
1. Przegląd
Seria codelabów Serverless Migration Station (samodzielne, praktyczne samouczki) i powiązane z nimi filmy mają na celu pomóc deweloperom usług bezserwerowych Google Cloud w modernizacji aplikacji poprzez przeprowadzenie ich przez co najmniej jedną migrację, głównie z usług starszego typu. Dzięki temu Twoje aplikacje będą bardziej przenośne, a Ty zyskasz więcej opcji i elastyczności, co umożliwi Ci integrację z szerszą gamą usług w chmurze i łatwiejsze przechodzenie na nowsze wersje języka. Chociaż początkowo skupialiśmy się na pierwszych użytkownikach usług w chmurze, głównie na deweloperach App Engine (środowisko standardowe), ta seria jest wystarczająco szeroka, aby obejmować inne platformy bezserwerowe, takie jak Cloud Functions i Cloud Run, lub inne, jeśli ma to zastosowanie.
Z tych ćwiczeń z programowania dowiesz się, jak w przykładowej aplikacji z ćwiczeń z programowania w module 1 uwzględnić i wykorzystać zadania typu pull w kolejce zadań App Engine. W tym samouczku (moduł 18) dodamy użycie zadań pull, a w module 19 przeniesiemy to użycie do Cloud Pub/Sub. Użytkownicy, którzy korzystają z kolejek zadań do zadań push, powinni zamiast tego przejść na Cloud Tasks i zapoznać się z modułami 7–9.
Dowiesz się, jak:
- Korzystanie z interfejsu API kolejki zadań App Engine lub usługi pakietowej
- Dodawanie użycia kolejki pull do podstawowej aplikacji w Pythonie 2 Flask App Engine NDB
Czego potrzebujesz
- projekt Google Cloud Platform z aktywnym kontem rozliczeniowym GCP;
- podstawowe umiejętności w zakresie Pythona,
- Praktyczna znajomość typowych poleceń systemu Linux
- Podstawowa wiedza na temat tworzenia i wdrażania aplikacji App Engine.
- Działająca aplikacja App Engine z modułu 1 (wykonaj ćwiczenia [zalecane] lub skopiuj aplikację z repozytorium).
Ankieta
Jak zamierzasz korzystać z tego samouczka?
Jak oceniasz swoje doświadczenie z Pythonem?
Jak oceniasz korzystanie z usług Google Cloud?
2. Tło
Aby przeprowadzić migrację z zadań pull w kolejce zadań App Engine, dodaj ich użycie do istniejącej aplikacji Flask i App Engine NDB, która powstała w wyniku wykonania ćwiczenia z modułu 1. Przykładowa aplikacja wyświetla użytkownikowi końcowemu najnowsze wizyty. To dobrze, ale jeszcze ciekawsze jest śledzenie odwiedzających, aby sprawdzić, kto najczęściej odwiedza Twoją stronę.
Do zliczania odwiedzających moglibyśmy użyć zadań push, ale chcemy podzielić odpowiedzialność między przykładową aplikację, której zadaniem jest rejestrowanie wizyt i natychmiastowe odpowiadanie użytkownikom, a wyznaczonego „pracownika”, którego zadaniem jest zliczanie odwiedzających poza normalnym przepływem pracy związanym z odpowiedzią na żądanie.
Aby wdrożyć ten projekt, dodajemy do głównej aplikacji korzystanie z kolejek pobierania, a także obsługę funkcji roboczej. Proces roboczy może działać jako osobny proces (np. instancja backendu lub kod działający na maszynie wirtualnej, która jest zawsze włączona), zadanie cron lub podstawowe żądanie HTTP w wierszu poleceń za pomocą curl lub wget. Po tej integracji możesz przenieść aplikację do Cloud Pub/Sub w kolejnych zajęciach z programowania (moduł 19).
Ten samouczek obejmuje te kroki:
- Konfiguracja/przygotowanie
- Aktualizacja konfiguracji
- Modyfikowanie kodu aplikacji
3. Konfiguracja/przygotowanie
Z tej sekcji dowiesz się, jak:
- Konfigurowanie projektu w chmurze
- Pobieranie przykładowej aplikacji podstawowej
- (Ponowne) wdrażanie i weryfikowanie aplikacji podstawowej
Dzięki tym czynnościom masz pewność, że zaczynasz od działającego kodu.
1. Konfigurowanie projektu
Jeśli masz za sobą ćwiczenie z programowania w module 1, użyj tego samego projektu (i kodu). Możesz też utworzyć zupełnie nowy projekt lub użyć innego istniejącego projektu. Upewnij się, że projekt ma aktywne konto rozliczeniowe i włączoną aplikację App Engine. Znajdź identyfikator projektu, ponieważ będzie on potrzebny kilka razy w tym laboratorium. Używaj go zawsze, gdy napotkasz zmienną PROJECT_ID.
2. Pobieranie przykładowej aplikacji podstawowej
Jednym z wymagań wstępnych tego modułu jest działająca aplikacja App Engine z modułu 1. Wykonaj moduł 1 (zalecane) lub skopiuj aplikację z modułu 1 z repozytorium. Niezależnie od tego, czy używasz własnego kodu, czy naszego, kod modułu 1 to miejsce, w którym „ZACZNIEMY”. W tym Codelabs znajdziesz instrukcje krok po kroku, a na końcu kod podobny do tego, który znajduje się w folderze „FINISH” w Repo modułu 18.
- START: Folder modułu 1 (Python 2)
- ZAKOŃCZ: Folder modułu 18 (Python 2)
- Całe repozytorium (do sklonowania lub pobrania pliku ZIP)
Niezależnie od tego, której aplikacji z modułu 1 używasz, folder powinien wyglądać jak poniżej. Może też zawierać folder lib:
$ ls README.md appengine_config.py requirements.txt app.yaml main.py templates
3. (Ponowne) wdrażanie aplikacji bazowej
Aby wdrożyć aplikację z modułu 1, wykonaj te czynności:
- Usuń folder
lib, jeśli istnieje, i uruchom polecenie:pip install -t lib -r requirements.txt, aby ponownie wypełnić folderlib. Jeśli masz zainstalowane obie wersje Pythona (2 i 3), może być konieczne użycie poleceniapip2. - Sprawdź, czy narzędzie wiersza poleceń
gcloudzostało zainstalowane i zainicjowane oraz czy znasz sposób jego użycia. - Ustaw projekt w chmurze za pomocą polecenia
gcloud config set projectPROJECT_ID, jeśli nie chcesz wpisywaćPROJECT_IDprzy każdym wydaniu poleceniagcloud. - Wdrażanie przykładowej aplikacji za pomocą
gcloud app deploy - Sprawdź, czy aplikacja Moduł 1 działa zgodnie z oczekiwaniami i wyświetla najnowsze wizyty (jak na ilustracji poniżej).
4. Aktualizacja konfiguracji
Nie musisz wprowadzać żadnych zmian w standardowych plikach konfiguracyjnych App Engine (app.yaml, requirements.txt, appengine_config.py). Zamiast tego dodaj nowy plik konfiguracyjny queue.yaml o tej treści, umieszczając go w tym samym katalogu najwyższego poziomu:
queue:
- name: pullq
mode: pull
Plik queue.yaml określa wszystkie kolejki zadań, które istnieją w Twojej aplikacji (z wyjątkiem kolejki default [push], która jest automatycznie tworzona przez App Engine). W tym przypadku jest tylko jedna kolejka pull o nazwie pullq. App Engine wymaga, aby dyrektywa mode była określona jako pull. W przeciwnym razie domyślnie tworzy kolejkę push. Więcej informacji o tworzeniu kolejek pobierania znajdziesz w dokumentacji. Inne opcje znajdziesz też na queue.yamlstronie referencyjnej.
Wdróż ten plik oddzielnie od aplikacji. Nadal będziesz używać polecenia gcloud app deploy, ale w wierszu poleceń musisz też podać queue.yaml:
$ gcloud app deploy queue.yaml Configurations to update: descriptor: [/tmp/mod18-gaepull/queue.yaml] type: [task queues] target project: [my-project] WARNING: Caution: You are updating queue configuration. This will override any changes performed using 'gcloud tasks'. More details at https://cloud.google.com/tasks/docs/queue-yaml Do you want to continue (Y/n)? Updating config [queue]...⠹WARNING: We are using the App Engine app location (us-central1) as the default location. Please use the "--location" flag if you want to use a different location. Updating config [queue]...done. Task queues have been updated. Visit the Cloud Platform Console Task Queues page to view your queues and cron jobs. $
5. Modyfikowanie kodu aplikacji
W tej sekcji znajdziesz aktualizacje tych plików:
main.py– dodanie do głównej aplikacji możliwości korzystania z kolejek pull.templates/index.html– zaktualizuj szablon internetowy, aby wyświetlać nowe dane.
Importy i stałe
Pierwszym krokiem jest dodanie jednego nowego importu i kilku stałych do obsługi kolejek pobierania:
- Dodaj import biblioteki kolejki zadań
google.appengine.api.taskqueue. - Dodaj 3 stałe, aby obsługiwać wypożyczanie maksymalnej liczby zadań typu pull (
TASKS) na godzinę (HOUR) z naszej kolejki pull (QUEUE). - Dodaj stałą, aby wyświetlać najnowsze wizyty oraz najważniejszych użytkowników (
LIMIT).
Poniżej znajdziesz oryginalny kod i jego wygląd po wprowadzeniu tych zmian:
PRZED:
from flask import Flask, render_template, request
from google.appengine.ext import ndb
app = Flask(__name__)
PO:
from flask import Flask, render_template, request
from google.appengine.api import taskqueue
from google.appengine.ext import ndb
HOUR = 3600
LIMIT = 10
TASKS = 1000
QNAME = 'pullq'
QUEUE = taskqueue.Queue(QNAME)
app = Flask(__name__)
Dodawanie zadania typu pull (zbieranie danych do zadania i tworzenie zadania w kolejce typu pull)
Model danych Visit pozostaje taki sam, podobnie jak zapytania o wizyty, które mają być wyświetlane w fetch_visits(). Jedyna zmiana wymagana w tej części kodu dotyczy store_visit(). Oprócz zarejestrowania wizyty dodaj do kolejki pull zadanie z adresem IP odwiedzającego, aby instancja robocza mogła zwiększyć licznik odwiedzających.
PRZED:
class Visit(ndb.Model):
'Visit entity registers visitor IP address & timestamp'
visitor = ndb.StringProperty()
timestamp = ndb.DateTimeProperty(auto_now_add=True)
def store_visit(remote_addr, user_agent):
'create new Visit entity in Datastore'
Visit(visitor='{}: {}'.format(remote_addr, user_agent)).put()
def fetch_visits(limit):
'get most recent visits'
return Visit.query().order(-Visit.timestamp).fetch(limit)
PO:
class Visit(ndb.Model):
'Visit entity registers visitor IP address & timestamp'
visitor = ndb.StringProperty()
timestamp = ndb.DateTimeProperty(auto_now_add=True)
def store_visit(remote_addr, user_agent):
'create new Visit in Datastore and queue request to bump visitor count'
Visit(visitor='{}: {}'.format(remote_addr, user_agent)).put()
QUEUE.add(taskqueue.Task(payload=remote_addr, method='PULL'))
def fetch_visits(limit):
'get most recent visits'
return Visit.query().order(-Visit.timestamp).fetch(limit)
Tworzenie modelu danych i funkcji zapytań na potrzeby śledzenia użytkowników
Dodaj model danych VisitorCount, aby śledzić użytkowników. Powinien on zawierać pola dla samego visitor, a także liczbę całkowitą counter do śledzenia liczby wizyt. Następnie dodaj nową funkcję (może to być też funkcja Pythona classmethod) o nazwie fetch_counts(), która będzie wyszukiwać i zwracać najważniejszych użytkowników w kolejności od największej do najmniejszej liczby wizyt. Dodaj klasę i funkcję bezpośrednio pod treścią fetch_visits():
class VisitorCount(ndb.Model):
visitor = ndb.StringProperty(repeated=False, required=True)
counter = ndb.IntegerProperty()
def fetch_counts(limit):
'get top visitors'
return VisitCount.query().order(-VisitCount.counter).fetch(limit)
Dodawanie kodu instancji roboczej
Dodaj nową funkcję log_visitors(), aby rejestrować odwiedzających za pomocą żądania GET do /log. Korzysta ze słownika lub funkcji skrótu, aby śledzić najnowsze liczby odwiedzających, i przez godzinę wykonuje jak najwięcej zadań. W przypadku każdego zadania zlicza wszystkie wizyty tego samego użytkownika. Po zebraniu danych aplikacja aktualizuje wszystkie odpowiednie elementy VisitorCount, które są już w Datastore, lub w razie potrzeby tworzy nowe. Ostatni krok zwraca wiadomość w formie zwykłego tekstu, która informuje, ilu użytkowników zarejestrowało się w ramach ilu przetworzonych zadań. Dodaj tę funkcję do main.py bezpośrednio pod fetch_counts():
@app.route('/log')
def log_visitors():
'worker processes recent visitor counts and updates them in Datastore'
# tally recent visitor counts from queue then delete those tasks
tallies = {}
tasks = QUEUE.lease_tasks(HOUR, TASKS)
for task in tasks:
visitor = task.payload
tallies[visitor] = tallies.get(visitor, 0) + 1
if tasks:
QUEUE.delete_tasks(tasks)
# increment those counts in Datastore and return
for visitor in tallies:
counter = VisitorCount.query(VisitorCount.visitor == visitor).get()
if not counter:
counter = VisitorCount(visitor=visitor, counter=0)
counter.put()
counter.counter += tallies[visitor]
counter.put()
return 'DONE (with %d task[s] logging %d visitor[s])\r\n' % (
len(tasks), len(tallies))
Aktualizowanie głównego modułu obsługi nowymi danymi wyświetlania
Aby wyświetlić najważniejszych gości, zaktualizuj główny moduł obsługi root(), aby wywołać fetch_counts(). Ponadto szablon zostanie zaktualizowany, aby wyświetlać liczbę najważniejszych i najnowszych wizyt. Spakuj liczbę odwiedzających wraz z najnowszymi wizytami z wywołania funkcji fetch_visits() i umieść je w jednym obiekcie context, aby przekazać go do szablonu internetowego. Poniżej znajdziesz kod przed wprowadzeniem tej zmiany i po niej:
PRZED:
@app.route('/')
def root():
'main application (GET) handler'
store_visit(request.remote_addr, request.user_agent)
visits = fetch_visits(10)
return render_template('index.html', visits=visits)
PO:
@app.route('/')
def root():
'main application (GET) handler'
store_visit(request.remote_addr, request.user_agent)
context = {
'limit': LIMIT,
'visits': fetch_visits(LIMIT),
'counts': fetch_counts(LIMIT),
}
return render_template('index.html', **context)
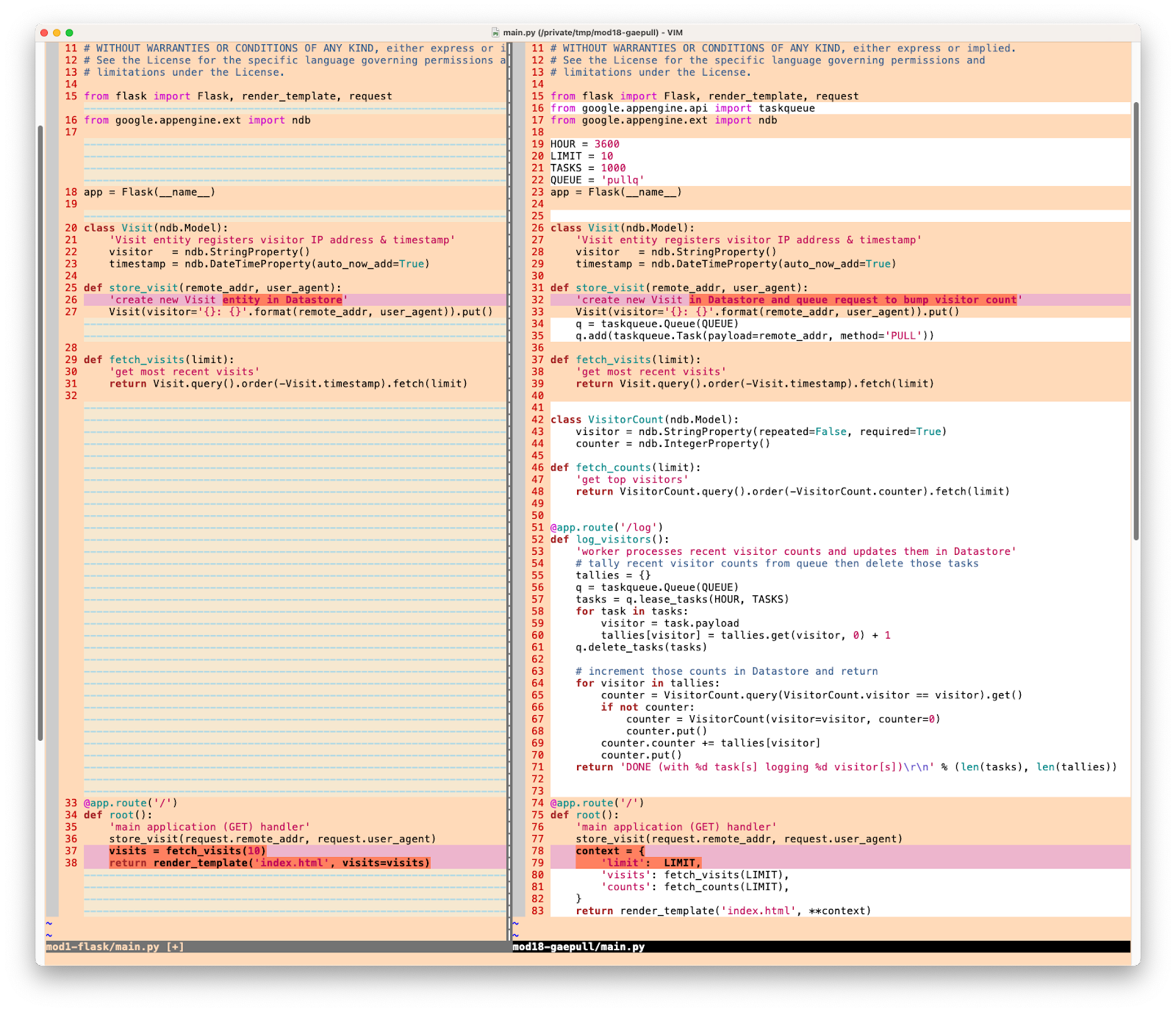
To wszystkie zmiany wymagane w przypadku main.py. Poniżej znajdziesz ilustrację tych aktualizacji, która pomoże Ci zrozumieć, jakie zmiany wprowadzasz w main.py:
Aktualizowanie szablonu internetowego o nowe dane wyświetlania
Szablon internetowy templates/index.html wymaga aktualizacji, aby wyświetlać użytkowników o największej aktywności oprócz zwykłego ładunku z informacjami o najnowszych użytkownikach. Umieść najpopularniejszych użytkowników i ich liczbę w tabeli u góry strony i nadal wyświetlaj najnowsze wizyty tak jak wcześniej. Jedyna inna zmiana polega na określeniu liczby wyświetlanej za pomocą zmiennej limit zamiast zakodowania jej na stałe. Oto zmiany, które należy wprowadzić w szablonie internetowym:
PRZED:
<!doctype html>
<html>
<head>
<title>VisitMe Example</title>
<body>
<h1>VisitMe example</h1>
<h3>Last 10 visits</h3>
<ul>
{% for visit in visits %}
<li>{{ visit.timestamp.ctime() }} from {{ visit.visitor }}</li>
{% endfor %}
</ul>
PO:
<!doctype html>
<html>
<head>
<title>VisitMe Example</title>
<body>
<h1>VisitMe example</h1>
<h3>Top {{ limit }} visitors</h3>
<table border=1 cellspacing=0 cellpadding=2>
<tr><th>Visitor</th><th>Visits</th></tr>
{% for count in counts %}
<tr><td>{{ count.visitor|e }}</td><td align="center">{{ count.counter }}</td></tr>
{% endfor %}
</table>
<h3>Last {{ limit }} visits</h3>
<ul>
{% for visit in visits %}
<li>{{ visit.timestamp.ctime() }} from {{ visit.visitor }}</li>
{% endfor %}
</ul>
W ten sposób zakończyliśmy wprowadzanie niezbędnych zmian, które umożliwiają korzystanie z zadań typu pull w kolejce zadań App Engine w przykładowej aplikacji z modułu 1. Twój katalog zawiera teraz przykładową aplikację z modułu 18 i powinien zawierać te pliki:
$ ls README.md appengine_config.py queue.yaml templates app.yaml main.py requirements.txt
6. Podsumowanie i czyszczenie
W tej sekcji podsumowujemy te warsztaty, wdrażając aplikację i sprawdzając, czy działa zgodnie z oczekiwaniami i czy dane wyjściowe są prawidłowe. Uruchom instancję roboczą osobno, aby przetworzyć liczbę użytkowników. Po zweryfikowaniu aplikacji wykonaj czynności związane z czyszczeniem i zastanów się, co dalej zrobić.
Wdrażanie i weryfikowanie aplikacji
Upewnij się, że kolejka pull została już skonfigurowana, tak jak zrobiliśmy to na początku tego samouczka za pomocą gcloud app deploy queue.yaml. Jeśli to zrobisz i przykładowa aplikacja będzie gotowa, wdróż ją za pomocą polecenia gcloud app deploy. Dane wyjściowe powinny być identyczne z aplikacją z modułu 1, z tym że u góry znajduje się teraz tabela „Najlepsi użytkownicy”:
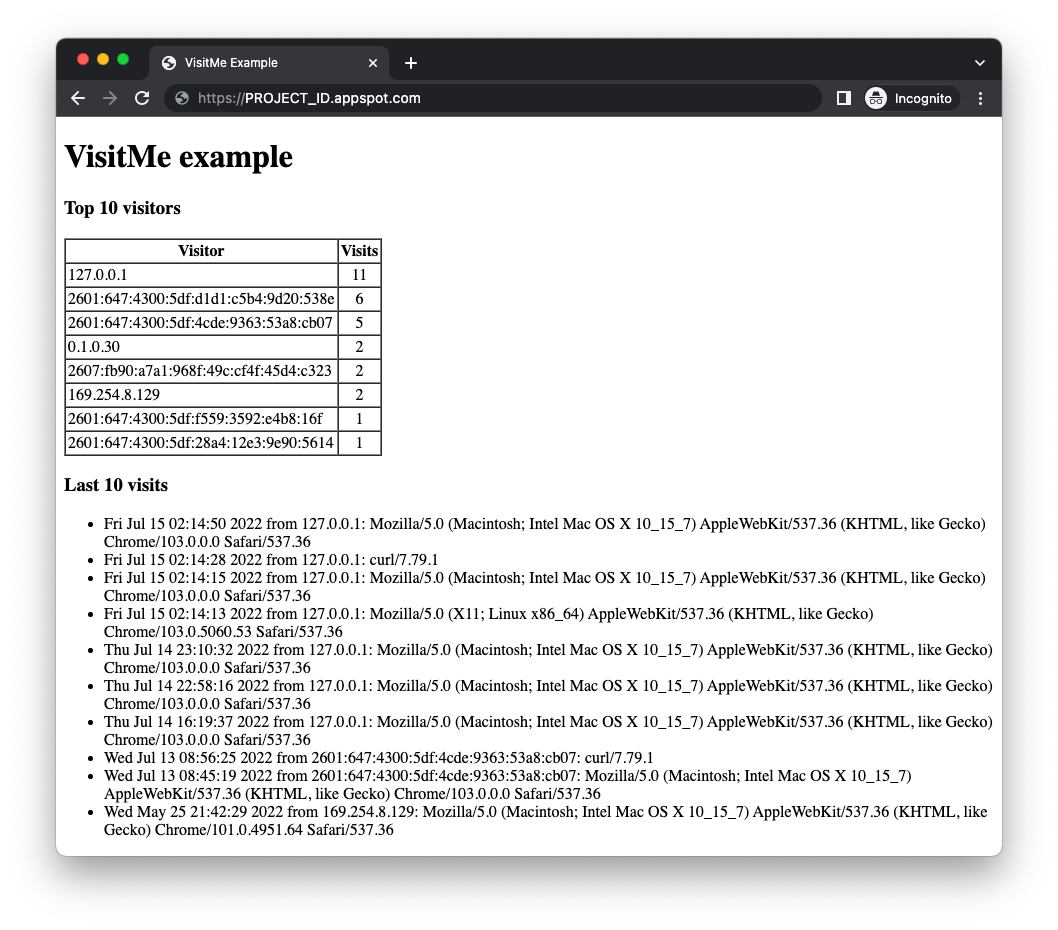
Zaktualizowany interfejs internetowy wyświetla najważniejszych i najnowszych użytkowników, ale pamiętaj, że liczba użytkowników nie obejmuje tej wizyty. Aplikacja wyświetla poprzednie liczby odwiedzających, a jednocześnie umieszcza w kolejce pull nowe zadanie zwiększające liczbę odwiedzających. To zadanie czeka na przetworzenie.
Możesz wykonać to zadanie, dzwoniąc pod numer /log na różne sposoby:
- usługa backendu App Engine,
- A
cronjob - przeglądarki internetowej,
- Żądanie HTTP w wierszu poleceń (
curl,wgetitp.)
Jeśli na przykład użyjesz curl, aby wysłać żądanie GET do /log, dane wyjściowe będą wyglądać tak, jeśli podasz swój PROJECT_ID:
$ curl https://PROJECT_ID.appspot.com/log DONE (with 1 task[s] logging 1 visitor[s])
Zaktualizowana liczba zostanie uwzględniona podczas następnej wizyty w witrynie. To wszystko.
Gratulacje! Ćwiczenie (w Codelabs) dotyczące dodawania do przykładowej aplikacji usługi kolejki pull App Engine Task Queue zostało ukończone. W module 19 będzie można przeprowadzić migrację do Cloud Pub/Sub, Cloud NDB i Pythona 3.
Czyszczenie danych
Ogólne
Jeśli na razie nie chcesz już korzystać z usługi, zalecamy wyłączenie aplikacji App Engine, aby uniknąć naliczania opłat. Jeśli jednak chcesz przeprowadzić więcej testów lub eksperymentów, platforma App Engine ma bezpłatny limit, więc dopóki nie przekroczysz tego poziomu wykorzystania, nie powinny być naliczane żadne opłaty. Dotyczy to obliczeń, ale mogą też wystąpić opłaty za odpowiednie usługi App Engine, więc więcej informacji znajdziesz na stronie z cennikiem. Jeśli migracja obejmuje inne usługi w chmurze, są one rozliczane oddzielnie. W każdym przypadku, jeśli to konieczne, zapoznaj się z sekcją „Specyficzne dla tego laboratorium” poniżej.
Wdrożenie na bezserwerowej platformie obliczeniowej Google Cloud, takiej jak App Engine, wiąże się z niewielkimi kosztami kompilacji i przechowywania. Cloud Build ma własny bezpłatny limit, podobnie jak Cloud Storage. Przechowywanie tego obrazu wykorzystuje część tego limitu. Możesz jednak mieszkać w regionie, w którym nie ma takiego bezpłatnego pakietu, więc kontroluj wykorzystanie miejsca na dane, aby zminimalizować potencjalne koszty. Sprawdź te „foldery” Cloud Storage:
console.cloud.google.com/storage/browser/LOC.artifacts.PROJECT_ID.appspot.com/containers/imagesconsole.cloud.google.com/storage/browser/staging.PROJECT_ID.appspot.com- Linki do pamięci masowej powyżej zależą od
PROJECT_IDi *LOC*acji, np. „us”, jeśli Twoja aplikacja jest hostowana w Stanach Zjednoczonych.
Jeśli nie zamierzasz kontynuować pracy z tą aplikacją ani innymi powiązanymi z nią samouczkami dotyczącymi migracji i chcesz wszystko całkowicie usunąć, wyłącz projekt.
Dotyczy tych ćwiczeń z programowania
Usługi wymienione poniżej są dostępne tylko w tym laboratorium. Więcej informacji znajdziesz w dokumentacji poszczególnych usług:
- Usługa kolejki zadań App Engine nie generuje dodatkowych opłat zgodnie z cennikiem starszych pakietów usług, takich jak kolejka zadań.
- Usługa App Engine Datastore jest udostępniana przez Cloud Datastore (Cloud Firestore w trybie Datastore), która również ma bezpłatny poziom. Więcej informacji znajdziesz na stronie z cennikiem.
Dalsze kroki
W ramach tej „migracji” dodaliśmy do przykładowej aplikacji z modułu 1 użycie kolejki push Task Queue, dodając obsługę śledzenia odwiedzających, a tym samym wdrażając przykładową aplikację z modułu 18. W ramach następnej migracji uaktualnimy zadania pull App Engine do Cloud Pub/Sub. Od końca 2021 r. użytkownicy nie muszą przeprowadzać migracji do Cloud Pub/Sub podczas uaktualniania do Pythona 3. Więcej informacji na ten temat znajdziesz w następnej sekcji.
Informacje o migracji do Cloud Pub/Sub znajdziesz w module 19 codelabu. Oprócz tego warto rozważyć dodatkowe migracje, takie jak Cloud Datastore, Cloud Memorystore, Cloud Storage czy Cloud Tasks (kolejki push). Istnieją też migracje między usługami do Cloud Run i Cloud Functions. Cała zawartość Serverless Migration Station (ćwiczenia z programowania, filmy, kod źródłowy [jeśli jest dostępny]) jest dostępna w repozytorium open source.
7. Migracja do Pythona 3
Jesienią 2021 r. zespół App Engine rozszerzył obsługę wielu usług pakietowych na środowiska wykonawcze 2 generacji (które mają środowisko wykonawcze 1 generacji). Dzięki temu nie musisz już migrować z usług pakietowych, takich jak kolejka zadań App Engine, do samodzielnych usług Cloud lub usług innych firm, takich jak Cloud Pub/Sub, podczas przenoszenia aplikacji do Pythona 3. Innymi słowy, możesz nadal używać kolejki zadań w aplikacjach App Engine w Pythonie 3, o ile dostosujesz kod, aby uzyskać dostęp do usług pakietowych ze środowisk wykonawczych nowej generacji.
Więcej informacji o przenoszeniu korzystania z usług pakietowych do Pythona 3 znajdziesz w ćwiczeniu programistycznym w module 17 i odpowiednim filmie. Ten temat wykracza poza zakres modułu 18, ale poniżej znajdziesz wersje aplikacji z modułu 1 w języku Python 3, które zostały przeniesione do tego języka i nadal korzystają z NDB w App Engine. (W pewnym momencie udostępnimy też wersję aplikacji z modułu 18 w języku Python 3).
8. Dodatkowe materiały
Poniżej znajdziesz dodatkowe materiały dla programistów, którzy chcą dowiedzieć się więcej o tym lub powiązanym module migracji, a także o powiązanych produktach. Znajdziesz tu m.in. miejsca, w których możesz przesłać opinię o tych treściach, linki do kodu i różne dokumenty, które mogą Ci się przydać.
Problemy z ćwiczeniami z programowania i opinie na ich temat
Jeśli zauważysz jakieś problemy z tym kursem, najpierw poszukaj rozwiązania, a dopiero potem zgłoś problem. Linki do wyszukiwania i tworzenia nowych problemów:
Materiały dotyczące migracji
Linki do folderów repozytorium dla modułu 1 (START) i modułu 18 (FINISH) znajdziesz w tabeli poniżej. Możesz też uzyskać do nich dostęp w repozytorium wszystkich migracji z App Engine do Codelab. Sklonuj je lub pobierz plik ZIP.
Ćwiczenia z programowania | Python 2 | Python 3 |
kod (nie jest omawiany w tym samouczku) | ||
Moduł 18 (to ćwiczenie) | Nie dotyczy |
Odsyłacze online
Poniżej znajdziesz zasoby przydatne w tym samouczku:
Kolejka zadań App Engine
- Omówienie kolejki zadań App Engine
- Omówienie kolejek pull w kolejce zadań App Engine
- Pełna przykładowa aplikacja kolejki pull w App Engine Task Queue
- Tworzenie kolejek pull w Task Queue
- Film z wprowadzenia kolejki pull na Google I/O 2011 ( przykładowa aplikacja Votelator)
queue.yamlźródło informacjiqueue.yamla Cloud Tasks- Przewodnik po migracji kolejek pull do Pub/Sub
- Przykładowa dokumentacja dotycząca przenoszenia kolejek pull z kolejek zadań App Engine do Cloud Pub/Sub
Platforma App Engine
Dokumentacja App Engine
Środowisko wykonawcze App Engine (środowisko standardowe) w Pythonie 2
Środowisko wykonawcze Pythona 3 w App Engine (środowisko standardowe)
Różnice między środowiskami wykonawczymi App Engine (środowisko standardowe) w Pythonie 2 i 3
Przewodnik po migracji z App Engine (środowisko standardowe) z Pythona 2 na Pythona 3
Informacje o cenach i limitach App Engine
Uruchomienie platformy App Engine drugiej generacji (2018)
Wsparcie długoterminowe dla starszych środowisk wykonawczych
Przykłady migracji dokumentacji
Inne informacje o chmurze
- Python w Google Cloud Platform
- Biblioteki klienta Google Cloud Python
- Poziom „Zawsze bezpłatny” w Google Cloud
- Google Cloud SDK (narzędzie wiersza poleceń
gcloud) - Cała dokumentacja Google Cloud
Filmy
- Serverless Migration Station
- Ekspedycje bezserwerowe
- Subskrybuj Google Cloud Tech
- Subskrybuj Google Developers
Licencja
To zadanie jest licencjonowane na podstawie ogólnej licencji Creative Commons Attribution 2.0.