
১. সংক্ষিপ্ত বিবরণ

ডকুমেন্ট এআই কী?
ডকুমেন্ট এআই হলো এমন একটি প্ল্যাটফর্ম যা আপনাকে আপনার ডকুমেন্ট থেকে গুরুত্বপূর্ণ তথ্য আহরণ করতে সাহায্য করে। মূলতঃ, এটি ডকুমেন্ট প্রসেসরের (কার্যকারিতার ওপর নির্ভর করে যেগুলোকে পার্সার বা স্প্লিটারও বলা হয়) একটি ক্রমবর্ধমান তালিকা প্রদান করে।
ডকুমেন্ট এআই প্রসেসর পরিচালনা করার দুটি উপায় রয়েছে:
- ওয়েব কনসোল থেকে ম্যানুয়ালি;
- প্রোগ্রাম্যাটিকভাবে, ডকুমেন্ট এআই এপিআই (Document AI API) ব্যবহার করে।
এখানে ওয়েব কনসোল এবং পাইথন কোড উভয় থেকেই আপনার প্রসেসর তালিকা দেখানো একটি উদাহরণ স্ক্রিনশট দেওয়া হলো:
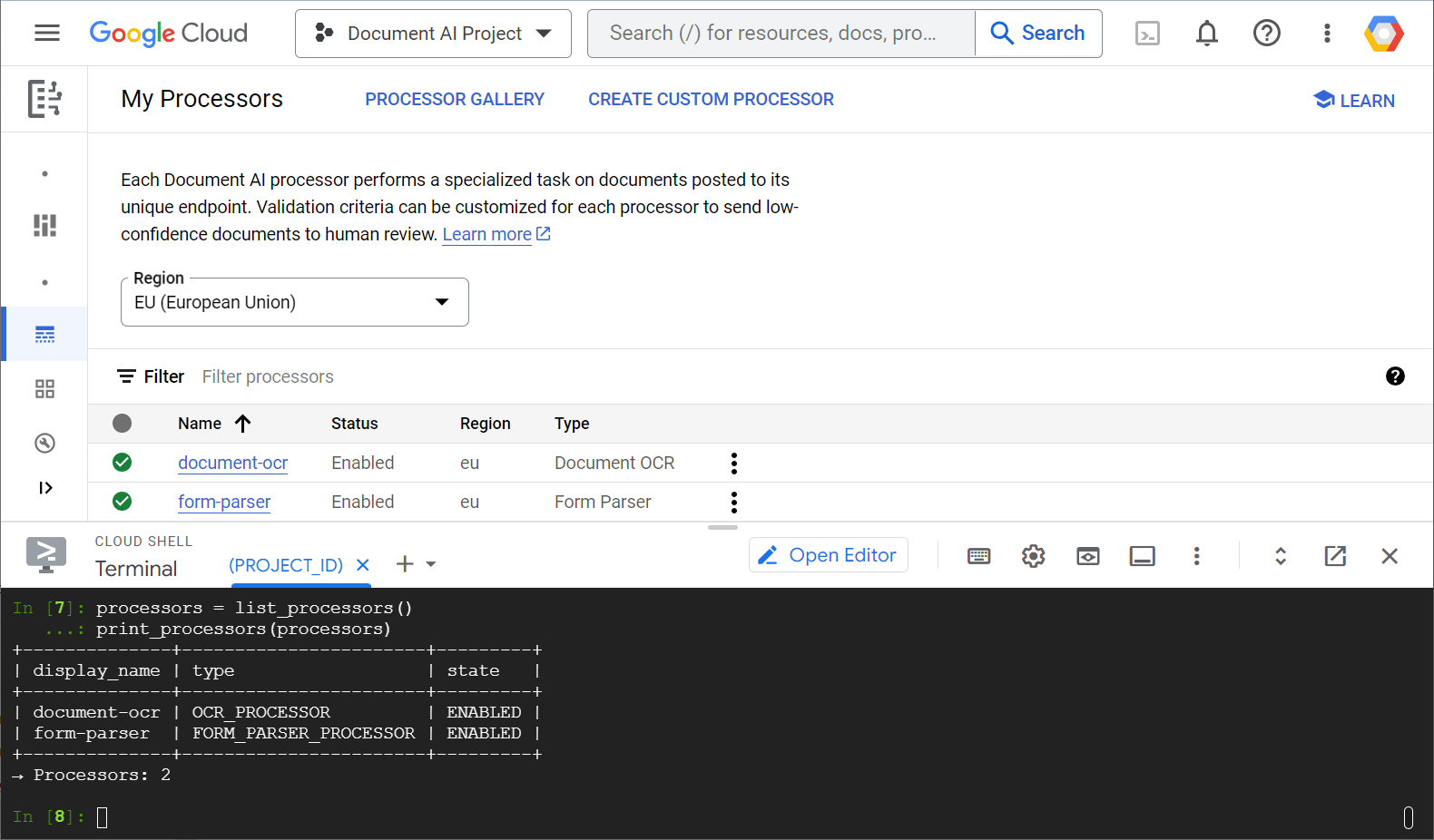
এই ল্যাবে, আপনি পাইথন ক্লায়েন্ট লাইব্রেরি ব্যবহার করে প্রোগ্রাম্যাটিকভাবে ডকুমেন্ট এআই প্রসেসর পরিচালনা করার উপর মনোযোগ দেবেন।
আপনি যা দেখবেন
- আপনার পরিবেশ কীভাবে সেট আপ করবেন
- প্রসেসরের প্রকারগুলি কীভাবে খুঁজে বের করবেন
- প্রসেসর তৈরি করার পদ্ধতি
- প্রজেক্ট প্রসেসরদের কীভাবে তালিকাভুক্ত করবেন
- প্রসেসর কীভাবে ব্যবহার করবেন
- প্রসেসরগুলি কীভাবে সক্রিয়/নিষ্ক্রিয় করবেন
- প্রসেসর সংস্করণগুলি কীভাবে পরিচালনা করবেন
- প্রসেসরগুলি কীভাবে মুছবেন
আপনার যা যা লাগবে
- একটি গুগল ক্লাউড প্রকল্প
- ক্রোম বা ফায়ারফক্সের মতো একটি ব্রাউজার
- পাইথন ব্যবহারে পরিচিতি
জরিপ
আপনি এই টিউটোরিয়ালটি কীভাবে ব্যবহার করবেন?
পাইথন নিয়ে আপনার অভিজ্ঞতাকে আপনি কীভাবে মূল্যায়ন করবেন?
গুগল ক্লাউড পরিষেবা ব্যবহারের অভিজ্ঞতাকে আপনি কীভাবে মূল্যায়ন করবেন?
২. সেটআপ এবং প্রয়োজনীয়তা
স্ব-গতিতে পরিবেশ সেটআপ
- Google Cloud Console- এ সাইন-ইন করুন এবং একটি নতুন প্রজেক্ট তৈরি করুন অথবা বিদ্যমান কোনো প্রজেক্ট পুনরায় ব্যবহার করুন। যদি আপনার আগে থেকে Gmail বা Google Workspace অ্যাকাউন্ট না থাকে, তবে আপনাকে অবশ্যই একটি তৈরি করতে হবে।

- প্রজেক্টের নামটি হলো এই প্রজেক্টের অংশগ্রহণকারীদের প্রদর্শিত নাম। এটি একটি ক্যারেক্টার স্ট্রিং যা গুগল এপিআই ব্যবহার করে না। আপনি যেকোনো সময় এটি আপডেট করতে পারেন।
- প্রজেক্ট আইডি সমস্ত গুগল ক্লাউড প্রজেক্ট জুড়ে অনন্য এবং অপরিবর্তনীয় (একবার সেট করার পর এটি পরিবর্তন করা যায় না)। ক্লাউড কনসোল স্বয়ংক্রিয়ভাবে একটি অনন্য স্ট্রিং তৈরি করে; সাধারণত এটি কী তা নিয়ে আপনার মাথা ঘামানোর দরকার নেই। বেশিরভাগ কোডল্যাবে, আপনাকে আপনার প্রজেক্ট আইডি উল্লেখ করতে হবে (যা সাধারণত
PROJECT_IDহিসাবে চিহ্নিত করা হয়)। তৈরি করা আইডিটি আপনার পছন্দ না হলে, আপনি এলোমেলোভাবে আরেকটি তৈরি করতে পারেন। বিকল্পভাবে, আপনি আপনার নিজের আইডি দিয়ে চেষ্টা করে দেখতে পারেন যে সেটি উপলব্ধ আছে কিনা। এই ধাপের পরে এটি পরিবর্তন করা যাবে না এবং প্রজেক্টের পুরো সময়কাল জুড়ে এটি অপরিবর্তিত থাকবে। - আপনার অবগতির জন্য জানাচ্ছি যে, তৃতীয় একটি ভ্যালু রয়েছে, যা হলো প্রজেক্ট নম্বর , এবং কিছু এপিআই এটি ব্যবহার করে থাকে। ডকুমেন্টেশনে এই তিনটি ভ্যালু সম্পর্কে আরও বিস্তারিত জানুন।
- এরপর, ক্লাউড রিসোর্স/এপিআই ব্যবহার করার জন্য আপনাকে ক্লাউড কনসোলে বিলিং চালু করতে হবে। এই কোডল্যাবটি সম্পন্ন করতে খুব বেশি খরচ হবে না, এমনকি আদৌ কোনো খরচ নাও হতে পারে। এই টিউটোরিয়ালের পর বিলিং এড়াতে রিসোর্সগুলো বন্ধ করার জন্য, আপনি আপনার তৈরি করা রিসোর্সগুলো অথবা প্রজেক্টটি ডিলিট করে দিতে পারেন। নতুন গুগল ক্লাউড ব্যবহারকারীরা ৩০০ মার্কিন ডলারের ফ্রি ট্রায়াল প্রোগ্রামের জন্য যোগ্য।
ক্লাউড শেল শুরু করুন
যদিও গুগল ক্লাউড আপনার ল্যাপটপ থেকে দূরবর্তীভাবে পরিচালনা করা যায়, এই ল্যাবে আপনি ক্লাউড শেল ব্যবহার করছেন, যা ক্লাউডে চলমান একটি কমান্ড লাইন পরিবেশ।
ক্লাউড শেল সক্রিয় করুন
- ক্লাউড কনসোল থেকে, Activate Cloud Shell-এ ক্লিক করুন।
 .
.

আপনি যদি প্রথমবারের মতো ক্লাউড শেল চালু করেন, তাহলে এটি কী তা বর্ণনা করে একটি মধ্যবর্তী স্ক্রিন আপনার সামনে আসবে। যদি একটি মধ্যবর্তী স্ক্রিন আসে, তাহলে 'চালিয়ে যান' (Continue) এ ক্লিক করুন।
ক্লাউড শেল প্রস্তুত করতে এবং এর সাথে সংযোগ স্থাপন করতে মাত্র কয়েক মুহূর্ত সময় লাগা উচিত।

এই ভার্চুয়াল মেশিনটিতে প্রয়োজনীয় সমস্ত ডেভেলপমেন্ট টুলস লোড করা আছে। এটি একটি স্থায়ী ৫ জিবি হোম ডিরেক্টরি প্রদান করে এবং গুগল ক্লাউডে চলে, যা নেটওয়ার্ক পারফরম্যান্স ও অথেনটিকেশনকে ব্যাপকভাবে উন্নত করে। এই কোডল্যাবে আপনার প্রায় সমস্ত কাজই একটি ব্রাউজার দিয়ে করা সম্ভব।
ক্লাউড শেলে সংযুক্ত হওয়ার পর, আপনি দেখতে পাবেন যে আপনাকে প্রমাণীকৃত করা হয়েছে এবং প্রজেক্টটি আপনার প্রজেক্ট আইডিতে সেট করা আছে।
- আপনি প্রমাণীকৃত কিনা তা নিশ্চিত করতে ক্লাউড শেলে নিম্নলিখিত কমান্ডটি চালান:
gcloud auth list
কমান্ড আউটপুট
Credentialed Accounts
ACTIVE ACCOUNT
* <my_account>@<my_domain.com>
To set the active account, run:
$ gcloud config set account `ACCOUNT`
- gcloud কমান্ডটি আপনার প্রজেক্ট সম্পর্কে জানে কিনা তা নিশ্চিত করতে ক্লাউড শেলে নিম্নলিখিত কমান্ডটি চালান:
gcloud config list project
কমান্ড আউটপুট
[core] project = <PROJECT_ID>
যদি তা না থাকে, তবে আপনি এই কমান্ডটি দিয়ে এটি সেট করতে পারেন:
gcloud config set project <PROJECT_ID>
কমান্ড আউটপুট
Updated property [core/project].
৩. পরিবেশ সেটআপ
Document AI ব্যবহার শুরু করার আগে, Document AI API সক্রিয় করতে Cloud Shell-এ নিম্নলিখিত কমান্ডটি চালান:
gcloud services enable documentai.googleapis.com
আপনার এইরকম কিছু দেখা উচিত:
Operation "operations/..." finished successfully.
এখন আপনি ডকুমেন্ট এআই ব্যবহার করতে পারেন!
আপনার হোম ডিরেক্টরিতে যান:
cd ~
নির্ভরতাগুলিকে বিচ্ছিন্ন করতে একটি পাইথন ভার্চুয়াল এনভায়রনমেন্ট তৈরি করুন:
virtualenv venv-docai
ভার্চুয়াল পরিবেশ সক্রিয় করুন:
source venv-docai/bin/activate
IPython, Document AI ক্লায়েন্ট লাইব্রেরি, এবং python-tabulate (যা আপনি অনুরোধের ফলাফল সুন্দরভাবে প্রিন্ট করতে ব্যবহার করবেন) ইনস্টল করুন:
pip install ipython google-cloud-documentai tabulate
আপনার এইরকম কিছু দেখা উচিত:
... Installing collected packages: ..., tabulate, ipython, google-cloud-documentai Successfully installed ... google-cloud-documentai-2.15.0 ...
এখন, আপনি ডকুমেন্ট এআই ক্লায়েন্ট লাইব্রেরি ব্যবহার করার জন্য প্রস্তুত!
নিম্নলিখিত পরিবেশ ভেরিয়েবলগুলো সেট করুন:
export PROJECT_ID=$(gcloud config get-value core/project)
# Choose "us" or "eu"
export API_LOCATION="us"
এখন থেকে সব ধাপ একই সেশনে সম্পন্ন করতে হবে।
আপনার এনভায়রনমেন্ট ভেরিয়েবলগুলো সঠিকভাবে সংজ্ঞায়িত করা হয়েছে কিনা তা নিশ্চিত করুন:
echo $PROJECT_ID
echo $API_LOCATION
পরবর্তী ধাপগুলোতে, আপনি IPython নামক একটি ইন্টারেক্টিভ পাইথন ইন্টারপ্রেটার ব্যবহার করবেন, যা আপনি এইমাত্র ইনস্টল করেছেন। ক্লাউড শেলে ipython রান করে একটি সেশন শুরু করুন:
ipython
আপনার এইরকম কিছু দেখা উচিত:
Python 3.12.3 (main, Feb 4 2025, 14:48:35) [GCC 13.3.0] Type 'copyright', 'credits' or 'license' for more information IPython 9.1.0 -- An enhanced Interactive Python. Type '?' for help. In [1]:
নিম্নলিখিত কোডটি আপনার IPython সেশনে কপি করুন:
import os
from typing import Iterator, MutableSequence, Optional, Sequence, Tuple
import google.cloud.documentai_v1 as docai
from tabulate import tabulate
PROJECT_ID = os.getenv("PROJECT_ID", "")
API_LOCATION = os.getenv("API_LOCATION", "")
assert PROJECT_ID, "PROJECT_ID is undefined"
assert API_LOCATION in ("us", "eu"), "API_LOCATION is incorrect"
# Test processors
document_ocr_display_name = "document-ocr"
form_parser_display_name = "form-parser"
test_processor_display_names_and_types = (
(document_ocr_display_name, "OCR_PROCESSOR"),
(form_parser_display_name, "FORM_PARSER_PROCESSOR"),
)
def get_client() -> docai.DocumentProcessorServiceClient:
client_options = {"api_endpoint": f"{API_LOCATION}-documentai.googleapis.com"}
return docai.DocumentProcessorServiceClient(client_options=client_options)
def get_parent(client: docai.DocumentProcessorServiceClient) -> str:
return client.common_location_path(PROJECT_ID, API_LOCATION)
def get_client_and_parent() -> Tuple[docai.DocumentProcessorServiceClient, str]:
client = get_client()
parent = get_parent(client)
return client, parent
আপনি আপনার প্রথম অনুরোধটি করতে এবং প্রসেসরের ধরনগুলো সংগ্রহ করতে প্রস্তুত।
৪. প্রসেসরের প্রকারভেদ সংগ্রহ করা
পরবর্তী ধাপে প্রসেসর তৈরি করার আগে, উপলব্ধ প্রসেসরের প্রকারগুলি সংগ্রহ করুন। আপনি fetch_processor_types ব্যবহার করে এই তালিকাটি পেতে পারেন।
আপনার IPython সেশনে নিম্নলিখিত ফাংশনগুলি যোগ করুন:
def fetch_processor_types() -> MutableSequence[docai.ProcessorType]:
client, parent = get_client_and_parent()
response = client.fetch_processor_types(parent=parent)
return response.processor_types
def print_processor_types(processor_types: Sequence[docai.ProcessorType]):
def sort_key(pt):
return (not pt.allow_creation, pt.category, pt.type_)
sorted_processor_types = sorted(processor_types, key=sort_key)
data = processor_type_tabular_data(sorted_processor_types)
headers = next(data)
colalign = next(data)
print(tabulate(data, headers, tablefmt="pretty", colalign=colalign))
print(f"→ Processor types: {len(sorted_processor_types)}")
def processor_type_tabular_data(
processor_types: Sequence[docai.ProcessorType],
) -> Iterator[Tuple[str, str, str, str]]:
def locations(pt):
return ", ".join(sorted(loc.location_id for loc in pt.available_locations))
yield ("type", "category", "allow_creation", "locations")
yield ("left", "left", "left", "left")
if not processor_types:
yield ("-", "-", "-", "-")
return
for pt in processor_types:
yield (pt.type_, pt.category, f"{pt.allow_creation}", locations(pt))
প্রসেসরের প্রকারভেদগুলো তালিকাভুক্ত করুন:
processor_types = fetch_processor_types()
print_processor_types(processor_types)
আপনার নিচের মতো কিছু পাওয়া উচিত:
+--------------------------------------+-------------+----------------+-----------+ | type | category | allow_creation | locations | +--------------------------------------+-------------+----------------+-----------+ | CUSTOM_CLASSIFICATION_PROCESSOR | CUSTOM | True | eu, us | ... | FORM_PARSER_PROCESSOR | GENERAL | True | eu, us | | LAYOUT_PARSER_PROCESSOR | GENERAL | True | eu, us | | OCR_PROCESSOR | GENERAL | True | eu, us | | BANK_STATEMENT_PROCESSOR | SPECIALIZED | True | eu, us | | EXPENSE_PROCESSOR | SPECIALIZED | True | eu, us | ... +--------------------------------------+-------------+----------------+-----------+ → Processor types: 19
এখন, পরবর্তী ধাপে প্রসেসর তৈরি করার জন্য আপনার কাছে প্রয়োজনীয় সমস্ত তথ্য রয়েছে।
৫. প্রসেসর তৈরি করা
একটি প্রসেসর তৈরি করতে, একটি ডিসপ্লে নাম এবং একটি প্রসেসর টাইপ সহ create_processor কল করুন।
নিম্নলিখিত ফাংশনটি যোগ করুন:
def create_processor(display_name: str, type: str) -> docai.Processor:
client, parent = get_client_and_parent()
processor = docai.Processor(display_name=display_name, type_=type)
return client.create_processor(parent=parent, processor=processor)
টেস্ট প্রসেসরগুলো তৈরি করুন:
separator = "=" * 80
for display_name, type in test_processor_display_names_and_types:
print(separator)
print(f"Creating {display_name} ({type})...")
try:
create_processor(display_name, type)
except Exception as err:
print(err)
print(separator)
print("Done")
আপনার নিম্নলিখিত জিনিসগুলো পাওয়া উচিত:
================================================================================ Creating document-ocr (OCR_PROCESSOR)... ================================================================================ Creating form-parser (FORM_PARSER_PROCESSOR)... ================================================================================ Done
আপনি নতুন প্রসেসর তৈরি করেছেন!
এরপর, প্রসেসরগুলো কীভাবে তালিকাভুক্ত করতে হয় তা দেখুন।
৬. প্রকল্প প্রক্রিয়াকারীদের তালিকাভুক্ত করা
list_processors আপনার প্রোজেক্টের অন্তর্গত সমস্ত প্রসেসরের তালিকা ফেরত দেয়।
নিম্নলিখিত ফাংশনগুলো যোগ করুন:
def list_processors() -> MutableSequence[docai.Processor]:
client, parent = get_client_and_parent()
response = client.list_processors(parent=parent)
return list(response.processors)
def print_processors(processors: Optional[Sequence[docai.Processor]] = None):
def sort_key(processor):
return processor.display_name
if processors is None:
processors = list_processors()
sorted_processors = sorted(processors, key=sort_key)
data = processor_tabular_data(sorted_processors)
headers = next(data)
colalign = next(data)
print(tabulate(data, headers, tablefmt="pretty", colalign=colalign))
print(f"→ Processors: {len(sorted_processors)}")
def processor_tabular_data(
processors: Sequence[docai.Processor],
) -> Iterator[Tuple[str, str, str]]:
yield ("display_name", "type", "state")
yield ("left", "left", "left")
if not processors:
yield ("-", "-", "-")
return
for processor in processors:
yield (processor.display_name, processor.type_, processor.state.name)
ফাংশনগুলো কল করুন:
processors = list_processors()
print_processors(processors)
আপনার নিম্নলিখিত জিনিসগুলো পাওয়া উচিত:
+--------------+-----------------------+---------+ | display_name | type | state | +--------------+-----------------------+---------+ | document-ocr | OCR_PROCESSOR | ENABLED | | form-parser | FORM_PARSER_PROCESSOR | ENABLED | +--------------+-----------------------+---------+ → Processors: 2
ডিসপ্লে নাম দ্বারা প্রসেসর খুঁজে বের করতে, নিম্নলিখিত ফাংশনটি যোগ করুন:
def get_processor(
display_name: str,
processors: Optional[Sequence[docai.Processor]] = None,
) -> Optional[docai.Processor]:
if processors is None:
processors = list_processors()
for processor in processors:
if processor.display_name == display_name:
return processor
return None
ফাংশনটি পরীক্ষা করুন:
processor = get_processor(document_ocr_display_name, processors)
assert processor is not None
print(processor)
আপনার এইরকম কিছু দেখা উচিত:
name: "projects/PROJECT_NUM/locations/LOCATION/processors/PROCESSOR_ID" type_: "OCR_PROCESSOR" display_name: "document-ocr" state: ENABLED ...
এখন আপনি জানেন কীভাবে আপনার প্রোজেক্ট প্রসেসরগুলোর তালিকা তৈরি করতে হয় এবং তাদের ডিসপ্লে নেম দিয়ে খুঁজে বের করতে হয়। এরপর দেখুন, কীভাবে একটি প্রসেসর ব্যবহার করতে হয়।
৭. প্রসেসর ব্যবহার করা
নথি দুইভাবে প্রক্রিয়াজাত করা যেতে পারে:
- একই সাথে : একটিমাত্র ডকুমেন্ট বিশ্লেষণ করতে এবং ফলাফল সরাসরি ব্যবহার করতে
process_documentকল করুন। - অ্যাসিঙ্ক্রোনাসভাবে : একাধিক বা বৃহৎ ডকুমেন্টের উপর ব্যাচ প্রসেসিং চালু করতে
batch_process_documentsকল করুন।
আপনার পরীক্ষার নথিটি ( পিডিএফ ) হলো হাতে লেখা উত্তর দিয়ে পূরণ করা একটি স্ক্যান করা প্রশ্নপত্র। আপনার আইপাইথন সেশন থেকে সরাসরি এটি আপনার ওয়ার্কিং ডিরেক্টরিতে ডাউনলোড করুন:
!gsutil cp gs://cloud-samples-data/documentai/form.pdf .
আপনার ওয়ার্কিং ডিরেক্টরির বিষয়বস্তু পরীক্ষা করুন:
!ls
আপনার নিম্নলিখিত জিনিসগুলো থাকা উচিত:
... form.pdf ... venv-docai ...
আপনি একটি স্থানীয় ফাইল বিশ্লেষণ করতে সিনক্রোনাস process_document মেথডটি ব্যবহার করতে পারেন। নিম্নলিখিত ফাংশনটি যোগ করুন:
def process_file(
processor: docai.Processor,
file_path: str,
mime_type: str,
) -> docai.Document:
client = get_client()
with open(file_path, "rb") as document_file:
document_content = document_file.read()
document = docai.RawDocument(content=document_content, mime_type=mime_type)
request = docai.ProcessRequest(raw_document=document, name=processor.name)
response = client.process_document(request)
return response.document
যেহেতু আপনার ডকুমেন্টটি একটি প্রশ্নমালা, তাই ফর্ম পার্সারটি বেছে নিন। সমস্ত প্রসেসরের মতোই টেক্সট (মুদ্রিত এবং হাতে লেখা) বের করার পাশাপাশি, এই সাধারণ প্রসেসরটি ফর্ম ফিল্ডগুলোও শনাক্ত করে।
নথিটি বিশ্লেষণ করুন:
processor = get_processor(form_parser_display_name)
assert processor is not None
file_path = "./form.pdf"
mime_type = "application/pdf"
document = process_file(processor, file_path, mime_type)
সমস্ত প্রসেসর ডকুমেন্টটির উপর অপটিক্যাল ক্যারেক্টার রিকগনিশন (OCR) এর প্রথম ধাপ চালায়। OCR ধাপে শনাক্ত করা টেক্সটটি পর্যালোচনা করুন:
document.text.split("\n")
আপনি নিচের মতো কিছু দেখতে পাবেন:
['FakeDoc M.D.', 'HEALTH INTAKE FORM', 'Please fill out the questionnaire carefully. The information you provide will be used to complete', 'your health profile and will be kept confidential.', 'Date:', '9/14/19', 'Name:', 'Sally Walker', 'DOB: 09/04/1986', 'Address: 24 Barney Lane', 'City: Towaco', 'State: NJ Zip: 07082', 'Email: Sally, walker@cmail.com', '_Phone #: (906) 917-3486', 'Gender: F', 'Marital Status:', ... ]
শনাক্তকৃত ফর্ম ফিল্ডগুলো প্রিন্ট করার জন্য নিম্নলিখিত ফাংশনগুলো যোগ করুন:
def print_form_fields(document: docai.Document):
sorted_form_fields = form_fields_sorted_by_ocr_order(document)
data = form_field_tabular_data(sorted_form_fields, document)
headers = next(data)
colalign = next(data)
print(tabulate(data, headers, tablefmt="pretty", colalign=colalign))
print(f"→ Form fields: {len(sorted_form_fields)}")
def form_field_tabular_data(
form_fields: Sequence[docai.Document.Page.FormField],
document: docai.Document,
) -> Iterator[Tuple[str, str, str]]:
yield ("name", "value", "confidence")
yield ("right", "left", "right")
if not form_fields:
yield ("-", "-", "-")
return
for form_field in form_fields:
name_layout = form_field.field_name
value_layout = form_field.field_value
name = text_from_layout(name_layout, document)
value = text_from_layout(value_layout, document)
confidence = value_layout.confidence
yield (name, value, f"{confidence:.1%}")
এছাড়াও এই ইউটিলিটি ফাংশনগুলো যোগ করুন:
def form_fields_sorted_by_ocr_order(
document: docai.Document,
) -> MutableSequence[docai.Document.Page.FormField]:
def sort_key(form_field):
# Sort according to the field name detected position
text_anchor = form_field.field_name.text_anchor
return text_anchor.text_segments[0].start_index if text_anchor else 0
fields = (field for page in document.pages for field in page.form_fields)
return sorted(fields, key=sort_key)
def text_from_layout(
layout: docai.Document.Page.Layout,
document: docai.Document,
) -> str:
full_text = document.text
segs = layout.text_anchor.text_segments
text = "".join(full_text[seg.start_index : seg.end_index] for seg in segs)
if text.endswith("\n"):
text = text[:-1]
return text
শনাক্তকৃত ফর্ম ক্ষেত্রগুলি প্রিন্ট করুন:
print_form_fields(document)
আপনি নিচের মতো একটি প্রিন্টআউট পাবেন:
+-----------------+-------------------------+------------+ | name | value | confidence | +-----------------+-------------------------+------------+ | Date: | 9/14/19 | 83.0% | | Name: | Sally Walker | 87.3% | | DOB: | 09/04/1986 | 88.5% | | Address: | 24 Barney Lane | 82.4% | | City: | Towaco | 90.0% | | State: | NJ | 89.4% | | Zip: | 07082 | 91.4% | | Email: | Sally, walker@cmail.com | 79.7% | | _Phone #: | walker@cmail.com | 93.2% | | | (906 | | | Gender: | F | 88.2% | | Marital Status: | Single | 85.2% | | Occupation: | Software Engineer | 81.5% | | Referred By: | None | 76.9% | ... +-----------------+-------------------------+------------+ → Form fields: 17
শনাক্তকৃত ফিল্ডের নাম এবং মানগুলো পর্যালোচনা করুন ( পিডিএফ )। এখানে প্রশ্নমালার উপরের অর্ধেক দেওয়া হলো:

আপনি এমন একটি ফর্ম বিশ্লেষণ করেছেন যাতে মুদ্রিত এবং হাতে লেখা উভয় প্রকারের লেখা রয়েছে। আপনি উচ্চ আত্মবিশ্বাসের সাথে এর ফিল্ডগুলোও শনাক্ত করেছেন। এর ফলস্বরূপ, আপনার পিক্সেলগুলো কাঠামোগত ডেটাতে রূপান্তরিত হয়েছে!
৮. প্রসেসর সক্রিয় এবং নিষ্ক্রিয় করা
disable_processor এবং enable_processor মাধ্যমে আপনি নিয়ন্ত্রণ করতে পারেন যে কোনো প্রসেসর ব্যবহার করা যাবে কি না।
নিম্নলিখিত ফাংশনগুলো যোগ করুন:
def update_processor_state(processor: docai.Processor, enable_processor: bool):
client = get_client()
if enable_processor:
request = docai.EnableProcessorRequest(name=processor.name)
operation = client.enable_processor(request)
else:
request = docai.DisableProcessorRequest(name=processor.name)
operation = client.disable_processor(request)
operation.result() # Wait for operation to complete
def enable_processor(processor: docai.Processor):
update_processor_state(processor, True)
def disable_processor(processor: docai.Processor):
update_processor_state(processor, False)
ফর্ম পার্সার প্রসেসরটি নিষ্ক্রিয় করুন এবং আপনার প্রসেসরগুলোর অবস্থা পরীক্ষা করুন:
processor = get_processor(form_parser_display_name)
assert processor is not None
disable_processor(processor)
print_processors()
আপনার নিম্নলিখিত জিনিসগুলো পাওয়া উচিত:
+--------------+-----------------------+----------+ | display_name | type | state | +--------------+-----------------------+----------+ | document-ocr | OCR_PROCESSOR | ENABLED | | form-parser | FORM_PARSER_PROCESSOR | DISABLED | +--------------+-----------------------+----------+ → Processors: 2
ফর্ম পার্সার প্রসেসরটি পুনরায় সক্রিয় করুন:
enable_processor(processor)
print_processors()
আপনার নিম্নলিখিত জিনিসগুলো পাওয়া উচিত:
+--------------+-----------------------+---------+ | display_name | type | state | +--------------+-----------------------+---------+ | document-ocr | OCR_PROCESSOR | ENABLED | | form-parser | FORM_PARSER_PROCESSOR | ENABLED | +--------------+-----------------------+---------+ → Processors: 2
এরপর, প্রসেসর সংস্করণগুলো কীভাবে পরিচালনা করতে হয় তা দেখুন।
৯. প্রসেসর সংস্করণ পরিচালনা করা
প্রসেসর একাধিক সংস্করণে উপলব্ধ থাকতে পারে। list_processor_versions এবং set_default_processor_version মেথডগুলো কীভাবে ব্যবহার করতে হয় তা দেখে নিন।
নিম্নলিখিত ফাংশনগুলো যোগ করুন:
def list_processor_versions(
processor: docai.Processor,
) -> MutableSequence[docai.ProcessorVersion]:
client = get_client()
response = client.list_processor_versions(parent=processor.name)
return list(response)
def get_sorted_processor_versions(
processor: docai.Processor,
) -> MutableSequence[docai.ProcessorVersion]:
def sort_key(processor_version: docai.ProcessorVersion):
return processor_version.name
versions = list_processor_versions(processor)
return sorted(versions, key=sort_key)
def print_processor_versions(processor: docai.Processor):
versions = get_sorted_processor_versions(processor)
default_version_name = processor.default_processor_version
data = processor_versions_tabular_data(versions, default_version_name)
headers = next(data)
colalign = next(data)
print(tabulate(data, headers, tablefmt="pretty", colalign=colalign))
print(f"→ Processor versions: {len(versions)}")
def processor_versions_tabular_data(
versions: Sequence[docai.ProcessorVersion],
default_version_name: str,
) -> Iterator[Tuple[str, str, str]]:
yield ("version", "display name", "default")
yield ("left", "left", "left")
if not versions:
yield ("-", "-", "-")
return
for version in versions:
mapping = docai.DocumentProcessorServiceClient.parse_processor_version_path(
version.name
)
processor_version = mapping["processor_version"]
is_default = "Y" if version.name == default_version_name else ""
yield (processor_version, version.display_name, is_default)
OCR প্রসেসরের জন্য উপলব্ধ সংস্করণগুলি তালিকাভুক্ত করুন:
processor = get_processor(document_ocr_display_name)
assert processor is not None
print_processor_versions(processor)
আপনি প্রসেসর সংস্করণগুলো পাবেন:
+--------------------------------+--------------------------+---------+ | version | display name | default | +--------------------------------+--------------------------+---------+ | pretrained-ocr-v1.0-2020-09-23 | Google Stable | | | pretrained-ocr-v1.1-2022-09-12 | Google Release Candidate | | | pretrained-ocr-v1.2-2022-11-10 | Google Release Candidate | | | pretrained-ocr-v2.0-2023-06-02 | Google Stable | Y | | pretrained-ocr-v2.1-2024-08-07 | Google Release Candidate | | +--------------------------------+--------------------------+---------+ → Processor versions: 5
এখন, ডিফল্ট প্রসেসর সংস্করণ পরিবর্তন করার জন্য একটি ফাংশন যোগ করুন:
def set_default_processor_version(processor: docai.Processor, version_name: str):
client = get_client()
request = docai.SetDefaultProcessorVersionRequest(
processor=processor.name,
default_processor_version=version_name,
)
operation = client.set_default_processor_version(request)
operation.result() # Wait for operation to complete
সর্বশেষ প্রসেসর সংস্করণে পরিবর্তন করুন:
processor = get_processor(document_ocr_display_name)
assert processor is not None
versions = get_sorted_processor_versions(processor)
new_version = versions[-1] # Latest version
set_default_processor_version(processor, new_version.name)
# Update the processor info
processor = get_processor(document_ocr_display_name)
assert processor is not None
print_processor_versions(processor)
আপনি নতুন সংস্করণের কনফিগারেশনটি পাবেন:
+--------------------------------+--------------------------+---------+ | version | display name | default | +--------------------------------+--------------------------+---------+ | pretrained-ocr-v1.0-2020-09-23 | Google Stable | | | pretrained-ocr-v1.1-2022-09-12 | Google Release Candidate | | | pretrained-ocr-v1.2-2022-11-10 | Google Release Candidate | | | pretrained-ocr-v2.0-2023-06-02 | Google Stable | | | pretrained-ocr-v2.1-2024-08-07 | Google Release Candidate | Y | +--------------------------------+--------------------------+---------+ → Processor versions: 5
এবং এরপরে, প্রসেসর ব্যবস্থাপনার চূড়ান্ত পদ্ধতি (মুছে ফেলা)।
১০. প্রসেসর মুছে ফেলা
সবশেষে, delete_processor মেথডটি কীভাবে ব্যবহার করতে হয় তা দেখে নিন।
নিম্নলিখিত ফাংশনটি যোগ করুন:
def delete_processor(processor: docai.Processor):
client = get_client()
operation = client.delete_processor(name=processor.name)
operation.result() # Wait for operation to complete
আপনার টেস্ট প্রসেসরগুলো মুছে ফেলুন:
processors_to_delete = [dn for dn, _ in test_processor_display_names_and_types]
print("Deleting processors...")
for processor in list_processors():
if processor.display_name not in processors_to_delete:
continue
print(f" Deleting {processor.display_name}...")
delete_processor(processor)
print("Done\n")
print_processors()
আপনার নিম্নলিখিত জিনিসগুলো পাওয়া উচিত:
Deleting processors... Deleting form-parser... Deleting document-ocr... Done +--------------+------+-------+ | display_name | type | state | +--------------+------+-------+ | - | - | - | +--------------+------+-------+ → Processors: 0
আপনি প্রসেসর ব্যবস্থাপনার সমস্ত পদ্ধতি শিখে ফেলেছেন! আপনার কাজ প্রায় শেষ...
১১. অভিনন্দন!
আপনি পাইথন ব্যবহার করে ডকুমেন্ট এআই প্রসেসর পরিচালনা করতে শিখেছেন!
পরিষ্কার করা
আপনার ডেভেলপমেন্ট এনভায়রনমেন্ট পরিষ্কার করতে, ক্লাউড শেল থেকে:
- আপনি যদি এখনও আপনার IPython সেশনে থাকেন, তাহলে শেল-এ ফিরে যান:
exit - পাইথন ভার্চুয়াল এনভায়রনমেন্ট ব্যবহার বন্ধ করুন:
deactivate - আপনার ভার্চুয়াল এনভায়রনমেন্ট ফোল্ডারটি মুছে ফেলুন:
cd ~ ; rm -rf ./venv-docai
ক্লাউড শেল থেকে আপনার গুগল ক্লাউড প্রজেক্ট ডিলিট করতে:
- আপনার বর্তমান প্রজেক্ট আইডি পুনরুদ্ধার করুন:
PROJECT_ID=$(gcloud config get-value core/project) - নিশ্চিত করুন যে এটিই সেই প্রজেক্ট যা আপনি মুছতে চান:
echo $PROJECT_ID - প্রজেক্টটি মুছে ফেলুন:
gcloud projects delete $PROJECT_ID
আরও জানুন
- আপনার ব্রাউজারে Document AI ব্যবহার করে দেখুন: https://cloud.google.com/document-ai/docs/drag-and-drop
- এআই প্রসেসরের বিবরণ এখানে দেখুন: https://cloud.google.com/document-ai/docs/processors-list
- গুগল ক্লাউডে পাইথন: https://cloud.google.com/python
- পাইথনের জন্য ক্লাউড ক্লায়েন্ট লাইব্রেরি: https://github.com/googleapis/google-cloud-python
লাইসেন্স
এই কাজটি ক্রিয়েটিভ কমন্স অ্যাট্রিবিউশন ২.০ জেনেরিক লাইসেন্সের অধীনে রয়েছে।