
1. 개요
Cloud Dataproc은 일괄 처리, 쿼리, 스트리밍, 머신러닝에 오픈소스 데이터 도구를 활용할 수 있는 관리형 Spark 및 Hadoop 서비스입니다. Cloud Dataproc 자동화를 사용하면 클러스터를 빠르게 만들고 손쉽게 관리할 수 있으며, 필요하지 않을 때는 클러스터를 사용 중지하여 비용을 절감할 수 있습니다. 관리에 드는 시간과 비용이 줄어드는 만큼 작업과 데이터에 집중할 수 있습니다.
이 튜토리얼은 https://cloud.google.com/dataproc/overview에서 가져왔습니다.
학습할 내용
- 관리형 Cloud Dataproc 클러스터를 만드는 방법 (Apache Spark가 사전 설치됨)
- Spark 작업 제출 방법
- 클러스터 크기를 조절하는 방법
- Dataproc 클러스터의 마스터 노드에 SSH로 연결하는 방법
- gcloud를 사용하여 클러스터, 작업, 방화벽 규칙을 검사하는 방법
- 클러스터를 종료하는 방법
필요한 항목
이 튜토리얼을 어떻게 사용하실 계획인가요?
귀하의 Google Cloud Platform 서비스 사용 경험을 평가해 주세요.
2. 설정 및 요구사항
자습형 환경 설정
- Cloud Console에 로그인하고 새 프로젝트를 만들거나 기존 프로젝트를 다시 사용합니다. (Gmail 또는 G Suite 계정이 없으면 만들어야 합니다.)



모든 Google Cloud 프로젝트에서 고유한 이름인 프로젝트 ID를 기억하세요(위의 이름은 이미 사용되었으므로 사용할 수 없습니다). 이 ID는 나중에 이 Codelab에서 PROJECT_ID라고 부릅니다.
- 그런 후 Google Cloud 리소스를 사용할 수 있도록 Cloud Console에서 결제를 사용 설정해야 합니다.
이 Codelab 실행에는 많은 비용이 들지 않습니다. 이 가이드를 마친 후 비용이 결제되지 않도록 리소스 종료 방법을 알려주는 '삭제' 섹션의 안내를 따르세요. Google Cloud 새 사용자에게는 미화 $300 상당의 무료 체험판 프로그램에 참여할 수 있는 자격이 부여됩니다.
3. Cloud Dataproc 및 Google Compute Engine API 사용 설정
화면 왼쪽 상단의 메뉴 아이콘을 클릭합니다.

드롭다운에서 API 관리자를 선택합니다.

API 및 서비스 사용 설정을 클릭합니다.

검색창에 'Compute Engine'을 검색합니다. 표시되는 결과 목록에서 'Google Compute Engine API'를 클릭합니다.

Google Compute Engine 페이지에서 사용 설정을 클릭합니다.

사용 설정되면 왼쪽을 향하는 화살표를 클릭하여 뒤로 돌아갑니다.
이제 'Google Cloud Dataproc API'를 검색하여 사용 설정합니다.

4. Cloud Shell 시작
이 Debian 기반 가상 머신에는 필요한 모든 개발 도구가 로드되어 있습니다. 영구적인 5GB 홈 디렉터리를 제공하고 Google Cloud에서 실행되므로 네트워크 성능과 인증이 크게 개선됩니다. 즉, 이 Codelab에 필요한 것은 브라우저뿐입니다(Chromebook에서도 작동 가능).
- Cloud Console에서 Cloud Shell을 활성화하려면 단순히 Cloud Shell 활성화
를 클릭합니다. 환경을 프로비저닝하고 연결하는 데 몇 정도만 소요됩니다.
Cloud Shell에 연결되면 사용자 인증이 이미 완료되었고 프로젝트가 내 PROJECT_ID에 설정되어 있음을 확인할 수 있습니다.
gcloud auth list
명령어 결과
Credentialed accounts: - <myaccount>@<mydomain>.com (active)
gcloud config list project
명령어 결과
[core] project = <PROJECT_ID>
어떤 이유로든 프로젝트가 설정되지 않았으면 다음 명령어를 실행하면 됩니다.
gcloud config set project <PROJECT_ID>
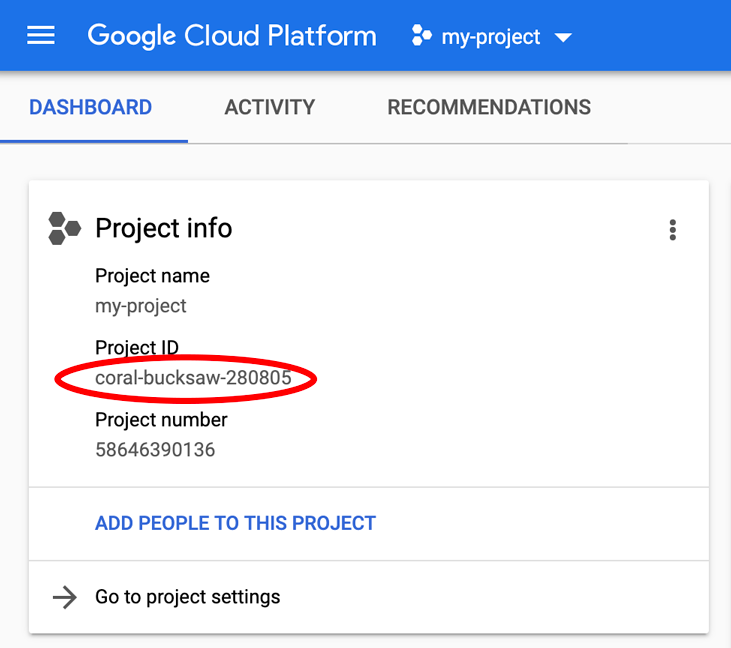
PROJECT_ID를 찾고 계신가요? 설정 단계에서 사용한 ID를 확인하거나 Cloud Console 대시보드에서 확인하세요.
또한 Cloud Shell은 기본적으로 이후 명령어를 실행할 때 유용할 수 있는 몇 가지 환경 변수를 설정합니다.
echo $GOOGLE_CLOUD_PROJECT
명령어 결과
<PROJECT_ID>
- 마지막으로 기본 영역 및 프로젝트 구성을 설정합니다.
gcloud config set compute/zone us-central1-f
다양한 영역을 선택할 수 있습니다. 자세한 내용은 리전 및 영역을 참조하세요.
5. Cloud Dataproc 클러스터 만들기
Cloud Shell이 실행되면 명령줄을 사용하여 Cloud SDK gcloud 명령어 또는 가상 머신 인스턴스에서 사용할 수 있는 다른 도구를 호출할 수 있습니다.
이 실습에서 사용할 클러스터 이름을 선택합니다.
$ CLUSTERNAME=${USER}-dplab
새 클러스터를 만들어 시작해 보겠습니다.
$ gcloud dataproc clusters create ${CLUSTERNAME} \
--region=us-central1 \
--scopes=cloud-platform \
--tags codelab \
--zone=us-central1-c
이 가이드에는 워커 노드 두 개가 포함된 기본 클러스터 설정이면 충분합니다. 위 명령어에는 클러스터가 생성될 지리적 영역을 지정하는 --zone 옵션과 아래에서 설명하는 두 가지 고급 옵션 --scopes 및 --tags가 포함되어 있습니다. 명령줄 플래그를 사용하여 클러스터 설정을 맞춤설정하는 방법은 Cloud SDK gcloud dataproc clusters create 명령어를 참고하세요.
6. 클러스터에 Spark 작업 제출
Cloud Dataproc API jobs.submit 요청을 통해, gcloud 명령줄 도구를 사용하여, 또는 Google Cloud Platform 콘솔에서 작업을 제출할 수 있습니다. SSH를 사용하여 클러스터의 머신 인스턴스에 연결한 후 인스턴스에서 작업을 실행할 수도 있습니다.
Cloud Shell 명령줄에서 gcloud 도구를 사용하여 작업을 제출해 보겠습니다.
$ gcloud dataproc jobs submit spark --cluster ${CLUSTERNAME} \
--class org.apache.spark.examples.SparkPi \
--jars file:///usr/lib/spark/examples/jars/spark-examples.jar -- 1000
작업이 실행되면 Cloud Shell 창에 출력이 표시됩니다.
Control-C를 입력하여 출력을 중단합니다. 이렇게 하면 gcloud 명령어가 중지되지만 작업은 Dataproc 클러스터에서 계속 실행됩니다.
7. 작업 나열 및 다시 연결
작업 목록을 인쇄하려면 다음 단계를 따르세요.
$ gcloud dataproc jobs list --cluster ${CLUSTERNAME}
가장 최근에 제출된 작업이 목록 맨 위에 있습니다. 작업 ID를 복사하여 아래 명령어의 'jobId' 자리에 붙여넣습니다. 이 명령어는 지정된 작업에 다시 연결하고 해당 출력을 표시합니다.
$ gcloud dataproc jobs wait jobId
작업이 완료되면 출력에 Pi 값의 근사치가 포함됩니다.

8. 클러스터 크기 조절
더 큰 계산을 실행하려면 클러스터에 노드를 추가하여 속도를 높이는 것이 좋습니다. Dataproc을 사용하면 언제든지 클러스터에 노드를 추가하거나 클러스터에서 노드를 삭제할 수 있습니다.
클러스터 구성을 검사합니다.
$ gcloud dataproc clusters describe ${CLUSTERNAME}
선점형 노드를 추가하여 클러스터를 더 크게 만듭니다.
$ gcloud dataproc clusters update ${CLUSTERNAME} --num-secondary-workers=2
클러스터를 다시 검사합니다.
$ gcloud dataproc clusters describe ${CLUSTERNAME}
원래 클러스터 설명의 workerConfig 외에도 선점 가능한 작업자를 위한 두 개의 instanceNames가 포함된 secondaryWorkerConfig도 있습니다. 새 노드가 부팅되는 동안 Dataproc은 클러스터 상태를 준비됨으로 표시합니다.
노드 2개로 시작하여 현재 4개가 있으므로 Spark 작업이 약 2배 더 빠르게 실행됩니다.
9. 클러스터에 SSH로 연결
인스턴스 이름이 항상 클러스터 이름에 -m이 추가된 마스터 노드에 SSH를 통해 연결합니다.
$ gcloud compute ssh ${CLUSTERNAME}-m --zone=us-central1-c
Cloud Shell에서 ssh 명령어를 처음 실행하면 계정의 ssh 키가 생성됩니다. 암호를 선택하거나 지금은 빈 암호를 사용하고 나중에 원하는 경우 ssh-keygen를 사용하여 변경할 수 있습니다.
인스턴스에서 호스트 이름을 확인합니다.
$ hostname
클러스터를 만들 때 --scopes=cloud-platform를 지정했으므로 클러스터에서 gcloud 명령어를 실행할 수 있습니다. 프로젝트의 클러스터를 나열합니다.
$ gcloud dataproc clusters list
작업이 끝나면 ssh 연결에서 로그아웃합니다.
$ logout
10. 태그 검사
클러스터를 만들 때 --tags 옵션을 포함하여 클러스터의 각 노드에 태그를 추가했습니다. 태그는 각 노드에 방화벽 규칙을 연결하는 데 사용됩니다. 이 Codelab에서는 일치하는 방화벽 규칙을 만들지 않았지만 노드의 태그와 네트워크의 방화벽 규칙을 검사할 수 있습니다.
마스터 노드의 설명을 출력합니다.
$ gcloud compute instances describe ${CLUSTERNAME}-m --zone us-central1-c
출력 끝부분 근처에서 tags:를 찾아 codelab이 포함되어 있는지 확인합니다.
방화벽 규칙을 출력합니다.
$ gcloud compute firewall-rules list
SRC_TAGS 및 TARGET_TAGS 열을 확인합니다. 방화벽 규칙에 태그를 연결하면 해당 태그가 있는 모든 노드에서 방화벽 규칙을 사용하도록 지정할 수 있습니다.
11. 클러스터 종료
클러스터는 Cloud Dataproc API clusters.delete 요청을 통해, gcloud dataproc clusters delete 실행 파일을 사용하여 명령줄에서 또는 Google Cloud Platform Console에서 종료할 수 있습니다.
Cloud Shell 명령줄을 사용하여 클러스터를 종료해 보겠습니다.
$ gcloud dataproc clusters delete ${CLUSTERNAME} --region us-central1
12. 축하합니다.
Dataproc 클러스터를 만들고, Spark 작업을 제출하고, 클러스터 크기를 조절하고, SSH를 사용하여 마스터 노드에 로그인하고, gcloud를 사용하여 클러스터, 작업, 방화벽 규칙을 검사하고, gcloud를 사용하여 클러스터를 종료하는 방법을 알아보았습니다.
자세히 알아보기
- Dataproc 문서: https://cloud.google.com/dataproc/overview
- 콘솔을 사용하여 Dataproc 시작하기 Codelab
라이선스
이 작업물은 크리에이티브 커먼즈 저작자 표시 3.0 일반 라이선스 및 Apache 2.0 라이선스에 따라 사용이 허가되었습니다.