
1. 概要
Cloud Dataproc は、オープンソースのデータツールを利用してバッチ処理、クエリ実行、ストリーミング、ML を行えるマネージド Spark / Hadoop サービスです。Cloud Dataproc の自動化機能を利用すると、クラスタを速やかに作成し、簡単に管理できます。また、不要なときにはクラスタを無効にして費用を節約できます。管理にかかる時間と費用が削減されるので、自分の仕事とデータに集中できます。
このチュートリアルは、https://cloud.google.com/dataproc/overview を基に作成されています。
学習内容
- マネージド Cloud Dataproc クラスタを作成する方法(Apache Spark があらかじめインストールされている)。
- Spark ジョブを送信する方法
- クラスタのサイズ変更の方法
- Dataproc クラスタのマスターノードに SSH で接続する方法
- gcloud を使用してクラスタ、ジョブ、ファイアウォール ルールを調べる方法
- クラスタをシャットダウンする方法
必要なもの
このチュートリアルをどのように使用されますか?
Google Cloud Platform サービスのご利用経験についてどのように評価されますか?
2. 設定と要件
セルフペース型の環境設定
- Cloud Console にログインし、新しいプロジェクトを作成するか、既存のプロジェクトを再利用します(Gmail アカウントまたは G Suite アカウントをお持ちでない場合は、アカウントを作成する必要があります)。



プロジェクト ID を忘れないようにしてください。プロジェクト ID はすべての Google Cloud プロジェクトを通じて一意の名前にする必要があります(上記の名前はすでに使用されているので使用できません)。以降、このコードラボでは PROJECT_ID と呼びます。
- 次に、Google Cloud リソースを使用するために、Cloud Console で課金を有効にする必要があります。
このコードラボを実行しても、費用はほとんどかからないはずです。このチュートリアル以外で請求が発生しないように、リソースのシャットダウン方法を説明する「クリーンアップ」セクションの手順に従うようにしてください。Google Cloud の新規ユーザーは、300 米ドル分の無料トライアル プログラムをご利用いただけます。
3. Cloud Dataproc API と Google Compute Engine API を有効にする
画面の左上にあるメニュー アイコンをクリックします。

プルダウンから [API Manager] を選択します。

[API とサービスの有効化] をクリックします。

検索ボックスで「Compute Engine」を検索します。表示された結果リストで [Google Compute Engine API] をクリックします。

[Google Compute Engine] ページで、[有効にする] をクリックします。

有効になったら、左向きの矢印をクリックして戻ります。
次に、「Google Cloud Dataproc API」を検索して有効にします。

4. Cloud Shell を起動する
この Debian ベースの仮想マシンには、必要な開発ツールがすべて用意されています。仮想マシンは Google Cloud で稼働し、永続的なホーム ディレクトリが 5 GB 用意されているため、ネットワークのパフォーマンスと認証が大幅に向上しています。つまり、この Codelab に必要なのはブラウザだけです(Chromebook でも動作します)。
- Cloud Console から Cloud Shell を有効にするには、[Cloud Shell をアクティブにする]
をクリックします(環境のプロビジョニングと接続に若干時間を要します)。
Cloud Shell に接続すると、すでに認証は完了しており、プロジェクトに各自の PROJECT_ID が設定されていることがわかります。
gcloud auth list
コマンド出力
Credentialed accounts: - <myaccount>@<mydomain>.com (active)
gcloud config list project
コマンド出力
[core] project = <PROJECT_ID>
なんらかの理由でプロジェクトが設定されていない場合は、次のコマンドを実行します。
gcloud config set project <PROJECT_ID>
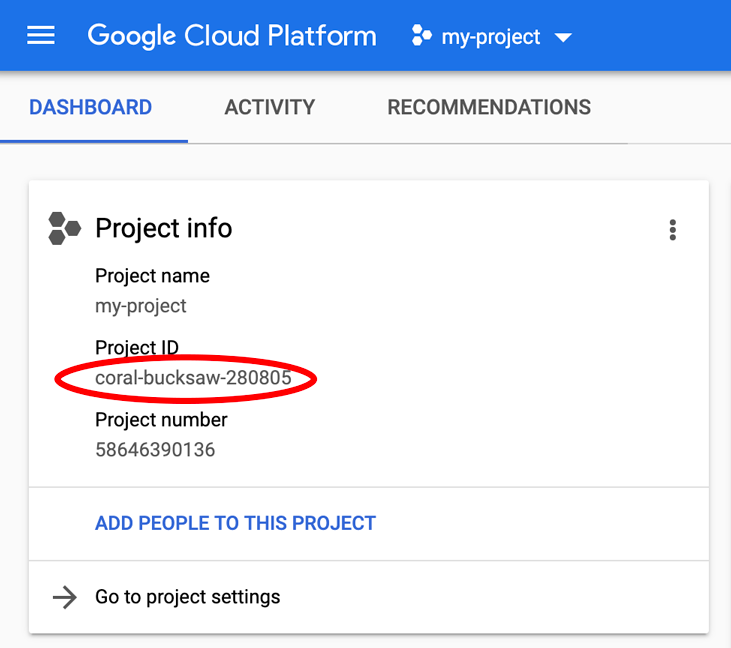
PROJECT_ID が見つからない場合は、設定手順で使用した ID を確認するか、Cloud Console ダッシュボードで検索します。
Cloud Shell では、デフォルトで環境変数もいくつか設定されます。これらの変数は、以降のコマンドを実行する際に有用なものです。
echo $GOOGLE_CLOUD_PROJECT
コマンド出力
<PROJECT_ID>
- 最後に、デフォルトのゾーンとプロジェクト構成を設定します。
gcloud config set compute/zone us-central1-f
さまざまなゾーンを選択できます。詳細については、リージョンとゾーンをご覧ください。
5. Cloud Dataproc クラスタを作成する
Cloud Shell が起動したら、コマンドラインを使用して、Cloud SDK の gcloud コマンドや、仮想マシン インスタンスで利用可能なその他のツールを実行できます。
このラボで使用するクラスタ名を選択します。
$ CLUSTERNAME=${USER}-dplab
まず、新しいクラスタを作成します。
$ gcloud dataproc clusters create ${CLUSTERNAME} \
--region=us-central1 \
--scopes=cloud-platform \
--tags codelab \
--zone=us-central1-c
このチュートリアルでは、デフォルトのクラスタ設定(2 つのワーカーノードを含む)で十分です。上記のコマンドには、クラスタを作成する地理的ゾーンを指定する --zone オプションと、2 つの詳細オプション --scopes と --tags が含まれています。これらのオプションが有効にする機能については、以下で説明します。コマンドライン フラグを使用したクラスタ設定のカスタマイズについては、Cloud SDK の gcloud dataproc clusters create コマンドをご覧ください。
6. クラスタに Spark ジョブを送信する
ジョブは、Cloud Dataproc API の jobs.submit リクエスト、gcloud コマンドライン ツール、または Google Cloud Platform Console から送信できます。SSH を使用してクラスタ内のマシン インスタンスに接続し、インスタンスからジョブを実行することもできます。
Cloud Shell コマンドラインから gcloud ツールを使用してジョブを送信してみましょう。
$ gcloud dataproc jobs submit spark --cluster ${CLUSTERNAME} \
--class org.apache.spark.examples.SparkPi \
--jars file:///usr/lib/spark/examples/jars/spark-examples.jar -- 1000
ジョブの実行中は、Cloud Shell ウィンドウに出力が表示されます。
Ctrl+C を入力して出力を中断します。これにより、gcloud コマンドは停止しますが、ジョブは Dataproc クラスタで引き続き実行されます。
7. ジョブの一覧表示と再接続
ジョブのリストを印刷します。
$ gcloud dataproc jobs list --cluster ${CLUSTERNAME}
最近送信されたジョブがリストの一番上に表示されます。ジョブ ID をコピーして、次のコマンドの「jobId」の代わりに貼り付けます。このコマンドは、指定されたジョブに再接続して、その出力を表示します。
$ gcloud dataproc jobs wait jobId
ジョブが完了すると、円周率の近似値が出力に含まれます。

8. クラスタのサイズ変更
大規模な計算を実行する場合は、クラスタにノードを追加して高速化することをおすすめします。Dataproc では、クラスタへのノードの追加とクラスタからのノードの削除をいつでも行うことができます。
クラスタの構成を確認します。
$ gcloud dataproc clusters describe ${CLUSTERNAME}
プリエンプティブル ノードを追加して、クラスタを大きくします。
$ gcloud dataproc clusters update ${CLUSTERNAME} --num-secondary-workers=2
クラスタをもう一度調べます。
$ gcloud dataproc clusters describe ${CLUSTERNAME}
元のクラスタの説明の workerConfig に加えて、プリエンプティブル ワーカー用の 2 つの instanceNames を含む secondaryWorkerConfig も追加されています。新しいノードの起動中、Dataproc はクラスタのステータスを [準備完了] と表示します。
ノードが 2 つから 4 つに増えたため、Spark ジョブの実行速度は約 2 倍になります。
9. クラスタに SSH 接続する
インスタンス名が常にクラスタ名に -m が付加されたマスターノードに SSH で接続します。
$ gcloud compute ssh ${CLUSTERNAME}-m --zone=us-central1-c
Cloud Shell で ssh コマンドを初めて実行すると、アカウントの SSH 認証鍵が生成されます。パスフレーズを選択するか、当面はパスフレーズを空白にしておき、後で ssh-keygen を使用して変更することもできます。
インスタンスでホスト名を確認します。
$ hostname
クラスタの作成時に --scopes=cloud-platform を指定したため、クラスタで gcloud コマンドを実行できます。プロジェクト内のクラスタを一覧表示します。
$ gcloud dataproc clusters list
完了したら、ssh 接続からログアウトします。
$ logout
10. タグを調べる
クラスタを作成したときに、--tags オプションを指定して、クラスタ内の各ノードにタグを追加しました。タグは、各ノードにファイアウォール ルールを関連付けるために使用されます。この Codelab では一致するファイアウォール ルールを作成していませんが、ノードのタグとネットワークのファイアウォール ルールを確認できます。
マスターノードの説明を出力します。
$ gcloud compute instances describe ${CLUSTERNAME}-m --zone us-central1-c
出力の最後の方にある tags: を探して、codelab が含まれていることを確認します。
ファイアウォール ルールを出力します。
$ gcloud compute firewall-rules list
SRC_TAGS 列と TARGET_TAGS 列を確認します。タグをファイアウォール ルールに付加することで、そのタグを持つすべてのノードで使用されるように指定できます。
11. クラスタをシャットダウンする
クラスタは、Cloud Dataproc API clusters.delete リクエスト、gcloud dataproc clusters delete 実行可能ファイルを使用したコマンドライン、または Google Cloud Platform Console からシャットダウンできます。
Cloud Shell コマンドラインを使用してクラスタをシャットダウンします。
$ gcloud dataproc clusters delete ${CLUSTERNAME} --region us-central1
12. 完了
Dataproc クラスタの作成、Spark ジョブの送信、クラスタのサイズ変更、ssh を使用したマスターノードへのログイン、gcloud を使用したクラスタ、ジョブ、ファイアウォール ルールの検査、gcloud を使用したクラスタのシャットダウンの方法を学習しました。
詳細
- Dataproc のドキュメント: https://cloud.google.com/dataproc/overview
- コンソールを使用した Dataproc スタートガイドの Codelab
ライセンス
この作品は、クリエイティブ・コモンズの表示 3.0 汎用ライセンスと Apache 2.0 ライセンスにより使用許諾されています。