
1. Introduction
Eventarc permet de connecter facilement les services Cloud Run à des événements provenant de diverses sources. Il vous permet de créer des architectures basées sur des événements dans lesquelles les microservices sont faiblement couplés et distribués. Il gère l'ingestion, la diffusion, la sécurité, l'autorisation et le traitement des erreurs à votre place.
Workflows est une plate-forme d'orchestration entièrement gérée qui exécute des services dans un ordre que vous définissez : un workflow. Ces workflows peuvent combiner des services hébergés sur Cloud Run ou Cloud Functions, des services Google Cloud tels que Cloud Vision AI et BigQuery, ainsi que toute API HTTP.
Dans cet atelier de programmation, vous allez créer une orchestration de microservices basée sur des événements pour traiter des images. Vous utiliserez Workflows pour orchestrer l'ordre, les entrées et les sorties de quatre Cloud Functions de traitement d'images. Vous allez ensuite activer l'orchestration pour qu'elle réponde aux événements Cloud Storage de manière faiblement couplée avec Eventarc.
À la fin de cet atelier, vous disposerez d'une architecture sans serveur flexible, mais structurée, pour traiter les images.
Points abordés
- Présentation d'Eventarc et de Workflows
- Déployer des services Cloud Functions
- Orchestrer des services à l'aide de Workflows
- Faire en sorte que Workflows réponde aux événements Cloud Storage avec Eventarc
2. Préparation
Configuration de l'environnement d'auto-formation
- Connectez-vous à la console Google Cloud, puis créez un projet ou réutilisez un projet existant. (Si vous ne possédez pas encore de compte Gmail ou Google Workspace, vous devez en créer un.)

- Le nom du projet est le nom à afficher pour les participants au projet. Il s'agit d'une chaîne de caractères non utilisée par les API Google. Vous pourrez toujours le modifier.
- L'ID du projet est unique parmi tous les projets Google Cloud et non modifiable une fois défini. La console Cloud génère automatiquement une chaîne unique (en général, vous n'y accordez d'importance particulière). Dans la plupart des ateliers de programmation, vous devrez indiquer l'ID de votre projet (généralement identifié par
PROJECT_ID). Si l'ID généré ne vous convient pas, vous pouvez en générer un autre de manière aléatoire. Vous pouvez également en spécifier un et voir s'il est disponible. Après cette étape, l'ID n'est plus modifiable et restera donc le même pour toute la durée du projet. - Pour information, il existe une troisième valeur (le numéro de projet) que certaines API utilisent. Pour en savoir plus sur ces trois valeurs, consultez la documentation.
- Vous devez ensuite activer la facturation dans la console Cloud pour utiliser les ressources/API Cloud. L'exécution de cet atelier de programmation est très peu coûteuse, voire sans frais. Pour désactiver les ressources et éviter ainsi que des frais ne vous soient facturés après ce tutoriel, vous pouvez supprimer le projet ou les ressources que vous avez créées. Les nouveaux utilisateurs de Google Cloud peuvent participer au programme d'essai sans frais pour bénéficier d'un crédit de 300 $.
Démarrer Cloud Shell
Bien que Google Cloud puisse être utilisé à distance depuis votre ordinateur portable, nous allons nous servir de Google Cloud Shell pour cet atelier de programmation, un environnement de ligne de commande exécuté dans le cloud.
Dans la console Google Cloud, cliquez sur l'icône Cloud Shell dans la barre d'outils supérieure :
Le provisionnement et la connexion à l'environnement prennent quelques instants seulement. Une fois l'opération terminée, le résultat devrait ressembler à ceci :

Cette machine virtuelle contient tous les outils de développement nécessaires. Elle comprend un répertoire d'accueil persistant de 5 Go et s'exécute sur Google Cloud, ce qui améliore nettement les performances du réseau et l'authentification. Vous pouvez effectuer toutes les tâches de cet atelier de programmation dans un navigateur. Vous n'avez rien à installer.
Configurer gcloud
Dans Cloud Shell, définissez votre ID de projet et la région dans laquelle vous souhaitez déployer votre application. Enregistrez-les en tant que variables PROJECT_ID et REGION. Pour connaître les régions disponibles, consultez Emplacements Cloud Functions.
PROJECT_ID=your-project-id gcloud config set project $PROJECT_ID
Obtenir le code source
Le code source de l'application se trouve dans le dossier processing-pipelines du dépôt eventarc-samples.
Clonez le dépôt :
git clone https://github.com/GoogleCloudPlatform/eventarc-samples.git
Accédez au dossier eventarc-samples/processing-pipelines :
cd eventarc-samples/processing-pipelines
3. Présentation de l'architecture
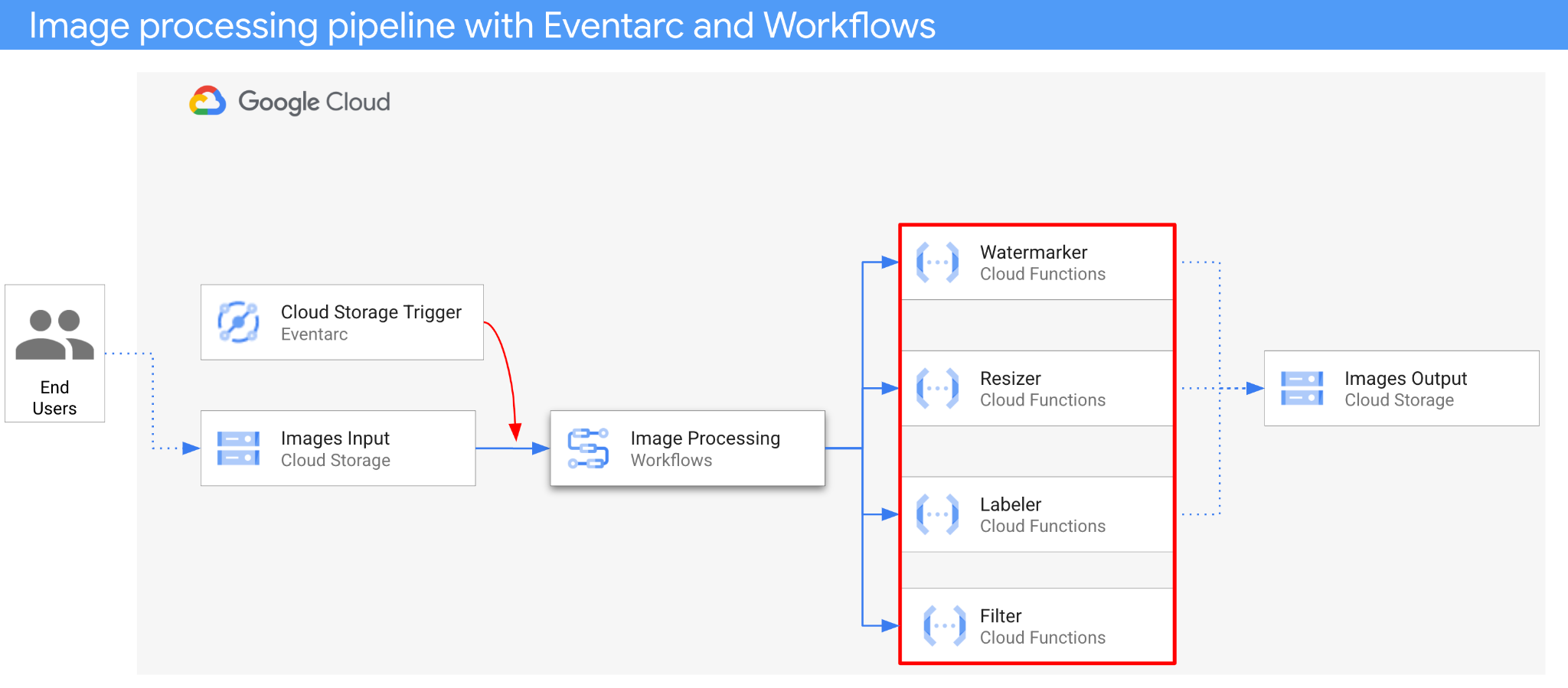
L'architecture de l'application est la suivante :
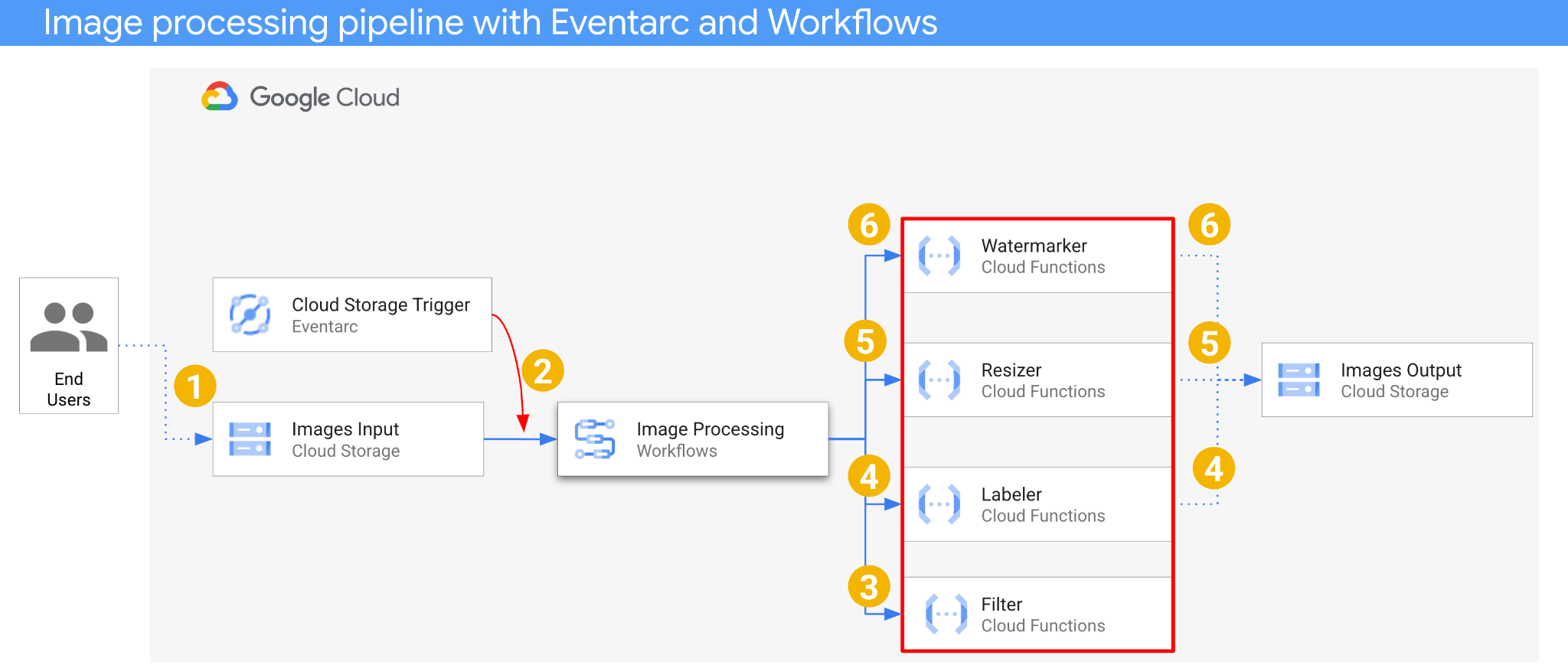
- Une image est enregistrée dans un bucket d'entrée qui génère un événement de création Cloud Storage.
- L'événement de création Cloud Storage est lu par Eventarc via un déclencheur Cloud Storage et transmis à Workflows en tant que CloudEvent.
- Lors de la première étape du workflow, Filter, un service Cloud Functions, utilise l'API Vision pour déterminer si l'image est sûre. Si l'image est sûre, Workflows passe aux étapes suivantes.
- Dans la deuxième étape du workflow, Labeler, un service Cloud Functions, extrait les libellés de l'image avec l'API Vision et les enregistre dans le bucket de sortie.
- À la troisième étape, Resizer, un autre service Cloud Functions, redimensionne l'image à l'aide d'ImageSharp et l'enregistre dans le bucket de sortie.
- À la dernière étape, Watermarker, un autre service Cloud Functions, ajoute un filigrane de libellés provenant de Labeler à l'image redimensionnée à l'aide d'ImageSharp et enregistre l'image dans le bucket de sortie.
L'application est déclenchée par un événement Cloud Storage, elle est donc axée sur les événements. Le traitement des images se fait dans un workflow, il s'agit donc d'une orchestration. En fin de compte, il s'agit d'une orchestration basée sur des événements pour une architecture sans serveur flexible, mais structurée, permettant de traiter des images.
4. Créer des buckets
Créez un bucket d'entrée pour que les utilisateurs puissent y importer les images, ainsi qu'un bucket de sortie pour que le pipeline de traitement d'images puisse y enregistrer les images traitées.
Exécutez la commande suivante dans Cloud Shell :
REGION=us-central1 BUCKET1=$PROJECT_ID-images-input-$RANDOM BUCKET2=$PROJECT_ID-images-output-$RANDOM gsutil mb -l $REGION gs://$BUCKET1 gsutil mb -l $REGION gs://$BUCKET2
5. Déployer le service de filtrage
Commençons par déployer le premier service. Ce service Cloud Functions reçoit les informations sur le bucket et le fichier, détermine si l'image est sécurisée avec l'API Vision et renvoie le résultat.
Tout d'abord, activez les services requis pour Cloud Functions Gen2 et l'API Vision :
gcloud services enable \ artifactregistry.googleapis.com \ cloudbuild.googleapis.com \ cloudfunctions.googleapis.com \ run.googleapis.com \ vision.googleapis.com
Dans le dossier racine processing-pipelines, déployez le service :
SERVICE_NAME=filter gcloud functions deploy $SERVICE_NAME \ --gen2 \ --allow-unauthenticated \ --runtime dotnet3 \ --trigger-http \ --region=$REGION \ --entry-point Filter.Function \ --set-build-env-vars GOOGLE_BUILDABLE=image-v3/filter/csharp
Une fois la fonction déployée, définissez l'URL du service dans une variable. Nous en aurons besoin plus tard :
FILTER_URL=$(gcloud functions describe $SERVICE_NAME --region=$REGION --gen2 --format 'value(serviceConfig.uri)')
6. Déployer le service d'étiquetage
Le deuxième service Cloud Functions reçoit les informations sur le bucket et le fichier, extrait les libellés de l'image avec l'API Vision et enregistre les libellés dans le bucket de sortie.
Dans le dossier racine processing-pipelines, déployez le service :
SERVICE_NAME=labeler gcloud functions deploy $SERVICE_NAME \ --gen2 \ --allow-unauthenticated \ --runtime dotnet3 \ --trigger-http \ --region=$REGION \ --set-env-vars BUCKET=$BUCKET2 \ --entry-point Labeler.Function \ --set-build-env-vars GOOGLE_BUILDABLE=image-v2/labeler/csharp
Une fois la fonction déployée, définissez l'URL du service dans une variable. Nous en aurons besoin plus tard :
LABELER_URL=$(gcloud functions describe $SERVICE_NAME --region=$REGION --gen2 --format 'value(serviceConfig.uri)')
7. Déployer le service de redimensionnement
Ce service Cloud Functions reçoit les informations sur le bucket et le fichier, redimensionne l'image à l'aide d'ImageSharp et l'enregistre dans le bucket de sortie.
Dans le dossier racine processing-pipelines, déployez le service :
SERVICE_NAME=resizer gcloud functions deploy $SERVICE_NAME \ --gen2 \ --allow-unauthenticated \ --runtime dotnet3 \ --trigger-http \ --region=$REGION \ --set-env-vars BUCKET=$BUCKET2 \ --entry-point Resizer.Function \ --set-build-env-vars GOOGLE_BUILDABLE=image-v2/resizer/csharp \ --timeout=120s
Notez la valeur timeout de deux minutes pour laisser à la fonction de redimensionnement un délai de traitement supplémentaire.
Une fois la fonction déployée, définissez l'URL du service dans une variable. Nous en aurons besoin plus tard :
RESIZER_URL=$(gcloud functions describe $SERVICE_NAME --region=$REGION --gen2 --format 'value(serviceConfig.uri)')
8. Déployer le service d'ajout de filigrane
Ce service Cloud Functions reçoit les informations sur le bucket, le fichier et les libellés, lit le fichier, ajoute les libellés en filigrane à l'image à l'aide d'ImageSharp et enregistre l'image dans le bucket de sortie.
Dans le dossier racine processing-pipelines, déployez le service :
SERVICE_NAME=watermarker gcloud functions deploy $SERVICE_NAME \ --gen2 \ --allow-unauthenticated \ --runtime dotnet3 \ --trigger-http \ --region=$REGION \ --set-env-vars BUCKET=$BUCKET2 \ --entry-point Watermarker.Function \ --set-build-env-vars GOOGLE_BUILDABLE=image-v2/watermarker/csharp
Une fois la fonction déployée, définissez l'URL du service dans une variable. Nous en aurons besoin plus tard :
WATERMARKER_URL=$(gcloud functions describe $SERVICE_NAME --region=$REGION --gen2 --format 'value(serviceConfig.uri)')
À ce stade, les quatre fonctions Cloud Functions doivent être déployées et en cours d'exécution :
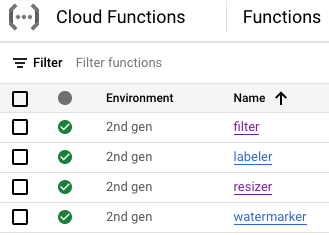
9. Définir et déployer un workflow
Utilisez Workflows pour regrouper les services de filtrage, d'étiquetage, de redimensionnement et de filigranage dans un workflow. Workflows orchestrera l'appel de ces services dans l'ordre et avec les paramètres que nous définissons.
Tout d'abord, activez les services requis pour Workflows :
gcloud services enable \ workflows.googleapis.com \ workflowexecutions.googleapis.com
Définir
Workflows reçoit un CloudEvent comme paramètre. Il proviendra d'Eventarc une fois que nous aurons créé un déclencheur. Lors des deux premières étapes, Workflows consigne l'événement et extrait les informations sur le bucket et le fichier à partir de l'événement :
main:
params: [event]
steps:
- log_event:
call: sys.log
args:
text: ${event}
severity: INFO
- extract_bucket_and_file:
assign:
- bucket: ${event.data.bucket}
- file: ${event.data.name}
À l'étape filter, Workflows appelle le service de filtrage que nous avons déployé précédemment. Il enregistre ensuite le fichier et vérifie sa sécurité :
- filter:
call: http.post
args:
url: FILTER_URL # TODO: Replace
auth:
type: OIDC
body:
bucket: ${bucket}
file: ${file}
result: filterResponse
- log_safety:
call: sys.log
args:
text: ${filterResponse.body.safe}
severity: INFO
- check_safety:
switch:
- condition: ${filterResponse.body.safe == true}
next: label
next: end
À l'étape label, Workflows appelle le service de classification et capture la réponse (les trois principaux libellés) :
- label:
call: http.post
args:
url: LABELER_URL # TODO: Replace
auth:
type: OIDC
body:
bucket: ${bucket}
file: ${file}
result: labelResponse
À l'étape resize, Workflows appelle le service de redimensionnement et capture la réponse (le bucket et le fichier de l'image redimensionnée) :
- resize:
call: http.post
args:
url: RESIZER_URL # TODO: Replace
auth:
type: OIDC
body:
bucket: ${bucket}
file: ${file}
result: resizeResponse
À l'étape watermark, Workflows appelle le service de filigranage avec l'image redimensionnée et les libellés, puis capture le résultat (l'image redimensionnée et filigranée) :
- watermark:
call: http.post
args:
url: WATERMARKER_URL # TODO: Replace
auth:
type: OIDC
body:
bucket: ${resizeResponse.body.bucket}
file: ${resizeResponse.body.file}
labels: ${labelResponse.body.labels}
result: watermarkResponse
À l'étape final, les workflows renvoient le code d'état HTTP des services de création de libellés, de redimensionnement et d'ajout de filigranes :
- final:
return:
label: ${labelResponse.code}
resize: ${resizeResponse.code}
watermark: ${watermarkResponse.code}
Déployer
Avant de déployer le workflow, assurez-vous que les URL de service sont remplacées par celles des fonctions déployées, manuellement ou à l'aide de sed :
Dans le dossier de premier niveau processing-pipelines, accédez au dossier image-v3 où se trouve le fichier workflows.yaml :
cd image-v3/
Exécutez sed pour remplacer les URL d'espace réservé par les URL réelles des services déployés :
sed -i -e "s|FILTER_URL|${FILTER_URL}|" workflow.yaml
sed -i -e "s|LABELER_URL|${LABELER_URL}|" workflow.yaml
sed -i -e "s|RESIZER_URL|${RESIZER_URL}|" workflow.yaml
sed -i -e "s|WATERMARKER_URL|${WATERMARKER_URL}|" workflow.yaml
Déployez le workflow :
WORKFLOW_NAME=image-processing
gcloud workflows deploy $WORKFLOW_NAME \
--source=workflow.yaml \
--location=$REGION
En quelques secondes, le workflow devrait s'afficher dans la console :
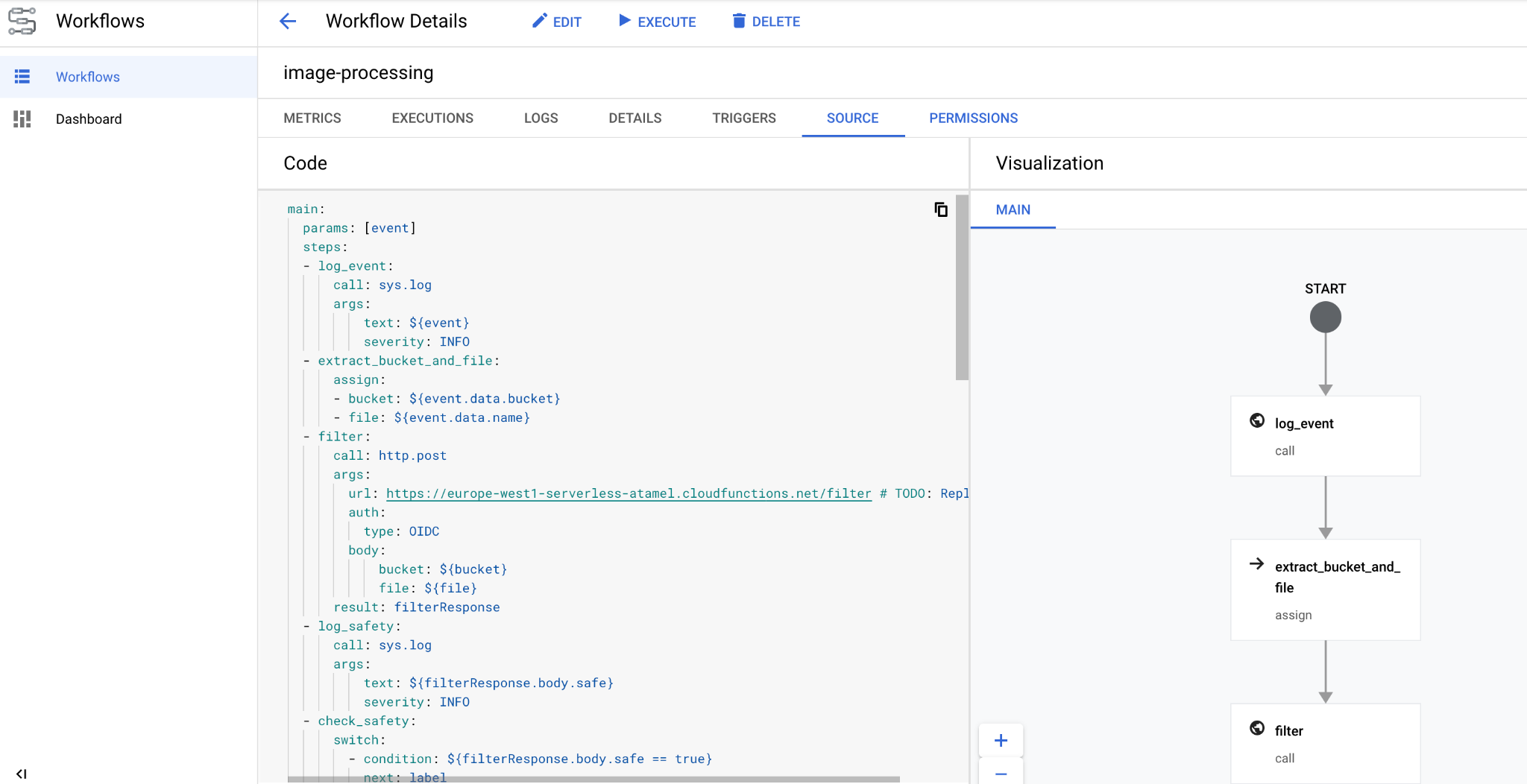
10. Créer un déclencheur
Maintenant que le workflow est déployé, la dernière étape consiste à le connecter aux événements Cloud Storage à l'aide d'un déclencheur Eventarc.
Configuration unique
Tout d'abord, activez les services requis pour Eventarc :
gcloud services enable \ eventarc.googleapis.com
Créez un compte de service que vous utiliserez dans le déclencheur Eventarc.
SERVICE_ACCOUNT=eventarc-trigger-imageproc-sa gcloud iam service-accounts create $SERVICE_ACCOUNT \ --display-name="Eventarc trigger image processing service account"
Attribuez le rôle workflows.invoker afin que le compte de service puisse être utilisé pour appeler des workflows depuis Eventarc :
gcloud projects add-iam-policy-binding $PROJECT_ID \ --role roles/workflows.invoker \ --member serviceAccount:$SERVICE_ACCOUNT@$PROJECT_ID.iam.gserviceaccount.com
Attribuez le rôle eventarc.eventReceiver au compte de service pour qu'il puisse être utilisé dans un
Déclencheur Cloud Storage :
gcloud projects add-iam-policy-binding $PROJECT_ID \ --role roles/eventarc.eventReceiver \ --member serviceAccount:$SERVICE_ACCOUNT@$PROJECT_ID.iam.gserviceaccount.com
Attribuez le rôle pubsub.publisher au compte de service Cloud Storage. Cela est nécessaire pour le déclencheur Cloud Storage d'Eventarc :
STORAGE_SERVICE_ACCOUNT="$(gsutil kms serviceaccount -p $PROJECT_ID)"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member serviceAccount:$STORAGE_SERVICE_ACCOUNT \
--role roles/pubsub.publisher
Créer
Exécutez la commande suivante pour créer un déclencheur. Ce déclencheur filtre les événements de création de fichiers à partir du bucket Cloud Storage d'entrée et les transmet au workflow que nous avons défini précédemment :
TRIGGER_NAME=trigger-image-processing gcloud eventarc triggers create $TRIGGER_NAME \ --location=$REGION \ --destination-workflow=$WORKFLOW_NAME \ --destination-workflow-location=$REGION \ --event-filters="type=google.cloud.storage.object.v1.finalized" \ --event-filters="bucket=$BUCKET1" \ --service-account=$SERVICE_ACCOUNT@$PROJECT_ID.iam.gserviceaccount.com
Vous pouvez voir que le déclencheur est créé et prêt à l'emploi dans la section Eventarc de la console Cloud :

11. Tester le pipeline
Le pipeline de traitement d'images est prêt à recevoir des événements de Cloud Storage. Pour tester le pipeline, importez une image dans le bucket d'entrée :
gsutil cp beach.jpg gs://$BUCKET1
Dès que vous importez l'image, une exécution de workflows devrait s'afficher à l'état actif :
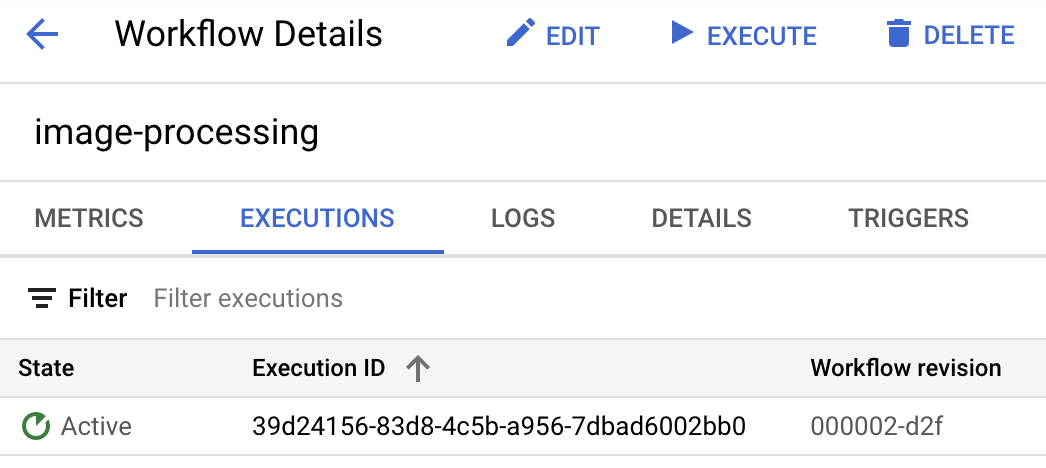
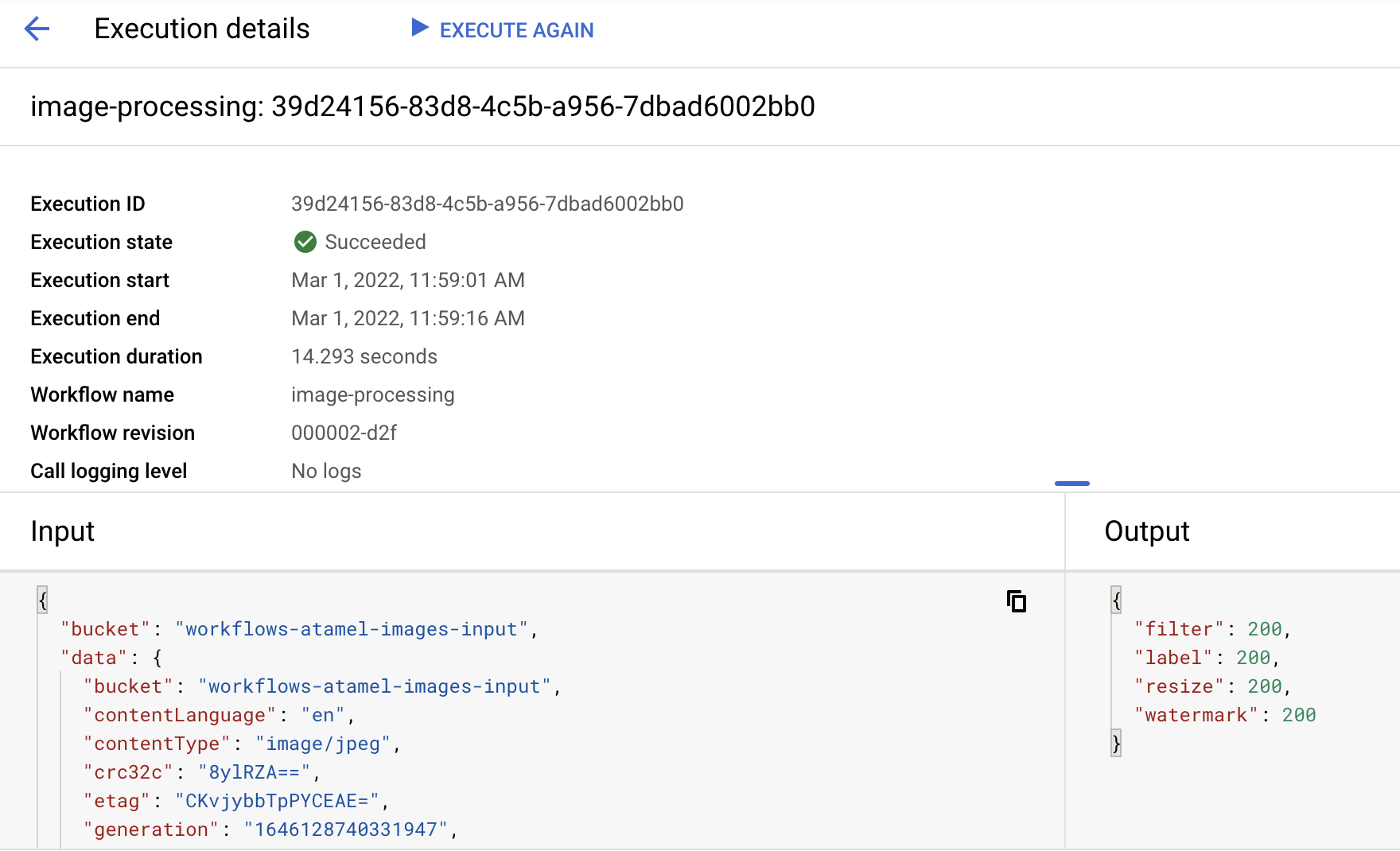
Après environ une minute, l'exécution devrait avoir réussi. Vous pouvez également voir l'entrée et la sortie du workflow :
Si vous listez le contenu du bucket de sortie, vous devriez voir l'image redimensionnée, l'image redimensionnée et filigranée, ainsi que les libellés de l'image :
gsutil ls gs://$BUCKET2 gs://$PROJECT_ID-images-output-$RANDOM/beach-400x400-watermark.jpeg gs://$PROJECT_ID-images-output-$RANDOM/beach-400x400.png gs://$PROJECT_ID-images-output-$RANDOM/beach-labels.txt
Pour vérifier, ouvrez l'image redimensionnée et en filigrane pour voir le résultat :

12. Félicitations
Félicitations, vous avez terminé cet atelier de programmation.
Points abordés
- Présentation d'Eventarc et de Workflows
- Déployer des services Cloud Functions
- Orchestrer des services à l'aide de Workflows
- Faire en sorte que Workflows réponde aux événements Cloud Storage avec Eventarc