
1. Обзор
Серия обучающих материалов Serverless Migration Station (самостоятельные практические уроки) и сопутствующих видеороликов призвана помочь разработчикам бессерверных приложений Google Cloud модернизировать свои приложения, проведя их через одну или несколько миграций, в первую очередь, через отказ от устаревших сервисов. Это делает ваши приложения более портативными, предоставляет больше возможностей и гибкости, позволяя интегрироваться с более широким спектром облачных продуктов и получать к ним доступ, а также упрощает обновление до более новых версий языков программирования. Хотя изначально серия ориентирована на самых первых пользователей облачных сервисов, в первую очередь разработчиков App Engine (стандартная среда), она достаточно широка, чтобы охватить и другие бессерверные платформы, такие как Cloud Functions и Cloud Run , или другие, если это применимо.
В этом практическом занятии вы узнаете, как добавить и использовать задачи App Engine Task Queue с функцией pull tasks в пример приложения из практического занятия по модулю 1. Использование задач pull tasks мы добавим в этом руководстве по модулю 18, а затем перенесем этот подход в Cloud Pub/Sub в модуле 19. Тем, кто использует Task Queues для задач push tasks, следует перейти к Cloud Tasks и обратиться к модулям 7-9.
Вы узнаете, как
- Используйте API/встроенный сервис очереди задач App Engine.
- Добавьте использование очереди запросов в базовое приложение Python 2 Flask App Engine NDB.
Что вам понадобится
- Проект на платформе Google Cloud Platform с активным платежным аккаунтом GCP.
- Базовые навыки работы с Python.
- Практические навыки работы с распространенными командами Linux.
- Базовые знания разработки и развертывания приложений на платформе App Engine.
- Рабочее приложение App Engine из модуля 1 (пройдите соответствующий практический урок [рекомендуется] или скопируйте приложение из репозитория).
Опрос
Как вы будете использовать этот учебный материал?
Как бы вы оценили свой опыт работы с Python?
Как бы вы оценили свой опыт использования сервисов Google Cloud?
2. Предыстория
Для перехода от задач App Engine Task Queue с функцией pull, добавьте её использование в существующее приложение Flask и App Engine NDB, созданное в рамках практического занятия по модулю 1. Пример приложения отображает пользователю информацию о последних посещениях. Это хорошо, но ещё интереснее отслеживать посетителей, чтобы увидеть, кто посещает сайт чаще всего.
Хотя для подсчета посетителей можно было бы использовать push-уведомления , мы хотим разделить ответственность между тестовым приложением, задача которого — регистрировать посещения и немедленно отвечать пользователям, и назначенным «работником», задача которого — подсчитывать количество посетителей вне обычного рабочего процесса запрос-ответ.
Для реализации этой концепции мы добавляем использование очередей запросов в основное приложение, а также поддерживаем функциональность воркера. Воркер может работать как отдельный процесс (например, как экземпляр бэкэнда или код, работающий на постоянно работающей виртуальной машине), как задание cron или как простой HTTP-запрос из командной строки с использованием curl или wget . После этой интеграции вы сможете перенести приложение в Cloud Pub/Sub в следующем практическом занятии (модуль 19).
В этом руководстве описаны следующие шаги:
- Подготовка/Настройка
- Обновить конфигурацию
- Измените код приложения
3. Подготовка/Предварительные работы
В этом разделе объясняется, как:
- Настройте свой облачный проект
- Получите базовый образец приложения
- (Повторное) развертывание и проверка базового приложения.
Эти шаги гарантируют, что вы начнете работу с работоспособным кодом.
1. Настройка проекта
Если вы выполнили практическое задание по модулю 1 , используйте тот же проект (и код). В качестве альтернативы создайте совершенно новый проект или используйте существующий. Убедитесь, что у проекта есть активный платежный аккаунт и включенное приложение App Engine. Найдите идентификатор вашего проекта, так как он понадобится вам несколько раз в этом практическом задании, и используйте его всякий раз, когда встретите переменную PROJECT_ID .
2. Получите базовый образец приложения.
Одно из предварительных условий для этого практического занятия — наличие работающего приложения App Engine из Модуля 1. Выполните практическое занятие по Модулю 1 (рекомендуется) или скопируйте приложение Модуля 1 из репозитория. Независимо от того, используете ли вы свой или наш код, мы начнём именно с кода Модуля 1. Это практическое занятие шаг за шагом проведёт вас через каждый этап, завершившись кодом, похожим на тот, что находится в папке «FINISH» репозитория Модуля 18.
- НАЧАЛО: Папка «Модуль 1» (Python 2)
- ЗАВЕРШЕНИЕ: Папка модуля 18 (Python 2)
- Весь репозиторий (для клонирования или загрузки ZIP-файла )
Независимо от того, какое приложение из Модуля 1 вы используете, папка должна выглядеть примерно так, как показано ниже, возможно, с дополнительной папкой lib :
$ ls README.md appengine_config.py requirements.txt app.yaml main.py templates
3. (Повторное) развертывание базового приложения
Для развертывания приложения «Модуль 1» выполните следующие действия:
- Удалите папку
lib, если она есть, и выполните команду:pip install -t lib -r requirements.txt, чтобы заново заполнитьlib. Возможно, вам потребуется использовать командуpip2, если у вас установлены Python 2 и 3. - Убедитесь, что вы установили и инициализировали инструмент командной строки
gcloudи ознакомились с его использованием. - Укажите свой облачный проект с помощью
gcloud config set projectPROJECT_ID, если вы не хотите вводить свойPROJECT_IDпри каждой командеgcloud. - Разверните демонстрационное приложение с помощью
gcloud app deploy - Убедитесь, что приложение «Модуль 1» работает должным образом и отображает последние посещения (иллюстрация ниже).
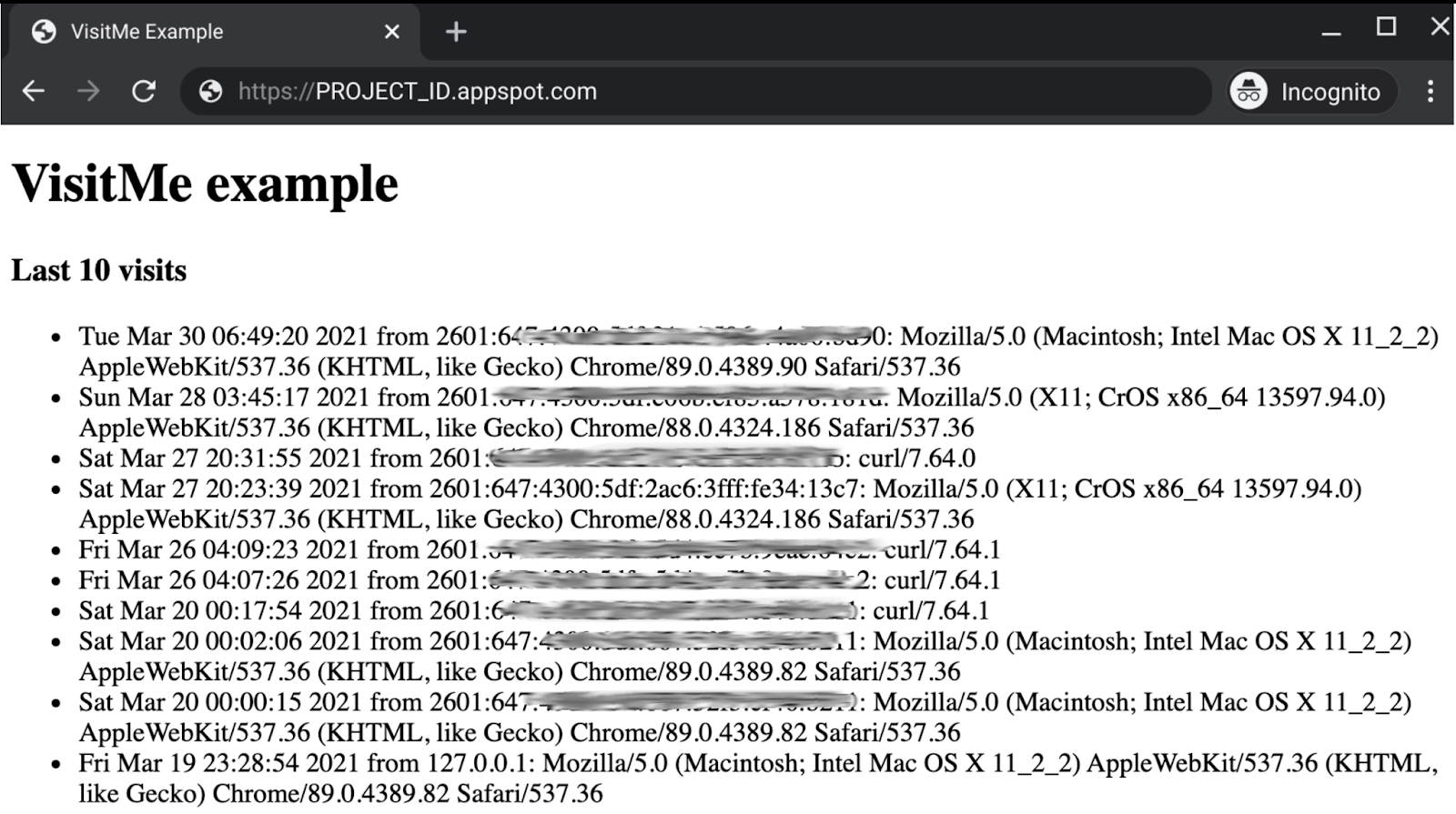
4. Обновите конфигурацию
Вносить изменения в стандартные конфигурационные файлы App Engine ( app.yaml , requirements.txt , appengine_config.py ) не требуется. Вместо этого добавьте новый конфигурационный файл queue.yaml со следующим содержимым, разместив его в том же корневом каталоге:
queue:
- name: pullq
mode: pull
Файл queue.yaml определяет все существующие очереди задач для вашего приложения (за исключением очереди default [push], которая автоматически создается App Engine). В данном случае существует только одна очередь — очередь pull с именем pullq . App Engine требует, чтобы директива mode была указана как pull , в противном случае по умолчанию создается очередь push. Подробнее о создании очередей pull см. в документации . Также см. страницу справочника по queue.yaml для получения информации о других параметрах.
Разверните этот файл отдельно от вашего приложения. Вы по-прежнему будете использовать gcloud app deploy , но также укажете queue.yaml в командной строке:
$ gcloud app deploy queue.yaml Configurations to update: descriptor: [/tmp/mod18-gaepull/queue.yaml] type: [task queues] target project: [my-project] WARNING: Caution: You are updating queue configuration. This will override any changes performed using 'gcloud tasks'. More details at https://cloud.google.com/tasks/docs/queue-yaml Do you want to continue (Y/n)? Updating config [queue]...⠹WARNING: We are using the App Engine app location (us-central1) as the default location. Please use the "--location" flag if you want to use a different location. Updating config [queue]...done. Task queues have been updated. Visit the Cloud Platform Console Task Queues page to view your queues and cron jobs. $
5. Измените код приложения.
В этом разделе представлены обновления следующих файлов:
-
main.py— добавляет использование очередей запросов в основное приложение -
templates/index.html— обновите веб-шаблон, чтобы отобразить новые данные.
Импорт и константы
Первый шаг — добавить один новый импорт и несколько констант для поддержки очередей запросов:
- Добавьте импорт библиотеки Task Queue:
google.appengine.api.taskqueue. - Добавьте три константы для поддержки аренды максимального количества задач (
TASKS) на час (HOUR) из нашей очереди (QUEUE). - Добавьте константу для отображения самых последних посещений, а также самых популярных посетителей (
LIMIT).
Ниже представлен исходный код и его вид после внесения этих изменений:
ДО:
from flask import Flask, render_template, request
from google.appengine.ext import ndb
app = Flask(__name__)
ПОСЛЕ:
from flask import Flask, render_template, request
from google.appengine.api import taskqueue
from google.appengine.ext import ndb
HOUR = 3600
LIMIT = 10
TASKS = 1000
QNAME = 'pullq'
QUEUE = taskqueue.Queue(QNAME)
app = Flask(__name__)
Добавить задачу типа «сбор данных» (собрать данные для задачи и создать задачу в очереди сбора данных).
Модель данных Visit остается неизменной, как и запрос посещений для отображения в fetch_visits() . Единственное изменение, необходимое в этой части кода, касается функции store_visit() . В дополнение к регистрации посещения, добавьте задачу в очередь запросов с IP-адресом посетителя, чтобы обработчик мог увеличивать счетчик посетителей.
ДО:
class Visit(ndb.Model):
'Visit entity registers visitor IP address & timestamp'
visitor = ndb.StringProperty()
timestamp = ndb.DateTimeProperty(auto_now_add=True)
def store_visit(remote_addr, user_agent):
'create new Visit entity in Datastore'
Visit(visitor='{}: {}'.format(remote_addr, user_agent)).put()
def fetch_visits(limit):
'get most recent visits'
return Visit.query().order(-Visit.timestamp).fetch(limit)
ПОСЛЕ:
class Visit(ndb.Model):
'Visit entity registers visitor IP address & timestamp'
visitor = ndb.StringProperty()
timestamp = ndb.DateTimeProperty(auto_now_add=True)
def store_visit(remote_addr, user_agent):
'create new Visit in Datastore and queue request to bump visitor count'
Visit(visitor='{}: {}'.format(remote_addr, user_agent)).put()
QUEUE.add(taskqueue.Task(payload=remote_addr, method='PULL'))
def fetch_visits(limit):
'get most recent visits'
return Visit.query().order(-Visit.timestamp).fetch(limit)
Создайте модель данных и функцию запроса для отслеживания посетителей.
Добавьте модель данных VisitorCount для отслеживания посетителей; она должна содержать поля для самого visitor , а также целочисленный counter для отслеживания количества посещений. Затем добавьте новую функцию (или classmethod Python) с именем fetch_counts() для запроса и возврата самых популярных посетителей в порядке от самых частых к наименее частым. Добавьте класс и функцию непосредственно под телом функции fetch_visits() :
class VisitorCount(ndb.Model):
visitor = ndb.StringProperty(repeated=False, required=True)
counter = ndb.IntegerProperty()
def fetch_counts(limit):
'get top visitors'
return VisitCount.query().order(-VisitCount.counter).fetch(limit)
Добавить код работника
Добавьте новую функцию log_visitors() для регистрации посетителей, отправляемых через GET-запрос к /log . Она использует словарь/хеш для отслеживания количества последних посетителей, выбирая максимально возможное количество задач на час. Для каждой задачи она подсчитывает все посещения одного и того же посетителя. Получив данные, приложение обновляет все соответствующие сущности VisitorCount уже находящиеся в Datastore, или создает новые при необходимости. На последнем шаге возвращается текстовое сообщение, указывающее, сколько посетителей было зарегистрировано и сколько задач было обработано. Добавьте эту функцию в main.py сразу после fetch_counts() :
@app.route('/log')
def log_visitors():
'worker processes recent visitor counts and updates them in Datastore'
# tally recent visitor counts from queue then delete those tasks
tallies = {}
tasks = QUEUE.lease_tasks(HOUR, TASKS)
for task in tasks:
visitor = task.payload
tallies[visitor] = tallies.get(visitor, 0) + 1
if tasks:
QUEUE.delete_tasks(tasks)
# increment those counts in Datastore and return
for visitor in tallies:
counter = VisitorCount.query(VisitorCount.visitor == visitor).get()
if not counter:
counter = VisitorCount(visitor=visitor, counter=0)
counter.put()
counter.counter += tallies[visitor]
counter.put()
return 'DONE (with %d task[s] logging %d visitor[s])\r\n' % (
len(tasks), len(tallies))
Обновить основной обработчик новыми данными для отображения.
Чтобы отобразить самых активных посетителей, обновите обработчик root() в главном окне, добавив вызов функции fetch_counts() . Кроме того, шаблон будет обновлен, чтобы отображать количество самых активных посетителей и самые последние посещения. Упакуйте количество посетителей вместе с самыми последними посещениями из вызова fetch_visits() и поместите это в единый context для передачи в веб-шаблон. Ниже приведен код до и после внесения этого изменения:
ДО:
@app.route('/')
def root():
'main application (GET) handler'
store_visit(request.remote_addr, request.user_agent)
visits = fetch_visits(10)
return render_template('index.html', visits=visits)
ПОСЛЕ:
@app.route('/')
def root():
'main application (GET) handler'
store_visit(request.remote_addr, request.user_agent)
context = {
'limit': LIMIT,
'visits': fetch_visits(LIMIT),
'counts': fetch_counts(LIMIT),
}
return render_template('index.html', **context)
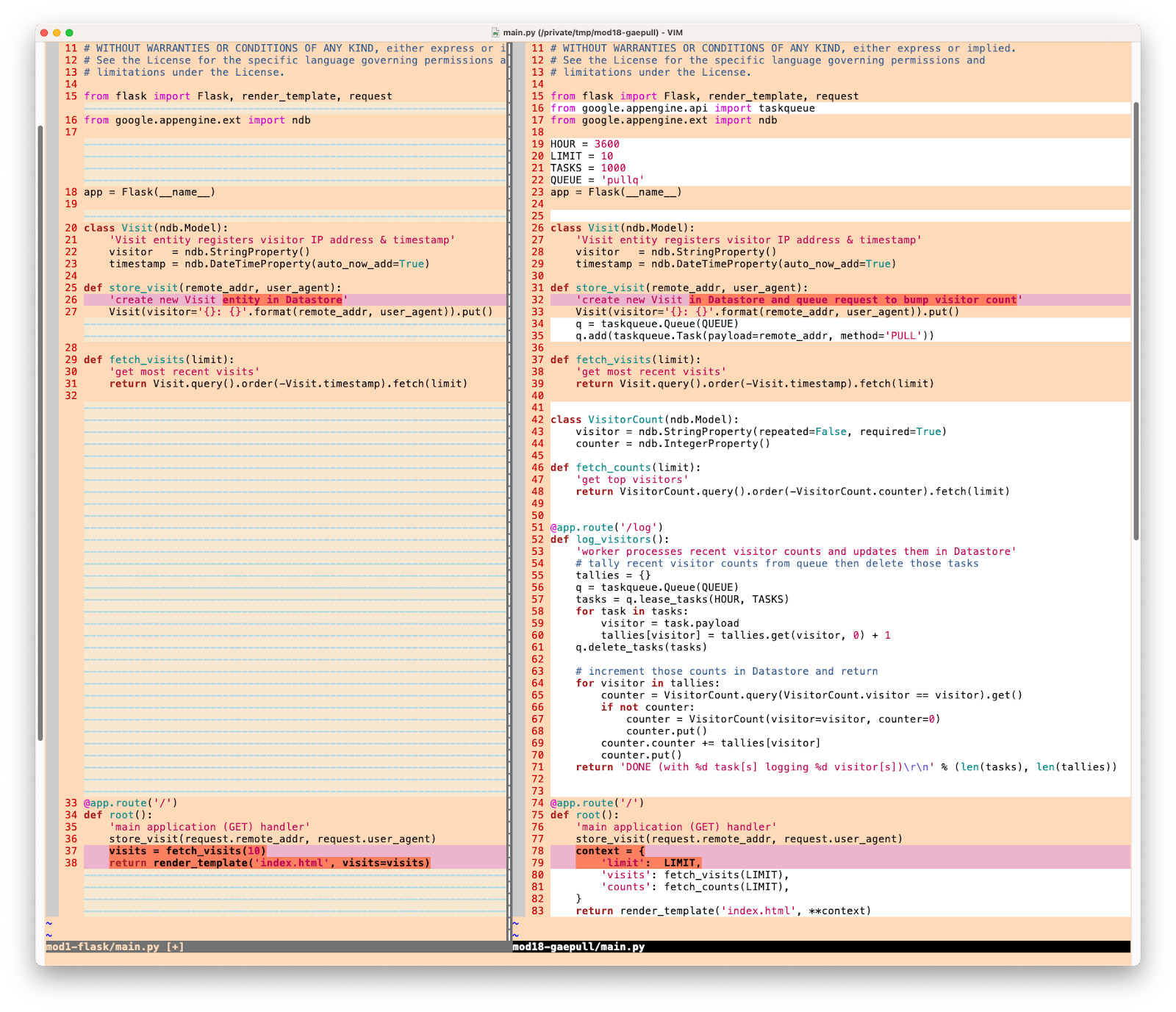
Это все изменения, которые необходимо внести в main.py , и вот графическое представление этих изменений для наглядности, чтобы дать вам общее представление об изменениях, которые вы вносите в main.py :
Обновите веб-шаблон, добавив новые отображаемые данные.
В веб-шаблоне templates/index.html необходимо внести изменения, чтобы помимо обычных данных о последних посетителях отображались и самые популярные посетители. Добавьте список самых популярных посетителей и их количество в таблицу в верхней части страницы, а отображение последних посещений должно работать как раньше. Единственное другое изменение — это указание отображаемого числа с помощью переменной limit вместо жесткого кодирования. Вот изменения, которые следует внести в ваш веб-шаблон:
ДО:
<!doctype html>
<html>
<head>
<title>VisitMe Example</title>
<body>
<h1>VisitMe example</h1>
<h3>Last 10 visits</h3>
<ul>
{% for visit in visits %}
<li>{{ visit.timestamp.ctime() }} from {{ visit.visitor }}</li>
{% endfor %}
</ul>
ПОСЛЕ:
<!doctype html>
<html>
<head>
<title>VisitMe Example</title>
<body>
<h1>VisitMe example</h1>
<h3>Top {{ limit }} visitors</h3>
<table border=1 cellspacing=0 cellpadding=2>
<tr><th>Visitor</th><th>Visits</th></tr>
{% for count in counts %}
<tr><td>{{ count.visitor|e }}</td><td align="center">{{ count.counter }}</td></tr>
{% endfor %}
</table>
<h3>Last {{ limit }} visits</h3>
<ul>
{% for visit in visits %}
<li>{{ visit.timestamp.ctime() }} from {{ visit.visitor }}</li>
{% endfor %}
</ul>
На этом завершаются необходимые изменения, добавляющие использование задач App Engine Task Queue в демонстрационное приложение Модуля 1. Теперь ваша директория представляет собой демонстрационное приложение Модуля 18 и должна содержать следующие файлы:
$ ls README.md appengine_config.py queue.yaml templates app.yaml main.py requirements.txt
6. Подведение итогов/Завершение
В этом разделе завершается выполнение данного практического задания: развертывается приложение, проверяется его работоспособность и корректность выходных данных. Для обработки количества посетителей запустите отдельный обработчик. После проверки приложения выполните необходимые действия по очистке и определитесь с дальнейшими шагами.
Разверните и проверьте приложение.
Убедитесь, что вы уже настроили очередь запросов, как мы это сделали в начале этого руководства, с помощью gcloud app deploy queue.yaml . Если это сделано и ваше тестовое приложение готово, разверните его с помощью gcloud app deploy . Результат должен быть идентичен приложению из модуля 1, за исключением того, что теперь вверху отображается таблица «самые популярные посетители»:
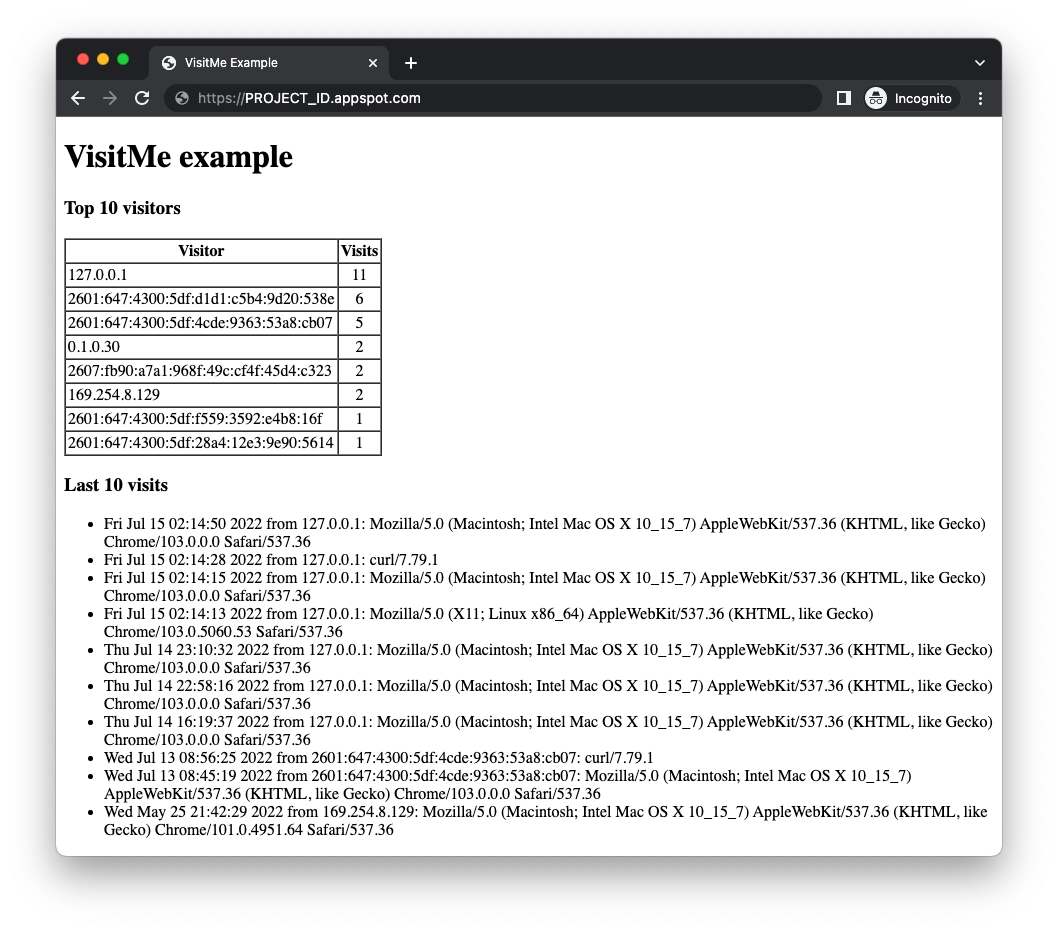
Хотя обновленный веб-интерфейс отображает самых активных посетителей и самые последние посещения, имейте в виду, что количество посетителей не включает это посещение. Приложение отображает предыдущее количество посетителей, добавляя в очередь задачу, увеличивающую счетчик этого посетителя, — задачу, ожидающую обработки.
Вы можете выполнить задачу, вызвав команду /log , несколькими способами:
- Сервис бэкэнда для App Engine
- Задание
cron - веб-браузер
- HTTP-запрос из командной строки (
curl,wgetи т. д.)
Например, если вы используете curl для отправки GET-запроса на /log , ваш вывод будет выглядеть примерно так, при условии, что вы указали PROJECT_ID :
$ curl https://PROJECT_ID.appspot.com/log DONE (with 1 task[s] logging 1 visitor[s])
Обновленные данные будут отображены при следующем посещении сайта. Вот и все!
Поздравляем с успешным завершением этого практического задания по добавлению использования сервиса очереди задач App Engine в демонстрационное приложение. Теперь оно готово к миграции на Cloud Pub/Sub, Cloud NDB и Python 3 в модуле 19.
Уборка
Общий
Если на этом пока всё, мы рекомендуем отключить ваше приложение App Engine, чтобы избежать дополнительных расходов. Однако, если вы хотите продолжить тестирование или эксперименты, платформа App Engine предоставляет бесплатную квоту , поэтому, пока вы не превысите этот лимит, с вас не должны взиматься дополнительные платежи. Это касается вычислительных ресурсов, но могут также взиматься плата за соответствующие услуги App Engine, поэтому проверьте страницу с ценами для получения дополнительной информации. Если эта миграция включает другие облачные сервисы, они оплачиваются отдельно. В любом случае, если применимо, см. раздел «Информация, относящаяся к этому практическому занятию» ниже.
Для полной ясности, развертывание на бессерверной вычислительной платформе Google Cloud, такой как App Engine, влечет за собой незначительные затраты на сборку и хранение . Cloud Build и Cloud Storage имеют собственную бесплатную квоту. Хранение образа использует часть этой квоты. Однако вы можете проживать в регионе, где нет такого бесплатного уровня, поэтому следите за использованием хранилища, чтобы минимизировать потенциальные затраты. К числу конкретных «папок» Cloud Storage, которые следует проверить, относятся:
-
console.cloud.google.com/storage/browser/LOC.artifacts.PROJECT_ID.appspot.com/containers/images -
console.cloud.google.com/storage/browser/staging.PROJECT_ID.appspot.com - Приведенные выше ссылки на хранилища зависят от вашего
PROJECT_IDи *LOC*, например, "us", если ваше приложение размещено в США.
С другой стороны, если вы не собираетесь продолжать работу над этим приложением или другими связанными с миграцией кодовыми руководствами и хотите полностью удалить все, закройте свой проект .
Это относится именно к данному практическому занятию.
Перечисленные ниже услуги являются уникальными для данной учебной лаборатории. Для получения более подробной информации обратитесь к документации по каждому продукту:
- Сервис App Engine Task Queue не влечет за собой дополнительных расходов, как указано на странице с ценами для устаревших пакетных сервисов, таких как Task Queue.
- Сервис App Engine Datastore предоставляется компанией Cloud Datastore (Cloud Firestore в режиме Datastore), которая также предлагает бесплатный тариф; подробную информацию можно найти на странице с ценами .
Следующие шаги
В ходе этой «миграции» вы добавили использование очереди задач (Task Queue) в пример приложения Модуля 1, добавив поддержку отслеживания посетителей и тем самым реализовав пример приложения Модуля 18. В следующей миграции вы обновите задачи App Engine до Cloud Pub/Sub. Начиная с конца 2021 года, пользователям больше не требуется переходить на Cloud Pub/Sub при обновлении до Python 3. Подробнее об этом читайте в следующем разделе.
Для миграции на Cloud Pub/Sub обратитесь к практическому руководству по модулю 19. Помимо этого, следует рассмотреть дополнительные варианты миграции, такие как Cloud Datastore, Cloud Memorystore, Cloud Storage или Cloud Tasks (очереди отправки). Также доступны варианты миграции между продуктами Cloud Run и Cloud Functions. Весь контент Serverless Migration Station (практические руководства, видео, исходный код [при наличии]) доступен в его репозитории с открытым исходным кодом .
7. Переход на Python 3
Осенью 2021 года команда App Engine расширила поддержку многих встроенных сервисов для сред выполнения второго поколения (которые используют среду выполнения первого поколения). В результате вам больше не нужно переходить от встроенных сервисов, таких как App Engine Task Queue, к автономным облачным сервисам или сторонним сервисам, таким как Cloud Pub/Sub, при портировании вашего приложения на Python 3. Другими словами, вы можете продолжать использовать Task Queue в приложениях App Engine на Python 3, если адаптируете код для доступа к встроенным сервисам из сред выполнения следующего поколения .
Подробнее о том, как перенести использование встроенных сервисов на Python 3, вы можете узнать в практическом занятии по модулю 17 и соответствующем видео. Хотя эта тема выходит за рамки модуля 18, ниже приведены ссылки на версии приложения из модуля 1, портированные на Python 3 и по-прежнему использующие App Engine NDB. (В какой-то момент будет также доступна версия приложения из модуля 18 на Python 3.)
8. Дополнительные ресурсы
Ниже перечислены дополнительные ресурсы для разработчиков, желающих подробнее изучить этот или связанный с ним модуль миграции, а также сопутствующие продукты. Сюда входят места для оставления отзывов о данном контенте, ссылки на код и различные документы, которые могут оказаться полезными.
Вопросы/отзывы по Codelab
Если вы обнаружите какие-либо проблемы в этом практическом задании, пожалуйста, сначала найдите свою проблему, прежде чем сообщать о ней. Ссылки для поиска и создания новых проблем:
Миграционные ресурсы
Ссылки на папки репозитория для Модуля 1 (НАЧАЛО) и Модуля 18 (ЗАВЕРШЕНИЕ) можно найти в таблице ниже. К ним также можно получить доступ из репозитория для всех миграций кода App Engine ; клонируйте его или скачайте ZIP-файл.
Кодлаб | Python 2 | Python 3 |
код (не представлен в этом уроке) | ||
Модуль 18 (данная практическая работа) | Н/Д |
Онлайн-ссылки
Ниже приведены ресурсы, имеющие отношение к данному уроку:
Очередь задач App Engine
- Обзор очереди задач App Engine
- Обзор очередей задач App Engine и очередей запросов.
- Пример приложения App Engine Task Queue pull queue.
- Создание очереди задач с возможностью выбора очередей
- Видео с презентации системы «pull queue» на Google I/O 2011 ( пример приложения Votelator )
- ссылка на файл
queue.yaml -
queue.yamlпротив облачных задач - Руководство по миграции очередей с использованием метода Pub/Sub
- Пример документации по App Engine Task Queue: извлечение данных из очереди задач в Cloud Pub/Sub.
платформа App Engine
Документация App Engine
Среда выполнения Python 2 App Engine (стандартная среда)
Среда выполнения Python 3 App Engine (стандартная среда)
Различия между средами выполнения Python 2 и 3 App Engine (стандартная среда)
Руководство по миграции с Python 2 на Python 3 App Engine (стандартная среда)
Информация о ценах и квотах App Engine
Запуск платформы App Engine второго поколения (2018)
Долгосрочная поддержка устаревших сред выполнения.
Образцы миграции документации
Прочая информация об облачных сервисах
- Python на платформе Google Cloud
- Клиентские библиотеки Python от Google Cloud
- Уровень Google Cloud «Всегда бесплатно»
- Google Cloud SDK (инструмент командной строки
gcloud) - Вся документация Google Cloud
Видео
- Станция миграции бессерверных приложений
- Бессерверные экспедиции
- Подпишитесь на Google Cloud Tech
- Подпишитесь на Google Developers
Лицензия
Данная работа распространяется под лицензией Creative Commons Attribution 2.0 Generic.