
1. ภาพรวม
Cloud Dataproc เป็นบริการ Spark และ Hadoop ที่มีการจัดการ ซึ่งช่วยให้คุณใช้ประโยชน์จากเครื่องมือข้อมูลแบบโอเพนซอร์สสำหรับการประมวลผลแบบกลุ่ม การค้นหา การสตรีม และแมชชีนเลิร์นนิงได้ ระบบอัตโนมัติของ Cloud Dataproc ช่วยให้คุณสร้างคลัสเตอร์ได้อย่างรวดเร็ว จัดการคลัสเตอร์ได้อย่างง่ายดาย และประหยัดเงินด้วยการปิดคลัสเตอร์เมื่อไม่จำเป็น เมื่อใช้เวลาและเงินในการดูแลระบบน้อยลง คุณก็จะมีเวลาโฟกัสกับงานและข้อมูลมากขึ้น
บทแนะนำนี้ดัดแปลงมาจาก https://cloud.google.com/dataproc/overview
สิ่งที่คุณจะได้เรียนรู้
- วิธีสร้างคลัสเตอร์ Cloud Dataproc ที่มีการจัดการ (ติดตั้ง Apache Spark ไว้ล่วงหน้า)
- วิธีส่งงาน Spark
- วิธีปรับขนาดคลัสเตอร์
- วิธี SSH ไปยังโหนดหลักของคลัสเตอร์ Dataproc
- วิธีใช้ gcloud เพื่อตรวจสอบคลัสเตอร์ งาน และกฎไฟร์วอลล์
- วิธีปิดคลัสเตอร์
สิ่งที่คุณต้องมี
คุณจะใช้บทแนะนำนี้อย่างไร
คุณจะให้คะแนนประสบการณ์การใช้บริการ Google Cloud Platform เท่าใด
2. การตั้งค่าและข้อกำหนด
การตั้งค่าสภาพแวดล้อมแบบเรียนรู้ด้วยตนเอง
- ลงชื่อเข้าใช้ Cloud Console แล้วสร้างโปรเจ็กต์ใหม่หรือใช้โปรเจ็กต์ที่มีอยู่ซ้ำ (หากยังไม่มีบัญชี Gmail หรือ G Suite คุณต้องสร้างบัญชี)



โปรดจดจำรหัสโปรเจ็กต์ ซึ่งเป็นชื่อที่ไม่ซ้ำกันในโปรเจ็กต์ Google Cloud ทั้งหมด (ชื่อด้านบนมีผู้ใช้แล้วและจะใช้ไม่ได้ ขออภัย) ซึ่งจะเรียกว่า PROJECT_ID ในภายหลังใน Codelab นี้
- จากนั้นคุณจะต้องเปิดใช้การเรียกเก็บเงินใน Cloud Console เพื่อใช้ทรัพยากร Google Cloud
การทำตาม Codelab นี้ไม่ควรมีค่าใช้จ่ายมากนัก หรืออาจไม่มีเลย โปรดทำตามวิธีการในส่วน "การล้างข้อมูล" ซึ่งจะแนะนำวิธีปิดทรัพยากรเพื่อไม่ให้มีการเรียกเก็บเงินนอกเหนือจากบทแนะนำนี้ ผู้ใช้ Google Cloud รายใหม่มีสิทธิ์เข้าร่วมโปรแกรมช่วงทดลองใช้ฟรีมูลค่า$300 USD
3. เปิดใช้ Cloud Dataproc และ Google Compute Engine API
คลิกไอคอนเมนูที่ด้านซ้ายบนของหน้าจอ

เลือก API Manager จากเมนูแบบเลื่อนลง

คลิกเปิดใช้ API และบริการ

ค้นหา "Compute Engine" ในช่องค้นหา คลิก "Google Compute Engine API" ในรายการผลลัพธ์ที่ปรากฏ

ในหน้า Google Compute Engine ให้คลิกเปิดใช้

เมื่อเปิดใช้แล้ว ให้คลิกลูกศรที่ชี้ไปทางซ้ายเพื่อกลับไป
ตอนนี้ให้ค้นหา "Google Cloud Dataproc API" แล้วเปิดใช้ด้วย

4. เริ่มต้น Cloud Shell
เครื่องเสมือนที่ใช้ Debian นี้มาพร้อมเครื่องมือพัฒนาทั้งหมดที่คุณต้องการ โดยมีไดเรกทอรีหลักแบบถาวรขนาด 5 GB และทำงานใน Google Cloud ซึ่งช่วยเพิ่มประสิทธิภาพเครือข่ายและการตรวจสอบสิทธิ์ได้อย่างมาก ซึ่งหมายความว่าคุณจะต้องมีเพียงเบราว์เซอร์เท่านั้นสำหรับโค้ดแล็บนี้ (ใช่แล้ว ใช้ได้ใน Chromebook)
- หากต้องการเปิดใช้งาน Cloud Shell จาก Cloud Console เพียงคลิกเปิดใช้งาน Cloud Shell
(ระบบจะใช้เวลาเพียงไม่กี่นาทีในการจัดสรรและเชื่อมต่อกับสภาพแวดล้อม)
เมื่อเชื่อมต่อกับ Cloud Shell แล้ว คุณควรเห็นว่าระบบได้ตรวจสอบสิทธิ์คุณแล้ว และตั้งค่าโปรเจ็กต์เป็น PROJECT_ID แล้ว
gcloud auth list
เอาต์พุตของคำสั่ง
Credentialed accounts: - <myaccount>@<mydomain>.com (active)
gcloud config list project
เอาต์พุตของคำสั่ง
[core] project = <PROJECT_ID>
หากไม่ได้ตั้งค่าโปรเจ็กต์ด้วยเหตุผลบางประการ ให้เรียกใช้คำสั่งต่อไปนี้
gcloud config set project <PROJECT_ID>
หากกำลังมองหา PROJECT_ID ตรวจสอบว่าคุณใช้รหัสใดในขั้นตอนการตั้งค่า หรือค้นหารหัสในแดชบอร์ด Cloud Console
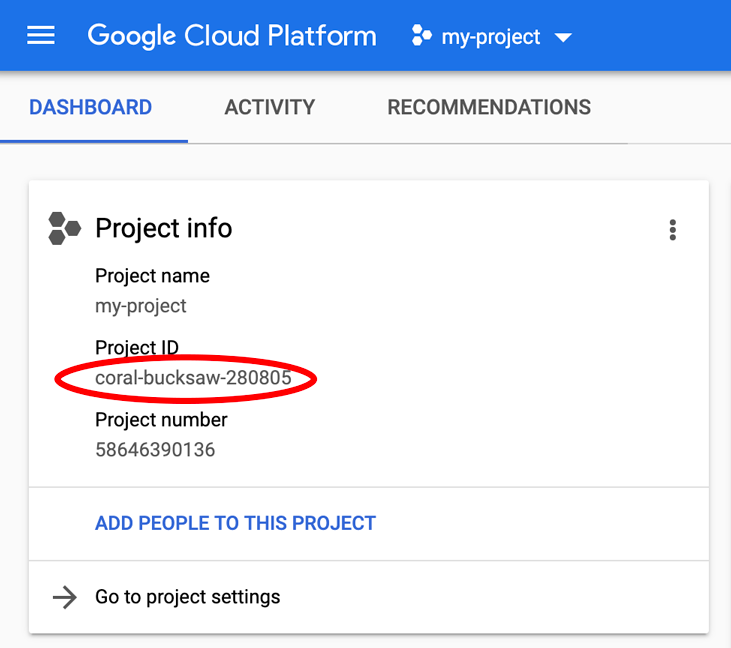
นอกจากนี้ Cloud Shell ยังตั้งค่าตัวแปรสภาพแวดล้อมบางอย่างโดยค่าเริ่มต้น ซึ่งอาจมีประโยชน์เมื่อคุณเรียกใช้คำสั่งในอนาคต
echo $GOOGLE_CLOUD_PROJECT
เอาต์พุตของคำสั่ง
<PROJECT_ID>
- สุดท้าย ให้ตั้งค่าโซนเริ่มต้นและการกำหนดค่าโปรเจ็กต์
gcloud config set compute/zone us-central1-f
คุณเลือกโซนต่างๆ ได้หลากหลาย ดูข้อมูลเพิ่มเติมได้ที่ภูมิภาคและโซน
5. สร้างคลัสเตอร์ Cloud Dataproc
หลังจากเปิดใช้ Cloud Shell แล้ว คุณจะใช้บรรทัดคำสั่งเพื่อเรียกใช้คำสั่ง gcloud ของ Cloud SDK หรือเครื่องมืออื่นๆ ที่มีในอินสแตนซ์เครื่องเสมือนได้
เลือกชื่อคลัสเตอร์ที่จะใช้ใน Lab นี้
$ CLUSTERNAME=${USER}-dplab
มาเริ่มต้นด้วยการสร้างคลัสเตอร์ใหม่กัน
$ gcloud dataproc clusters create ${CLUSTERNAME} \
--region=us-central1 \
--scopes=cloud-platform \
--tags codelab \
--zone=us-central1-c
การตั้งค่าคลัสเตอร์เริ่มต้นซึ่งรวมถึงโหนด Worker 2 รายการควรเพียงพอสำหรับบทแนะนำนี้ คำสั่งด้านบนมีตัวเลือก --zone เพื่อระบุเขตภูมิศาสตร์ที่จะสร้างคลัสเตอร์ และตัวเลือกขั้นสูง 2 รายการ ได้แก่ --scopes และ --tags ซึ่งจะอธิบายไว้ด้านล่างเมื่อคุณใช้ฟีเจอร์ที่ตัวเลือกเหล่านี้เปิดใช้ ดูข้อมูลเกี่ยวกับการใช้ Flag บรรทัดคำสั่งเพื่อปรับแต่งการตั้งค่าคลัสเตอร์ได้ที่คำสั่ง gcloud dataproc clusters create ของ Cloud SDK
6. ส่งงาน Spark ไปยังคลัสเตอร์
คุณส่งงานผ่านคำขอ Cloud Dataproc API jobs.submit ได้โดยใช้เครื่องมือบรรทัดคำสั่ง gcloud หรือจากคอนโซล Google Cloud Platform นอกจากนี้ คุณยังเชื่อมต่อกับอินสแตนซ์ของเครื่องในคลัสเตอร์โดยใช้ SSH แล้วเรียกใช้ช็อตจากอินสแตนซ์ได้ด้วย
มาส่งงานโดยใช้เครื่องมือ gcloud จากบรรทัดคำสั่งของ Cloud Shell กัน
$ gcloud dataproc jobs submit spark --cluster ${CLUSTERNAME} \
--class org.apache.spark.examples.SparkPi \
--jars file:///usr/lib/spark/examples/jars/spark-examples.jar -- 1000
ขณะที่งานทำงาน คุณจะเห็นเอาต์พุตในหน้าต่าง Cloud Shell
ขัดจังหวะเอาต์พุตโดยกด Control-C การดำเนินการนี้จะหยุดคำสั่ง gcloud แต่จะยังคงเรียกใช้งานในคลัสเตอร์ Dataproc ต่อไป
7. แสดงรายการงานและเชื่อมต่ออีกครั้ง
วิธีพิมพ์รายการงาน
$ gcloud dataproc jobs list --cluster ${CLUSTERNAME}
งานที่ส่งล่าสุดจะอยู่ด้านบนสุดของรายการ คัดลอกรหัสงานแล้ววางแทน "jobId" ในคำสั่งด้านล่าง คำสั่งจะเชื่อมต่อกับงานที่ระบุอีกครั้งและแสดงเอาต์พุตของงาน
$ gcloud dataproc jobs wait jobId
เมื่องานเสร็จสมบูรณ์ เอาต์พุตจะมีค่าประมาณของค่าพาย

8. ปรับขนาดคลัสเตอร์
หากต้องการเรียกใช้การคำนวณที่ใหญ่ขึ้น คุณอาจต้องเพิ่มโหนดลงในคลัสเตอร์เพื่อเพิ่มความเร็ว Dataproc ช่วยให้คุณเพิ่มและนำโหนดออกจากคลัสเตอร์ได้ทุกเมื่อ
ตรวจสอบการกำหนดค่าคลัสเตอร์
$ gcloud dataproc clusters describe ${CLUSTERNAME}
ขยายคลัสเตอร์โดยเพิ่มโหนดที่ยุติการทำงานเองได้
$ gcloud dataproc clusters update ${CLUSTERNAME} --num-secondary-workers=2
ตรวจสอบคลัสเตอร์อีกครั้ง
$ gcloud dataproc clusters describe ${CLUSTERNAME}
โปรดทราบว่านอกจาก workerConfig จากคำอธิบายคลัสเตอร์เดิมแล้ว ตอนนี้ยังมี secondaryWorkerConfig ที่มี instanceNames 2 รายการสำหรับ Worker ที่หยุดชั่วคราวได้ด้วย Dataproc จะแสดงสถานะคลัสเตอร์เป็น "พร้อม" ในขณะที่โหนดใหม่กำลังบูต
เนื่องจากคุณเริ่มต้นด้วย 2 โหนดและตอนนี้มี 4 โหนดแล้ว งาน Spark ของคุณจึงควรทำงานเร็วขึ้นประมาณ 2 เท่า
9. SSH เข้าสู่คลัสเตอร์
เชื่อมต่อผ่าน SSH ไปยังโหนดหลักซึ่งมีชื่ออินสแตนซ์เป็นชื่อคลัสเตอร์เสมอโดยมี -m ต่อท้าย
$ gcloud compute ssh ${CLUSTERNAME}-m --zone=us-central1-c
เมื่อคุณเรียกใช้คำสั่ง ssh ใน Cloud Shell เป็นครั้งแรก ระบบจะสร้างคีย์ SSH สำหรับบัญชีของคุณในนั้น คุณสามารถเลือกใช้รหัสผ่าน หรือใช้รหัสผ่านว่างไว้ก่อนแล้วเปลี่ยนในภายหลังโดยใช้ ssh-keygen หากต้องการ
ตรวจสอบชื่อโฮสต์ในอินสแตนซ์โดยทำดังนี้
$ hostname
เนื่องจากคุณระบุ --scopes=cloud-platform เมื่อสร้างคลัสเตอร์ คุณจึงเรียกใช้คำสั่ง gcloud ในคลัสเตอร์ได้ แสดงรายการคลัสเตอร์ในโปรเจ็กต์
$ gcloud dataproc clusters list
ออกจากระบบการเชื่อมต่อ SSH เมื่อดำเนินการเสร็จแล้ว
$ logout
10. ตรวจสอบแท็ก
เมื่อสร้างคลัสเตอร์ คุณได้รวม--tagsตัวเลือกในการเพิ่มแท็กให้กับแต่ละโหนดในคลัสเตอร์ ระบบใช้แท็กเพื่อแนบกฎไฟร์วอลล์กับแต่ละโหนด คุณไม่ได้สร้างกฎไฟร์วอลล์ที่ตรงกันใน Codelab นี้ แต่ยังคงตรวจสอบแท็กในโหนดและกฎไฟร์วอลล์ในเครือข่ายได้
พิมพ์คำอธิบายของโหนดหลัก
$ gcloud compute instances describe ${CLUSTERNAME}-m --zone us-central1-c
มองหา tags: ใกล้กับส่วนท้ายของเอาต์พุตและดูว่ามี codelab
พิมพ์กฎไฟร์วอลล์
$ gcloud compute firewall-rules list
สังเกตคอลัมน์ SRC_TAGS และ TARGET_TAGS การแนบแท็กกับกฎไฟร์วอลล์จะช่วยให้คุณระบุได้ว่าควรใช้กฎดังกล่าวในโหนดทั้งหมดที่มีแท็กนั้น
11. ปิดคลัสเตอร์
คุณปิดคลัสเตอร์ได้ผ่านคำขอ Cloud Dataproc API clusters.delete จากบรรทัดคำสั่งโดยใช้ไฟล์ที่เรียกใช้งานได้ gcloud dataproc clusters delete หรือจากคอนโซล Google Cloud Platform
มาปิดคลัสเตอร์โดยใช้บรรทัดคำสั่ง Cloud Shell กัน
$ gcloud dataproc clusters delete ${CLUSTERNAME} --region us-central1
12. ยินดีด้วย
คุณได้เรียนรู้วิธีสร้างคลัสเตอร์ Dataproc, ส่งงาน Spark, ปรับขนาดคลัสเตอร์, ใช้ SSH เพื่อเข้าสู่ระบบโหนดหลัก, ใช้ gcloud เพื่อตรวจสอบคลัสเตอร์ งาน และกฎไฟร์วอลล์ รวมถึงปิดคลัสเตอร์โดยใช้ gcloud
ดูข้อมูลเพิ่มเติม
- เอกสารประกอบ Dataproc: https://cloud.google.com/dataproc/overview
- Codelab การเริ่มต้นใช้งาน Dataproc โดยใช้ Console
ใบอนุญาต
ผลงานนี้ได้รับอนุญาตภายใต้สัญญาอนุญาตครีเอทีฟคอมมอนส์แบบระบุแหล่งที่มา 3.0 ทั่วไป และสัญญาอนุญาต Apache 2.0