
1. مقدمة
| Kubeflow هي مجموعة أدوات لتعلُّم الآلة في Kubernetes. يهدف المشروع إلى تسهيل عمليات النشر لعمليات سير عمل تعلُّم الآلة (ML) على Kubernetes، بالإضافة إلى توفير إمكانية نقلها وتوسيع نطاقها. الهدف هو توفير طريقة مباشرة لنشر أفضل أنظمة مفتوحة المصدر لتعلُّم الآلة على بنى أساسية متنوعة. |
| يمكن أن يتضمّن سير عمل تعلُّم الآلة العديد من الخطوات التي تعتمد على بعضها البعض، بدءًا من إعداد البيانات وتحليلها، ثم التدريب، ثم التقييم، ثم التفعيل، وغير ذلك. يصعب إنشاء هذه العمليات وتتبُّعها بطريقة مخصّصة، مثلاً في مجموعة من دفاتر الملاحظات أو النصوص البرمجية، وتصبح أمور مثل التدقيق وإمكانية التكرار أكثر إشكالية.تساعد Kubeflow Pipelines (KFP) في حلّ هذه المشاكل من خلال توفير طريقة لتفعيل مسارات تعلُّم الآلة قوية وقابلة للتكرار، بالإضافة إلى الرصد والتدقيق وتتبُّع الإصدارات وإمكانية التكرار. تسهّل Cloud AI Pipelines عملية إعداد عملية تثبيت KFP. |


ما ستنشئه
في هذا الدرس التطبيقي حول الترميز، ستنشئ تطبيق ويب يلخّص المشاكل على GitHub باستخدام Kubeflow Pipelines لتدريب نموذج وعرضه. ويستند إلى مثال في مستودع أمثلة Kubeflow. عند اكتمال العملية، ستتضمّن بنيتك الأساسية ما يلي:
- مجموعة Google Kubernetes Engine (GKE) مع تثبيت Kubeflow Pipelines (من خلال Cloud AI Pipelines)
- برنامج يعالج البيانات وينفّذها لتدريب نموذج Tensor2Tensor على وحدات معالجة الرسومات
- حاوية عرض تقدّم توقّعات من النموذج المدرَّب
- واجهة مستخدم تفسّر التوقعات لتقديم ملخّصات لمشاكل GitHub
- دفتر ملاحظات ينشئ مسارًا من البداية باستخدام حزمة تطوير البرامج (SDK) الخاصة بـ Kubeflow Pipelines (KFP)
ما ستتعلمه
سيدرّب مسار العرض الذي ستنشئه نموذج Tensor2Tensor على بيانات مشاكل GitHub، ويتعلّم كيفية توقّع عناوين المشاكل من نصوصها. بعد ذلك، يتم تصدير النموذج المُدرَّب ونشره باستخدام Tensorflow Serving. تُطلق الخطوة الأخيرة في مسار العمل تطبيق ويب يتفاعل مع مثيل TF-Serving للحصول على توقّعات النموذج.
- كيفية تثبيت Kubeflow Pipelines على مجموعة GKE
- كيفية إنشاء سير عمل تعلُّم الآلة وتشغيله باستخدام Kubeflow Pipelines
- كيفية تحديد وتشغيل خطوط الأنابيب من دفتر ملاحظات AI Platform
المتطلبات
- سيكون الإلمام بأساسيات Kubernetes مفيدًا ولكنّه ليس ضروريًا
- مشروع نشط على Google Cloud Platform لديك أذونات المالك له
- (اختياري) حساب على GitHub
- الوصول إلى Google Cloud Shell المتاح في وحدة تحكّم Google Cloud Platform (GCP)
2. الإعداد
Cloud Shell
انتقِل إلى وحدة تحكّم Google Cloud Platform في المتصفّح وسجِّل الدخول باستخدام بيانات اعتماد مشروعك:
انقر على "اختيار مشروع" إذا لزم الأمر، حتى تتمكّن من العمل على مشروع الدرس العملي.

بعد ذلك، انقر على رمز "تفعيل Cloud Shell" في أعلى يسار وحدة التحكّم لبدء تشغيل Cloud Shell.
عند بدء تشغيل Cloud Shell، سيخبرك باسم المشروع الذي تم ضبطه لاستخدامه. تأكَّد من أنّ هذا الإعداد صحيح.
للعثور على رقم تعريف مشروعك، انتقِل إلى لوحة "الصفحة الرئيسية" في GCP Console. إذا كانت الشاشة فارغة، انقر على "نعم" في الطلب لإنشاء لوحة بيانات.

بعد ذلك، في نافذة Cloud Shell، نفِّذ الأوامر التالية إذا لزم الأمر لضبط gcloud لاستخدام المشروع الصحيح:
export PROJECT_ID=<your_project_id>
gcloud config set project ${PROJECT_ID}
إنشاء حزمة تخزين
أنشئ حزمة Cloud Storage لتخزين ملفات خطوط الإنتاج. عليك استخدام معرّف فريد على مستوى العالم، لذا من الملائم تحديد اسم حزمة يتضمّن رقم تعريف مشروعك. أنشئ الحزمة باستخدام الأمر gsutil mb (إنشاء حزمة):
export PROJECT_ID=<your_project_id>
export BUCKET_NAME=kubeflow-${PROJECT_ID}
gsutil mb gs://${BUCKET_NAME}
بدلاً من ذلك، يمكنك إنشاء حزمة من خلال وحدة تحكّم Google Cloud Platform.
اختياري**: إنشاء رمز مميز في GitHub**
يستدعي هذا الدرس التطبيقي حول الترميز GitHub API لاسترداد البيانات المتاحة للجميع. لمنع الحدّ من معدّل الاستخدام، خاصةً في الأحداث التي يتم فيها إرسال عدد كبير من الطلبات المجهولة الهوية إلى واجهات GitHub API، عليك إعداد رمز مميّز للوصول بدون أذونات. هذا الإجراء مطلوب فقط لتأكيد هويتك كمستخدم فردي وليس كمستخدم مجهول الهوية.
- انتقِل إلى https://github.com/settings/tokens وأنشئ رمزًا مميزًا جديدًا بدون نطاقات.
- احفظها في مكان آمن. وفي حال نسيانه، عليك حذفه وإنشاء رمز جديد.
إذا تخطّيت هذه الخطوة، سيظل المختبر يعمل، ولكن ستكون خياراتك محدودة أكثر لإنشاء بيانات الإدخال لاختبار النموذج.
اختياري: تثبيت لوحات البيانات المفيدة
في وحدة تحكّم Google Cloud Platform، ثبِّت لوحات بيانات Kubernetes Engine والتخزين لتسهيل الوصول إليها.
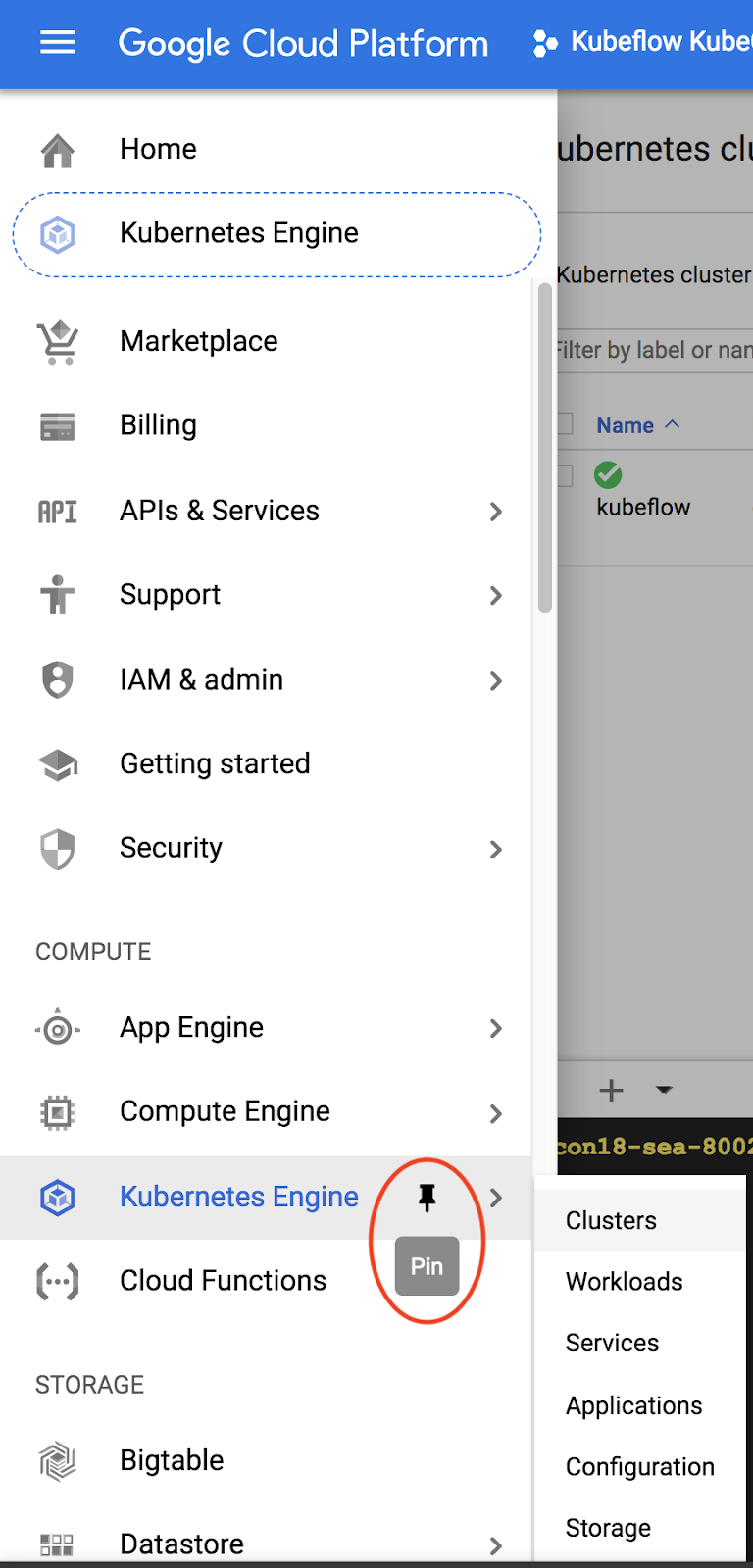
إنشاء عملية تثبيت AI Platform Pipelines (Kubeflow Pipelines المستضافة)
اتّبِع التعليمات الواردة في قسمَي "قبل البدء" و"إعداد المثيل" هنا لإعداد مثيل GKE مع تثبيت KFP. احرص على وضع علامة في المربّع السماح بالوصول إلى واجهات Cloud APIs التالية كما هو موضّح في المستندات. (إذا لم تفعل ذلك، لن يتم تشغيل المثال بنجاح). اترك مساحة الاسم الخاصة بالتثبيت على default.
عليك اختيار منطقة تتوافق مع وحدات معالجة الرسومات Nvidia k80s. يمكنك استخدام us-central1-a أو us-central1-c كقيم تلقائية.
بعد اكتمال عملية التثبيت، سجِّل اسم المجموعة والمنطقة في GKE المُدرَجة لعملية التثبيت في لوحة بيانات AI Pipelines، ولتسهيل الأمر، اضبط متغيّرات البيئة على هذه القيم.

export ZONE=<your zone> export CLUSTER_NAME=<your cluster name>
إعداد kubectl لاستخدام بيانات اعتماد مجموعة GKE الجديدة
بعد إنشاء مجموعة GKE، اضبط kubectl لاستخدام بيانات اعتماد المجموعة الجديدة من خلال تنفيذ الأمر التالي في Cloud Shell:
gcloud container clusters get-credentials ${CLUSTER_NAME} \
--project ${PROJECT_ID} \
--zone ${ZONE}
بدلاً من ذلك، انقر على اسم المجموعة في لوحة بيانات "مسارات الذكاء الاصطناعي" للانتقال إلى صفحة GKE الخاصة بها، ثم انقر على "ربط" في أعلى الصفحة. من النافذة المنبثقة، الصِق الأمر في Cloud Shell.
يؤدي ذلك إلى ضبط سياق kubectl حتى تتمكّن من التفاعل مع مجموعتك. للتحقّق من الإعدادات، شغِّل الأمر التالي:
kubectl get nodes -o wide
يجب أن ترى العُقد مُدرَجة مع الحالة "Ready"، ومعلومات أخرى حول عمر العُقدة وإصدارها وعنوان IP الخارجي وصورة نظام التشغيل وإصدار النواة ووقت تشغيل الحاوية.
ضبط المجموعة لتثبيت برنامج تشغيل Nvidia على مجموعات العُقد التي تم تفعيل وحدة معالجة الرسومات فيها
بعد ذلك، سنطبّق daemonset على المجموعة، ما سيؤدي إلى تثبيت برنامج تشغيل Nvidia على أي عقد مجموعة مفعّلة لوحدة معالجة الرسومات:
kubectl apply -f https://raw.githubusercontent.com/GoogleCloudPlatform/container-engine-accelerators/master/nvidia-driver-installer/cos/daemonset-preloaded.yaml
بعد ذلك، شغِّل الأمر التالي الذي يمنح مكوّنات KFP الإذن بإنشاء موارد Kubernetes جديدة:
kubectl create clusterrolebinding sa-admin --clusterrole=cluster-admin --serviceaccount=kubeflow:pipeline-runner
إنشاء مجموعة أجهزة ذات التخصيص نفسه لوحدة معالجة رسومات
بعد ذلك، سنُعدّ مجموعة أجهزة ذات التخصيص نفسه لوحدة معالجة الرسومات بحجم 1:
gcloud container node-pools create gpu-pool \
--cluster=${CLUSTER_NAME} \
--zone ${ZONE} \
--num-nodes=1 \
--machine-type n1-highmem-8 \
--scopes cloud-platform --verbosity error \
--accelerator=type=nvidia-tesla-k80,count=1
3- تشغيل خط أنابيب من لوحة بيانات "خطوط الأنابيب"
فتح لوحة بيانات "خطوط الإنتاج"
في Cloud Console، انتقِل إلى لوحة Pipelines إذا لم تكن فيها. بعد ذلك، انقر على فتح لوحة بيانات خطوط الإنتاج لعملية التثبيت، ثم انقر على خطوط الإنتاج في شريط القوائم الأيمن. إذا ظهر لك خطأ في التحميل، أعِد تحميل علامة التبويب. من المفترض أن تظهر لك صفحة جديدة على النحو التالي:
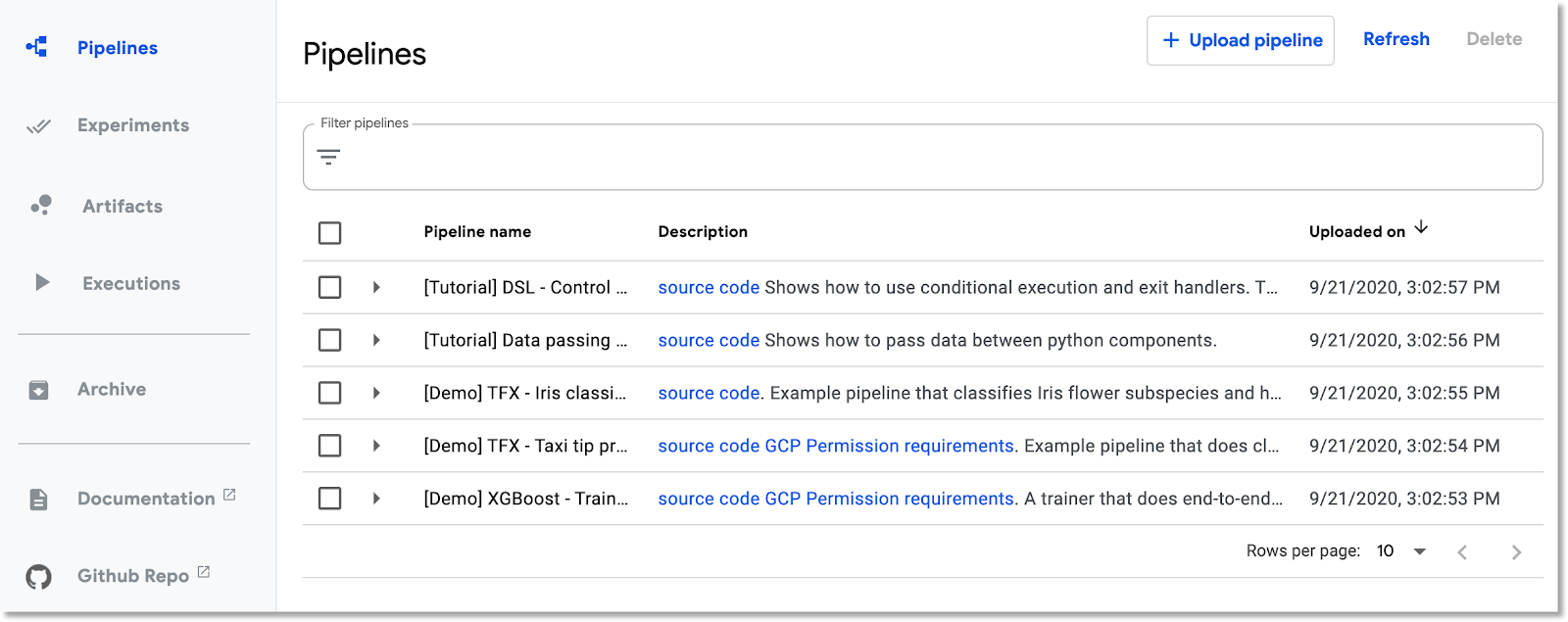
وصف مسار الإحالة الناجحة
تتضمّن عملية النقل التي ستنفّذها عدة خطوات (راجِع "الملحق" في هذا الدرس التطبيقي حول الترميز للحصول على التفاصيل):
- يتم نسخ نقطة تحقّق نموذج حالية إلى الحزمة.
- يتم تدريب نموذج Tensor2Tensor باستخدام بيانات تمت معالجتها مسبقًا.
- يبدأ التدريب من نقطة التحقّق من النموذج الحالي التي تم نسخها في الخطوة الأولى، ثم يتم التدريب لبضع مئات من الخطوات الإضافية. (سيستغرق تدريب النموذج بالكامل وقتًا طويلاً جدًا خلال الدرس التطبيقي حول الترميز).
- عند انتهاء التدريب، تصدِّر خطوة العرض النموذج بتنسيق مناسب للعرض باستخدام TensorFlow Serving.
- يتم نشر مثيل TensorFlow Serving باستخدام هذا النموذج.
- يتم تشغيل تطبيق ويب للتفاعل مع النموذج المعروض لاسترداد التوقعات.
تنزيل مسار العرض وتجميعه
في هذا القسم، سنرى كيفية تجميع تعريف خط أنابيب. أول ما علينا فعله هو تثبيت KFP SDK. نفِّذ ما يلي في Cloud Shell:
pip3 install -U kfp
لتنزيل ملف تعريف خط الأنابيب، نفِّذ الأمر التالي من Cloud Shell:
curl -O https://raw.githubusercontent.com/amygdala/kubeflow-examples/ghsumm/github_issue_summarization/pipelines/example_pipelines/gh_summ_hosted_kfp.py
بعد ذلك، يمكنك تجميع ملف تعريف خط الأنابيب من خلال تشغيله على النحو التالي:
python3 gh_summ_hosted_kfp.py
سيظهر الملف gh_summ_hosted_kfp.py.tar.gz كنتيجة.
تحميل مسار العرض المجمّع
في واجهة مستخدم الويب الخاصة بـ Kubeflow Pipelines، انقر على تحميل مسار، ثم اختَر الاستيراد من خلال عنوان URL. انسخ عنوان URL التالي الذي يشير إلى مسار العرض نفسه الذي تم تجميعه للتو، ثم الصقه. (تتطلّب عملية تحميل ملف من Cloud Shell بضع خطوات إضافية، لذا سنستخدم اختصارًا).
أدخِل اسمًا لخط الأنابيب (مثل gh_summ).
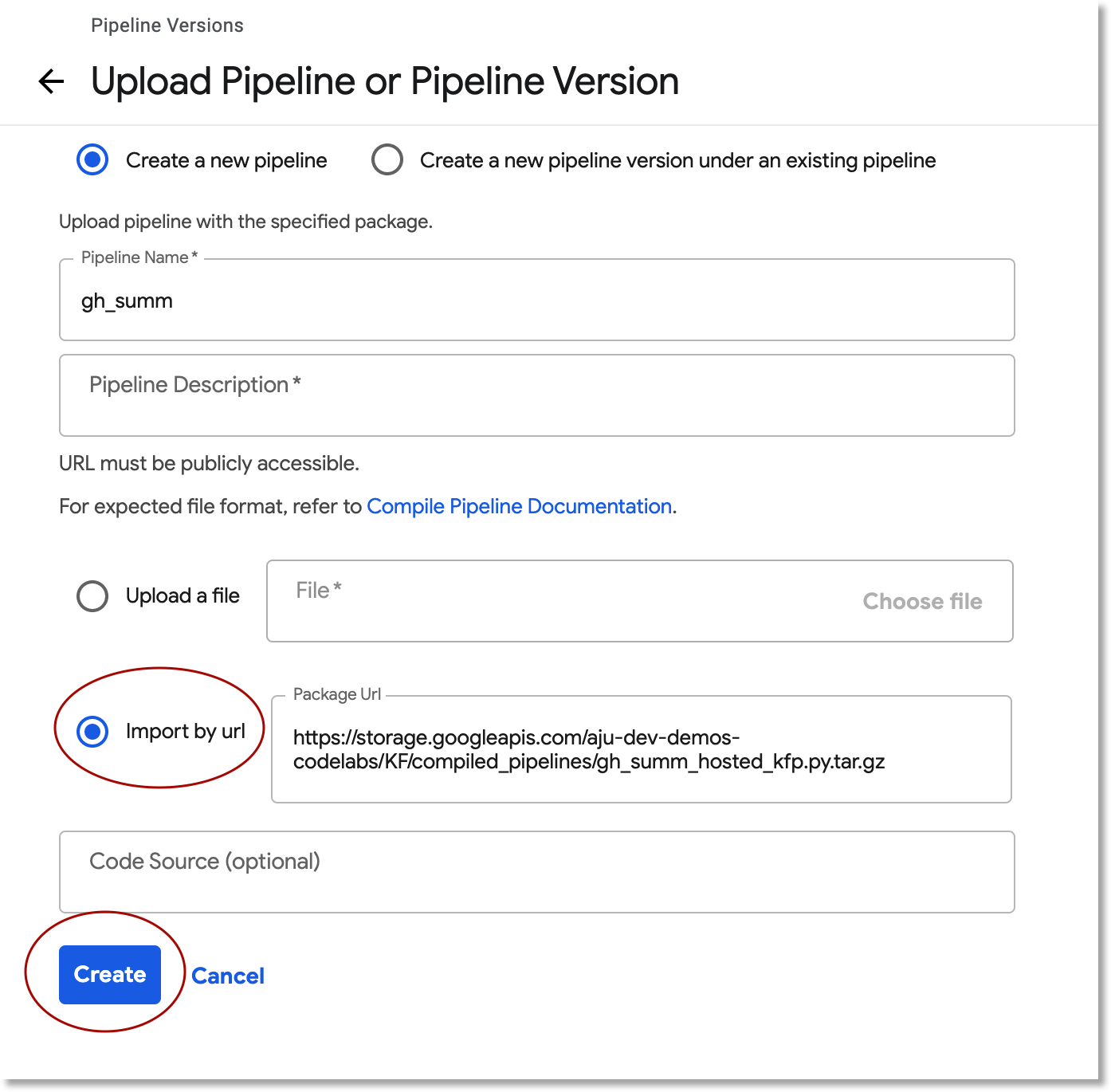
تشغيل مسار العرض
انقر على مسار البيانات الذي تم تحميله في القائمة، ما يتيح لك عرض الرسم البياني الثابت لمسار البيانات، ثم انقر على إنشاء تجربة لإنشاء تجربة جديدة باستخدام مسار البيانات. التجربة هي طريقة لتجميع عمليات التشغيل ذات الصلة دلاليًا.
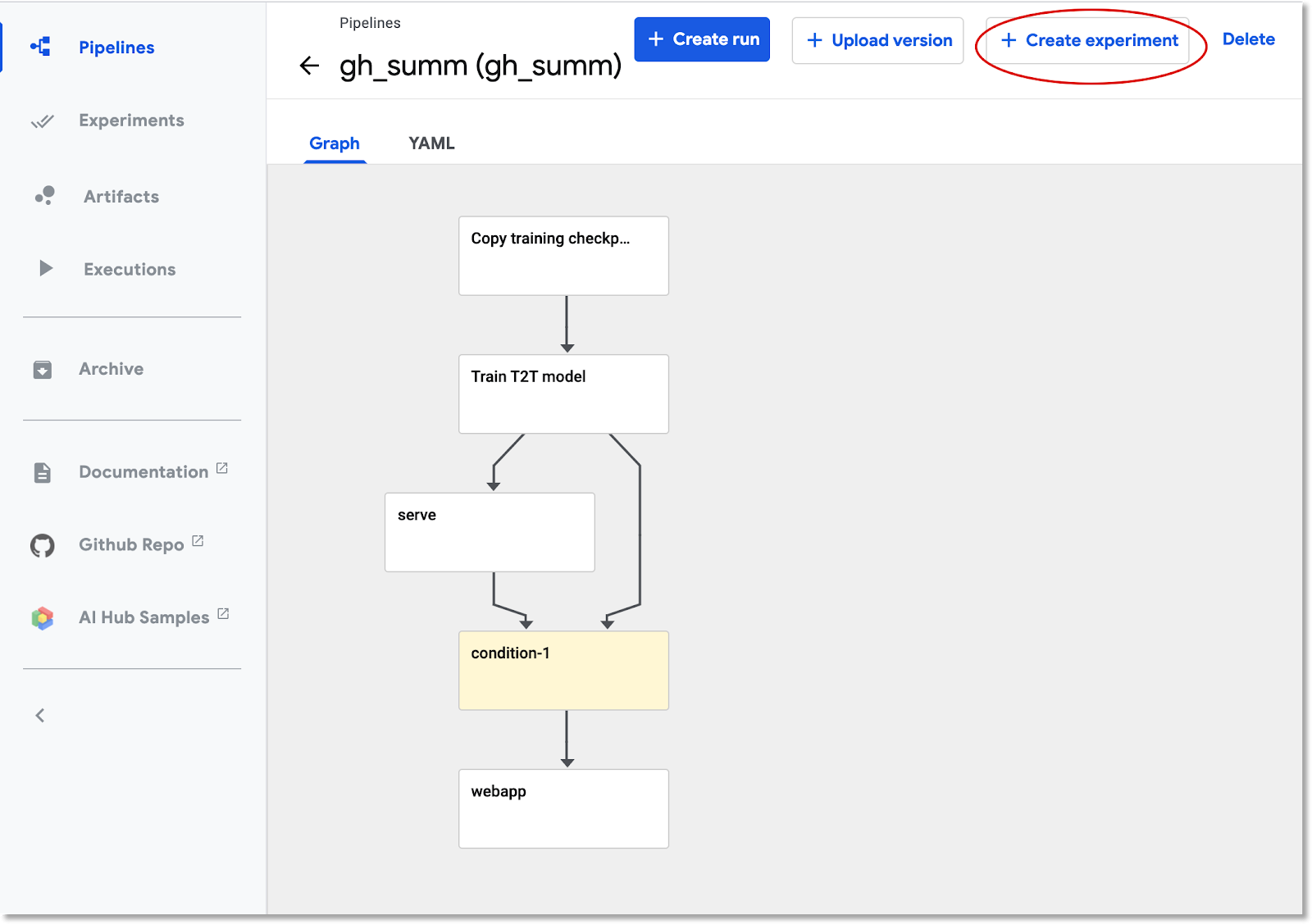
أدخِل اسمًا للتجربة (مثل الاسم نفسه الذي يحمله خط الإنتاج، gh_summ)، ثم انقر على التالي لإنشاء التجربة.

سيؤدي ذلك إلى فتح صفحة يمكنك فيها إدخال مَعلمات عملية التنفيذ وبدءها.
يمكنك تنفيذ الأوامر التالية في Cloud Shell للمساعدة في ملء المَعلمات.
gcloud config get-value project
echo "gs://${BUCKET_NAME}/codelab"
سيتم ملء اسم عملية التشغيل تلقائيًا، ولكن يمكنك منحه اسمًا مختلفًا إذا أردت ذلك.
بعد ذلك، املأ حقول المَعلمات الثلاثة:
project- (اختياري)
github-token working-dir
بالنسبة إلى working-dir، أدخِل بعض المسارات ضمن حزمة GCS التي أنشأتها. أدرِج البادئة "gs://". في حقل github-token، أدخِل الرمز المميز الذي أنشأته اختياريًا في وقت سابق، أو اترك سلسلة العنصر النائب كما هي إذا لم تنشئ رمزًا مميزًا.

بعد ملء الحقول، انقر على بدء، ثم انقر على عملية التشغيل المُدرَجة لعرض تفاصيلها. أثناء تنفيذ خطوة معيّنة في مسار البيانات، يمكنك النقر عليها للحصول على مزيد من المعلومات عنها، بما في ذلك عرض سجلات وحدة pod الخاصة بها. (يمكنك أيضًا عرض سجلّات خطوة سلسلة المعالجة من خلال الرابط المؤدي إلى سجلّات Cloud Logging (Stackdriver)، حتى إذا تم إيقاف عقدة المجموعة).
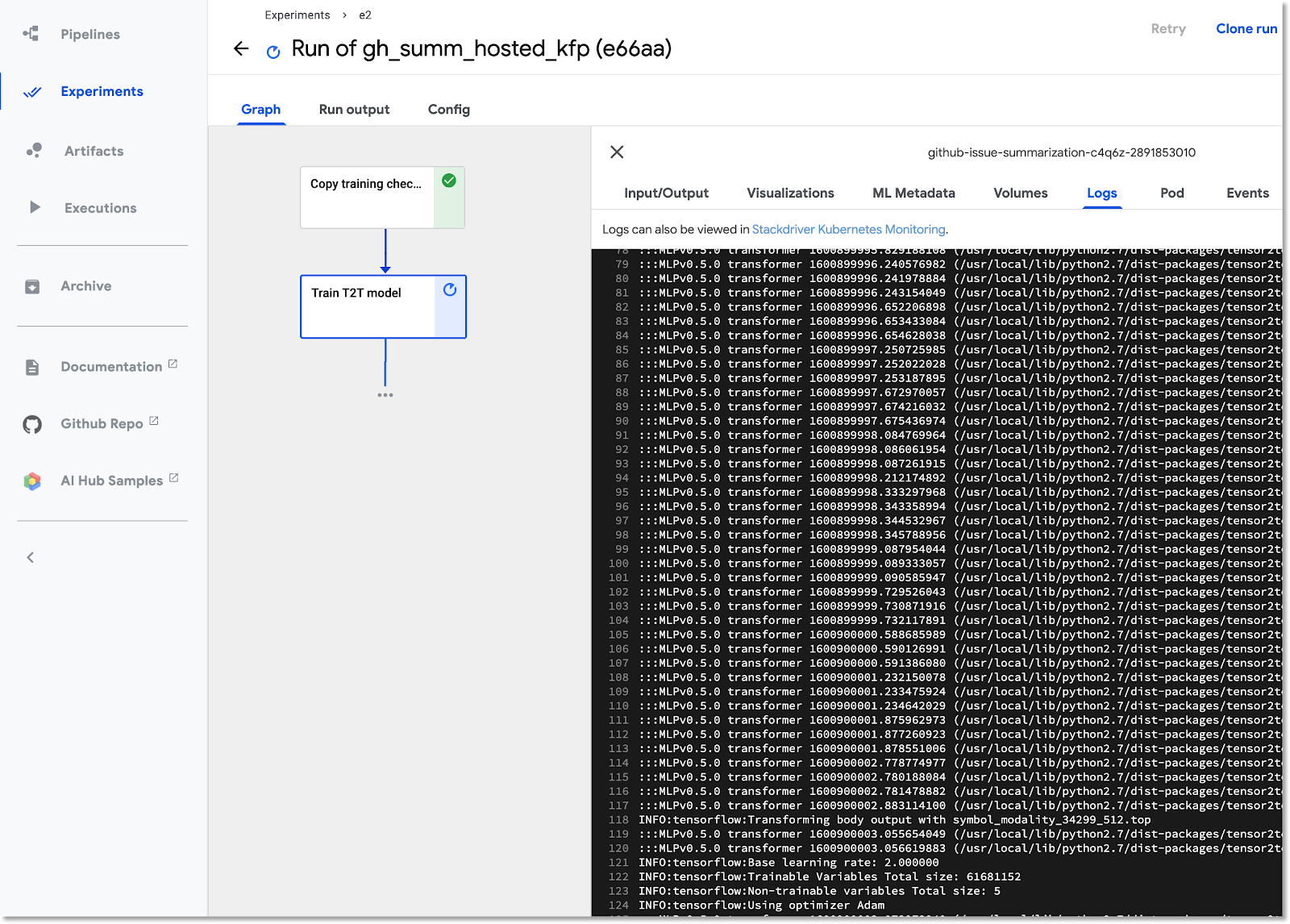
عرض تعريف مسار العرض
أثناء تشغيل خط الأنابيب، قد تحتاج إلى إلقاء نظرة فاحصة على طريقة تجميعه وما يفعله. يمكنك الاطّلاع على مزيد من التفاصيل في قسم الملحق من الدرس العملي.
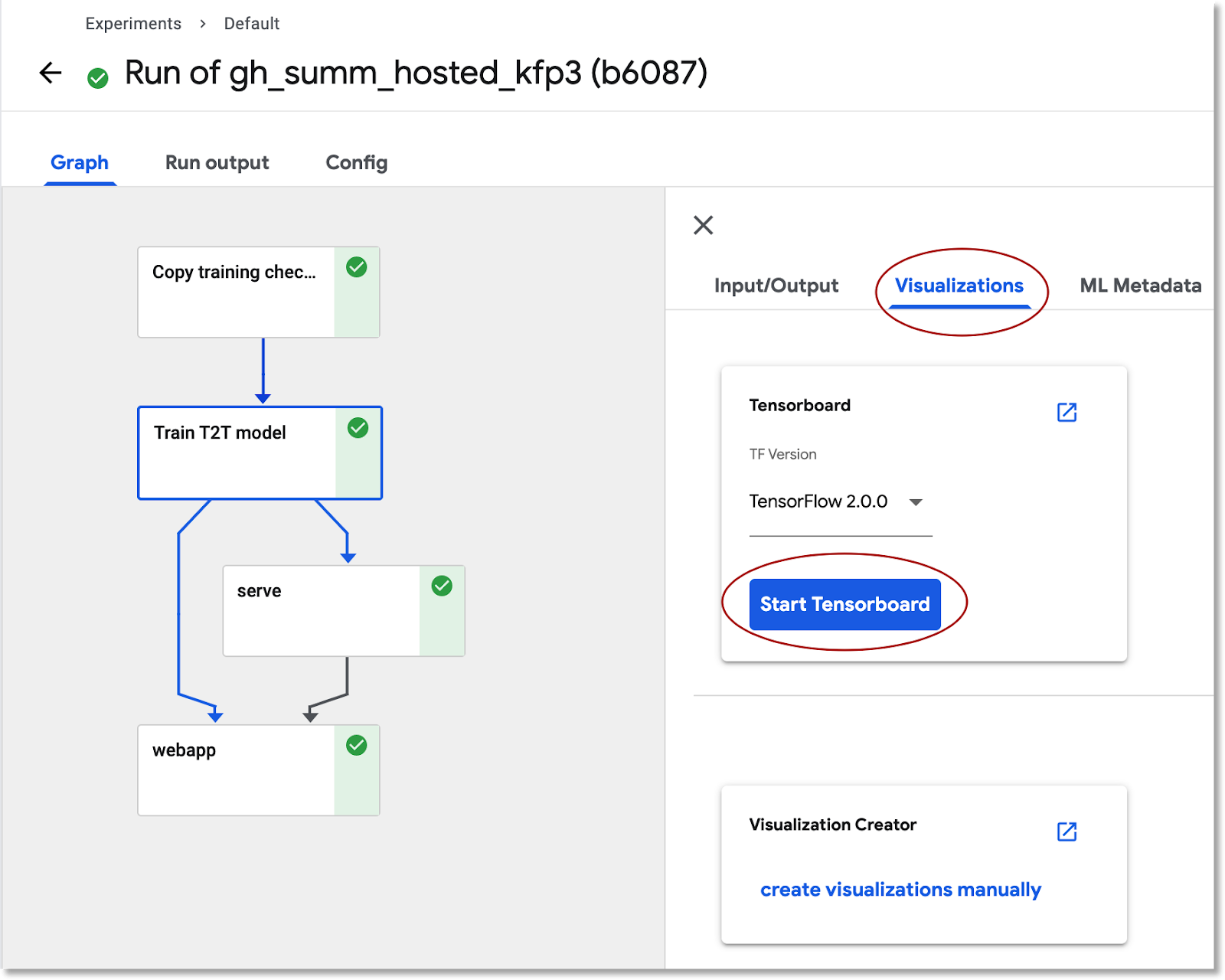
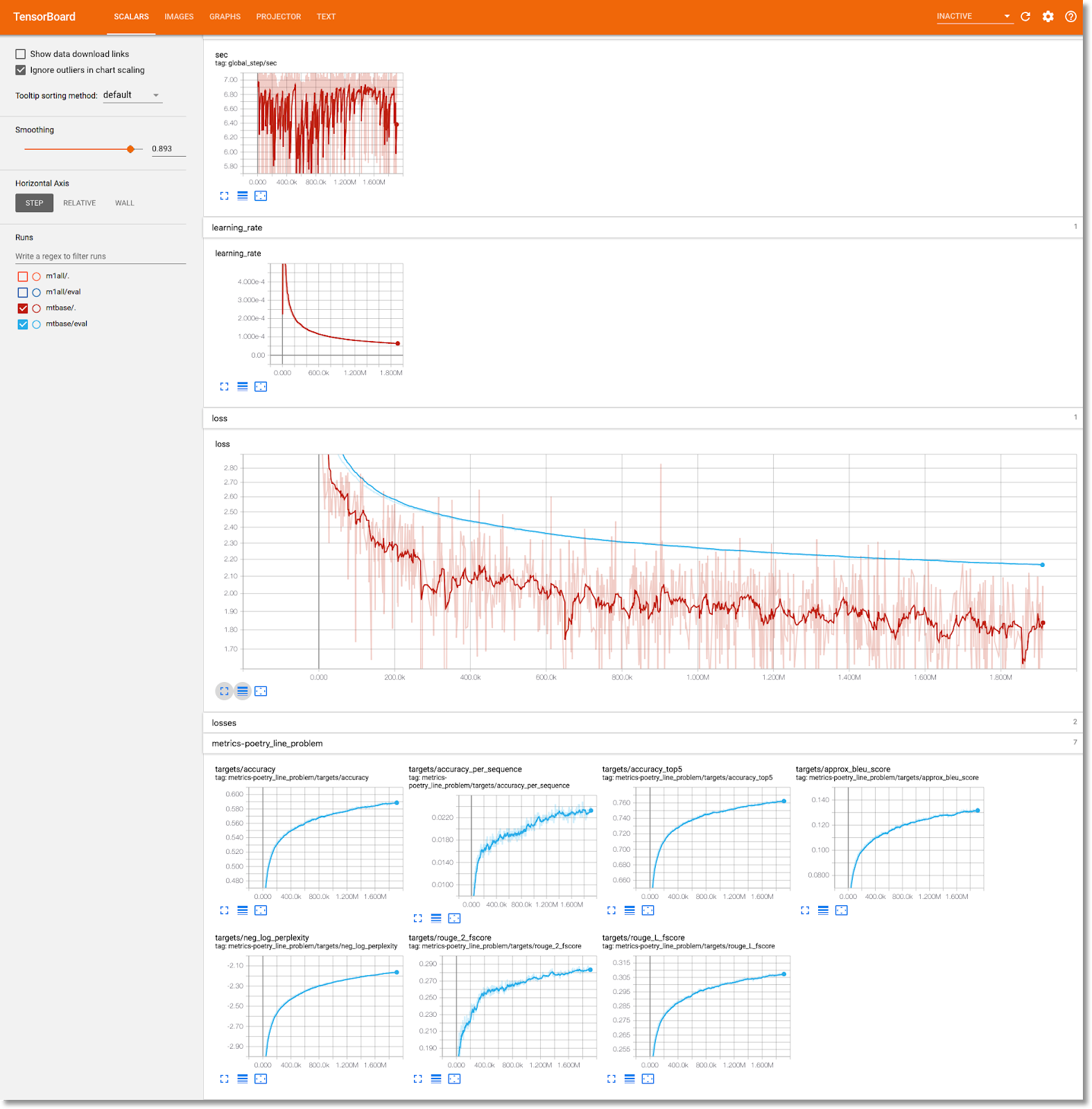
عرض معلومات تدريب النموذج في TensorBoard
بعد اكتمال خطوة التدريب، اختَر علامة التبويب الرسومات وانقر على الزر الأزرق بدء TensorBoard، ثمّ انقر على فتح Tensorboard بعد أن يصبح جاهزًا.
استكشاف لوحة بيانات "النتائج وعمليات التنفيذ"
تسجّل Kubeflow Pipelines تلقائيًا البيانات الوصفية حول خطوات خط الأنابيب أثناء تنفيذه. يتم تسجيل معلومات النتائج والتنفيذ. انقر على هذه الإدخالات في شريط التنقّل الأيمن ضمن لوحة البيانات لاستكشاف المزيد.
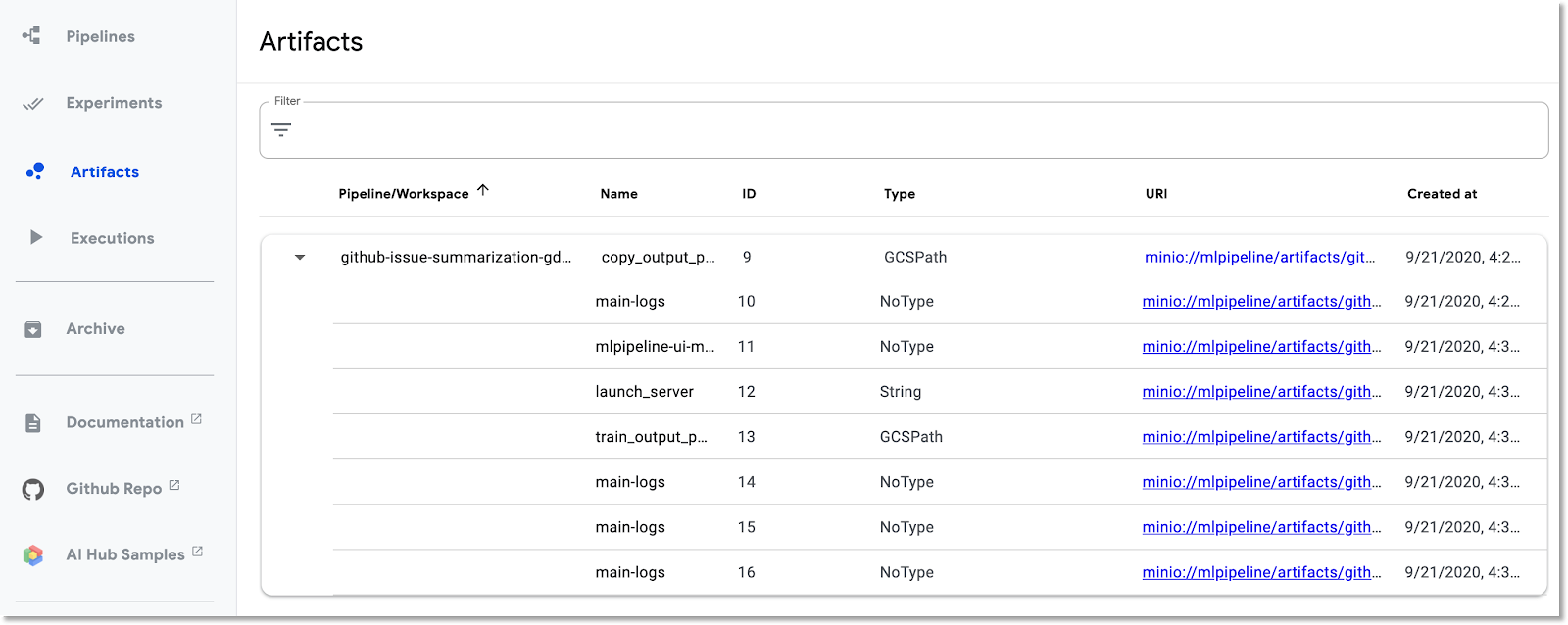
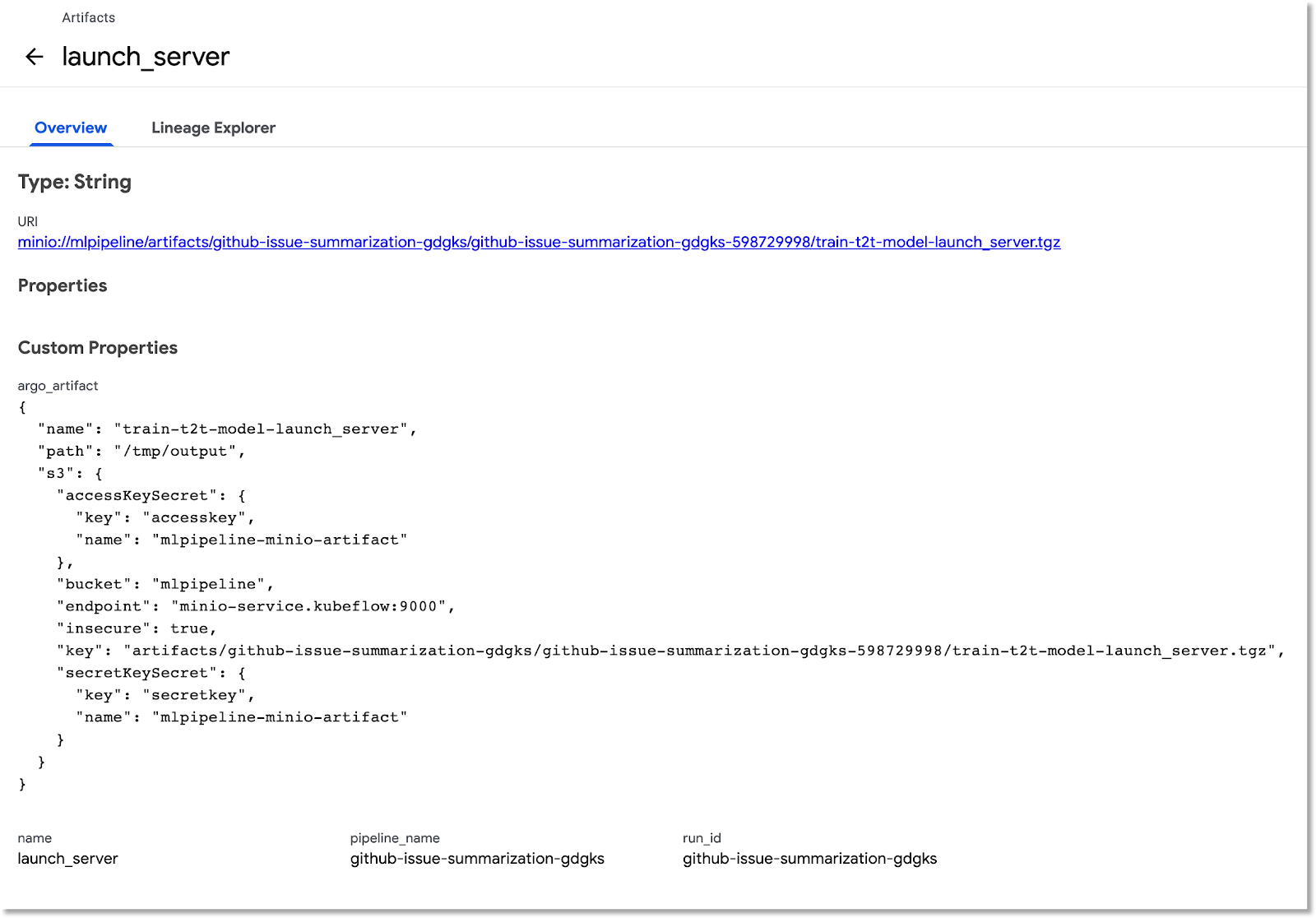
بالنسبة إلى Artifacts، يمكنك عرض كلّ من لوحة النظرة العامة ولوحة Lineage Explorer.
عرض تطبيق الويب الذي تم إنشاؤه بواسطة مسار العرض وإجراء بعض التوقعات
تنفّذ الخطوة الأخيرة في مسار العمل تطبيق ويب يوفّر واجهة مستخدم للاستعلام عن النموذج المدرَّب، ويتم عرضه من خلال TF Serving لتقديم التوقعات.
بعد اكتمال عملية التنفيذ، اربط تطبيق الويب من خلال إعادة توجيه المنفذ إلى الخدمة (نحن نعيد توجيه المنفذ لأنّه في هذا الدرس التطبيقي حول الترميز، لم يتم إعداد خدمة تطبيق الويب ليكون لها نقطة نهاية خارجية).
ابحث عن اسم الخدمة من خلال تنفيذ هذا الأمر في Cloud Shell:
kubectl get services
ابحث عن اسم خدمة مثل ghsumm-*-webappsvc في القائمة.
بعد ذلك، في Cloud Shell، يمكنك إعادة توجيه المنفذ إلى تلك الخدمة على النحو التالي، مع تغيير الأمر التالي لاستخدام اسم webappsvc:
kubectl port-forward svc/ghsumm-xxxxx-webappsvc 8080:80
بعد تشغيل عملية إعادة توجيه المنفذ، انقر على رمز "المعاينة" أعلى لوحة Cloud Shell، ثم انقر على "المعاينة على المنفذ 8080" في القائمة المنسدلة.
من المفترض أن تظهر صفحة مشابهة لما يلي في علامة تبويب جديدة:
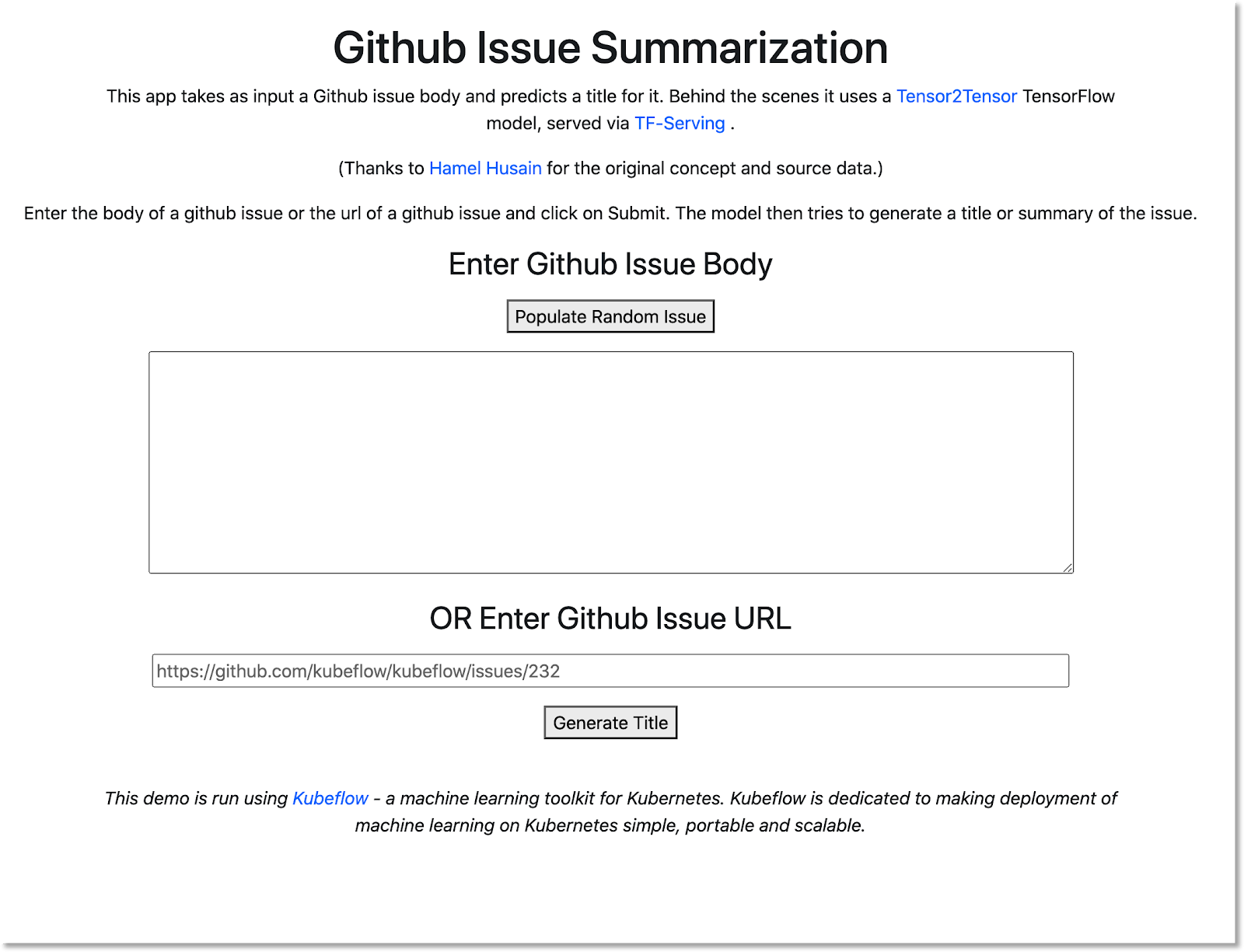
انقر على الزر ملء مشكلة عشوائية لاسترداد فقرة من النص. انقر على إنشاء عنوان لاستدعاء النموذج المدرَّب وعرض توقّع.
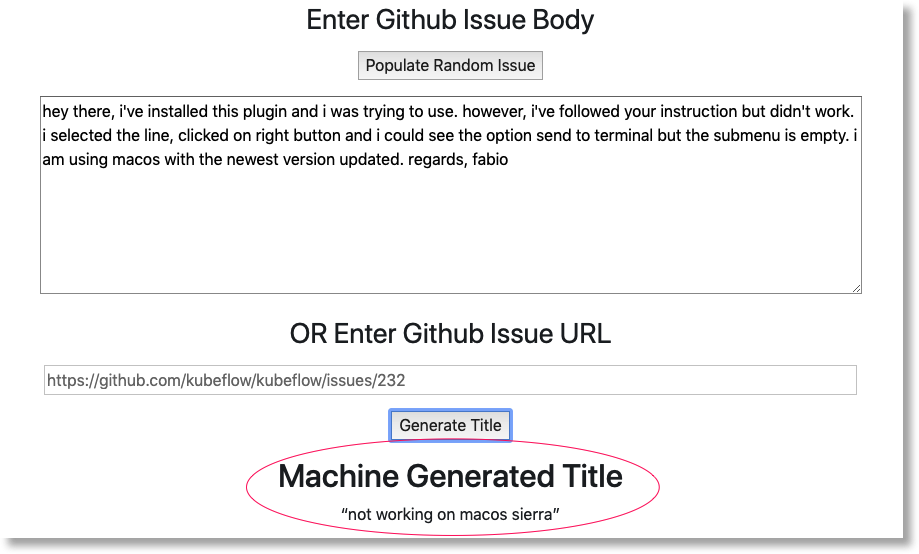
إذا كانت مَعلمات مسار العرض تتضمّن رمزًا مميزًا صالحًا من GitHub، يمكنك بدلاً من ذلك محاولة إدخال عنوان URL من GitHub في الحقل الثاني، ثم النقر على "إنشاء عنوان". إذا لم تُعدّ رمزًا مميزًا صالحًا على GitHub، استخدِم الحقل "ملء مشكلة عشوائية" فقط.
4. تشغيل مسار من "دفتر ملاحظات AI Platform"
يمكنك أيضًا تحديد وتشغيل Kubeflow Pipelines بشكل تفاعلي من دفتر ملاحظات Jupyter باستخدام حزمة تطوير البرامج (SDK) الخاصة بـ KFP. تسهّل دفاتر ملاحظات AI Platform، التي سنستخدمها في هذا الدرس التطبيقي، هذه العملية.
إنشاء آلة افتراضية لدفتر ملاحظات
سننشئ مثيلاً لدفتر ملاحظات من Cloud Shell باستخدام واجهة برمجة التطبيقات. (يمكنك بدلاً من ذلك إنشاء دفتر ملاحظات من خلال Cloud Console. يمكنك الاطّلاع على المستندات للحصول على مزيد من المعلومات).
اضبط متغيرات البيئة التالية في Cloud Shell:
export INSTANCE_NAME="kfp-ghsumm" export VM_IMAGE_PROJECT="deeplearning-platform-release" export VM_IMAGE_FAMILY="tf2-2-3-cpu" export MACHINE_TYPE="n1-standard-4" export LOCATION="us-central1-c"
بعد ذلك، شغِّل الأمر التالي من Cloud Shell لإنشاء مثيل دفتر الملاحظات:
gcloud beta notebooks instances create $INSTANCE_NAME \ --vm-image-project=$VM_IMAGE_PROJECT \ --vm-image-family=$VM_IMAGE_FAMILY \ --machine-type=$MACHINE_TYPE --location=$LOCATION
عند تنفيذ هذا الأمر لأول مرة، قد يُطلب منك تفعيل واجهة برمجة التطبيقات notebooks لمشروعك. يُرجى الردّ بـ "y" إذا كان الأمر كذلك.
بعد بضع دقائق، سيتم تشغيل خادم دفتر الملاحظات. يمكنك الاطّلاع على مثيلات Notebook المدرَجة في Cloud Console.

تحميل دفتر ملاحظات الدرس التطبيقي حول الترميز
بعد إنشاء مثيل دفتر الملاحظات، انقر على هذا الرابط لتحميل دفتر ملاحظات Jupyter الخاص بتجربة البرمجة. اختَر مثيل دفتر الملاحظات الذي تريد استخدامه. سيتم فتح دفتر الملاحظات تلقائيًا.
تنفيذ دفتر الملاحظات
اتّبِع التعليمات الواردة في دفتر الملاحظات لإكمال بقية التمرين العملي. يُرجى العِلم أنّه في جزء "الإعداد" من دفتر الملاحظات، عليك ملء القيم الخاصة بك قبل تشغيل بقية دفتر الملاحظات.
(إذا كنت تستخدم مشروعك الخاص، لا تنسَ الرجوع إلى قسم "التنظيف" في هذا الدرس التطبيقي وإكماله).
5- تَنظيم
لست بحاجة إلى تنفيذ ذلك إذا كنت تستخدم حسابًا مؤقتًا في Codelab، ولكن قد تحتاج إلى إيقاف تثبيت Pipelines وNotebook إذا كنت تستخدم مشروعك الخاص.
إيقاف مجموعة GKE الخاصة بـ Pipelines
يمكنك حذف مجموعة Pipelines من Cloud Console. (يمكنك حذف عملية تثبيت Pipelines فقط إذا أردت إعادة استخدام مجموعة GKE).
حذف مثيل AI Notebook
إذا نفّذت جزء "دفتر الملاحظات" من تجربة البرمجة، يمكنك حذف أو إيقاف مثيل دفتر الملاحظات من Cloud Console.
اختياري: إزالة رمز GitHub المميز
انتقِل إلى https://github.com/settings/tokens وأزِل الرمز المميّز الذي تم إنشاؤه.
6. الملاحق
نظرة على الرمز
تحديد مسار المعالجة
يمكنك الاطّلاع هنا على تعريف خطوة المعالجة المستخدَمة في هذا الدرس العملي.
لنلقِ نظرة على كيفية تحديدها، بالإضافة إلى كيفية تحديد مكوّناتها (الخطوات). سنوضّح بعض النقاط البارزة، ولكن يمكنك الاطّلاع على المستندات لمزيد من التفاصيل.
تستند خطوات Kubeflow Pipeline إلى الحاويات. عند إنشاء مسار، يمكنك استخدام مكوّنات معدّة مسبقًا تتضمّن صور حاويات معدّة مسبقًا، أو يمكنك إنشاء مكوّناتك الخاصة. في هذا الدرس التطبيقي حول الترميز، أنشأنا نموذجًا خاصًا بنا.
يتم تحديد أربع خطوات من خطوات سلسلة المعالجة من المكوّنات القابلة لإعادة الاستخدام، والتي يمكن الوصول إليها من خلال ملفات تعريف المكوّنات. في مقتطف الرمز الأول هذا، نصل إلى ملفات تعريف المكوّنات هذه من خلال عنوان URL الخاص بها، ونستخدم هذه التعريفات لإنشاء "عمليات" سنستخدمها لإنشاء خطوة في مسار البيانات.
import kfp.dsl as dsl
import kfp.gcp as gcp
import kfp.components as comp
...
copydata_op = comp.load_component_from_url(
'https://raw.githubusercontent.com/kubeflow/examples/master/github_issue_summarization/pipelines/components/t2t/datacopy_component.yaml'
)
train_op = comp.load_component_from_url(
'https://raw.githubusercontent.com/kubeflow/examples/master/github_issue_summarization/pipelines/components/t2t/train_component.yaml'
)
في ما يلي أحد تعريفات المكوّنات، لعملية التدريب، بتنسيق yaml. يمكنك ملاحظة أنّه تم تحديد المدخلات والمخرجات وصورة الحاوية ووسيطات نقطة دخول الحاوية.
name: Train T2T model
description: |
A Kubeflow Pipeline component to train a Tensor2Tensor
model
metadata:
labels:
add-pod-env: 'true'
inputs:
- name: train_steps
description: '...'
type: Integer
default: 2019300
- name: data_dir
description: '...'
type: GCSPath
- name: model_dir
description: '...'
type: GCSPath
- name: action
description: '...'
type: String
- name: deploy_webapp
description: '...'
type: String
outputs:
- name: launch_server
description: '...'
type: String
- name: train_output_path
description: '...'
type: GCSPath
- name: MLPipeline UI metadata
type: UI metadata
implementation:
container:
image: gcr.io/google-samples/ml-pipeline-t2ttrain:v3ap
args: [
--data-dir, {inputValue: data_dir},
--action, {inputValue: action},
--model-dir, {inputValue: model_dir},
--train-steps, {inputValue: train_steps},
--deploy-webapp, {inputValue: deploy_webapp},
--train-output-path, {outputPath: train_output_path}
]
env:
KFP_POD_NAME: "{{pod.name}}"
fileOutputs:
launch_server: /tmp/output
MLPipeline UI metadata: /mlpipeline-ui-metadata.json
يمكنك أيضًا تحديد خطوة في مسار البيانات من خلال الدالة الإنشائية dsl.ContainerOp، كما سنرى أدناه.
في ما يلي الجزء الأكبر من تعريف مسار الإعداد. نحن بصدد تحديد مدخلات مسار الإحالة الناجحة (وقيمها التلقائية). بعد ذلك، نحدّد خطوات مسار الإحالة الناجحة. بالنسبة إلى معظم العمليات، نستخدم "العمليات" المحدّدة أعلاه، ولكننا نحدّد أيضًا خطوة "العرض" مضمّنة من خلال ContainerOp، مع تحديد صورة الحاوية ووسيطات نقطة الدخول مباشرةً.
يمكنك ملاحظة أنّ الخطوات train وlog_model وserve تستخدم نواتج الخطوات السابقة كمدخلات. يمكنك الاطّلاع على مزيد من المعلومات حول كيفية تحديد ذلك هنا.
@dsl.pipeline(
name='Github issue summarization',
description='Demonstrate Tensor2Tensor-based training and TF-Serving'
)
def gh_summ( #pylint: disable=unused-argument
train_steps: 'Integer' = 2019300,
project: str = 'YOUR_PROJECT_HERE',
github_token: str = 'YOUR_GITHUB_TOKEN_HERE',
working_dir: 'GCSPath' = 'gs://YOUR_GCS_DIR_HERE',
checkpoint_dir: 'GCSPath' = 'gs://aju-dev-demos-codelabs/kubecon/model_output_tbase.bak2019000/',
deploy_webapp: str = 'true',
data_dir: 'GCSPath' = 'gs://aju-dev-demos-codelabs/kubecon/t2t_data_gh_all/'
):
copydata = copydata_op(
data_dir=data_dir,
checkpoint_dir=checkpoint_dir,
model_dir='%s/%s/model_output' % (working_dir, dsl.RUN_ID_PLACEHOLDER),
action=COPY_ACTION,
)
train = train_op(
data_dir=data_dir,
model_dir=copydata.outputs['copy_output_path'],
action=TRAIN_ACTION, train_steps=train_steps,
deploy_webapp=deploy_webapp
)
serve = dsl.ContainerOp(
name='serve',
image='gcr.io/google-samples/ml-pipeline-kubeflow-tfserve:v6',
arguments=["--model_name", 'ghsumm-%s' % (dsl.RUN_ID_PLACEHOLDER,),
"--model_path", train.outputs['train_output_path']
]
)
train.set_gpu_limit(1)
يُرجى العِلم أنّنا نطلب تنفيذ خطوة "التدريب" على عقدة في المجموعة تتوفّر فيها وحدة معالجة رسومات واحدة على الأقل.
train.set_gpu_limit(1)
الخطوة الأخيرة في مسار العرض، والتي يتم تحديدها أيضًا بشكل مضمّن، هي خطوة شرطية. سيتم تشغيلها بعد الانتهاء من الخطوة "serve"، فقط إذا كان الناتج من خطوة التدريب launch_server هو السلسلة "true". يتم إطلاق "تطبيق الويب الخاص بالتوقعات" الذي استخدمناه لطلب ملخّصات المشاكل من نموذج T2T المدرَّب.
with dsl.Condition(train.outputs['launch_server'] == 'true'):
webapp = dsl.ContainerOp(
name='webapp',
image='gcr.io/google-samples/ml-pipeline-webapp-launcher:v1',
arguments=["--model_name", 'ghsumm-%s' % (dsl.RUN_ID_PLACEHOLDER,),
"--github_token", github_token]
)
webapp.after(serve)
تعريفات صور حاويات المكوّنات
يصف مستند Kubeflow Pipeline بعض أفضل الممارسات لإنشاء مكوّناتك الخاصة. كجزء من هذه العملية، عليك تحديد صورة حاوية وإنشاؤها. يمكنك الاطّلاع على خطوات المكوّنات في مسار هذا الدرس العملي هنا. تتوفّر تعريفات Dockerfile في الأدلة الفرعية containers، مثلاً هنا.
استخدام آلات افتراضية قابلة للإيقاف مع وحدات معالجة الرسومات للتدريب
الأجهزة الافتراضية الاستباقية هي مثيلات الأجهزة الافتراضية في Compute Engine التي تستمر لمدة 24 ساعة كحد أقصى ولا تقدّم أي ضمانات بشأن التوفّر. سعر الأجهزة الافتراضية الاستباقية أقل من سعر أجهزة Compute Engine الافتراضية العادية.
باستخدام Google Kubernetes Engine (GKE)، يمكنك بسهولة إعداد مجموعة أو مجموعة أجهزة ذات تخصيص نفسه تستخدم أجهزة افتراضية قابلة للإيقاف. يمكنك إعداد مجموعة أجهزة ذات التخصيص نفسه من هذا النوع باستخدام وحدات معالجة الرسومات (GPU) المرفقة بالمثيلات القابلة للإيقاف. تعمل هذه العُقد بالطريقة نفسها التي تعمل بها العُقد العادية المتوافقة مع وحدات معالجة الرسومات، ولكنّ وحدات معالجة الرسومات تظل متاحة فقط طوال مدة تشغيل الآلة الافتراضية.
يمكنك إعداد مجموعة أجهزة ذات التخصيص نفسه قابلة للمقاطعة ومفعَّلة لوحدة معالجة رسومات لمجموعتك عن طريق تنفيذ أمر مشابه للأمر التالي، وتعديل الأمر التالي باستخدام اسم مجموعتك والمنطقة، وتعديل نوع المسرِّع وعددها وفقًا لمتطلباتك. يمكنك اختياريًا تحديد مجموعة أجهزة ذات التخصيص نفسه التي سيتم توسيع نطاقها تلقائيًا استنادًا إلى أحمال العمل الحالية.
gcloud container node-pools create preemptible-gpu-pool \
--cluster=<your-cluster-name> \
--zone <your-cluster-zone> \
--enable-autoscaling --max-nodes=4 --min-nodes=0 \
--machine-type n1-highmem-8 \
--preemptible \
--node-taints=preemptible=true:NoSchedule \
--scopes cloud-platform --verbosity error \
--accelerator=type=nvidia-tesla-k80,count=4
يمكنك أيضًا إعداد مجموعة أجهزة ذات التخصيص نفسه من خلال Cloud Console.
تحديد مسار Kubeflow يستخدم عُقد GKE القابلة للإيقاف
إذا كنت تستخدم Kubeflow على GKE، أصبح من السهل الآن تحديد وتشغيل Kubeflow Pipelines التي يتم فيها تشغيل خطوة واحدة أو أكثر من خطوات خط أنابيب المعالجة (المكوّنات) على عُقد قابلة للمقاطعة، ما يقلّل من تكلفة تشغيل مهمة. لاستخدام الأجهزة الافتراضية الاستباقية للحصول على نتائج صحيحة، يجب أن تكون الخطوات التي تحدّدها على أنّها استباقية إما متطابقة (أي إذا نفّذت خطوة عدة مرات، ستحصل على النتيجة نفسها)، أو يجب أن يتم حفظ حالة العمل حتى تتمكّن الخطوة من استئناف العمل من حيث توقّفت في حال حدوث انقطاع.
عند تحديد Kubeflow Pipeline، يمكنك الإشارة إلى أنّ خطوة معيّنة يجب أن يتم تشغيلها على عقدة قابلة للإيقاف عن طريق تعديل العملية على النحو التالي:
your_pipelines_op.apply(gcp.use_preemptible_nodepool())
لمزيد من التفاصيل، يُرجى الاطّلاع على المستندات.
من المفترض أيضًا أنك تريد إعادة محاولة تنفيذ الخطوة عدة مرات إذا تم إيقاف العقدة بشكل استباقي. يمكنك إجراء ذلك على النحو التالي، حيث نحدّد هنا 5 محاولات إعادة تشغيل.
your_pipelines_op.set_gpu_limit(1).apply(gcp.use_preemptible_nodepool()).set_retry(5)
حاوِل تعديل مسار Kubeflow الذي استخدمناه في هذا الدرس التطبيقي حول الترميز لتشغيل خطوة التدريب على جهاز افتراضي قابل للإيقاف.
غيِّر السطر التالي في مواصفات مسار البيانات لاستخدام مجموعة عقد قابلة للمقاطعة (تأكَّد من إنشاء مجموعة كما هو موضّح أعلاه)، وإعادة المحاولة 5 مرات:
train.set_gpu_limit(1)
بعد ذلك، أعِد تجميع خط الأنابيب، وحمِّل الإصدار الجديد (مع إعطائه اسمًا جديدًا)، ثم شغِّل الإصدار الجديد من خط الأنابيب.