
Google Cloud Platform की सेवाओं को इस्तेमाल करने के अपने अनुभव को आप क्या रेटिंग देंगे?
2. सेटअप और ज़रूरी शर्तें
अपने हिसाब से एनवायरमेंट सेट अप करना
- Cloud Console में साइन इन करें. इसके बाद, नया प्रोजेक्ट बनाएं या किसी मौजूदा प्रोजेक्ट का फिर से इस्तेमाल करें. (अगर आपके पास पहले से Gmail या G Suite खाता नहीं है, तो आपको एक खाता बनाना होगा.)



प्रोजेक्ट आईडी याद रखें. यह सभी Google Cloud प्रोजेक्ट के लिए एक यूनीक नाम होता है. ऊपर दिया गया नाम पहले ही इस्तेमाल किया जा चुका है. इसलिए, यह आपके लिए काम नहीं करेगा. माफ़ करें! इस कोड लैब में इसे बाद में PROJECT_ID के तौर पर दिखाया जाएगा.
- इसके बाद, Google Cloud संसाधनों का इस्तेमाल करने के लिए, आपको Cloud Console में बिलिंग चालू करनी होगी.
इस कोडलैब को पूरा करने में ज़्यादा खर्च नहीं आएगा. "सफ़ाई करना" सेक्शन में दिए गए निर्देशों का पालन करना न भूलें. इसमें बताया गया है कि संसाधनों को कैसे बंद किया जाए, ताकि इस ट्यूटोरियल के बाद आपको बिलिंग न करनी पड़े. Google Cloud के नए उपयोगकर्ता, मुफ़्त में आज़माने के लिए 300 डॉलर के प्रोग्राम में शामिल हो सकते हैं.
3. Cloud Dataproc और Google Compute Engine API चालू करें
स्क्रीन पर सबसे ऊपर बाईं ओर मौजूद, मेन्यू आइकॉन पर क्लिक करें.

ड्रॉप-डाउन से API Manager चुनें.

एपीआई और सेवाएं चालू करें पर क्लिक करें.

खोज बॉक्स में "Compute Engine" खोजें. नतीजों की सूची में दिखने वाले "Google Compute Engine API" पर क्लिक करें.

Google Compute Engine पेज पर, चालू करें पर क्लिक करें

चालू होने के बाद, वापस जाने के लिए बाईं ओर इशारा करने वाले ऐरो पर क्लिक करें.
अब "Google Cloud Dataproc API" खोजें और इसे भी चालू करें.

4. Cloud Shell शुरू करना
यह Debian पर आधारित वर्चुअल मशीन है. इसमें डेवलपमेंट के लिए ज़रूरी सभी टूल पहले से मौजूद हैं. यह 5 जीबी की होम डायरेक्ट्री उपलब्ध कराता है और Google Cloud में चलता है. इससे नेटवर्क की परफ़ॉर्मेंस और पुष्टि करने की प्रोसेस बेहतर होती है. इसका मतलब है कि इस कोडलैब के लिए, आपको सिर्फ़ एक ब्राउज़र की ज़रूरत होगी. हां, यह Chromebook पर भी काम करता है.
- Cloud Console से Cloud Shell चालू करने के लिए, बस Cloud Shell चालू करें
पर क्लिक करें. इसे चालू होने और एनवायरमेंट से कनेक्ट होने में कुछ ही समय लगेगा.
Cloud Shell से कनेक्ट होने के बाद, आपको दिखेगा कि आपकी पुष्टि पहले ही हो चुकी है और प्रोजेक्ट पहले से ही आपके PROJECT_ID पर सेट है.
gcloud auth list
कमांड आउटपुट
Credentialed accounts: - <myaccount>@<mydomain>.com (active)
gcloud config list project
कमांड आउटपुट
[core] project = <PROJECT_ID>
अगर किसी वजह से प्रोजेक्ट सेट नहीं है, तो यह कमांड दें:
gcloud config set project <PROJECT_ID>
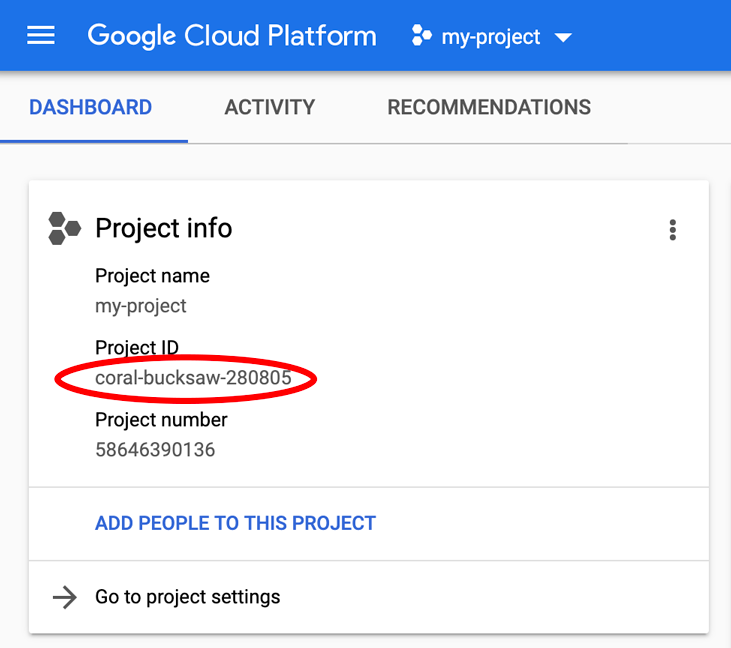
क्या आपको PROJECT_ID की तलाश है? देखें कि आपने सेटअप के दौरान किस आईडी का इस्तेमाल किया था या Cloud Console के डैशबोर्ड में जाकर इसे देखें:
Cloud Shell, कुछ एनवायरमेंट वैरिएबल को डिफ़ॉल्ट रूप से भी सेट करता है. ये वैरिएबल, आने वाले समय में कमांड चलाने के दौरान आपके काम आ सकते हैं.
echo $GOOGLE_CLOUD_PROJECT
कमांड आउटपुट
<PROJECT_ID>
- आखिर में, डिफ़ॉल्ट ज़ोन और प्रोजेक्ट कॉन्फ़िगरेशन सेट करें.
gcloud config set compute/zone us-central1-f
आपके पास अलग-अलग ज़ोन चुनने का विकल्प होता है. ज़्यादा जानकारी के लिए, रीजन और ज़ोन देखें.
5. Cloud Dataproc क्लस्टर बनाना
Cloud Shell लॉन्च होने के बाद, कमांड लाइन का इस्तेमाल करके Cloud SDK gcloud कमांड या वर्चुअल मशीन इंस्टेंस पर उपलब्ध अन्य टूल को चालू किया जा सकता है.
इस लैब में इस्तेमाल करने के लिए, क्लस्टर का नाम चुनें:
$ CLUSTERNAME=${USER}-dplab
आइए, नया क्लस्टर बनाकर शुरू करें:
$ gcloud dataproc clusters create ${CLUSTERNAME} \
--region=us-central1 \
--scopes=cloud-platform \
--tags codelab \
--zone=us-central1-c
डिफ़ॉल्ट क्लस्टर सेटिंग में दो वर्कर नोड शामिल होते हैं. इस ट्यूटोरियल के लिए, ये सेटिंग काफ़ी हैं. ऊपर दिए गए कमांड में, --zone विकल्प शामिल है. इसका इस्तेमाल करके, उस भौगोलिक ज़ोन के बारे में बताया जा सकता है जिसमें क्लस्टर बनाया जाएगा. इसमें दो बेहतर विकल्प, --scopes और --tags भी शामिल हैं. इन विकल्पों के बारे में यहां बताया गया है. इनका इस्तेमाल तब किया जाता है, जब इनसे जुड़ी सुविधाएं इस्तेमाल की जाती हैं. क्लस्टर की सेटिंग को पसंद के मुताबिक बनाने के लिए, कमांड लाइन फ़्लैग इस्तेमाल करने के बारे में जानकारी पाने के लिए, Cloud SDK gcloud dataproc clusters create कमांड देखें.
6. अपने क्लस्टर में Spark जॉब सबमिट करना
Cloud Dataproc API jobs.submit अनुरोध के ज़रिए, gcloud कमांड लाइन टूल का इस्तेमाल करके या Google Cloud Platform Console से कोई जॉब सबमिट की जा सकती है. एसएसएच का इस्तेमाल करके, अपने क्लस्टर में मौजूद मशीन इंस्टेंस से कनेक्ट किया जा सकता है. इसके बाद, इंस्टेंस से कोई जॉब चलाई जा सकती है.
Cloud Shell कमांड लाइन से gcloud टूल का इस्तेमाल करके, कोई जॉब सबमिट करते हैं:
$ gcloud dataproc jobs submit spark --cluster ${CLUSTERNAME} \
--class org.apache.spark.examples.SparkPi \
--jars file:///usr/lib/spark/examples/jars/spark-examples.jar -- 1000
जॉब पूरा होने पर, आपको Cloud Shell विंडो में आउटपुट दिखेगा.
Control-C दबाकर, आउटपुट को रोकें. इससे gcloud कमांड बंद हो जाएगी. हालाँकि, Dataproc क्लस्टर पर काम जारी रहेगा.
7. जॉब की सूची बनाना और फिर से कनेक्ट करना
जॉब की सूची प्रिंट करने के लिए:
$ gcloud dataproc jobs list --cluster ${CLUSTERNAME}
सबसे हाल ही में सबमिट किया गया जॉब, सूची में सबसे ऊपर दिखता है. जॉब आईडी को कॉपी करें और नीचे दिए गए निर्देश में "jobId" की जगह पर चिपकाएं. यह कमांड, तय की गई जॉब से फिर से कनेक्ट हो जाएगी और उसका आउटपुट दिखाएगी:
$ gcloud dataproc jobs wait jobId
जॉब पूरा होने पर, आउटपुट में पाई की वैल्यू का अनुमान शामिल होगा.

8. क्लस्टर का साइज़ बदलना
ज़्यादा बड़े कंप्यूटेशन करने के लिए, क्लस्टर में ज़्यादा नोड जोड़े जा सकते हैं, ताकि प्रोसेस को तेज़ी से पूरा किया जा सके. Dataproc की मदद से, अपने क्लस्टर में नोड जोड़े और हटाए जा सकते हैं.
क्लस्टर के कॉन्फ़िगरेशन की जांच करें:
$ gcloud dataproc clusters describe ${CLUSTERNAME}
कुछ ऐसे नोड जोड़ें जिन्हें पहले से खाली किया जा सकता है. इससे क्लस्टर बड़ा हो जाएगा:
$ gcloud dataproc clusters update ${CLUSTERNAME} --num-secondary-workers=2
क्लस्टर की फिर से जांच करें:
$ gcloud dataproc clusters describe ${CLUSTERNAME}
ध्यान दें कि ओरिजनल क्लस्टर के ब्यौरे में मौजूद workerConfig के अलावा, अब एक secondaryWorkerConfig भी है. इसमें प्रीएम्प्टिबल वर्कर के लिए दो instanceNames शामिल हैं. नए नोड बूट होने के दौरान, Dataproc क्लस्टर का स्टेटस 'तैयार है' के तौर पर दिखाता है.
आपने दो नोड से शुरुआत की थी और अब आपके पास चार नोड हैं. इसलिए, आपके Spark जॉब पहले की तुलना में करीब दो गुना तेज़ी से पूरे होने चाहिए.
9. क्लस्टर में एसएसएच करना
मास्टर नोड से एसएसएच के ज़रिए कनेक्ट करें. इसका इंस्टेंस नाम हमेशा क्लस्टर का नाम होता है. इसके आखिर में -m जोड़ा जाता है:
$ gcloud compute ssh ${CLUSTERNAME}-m --zone=us-central1-c
Cloud Shell पर पहली बार ssh कमांड चलाने पर, यह आपके खाते के लिए ssh कुंजियां जनरेट करेगा. आपके पास लंबा पासवर्ड चुनने का विकल्प होता है. इसके अलावा, आपके पास अभी के लिए लंबा पासवर्ड सेट न करने का विकल्प भी होता है. अगर आपको बाद में लंबा पासवर्ड सेट करना है, तो ssh-keygen का इस्तेमाल करके इसे बदला जा सकता है.
इंस्टेंस पर, होस्टनेम की जांच करें:
$ hostname
आपने क्लस्टर बनाते समय --scopes=cloud-platform तय किया था. इसलिए, अपने क्लस्टर पर gcloud कमांड चलाई जा सकती हैं. अपने प्रोजेक्ट में मौजूद क्लस्टर की सूची बनाएं:
$ gcloud dataproc clusters list
काम हो जाने के बाद, ssh कनेक्शन से लॉग आउट करें:
$ logout
10. टैग की जांच करना
क्लस्टर बनाते समय, आपने --tags विकल्प को चुना था. इससे क्लस्टर के हर नोड में टैग जोड़ा जा सकता है. टैग का इस्तेमाल, हर नोड में फ़ायरवॉल के नियमों को अटैच करने के लिए किया जाता है. आपने इस कोडलैब में, मैच करने वाले फ़ायरवॉल के कोई नियम नहीं बनाए हैं. हालांकि, अब भी किसी नोड पर मौजूद टैग और नेटवर्क पर मौजूद फ़ायरवॉल के नियमों की जांच की जा सकती है.
मास्टर नोड की जानकारी प्रिंट करें:
$ gcloud compute instances describe ${CLUSTERNAME}-m --zone us-central1-c
आउटपुट के आखिर में tags: देखें और पक्का करें कि इसमें codelab शामिल हो.
फ़ायरवॉल के नियमों को प्रिंट करें:
$ gcloud compute firewall-rules list
SRC_TAGS और TARGET_TAGS कॉलम देखें. फ़ायरवॉल के नियम से टैग अटैच करके, यह तय किया जा सकता है कि उस टैग का इस्तेमाल उन सभी नोड पर किया जाए जिनमें वह टैग मौजूद है.
11. अपने क्लस्टर को बंद करना
Cloud Dataproc API clusters.delete अनुरोध के ज़रिए, gcloud dataproc clusters delete एक्ज़ीक्यूटेबल का इस्तेमाल करके कमांड लाइन से या Google Cloud Platform Console से क्लस्टर बंद किया जा सकता है.
Cloud Shell कमांड लाइन का इस्तेमाल करके, क्लस्टर को बंद करें:
$ gcloud dataproc clusters delete ${CLUSTERNAME} --region us-central1
12. बधाई हो!
आपने Dataproc क्लस्टर बनाने, Spark जॉब सबमिट करने, क्लस्टर का साइज़ बदलने, अपने मास्टर नोड में लॉग इन करने के लिए ssh का इस्तेमाल करने, क्लस्टर, जॉब, और फ़ायरवॉल के नियमों की जांच करने के लिए gcloud का इस्तेमाल करने, और gcloud का इस्तेमाल करके अपने क्लस्टर को बंद करने का तरीका सीखा!
ज़्यादा जानें
- Dataproc से जुड़े दस्तावेज़: https://cloud.google.com/dataproc/overview
- Console का इस्तेमाल करके Dataproc को शुरू करने के बारे में जानकारी देने वाली कोडलैब
लाइसेंस
इस काम के लिए, Creative Commons एट्रिब्यूशन 3.0 जेनेरिक लाइसेंस और Apache 2.0 लाइसेंस के तहत लाइसेंस मिला है.