
1. Обзор
Cloud Dataproc — это управляемый сервис Spark и Hadoop, позволяющий использовать инструменты обработки данных с открытым исходным кодом для пакетной обработки, запросов, потоковой обработки и машинного обучения. Автоматизация Cloud Dataproc помогает быстро создавать кластеры, легко управлять ими и экономить деньги, отключая кластеры, когда они не нужны. Сократив время и затраты на администрирование, вы можете сосредоточиться на своих задачах и данных.
Данный учебный материал адаптирован из https://cloud.google.com/dataproc/overview
Что вы узнаете
- Как создать управляемый кластер Cloud Dataproc (с предустановленным Apache Spark ).
- Как отправить задание Spark
- Как изменить размер кластера
- Как подключиться по SSH к главному узлу кластера Dataproc
- Как использовать gcloud для анализа кластеров, заданий и правил брандмауэра
- Как остановить работу кластера
Что вам понадобится
Как вы будете использовать этот учебник?
Как бы вы оценили свой опыт использования сервисов Google Cloud Platform?
2. Настройка и требования
Настройка среды для самостоятельного обучения
- Войдите в Cloud Console и создайте новый проект или используйте существующий. (Если у вас еще нет учетной записи Gmail или G Suite, вам необходимо ее создать .)



Запомните идентификатор проекта (Project ID) — уникальное имя для всех проектов Google Cloud (указанное выше имя уже занято и вам не подойдёт, извините!). В дальнейшем в этом практическом занятии оно будет обозначаться как PROJECT_ID .
- Далее вам потребуется включить оплату в Cloud Console, чтобы использовать ресурсы Google Cloud.
Выполнение этого практического задания не должно стоить дорого, если вообще что-либо. Обязательно следуйте инструкциям в разделе «Очистка», где указано, как отключить ресурсы, чтобы избежать дополнительных расходов после завершения этого урока. Новые пользователи Google Cloud имеют право на бесплатную пробную версию стоимостью 300 долларов США .
3. Включите API Cloud Dataproc и Google Compute Engine.
Нажмите на значок меню в верхнем левом углу экрана.

Выберите «Менеджер API» из выпадающего списка.
Нажмите «Включить API и сервисы» .

Введите в поисковую строку «Compute Engine». В появившемся списке результатов нажмите на «Google Compute Engine API».

На странице Google Compute Engine нажмите «Включить».

После включения нажмите стрелку влево, чтобы вернуться назад.
Теперь найдите "Google Cloud Dataproc API" и включите его.

4. Запустите Cloud Shell
Эта виртуальная машина на базе Debian содержит все необходимые инструменты разработки. Она предоставляет постоянный домашний каталог размером 5 ГБ и работает в облаке Google, что значительно повышает производительность сети и аутентификацию. Это означает, что для выполнения этого практического задания вам понадобится только браузер (да, он работает и на Chromebook).
- Для активации Cloud Shell из консоли Cloud Console просто нажмите «Активировать Cloud Shell».
(На подготовку и подключение к среде должно уйти всего несколько минут).
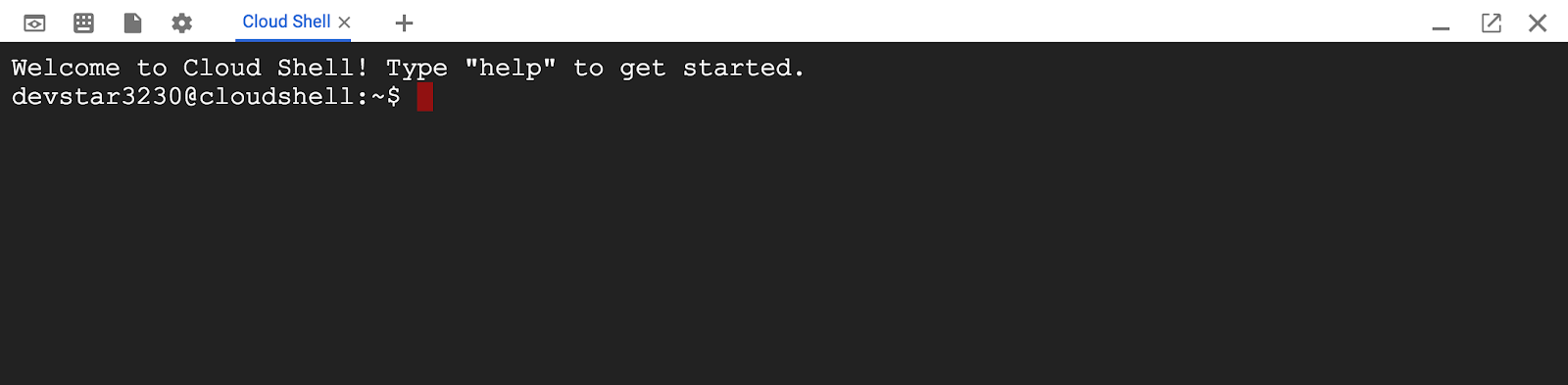
После подключения к Cloud Shell вы увидите, что ваша аутентификация пройдена и проект уже настроен на ваш PROJECT_ID .
gcloud auth list
вывод команды
Credentialed accounts: - <myaccount>@<mydomain>.com (active)
gcloud config list project
вывод команды
[core] project = <PROJECT_ID>
Если по какой-либо причине проект не создан, просто выполните следующую команду:
gcloud config set project <PROJECT_ID>
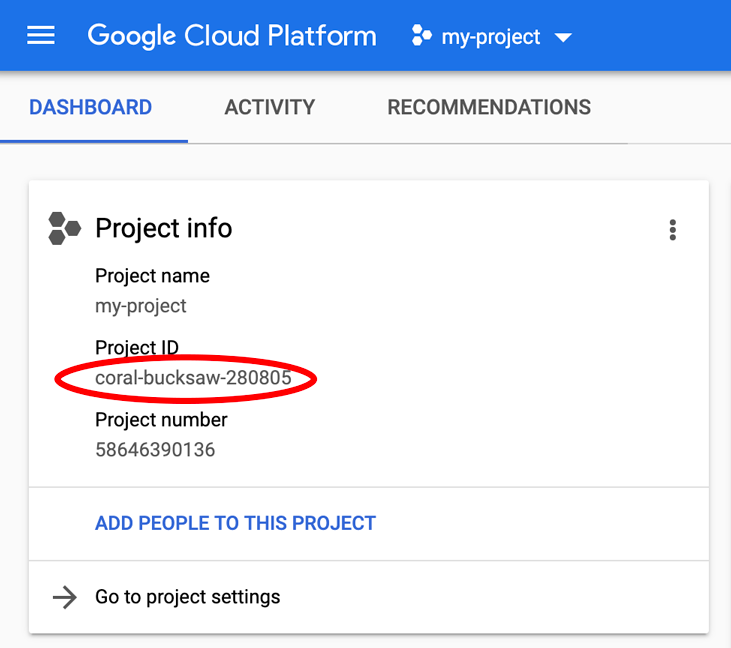
Ищете свой PROJECT_ID ? Проверьте, какой ID вы использовали на этапах настройки, или найдите его на панели управления Cloud Console:
Cloud Shell также по умолчанию устанавливает некоторые переменные среды, которые могут быть полезны при выполнении будущих команд.
echo $GOOGLE_CLOUD_PROJECT
вывод команды
<PROJECT_ID>
- Наконец, установите зону по умолчанию и конфигурацию проекта.
gcloud config set compute/zone us-central1-f
Вы можете выбрать различные зоны. Для получения дополнительной информации см. раздел «Регионы и зоны» .
5. Создайте кластер Cloud Dataproc.
После запуска Cloud Shell вы можете использовать командную строку для вызова команды gcloud из Cloud SDK или других инструментов, доступных в экземпляре виртуальной машины.
Выберите имя кластера для использования в этой лабораторной работе:
$ CLUSTERNAME=${USER}-dplab
Начнём с создания нового кластера:
$ gcloud dataproc clusters create ${CLUSTERNAME} \
--region=us-central1 \
--scopes=cloud-platform \
--tags codelab \
--zone=us-central1-c
Для этого руководства достаточно настроек кластера по умолчанию, включающих два рабочих узла. Приведенная выше команда включает параметр --zone для указания географической зоны, в которой будет создан кластер, а также два дополнительных параметра, --scopes и --tags , которые описаны ниже при использовании функций, которые они позволяют. Информацию об использовании флагов командной строки для настройки параметров кластера см. в документации Cloud SDK gcloud dataproc clusters create command.
6. Отправьте задание Spark в свой кластер.
Вы можете отправить задание через запрос jobs.submit API Cloud Dataproc, используя инструмент командной строки gcloud или из консоли Google Cloud Platform . Вы также можете подключиться к экземпляру машины в вашем кластере с помощью SSH, а затем запустить задание с этого экземпляра.
Давайте отправим задание, используя инструмент gcloud из командной строки Cloud Shell:
$ gcloud dataproc jobs submit spark --cluster ${CLUSTERNAME} \
--class org.apache.spark.examples.SparkPi \
--jars file:///usr/lib/spark/examples/jars/spark-examples.jar -- 1000
В процессе выполнения задания вы будете видеть результат в окне Cloud Shell.
Прервите вывод, нажав Ctrl+C. Это остановит команду gcloud , но задание продолжит выполняться в кластере Dataproc.
7. Составьте список вакансий и возобновите общение.
Распечатать список вакансий:
$ gcloud dataproc jobs list --cluster ${CLUSTERNAME}
Последнее отправленное задание находится вверху списка. Скопируйте идентификатор задания и вставьте его вместо " jobId " в приведенную ниже команду. Команда переподключится к указанному заданию и отобразит его результат:
$ gcloud dataproc jobs wait jobId
По завершении работы в выходных данных будет содержаться приблизительное значение числа Пи.

8. Изменение размера кластера
Для выполнения более сложных вычислений может потребоваться добавить в кластер больше узлов, чтобы ускорить его работу. Dataproc позволяет добавлять и удалять узлы из кластера в любое время.
Изучите конфигурацию кластера:
$ gcloud dataproc clusters describe ${CLUSTERNAME}
Увеличьте размер кластера, добавив несколько узлов с возможностью вытеснения:
$ gcloud dataproc clusters update ${CLUSTERNAME} --num-secondary-workers=2
Проверим кластер еще раз:
$ gcloud dataproc clusters describe ${CLUSTERNAME}
Обратите внимание, что в дополнение к workerConfig из исходного описания кластера теперь также присутствует secondaryWorkerConfig , который включает два instanceNames для прерываемых рабочих процессов. Dataproc показывает статус кластера как «готов» во время загрузки новых узлов.
Поскольку вы начинали с двух узлов, а теперь у вас их четыре, ваши задания Spark должны выполняться примерно в два раза быстрее.
9. Подключение к кластеру по SSH.
Подключитесь по SSH к главному узлу, имя экземпляра которого всегда совпадает с именем кластера с добавлением параметра -m :
$ gcloud compute ssh ${CLUSTERNAME}-m --zone=us-central1-c
При первом запуске команды ssh в Cloud Shell будут сгенерированы SSH-ключи для вашей учетной записи. Вы можете выбрать парольную фразу или использовать пустую фразу, а затем изменить ее с помощью ssh-keygen если захотите.
На экземпляре проверьте имя хоста:
$ hostname
Поскольку при создании кластера вы указали --scopes=cloud-platform , вы можете запускать команды gcloud в своем кластере. Перечислите кластеры в вашем проекте:
$ gcloud dataproc clusters list
Когда закончите, выйдите из SSH-соединения:
$ logout
10. Осмотрите бирки.
При создании кластера вы добавили опцию --tags для добавления тега к каждому узлу в кластере. Теги используются для прикрепления правил брандмауэра к каждому узлу. В этом практическом задании вы не создавали соответствующих правил брандмауэра, но вы все равно можете просмотреть теги на узле и правила брандмауэра в сети.
Вывести описание главного узла:
$ gcloud compute instances describe ${CLUSTERNAME}-m --zone us-central1-c
Найдите tags: в конце вывода и убедитесь, что он включает codelab .`.
Распечатайте правила брандмауэра:
$ gcloud compute firewall-rules list
Обратите внимание на столбцы SRC_TAGS и TARGET_TAGS . Прикрепив тег к правилу брандмауэра, вы можете указать, что оно должно использоваться на всех узлах, имеющих этот тег.
11. Выключите кластер.
Выключить кластер можно с помощью запроса clusters.delete через API Cloud Dataproc, из командной строки, используя исполняемый файл gcloud dataproc clusters delete , или из консоли Google Cloud Platform .
Давайте остановим кластер с помощью командной строки Cloud Shell:
$ gcloud dataproc clusters delete ${CLUSTERNAME} --region us-central1
12. Поздравляем!
Вы научились создавать кластер Dataproc, отправлять задания Spark, изменять размер кластера, использовать SSH для входа на главный узел, использовать gcloud для проверки кластеров, заданий и правил брандмауэра, а также выключать кластер с помощью gcloud!
Узнать больше
- Документация Dataproc: https://cloud.google.com/dataproc/overview
- Начало работы с Dataproc с помощью примера работы в консоли.
Лицензия
Данная работа распространяется под лицензией Creative Commons Attribution 3.0 Generic License и лицензией Apache 2.0.