
1. Visão geral
Com o Cloud Dataproc, um serviço Spark e Hadoop gerenciado, você pode usar ferramentas de dados de código aberto para processamento em lote, consultas, streaming e machine learning. A automação do Cloud Dataproc facilita a criação e o gerenciamento de clusters. Ela também gera economia porque permite desativar os clusters que não estão em uso. Com menos tempo e dinheiro gastos com administração, você pode se concentrar nos jobs e dados.
Este tutorial foi adaptado de https://cloud.google.com/dataproc/overview
O que você vai aprender
- Como criar um cluster gerenciado do Cloud Dataproc com o Apache Spark pré-instalado.
- Como enviar um job do Spark
- Como redimensionar um cluster
- Como usar SSH no nó mestre de um cluster do Dataproc
- Como usar o gcloud para examinar clusters, jobs e regras de firewall
- Como encerrar o cluster
O que é necessário
Como você vai usar este tutorial?
Como você classificaria sua experiência com o uso dos serviços do Google Cloud Platform?
2. Configuração e requisitos
Configuração de ambiente autoguiada
- Faça login no Console do Cloud e crie um novo projeto ou reutilize um existente. Crie uma se você ainda não tiver uma conta do Gmail ou do G Suite.



Lembre-se do código do projeto, um nome exclusivo em todos os projetos do Google Cloud. O nome acima já foi escolhido e não servirá para você. Faremos referência a ele mais adiante neste codelab como PROJECT_ID.
- Em seguida, será necessário ativar o faturamento no Console do Cloud para usar os recursos do Google Cloud.
A execução deste codelab não será muito cara, se for o caso. Siga todas as instruções na seção "Limpeza", que orienta você sobre como encerrar recursos para não incorrer em cobranças além deste tutorial. Novos usuários do Google Cloud estão qualificados para o programa de US$ 300 de avaliação sem custos.
3. Ativar as APIs Cloud Dataproc e Google Compute Engine
Clique no ícone de menu no canto superior esquerdo da tela.

Selecione "API Manager" no menu suspenso.

Clique em Ativar APIs e serviços.

Pesquise "Compute Engine" na caixa de pesquisa. Clique em "API Compute Engine" na lista de resultados que aparece.

Na página do Google Compute Engine, clique em Ativar.

Depois de fazer a ativação, clique na seta apontando para a esquerda para voltar.
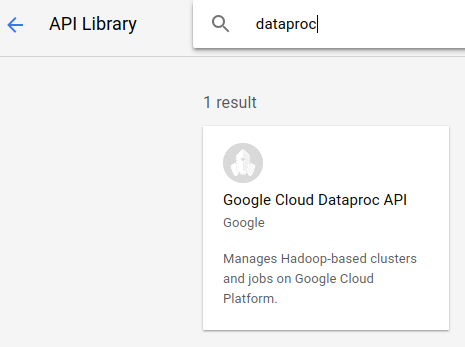
Agora pesquise "API Dataproc do Google Cloud" e ative-a também.
4. Iniciar o Cloud Shell
O Cloud Shell é uma máquina virtual com base em Debian que contém todas as ferramentas de desenvolvimento necessárias. Ela oferece um diretório principal persistente de 5 GB, além de ser executada no Google Cloud. Isso aprimora o desempenho e a autenticação da rede. Isso significa que tudo que você precisa para este codelab é um navegador (sim, funciona em um Chromebook).
- Para ativar o Cloud Shell no Console do Cloud, basta clicar em Ativar o Cloud Shell
. Leva apenas alguns instantes para provisionar e se conectar ao ambiente.
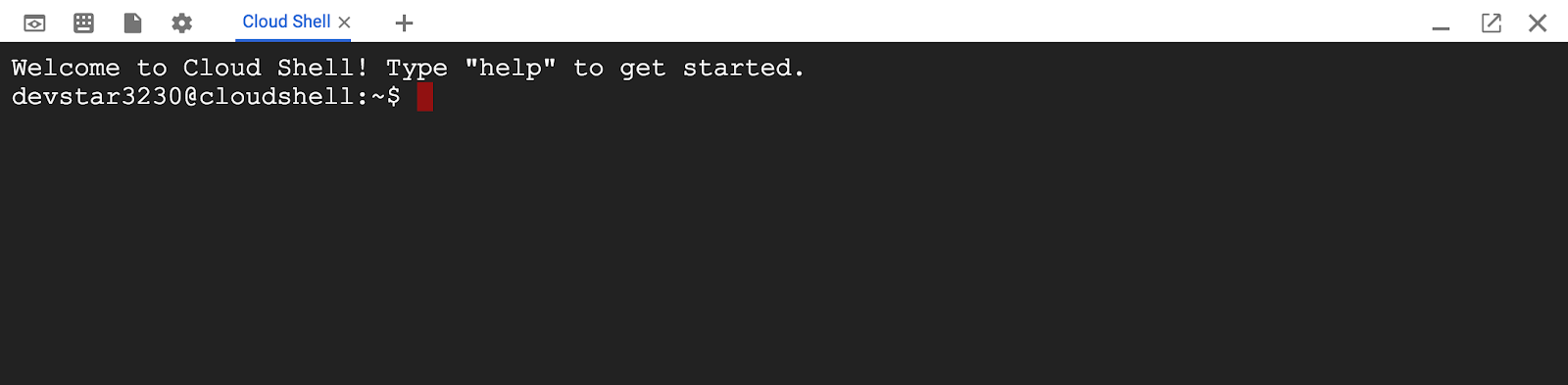
Depois de se conectar ao Cloud Shell, você já estará autenticado e o projeto estará configurado com seu PROJECT_ID.
gcloud auth list
Resposta ao comando
Credentialed accounts: - <myaccount>@<mydomain>.com (active)
gcloud config list project
Resposta ao comando
[core] project = <PROJECT_ID>
Se, por algum motivo, o projeto não estiver definido, basta emitir o seguinte comando:
gcloud config set project <PROJECT_ID>
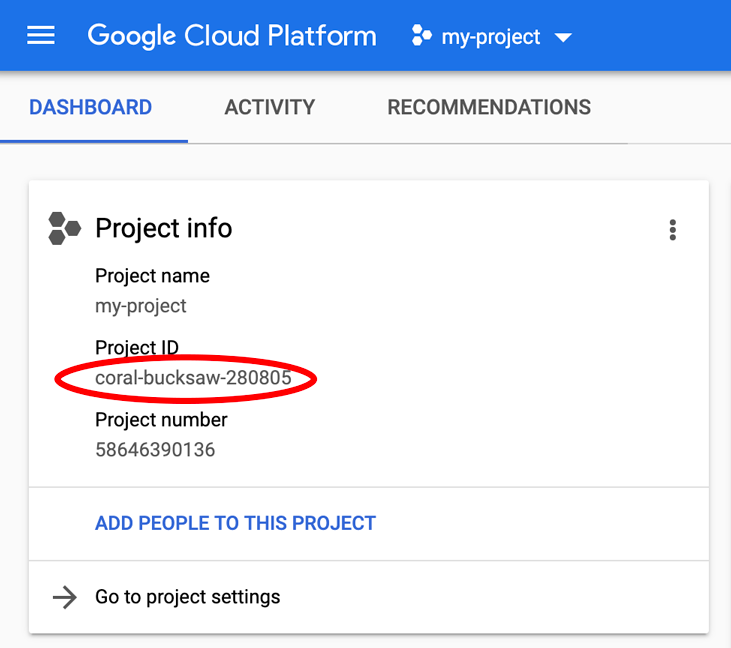
Quer encontrar seu PROJECT_ID? Veja qual ID você usou nas etapas de configuração ou procure-o no painel do Console do Cloud:
O Cloud Shell também define algumas variáveis de ambiente por padrão, o que pode ser útil ao executar comandos futuros.
echo $GOOGLE_CLOUD_PROJECT
Resposta ao comando
<PROJECT_ID>
- Defina a zona padrão e a configuração do projeto:
gcloud config set compute/zone us-central1-f
É possível escolher uma variedade de zonas diferentes. Para mais informações, consulte Regiões e zonas.
5. Criar um cluster do Cloud Dataproc
Depois que o Cloud Shell for iniciado, use a linha de comando para invocar o comando gcloud do SDK Cloud ou outras ferramentas disponíveis na instância da máquina virtual.
Escolha um nome de cluster para usar neste laboratório:
$ CLUSTERNAME=${USER}-dplab
Vamos começar criando um cluster:
$ gcloud dataproc clusters create ${CLUSTERNAME} \
--region=us-central1 \
--scopes=cloud-platform \
--tags codelab \
--zone=us-central1-c
As configurações padrão de cluster, que incluem dois nós de trabalho, devem ser suficientes para este tutorial. O comando acima inclui a opção --zone para especificar a zona geográfica em que o cluster será criado e duas opções avançadas, --scopes e --tags, que são explicadas abaixo quando você usa os recursos que elas ativam. Consulte o comando gcloud dataproc clusters create do SDK Cloud para saber como usar flags de linha de comando e personalizar as configurações do cluster.
6. enviar um job do Spark para o cluster
É possível enviar um job por meio de uma solicitação da API Dataproc jobs.submit, usando a ferramenta de linha de comando gcloud ou pelo Console do Google Cloud Platform. Também é possível se conectar a uma instância de máquina no cluster usando SSH e executar um job na instância.
Vamos enviar um job usando a ferramenta gcloud na linha de comando do Cloud Shell:
$ gcloud dataproc jobs submit spark --cluster ${CLUSTERNAME} \
--class org.apache.spark.examples.SparkPi \
--jars file:///usr/lib/spark/examples/jars/spark-examples.jar -- 1000
À medida que o job é executado, a saída aparece na janela do Cloud Shell.
Interrompa a saída pressionando Control-C. Isso vai interromper o comando gcloud, mas o job ainda será executado no cluster do Dataproc.
7. Listar jobs e reconectar
Imprima uma lista de jobs:
$ gcloud dataproc jobs list --cluster ${CLUSTERNAME}
O job enviado mais recentemente aparece no topo da lista. Copie o ID do job e cole no lugar de "jobId" no comando abaixo. O comando vai se reconectar ao job especificado e mostrar a saída dele:
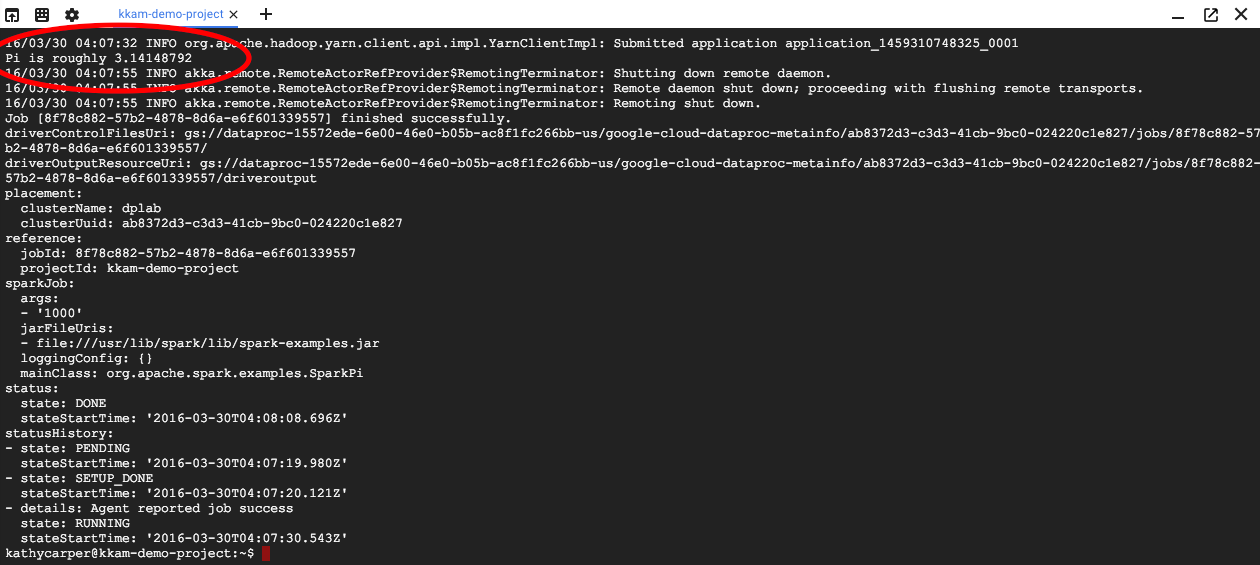
$ gcloud dataproc jobs wait jobId
Quando o job for concluído, a saída vai incluir uma aproximação do valor de Pi.
8. Redimensionar cluster
Para executar cálculos maiores, talvez seja necessário adicionar mais nós ao cluster para acelerar o processo. Com o Dataproc, é possível adicionar e remover nós do cluster a qualquer momento.
Examine a configuração do cluster:
$ gcloud dataproc clusters describe ${CLUSTERNAME}
Aumente o cluster adicionando alguns nós preemptivos:
$ gcloud dataproc clusters update ${CLUSTERNAME} --num-secondary-workers=2
Examine o cluster novamente:
$ gcloud dataproc clusters describe ${CLUSTERNAME}
Além do workerConfig da descrição original do cluster, agora também há um secondaryWorkerConfig que inclui dois instanceNames para os workers preemptivos. O Dataproc mostra o status do cluster como "pronto" enquanto os novos nós estão sendo inicializados.
Como você começou com dois nós e agora tem quatro, seus jobs do Spark devem ser executados cerca de duas vezes mais rápido.
9. SSH no cluster
Conecte-se via SSH ao nó mestre, cujo nome da instância é sempre o nome do cluster com -m anexado:
$ gcloud compute ssh ${CLUSTERNAME}-m --zone=us-central1-c
Na primeira vez que você executa um comando ssh no Cloud Shell, ele gera chaves ssh para sua conta. Você pode escolher uma senha longa ou usar uma em branco por enquanto e mudar depois usando ssh-keygen, se quiser.
Na instância, verifique o nome do host:
$ hostname
Como você especificou --scopes=cloud-platform ao criar o cluster, é possível executar comandos gcloud nele. Liste os clusters no seu projeto:
$ gcloud dataproc clusters list
Saia da conexão SSH quando terminar:
$ logout
10. Analisar tags
Ao criar o cluster, você incluiu uma opção --tags para adicionar uma tag a cada nó do cluster. As tags são usadas para anexar regras de firewall a cada nó. Você não criou nenhuma regra de firewall correspondente neste codelab, mas ainda pode examinar as tags em um nó e as regras de firewall na rede.
Imprima a descrição do nó mestre:
$ gcloud compute instances describe ${CLUSTERNAME}-m --zone us-central1-c
Procure tags: perto do final da saída e veja que ele inclui codelab.
Imprima as regras de firewall:
$ gcloud compute firewall-rules list
Observe as colunas SRC_TAGS e TARGET_TAGS. Ao anexar uma tag a uma regra de firewall, você pode especificar que ela seja usada em todos os nós com essa tag.
11. encerrar o cluster
É possível encerrar um cluster por meio de uma solicitação clusters.delete da API Dataproc, da linha de comando usando o executável gcloud dataproc clusters delete ou do Console do Google Cloud Platform.
Vamos desligar o cluster usando a linha de comando do Cloud Shell:
$ gcloud dataproc clusters delete ${CLUSTERNAME} --region us-central1
12. Parabéns!
Você aprendeu a criar um cluster do Dataproc, enviar um job do Spark, redimensionar um cluster, usar o SSH para fazer login no nó mestre, usar a gcloud para examinar clusters, jobs e regras de firewall e encerrar o cluster usando a gcloud.
Saiba mais
- Documentação do Dataproc: https://cloud.google.com/dataproc/overview
- Codelab Primeiros passos com o Dataproc usando o console
Licença
Este trabalho está licenciado sob uma Licença Creative Commons Atribuição 3.0 Genérica e uma licença Apache 2.0.