
1. Présentation
La série d'ateliers de programmation Serverless Migration Station (tutoriels pratiques à suivre à votre rythme) et les vidéos associées sont destinées à aider les développeurs Google Cloud sans serveur à moderniser leurs applications en les guidant tout au long d'une ou plusieurs migrations, principalement en les aidant à abandonner les anciens services. Cela rend vos applications plus portables et vous offre plus d'options et de flexibilité, ce qui vous permet de vous intégrer à une plus large gamme de produits Cloud et d'y accéder, et de passer plus facilement aux versions linguistiques plus récentes. Bien qu'elle se concentre initialement sur les premiers utilisateurs de Cloud, principalement les développeurs App Engine (environnement standard), cette série est suffisamment large pour inclure d'autres plates-formes sans serveur comme Cloud Functions et Cloud Run, ou ailleurs si nécessaire.
L'objectif de cet atelier de programmation est de montrer aux développeurs App Engine Python 2 comment migrer des tâches de retrait App Engine Task Queue vers Cloud Pub/Sub. Il existe également une migration implicite d'App Engine NDB vers Cloud NDB pour l'accès à Datastore (principalement abordé dans le module 2), ainsi qu'une mise à niveau vers Python 3.
Dans le module 18, vous avez appris à ajouter l'utilisation des tâches pull dans votre application. Dans ce module, vous allez prendre l'application du module 18 terminée et migrer cette utilisation vers Cloud Pub/Sub. Ceux qui utilisent les files d'attente de tâches pour les tâches push migreront plutôt vers Cloud Tasks et devront se reporter aux modules 7 à 9.
Vous apprendrez à
- Remplacer l'utilisation de la file d'attente de tâches App Engine (tâches de retrait) par Cloud Pub/Sub
- Remplacer l'utilisation d'App Engine NDB par Cloud NDB (voir aussi le module 2)
- Transférer l'application vers Python 3
Prérequis
- Un projet Google Cloud Platform avec un compte de facturation GCP actif
- Des connaissances de base en Python
- Une connaissance correcte des commandes Linux courantes
- Des connaissances de base du développement et du déploiement d'applications App Engine
- Un exemple d'application App Engine du module 18 fonctionnel
Enquête
Comment allez-vous utiliser ce tutoriel ?
Quel est votre niveau d'expérience avec Python ?
Quel est votre niveau d'expérience avec les services Google Cloud ?
2. Arrière-plan
La file d'attente de tâches App Engine accepte les tâches d'envoi et de retrait. Pour améliorer la portabilité des applications, Google Cloud recommande de migrer les anciens services groupés tels que Task Queue vers d'autres services Cloud autonomes ou équivalents tiers.
- Les utilisateurs de files d'attente de tâches push doivent migrer vers Cloud Tasks.
- Les utilisateurs de files d'attente de tâches de retrait doivent migrer vers Cloud Pub/Sub.
Les modules 7 à 9 couvrent la migration des tâches push, tandis que les modules 18 et 19 se concentrent sur la migration des tâches pull. Bien que Cloud Tasks corresponde davantage aux tâches d'envoi Task Queues, Pub/Sub n'est pas aussi proche des tâches de retrait Task Queues.
Pub/Sub offre plus de fonctionnalités que la fonctionnalité de retrait fournie par Task Queues. Par exemple, Pub/Sub dispose également d'une fonctionnalité d'envoi. Toutefois, Cloud Tasks ressemble davantage aux tâches d'envoi de la file d'attente des tâches. L'envoi Pub/Sub n'est donc pas couvert par les modules de migration. L'atelier de programmation du module 19 montre comment passer du mécanisme de mise en file d'attente des files d'attente de retrait Task Queue à Pub/Sub, et comment migrer d'App Engine NDB vers Cloud NDB pour accéder à Datastore, en répétant la migration du module 2.
Bien que le code du module 18 soit "annoncé" comme un exemple d'application Python 2, la source elle-même est compatible avec Python 2 et 3, et elle le reste même après la migration vers Cloud Pub/Sub (et Cloud NDB) dans le module 19.
Ce tutoriel comprend les étapes suivantes :
- Configuration/Préparation
- Mettre à jour la configuration
- Modifier le code de l'application
3. Configuration/Préparation
Cette section explique comment effectuer les opérations suivantes :
- Configurer votre projet Cloud
- Obtenir un exemple d'application de référence
- (Re)Déployer et valider l'application de référence
- Activer de nouveaux services/API Google Cloud
Ces étapes vous permettent de commencer avec un code fonctionnel et de vous assurer qu'il est prêt à être migré vers les services cloud.
1. Configurer le projet
Si vous avez terminé l'atelier de programmation du module 18, réutilisez le même projet (et le même code). Vous pouvez également créer un projet ou réutiliser un autre projet existant. Assurez-vous que le projet dispose d'un compte de facturation actif et d'une application App Engine activée. Trouvez l'ID de votre projet, car vous en aurez besoin pendant cet atelier de programmation. Utilisez-le chaque fois que vous rencontrez la variable PROJECT_ID.
2. Obtenir un exemple d'application de référence
L'une des conditions préalables est de disposer d'une application App Engine fonctionnelle du module 18. Vous pouvez donc suivre l'atelier de programmation correspondant (recommandé, lien ci-dessus) ou copier le code du module 18 depuis le dépôt. Que vous utilisiez votre application ou la nôtre, c'est ici que nous allons commencer ("START"). Cet atelier de programmation vous guide tout au long de la migration jusqu'à obtenir un code similaire à celui du dossier du dépôt du module 19 ("FINISH").
- START : Dossier du module 18 (Python 2)
- FINISH : Dossier du module 19 (Python 2 et 3)
- Dépôt complet (pour cloner ou télécharger le fichier ZIP)
Quel que soit le module 18 que vous utilisez, le dossier doit ressembler à ce qui suit, avec éventuellement un dossier lib :
$ ls README.md appengine_config.py queue.yaml templates app.yaml main.py requirements.txt
3. (Re)Déployer et valider l'application de référence
Pour déployer l'application du module 18, procédez comme suit :
- Supprimez le dossier
lib, le cas échéant, puis exécutezpip install -t lib -r requirements.txtpour le remplir à nouveau.libSi Python 2 et Python 3 sont tous les deux installés sur votre machine de développement, vous devrez peut-être utiliserpip2à la place. - Assurez-vous d'avoir installé et initialisé l'outil de ligne de commande
gcloud, et d'avoir consulté son utilisation. - (Facultatif) Définissez votre projet Cloud avec
gcloud config set projectPROJECT_IDsi vous ne souhaitez pas saisirPROJECT_IDà chaque commandegcloudque vous exécutez. - Déployez l'exemple d'application avec
gcloud app deploy - Vérifiez que l'application s'exécute comme prévu et sans problème. Si vous avez terminé l'atelier de programmation du module 18, l'application affiche les visiteurs les plus fréquents ainsi que les visites les plus récentes (illustrées ci-dessous). Si ce n'est pas le cas, il est possible qu'aucun nombre de visiteurs ne soit disponible.
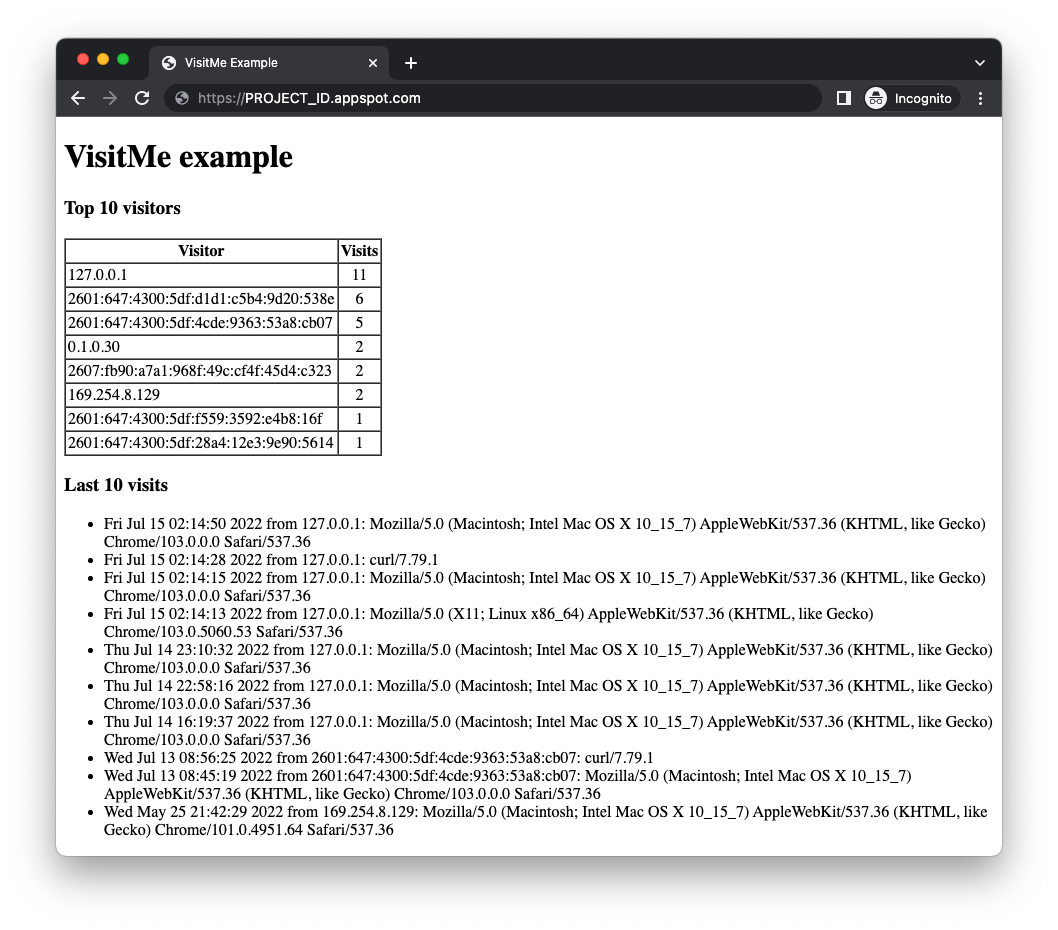
Avant de migrer l'exemple d'application du module 18, vous devez d'abord activer les services Cloud que l'application modifiée utilisera.
4. Activer de nouveaux services/API Google Cloud
L'ancienne application utilisait les services groupés App Engine, qui ne nécessitent aucune configuration supplémentaire. En revanche, les services Cloud autonomes en nécessitent une. L'application mise à jour utilisera à la fois Cloud Pub/Sub et Cloud Datastore (via la bibliothèque cliente Cloud NDB). App Engine et les deux API Cloud disposent de quotas "Toujours sans frais". Tant que vous ne dépassez pas ces limites, vous ne devriez pas être facturé pour ce tutoriel. Vous pouvez activer les API Cloud depuis la console Cloud ou la ligne de commande, selon vos préférences.
Depuis Cloud Console
Accédez à la page Bibliothèque du gestionnaire d'API (pour le bon projet) dans la console Cloud, puis recherchez les API Cloud Datastore et Cloud Pub/Sub à l'aide de la barre de recherche au milieu de la page :
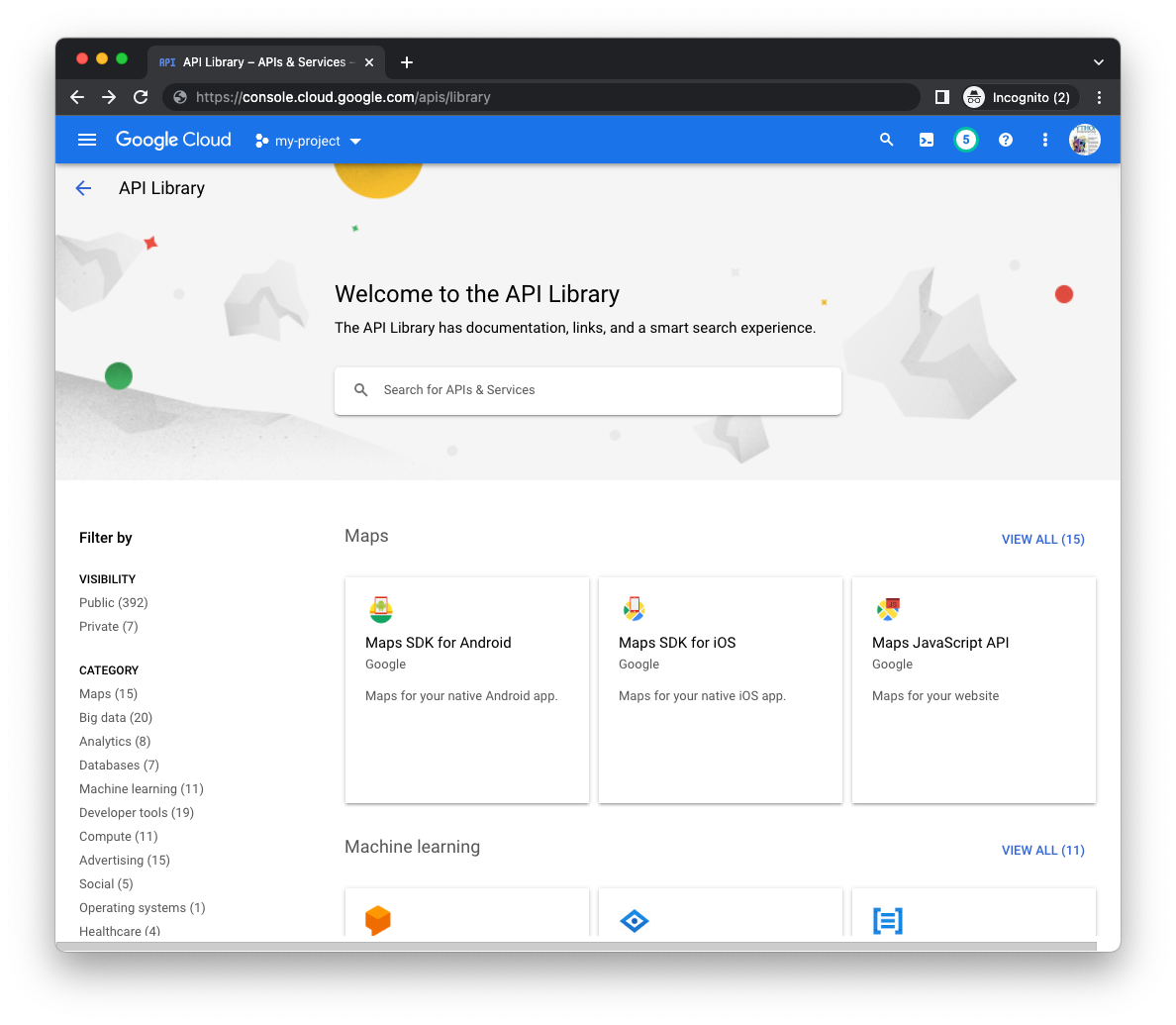
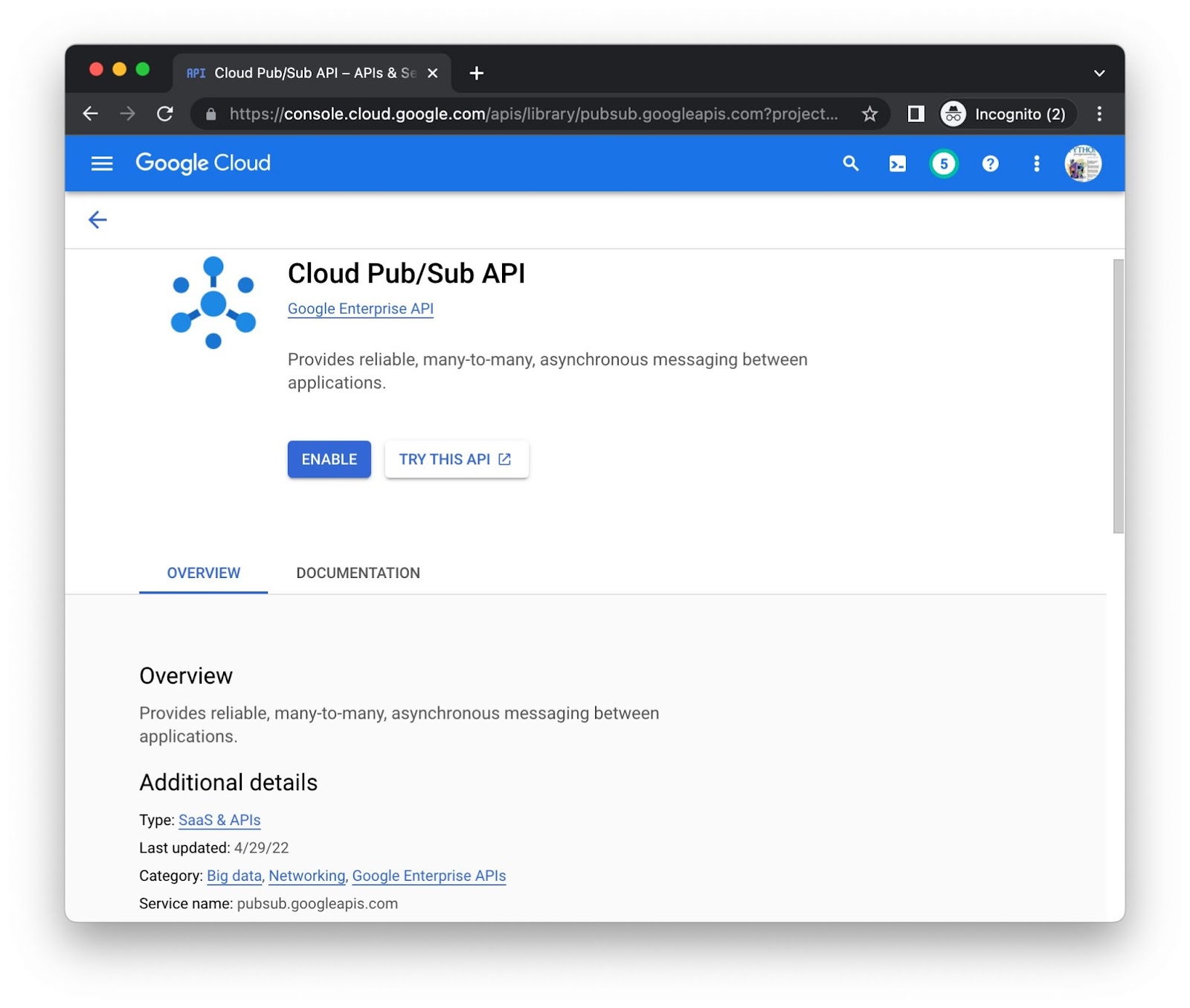
Cliquez sur le bouton Activer pour chaque API séparément. Vous serez peut-être invité à fournir des informations de facturation. Par exemple, voici la page de la bibliothèque d'API Cloud Pub/Sub :
Depuis la ligne de commande
Bien que l'activation des API à partir de la console soit visuellement informative, certains utilisateurs préfèrent la ligne de commande. Exécutez la commande gcloud services enable pubsub.googleapis.com datastore.googleapis.com pour activer les deux API en même temps :
$ gcloud services enable pubsub.googleapis.com datastore.googleapis.com Operation "operations/acat.p2-aaa-bbb-ccc-ddd-eee-ffffff" finished successfully.
Vous serez peut-être invité à fournir des informations de facturation. Si vous souhaitez activer d'autres API Cloud et connaître leurs URI, vous les trouverez en bas de la page de la bibliothèque de chaque API. Par exemple, observez pubsub.googleapis.com comme "Nom du service" en bas de la page Pub/Sub ci-dessus.
Une fois ces étapes terminées, votre projet pourra accéder aux API. Il est maintenant temps de mettre à jour l'application pour utiliser ces API.
4. Créer les ressources Pub/Sub
Récapitulons l'ordre de séquence du workflow Task Queue du module 18 :
- Le module 18 utilisait le fichier
queue.yamlpour créer une file d'attente de retrait nomméepullq. - L'application ajoute des tâches à la file d'attente de retrait pour suivre les visiteurs.
- Les tâches sont finalement traitées par un nœud de calcul, loué pour une durée limitée (une heure).
- Les tâches sont exécutées pour comptabiliser le nombre de visiteurs récents.
- Les tâches sont supprimées de la file d'attente une fois terminées.
Vous allez répliquer un workflow semblable avec Pub/Sub. La section suivante présente la terminologie de base de Pub/Sub, avec trois façons différentes de créer les ressources Pub/Sub nécessaires.
Terminologie de la file d'attente de tâches App Engine (extraction) et de Cloud Pub/Sub
Pour passer à Pub/Sub, vous devez légèrement modifier votre vocabulaire. Vous trouverez ci-dessous les principales catégories, ainsi que les termes associés pour les deux produits. Consultez également le guide de migration, qui présente des comparaisons similaires.
- Structure des données de mise en file d'attente : avec les files d'attente de tâches, les données sont placées dans des files d'attente de retrait, tandis qu'avec Pub/Sub, elles sont placées dans des sujets.
- Unités de données mises en file d'attente : les tâches de retrait avec Task Queue sont appelées messages avec Pub/Sub.
- Processeurs de données : avec Task Queue, les workers accèdent aux tâches de retrait. Avec Pub/Sub, vous avez besoin d'abonnements/abonnés pour recevoir des messages.
- Extraction de données : louer une tâche pull revient à extraire un message d'un sujet (via un abonnement).
- Nettoyage/Finalisation : supprimer une tâche Task Queues d'une file d'attente de retrait une fois qu'elle est terminée est analogue à confirmer un message Pub/Sub.
Bien que le produit de mise en file d'attente change, le workflow reste relativement similaire :
- Au lieu d'une file d'attente, l'application utilise un sujet nommé
pullq. - Au lieu d'ajouter des tâches à une file d'attente de retrait, l'application envoie des messages à un sujet (
pullq). - Au lieu qu'un nœud de calcul loue des tâches à partir de la file d'attente de retrait, un abonné nommé
workerextrait les messages du sujetpullq. - L'application traite les charges utiles des messages, en incrémentant le nombre de visiteurs dans Datastore.
- Au lieu de supprimer les tâches de la file d'attente, l'application confirme la réception des messages traités.
Avec Task Queue, la configuration consiste à créer la file d'attente de retrait. Avec Pub/Sub, la configuration nécessite de créer à la fois un sujet et un abonnement. Dans le module 18, nous avons traité queue.yaml en dehors de l'exécution de l'application. Nous devons maintenant faire de même avec Pub/Sub.
Vous pouvez créer des thèmes et des abonnements de trois manières différentes :
- Depuis la console Cloud
- Depuis la ligne de commande
- À partir du code (script Python court)
Choisissez l'une des options ci-dessous et suivez les instructions correspondantes pour créer vos ressources Pub/Sub.
Depuis la console Cloud
Pour créer un sujet à partir de la console Cloud, procédez comme suit :
- Accédez à la page Sujets Pub/Sub de la console Cloud.
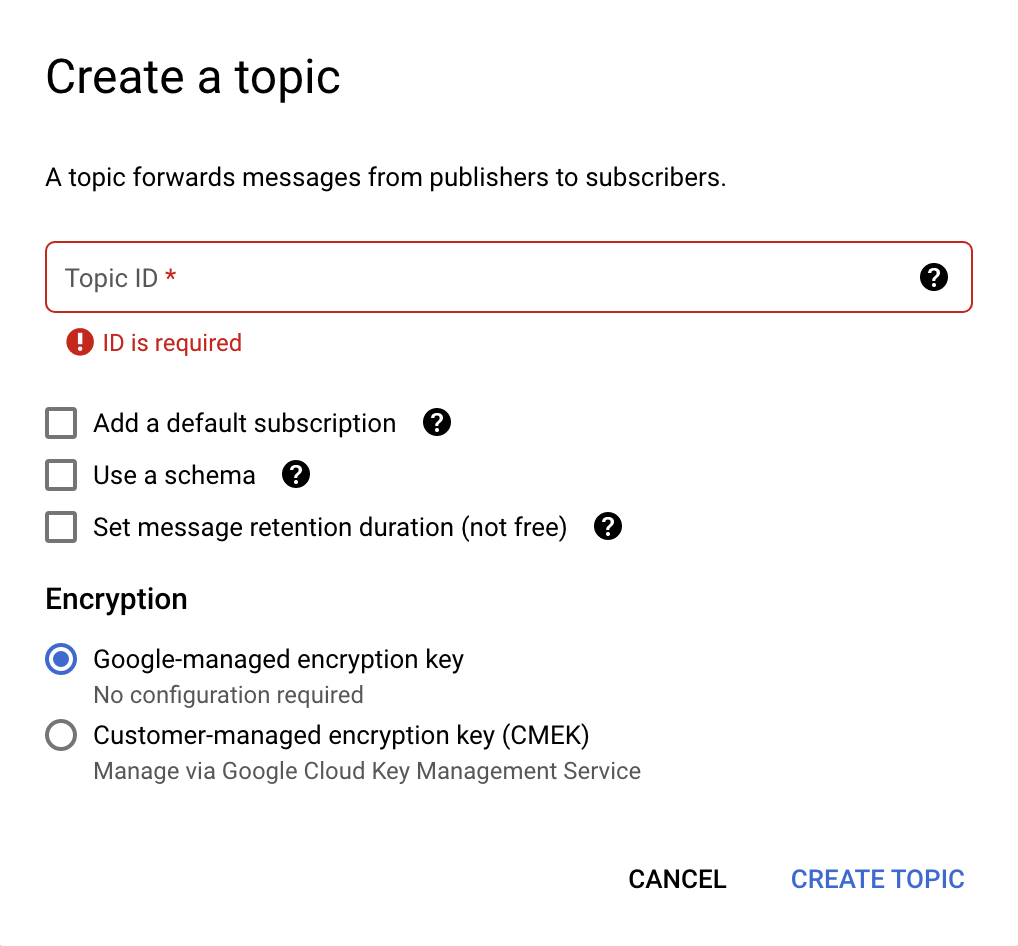
- Cliquez sur Créer un sujet en haut de la page. Une nouvelle boîte de dialogue s'ouvre (voir l'image ci-dessous).
- Dans le champ ID du sujet, saisissez
pullq. - Décochez toutes les options cochées, puis sélectionnez Clé de chiffrement gérée par Google.
- Cliquez sur le bouton Créer un sujet.
Voici à quoi ressemble la boîte de dialogue de création de sujet :
Maintenant que vous avez un sujet, vous devez créer un abonnement pour ce sujet :
- Accédez à la page Abonnements Pub/Sub de la console Cloud.
- Cliquez sur Créer un abonnement en haut de la page (voir l'image ci-dessous).
- Saisissez
workerdans le champ ID d'abonnement. - Sélectionnez
pullqdans le menu déroulant Sélectionner un sujet Cloud Pub/Sub, en notant son "chemin d'accès complet", par exempleprojects/PROJECT_ID/topics/pullq. - Pour Type de distribution, sélectionnez Pull.
- Laissez toutes les autres options telles quelles, puis cliquez sur le bouton Créer.
Voici à quoi ressemble l'écran de création d'abonnement :
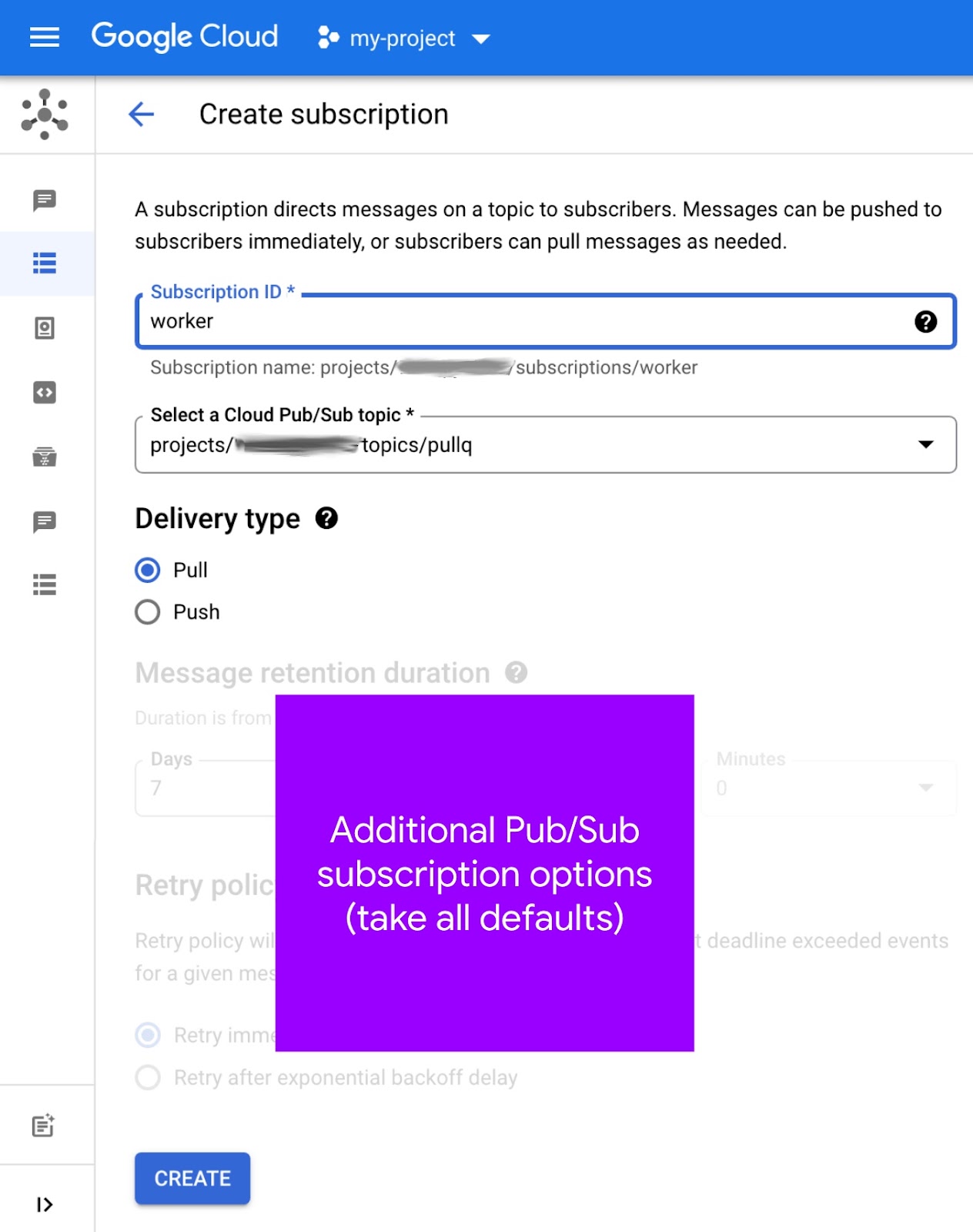
Vous pouvez également créer un abonnement à partir de la page Sujets. Ce "raccourci" peut vous aider à associer des sujets à des abonnements. Pour en savoir plus sur la création d'abonnements, consultez la documentation.
Depuis la ligne de commande
Les utilisateurs Pub/Sub peuvent créer des sujets et des abonnements avec les commandes gcloud pubsub topics create TOPIC_ID et gcloud pubsub subscriptions create SUBSCRIPTION_ID --topic=TOPIC_ID, respectivement. L'exécution de ces commandes avec un TOPIC_ID de pullq et un SUBSCRIPTION_ID de worker génère la sortie suivante pour le projet PROJECT_ID :
$ gcloud pubsub topics create pullq Created topic [projects/PROJECT_ID/topics/pullq]. $ gcloud pubsub subscriptions create worker --topic=pullq Created subscription [projects/PROJECT_ID/subscriptions/worker].
Consultez également cette page dans la documentation du guide de démarrage rapide. L'utilisation de la ligne de commande peut simplifier les workflows dans lesquels des thèmes et des abonnements sont créés régulièrement. Ces commandes peuvent être utilisées dans des scripts shell à cet effet.
À partir du code (script Python court)
Une autre façon d'automatiser la création de sujets et d'abonnements consiste à utiliser l'API Pub/Sub dans le code source. Vous trouverez ci-dessous le code du script maker.py dans le dossier du dépôt du module 19.
from __future__ import print_function
import google.auth
from google.api_core import exceptions
from google.cloud import pubsub
_, PROJECT_ID = google.auth.default()
TOPIC = 'pullq'
SBSCR = 'worker'
ppc_client = pubsub.PublisherClient()
psc_client = pubsub.SubscriberClient()
TOP_PATH = ppc_client.topic_path(PROJECT_ID, TOPIC)
SUB_PATH = psc_client.subscription_path(PROJECT_ID, SBSCR)
def make_top():
try:
top = ppc_client.create_topic(name=TOP_PATH)
print('Created topic %r (%s)' % (TOPIC, top.name))
except exceptions.AlreadyExists:
print('Topic %r already exists at %r' % (TOPIC, TOP_PATH))
def make_sub():
try:
sub = psc_client.create_subscription(name=SUB_PATH, topic=TOP_PATH)
print('Subscription created %r (%s)' % (SBSCR, sub.name))
except exceptions.AlreadyExists:
print('Subscription %r already exists at %r' % (SBSCR, SUB_PATH))
try:
psc_client.close()
except AttributeError: # special Py2 handler for grpcio<1.12.0
pass
make_top()
make_sub()
L'exécution de ce script génère le résultat attendu (à condition qu'il n'y ait pas d'erreurs) :
$ python3 maker.py Created topic 'pullq' (projects/PROJECT_ID/topics/pullq) Subscription created 'worker' (projects/PROJECT_ID/subscriptions/worker)
L'appel de l'API pour créer des ressources existantes entraîne une exception google.api_core.exceptions.AlreadyExists générée par la bibliothèque cliente, qui est gérée de manière fluide par le script :
$ python3 maker.py Topic 'pullq' already exists at 'projects/PROJECT_ID/topics/pullq' Subscription 'worker' already exists at 'projects/PROJECT_ID/subscriptions/worker'
Si vous débutez avec Pub/Sub, consultez le livre blanc sur l'architecture Pub/Sub pour en savoir plus.
5. Mettre à jour la configuration
Les mises à jour de configuration incluent la modification de différents fichiers de configuration ainsi que la création de l'équivalent des files d'attente de retrait App Engine, mais dans l'écosystème Cloud Pub/Sub.
Supprimer queue.yaml
Nous abandonnons complètement les files d'attente de tâches. Supprimez donc queue.yaml, car Pub/Sub n'utilise pas ce fichier. Au lieu de créer une file d'attente pull, vous allez créer un sujet (et un abonnement) Pub/Sub.
requirements.txt
Ajoutez google-cloud-ndb et google-cloud-pubsub à requirements.txt pour joindre flask à partir du module 18. Votre fichier requirements.txt du module 19 modifié devrait maintenant ressembler à ceci :
flask
google-cloud-ndb
google-cloud-pubsub
Ce fichier requirements.txt ne comporte aucun numéro de version, ce qui signifie que les dernières versions sont sélectionnées. En cas d'incompatibilité, suivez la procédure standard d'utilisation des numéros de version pour verrouiller les versions fonctionnelles d'une application.
app.yaml
Les modifications apportées à app.yaml diffèrent selon que vous restez avec Python 2 ou que vous passez à Python 3.
Python 2
La mise à jour ci-dessus de requirements.txt ajoute l'utilisation des bibliothèques clientes Google Cloud. Elles nécessitent une assistance supplémentaire d'App Engine, à savoir quelques bibliothèques intégrées, setuptools et grpcio. L'utilisation de bibliothèques intégrées nécessite une section libraries dans app.yaml et les numéros de version des bibliothèques, ou "latest" pour la dernière version disponible sur les serveurs App Engine. Le module 18 app.yaml ne comporte pas encore l'une de ces sections :
AVANT :
runtime: python27
threadsafe: yes
api_version: 1
handlers:
- url: /.*
script: main.app
Ajoutez une section libraries à app.yaml, ainsi que des entrées pour setuptools et grpcio, en sélectionnant leurs dernières versions. Ajoutez également une entrée d'espace réservé runtime pour Python 3, mise en commentaire avec une version 3.x actuelle (par exemple, 3.10 au moment de la rédaction). Avec ces modifications, app.yaml se présente désormais comme suit :
APRÈS :
#runtime: python310
runtime: python27
threadsafe: yes
api_version: 1
handlers:
- url: /.*
script: main.app
libraries:
- name: setuptools
version: latest
- name: grpcio
version: latest
Python 3
Pour les utilisateurs de Python 3 et app.yaml, il s'agit de supprimer des éléments. Dans cette section, vous allez supprimer la section handlers, les directives threadsafe et api_version, et vous ne créerez pas de section libraries.
Les environnements d'exécution de deuxième génération ne fournissent pas de bibliothèques tierces intégrées. Par conséquent, une section libraries n'est pas nécessaire dans app.yaml. De plus, il n'est plus nécessaire de copier (parfois appelé "vendorisation" ou "auto-regroupement") les non-packages tiers intégrés. Il vous suffit de lister les bibliothèques tierces que votre application utilise dans requirements.txt.
La section handlers de app.yaml permet de spécifier les gestionnaires de fichiers statiques et d'application (script). Étant donné que l'environnement d'exécution Python 3 exige que les frameworks Web effectuent leur propre routage, tous les gestionnaires de scripts doivent être définis sur auto. Si votre application (comme celle du module 18) ne diffuse pas de fichiers statiques, tous les itinéraires seraient alors auto, ce qui les rendrait inutiles. Par conséquent, la section handlers n'est pas non plus nécessaire. Supprimez-la.
Enfin, ni la directive threadsafe ni la directive api_version ne sont utilisées dans Python 3. Supprimez-les également. En résumé, vous devez supprimer toutes les sections de app.yaml afin qu'il ne reste que la directive runtime, qui spécifie une version moderne de Python 3, par exemple 3.10. Voici à quoi ressemble app.yaml avant et après ces modifications :
AVANT :
runtime: python27
threadsafe: yes
api_version: 1
handlers:
- url: /.*
script: main.app
APRÈS :
runtime: python310
Pour ceux qui ne sont pas prêts à tout supprimer de leur app.yaml pour Python 3, nous avons fourni un fichier app3.yaml alternatif dans le dossier du dépôt du module 19. Si vous souhaitez l'utiliser pour les déploiements, veillez à ajouter ce nom de fichier à la fin de votre commande : gcloud app deploy app3.yaml (sinon, l'application sera déployée par défaut avec le fichier app.yaml Python 2 que vous avez laissé inchangé).
appengine_config.py
Si vous passez à Python 3, vous n'avez pas besoin de appengine_config.py. Supprimez-le. Il n'est pas nécessaire de le faire, car la prise en charge des bibliothèques tierces ne nécessite que de les spécifier dans requirements.txt. Si vous utilisez Python 2, lisez la suite.
Le fichier appengine_config.py du module 18 contient le code approprié pour prendre en charge les bibliothèques tierces, par exemple Flask et les bibliothèques clientes Cloud qui viennent d'être ajoutées à requirements.txt :
AVANT :
from google.appengine.ext import vendor
# Set PATH to your libraries folder.
PATH = 'lib'
# Add libraries installed in the PATH folder.
vendor.add(PATH)
Toutefois, ce code seul ne suffit pas pour prendre en charge les bibliothèques intégrées qui viennent d'être ajoutées (setuptools, grpcio). Quelques lignes supplémentaires sont nécessaires. Mettez donc à jour appengine_config.py pour qu'il ressemble à ceci :
APRÈS :
import pkg_resources
from google.appengine.ext import vendor
# Set PATH to your libraries folder.
PATH = 'lib'
# Add libraries installed in the PATH folder.
vendor.add(PATH)
# Add libraries to pkg_resources working set to find the distribution.
pkg_resources.working_set.add_entry(PATH)
Pour en savoir plus sur les modifications requises pour prendre en charge les bibliothèques clientes Cloud, consultez la documentation sur la migration des services groupés.
Autres mises à jour de configuration
Si vous avez un dossier lib, supprimez-le. Si vous utilisez Python 2, réapprovisionnez le dossier lib en exécutant la commande suivante :
pip install -t lib -r requirements.txt # or pip2
Si Python 2 et Python 3 sont tous les deux installés sur votre système de développement, vous devrez peut-être utiliser pip2 au lieu de pip.
6. Modifier le code de l'application
Cette section présente les modifications apportées au fichier d'application principal, main.py, en remplaçant l'utilisation des files d'attente pull d'App Engine Task Queue par Cloud Pub/Sub. Aucune modification n'a été apportée au modèle Web templates/index.html. Les deux applications doivent fonctionner de manière identique et afficher les mêmes données.
Mettre à jour les importations et l'initialisation
Plusieurs modifications ont été apportées aux importations et à l'initialisation :
- Pour les importations, remplacez App Engine NDB et Task Queue par Cloud NDB et Pub/Sub.
- Renommez
pullqen remplaçant le nomQUEUEpar un nomTOPIC. - Avec les tâches d'extraction, le nœud de calcul les louait pendant une heure, mais avec Pub/Sub, les délais d'attente sont mesurés pour chaque message. Supprimez donc la constante
HOUR. - Les API Cloud nécessitent l'utilisation d'un client d'API. Initialisez-les pour Cloud NDB et Cloud Pub/Sub, ce dernier fournissant des clients pour les sujets et les abonnements.
- Pub/Sub nécessite l'ID du projet Cloud. Importez-le et récupérez-le à partir de
google.auth.default(). - Pub/Sub exige des "noms de chemin complets" pour les sujets et les abonnements. Créez-les à l'aide des fonctions pratiques
*_path().
Vous trouverez ci-dessous les importations et l'initialisation du module 18, suivies de l'apparence des sections après l'implémentation des modifications ci-dessus. La majeure partie du nouveau code concerne diverses ressources Pub/Sub :
AVANT :
from flask import Flask, render_template, request
from google.appengine.api import taskqueue
from google.appengine.ext import ndb
HOUR = 3600
LIMIT = 10
TASKS = 1000
QNAME = 'pullq'
QUEUE = taskqueue.Queue(QNAME)
app = Flask(__name__)
APRÈS :
from flask import Flask, render_template, request
import google.auth
from google.cloud import ndb, pubsub
LIMIT = 10
TASKS = 1000
TOPIC = 'pullq'
SBSCR = 'worker'
app = Flask(__name__)
ds_client = ndb.Client()
ppc_client = pubsub.PublisherClient()
psc_client = pubsub.SubscriberClient()
_, PROJECT_ID = google.auth.default()
TOP_PATH = ppc_client.topic_path(PROJECT_ID, TOPIC)
SUB_PATH = psc_client.subscription_path(PROJECT_ID, SBSCR)
Accéder aux mises à jour du modèle de données
Le modèle de données Visit ne change pas. L'accès à Datastore nécessite l'utilisation explicite du gestionnaire de contexte du client de l'API Cloud NDB, ds_client.context(). Dans le code, cela signifie que vous encapsulez les appels Datastore dans store_visit() et fetch_visits() à l'intérieur des blocs with Python. Cette mise à jour est identique à celle abordée dans le module 2.
Le changement le plus pertinent pour Pub/Sub consiste à remplacer la mise en file d'attente d'une tâche de retrait de la file d'attente des tâches par la publication d'un message Pub/Sub dans le sujet pullq. Vous trouverez ci-dessous le code avant et après ces modifications :
AVANT :
class Visit(ndb.Model):
'Visit entity registers visitor IP address & timestamp'
visitor = ndb.StringProperty()
timestamp = ndb.DateTimeProperty(auto_now_add=True)
def store_visit(remote_addr, user_agent):
'create new Visit in Datastore and queue request to bump visitor count'
Visit(visitor='{}: {}'.format(remote_addr, user_agent)).put()
QUEUE.add(taskqueue.Task(payload=remote_addr, method='PULL'))
def fetch_visits(limit):
'get most recent visits'
return Visit.query().order(-Visit.timestamp).fetch(limit)
APRÈS :
class Visit(ndb.Model):
'Visit entity registers visitor IP address & timestamp'
visitor = ndb.StringProperty()
timestamp = ndb.DateTimeProperty(auto_now_add=True)
def store_visit(remote_addr, user_agent):
'create new Visit in Datastore and queue request to bump visitor count'
with ds_client.context():
Visit(visitor='{}: {}'.format(remote_addr, user_agent)).put()
ppc_client.publish(TOP_PATH, remote_addr.encode('utf-8'))
def fetch_visits(limit):
'get most recent visits'
with ds_client.context():
return Visit.query().order(-Visit.timestamp).fetch(limit)
Mises à jour du modèle de données VisitorCount
Le modèle de données VisitorCount ne change pas et fetch_counts(), sauf pour l'encapsulation de sa requête Datastore dans un bloc with, comme illustré ci-dessous :
AVANT :
class VisitorCount(ndb.Model):
visitor = ndb.StringProperty(repeated=False, required=True)
counter = ndb.IntegerProperty()
def fetch_counts(limit):
'get top visitors'
return VisitorCount.query().order(-VisitorCount.counter).fetch(limit)
APRÈS :
class VisitorCount(ndb.Model):
visitor = ndb.StringProperty(repeated=False, required=True)
counter = ndb.IntegerProperty()
def fetch_counts(limit):
'get top visitors'
with ds_client.context():
return VisitorCount.query().order(-VisitorCount.counter).fetch(limit)
Mettre à jour le code du worker
Le code du nœud de calcul est mis à jour pour remplacer NDB par Cloud NDB et Task Queue par Pub/Sub, mais son workflow reste le même.
- Encapsulez les appels Datastore dans le bloc
withdu gestionnaire de contexte Cloud NDB. - Le nettoyage de la file d'attente des tâches consiste à supprimer toutes les tâches de la file d'attente d'extraction. Avec Pub/Sub, les "ID de confirmation" sont collectés dans
acks, puis supprimés/confirmés à la fin. - Les tâches de retrait de la file d'attente des tâches sont louées de la même manière que les messages Pub/Sub sont retirés. Alors que les tâches d'extraction sont supprimées avec les objets de tâche eux-mêmes, les messages Pub/Sub sont supprimés à l'aide de leurs ID de confirmation.
- Les charges utiles des messages Pub/Sub nécessitent des octets (et non des chaînes Python). Par conséquent, un encodage et un décodage UTF-8 sont nécessaires lors de la publication et de l'extraction de messages à partir d'un sujet, respectivement.
Remplacez log_visitors() par le code mis à jour ci-dessous, qui implémente les modifications que nous venons de décrire :
AVANT :
@app.route('/log')
def log_visitors():
'worker processes recent visitor counts and updates them in Datastore'
# tally recent visitor counts from queue then delete those tasks
tallies = {}
tasks = QUEUE.lease_tasks(HOUR, TASKS)
for task in tasks:
visitor = task.payload
tallies[visitor] = tallies.get(visitor, 0) + 1
if tasks:
QUEUE.delete_tasks(tasks)
# increment those counts in Datastore and return
for visitor in tallies:
counter = VisitorCount.query(VisitorCount.visitor == visitor).get()
if not counter:
counter = VisitorCount(visitor=visitor, counter=0)
counter.put()
counter.counter += tallies[visitor]
counter.put()
return 'DONE (with %d task[s] logging %d visitor[s])\r\n' % (
len(tasks), len(tallies))
APRÈS :
@app.route('/log')
def log_visitors():
'worker processes recent visitor counts and updates them in Datastore'
# tally recent visitor counts from queue then delete those tasks
tallies = {}
acks = set()
rsp = psc_client.pull(subscription=SUB_PATH, max_messages=TASKS)
msgs = rsp.received_messages
for rcvd_msg in msgs:
acks.add(rcvd_msg.ack_id)
visitor = rcvd_msg.message.data.decode('utf-8')
tallies[visitor] = tallies.get(visitor, 0) + 1
if acks:
psc_client.acknowledge(subscription=SUB_PATH, ack_ids=acks)
try:
psc_client.close()
except AttributeError: # special handler for grpcio<1.12.0
pass
# increment those counts in Datastore and return
if tallies:
with ds_client.context():
for visitor in tallies:
counter = VisitorCount.query(VisitorCount.visitor == visitor).get()
if not counter:
counter = VisitorCount(visitor=visitor, counter=0)
counter.put()
counter.counter += tallies[visitor]
counter.put()
return 'DONE (with %d task[s] logging %d visitor[s])\r\n' % (
len(msgs), len(tallies))
Aucune modification n'a été apportée au gestionnaire d'application principal root(). Aucune modification n'est nécessaire dans le fichier de modèle HTML, templates/index.html. Toutes les mises à jour nécessaires sont donc effectuées. Félicitations pour votre nouvelle application du module 19 utilisant Cloud Pub/Sub !
7. Résumé/Nettoyage
Déployez votre application pour vérifier qu'elle fonctionne comme prévu et dans toute sortie reflétée. Exécutez également le nœud de calcul pour traiter le nombre de visiteurs. Après la validation de l'application, effectuez les étapes de nettoyage et réfléchissez aux prochaines étapes.
Déployer et vérifier l'application
Assurez-vous d'avoir déjà créé le sujet pullq et l'abonnement worker. Si vous avez terminé cette étape et que votre application exemple est prête, déployez votre application avec gcloud app deploy. Le résultat doit être identique à celui de l'application du module 18, sauf que vous avez remplacé l'intégralité du mécanisme de mise en file d'attente sous-jacent :
L'interface Web de l'application vérifie désormais que cette partie de l'application fonctionne. Bien que cette partie de l'application interroge et affiche correctement les visiteurs les plus fréquents et les visites les plus récentes, n'oubliez pas que l'application enregistre cette visite et crée une tâche d'extraction pour ajouter ce visiteur au nombre total. Cette tâche est désormais en file d'attente pour être traitée.
Vous pouvez exécuter cette opération avec un service de backend App Engine, un job cron, en accédant à /log ou en envoyant une requête HTTP en ligne de commande. Voici un exemple d'exécution et de sortie de l'appel du code du worker avec curl (remplacez PROJECT_ID par votre propre valeur) :
$ curl https://PROJECT_ID.appspot.com/log DONE (with 1 task[s] logging 1 visitor[s])
Le nombre mis à jour sera ensuite reflété lors de la prochaine visite du site Web. Et voilà !
Effectuer un nettoyage
Général
Si vous avez terminé pour le moment, nous vous recommandons de désactiver votre application App Engine pour éviter d'être facturé. Toutefois, si vous souhaitez effectuer d'autres tests ou expériences, la plate-forme App Engine dispose d'un quota sans frais. Tant que vous ne dépassez pas ce niveau d'utilisation, aucun frais ne devrait vous être facturé. Cela concerne le calcul, mais des frais peuvent également s'appliquer aux services App Engine concernés. Pour en savoir plus, consultez la page de tarification. Si cette migration implique d'autres services Cloud, ceux-ci sont facturés séparément. Dans les deux cas, le cas échéant, consultez la section "Spécifique à cet atelier de programmation" ci-dessous.
Pour être tout à fait transparent, le déploiement sur une plate-forme de calcul sans serveur Google Cloud comme App Engine entraîne de légers coûts de compilation et de stockage. Cloud Build et Cloud Storage disposent chacun de leur propre quota sans frais. Le stockage de cette image utilise une partie de ce quota. Toutefois, il est possible que vous résidiez dans une région où ce niveau sans frais n'est pas disponible. Veillez donc à surveiller votre utilisation de l'espace de stockage pour minimiser les coûts potentiels. Voici quelques "dossiers" Cloud Storage spécifiques que vous devez examiner :
console.cloud.google.com/storage/browser/LOC.artifacts.PROJECT_ID.appspot.com/containers/imagesconsole.cloud.google.com/storage/browser/staging.PROJECT_ID.appspot.com- Les liens de stockage ci-dessus dépendent de votre
PROJECT_IDet de votre *LOC*ation. Par exemple, "us" si votre application est hébergée aux États-Unis.
En revanche, si vous ne souhaitez pas poursuivre avec cette application ni avec d'autres ateliers de programmation de migration associés et que vous souhaitez tout supprimer complètement, arrêtez votre projet.
Spécifique à cet atelier de programmation
Les services listés ci-dessous sont propres à cet atelier de programmation. Pour en savoir plus, consultez la documentation de chaque produit :
- Différents composants de Cloud Pub/Sub disposent d'un niveau sans frais. Déterminez votre utilisation globale pour mieux comprendre les implications en termes de coûts. Pour en savoir plus, consultez la page de tarification.
- Le service App Engine Datastore est fourni par Cloud Datastore (Cloud Firestore en mode Datastore), qui propose également un niveau sans frais. Pour en savoir plus, consultez sa page de tarification.
Étapes suivantes
Au-delà de ce tutoriel, voici d'autres modules de migration qui se concentrent sur l'abandon des anciens services groupés :
- Module 2 : migrer depuis App Engine
ndbvers Cloud NDB - Modules 7 à 9 : migrer d'App Engine Task Queue (tâches push) vers Cloud Tasks
- Modules 12 et 13 : migrer d'App Engine Memcache vers Cloud Memorystore
- Modules 15 et 16 : migrer d'App Engine Blobstore vers Cloud Storage
App Engine n'est plus la seule plate-forme sans serveur de Google Cloud. Si vous avez une petite application App Engine ou une application dont les fonctionnalités sont limitées et que vous souhaitez la transformer en microservice autonome, ou si vous souhaitez diviser une application monolithique en plusieurs composants réutilisables, ce sont de bonnes raisons d'envisager de passer à Cloud Functions. Si la conteneurisation fait désormais partie de votre workflow de développement d'applications, en particulier s'il s'agit d'un pipeline CI/CD (intégration continue/livraison ou déploiement continus), envisagez de migrer vers Cloud Run. Ces scénarios sont couverts par les modules suivants :
- Migrer d'App Engine vers Cloud Functions : consultez le module 11.
- Migrer d'App Engine vers Cloud Run : consultez le module 4 pour conteneuriser votre application avec Docker, ou le module 5 pour le faire sans conteneurs, sans connaissances sur Docker ni
Dockerfile.
Le passage à une autre plate-forme serverless est facultatif. Nous vous recommandons d'examiner les meilleures options pour vos applications et vos cas d'utilisation avant d'apporter des modifications.
Quel que soit le module de migration que vous envisagez ensuite, vous pouvez accéder à l'ensemble du contenu Serverless Migration Station (ateliers de programmation, vidéos, code source [le cas échéant]) dans son dépôt Open Source. Le README du dépôt fournit également des conseils sur les migrations à envisager et sur l'"ordre" pertinent des modules de migration.
8. Ressources supplémentaires
Vous trouverez ci-dessous des ressources supplémentaires pour les développeurs qui souhaitent en savoir plus sur ce module de migration ou sur des modules et produits associés. Vous y trouverez des liens vers le code, des informations sur la façon de nous faire part de vos commentaires sur ce contenu et divers éléments de documentation qui pourraient vous être utiles.
Problèmes/commentaires concernant les ateliers de programmation
Si vous rencontrez des problèmes avec cet atelier de programmation, commencez par faire une recherche avant de les signaler. Liens vers la recherche et la création d'un signalement :
Ressources de migration
Le tableau ci-dessous contient des liens vers les dossiers du dépôt pour les modules 18 (START) et 19 (FINISH).
Atelier de programmation | Python 2 | Python 3 |
(n/a) | ||
Module 19 (cet atelier de programmation) | (identique à Python 2, sauf que vous devez utiliser app3.yaml, sauf si vous avez mis à jour app.yaml comme indiqué ci-dessus) |
Références en ligne
Vous trouverez ci-dessous des ressources utiles pour ce tutoriel :
File d'attente de tâches d'App Engine
- Présentation d'App Engine Task Queue
- Présentation des files d'attente de tâches App Engine
- Exemple d'application complète de file d'attente pull App Engine Task Queue
- Créer des files d'attente de retrait Task Queue
- Vidéo de lancement de la file d'attente Google I/O 2011 ( exemple d'application Votelator)
- Documentation de référence sur
queue.yaml queue.yamlvs Cloud Tasks- Guide de migration des files d'attente de retrait vers Pub/Sub
Cloud Pub/Sub
- Page produit Cloud Pub/Sub
- Utiliser les bibliothèques clientes Pub/Sub
- Exemples de la bibliothèque cliente Python Pub/Sub
- Documentation de la bibliothèque cliente Python Pub/Sub
- Créer et gérer des sujets Pub/Sub
- Consignes concernant la dénomination des sujets Pub/Sub
- Créer et gérer des abonnements Pub/Sub
- Exemple d'application App Engine (flexible) (également déployable dans l'environnement standard ; Python 3)
- Dépôt de l'exemple d'application ci-dessus
- Abonnements pull Pub/Sub
- Abonnements push Pub/Sub
- Exemple d'application push Pub/Sub App Engine (Python 3)
- Dépôt d'application exemple App Engine Pub/Sub push
- Informations sur les tarifs de Pub/Sub
- Cloud Tasks ou Cloud Pub/Sub ? (push ou pull)
App Engine NDB et Cloud NDB (Datastore)
- Documentation App Engine NDB
- Dépôt App Engine NDB
- Documentation Google Cloud NDB
- Dépôt Google Cloud NDB
- Informations sur les tarifs de Cloud Datastore
Plate-forme App Engine
- Documentation App Engine
- Environnement d'exécution Python 2 App Engine (environnement standard)
- Utiliser les bibliothèques intégrées d'App Engine sur Python 2 App Engine
- Environnement d'exécution Python 3 App Engine (environnement standard)
- Différences entre les environnements d'exécution Python 2 et Python 3 App Engine (environnement standard)
- Guide de migration d'App Engine (environnement standard) de Python 2 vers Python 3
- Informations sur les tarifs et les quotas d'App Engine
- Lancement de la plate-forme App Engine de deuxième génération (2018)
- Comparer les plates-formes de première et de deuxième génération
- Compatibilité à long terme avec les anciens environnements d'exécution
- Exemples de migration de la documentation
- Exemples de migration issus de la communauté
Informations sur les autres clouds
- Python sur Google Cloud Platform
- Bibliothèques clientes Google Cloud Python
- Niveau "Toujours sans frais" de Google Cloud
- SDK Google Cloud (outil de ligne de commande
gcloud) - Toute la documentation Google Cloud
Vidéos
- Serverless Migration Station
- Expéditions sans serveur
- S'abonner à Google Cloud Tech
- S'abonner à Google Developers
Licence
Ce document est publié sous une licence Creative Commons Attribution 2.0 Generic.