
1. Panoramica
Cloud Dataproc è un servizio Spark e Hadoop gestito che ti consente di sfruttare gli strumenti per i dati open source per elaborazione batch, esecuzione di query, inserimento di flussi e machine learning. L'automazione di Cloud Dataproc ti aiuta a creare i cluster rapidamente, a gestirli con facilità e a risparmiare denaro disattivandoli quando non ti servono. Risparmiando tempo e denaro sull'amministrazione, puoi concentrarti sui tuoi progetti e sui tuoi dati.
Questo tutorial è adattato da https://cloud.google.com/dataproc/overview
Obiettivi didattici
- Come creare un cluster Cloud Dataproc gestito (con Apache Spark preinstallato).
- Come inviare un job Spark
- Come ridimensionare un cluster
- Come eseguire l'accesso SSH al nodo master di un cluster Dataproc
- Come utilizzare gcloud per esaminare cluster, job e regole firewall
- Come arrestare il cluster
Che cosa ti serve
Come utilizzerai questo tutorial?
Come valuti la tua esperienza di utilizzo dei servizi Google Cloud Platform?
2. Configurazione e requisiti
Configurazione dell'ambiente autonomo
- Accedi alla console Cloud e crea un nuovo progetto o riutilizzane uno esistente. Se non hai già un account Gmail o G Suite, devi crearne uno.



Ricorda l'ID progetto, un nome univoco tra tutti i progetti Google Cloud (il nome sopra è già stato utilizzato e non funzionerà per te, mi dispiace). In questo codelab verrà chiamato PROJECT_ID.
- Successivamente, dovrai abilitare la fatturazione in Cloud Console per utilizzare le risorse Google Cloud.
L'esecuzione di questo codelab non dovrebbe costare molto, se non nulla. Assicurati di seguire le istruzioni riportate nella sezione "Pulizia", che ti consiglia come arrestare le risorse in modo da non incorrere in addebiti oltre questo tutorial. I nuovi utenti di Google Cloud possono beneficiare del programma prova senza costi di 300$.
3. Abilitare le API Cloud Dataproc e Google Compute Engine
Fai clic sull'icona del menu nella parte superiore sinistra dello schermo.

Seleziona API Manager dal menu a discesa.

Fai clic su Abilita API e servizi.

Cerca "Compute Engine" nella casella di ricerca. Fai clic su "API Google Compute Engine" nell'elenco dei risultati visualizzato.

Nella pagina di Google Compute Engine, fai clic su Attiva.

Una volta attivato, fai clic sulla freccia rivolta a sinistra per tornare indietro.
Ora cerca "API Google Cloud Dataproc" e attivala.

4. Avvia Cloud Shell
Questa macchina virtuale basata su Debian viene caricata con tutti gli strumenti di sviluppo di cui avrai bisogno. Offre una home directory permanente da 5 GB e viene eseguita in Google Cloud, migliorando notevolmente le prestazioni e l'autenticazione della rete. Ciò significa che per questo codelab ti servirà solo un browser (sì, funziona su Chromebook).
- Per attivare Cloud Shell dalla console Cloud, fai clic su Attiva Cloud Shell
(bastano pochi istanti per eseguire il provisioning e connettersi all'ambiente).
Una volta eseguita la connessione a Cloud Shell, dovresti vedere che il tuo account è già autenticato e il progetto è già impostato sul tuo PROJECT_ID.
gcloud auth list
Output comando
Credentialed accounts: - <myaccount>@<mydomain>.com (active)
gcloud config list project
Output comando
[core] project = <PROJECT_ID>
Se per qualche motivo il progetto non è impostato, esegui questo comando:
gcloud config set project <PROJECT_ID>
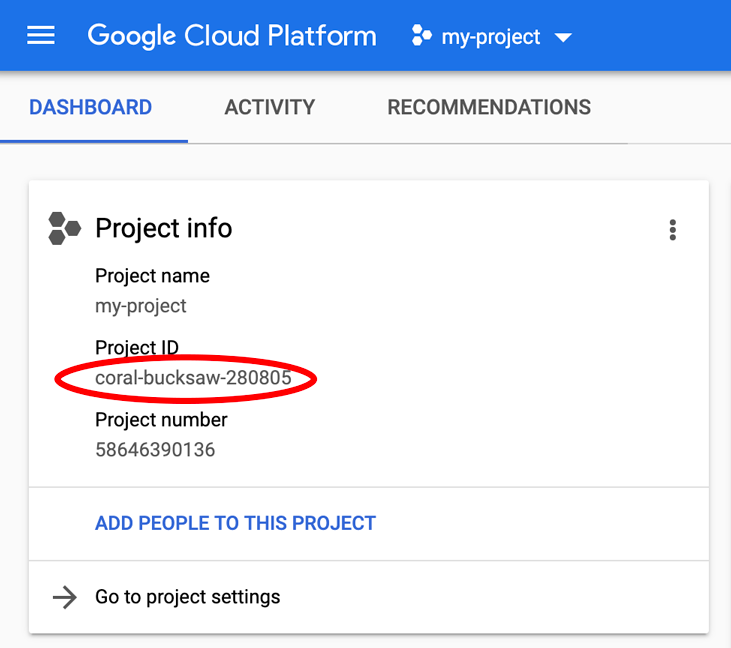
Stai cercando PROJECT_ID? Controlla l'ID che hai utilizzato nei passaggi di configurazione o cercalo nella dashboard della console Cloud:
Cloud Shell imposta anche alcune variabili di ambiente per impostazione predefinita, che potrebbero essere utili quando esegui i comandi futuri.
echo $GOOGLE_CLOUD_PROJECT
Output comando
<PROJECT_ID>
- Infine, imposta la zona e la configurazione del progetto predefinite.
gcloud config set compute/zone us-central1-f
Puoi scegliere una serie di zone diverse. Per saperne di più, consulta Regioni e zone.
5. Crea un cluster Cloud Dataproc
Dopo l'avvio di Cloud Shell, puoi utilizzare la riga di comando per richiamare il comando gcloud di Cloud SDK oppure altri strumenti disponibili nell'istanza della macchina virtuale.
Scegli un nome del cluster da utilizzare in questo lab:
$ CLUSTERNAME=${USER}-dplab
Iniziamo creando un nuovo cluster:
$ gcloud dataproc clusters create ${CLUSTERNAME} \
--region=us-central1 \
--scopes=cloud-platform \
--tags codelab \
--zone=us-central1-c
Le impostazioni predefinite del cluster, che includono due nodi worker, dovrebbero essere sufficienti per questo tutorial. Il comando precedente include l'opzione --zone per specificare la zona geografica in cui verrà creato il cluster e due opzioni avanzate, --scopes e --tags, che vengono spiegate di seguito quando utilizzi le funzionalità che abilitano. Per informazioni sull'utilizzo dei flag della riga di comando per personalizzare le impostazioni del cluster, consulta il comando gcloud dataproc clusters create di Cloud SDK.
6. Invia un job Spark al cluster
Puoi inviare un job tramite una richiesta dell'API Cloud Dataproc jobs.submit, utilizzando lo strumento a riga di comando gcloud o dalla console di Google Cloud Platform. Puoi anche connetterti a un'istanza di macchina nel cluster utilizzando SSH e poi eseguire un job dall'istanza.
Inviamo un job utilizzando lo strumento gcloud dalla riga di comando di Cloud Shell:
$ gcloud dataproc jobs submit spark --cluster ${CLUSTERNAME} \
--class org.apache.spark.examples.SparkPi \
--jars file:///usr/lib/spark/examples/jars/spark-examples.jar -- 1000
Mentre il job viene eseguito, vedrai l'output nella finestra di Cloud Shell.
Interrompi l'output inserendo Control-C. Il comando gcloud verrà interrotto, ma il job continuerà a essere eseguito sul cluster Dataproc.
7. Elenco dei job e riconnessione
Stampare un elenco di lavori:
$ gcloud dataproc jobs list --cluster ${CLUSTERNAME}
Il job inviato più di recente si trova in cima all'elenco. Copia l'ID job e incollalo al posto di "jobId" nel comando riportato di seguito. Il comando si riconnetterà al job specificato e ne visualizzerà l'output:
$ gcloud dataproc jobs wait jobId
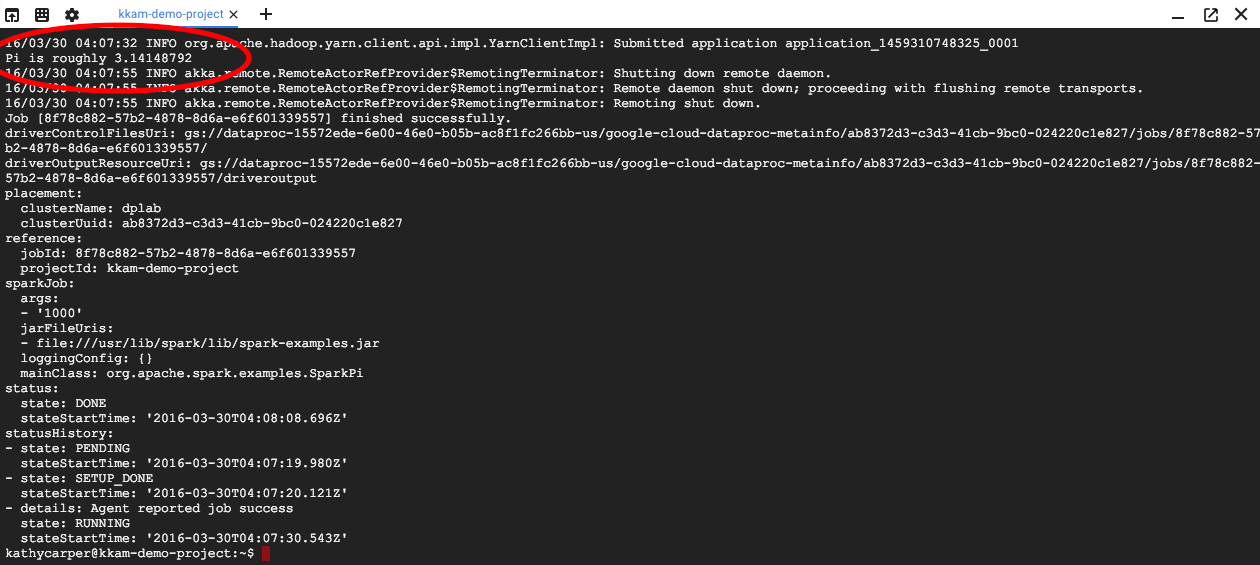
Al termine del job, l'output includerà un'approssimazione del valore di Pi greco.
8. Ridimensiona cluster
Per eseguire calcoli più grandi, potresti voler aggiungere altri nodi al cluster per velocizzarlo. Dataproc ti consente di aggiungere e rimuovere nodi dal cluster in qualsiasi momento.
Esamina la configurazione del cluster:
$ gcloud dataproc clusters describe ${CLUSTERNAME}
Aumenta le dimensioni del cluster aggiungendo alcuni nodi preemptible:
$ gcloud dataproc clusters update ${CLUSTERNAME} --num-secondary-workers=2
Esamina di nuovo il cluster:
$ gcloud dataproc clusters describe ${CLUSTERNAME}
Tieni presente che, oltre al workerConfig della descrizione originale del cluster, ora è presente anche un secondaryWorkerConfig che include due instanceNames per i worker preemptive. Dataproc mostra lo stato del cluster come pronto durante l'avvio dei nuovi nodi.
Poiché hai iniziato con due nodi e ora ne hai quattro, i job Spark dovrebbero essere eseguiti circa il doppio più velocemente.
9. Accedere al cluster tramite SSH
Connettiti tramite SSH al nodo master, il cui nome istanza è sempre il nome del cluster con l'aggiunta di -m:
$ gcloud compute ssh ${CLUSTERNAME}-m --zone=us-central1-c
La prima volta che esegui un comando ssh su Cloud Shell, vengono generate le chiavi ssh per il tuo account. Puoi scegliere una passphrase o utilizzarne una vuota per il momento e modificarla in un secondo momento utilizzando ssh-keygen, se vuoi.
Nell'istanza, controlla il nome host:
$ hostname
Poiché hai specificato --scopes=cloud-platform quando hai creato il cluster, puoi eseguire i comandi gcloud sul cluster. Elenca i cluster nel tuo progetto:
$ gcloud dataproc clusters list
Esci dalla connessione SSH quando hai terminato:
$ logout
10. Esaminare i tag
Quando hai creato il cluster, hai incluso un'opzione --tags per aggiungere un tag a ogni nodo del cluster. I tag vengono utilizzati per collegare le regole firewall a ogni nodo. In questo codelab non hai creato regole firewall corrispondenti, ma puoi comunque esaminare i tag su un nodo e le regole firewall sulla rete.
Stampa la descrizione del nodo master:
$ gcloud compute instances describe ${CLUSTERNAME}-m --zone us-central1-c
Cerca tags: verso la fine dell'output e verifica che includa codelab.
Stampa le regole firewall:
$ gcloud compute firewall-rules list
Prendi nota delle colonne SRC_TAGS e TARGET_TAGS. Se colleghi un tag a una regola firewall, puoi specificare che deve essere utilizzato su tutti i nodi che hanno quel tag.
11. Arresta il cluster
Puoi arrestare un cluster tramite una richiesta dell'API Cloud Dataproc clusters.delete, dalla riga di comando utilizzando l'eseguibile gcloud dataproc clusters delete o dalla console Google Cloud.
Chiudiamo il cluster utilizzando la riga di comando di Cloud Shell:
$ gcloud dataproc clusters delete ${CLUSTERNAME} --region us-central1
12. Complimenti!
Hai imparato a creare un cluster Dataproc, inviare un job Spark, ridimensionare un cluster, utilizzare SSH per accedere al nodo master, utilizzare gcloud per esaminare cluster, job e regole firewall e arrestare il cluster utilizzando gcloud.
Scopri di più
- Documentazione di Dataproc: https://cloud.google.com/dataproc/overview
- Getting Started with Dataproc using the Console codelab
Licenza
Questo lavoro è concesso in licenza ai sensi di una licenza Creative Commons Attribution 3.0 Generic e di una licenza Apache 2.0.