
1. Présentation

Qu'est-ce que Document AI ?
Document AI est une plate-forme qui vous permet d'extraire des insights de vos documents. Il propose une liste croissante de processeurs de documents (également appelés analyseurs ou séparateurs, selon leur fonctionnalité).
Vous pouvez gérer les processeurs Document AI de deux manières :
- manuellement, depuis la console Web ;
- par programmation, à l'aide de l'API Document AI.
Voici un exemple de capture d'écran montrant votre liste de processeurs, à la fois depuis la console Web et depuis le code Python :
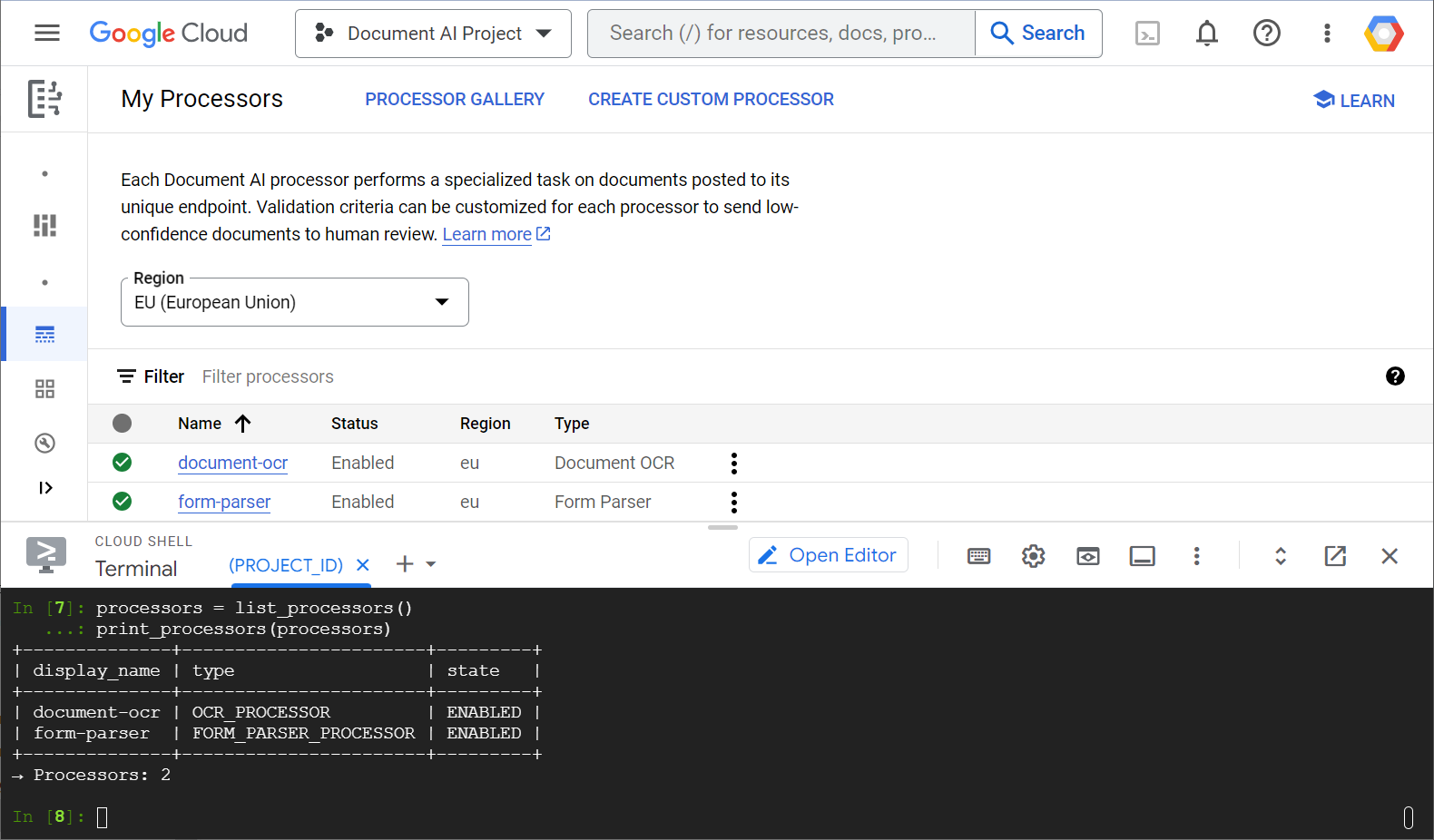
Dans cet atelier, vous allez vous concentrer sur la gestion programmatique des processeurs Document AI avec la bibliothèque cliente Python.
Ce que vous verrez
- Configurer votre environnement
- Récupérer les types de processeurs
- Créer des processeurs
- Lister les processeurs de projet
- Utiliser les processeurs
- Activer/Désactiver les processeurs
- Gérer les versions du processeur
- Supprimer des processeurs
Prérequis
Enquête
Comment allez-vous utiliser ce tutoriel ?
Quel est votre niveau d'expérience avec Python ?
Quel est votre niveau d'expérience avec les services Google Cloud ?
2. Préparation
Configuration de l'environnement au rythme de chacun
- Connectez-vous à la console Google Cloud, puis créez un projet ou réutilisez un projet existant. Si vous n'avez pas encore de compte Gmail ou Google Workspace, vous devez en créer un.

- Le nom du projet est le nom à afficher pour les participants au projet. Il s'agit d'une chaîne de caractères non utilisée par les API Google. Vous pourrez toujours le modifier.
- L'ID du projet est unique parmi tous les projets Google Cloud et non modifiable une fois défini. La console Cloud génère automatiquement une chaîne unique (en général, vous n'y accordez d'importance particulière). Dans la plupart des ateliers de programmation, vous devrez indiquer l'ID de votre projet (généralement identifié par
PROJECT_ID). Si l'ID généré ne vous convient pas, vous pouvez en générer un autre de manière aléatoire. Vous pouvez également en spécifier un et voir s'il est disponible. Après cette étape, l'ID n'est plus modifiable et restera donc le même pour toute la durée du projet. - Pour information, il existe une troisième valeur (le numéro de projet) que certaines API utilisent. Pour en savoir plus sur ces trois valeurs, consultez la documentation.
- Vous devez ensuite activer la facturation dans la console Cloud pour utiliser les ressources/API Cloud. L'exécution de cet atelier de programmation est très peu coûteuse, voire sans frais. Pour désactiver les ressources et éviter ainsi que des frais ne vous soient facturés après ce tutoriel, vous pouvez supprimer le projet ou les ressources que vous avez créées. Les nouveaux utilisateurs de Google Cloud peuvent participer au programme d'essai sans frais pour bénéficier d'un crédit de 300 $.
Démarrer Cloud Shell
Bien que Google Cloud puisse être utilisé à distance depuis votre ordinateur portable, vous allez utiliser Cloud Shell, un environnement de ligne de commande exécuté dans le cloud, lors de cet atelier.
Activer Cloud Shell
- Dans Cloud Console, cliquez sur Activer Cloud Shell
 .
.

Si vous démarrez Cloud Shell pour la première fois, un écran intermédiaire s'affiche pour vous expliquer de quoi il s'agit. Si cet écran s'est affiché, cliquez sur Continuer.
Le provisionnement et la connexion à Cloud Shell ne devraient pas prendre plus de quelques minutes.

Cette machine virtuelle contient tous les outils de développement nécessaires. Elle comprend un répertoire d'accueil persistant de 5 Go et s'exécute sur Google Cloud, ce qui améliore nettement les performances du réseau et l'authentification. Vous pouvez réaliser une grande partie, voire la totalité, des activités de cet atelier de programmation dans un navigateur.
Une fois connecté à Cloud Shell, vous êtes en principe authentifié, et le projet est défini avec votre ID de projet.
- Exécutez la commande suivante dans Cloud Shell pour vérifier que vous êtes authentifié :
gcloud auth list
Résultat de la commande
Credentialed Accounts
ACTIVE ACCOUNT
* <my_account>@<my_domain.com>
To set the active account, run:
$ gcloud config set account `ACCOUNT`
- Exécutez la commande suivante dans Cloud Shell pour vérifier que la commande gcloud connaît votre projet :
gcloud config list project
Résultat de la commande
[core] project = <PROJECT_ID>
Si vous obtenez un résultat différent, exécutez cette commande :
gcloud config set project <PROJECT_ID>
Résultat de la commande
Updated property [core/project].
3. Configuration de l'environnement
Avant de pouvoir utiliser Document AI, exécutez la commande suivante dans Cloud Shell pour activer l'API Document AI :
gcloud services enable documentai.googleapis.com
L'écran qui s'affiche devrait ressembler à ce qui suit :
Operation "operations/..." finished successfully.
Vous pouvez maintenant utiliser Document AI.
Accédez à votre répertoire d'accueil :
cd ~
Créez un environnement virtuel Python pour isoler les dépendances :
virtualenv venv-docai
Activez l'environnement virtuel :
source venv-docai/bin/activate
Installez IPython, la bibliothèque cliente Document AI et python-tabulate (que vous utiliserez pour mettre en forme les résultats de la requête) :
pip install ipython google-cloud-documentai tabulate
L'écran qui s'affiche devrait ressembler à ce qui suit :
... Installing collected packages: ..., tabulate, ipython, google-cloud-documentai Successfully installed ... google-cloud-documentai-2.15.0 ...
Vous êtes maintenant prêt à utiliser la bibliothèque cliente Document AI.
Définissez les variables d'environnement suivantes :
export PROJECT_ID=$(gcloud config get-value core/project)
# Choose "us" or "eu"
export API_LOCATION="us"
Désormais, toutes les étapes doivent être effectuées au cours de la même session.
Assurez-vous que vos variables d'environnement sont correctement définies :
echo $PROJECT_ID
echo $API_LOCATION
Dans les étapes suivantes, vous allez utiliser un interpréteur Python interactif appelé IPython, que vous venez d'installer. Démarrez une session en exécutant ipython dans Cloud Shell :
ipython
L'écran qui s'affiche devrait ressembler à ce qui suit :
Python 3.12.3 (main, Feb 4 2025, 14:48:35) [GCC 13.3.0] Type 'copyright', 'credits' or 'license' for more information IPython 9.1.0 -- An enhanced Interactive Python. Type '?' for help. In [1]:
Copiez le code suivant dans votre session IPython :
import os
from typing import Iterator, MutableSequence, Optional, Sequence, Tuple
import google.cloud.documentai_v1 as docai
from tabulate import tabulate
PROJECT_ID = os.getenv("PROJECT_ID", "")
API_LOCATION = os.getenv("API_LOCATION", "")
assert PROJECT_ID, "PROJECT_ID is undefined"
assert API_LOCATION in ("us", "eu"), "API_LOCATION is incorrect"
# Test processors
document_ocr_display_name = "document-ocr"
form_parser_display_name = "form-parser"
test_processor_display_names_and_types = (
(document_ocr_display_name, "OCR_PROCESSOR"),
(form_parser_display_name, "FORM_PARSER_PROCESSOR"),
)
def get_client() -> docai.DocumentProcessorServiceClient:
client_options = {"api_endpoint": f"{API_LOCATION}-documentai.googleapis.com"}
return docai.DocumentProcessorServiceClient(client_options=client_options)
def get_parent(client: docai.DocumentProcessorServiceClient) -> str:
return client.common_location_path(PROJECT_ID, API_LOCATION)
def get_client_and_parent() -> Tuple[docai.DocumentProcessorServiceClient, str]:
client = get_client()
parent = get_parent(client)
return client, parent
Vous êtes prêt à envoyer votre première requête et à récupérer les types de processeurs.
4. Récupérer les types de processeurs
Avant de créer un processeur à l'étape suivante, récupérez les types de processeurs disponibles. Vous pouvez récupérer cette liste avec fetch_processor_types.
Ajoutez les fonctions suivantes à votre session IPython :
def fetch_processor_types() -> MutableSequence[docai.ProcessorType]:
client, parent = get_client_and_parent()
response = client.fetch_processor_types(parent=parent)
return response.processor_types
def print_processor_types(processor_types: Sequence[docai.ProcessorType]):
def sort_key(pt):
return (not pt.allow_creation, pt.category, pt.type_)
sorted_processor_types = sorted(processor_types, key=sort_key)
data = processor_type_tabular_data(sorted_processor_types)
headers = next(data)
colalign = next(data)
print(tabulate(data, headers, tablefmt="pretty", colalign=colalign))
print(f"→ Processor types: {len(sorted_processor_types)}")
def processor_type_tabular_data(
processor_types: Sequence[docai.ProcessorType],
) -> Iterator[Tuple[str, str, str, str]]:
def locations(pt):
return ", ".join(sorted(loc.location_id for loc in pt.available_locations))
yield ("type", "category", "allow_creation", "locations")
yield ("left", "left", "left", "left")
if not processor_types:
yield ("-", "-", "-", "-")
return
for pt in processor_types:
yield (pt.type_, pt.category, f"{pt.allow_creation}", locations(pt))
Répertoriez les types de processeurs :
processor_types = fetch_processor_types()
print_processor_types(processor_types)
Vous devriez obtenir un résultat semblable à celui-ci :
+--------------------------------------+-------------+----------------+-----------+ | type | category | allow_creation | locations | +--------------------------------------+-------------+----------------+-----------+ | CUSTOM_CLASSIFICATION_PROCESSOR | CUSTOM | True | eu, us | ... | FORM_PARSER_PROCESSOR | GENERAL | True | eu, us | | LAYOUT_PARSER_PROCESSOR | GENERAL | True | eu, us | | OCR_PROCESSOR | GENERAL | True | eu, us | | BANK_STATEMENT_PROCESSOR | SPECIALIZED | True | eu, us | | EXPENSE_PROCESSOR | SPECIALIZED | True | eu, us | ... +--------------------------------------+-------------+----------------+-----------+ → Processor types: 19
Vous disposez maintenant de toutes les informations nécessaires pour créer des processeurs à l'étape suivante.
5. Créer des processeurs
Pour créer un processeur, appelez create_processor avec un nom à afficher et un type de processeur.
Ajoutez la fonction suivante :
def create_processor(display_name: str, type: str) -> docai.Processor:
client, parent = get_client_and_parent()
processor = docai.Processor(display_name=display_name, type_=type)
return client.create_processor(parent=parent, processor=processor)
Créez les processeurs de test :
separator = "=" * 80
for display_name, type in test_processor_display_names_and_types:
print(separator)
print(f"Creating {display_name} ({type})...")
try:
create_processor(display_name, type)
except Exception as err:
print(err)
print(separator)
print("Done")
Vous devriez obtenir le résultat suivant :
================================================================================ Creating document-ocr (OCR_PROCESSOR)... ================================================================================ Creating form-parser (FORM_PARSER_PROCESSOR)... ================================================================================ Done
Vous avez créé des processeurs.
Ensuite, découvrez comment lister les processeurs.
6. Lister les processeurs de projet
list_processors renvoie la liste de tous les processeurs appartenant à votre projet.
Ajoutez les fonctions suivantes :
def list_processors() -> MutableSequence[docai.Processor]:
client, parent = get_client_and_parent()
response = client.list_processors(parent=parent)
return list(response.processors)
def print_processors(processors: Optional[Sequence[docai.Processor]] = None):
def sort_key(processor):
return processor.display_name
if processors is None:
processors = list_processors()
sorted_processors = sorted(processors, key=sort_key)
data = processor_tabular_data(sorted_processors)
headers = next(data)
colalign = next(data)
print(tabulate(data, headers, tablefmt="pretty", colalign=colalign))
print(f"→ Processors: {len(sorted_processors)}")
def processor_tabular_data(
processors: Sequence[docai.Processor],
) -> Iterator[Tuple[str, str, str]]:
yield ("display_name", "type", "state")
yield ("left", "left", "left")
if not processors:
yield ("-", "-", "-")
return
for processor in processors:
yield (processor.display_name, processor.type_, processor.state.name)
Appelez les fonctions :
processors = list_processors()
print_processors(processors)
Vous devriez obtenir le résultat suivant :
+--------------+-----------------------+---------+ | display_name | type | state | +--------------+-----------------------+---------+ | document-ocr | OCR_PROCESSOR | ENABLED | | form-parser | FORM_PARSER_PROCESSOR | ENABLED | +--------------+-----------------------+---------+ → Processors: 2
Pour récupérer un processeur par son nom à afficher, ajoutez la fonction suivante :
def get_processor(
display_name: str,
processors: Optional[Sequence[docai.Processor]] = None,
) -> Optional[docai.Processor]:
if processors is None:
processors = list_processors()
for processor in processors:
if processor.display_name == display_name:
return processor
return None
Testez la fonction :
processor = get_processor(document_ocr_display_name, processors)
assert processor is not None
print(processor)
L'écran qui s'affiche devrait ressembler à ce qui suit :
name: "projects/PROJECT_NUM/locations/LOCATION/processors/PROCESSOR_ID" type_: "OCR_PROCESSOR" display_name: "document-ocr" state: ENABLED ...
Vous savez maintenant comment lister les processeurs de votre projet et les récupérer par leur nom à afficher. Ensuite, découvrez comment utiliser un processeur.
7. Utiliser des processeurs
Les documents peuvent être traités de deux manières :
- De manière synchrone : appelez
process_documentpour analyser un seul document et utiliser directement les résultats. - Asynchrone : appelez
batch_process_documentspour lancer un traitement par lot sur plusieurs documents ou sur des documents volumineux.
Votre document de test ( PDF) est un questionnaire scanné avec des réponses manuscrites. Téléchargez-le dans votre répertoire de travail, directement depuis votre session IPython :
!gsutil cp gs://cloud-samples-data/documentai/form.pdf .
Vérifiez le contenu de votre répertoire de travail :
!ls
Vous devez disposer des éléments suivants :
... form.pdf ... venv-docai ...
Vous pouvez utiliser la méthode synchrone process_document pour analyser un fichier local. Ajoutez la fonction suivante :
def process_file(
processor: docai.Processor,
file_path: str,
mime_type: str,
) -> docai.Document:
client = get_client()
with open(file_path, "rb") as document_file:
document_content = document_file.read()
document = docai.RawDocument(content=document_content, mime_type=mime_type)
request = docai.ProcessRequest(raw_document=document, name=processor.name)
response = client.process_document(request)
return response.document
Comme votre document est un questionnaire, choisissez l'analyseur de formulaire. En plus d'extraire le texte (imprimé et manuscrit), ce que font tous les processeurs, ce processeur général détecte les champs de formulaire.
Analysez le document :
processor = get_processor(form_parser_display_name)
assert processor is not None
file_path = "./form.pdf"
mime_type = "application/pdf"
document = process_file(processor, file_path, mime_type)
Tous les processeurs exécutent une première passe de reconnaissance optique des caractères (OCR) sur le document. Examinez le texte détecté par l'OCR :
document.text.split("\n")
Ce type de page s'affiche :
['FakeDoc M.D.', 'HEALTH INTAKE FORM', 'Please fill out the questionnaire carefully. The information you provide will be used to complete', 'your health profile and will be kept confidential.', 'Date:', '9/14/19', 'Name:', 'Sally Walker', 'DOB: 09/04/1986', 'Address: 24 Barney Lane', 'City: Towaco', 'State: NJ Zip: 07082', 'Email: Sally, walker@cmail.com', '_Phone #: (906) 917-3486', 'Gender: F', 'Marital Status:', ... ]
Ajoutez les fonctions suivantes pour imprimer les champs de formulaire détectés :
def print_form_fields(document: docai.Document):
sorted_form_fields = form_fields_sorted_by_ocr_order(document)
data = form_field_tabular_data(sorted_form_fields, document)
headers = next(data)
colalign = next(data)
print(tabulate(data, headers, tablefmt="pretty", colalign=colalign))
print(f"→ Form fields: {len(sorted_form_fields)}")
def form_field_tabular_data(
form_fields: Sequence[docai.Document.Page.FormField],
document: docai.Document,
) -> Iterator[Tuple[str, str, str]]:
yield ("name", "value", "confidence")
yield ("right", "left", "right")
if not form_fields:
yield ("-", "-", "-")
return
for form_field in form_fields:
name_layout = form_field.field_name
value_layout = form_field.field_value
name = text_from_layout(name_layout, document)
value = text_from_layout(value_layout, document)
confidence = value_layout.confidence
yield (name, value, f"{confidence:.1%}")
Ajoutez également les fonctions utilitaires suivantes :
def form_fields_sorted_by_ocr_order(
document: docai.Document,
) -> MutableSequence[docai.Document.Page.FormField]:
def sort_key(form_field):
# Sort according to the field name detected position
text_anchor = form_field.field_name.text_anchor
return text_anchor.text_segments[0].start_index if text_anchor else 0
fields = (field for page in document.pages for field in page.form_fields)
return sorted(fields, key=sort_key)
def text_from_layout(
layout: docai.Document.Page.Layout,
document: docai.Document,
) -> str:
full_text = document.text
segs = layout.text_anchor.text_segments
text = "".join(full_text[seg.start_index : seg.end_index] for seg in segs)
if text.endswith("\n"):
text = text[:-1]
return text
Imprimez les champs de formulaire détectés :
print_form_fields(document)
Vous devriez obtenir un résultat semblable à celui-ci :
+-----------------+-------------------------+------------+ | name | value | confidence | +-----------------+-------------------------+------------+ | Date: | 9/14/19 | 83.0% | | Name: | Sally Walker | 87.3% | | DOB: | 09/04/1986 | 88.5% | | Address: | 24 Barney Lane | 82.4% | | City: | Towaco | 90.0% | | State: | NJ | 89.4% | | Zip: | 07082 | 91.4% | | Email: | Sally, walker@cmail.com | 79.7% | | _Phone #: | walker@cmail.com | 93.2% | | | (906 | | | Gender: | F | 88.2% | | Marital Status: | Single | 85.2% | | Occupation: | Software Engineer | 81.5% | | Referred By: | None | 76.9% | ... +-----------------+-------------------------+------------+ → Form fields: 17
Examinez les noms et les valeurs des champs qui ont été détectés ( PDF). Voici la première moitié du questionnaire :

Vous avez analysé un formulaire contenant du texte imprimé et manuscrit. Vous avez également détecté ses champs avec un niveau de confiance élevé. Vos pixels ont ainsi été transformés en données structurées.
8. Activer et désactiver les processeurs
Avec disable_processor et enable_processor, vous pouvez contrôler si un processeur peut être utilisé.
Ajoutez les fonctions suivantes :
def update_processor_state(processor: docai.Processor, enable_processor: bool):
client = get_client()
if enable_processor:
request = docai.EnableProcessorRequest(name=processor.name)
operation = client.enable_processor(request)
else:
request = docai.DisableProcessorRequest(name=processor.name)
operation = client.disable_processor(request)
operation.result() # Wait for operation to complete
def enable_processor(processor: docai.Processor):
update_processor_state(processor, True)
def disable_processor(processor: docai.Processor):
update_processor_state(processor, False)
Désactivez le processeur d'analyse de formulaires et vérifiez l'état de vos processeurs :
processor = get_processor(form_parser_display_name)
assert processor is not None
disable_processor(processor)
print_processors()
Vous devriez obtenir le résultat suivant :
+--------------+-----------------------+----------+ | display_name | type | state | +--------------+-----------------------+----------+ | document-ocr | OCR_PROCESSOR | ENABLED | | form-parser | FORM_PARSER_PROCESSOR | DISABLED | +--------------+-----------------------+----------+ → Processors: 2
Réactivez le processeur d'analyse des formulaires :
enable_processor(processor)
print_processors()
Vous devriez obtenir le résultat suivant :
+--------------+-----------------------+---------+ | display_name | type | state | +--------------+-----------------------+---------+ | document-ocr | OCR_PROCESSOR | ENABLED | | form-parser | FORM_PARSER_PROCESSOR | ENABLED | +--------------+-----------------------+---------+ → Processors: 2
Ensuite, découvrez comment gérer les versions de l'outil de traitement.
9. Gérer les versions de l'outil de traitement
Les processeurs peuvent être disponibles en plusieurs versions. Découvrez comment utiliser les méthodes list_processor_versions et set_default_processor_version.
Ajoutez les fonctions suivantes :
def list_processor_versions(
processor: docai.Processor,
) -> MutableSequence[docai.ProcessorVersion]:
client = get_client()
response = client.list_processor_versions(parent=processor.name)
return list(response)
def get_sorted_processor_versions(
processor: docai.Processor,
) -> MutableSequence[docai.ProcessorVersion]:
def sort_key(processor_version: docai.ProcessorVersion):
return processor_version.name
versions = list_processor_versions(processor)
return sorted(versions, key=sort_key)
def print_processor_versions(processor: docai.Processor):
versions = get_sorted_processor_versions(processor)
default_version_name = processor.default_processor_version
data = processor_versions_tabular_data(versions, default_version_name)
headers = next(data)
colalign = next(data)
print(tabulate(data, headers, tablefmt="pretty", colalign=colalign))
print(f"→ Processor versions: {len(versions)}")
def processor_versions_tabular_data(
versions: Sequence[docai.ProcessorVersion],
default_version_name: str,
) -> Iterator[Tuple[str, str, str]]:
yield ("version", "display name", "default")
yield ("left", "left", "left")
if not versions:
yield ("-", "-", "-")
return
for version in versions:
mapping = docai.DocumentProcessorServiceClient.parse_processor_version_path(
version.name
)
processor_version = mapping["processor_version"]
is_default = "Y" if version.name == default_version_name else ""
yield (processor_version, version.display_name, is_default)
Répertoriez les versions disponibles pour le processeur ROC :
processor = get_processor(document_ocr_display_name)
assert processor is not None
print_processor_versions(processor)
Vous obtenez les versions du processeur :
+--------------------------------+--------------------------+---------+ | version | display name | default | +--------------------------------+--------------------------+---------+ | pretrained-ocr-v1.0-2020-09-23 | Google Stable | | | pretrained-ocr-v1.1-2022-09-12 | Google Release Candidate | | | pretrained-ocr-v1.2-2022-11-10 | Google Release Candidate | | | pretrained-ocr-v2.0-2023-06-02 | Google Stable | Y | | pretrained-ocr-v2.1-2024-08-07 | Google Release Candidate | | +--------------------------------+--------------------------+---------+ → Processor versions: 5
Ajoutez maintenant une fonction pour modifier la version du processeur par défaut :
def set_default_processor_version(processor: docai.Processor, version_name: str):
client = get_client()
request = docai.SetDefaultProcessorVersionRequest(
processor=processor.name,
default_processor_version=version_name,
)
operation = client.set_default_processor_version(request)
operation.result() # Wait for operation to complete
Passez à la dernière version du processeur :
processor = get_processor(document_ocr_display_name)
assert processor is not None
versions = get_sorted_processor_versions(processor)
new_version = versions[-1] # Latest version
set_default_processor_version(processor, new_version.name)
# Update the processor info
processor = get_processor(document_ocr_display_name)
assert processor is not None
print_processor_versions(processor)
Vous obtenez la configuration de la nouvelle version :
+--------------------------------+--------------------------+---------+ | version | display name | default | +--------------------------------+--------------------------+---------+ | pretrained-ocr-v1.0-2020-09-23 | Google Stable | | | pretrained-ocr-v1.1-2022-09-12 | Google Release Candidate | | | pretrained-ocr-v1.2-2022-11-10 | Google Release Candidate | | | pretrained-ocr-v2.0-2023-06-02 | Google Stable | | | pretrained-ocr-v2.1-2024-08-07 | Google Release Candidate | Y | +--------------------------------+--------------------------+---------+ → Processor versions: 5
Ensuite, la méthode ultime de gestion des processeurs (suppression).
10. Supprimer des processeurs
Enfin, découvrez comment utiliser la méthode delete_processor.
Ajoutez la fonction suivante :
def delete_processor(processor: docai.Processor):
client = get_client()
operation = client.delete_processor(name=processor.name)
operation.result() # Wait for operation to complete
Supprimez vos processeurs de test :
processors_to_delete = [dn for dn, _ in test_processor_display_names_and_types]
print("Deleting processors...")
for processor in list_processors():
if processor.display_name not in processors_to_delete:
continue
print(f" Deleting {processor.display_name}...")
delete_processor(processor)
print("Done\n")
print_processors()
Vous devriez obtenir le résultat suivant :
Deleting processors... Deleting form-parser... Deleting document-ocr... Done +--------------+------+-------+ | display_name | type | state | +--------------+------+-------+ | - | - | - | +--------------+------+-------+ → Processors: 0
Vous avez découvert toutes les méthodes de gestion des processeurs. Vous avez presque terminé…
11. Félicitations !
Vous avez appris à gérer les processeurs Document AI à l'aide de Python.
Effectuer un nettoyage
Pour nettoyer votre environnement de développement, depuis Cloud Shell :
- Si vous êtes toujours dans votre session IPython, revenez à l'invite de commande :
exit - Arrêtez d'utiliser l'environnement virtuel Python :
deactivate - Supprimez le dossier de votre environnement virtuel :
cd ~ ; rm -rf ./venv-docai
Pour supprimer votre projet Google Cloud depuis Cloud Shell :
- Récupérez l'ID de votre projet actuel :
PROJECT_ID=$(gcloud config get-value core/project) - Assurez-vous qu'il s'agit bien du projet que vous souhaitez supprimer :
echo $PROJECT_ID - Supprimez le projet :
gcloud projects delete $PROJECT_ID
En savoir plus
- Essayez Document AI dans votre navigateur : https://cloud.google.com/document-ai/docs/drag-and-drop
- Informations sur les processeurs Document AI : https://cloud.google.com/document-ai/docs/processors-list
- Python sur Google Cloud : https://cloud.google.com/python
- Bibliothèques clientes Cloud pour Python : https://github.com/googleapis/google-cloud-python
Licence
Ce document est publié sous une licence Creative Commons Attribution 2.0 Generic.