
1. מבוא
| Kubeflow הוא ערכת כלים ללמידת מכונה ל-Kubernetes. הפרויקט מוקדש להפיכת פריסות של תהליכי עבודה של למידת מכונה (ML) ב-Kubernetes לפשוטות, לניידות ולניתנות להתאמה לעומס (scaling). המטרה היא לספק דרך פשוטה לפריסת מערכות קוד פתוח מהשורה הראשונה ללמידת מכונה בתשתיות מגוונות. |

איך נראה פריסת Kubeflow?
פריסת Kubeflow היא:
- נייד – פועל בכל אשכול Kubernetes, בין אם הוא נמצא ב-Google Cloud Platform (GCP), במקום או אצל ספקים שונים.
- ניתן להרחבה – אפשר להשתמש במשאבים משתנים, והמגבלה היחידה היא מספר המשאבים שהוקצו לאשכול Kubernetes.
- ניתן להרכבה – משופר באמצעות Service Workers כדי לפעול אופליין או ברשתות באיכות נמוכה.
זוהי דרך לארגן מיקרו-שירותים עם צימוד רופף כיחידה אחת ולפרוס אותם במיקומים שונים, בין אם זה מחשב נייד או הענן.
Codelab זה ידריך אתכם ביצירת פריסת Kubeflow משלכם באמצעות MiniKF, ובהרצת תהליך עבודה של Kubeflow Pipelines מתוך מחברת Jupyter.
מה תפַתחו
ב-Codelab הזה תלמדו איך ליצור צינור עיבוד נתונים מורכב למדע הנתונים באמצעות Kubeflow Pipelines, בלי להשתמש בפקודות CLI או ב-SDK. לא נדרש ידע ב-Kubernetes או ב-Docker. בסיום התהליך, התשתית שלכם תכלול:
- מכונה וירטואלית של MiniKF (Mini Kubeflow) שמתקינה באופן אוטומטי:
- Kubernetes (באמצעות Minikube)
- Kubeflow
- Kale, כלי להמרת קובצי Jupyter Notebooks למטרות כלליות לזרימות עבודה של Kubeflow Pipelines ( GitHub)
- Arrikto Rok לניהול גרסאות של נתונים ולשחזור תוצאות
מה תלמדו
- איך מתקינים את Kubeflow באמצעות MiniKF
- איך להמיר את קובצי ה-Notebook של Jupyter ל-Kubeflow Pipelines בלי להשתמש בפקודות CLI או ב-SDK
- איך מריצים Kubeflow Pipelines מתוך מחברת בלחיצת כפתור
- איך ליצור גרסאות אוטומטיות של הנתונים במחברת ובכל שלב בצינור
מה תצטרכו
- פרויקט פעיל ב-GCP שבו יש לכם הרשאות בעלים
זהו Codelab מתקדם שמתמקד ב-Kubeflow. למידע נוסף על הרקע ועל הפלטפורמה, אפשר לעיין במסמכי העזרה בנושא מבוא ל-Kubeflow. מושגים ובלוקים של קוד שלא רלוונטיים מוצגים בקצרה, ואתם יכולים פשוט להעתיק ולהדביק אותם.
2. הגדרת הסביבה
הגדרת מזהה הפרויקט ב-GCP ושם האשכול
כדי למצוא את מזהה הפרויקט, עוברים לחלונית 'דף הבית' ב-GCP Console, שנמצאת בתפריט ההמבורגר בפינה הימנית העליונה. אם המסך ריק, לוחצים על 'כן' בהנחיה כדי ליצור מרכז בקרה.

אם הפרויקט לא נבחר עדיין, לוחצים על Select a project:

בוחרים את הפרויקט. צריך להיות לכם רק אחד מהם:

3. התקנה של MiniKF
יצירת מכונת Compute
ב-GCP Marketplace, מחפשים את MiniKF.
בוחרים את המכונה הווירטואלית MiniKF של Arrikto.

לוחצים על הלחצן הפעלה ב-Compute Engine ובוחרים את הפרויקט.

בחלון Configure & Deploy (הגדרה ופריסה), בוחרים שם למופע MiniKF ומשאירים את אפשרויות ברירת המחדל. אחר כך לוחצים על הלחצן פריסה.

מחכים שהמכונה של MiniKF Compute תופעל.

כניסה ל-MiniKF
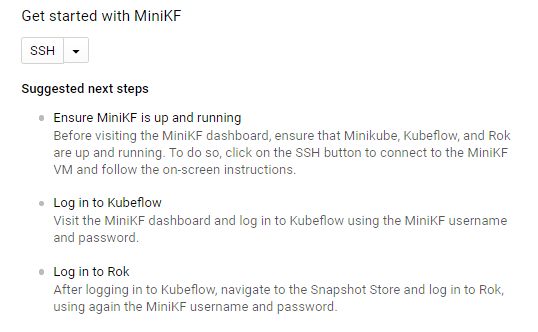
כשהמכונה הווירטואלית MiniKF פועלת, לוחצים על לחצן ה-SSH כדי להתחבר ולהיכנס. פועלים לפי ההוראות במסך כדי להריץ את הפקודה minikf, שתתחיל את הפריסה של Minikube, Kubeflow ו-Rok. הפעולה תימשך כמה דקות.
כניסה ל-Kubeflow
אחרי שההתקנה מסתיימת וכל הפודים מוכנים, עוברים אל מרכז הבקרה של MiniKF. מתחברים ל-Kubeflow באמצעות שם המשתמש והסיסמה של MiniKF.


משתמשי Chrome יראו את המסך הזה:

משתמשי Firefox יראו את המסך הזה:

משתמשי Safari יראו את המסך הזה:

כניסה ל-Rok
אחרי שנכנסים ל-Kubeflow, פותחים את התפריט הימני על ידי לחיצה על סמל האפשרויות הנוספות (3 קווים). עוברים אל Snapshot Store ומתחברים ל-Rok באמצעות שם המשתמש והסיסמה של MiniKF.


מעולה! הפריסה של MiniKF ב-GCP הושלמה בהצלחה. עכשיו אפשר ליצור מחברות, לכתוב את קוד ה-ML ולהריץ את Kubeflow Pipelines. משתמשים ב-Rok לניהול גרסאות של נתונים ולשחזור נתונים.
4. הרצת צינור (Pipeline) מתוך Notebook
במהלך הקטע הזה, תריצו את הדוגמה של הטיטאניק, תחרות ב-Kaggle שבה מנסים לחזות אילו נוסעים שרדו את טביעת הטיטאניק.
יצירת שרת Notebook
עוברים לקישור Notebook Servers (שרתי מחברות) במרכז הבקרה המרכזי של Kubeflow.

לוחצים על שרת חדש.

מזינים שם לשרת המחברות.

חשוב לוודא שבחרתם את התמונה הזו:
gcr.io/arrikto-public/tensorflow-1.14.0-notebook-cpu:kubecon-workshop
מוסיפים נפח נתונים חדש וריק בגודל 5GB ונותנים לו את השם data.

לוחצים על הפעלה כדי ליצור את שרת ה-Notebook.

כשהשרת של המחברת זמין, לוחצים על Connect כדי להתחבר אליו.

הורדת הנתונים ופנקס הרשימות
תיפתח כרטיסייה חדשה עם דף הנחיתה של JupyterLab. יוצרים טרמינל חדש ב-JupyterLab.

בחלון Terminal, מריצים את הפקודות האלה כדי לנווט לתיקייה data ולהוריד את המחברת ואת הנתונים שבהם תשתמשו בהמשך שיעור ה-Lab.
cd data/ git clone -b kubecon-workshop https://github.com/kubeflow-kale/examples
המאגר הזה מכיל סדרה של דוגמאות שנבחרו בקפידה עם נתונים ומחברות עם הערות. עוברים לתיקייה data/examples/titanic-ml-dataset/ בסרגל הצד ופותחים את המחברת titanic_dataset_ml.ipynb.

עיון בקוד ה-ML של האתגר Titanic
מריצים את ה-notebook שלב אחר שלב. שימו לב שהקוד נכשל כי חסרה ספרייה.

חוזרים לטרמינל ומתקינים את הספרייה החסרה.
pip3 install --user seaborn

מפעילים מחדש את ליבת ה-Notebook בלחיצה על סמל הרענון.

מריצים שוב את התא עם הספריות הנכונות שהותקנו ורואים שהפעולה מצליחה.
המרת מחברת ל-Kubeflow Pipeline
כדי להפעיל את Kale, לוחצים על סמל Kubeflow בחלונית הימנית.

בודקים את התלות של כל תא. אפשר לראות איך כמה תאים יכולים להיות חלק משלב אחד בצינור, ואיך שלב בצינור יכול להיות תלוי בשלבים קודמים.

לוחצים על הלחצן הידור והרצה.

צופים בהתקדמות של תמונת המצב.

צופים בהתקדמות של הפעלת צינור עיבוד הנתונים.

לוחצים על הקישור כדי לעבור לממשק המשתמש של Kubeflow Pipelines ולראות את ההרצה.

מחכים לסיום.


מעולה! הרצתם עכשיו צינור Kubeflow מקצה לקצה, החל מה-notebook שלכם.
5. שחזור עם תמונות מצב של נפח אחסון
בדיקת התוצאות
כדאי לעיין ביומנים של השלב השני לפני האחרון בצינור Results. שימו לב שכל התחזיות מציגות ציון של 100%. מדען נתונים מנוסה יזהה מיד את החשד. זהו סימן טוב לכך שהמודלים שלנו לא מבצעים הכללה, אלא מתאימים יתר על המידה למערך נתוני האימון. הסיבה לכך היא כנראה בעיה בנתונים שהמודלים צורכים.

שחזור המצב הקודם
למזלנו, Rok מטפל בניהול גרסאות של הנתונים וביצירה מחדש של כל הסביבה כפי שהיא הייתה בזמן שלחצתם על הלחצן Compile and Run (הידור והרצה). כך תוכלו לחזור אחורה בזמן ולראות את הנתונים והקוד שלכם. אז נחזור למצב של צינור הנתונים לפני אימון אחד מהמודלים ונראה מה קורה. מעיינים בשלב randomforest ואז לוחצים על Artifacts.

פועלים לפי השלבים במאמר בנושא Markdown, כלומר לוחצים על הקישור המתאים כדי להציג את התמונה ב-Rok UI.

מעתיקים את כתובת ה-URL של Rok.

עוברים לקישור Notebook Servers (שרתי מחברות).

לוחצים על שרת חדש.

מדביקים את כתובת ה-URL של Rok שהעתקתם קודם ולוחצים על הכפתור מילוי אוטומטי.

מזינים שם למחברת.

חשוב לוודא שבחרתם את התמונה הזו:
gcr.io/arrikto-public/tensorflow-1.14.0-notebook-cpu:kubecon-workshop
לוחצים על הפעלה כדי ליצור את שרת ה-Notebook.
כשהשרת של המחברת זמין, לוחצים על Connect כדי להתחבר אליו.

שימו לב: המחברת נפתחת בתא המדויק של שלב צינור עיבוד הנתונים שיצרתם.

ברקע, Kale חידש את מצב המחברת על ידי ייבוא של כל הספריות וטעינה של המשתנים מהשלבים הקודמים.
ניפוי באגים במצב קודם
מוסיפים פקודת הדפסה לתא הזה:
print(acc_random_forest)
מריצים את התא הפעיל על ידי הקשה על Shift + Return כדי לאמן מחדש את יער ההחלטה ולהדפיס את הניקוד. המספר הוא 100.

עכשיו נבדוק אם יש משהו מוזר בנתוני האימון. כדי לבדוק ולפתור את הבעיה הזו, מוסיפים תא מעל לסימון של יער אקראי. לשם כך, בוחרים את התא הקודם ולוחצים על סמל הפלוס (+).

מוסיפים את הטקסט הבא ומריצים את התא כדי להדפיס את קבוצת הנתונים לאימון.
train_df

אופס! העמודה עם תוויות האימון (Survived) נכללה בטעות כמאפייני קלט. המודל למד להתמקד בתכונה 'האם הנוסע שרד' ולהתעלם מכל השאר, וכך הוא מזוהם. העמודה הזו תואמת בדיוק ליעד של המודל ולא מופיעה במהלך החיזוי, ולכן צריך להסיר אותה ממערך הנתונים לאימון כדי לאפשר למודל ללמוד מהתכונות האחרות.
הוספת תיקון באג
כדי להסיר את העמודה הזו, עורכים את התא כדי להוסיף את הפקודה הבאה:
train_df.drop('Survived', axis=1, inplace=True)
train_df

מפעילים את Kale ומוודאים שהתא שמסיר את התוויות Survived הוא חלק משלב הצינור featureengineering (צבע המתאר שלו צריך להיות זהה).
מריצים שוב את צינור העיבוד בלחיצה על הלחצן הידור והרצה.
לוחצים על הקישור כדי לעבור לממשק המשתמש של Kubeflow Pipelines ולראות את ההרצה.
מחכים לסיום השלב results וצופים ביומנים כדי לראות את התוצאות הסופיות. עכשיו יש לכם ציוני חיזוי ריאליים!

6. הסרת המשאבים
כיבוי סופי של המכונה הווירטואלית של MiniKF
עוברים אל Deployment Manager במסוף GCP ומוחקים את הפריסה minikf-1.
7. מזל טוב
כל הכבוד, הפעלתם בהצלחה תהליך עבודה של מדעי הנתונים מקצה לקצה באמצעות Kubeflow (MiniKF), Kale ו-Rok.
מה השלב הבא?
הצטרפות לקהילת Kubeflow:
- github.com/kubeflow
- Kubeflow Slack
- kubeflow-discuss@googlegroups.com
- שיחה קהילתית בימי שלישי