
1. 概览
无服务器迁移站系列 Codelab(自定进度的动手教程)和相关视频旨在帮助 Google Cloud 无服务器开发者通过一次或多次迁移(主要是从旧版服务迁移)来指导他们的应用现代化。这样做可让您的应用更易于移植,并为您提供更多选择和灵活性,使您能够与更多 Cloud 产品集成并访问这些产品,还能更轻松地升级到新的语言版本。虽然最初侧重于最早的 Cloud 用户(主要是 App Engine [标准环境] 开发者),但本系列文章的范围足够广,可涵盖其他无服务器平台(例如 Cloud Functions 和 Cloud Run),或者其他平台(如果适用)。
本 Codelab 将介绍如何将 Module 1 Codelab 中的 示例应用与 App Engine 任务队列拉取任务搭配使用。我们在本模块 18 教程中添加了对拉取任务的使用,然后在模块 19 中将该使用迁移到 Cloud Pub/Sub。如果使用 Task Queues 处理推送任务,则应改用 Cloud Tasks,并参阅模块 7-9。
在接下来的实验中
- 使用 App Engine 任务队列 API/捆绑服务
- 向基本的 Python 2 Flask App Engine NDB 应用添加拉取队列使用情况
所需条件
- 具有有效的 GCP 结算账号的 Google Cloud Platform 项目
- 基本 Python 技能
- 常用 Linux 命令的实践知识
- 具备开发和部署 App Engine 应用的基础知识
- 有效的模块 1 App Engine 应用(完成其 Codelab [推荐] 或从代码库复制应用)
调查问卷
您将如何使用本教程?
您如何评价使用 Python 的体验?
您如何评价自己在使用 Google Cloud 服务方面的经验水平?
2. 背景
为了从 App Engine 任务队列拉取任务进行迁移,请将相应用法添加到 模块 1 Codelab 中生成的现有 Flask 和 App Engine NDB 应用。示例应用会向最终用户显示最近的访问记录。这当然没问题,但如果还能跟踪访问者,看看谁的访问次数最多,那就更有趣了。
虽然我们可以使用 推送任务来处理这些访问者计数,但我们希望在负责注册访问次数并立即响应用户的示例应用与负责在正常请求-响应工作流之外统计访问者计数的指定“工作器”之间分摊责任。
为了实现此设计,我们正在向主应用添加对拉取队列的使用,并支持 worker 功能。工作器可以作为单独的进程(例如后端实例或始终在运行的虚拟机上的代码)、Cron 作业或使用 curl 或 wget 的基本命令行 HTTP 请求来运行。完成此集成后,您可以在下一个 Codelab(模块 19)中将应用迁移到 Cloud Pub/Sub。
本教程包含以下步骤:
- 设置/准备工作
- 更新配置
- 修改应用代码
3. 设置/准备工作
本节介绍如何执行以下操作:
- 设置 Cloud 项目
- 获取基准示例应用
- (重新)部署并验证基准应用
这些步骤可确保您从正常运行的代码开始。
1. 设置项目
如果您已完成模块 1 Codelab,请重复使用同一项目(和代码)。或者,您可以创建一个全新的项目或重复使用另一个现有项目。确保该项目具有有效的结算账号,并且已启用 App Engine 应用。找到您的项目 ID,因为在本 Codelab 中您需要多次用到它,并且每当遇到 PROJECT_ID 变量时都要使用它。
2. 获取基准示例应用
此 Codelab 的前提条件之一是拥有一个有效的工作模块 1 App Engine 应用。完成模块 1 Codelab(推荐)或从代码库复制模块 1 应用。无论您是使用自己的代码还是我们的代码,我们都能在模块 1 中“开始”。本 Codelab 将引导您完成每个步骤,最终获得类似于模块 18 代码库文件夹“FINISH”中的代码。
无论您使用哪个模块 1 应用,该文件夹都应类似于以下输出,可能还包含 lib 文件夹:
$ ls README.md appengine_config.py requirements.txt app.yaml main.py templates
3. (重新)部署基准应用
执行以下步骤来部署模块 1 应用:
- 删除
lib文件夹(如果有),然后运行pip install -t lib -r requirements.txt以重新填充lib。如果您同时安装了 Python 2 和 3,可能需要改用pip2命令。 - 确保您已安装并初始化
gcloud命令行工具,并已查看其用法。 - 如果您不想在每次发出
gcloud命令时都输入PROJECT_ID,请使用gcloud config set projectPROJECT_ID设置您的云项目。 - 使用
gcloud app deploy部署示例应用 - 确认模块 1 应用按预期运行并显示最近的访问(如下所示)
4. 更新配置
无需对标准 App Engine 配置文件(app.yaml、requirements.txt、appengine_config.py)进行任何更改。只需添加一个新配置文件 queue.yaml,其中包含以下内容,并将其放在同一顶级目录中:
queue:
- name: pullq
mode: pull
queue.yaml 文件用于指定应用的所有任务队列(default [推送] 队列除外,该队列由 App Engine 自动创建)。在本例中,只有一个拉取队列,名为 pullq。App Engine 要求将 mode 指令指定为 pull,否则默认情况下会创建推送队列。如需详细了解如何创建拉取队列,请参阅文档。另请参阅 queue.yaml 参考页面,了解其他选项。
单独部署此文件,而不是与应用一起部署。您仍将使用 gcloud app deploy,但也会在命令行中提供 queue.yaml:
$ gcloud app deploy queue.yaml Configurations to update: descriptor: [/tmp/mod18-gaepull/queue.yaml] type: [task queues] target project: [my-project] WARNING: Caution: You are updating queue configuration. This will override any changes performed using 'gcloud tasks'. More details at https://cloud.google.com/tasks/docs/queue-yaml Do you want to continue (Y/n)? Updating config [queue]...⠹WARNING: We are using the App Engine app location (us-central1) as the default location. Please use the "--location" flag if you want to use a different location. Updating config [queue]...done. Task queues have been updated. Visit the Cloud Platform Console Task Queues page to view your queues and cron jobs. $
5. 修改应用代码
此部分包含以下文件的更新:
main.py- 向主应用添加了拉取队列的使用templates/index.html- 更新 Web 模板以显示新数据
导入和常量
第一步是添加一项新的导入和多个常量,以支持拉取队列:
- 添加对 Task Queue 库 (
google.appengine.api.taskqueue) 的导入。 - 添加了三个常量,以支持从拉取队列 (
QUEUE) 租用一小时 (HOUR) 的最大拉取任务数 (TASKS)。 - 添加一个用于显示最近访问者以及热门访问者的常量 (
LIMIT)。
以下是原始代码以及在进行这些更新后的代码:
之前:
from flask import Flask, render_template, request
from google.appengine.ext import ndb
app = Flask(__name__)
升级后:
from flask import Flask, render_template, request
from google.appengine.api import taskqueue
from google.appengine.ext import ndb
HOUR = 3600
LIMIT = 10
TASKS = 1000
QNAME = 'pullq'
QUEUE = taskqueue.Queue(QNAME)
app = Flask(__name__)
添加拉取任务(收集任务数据并在拉取队列中创建任务)
数据模型 Visit 保持不变,在 fetch_visits() 中显示访问次数的查询也保持不变。此部分代码中唯一需要更改的是 store_visit()。除了注册访问之外,还需向拉取队列添加一项包含访问者 IP 地址的任务,以便工作器可以递增访问者计数器。
之前:
class Visit(ndb.Model):
'Visit entity registers visitor IP address & timestamp'
visitor = ndb.StringProperty()
timestamp = ndb.DateTimeProperty(auto_now_add=True)
def store_visit(remote_addr, user_agent):
'create new Visit entity in Datastore'
Visit(visitor='{}: {}'.format(remote_addr, user_agent)).put()
def fetch_visits(limit):
'get most recent visits'
return Visit.query().order(-Visit.timestamp).fetch(limit)
升级后:
class Visit(ndb.Model):
'Visit entity registers visitor IP address & timestamp'
visitor = ndb.StringProperty()
timestamp = ndb.DateTimeProperty(auto_now_add=True)
def store_visit(remote_addr, user_agent):
'create new Visit in Datastore and queue request to bump visitor count'
Visit(visitor='{}: {}'.format(remote_addr, user_agent)).put()
QUEUE.add(taskqueue.Task(payload=remote_addr, method='PULL'))
def fetch_visits(limit):
'get most recent visits'
return Visit.query().order(-Visit.timestamp).fetch(limit)
为访问者跟踪创建数据模型和查询函数
添加一个数据模型 VisitorCount 以跟踪访问者;该模型应包含 visitor 本身的字段以及一个用于跟踪访问次数的整数 counter。然后,添加一个名为 fetch_counts() 的新函数(也可以是 Python classmethod),用于查询并按从多到少的顺序返回热门访问者。在 fetch_visits() 的正文下方添加类和函数:
class VisitorCount(ndb.Model):
visitor = ndb.StringProperty(repeated=False, required=True)
counter = ndb.IntegerProperty()
def fetch_counts(limit):
'get top visitors'
return VisitCount.query().order(-VisitCount.counter).fetch(limit)
添加工作者代码
添加一个新函数 log_visitors(),以通过向 /log 发送 GET 请求来记录访问者。它使用字典/哈希来跟踪最近的访问者数量,并尽可能多地租用任务一小时。对于每个任务,它会统计同一访问者的所有访问次数。获得统计数据后,应用会更新 Datastore 中所有对应的 VisitorCount 实体,或根据需要创建新实体。最后一步会返回一条纯文本消息,其中指明了有多少访问者通过多少已处理的任务进行了注册。将此函数添加到 main.py 中的 fetch_counts() 正下方:
@app.route('/log')
def log_visitors():
'worker processes recent visitor counts and updates them in Datastore'
# tally recent visitor counts from queue then delete those tasks
tallies = {}
tasks = QUEUE.lease_tasks(HOUR, TASKS)
for task in tasks:
visitor = task.payload
tallies[visitor] = tallies.get(visitor, 0) + 1
if tasks:
QUEUE.delete_tasks(tasks)
# increment those counts in Datastore and return
for visitor in tallies:
counter = VisitorCount.query(VisitorCount.visitor == visitor).get()
if not counter:
counter = VisitorCount(visitor=visitor, counter=0)
counter.put()
counter.counter += tallies[visitor]
counter.put()
return 'DONE (with %d task[s] logging %d visitor[s])\r\n' % (
len(tasks), len(tallies))
使用新的显示数据更新了主处理程序
如需显示热门访问者,请更新主处理程序 root() 以调用 fetch_counts()。此外,该模板还将更新为显示热门访问者的数量和最近的访问次数。将访问者数量与对 fetch_visits() 的调用的最新访问记录打包在一起,然后将其放入单个 context 中以传递给 Web 模板。以下是进行此项更改前后的代码:
之前:
@app.route('/')
def root():
'main application (GET) handler'
store_visit(request.remote_addr, request.user_agent)
visits = fetch_visits(10)
return render_template('index.html', visits=visits)
升级后:
@app.route('/')
def root():
'main application (GET) handler'
store_visit(request.remote_addr, request.user_agent)
context = {
'limit': LIMIT,
'visits': fetch_visits(LIMIT),
'counts': fetch_counts(LIMIT),
}
return render_template('index.html', **context)
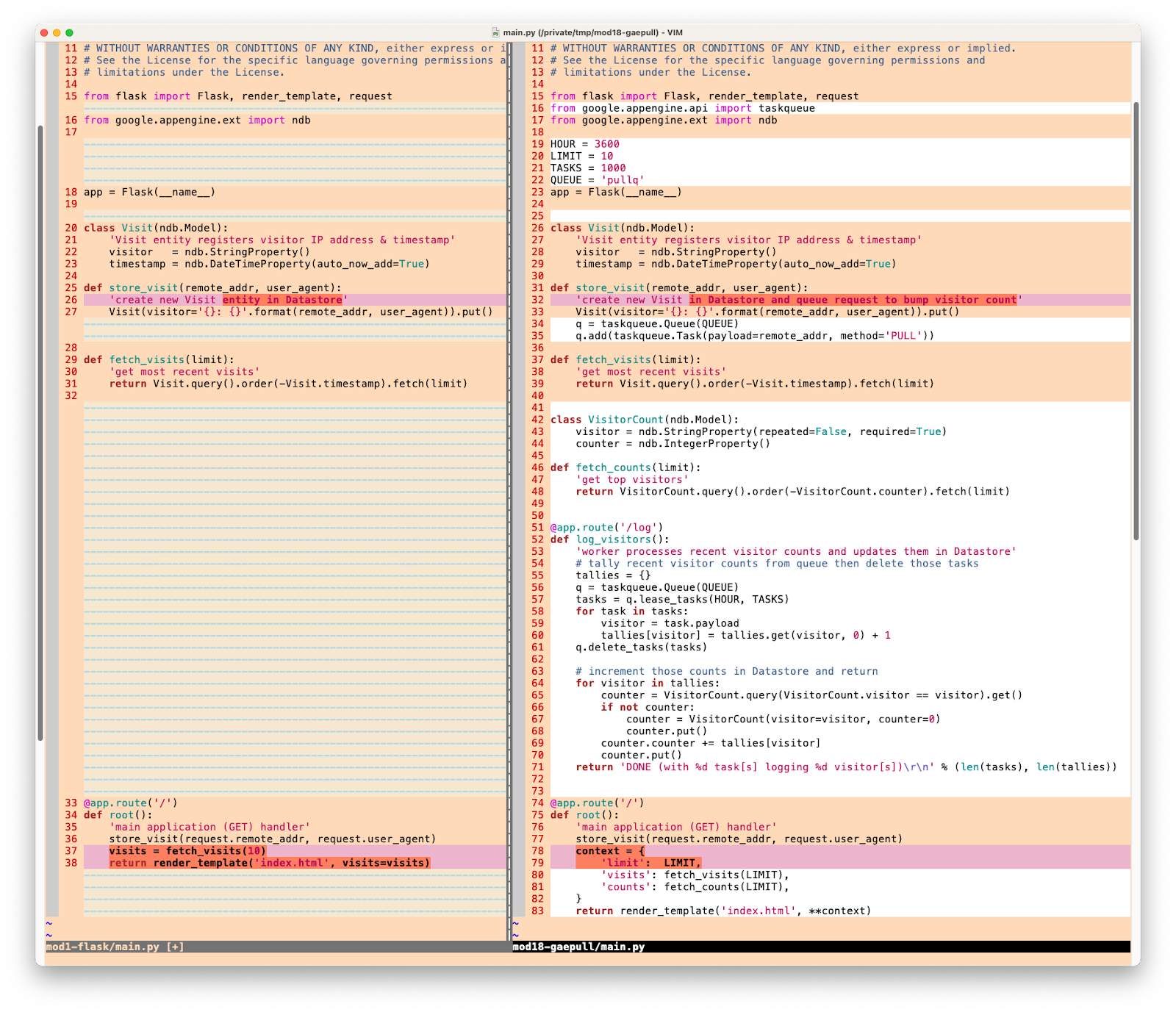
以上是 main.py 所需的所有更改,下图以图示方式展示了这些更新,以便您大致了解您对 main.py 所做的更改:
使用新的展示数据更新网页模板
除了最近访问者的常规载荷之外,网页模板 templates/index.html 还需要更新才能显示热门访问者。将热门访问者及其访问次数放入页面顶部的表格中,并继续像以前一样呈现最近的访问。唯一其他更改是,通过 limit 变量指定显示的数字,而不是对数字进行硬编码。您应按以下说明更新网页模板:
之前:
<!doctype html>
<html>
<head>
<title>VisitMe Example</title>
<body>
<h1>VisitMe example</h1>
<h3>Last 10 visits</h3>
<ul>
{% for visit in visits %}
<li>{{ visit.timestamp.ctime() }} from {{ visit.visitor }}</li>
{% endfor %}
</ul>
升级后:
<!doctype html>
<html>
<head>
<title>VisitMe Example</title>
<body>
<h1>VisitMe example</h1>
<h3>Top {{ limit }} visitors</h3>
<table border=1 cellspacing=0 cellpadding=2>
<tr><th>Visitor</th><th>Visits</th></tr>
{% for count in counts %}
<tr><td>{{ count.visitor|e }}</td><td align="center">{{ count.counter }}</td></tr>
{% endfor %}
</table>
<h3>Last {{ limit }} visits</h3>
<ul>
{% for visit in visits %}
<li>{{ visit.timestamp.ctime() }} from {{ visit.visitor }}</li>
{% endfor %}
</ul>
至此,我们已完成必要的更改,将 App Engine 任务队列拉取任务的使用添加到模块 1 示例应用中。您的目录现在表示模块 18 示例应用,应包含以下文件:
$ ls README.md appengine_config.py queue.yaml templates app.yaml main.py requirements.txt
6. 总结/清理
本部分将通过部署应用来结束此 Codelab,并验证应用是否按预期运行以及是否在任何反映的输出中正常运行。单独运行工作器以处理访问者数量。应用验证完成后,执行任何清理步骤,并考虑后续步骤。
部署并验证应用
请确保您已设置拉取队列,就像我们在本 Codelab 顶部附近使用 gcloud app deploy queue.yaml 所做的那样。如果已完成上述操作,并且您的示例应用已准备就绪,请使用 gcloud app deploy 部署应用。输出应与模块 1 应用相同,只是现在顶部会显示“热门访问者”表格:
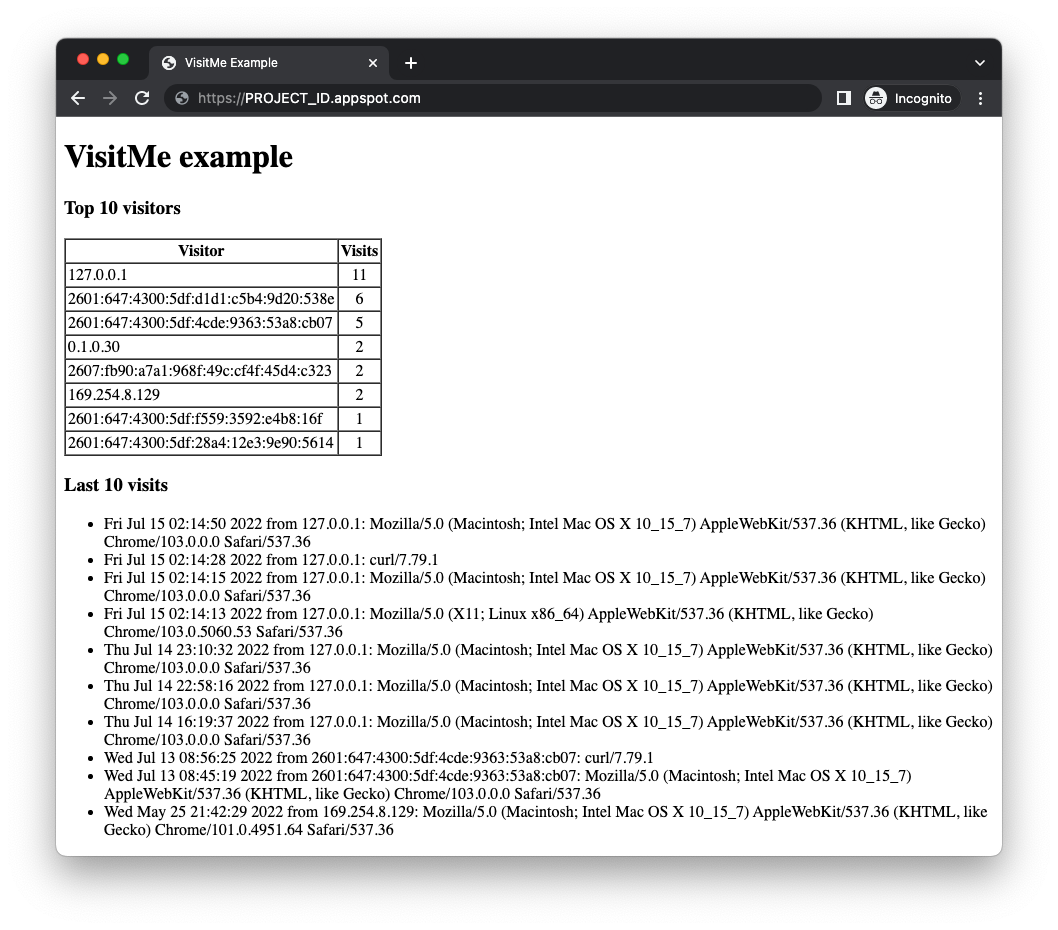
虽然更新后的 Web 前端会显示热门访问者和最近的访问者,但请注意,访问者人数不包括本次访问。应用会显示之前的访问者数量,同时在拉取队列中放置一个新任务,用于递增此访问者的数量(该任务正在等待处理)。
您可以通过多种方式调用 /log 来执行任务:
例如,如果您使用 curl 向 /log 发送 GET 请求,则在您提供 PROJECT_ID 的情况下,输出将如下所示:
$ curl https://PROJECT_ID.appspot.com/log DONE (with 1 task[s] logging 1 visitor[s])
然后,更新后的数量会在您下次访问网站时显示。大功告成!
恭喜您成功完成此 Codelab,为示例应用添加了对 App Engine 任务队列拉取队列服务的使用。现在,它已准备好在模块 19 中迁移到 Cloud Pub/Sub、Cloud NDB 和 Python 3。
清理
常规
如果您暂时不想继续操作,建议您停用 App Engine 应用,以免产生结算费用。不过,如果您想进一步测试或实验,App Engine 平台有免费配额,因此只要您不超过该使用层级,就不会产生费用。这是计算费用,但相关 App Engine 服务也可能会产生费用,因此请查看其价格页面了解详情。如果此迁移涉及其他 Cloud 服务,则这些服务会单独计费。在任何一种情况下,如果适用,请参阅下文中的“本 Codelab 特有的问题”部分。
为了完全公开透明,我们在此说明,部署到 Google Cloud 无服务器计算平台(例如 App Engine)会产生少量 build 和存储费用。Cloud Build 和 Cloud Storage 都有各自的免费配额。存储该图片会占用部分配额。不过,您可能居住在没有此类免费层的地区,因此请注意存储空间用量,以尽可能减少潜在费用。您应查看的特定 Cloud Storage“文件夹”包括:
console.cloud.google.com/storage/browser/LOC.artifacts.PROJECT_ID.appspot.com/containers/imagesconsole.cloud.google.com/storage/browser/staging.PROJECT_ID.appspot.com- 上述存储链接取决于您的
PROJECT_ID和 *LOC*ation,例如,如果您的应用托管在美国,则为“us”。
另一方面,如果您不打算继续学习此应用或其他相关迁移 Codelab,并且想要彻底删除所有内容,请关闭您的项目。
此 Codelab 特有的
以下列出的服务是此 Codelab 特有的。如需了解详情,请参阅各个产品的文档:
- 根据旧版捆绑式服务(例如任务队列)的价格页面,App Engine 任务队列服务不会产生任何额外费用。
- App Engine Datastore 服务由 Cloud Datastore(Datastore 模式的 Cloud Firestore)提供,后者也提供免费层级;如需了解详情,请参阅其价格页面。
后续步骤
在此“迁移”中,您通过添加对跟踪访问者的支持,为模块 1 示例应用添加了任务队列推送队列使用情况,从而实现了模块 18 示例应用。在下一次迁移中,您将把 App Engine 拉取任务升级到 Cloud Pub/Sub。自 2021 年末起,用户在升级到 Python 3 时不再需要迁移到 Cloud Pub/Sub。如需详细了解,请参阅下一部分。
如需了解如何迁移到 Cloud Pub/Sub,请参阅模块 19 的 Codelab。除此之外,您还需要考虑其他迁移,例如 Cloud Datastore、Cloud Memorystore、Cloud Storage 或 Cloud Tasks(推送队列)。此外,还可以跨产品迁移到 Cloud Run 和 Cloud Functions。您可以在 开源代码库中访问所有无服务器迁移站内容(Codelab、视频、源代码 [如有])。
7. 迁移到 Python 3
2021 年秋季,App Engine 团队将许多捆绑服务的支持范围扩展到第二代运行时(具有第一代运行时)。因此,在将应用移植到 Python 3 时,您不再需要从 App Engine Task Queue 等捆绑服务迁移到 Cloud Pub/Sub 等独立 Cloud 服务或第三方服务。换句话说,只要您改造代码以从新一代运行时访问捆绑服务,就可以继续在 Python 3 App Engine 应用中使用任务队列。
您可以在模块 17 Codelab 及其对应的视频中详细了解如何将捆绑服务使用情况迁移到 Python 3。虽然该主题不在模块 18 的范围内,但下面链接的是模块 1 应用的 Python 3 版本,该版本已移植到 Python 3,但仍在使用 App Engine NDB。(在某个时间点,我们还会提供模块 18 应用的 Python 3 版本。)
8. 其他资源
下面列出了其他资源,可供开发者进一步探索本迁移模块或相关迁移模块以及相关产品。这包括提供有关此内容的反馈的途径、指向代码的链接,以及您可能会觉得有用的各种文档。
Codelab 问题/反馈
如果您发现本 Codelab 存在任何问题,请先搜索您的问题,然后再提交。用于搜索和创建新问题的链接:
迁移时可参考的资源
下表中提供了指向模块 1 (START) 和模块 18 (FINISH) 的代码库文件夹的链接。您还可以从所有 App Engine Codelab 迁移的代码库中访问这些文件;克隆该代码库或下载 ZIP 文件。
Codelab | Python 2 | Python 3 |
代码(本教程中未介绍) | ||
模块 18(本 Codelab) | 不适用 |
在线参考
以下是与本教程相关的资源:
App Engine Task Queue
- App Engine Task Queue 概览
- App Engine 任务队列拉取队列概览
- App Engine Task Queue 拉取队列完整示例应用
- 创建任务队列拉取队列
- Google I/O 2011 拉取队列发布视频(Votelator 示例应用)
queue.yaml参考文档queue.yaml与 Cloud Tasks- 将拉取队列迁移到 Pub/Sub 的指南
- App Engine 任务队列拉取队列到 Cloud Pub/Sub 文档示例
App Engine 平台
App Engine 文档
Python 2 App Engine(标准环境)运行时
Python 3 App Engine(标准环境)运行时
Python 2 和 3 App Engine(标准环境)运行时之间的差异
Python 2 到 3 App Engine(标准环境)迁移指南
App Engine 价格和配额信息
第二代 App Engine 平台发布 (2018)
对旧版运行时的长期支持
文档迁移示例
其他云信息
- 在 Google Cloud Platform 上使用 Python 应用
- Google Cloud Python 客户端库
- Google Cloud“始终免费”层级
- Google Cloud SDK(
gcloud命令行工具) - 所有 Google Cloud 文档
视频
许可
此作品已获得 Creative Commons Attribution 2.0 通用许可授权。