
1. 總覽
Cloud Dataproc 是一項代管的 Spark 和 Hadoop 服務,能夠讓您妥善運用開放原始碼資料工具,進行批次處理、查詢、串流及機器學習作業。Cloud Dataproc 自動化功能可協助您快速建立叢集、輕鬆管理叢集,並在不需要叢集時關閉叢集來節省支出。省下管理作業所需的時間與費用之後,您就能專心處理工作與資料。
本教學課程改編自 https://cloud.google.com/dataproc/overview
課程內容
- 如何建立代管 Cloud Dataproc 叢集 (需預先安裝 Apache Spark)。
- 如何提交 Spark 工作
- 如何調整叢集大小
- 如何透過 SSH 連線至 Dataproc 叢集的主要節點
- 如何使用 gcloud 檢查叢集、作業和防火牆規則
- 如何關閉叢集
軟硬體需求
您會如何使用這項教學課程?
您對使用 Google Cloud Platform 服務的體驗有何評價?
2. 設定和需求
自修實驗室環境設定



請記住專案 ID,這是所有 Google Cloud 專案中不重複的名稱 (上述名稱已遭占用,因此不適用於您,抱歉!)。本程式碼研究室稍後會將其稱為 PROJECT_ID。
- 接著,您必須在 Cloud 控制台中啟用帳單,才能使用 Google Cloud 資源。
完成本程式碼研究室的費用應該不高,甚至完全免費。請務必按照「清除」部分的指示操作,瞭解如何停用資源,避免在本教學課程結束後繼續產生帳單費用。Google Cloud 新使用者可參加價值$300 美元的免費試用計畫。
3. 啟用 Cloud Dataproc 和 Google Compute Engine API
按一下畫面左上方的「選單」圖示。

從下拉式選單中選取「API 管理工具」。

按一下「啟用 API 和服務」。

在搜尋框中搜尋「Compute Engine」。在顯示的結果清單中,按一下「Google Compute Engine API」。

在 Google Compute Engine 頁面中,按一下「啟用」

啟用後,請點選向左箭頭返回。
現在搜尋「Google Cloud Dataproc API」,並啟用這項 API。

4. 啟動 Cloud Shell
這部以 Debian 為基礎的虛擬機器,搭載各種您需要的開發工具,並提供永久的 5GB 主目錄,而且可在 Google Cloud 運作,大幅提升網路效能並強化驗證功能。也就是說,您只需要瀏覽器 (Chromebook 也可以) 就能完成本程式碼研究室。
- 如要從 Cloud 控制台啟用 Cloud Shell,只要按一下「啟用 Cloud Shell」
即可 (佈建並連線至環境的作業需要一些時間才能完成)。
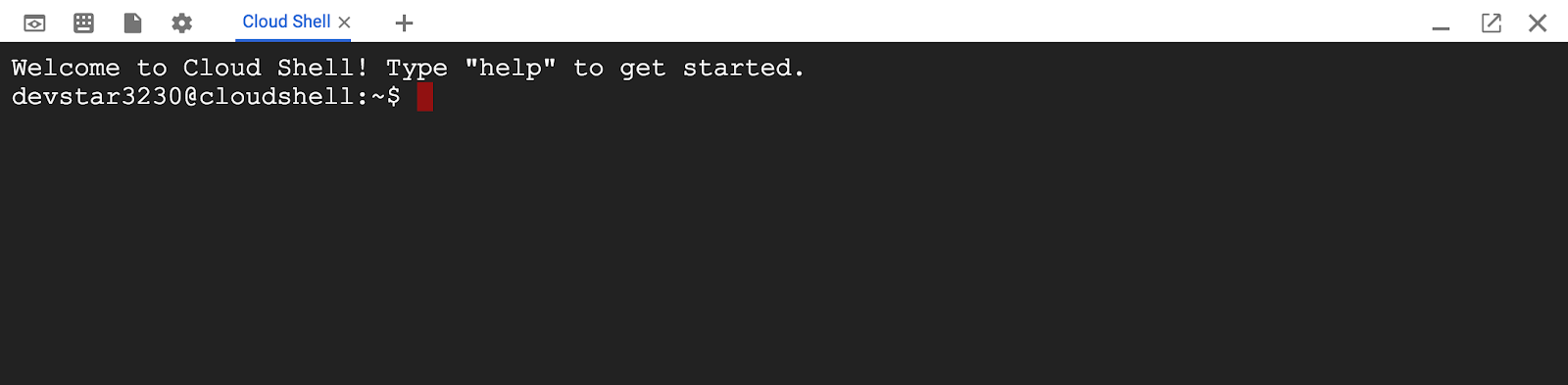
連至 Cloud Shell 後,您應該會看到驗證已完成,專案也已設為獲派的專案 ID PROJECT_ID。
gcloud auth list
指令輸出
Credentialed accounts: - <myaccount>@<mydomain>.com (active)
gcloud config list project
指令輸出
[core] project = <PROJECT_ID>
如果專案未設定,請發出下列指令:
gcloud config set project <PROJECT_ID>
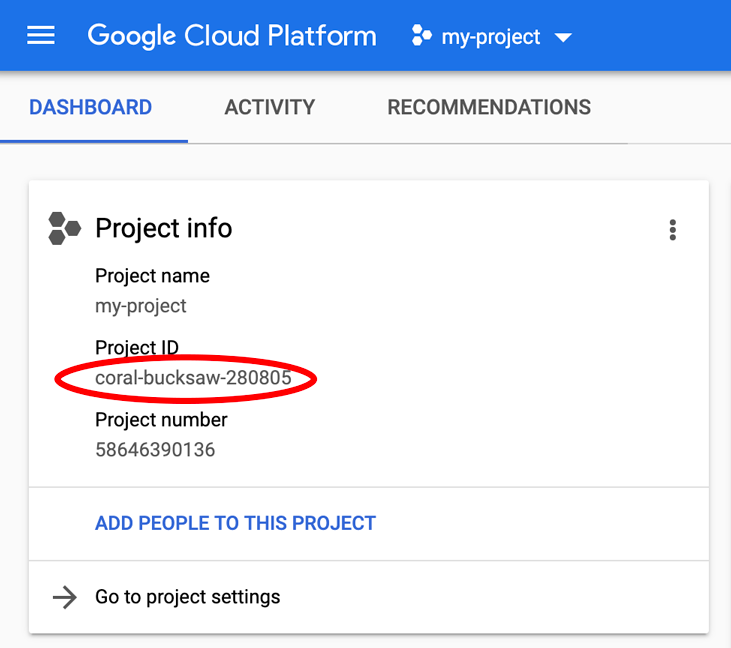
在尋找「PROJECT_ID」嗎?請檢查您在設定步驟中使用的 ID,或在 Cloud 控制台資訊主頁中尋找:
Cloud Shell 也會預設設定部分環境變數,這些變數在您執行後續指令時可能很有用。
echo $GOOGLE_CLOUD_PROJECT
指令輸出
<PROJECT_ID>
- 最後,設定預設可用區和專案。
gcloud config set compute/zone us-central1-f
你可以選擇各種不同區域。詳情請參閱「地區和區域」。
5. 建立 Cloud Dataproc 叢集
啟動 Cloud Shell 後,您可以使用指令列叫用 Cloud SDK gcloud 指令,或叫用虛擬機器執行個體提供的其他工具。
選擇要在本實驗室使用的叢集名稱:
$ CLUSTERNAME=${USER}-dplab
首先,請建立新的叢集:
$ gcloud dataproc clusters create ${CLUSTERNAME} \
--region=us-central1 \
--scopes=cloud-platform \
--tags codelab \
--zone=us-central1-c
預設的叢集設定包含兩個工作站節點,應能滿足本教學課程的需求。上述指令包含 --zone 選項,可指定要建立叢集的地理區域,以及兩個進階選項 --scopes 和 --tags。使用這些選項啟用的功能時,我們會說明這些選項。如要瞭解如何使用指令列旗標來自訂叢集設定,請參閱 Cloud SDK gcloud dataproc clusters create 指令。
6. 將 Spark 工作提交至叢集
您可以透過 Cloud Dataproc API jobs.submit 要求、使用 gcloud 指令列工具,或從 Google Cloud Platform 主控台提交工作。您也可以使用 SSH 連線至叢集中的機器執行個體,然後從該執行個體執行工作。
接著,我們將透過 Cloud Shell 指令列的 gcloud 工具提交工作:
$ gcloud dataproc jobs submit spark --cluster ${CLUSTERNAME} \
--class org.apache.spark.examples.SparkPi \
--jars file:///usr/lib/spark/examples/jars/spark-examples.jar -- 1000
作業執行時,Cloud Shell 視窗會顯示輸出內容。
輸入 Control-C 中斷輸出內容。這會停止 gcloud 指令,但工作仍會在 Dataproc 叢集上執行。
7. 列出工作並重新連線
列印工作清單:
$ gcloud dataproc jobs list --cluster ${CLUSTERNAME}
最近提交的工作會顯示在清單頂端。複製作業 ID,並貼到下方指令的「jobId」位置。這項指令會重新連線至指定工作,並顯示其輸出內容:
$ gcloud dataproc jobs wait jobId
工作完成後,輸出內容會包含圓周率的近似值。

8. 調整叢集大小
如要執行較大的運算作業,建議在叢集中新增更多節點,以加快運算速度。Dataproc 可讓您隨時在叢集中新增及移除節點。
檢查叢集設定:
$ gcloud dataproc clusters describe ${CLUSTERNAME}
新增一些先佔節點,擴大叢集:
$ gcloud dataproc clusters update ${CLUSTERNAME} --num-secondary-workers=2
再次檢查叢集:
$ gcloud dataproc clusters describe ${CLUSTERNAME}
請注意,除了原始叢集說明中的 workerConfig 之外,現在還有 secondaryWorkerConfig,其中包含先占 worker 的兩個 instanceNames。新節點啟動時,Dataproc 會將叢集狀態顯示為就緒。
您一開始有兩個節點,現在有四個,因此 Spark 工作執行速度應該會快上兩倍。
9. 透過 SSH 連線至叢集
透過 SSH 連線至主節點,執行個體名稱一律為叢集名稱加上 -m:
$ gcloud compute ssh ${CLUSTERNAME}-m --zone=us-central1-c
首次在 Cloud Shell 執行 ssh 指令時,系統會為您的帳戶產生 ssh 金鑰。您可以選擇通關密語,也可以暫時使用空白通關密語,日後再透過 ssh-keygen 變更。
在執行個體上檢查主機名稱:
$ hostname
由於您在建立叢集時指定了 --scopes=cloud-platform,因此可以在叢集上執行 gcloud 指令。列出專案中的叢集:
$ gcloud dataproc clusters list
完成後,請登出 SSH 連線:
$ logout
10. 檢查代碼
建立叢集時,您加入了 --tags 選項,可為叢集中的每個節點新增標記。標記用於將防火牆規則附加至每個節點。您在本 Codelab 中未建立任何相符的防火牆規則,但仍可檢查節點上的標記和網路上的防火牆規則。
列印主節點的說明:
$ gcloud compute instances describe ${CLUSTERNAME}-m --zone us-central1-c
在輸出內容結尾附近尋找 tags:,確認其中包含 codelab。
列印防火牆規則:
$ gcloud compute firewall-rules list
請注意 SRC_TAGS 和 TARGET_TAGS 欄。只要將標記附加至防火牆規則,即可指定該規則應套用至所有具有該標記的節點。
11. 關閉叢集
您可以透過 Cloud Dataproc API clusters.delete 要求、使用 gcloud dataproc clusters delete 可執行檔從指令列,或從 Google Cloud Platform 主控台關閉叢集。
讓我們使用 Cloud Shell 指令列關閉叢集:
$ gcloud dataproc clusters delete ${CLUSTERNAME} --region us-central1
12. 恭喜!
您已瞭解如何建立 Dataproc 叢集、提交 Spark 工作、調整叢集大小、使用 SSH 登入主要節點、使用 gcloud 檢查叢集、工作和防火牆規則,以及使用 gcloud 關閉叢集!
瞭解詳情
- Dataproc 說明文件:https://cloud.google.com/dataproc/overview
- 透過控制台開始使用 Dataproc 程式碼研究室
授權
這項內容採用的授權為創用 CC 姓名標示 3.0 通用授權和 Apache 2.0 授權。