
1. Introducción
Eventarc facilita la conexión de los servicios de Cloud Run con eventos de una variedad de fuentes. Te permite compilar arquitecturas basadas en eventos en las que los microservicios están distribuidos y con acoplamiento bajo. Se encarga de la transferencia, la entrega, la seguridad, la autorización y el manejo de errores de eventos por ti.
Workflows es una plataforma de organización completamente administrada que ejecuta servicios en el orden que defines: un flujo de trabajo. Estos flujos de trabajo pueden combinar servicios alojados en Cloud Run o Cloud Functions, servicios de Google Cloud, como Cloud Vision AI y BigQuery, y cualquier API basada en HTTP.
En este codelab, compilarás una organización de microservicios basada en eventos para procesar imágenes. Usarás Workflows para organizar el orden, las entradas y las salidas de 4 Cloud Functions de procesamiento de imágenes. Luego, habilitarás la orquestación para que responda a los eventos de Cloud Storage de una manera con acoplamiento bajo con Eventarc.
Al final, tendrás una arquitectura sin servidores flexible y estructurada para procesar imágenes.
Qué aprenderás
- Descripción general de Eventarc y Workflows
- Cómo implementar servicios de Cloud Functions
- Cómo organizar servicios con Workflows
- Cómo hacer que Workflows responda a eventos de Cloud Storage con Eventarc
2. Configuración y requisitos
Cómo configurar el entorno a tu propio ritmo
- Accede a Google Cloud Console y crea un proyecto nuevo o reutiliza uno existente. Si aún no tienes una cuenta de Gmail o de Google Workspace, debes crear una.

- El Nombre del proyecto es el nombre visible de los participantes de este proyecto. Es una cadena de caracteres que no se utiliza en las APIs de Google. Puedes actualizarla cuando quieras.
- El ID del proyecto es único en todos los proyectos de Google Cloud y es inmutable (no se puede cambiar después de configurarlo). La consola de Cloud genera automáticamente una cadena única. Por lo general, no importa cuál sea. En la mayoría de los codelabs, deberás hacer referencia al ID de tu proyecto (suele identificarse como
PROJECT_ID). Si no te gusta el ID que se generó, podrías generar otro aleatorio. También puedes probar uno propio y ver si está disponible. No se puede cambiar después de este paso y se usa el mismo durante todo el proyecto. - Recuerda que hay un tercer valor, un número de proyecto, que usan algunas APIs. Obtén más información sobre estos tres valores en la documentación.
- A continuación, deberás habilitar la facturación en la consola de Cloud para usar las APIs o los recursos de Cloud. Ejecutar este codelab no costará mucho, tal vez nada. Para cerrar recursos y evitar que se generen cobros más allá de este instructivo, puedes borrar los recursos que creaste o borrar el proyecto. Los usuarios nuevos de Google Cloud son aptos para participar en el programa Prueba gratuita de $300.
Inicie Cloud Shell
Si bien Google Cloud y Spanner se pueden operar de manera remota desde tu laptop, en este codelab usarás Google Cloud Shell, un entorno de línea de comandos que se ejecuta en la nube.
En Google Cloud Console, haz clic en el ícono de Cloud Shell en la barra de herramientas en la parte superior derecha:
El aprovisionamiento y la conexión al entorno deberían tomar solo unos minutos. Cuando termine el proceso, debería ver algo como lo siguiente:

Esta máquina virtual está cargada con todas las herramientas de desarrollo que necesitarás. Ofrece un directorio principal persistente de 5 GB y se ejecuta en Google Cloud, lo que permite mejorar considerablemente el rendimiento de la red y la autenticación. Todo tu trabajo en este codelab se puede hacer en un navegador. No es necesario que instales nada.
Configura gcloud
En Cloud Shell, establece el ID del proyecto y la región en la que deseas implementar tu aplicación. Guárdalos como variables PROJECT_ID y REGION. Consulta las ubicaciones de Cloud Functions para conocer las regiones disponibles.
PROJECT_ID=your-project-id gcloud config set project $PROJECT_ID
Obtén el código fuente
El código fuente de la aplicación se encuentra en la carpeta processing-pipelines del repo eventarc-samples.
Clone el repositorio:
git clone https://github.com/GoogleCloudPlatform/eventarc-samples.git
Navega a la carpeta eventarc-samples/processing-pipelines:
cd eventarc-samples/processing-pipelines
3. Descripción general de la arquitectura
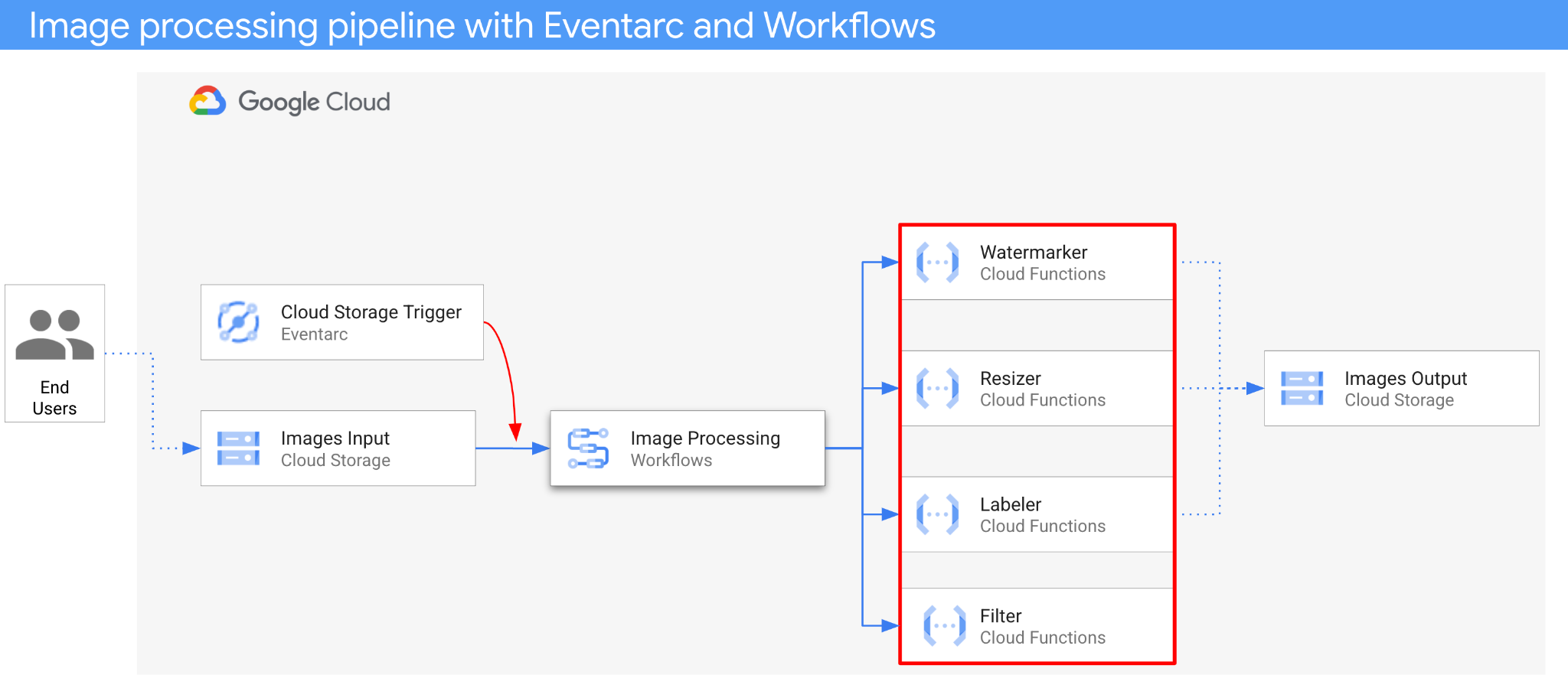
La arquitectura de la aplicación es la siguiente:
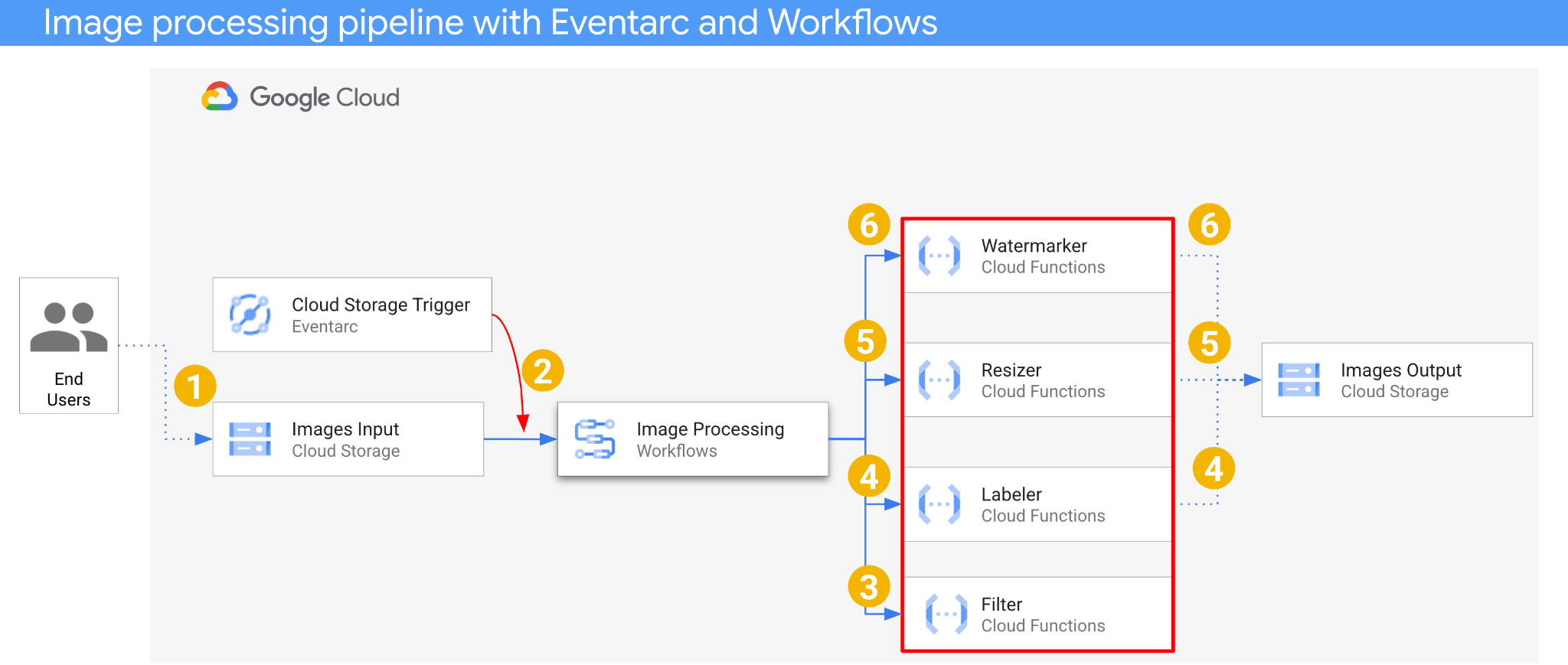
- Se guarda una imagen en un bucket de entrada que genera un evento de creación de Cloud Storage.
- Eventarc lee el evento de creación de Cloud Storage a través de un activador de Cloud Storage y lo pasa a Workflows como un CloudEvent.
- En el primer paso del flujo de trabajo, Filter, un servicio de Cloud Functions, usa la API de Vision para determinar si la imagen es segura. Si la imagen es segura, Workflows continúa con los siguientes pasos.
- En el segundo paso del flujo de trabajo, Labeler, un servicio de Cloud Functions, extrae las etiquetas de la imagen con la API de Vision y las guarda en el bucket de salida.
- En el tercer paso, Resizer, otro servicio de Cloud Functions, cambia el tamaño de la imagen con ImageSharp y guarda la imagen redimensionada en el bucket de salida.
- En el último paso, Watermarker, otro servicio de Cloud Functions, agrega una marca de agua de las etiquetas de Labeler a la imagen redimensionada con ImageSharp y guarda la imagen en el bucket de salida.
La aplicación se activa con un evento de Cloud Storage, por lo que se controla por eventos. El procesamiento de imágenes se realiza en un flujo de trabajo, por lo que es una organización. Al final, se trata de una organización basada en eventos para una arquitectura sin servidores flexible y estructurada para procesar imágenes.
4. Crear depósitos
Crea un bucket de entrada para que los usuarios suban las imágenes y un bucket de salida para que la canalización de procesamiento de imágenes guarde las imágenes procesadas.
En Cloud Shell, ejecute lo siguiente:
REGION=us-central1 BUCKET1=$PROJECT_ID-images-input-$RANDOM BUCKET2=$PROJECT_ID-images-output-$RANDOM gsutil mb -l $REGION gs://$BUCKET1 gsutil mb -l $REGION gs://$BUCKET2
5. Implementa el servicio de filtros
Comencemos por implementar el primer servicio. Este servicio de Cloud Functions recibe la información del bucket y del archivo, determina si la imagen es segura con la API de Vision y devuelve el resultado.
Primero, habilita los servicios requeridos para Cloud Functions gen2 y la API de Vision:
gcloud services enable \ artifactregistry.googleapis.com \ cloudbuild.googleapis.com \ cloudfunctions.googleapis.com \ run.googleapis.com \ vision.googleapis.com
Dentro de la carpeta de nivel superior processing-pipelines, implementa el servicio:
SERVICE_NAME=filter gcloud functions deploy $SERVICE_NAME \ --gen2 \ --allow-unauthenticated \ --runtime dotnet3 \ --trigger-http \ --region=$REGION \ --entry-point Filter.Function \ --set-build-env-vars GOOGLE_BUILDABLE=image-v3/filter/csharp
Una vez que se implemente la función, establece la URL del servicio en una variable. La necesitaremos más adelante:
FILTER_URL=$(gcloud functions describe $SERVICE_NAME --region=$REGION --gen2 --format 'value(serviceConfig.uri)')
6. Implementa el servicio de etiquetado
El segundo servicio de Cloud Functions recibe la información del bucket y el archivo, extrae las etiquetas de la imagen con la API de Vision y guarda las etiquetas en el bucket de salida.
Dentro de la carpeta de nivel superior processing-pipelines, implementa el servicio:
SERVICE_NAME=labeler gcloud functions deploy $SERVICE_NAME \ --gen2 \ --allow-unauthenticated \ --runtime dotnet3 \ --trigger-http \ --region=$REGION \ --set-env-vars BUCKET=$BUCKET2 \ --entry-point Labeler.Function \ --set-build-env-vars GOOGLE_BUILDABLE=image-v2/labeler/csharp
Una vez que se implemente la función, establece la URL del servicio en una variable. La necesitaremos más adelante:
LABELER_URL=$(gcloud functions describe $SERVICE_NAME --region=$REGION --gen2 --format 'value(serviceConfig.uri)')
7. Implementa el servicio de cambio de tamaño
Este servicio de Cloud Functions recibe la información del bucket y el archivo, cambia el tamaño de la imagen con ImageSharp y guarda la imagen en el bucket de salida.
Dentro de la carpeta de nivel superior processing-pipelines, implementa el servicio:
SERVICE_NAME=resizer gcloud functions deploy $SERVICE_NAME \ --gen2 \ --allow-unauthenticated \ --runtime dotnet3 \ --trigger-http \ --region=$REGION \ --set-env-vars BUCKET=$BUCKET2 \ --entry-point Resizer.Function \ --set-build-env-vars GOOGLE_BUILDABLE=image-v2/resizer/csharp \ --timeout=120s
Ten en cuenta el valor de timeout de 2 minutos para permitir que la función de cambio de tamaño tenga tiempo adicional para el procesamiento.
Una vez que se implemente la función, establece la URL del servicio en una variable. La necesitaremos más adelante:
RESIZER_URL=$(gcloud functions describe $SERVICE_NAME --region=$REGION --gen2 --format 'value(serviceConfig.uri)')
8. Implementa el servicio de marcas de agua
Este servicio de Cloud Functions recibe la información del bucket, el archivo y las etiquetas, lee el archivo, agrega las etiquetas como marcas de agua a la imagen con ImageSharp y guarda la imagen en el bucket de salida.
Dentro de la carpeta de nivel superior processing-pipelines, implementa el servicio:
SERVICE_NAME=watermarker gcloud functions deploy $SERVICE_NAME \ --gen2 \ --allow-unauthenticated \ --runtime dotnet3 \ --trigger-http \ --region=$REGION \ --set-env-vars BUCKET=$BUCKET2 \ --entry-point Watermarker.Function \ --set-build-env-vars GOOGLE_BUILDABLE=image-v2/watermarker/csharp
Una vez que se implemente la función, establece la URL del servicio en una variable. La necesitaremos más adelante:
WATERMARKER_URL=$(gcloud functions describe $SERVICE_NAME --region=$REGION --gen2 --format 'value(serviceConfig.uri)')
En este punto, las cuatro funciones de Cloud Functions deberían estar implementadas y en ejecución:
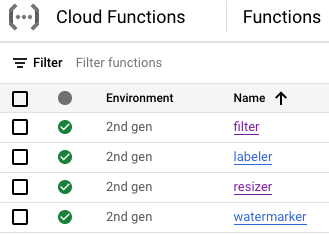
9. Define e implementa el flujo de trabajo
Usa Workflows para reunir los servicios de filtro, etiquetado, cambio de tamaño y marca de agua en un flujo de trabajo. Workflows organizará las llamadas a estos servicios en el orden y con los parámetros que definamos.
Primero, habilita los servicios requeridos para Workflows:
gcloud services enable \ workflows.googleapis.com \ workflowexecutions.googleapis.com
Definir
Workflows recibe un CloudEvent como parámetro. Esto provendrá de Eventarc una vez que creemos un activador. En los dos primeros pasos, Workflows registra el evento y extrae la información del bucket y el archivo del evento:
main:
params: [event]
steps:
- log_event:
call: sys.log
args:
text: ${event}
severity: INFO
- extract_bucket_and_file:
assign:
- bucket: ${event.data.bucket}
- file: ${event.data.name}
En el paso filter, Workflows llama al servicio de filtro que implementamos antes. Luego, registra y verifica la seguridad del archivo:
- filter:
call: http.post
args:
url: FILTER_URL # TODO: Replace
auth:
type: OIDC
body:
bucket: ${bucket}
file: ${file}
result: filterResponse
- log_safety:
call: sys.log
args:
text: ${filterResponse.body.safe}
severity: INFO
- check_safety:
switch:
- condition: ${filterResponse.body.safe == true}
next: label
next: end
En el paso label, Workflows llama al servicio de etiquetado y captura la respuesta (las 3 etiquetas principales):
- label:
call: http.post
args:
url: LABELER_URL # TODO: Replace
auth:
type: OIDC
body:
bucket: ${bucket}
file: ${file}
result: labelResponse
En el paso resize, Workflows llama al servicio de cambio de tamaño y captura la respuesta (el bucket y el archivo de la imagen redimensionada):
- resize:
call: http.post
args:
url: RESIZER_URL # TODO: Replace
auth:
type: OIDC
body:
bucket: ${bucket}
file: ${file}
result: resizeResponse
En el paso watermark, Workflows llama al servicio de marcas de agua con la imagen y las etiquetas redimensionadas, y captura el resultado (la imagen redimensionada y con marca de agua):
- watermark:
call: http.post
args:
url: WATERMARKER_URL # TODO: Replace
auth:
type: OIDC
body:
bucket: ${resizeResponse.body.bucket}
file: ${resizeResponse.body.file}
labels: ${labelResponse.body.labels}
result: watermarkResponse
En el paso final, Workflows devuelve el código de estado HTTP de los servicios de etiquetado, cambio de tamaño y marca de agua:
- final:
return:
label: ${labelResponse.code}
resize: ${resizeResponse.code}
watermark: ${watermarkResponse.code}
Implementar
Antes de implementar el flujo de trabajo, asegúrate de que las URLs de servicio se reemplacen por las URLs de las funciones implementadas, ya sea de forma manual o con sed:
Dentro de la carpeta processing-pipelines de nivel superior, navega a la carpeta image-v3 en la que se encuentra el archivo workflows.yaml:
cd image-v3/
Ejecuta sed para reemplazar las URLs de marcador de posición por las URLs reales de los servicios implementados:
sed -i -e "s|FILTER_URL|${FILTER_URL}|" workflow.yaml
sed -i -e "s|LABELER_URL|${LABELER_URL}|" workflow.yaml
sed -i -e "s|RESIZER_URL|${RESIZER_URL}|" workflow.yaml
sed -i -e "s|WATERMARKER_URL|${WATERMARKER_URL}|" workflow.yaml
Implementa el flujo de trabajo:
WORKFLOW_NAME=image-processing
gcloud workflows deploy $WORKFLOW_NAME \
--source=workflow.yaml \
--location=$REGION
En unos segundos, deberías ver el flujo de trabajo implementado en la consola:
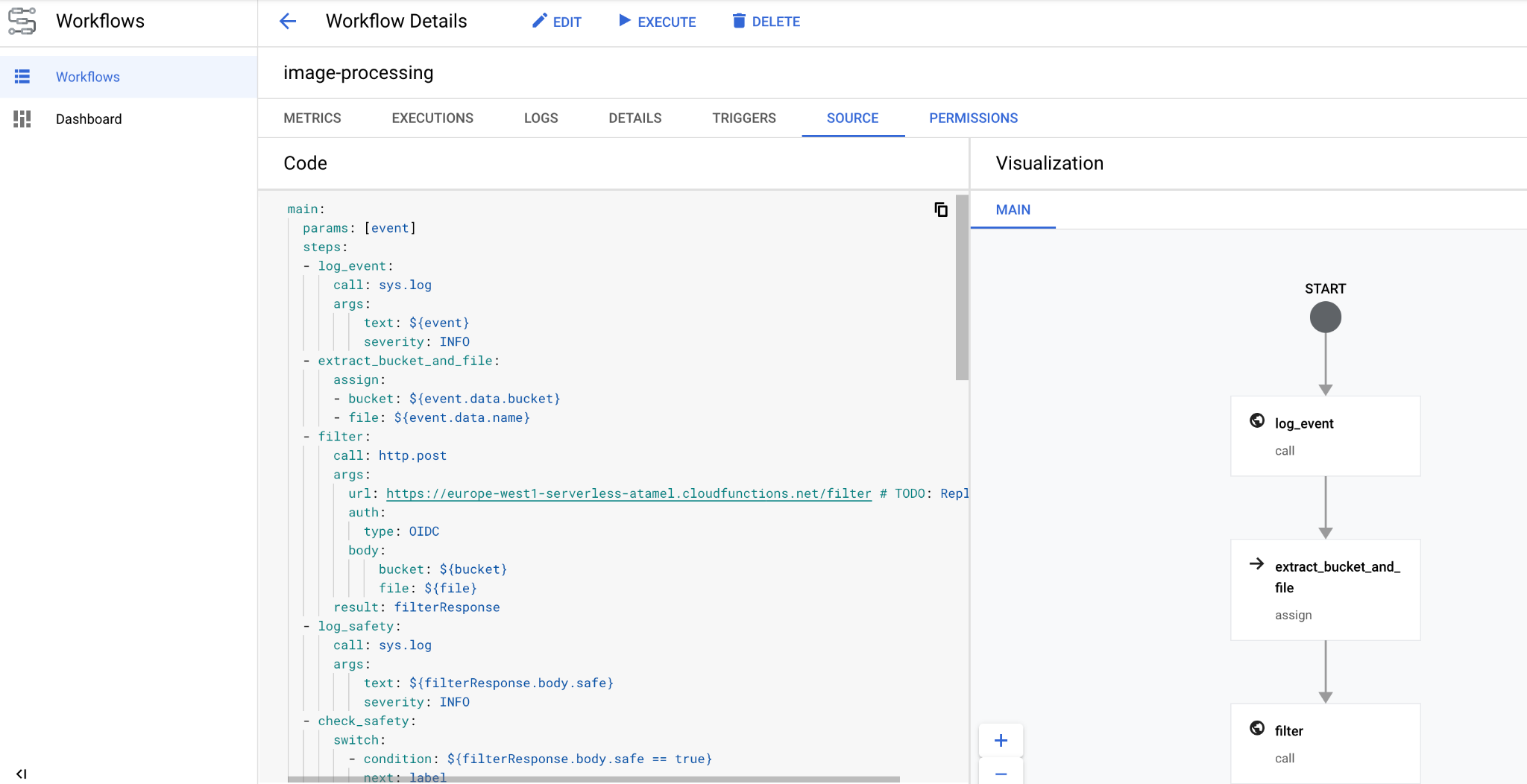
10. Crear activador
Ahora que el flujo de trabajo está implementado, el último paso es conectarlo a los eventos de Cloud Storage con un activador de Eventarc.
Configuración única
Primero, habilita los servicios obligatorios para Eventarc:
gcloud services enable \ eventarc.googleapis.com
Crea una cuenta de servicio que usarás en el activador de Eventarc.
SERVICE_ACCOUNT=eventarc-trigger-imageproc-sa gcloud iam service-accounts create $SERVICE_ACCOUNT \ --display-name="Eventarc trigger image processing service account"
Otorga el rol workflows.invoker para que la cuenta de servicio se pueda usar para invocar Workflows desde Eventarc:
gcloud projects add-iam-policy-binding $PROJECT_ID \ --role roles/workflows.invoker \ --member serviceAccount:$SERVICE_ACCOUNT@$PROJECT_ID.iam.gserviceaccount.com
Otorga el rol eventarc.eventReceiver, o bien la cuenta de servicio se puede usar en un
Activador de Cloud Storage:
gcloud projects add-iam-policy-binding $PROJECT_ID \ --role roles/eventarc.eventReceiver \ --member serviceAccount:$SERVICE_ACCOUNT@$PROJECT_ID.iam.gserviceaccount.com
Otorga el rol pubsub.publisher a la cuenta de servicio de Cloud Storage. Esto es necesario para el activador de Cloud Storage de Eventarc:
STORAGE_SERVICE_ACCOUNT="$(gsutil kms serviceaccount -p $PROJECT_ID)"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member serviceAccount:$STORAGE_SERVICE_ACCOUNT \
--role roles/pubsub.publisher
Crear
Ejecuta el siguiente comando para crear un activador. Este activador filtra los eventos de creación de archivos nuevos del bucket de Cloud Storage de entrada y los pasa al flujo de trabajo que definimos anteriormente:
TRIGGER_NAME=trigger-image-processing gcloud eventarc triggers create $TRIGGER_NAME \ --location=$REGION \ --destination-workflow=$WORKFLOW_NAME \ --destination-workflow-location=$REGION \ --event-filters="type=google.cloud.storage.object.v1.finalized" \ --event-filters="bucket=$BUCKET1" \ --service-account=$SERVICE_ACCOUNT@$PROJECT_ID.iam.gserviceaccount.com
Puedes ver que el activador se creó y está listo en la sección Eventarc de Cloud Console:

11. Prueba la canalización
La canalización de procesamiento de imágenes está lista para recibir eventos de Cloud Storage. Para probar la canalización, sube una imagen al bucket de entrada:
gsutil cp beach.jpg gs://$BUCKET1
En cuanto subas la imagen, deberías ver una ejecución de Workflows en estado activo:
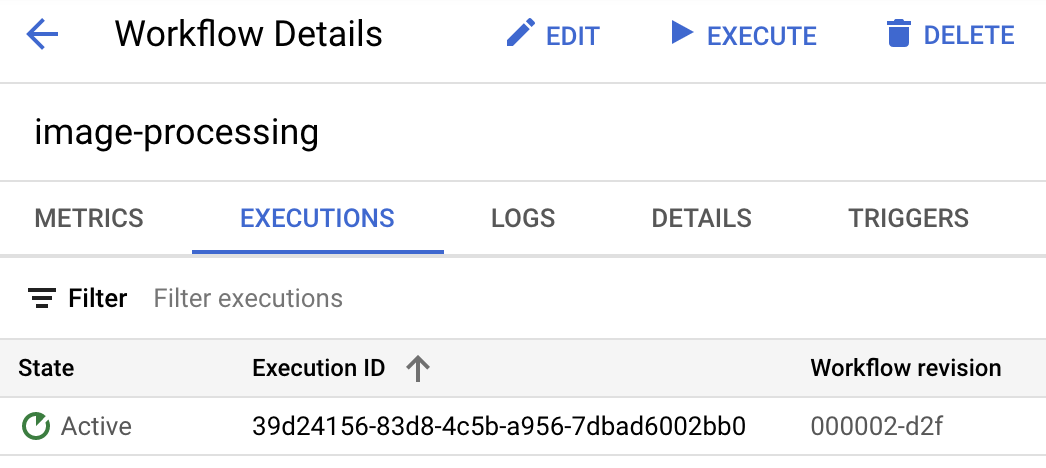
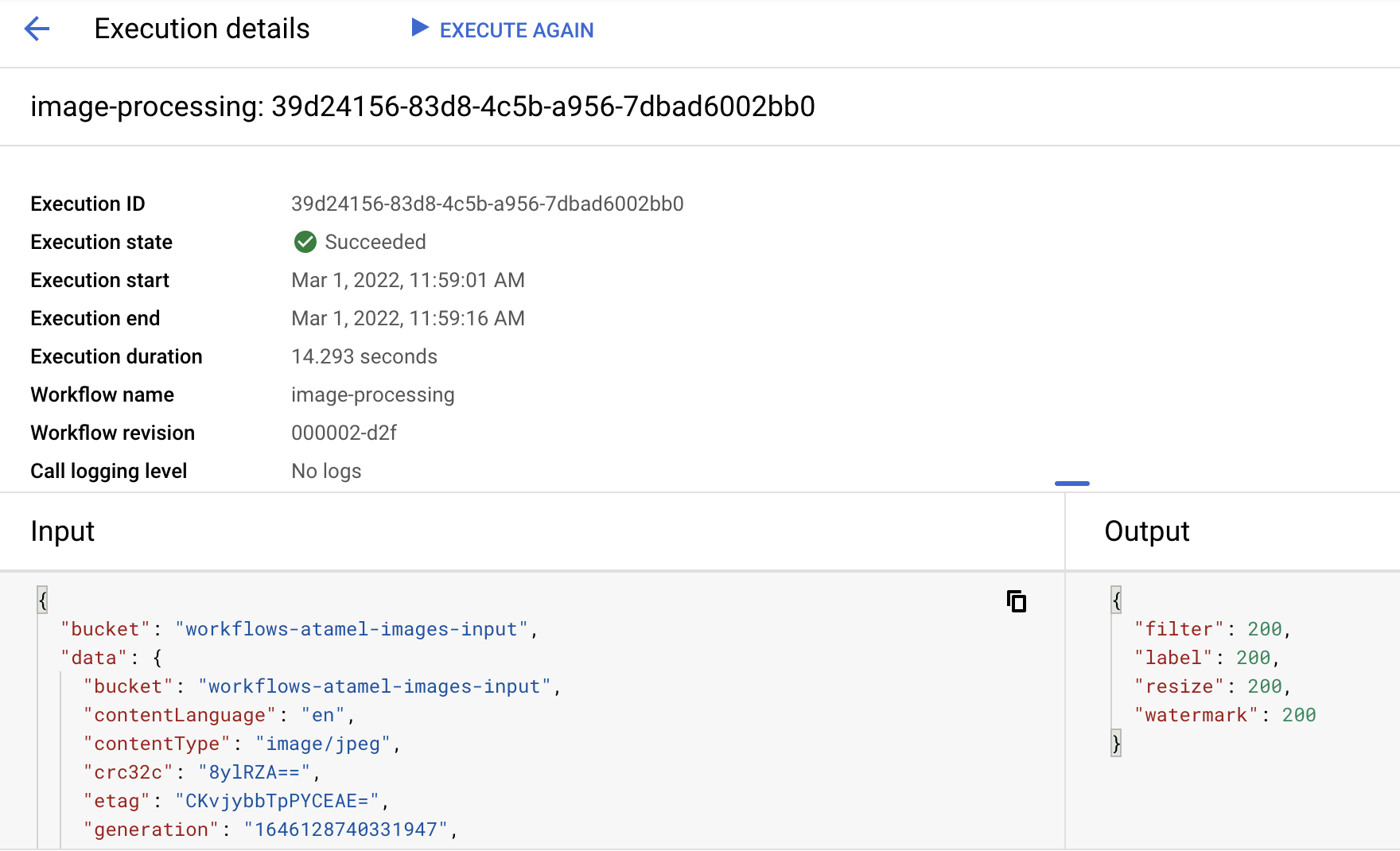
Después de un minuto aproximadamente, deberías ver que la ejecución se realizó correctamente. También puedes ver la entrada y la salida del flujo de trabajo:
Si enumeras el contenido del bucket de salida, deberías ver la imagen redimensionada, la imagen redimensionada con marca de agua y las etiquetas de la imagen:
gsutil ls gs://$BUCKET2 gs://$PROJECT_ID-images-output-$RANDOM/beach-400x400-watermark.jpeg gs://$PROJECT_ID-images-output-$RANDOM/beach-400x400.png gs://$PROJECT_ID-images-output-$RANDOM/beach-labels.txt
Para verificarlo, puedes abrir la imagen redimensionada y con marca de agua para ver el resultado:

12. Felicitaciones
¡Felicitaciones! Completaste el codelab.
Temas abordados
- Descripción general de Eventarc y Workflows
- Cómo implementar servicios de Cloud Functions
- Cómo organizar servicios con Workflows
- Cómo hacer que Workflows responda a eventos de Cloud Storage con Eventarc