
1. Genel Bakış
Cloud Dataproc, toplu işleme, sorgulama, akış ve makine öğrenimi için açık kaynaklı veri araçlarından yararlanmanızı sağlayan yönetilen bir Spark ve Hadoop hizmetidir. Cloud Dataproc otomasyonu, kümeleri hızlı bir şekilde oluşturmanıza, kolayca yönetmenize ve ihtiyacınız olmadığında kümeleri kapatarak tasarruf etmenize yardımcı olur. Yönetime daha az zaman ve para harcayarak işlerinize ve verilerinize odaklanabilirsiniz.
Bu eğitim, https://cloud.google.com/dataproc/overview adresinden uyarlanmıştır.
Neler öğreneceksiniz?
- Yönetilen bir Cloud Dataproc kümesi oluşturma (Apache Spark önceden yüklenmiş).
- Spark işi gönderme
- Küme nasıl yeniden boyutlandırılır?
- Dataproc kümesinin ana düğümüne SSH ile bağlanma
- Kümeleri, işleri ve güvenlik duvarı kurallarını incelemek için gcloud'u kullanma
- Kümenizi kapatma
Gerekenler
Bu eğiticiden nasıl yararlanacaksınız?
Google Cloud Platform hizmetlerini kullanma deneyiminizi nasıl değerlendirirsiniz?
2. Kurulum ve Gereksinimler
Yönlendirmesiz ortam kurulumu
- Cloud Console'da oturum açın ve yeni bir proje oluşturun veya mevcut bir projeyi yeniden kullanın. (Gmail veya G Suite hesabınız yoksa hesap oluşturmanız gerekir.)



Proje kimliğini unutmayın. Bu kimlik, tüm Google Cloud projelerinde benzersiz bir addır (Yukarıdaki ad zaten alınmış olduğundan sizin için çalışmayacaktır). Bu codelab'in ilerleyen kısımlarında PROJECT_ID olarak adlandırılacaktır.
- Ardından, Google Cloud kaynaklarını kullanmak için Cloud Console'da faturalandırmayı etkinleştirmeniz gerekir.
Bu codelab'i tamamlamak neredeyse hiç maliyetli değildir. Bu eğitimin ötesinde faturalandırma ücreti alınmaması için kaynakları nasıl kapatacağınız konusunda size tavsiyelerde bulunan "Temizleme" bölümündeki talimatları uyguladığınızdan emin olun. Google Cloud'un yeni kullanıcıları 300 ABD doları değerinde ücretsiz deneme programından yararlanabilir.
3. Cloud Dataproc ve Google Compute Engine API'lerini etkinleştirin.
Ekranın sol üst kısmındaki menü simgesini tıklayın.

Açılır menüden API Yöneticisi'ni seçin.

API'leri ve hizmetleri etkinleştir'i tıklayın.

Arama kutusuna "Compute Engine" yazın. Görünen sonuç listesinde "Google Compute Engine API"yi tıklayın.

Google Compute Engine sayfasında Etkinleştir'i tıklayın.

Etkinleştirildikten sonra geri gitmek için sola bakan oku tıklayın.
Şimdi "Google Cloud Dataproc API"yi arayın ve bunu da etkinleştirin.

4. Cloud Shell'i Başlatma
Bu Debian tabanlı sanal makine, ihtiyaç duyacağınız tüm geliştirme araçlarını içerir. 5 GB boyutunda kalıcı bir ana dizin bulunur ve Google Cloud'da çalışır. Bu sayede ağ performansı ve kimlik doğrulama önemli ölçüde güçlenir. Bu nedenle, bu codelab için ihtiyacınız olan tek şey bir tarayıcıdır (Chromebook'ta da çalışır).
- Cloud Shell'i Cloud Console'dan etkinleştirmek için Cloud Shell'i etkinleştir 'i
tıklamanız yeterlidir (ortamın sağlanması ve bağlantının kurulması yalnızca birkaç saniye sürer).
Cloud Shell'e bağlandıktan sonra kimliğinizin doğrulandığını ve projenin, PROJECT_ID'nize ayarlandığını görürsünüz.
gcloud auth list
Komut çıkışı
Credentialed accounts: - <myaccount>@<mydomain>.com (active)
gcloud config list project
Komut çıkışı
[core] project = <PROJECT_ID>
Herhangi bir nedenle proje ayarlanmamışsa şu komutu verin:
gcloud config set project <PROJECT_ID>
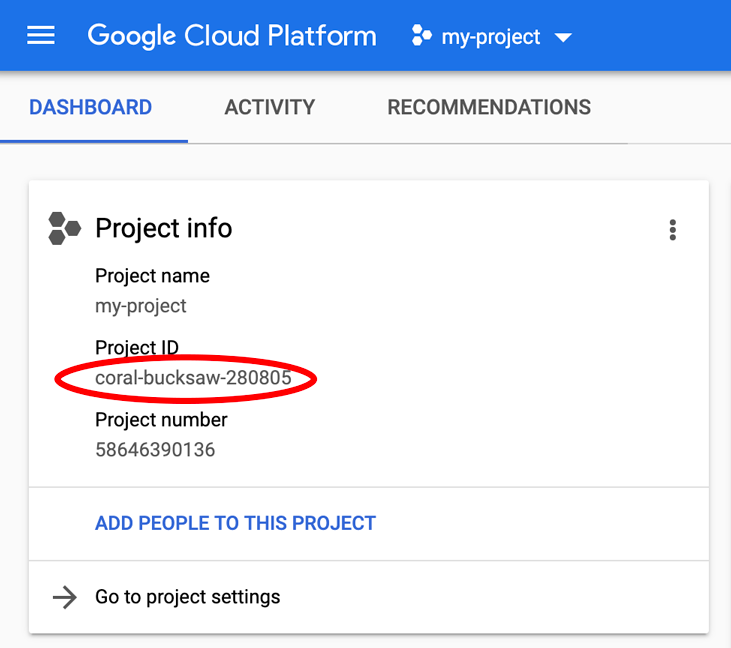
PROJECT_ID cihazınızı mı arıyorsunuz? Kurulum adımlarında hangi kimliği kullandığınızı kontrol edin veya Cloud Console kontrol panelinde arayın:
Cloud Shell, gelecekteki komutları çalıştırırken faydalı olabilecek bazı ortam değişkenlerini de varsayılan olarak ayarlar.
echo $GOOGLE_CLOUD_PROJECT
Komut çıkışı
<PROJECT_ID>
- Son olarak, varsayılan alt bölgeyi ve proje yapılandırmasını ayarlayın.
gcloud config set compute/zone us-central1-f
Çeşitli bölgeler arasından seçim yapabilirsiniz. Daha fazla bilgi için Bölgeler ve Alt Bölgeler başlıklı makaleyi inceleyin.
5. Bir Cloud Dataproc kümesi oluşturun
Cloud Shell başlatıldıktan sonra Cloud SDK gcloud komutunu veya sanal makine örneğinde bulunan diğer araçları çağırmak için komut satırını kullanabilirsiniz.
Bu laboratuvarda kullanılacak bir küme adı seçin:
$ CLUSTERNAME=${USER}-dplab
Yeni bir küme oluşturarak başlayalım:
$ gcloud dataproc clusters create ${CLUSTERNAME} \
--region=us-central1 \
--scopes=cloud-platform \
--tags codelab \
--zone=us-central1-c
İki çalışma düğümü içeren varsayılan küme ayarları bu eğitim için yeterli olmalıdır. Yukarıdaki komutta, kümenin oluşturulacağı coğrafi bölgeyi belirtmek için --zone seçeneği ve iki gelişmiş seçenek (--scopes ve --tags) yer alır. Bu seçenekler, etkinleştirdikleri özellikler kullanıldığında aşağıda açıklanır. Küme ayarlarını özelleştirmek için komut satırı işaretlerini kullanma hakkında bilgi edinmek üzere Cloud SDK gcloud dataproc clusters create komutuna bakın.
6. Kümenize Spark işi gönderme
Cloud Dataproc API jobs.submit isteğiyle, gcloud komut satırı aracını kullanarak veya Google Cloud Platform Console'dan iş gönderebilirsiniz. Ayrıca, SSH kullanarak kümenizdeki bir makine örneğine bağlanabilir ve ardından örnekten bir iş çalıştırabilirsiniz.
Cloud Shell komut satırından gcloud aracını kullanarak bir iş gönderelim:
$ gcloud dataproc jobs submit spark --cluster ${CLUSTERNAME} \
--class org.apache.spark.examples.SparkPi \
--jars file:///usr/lib/spark/examples/jars/spark-examples.jar -- 1000
İş çalışırken çıkışı Cloud Shell pencerenizde görürsünüz.
Control-C tuşlarına basarak çıkışı durdurun. Bu işlem, gcloud komutunu durdurur ancak iş, Dataproc kümesinde çalışmaya devam eder.
7. İşleri Listeleme ve Yeniden Bağlanma
İş listesini yazdırma:
$ gcloud dataproc jobs list --cluster ${CLUSTERNAME}
En son gönderilen iş, listenin en üstünde yer alır. İş kimliğini kopyalayın ve aşağıdaki komutta "jobId" yerine yapıştırın. Komut, belirtilen işe yeniden bağlanır ve çıkışını gösterir:
$ gcloud dataproc jobs wait jobId
İş tamamlandığında çıkış, Pi değerinin yaklaşık bir değerini içerir.

8. Kümeyi Yeniden Boyutlandırma
Daha büyük hesaplamalar yapmak için kümenize daha fazla düğüm ekleyerek hızını artırabilirsiniz. Dataproc, istediğiniz zaman kümenize düğüm eklemenize ve kümenizden düğüm kaldırmanıza olanak tanır.
Küme yapılandırmasını inceleyin:
$ gcloud dataproc clusters describe ${CLUSTERNAME}
Öncelikli düğümler ekleyerek kümeyi büyütün:
$ gcloud dataproc clusters update ${CLUSTERNAME} --num-secondary-workers=2
Kümeyi tekrar inceleyin:
$ gcloud dataproc clusters describe ${CLUSTERNAME}
Orijinal küme açıklamasındaki workerConfig'ya ek olarak, artık öncelikli olmayan çalışanlar için iki instanceNames içeren bir secondaryWorkerConfig olduğunu unutmayın. Dataproc, yeni düğümler başlatılırken küme durumunu hazır olarak gösterir.
İki düğümle başladığınız ve şu anda dört düğüme sahip olduğunuz için Spark işleriniz yaklaşık iki kat daha hızlı çalışmalıdır.
9. Kümeye SSH ile bağlanma
Örnek adı her zaman -m eklenmiş küme adı olan ana düğüme SSH üzerinden bağlanın:
$ gcloud compute ssh ${CLUSTERNAME}-m --zone=us-central1-c
Cloud Shell'de ilk kez bir SSH komutu çalıştırdığınızda hesabınız için SSH anahtarları oluşturulur. Parola seçebilir veya isterseniz şimdilik boş bir parola kullanıp daha sonra ssh-keygen seçeneğini kullanarak değiştirebilirsiniz.
Örnekte ana makine adını kontrol edin:
$ hostname
Küme oluştururken --scopes=cloud-platform belirttiğiniz için kümenizde gcloud komutlarını çalıştırabilirsiniz. Projenizdeki kümeleri listeleyin:
$ gcloud dataproc clusters list
İşiniz bittiğinde SSH bağlantısından çıkış yapın:
$ logout
10. Etiketleri inceleme
Kümenizi oluştururken, kümedeki her düğüme etiket eklemek için --tags seçeneğini belirlediniz. Etiketler, güvenlik duvarı kurallarını her düğüme eklemek için kullanılır. Bu codelab'de eşleşen güvenlik duvarı kuralları oluşturmadınız ancak yine de bir düğümdeki etiketleri ve ağdaki güvenlik duvarı kurallarını inceleyebilirsiniz.
Ana düğümün açıklamasını yazdırın:
$ gcloud compute instances describe ${CLUSTERNAME}-m --zone us-central1-c
Çıkışın sonuna yakın bir yerde tags: ifadesini bulun ve codelab içerdiğini doğrulayın.
Güvenlik duvarı kurallarını yazdırma:
$ gcloud compute firewall-rules list
SRC_TAGS ve TARGET_TAGS sütunlarını not edin. Bir güvenlik duvarı kuralına etiket ekleyerek bu etikete sahip tüm düğümlerde kullanılmasını sağlayabilirsiniz.
11. Kümenizi kapatma
Bir kümeyi Cloud Dataproc API clusters.delete isteğiyle, komut satırından gcloud dataproc clusters delete yürütülebilir dosyasını kullanarak veya Google Cloud Platform Console'dan kapatabilirsiniz.
Cloud Shell komut satırını kullanarak kümeyi kapatalım:
$ gcloud dataproc clusters delete ${CLUSTERNAME} --region us-central1
12. Tebrikler!
Dataproc kümesi oluşturmayı, Spark işi göndermeyi, kümeyi yeniden boyutlandırmayı, ana düğümünüze giriş yapmak için SSH'yi kullanmayı, kümeleri, işleri ve güvenlik duvarı kurallarını incelemek için gcloud'u kullanmayı ve gcloud'u kullanarak kümenizi kapatmayı öğrendiniz.
Daha Fazla Bilgi
- Dataproc Belgeleri: https://cloud.google.com/dataproc/overview
- Console'u kullanarak Dataproc'u kullanmaya başlama codelab'i
Lisans
Bu çalışma, Creative Commons Attribution 3.0 Genel Amaçlı Lisans ve Apache 2.0 lisansı ile lisanslanmıştır.