
1. מבוא
| Kubeflow הוא ערכת כלים ללמידת מכונה ל-Kubernetes. הפרויקט מוקדש להפיכת פריסות של תהליכי עבודה של למידת מכונה (ML) ב-Kubernetes לפשוטות, לניידות ולהתאמה לעומס (scaling). המטרה היא לספק דרך פשוטה לפריסת מערכות קוד פתוח מהשורה הראשונה ללמידת מכונה בתשתיות מגוונות. |
| תהליך עבודה של למידת מכונה יכול לכלול שלבים רבים עם תלות הדדית, החל מהכנת נתונים וניתוח, דרך אימון והערכה, ועד לפריסה ועוד. קשה ליצור ולעקוב אחרי התהליכים האלה באופן אד-הוק – למשל, בסדרת מחברות או סקריפטים – ובעיות כמו ביקורת ושחזור הופכות לבעייתיות יותר ויותר.Kubeflow Pipelines (KFP) עוזר לפתור את הבעיות האלה על ידי מתן דרך לפריסת צינורות חזקים וניתנים לשחזור של למידת מכונה, יחד עם מעקב, ביקורת, מעקב אחר גרסאות ושחזור. בעזרת Cloud AI Pipelines קל להגדיר התקנה של KFP. |


מה תפַתחו
ב-Codelab הזה תבנו אפליקציית אינטרנט שמסכמת בעיות ב-GitHub באמצעות Kubeflow Pipelines כדי לאמן מודל ולספק אותו. היא מבוססת על דוגמה במאגר הדוגמאות של Kubeflow. בסיום התהליך, התשתית שלכם תכלול:
- אשכול Google Kubernetes Engine (GKE) עם Kubeflow Pipelines מותקן (דרך Cloud AI Pipelines).
- צינור עיבוד נתונים שמבצע אימון של מודל Tensor2Tensor במעבדי GPU
- קונטיינר להצגת נתונים שכולל חיזויים מהמודל שאומן
- ממשק משתמש שמפרש את התחזיות כדי לספק סיכומים של בעיות ב-GitHub
- Notebook שיוצר צינור עיבוד נתונים מאפס באמצעות Kubeflow Pipelines (KFP) SDK
מה תלמדו
צינור עיבוד הנתונים שתבנו יאמן מודל Tensor2Tensor על נתוני בעיות מ-GitHub, כדי ללמוד לחזות את כותרות הבעיות מתוך גופי הבעיות. לאחר מכן, המערכת מייצאת את המודל שאומן ופורסת את המודל המיוצא באמצעות Tensorflow Serving. השלב האחרון בצינור מעורר אפליקציית אינטרנט, שמתקשרת עם מופע TF-Serving כדי לקבל תחזיות של המודל.
- איך מתקינים את Kubeflow Pipelines באשכול GKE
- איך יוצרים ומריצים תהליכי עבודה של למידת מכונה באמצעות Kubeflow Pipelines
- איך מגדירים ומריצים צינורות נתונים מ-AI Platform Notebook
מה תצטרכו
- הבנה בסיסית של Kubernetes תעזור לכם, אבל היא לא הכרחית
- פרויקט פעיל ב-GCP שבו יש לכם הרשאות בעלים
- (אופציונלי) חשבון ב-GitHub
- גישה אל Google Cloud Shell, שזמין ב-Google Cloud Platform (GCP) Console
2. הגדרה
Cloud Shell
נכנסים למסוף GCP בדפדפן ומתחברים באמצעות פרטי הכניסה לפרויקט:
אם צריך, לוחצים על 'בחירת פרויקט' כדי לעבוד עם פרויקט ה-codelab.

אחר כך לוחצים על הסמל 'הפעלת Cloud Shell' בפינה הימנית העליונה של המסוף כדי להפעיל Cloud Shell.

כשמפעילים את Cloud Shell, מוצג שם הפרויקט שמוגדר לשימוש. בודקים שההגדרה הזו נכונה.
כדי למצוא את מזהה הפרויקט, עוברים לחלונית 'דף הבית' ב-GCP Console. אם המסך ריק, לוחצים על 'כן' בהודעה שמופיעה כדי ליצור מרכז בקרה.

אחר כך, בטרמינל של Cloud Shell, מריצים את הפקודות הבאות אם צריך להגדיר את gcloud כך שישתמש בפרויקט הנכון:
export PROJECT_ID=<your_project_id>
gcloud config set project ${PROJECT_ID}
יצירה של קטגוריית אחסון
יוצרים קטגוריה של Cloud Storage לאחסון קבצים של צינורות. כדי להבטיח שהשם יהיה ייחודי גלובלית, כדאי להגדיר שם לקטגוריה שיכלול את מזהה הפרויקט. יוצרים את הקטגוריה באמצעות הפקודה gsutil mb (יצירת קטגוריה):
export PROJECT_ID=<your_project_id>
export BUCKET_NAME=kubeflow-${PROJECT_ID}
gsutil mb gs://${BUCKET_NAME}
אפשר גם ליצור מאגר דרך מסוף GCP.
אופציונלי**: יצירת טוקן ב-GitHub**
ב-Codelab הזה מתבצעת קריאה ל-GitHub API כדי לאחזר נתונים שזמינים לכולם. כדי למנוע הגבלת קצב, במיוחד באירועים שבהם נשלח מספר גדול של בקשות אנונימיות לממשקי ה-API של GitHub, צריך להגדיר אסימון גישה ללא הרשאות. הסיבה לכך היא רק כדי לאמת אתכם כמשתמשים פרטיים ולא כמשתמשים לא רשומים.
- עוברים אל https://github.com/settings/tokens ויוצרים טוקן חדש ללא היקפי הרשאות.
- שומרים אותו במקום בטוח. אם מאבדים אותו, צריך למחוק אותו וליצור חדש.
אם תדלגו על השלב הזה, ה-Lab עדיין יפעל – פשוט יהיו לכם פחות אפשרויות ליצירת נתוני קלט לבדיקת המודל.
אופציונלי: הצמדת לוחות בקרה שימושיים
במסוף GCP, מצמידים את מרכזי הבקרה Kubernetes Engine ו-Storage כדי לגשת אליהם בקלות.

יצירת התקנה של AI Platform Pipelines (Hosted Kubeflow Pipelines)
כדי להגדיר מכונת GKE עם KFP מותקן, פועלים לפי ההוראות שבקטעים 'לפני שמתחילים' ו'הגדרת המכונה' כאן. חשוב לסמן את התיבה אישור גישה לממשקי ה-API הבאים של Cloud כמו שמוסבר במסמכי התיעוד. (אם לא, צינור העיבוד לדוגמה לא יפעל). משאירים את מרחב השמות של ההתקנה כ-default.
תצטרכו לבחור אזור שתומך ב-Nvidia k80s. אפשר להשתמש ב-us-central1-a או ב-us-central1-c כברירות מחדל.
אחרי שההתקנה מסתיימת, כדאי לרשום את שם האשכול ואזור הזמן של GKE שמופיעים בהתקנה בלוח הבקרה של AI Pipelines, ולהגדיר משתני סביבה עם הערכים האלה.

export ZONE=<your zone> export CLUSTER_NAME=<your cluster name>
הגדרה של kubectl לשימוש בפרטי הכניסה של אשכול GKE החדש
אחרי שיוצרים את אשכול GKE, מריצים את הפקודה הבאה ב-Cloud Shell כדי להגדיר את kubectl לשימוש בפרטי הכניסה של האשכול החדש:
gcloud container clusters get-credentials ${CLUSTER_NAME} \
--project ${PROJECT_ID} \
--zone ${ZONE}
אפשרות אחרת היא ללחוץ על שם האשכול בלוח הבקרה של AI Pipelines כדי לעבור לדף GKE שלו, ואז ללחוץ על 'חיבור' בחלק העליון של הדף. בחלון הקופץ, מדביקים את הפקודה ב-Cloud Shell.
הפעולה הזו מגדירה את ההקשר של kubectl כדי שתוכלו ליצור אינטראקציה עם האשכול. כדי לאמת את ההגדרה, מריצים את הפקודה הבאה:
kubectl get nodes -o wide
אמורים לראות רשימה של צמתים עם הסטטוס Ready ומידע נוסף על גיל הצומת, הגרסה, כתובת ה-IP החיצונית, תמונת מערכת ההפעלה, גרסת הליבה וזמן הריצה של הקונטיינר.
הגדרת האשכול להתקנת הדרייבר של Nvidia במאגרי צמתים עם GPU
בשלב הבא, נחיל daemonset על האשכול, שיגרום להתקנת מנהל ההתקן של Nvidia בכל צמתי האשכולות עם GPU:
kubectl apply -f https://raw.githubusercontent.com/GoogleCloudPlatform/container-engine-accelerators/master/nvidia-driver-installer/cos/daemonset-preloaded.yaml
לאחר מכן מריצים את הפקודה הבאה, שנותנת לרכיבי KFP הרשאה ליצור משאבי Kubernetes חדשים:
kubectl create clusterrolebinding sa-admin --clusterrole=cluster-admin --serviceaccount=kubeflow:pipeline-runner
יצירת מאגר צמתים של מעבדים גרפיים
לאחר מכן, נגדיר מאגר צמתים של GPU בגודל 1:
gcloud container node-pools create gpu-pool \
--cluster=${CLUSTER_NAME} \
--zone ${ZONE} \
--num-nodes=1 \
--machine-type n1-highmem-8 \
--scopes cloud-platform --verbosity error \
--accelerator=type=nvidia-tesla-k80,count=1
3. הפעלת צינור עיבוד נתונים ממרכז הבקרה Pipelines
פתיחת מרכז הבקרה של צינורות העברת הנתונים
אם אתם לא נמצאים ב-Cloud Console, נכנסים אל החלונית Pipelines. אחר כך לוחצים על OPEN PIPELINES DASHBOARD (פתיחת לוח הבקרה של צינורות הנתונים) בהתקנה, ולוחצים על Pipelines (צינורות נתונים) בסרגל התפריטים הימני. אם מופיעה שגיאת טעינה, מרעננים את הכרטיסייה. אמור להופיע דף חדש כמו זה:
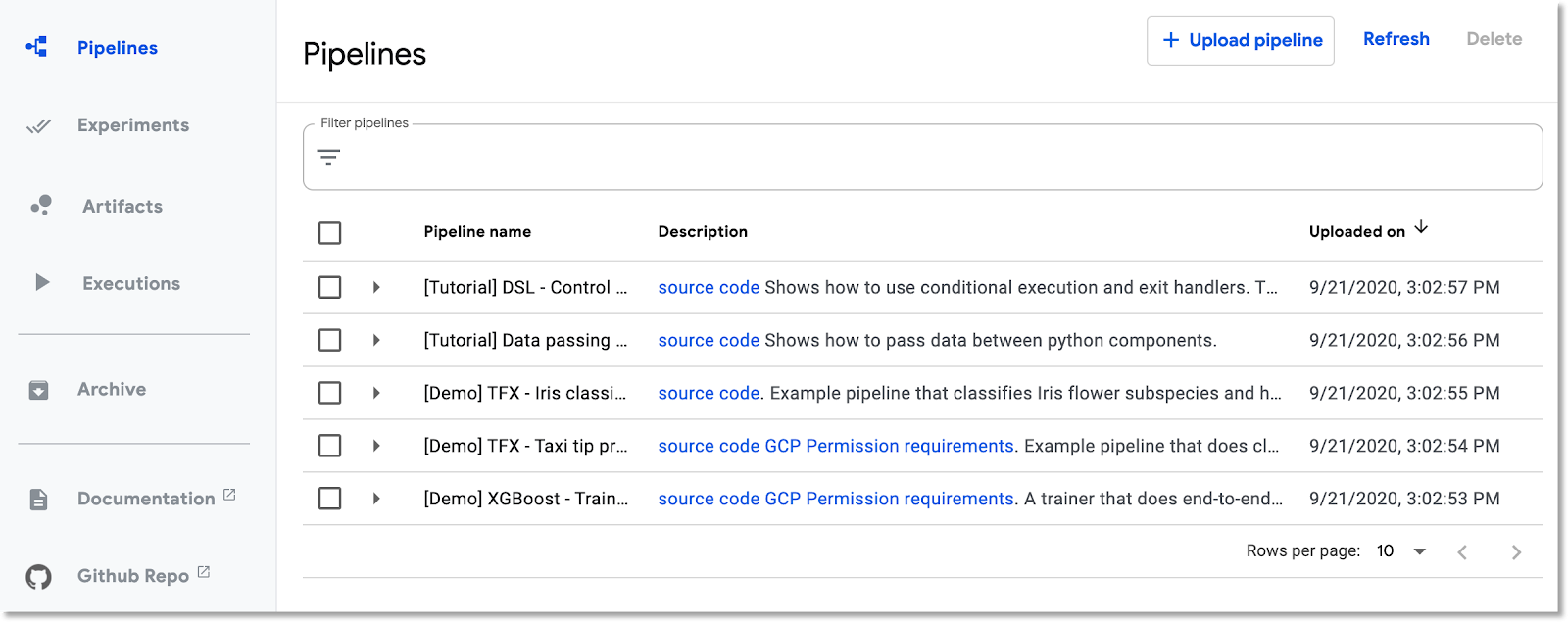
תיאור צינור עיבוד הנתונים
לצינור שתפעילו יש כמה שלבים (פרטים מופיעים בנספח של ה-codelab הזה):
- עותק של נקודת ביקורת קיימת של מודל מועתק לקטגוריה.
- מודל Tensor2Tensor עובר אימון באמצעות נתונים שעברו עיבוד מראש.
- האימון מתחיל מנקודת הבדיקה של המודל הקיים שהועתקה בשלב הראשון, ואז מתבצע אימון למאות שלבים נוספים. (ייקח יותר מדי זמן לאמן אותו באופן מלא במהלך ה-codelab).
- בסיום האימון, שלב צינור עיבוד הנתונים מייצא את המודל בפורמט שמתאים להצגה באמצעות TensorFlow Serving.
- מופע TensorFlow-serving נפרס באמצעות המודל הזה.
- אפליקציית אינטרנט מופעלת כדי ליצור אינטראקציה עם המודל שמוצג ולאחזר תחזיות.
הורדה והידור של הפייפליין
בקטע הזה נסביר איך לקמפל הגדרה של צינור. הדבר הראשון שצריך לעשות הוא להתקין את KFP SDK. מריצים את הפקודה הבאה ב-Cloud Shell:
pip3 install -U kfp
כדי להוריד את קובץ הגדרת צינור העיבוד, מריצים את הפקודה הזו מ-Cloud Shell:
curl -O https://raw.githubusercontent.com/amygdala/kubeflow-examples/ghsumm/github_issue_summarization/pipelines/example_pipelines/gh_summ_hosted_kfp.py
לאחר מכן, קומפלו את קובץ הגדרת הצינור על ידי הרצתו כך:
python3 gh_summ_hosted_kfp.py
הקובץ gh_summ_hosted_kfp.py.tar.gz יופיע כתוצאה.
העלאת צינור עיבוד הנתונים המהודר
בממשק המשתמש באינטרנט של Kubeflow Pipelines, לוחצים על Upload pipeline (העלאת צינור) ובוחרים באפשרות Import by URL (ייבוא לפי כתובת URL). מעתיקים את כתובת ה-URL הבאה, שמפנה לאותו צינור שזה עתה קומפלתם, ואז מדביקים אותה. (כדי להעלות קובץ מ-Cloud Shell צריך לבצע כמה שלבים נוספים, אז אנחנו משתמשים בקיצור דרך).
נותנים שם לצינור (למשל, gh_summ).

הפעלת צינור עיבוד הנתונים
לוחצים על צינור הנתונים שהועלה ברשימה כדי לראות את הגרף הסטטי של צינור הנתונים, ואז לוחצים על יצירת ניסוי כדי ליצור ניסוי חדש באמצעות צינור הנתונים. ניסוי הוא דרך לקבץ ריצות שקשורות זו לזו מבחינה סמנטית.
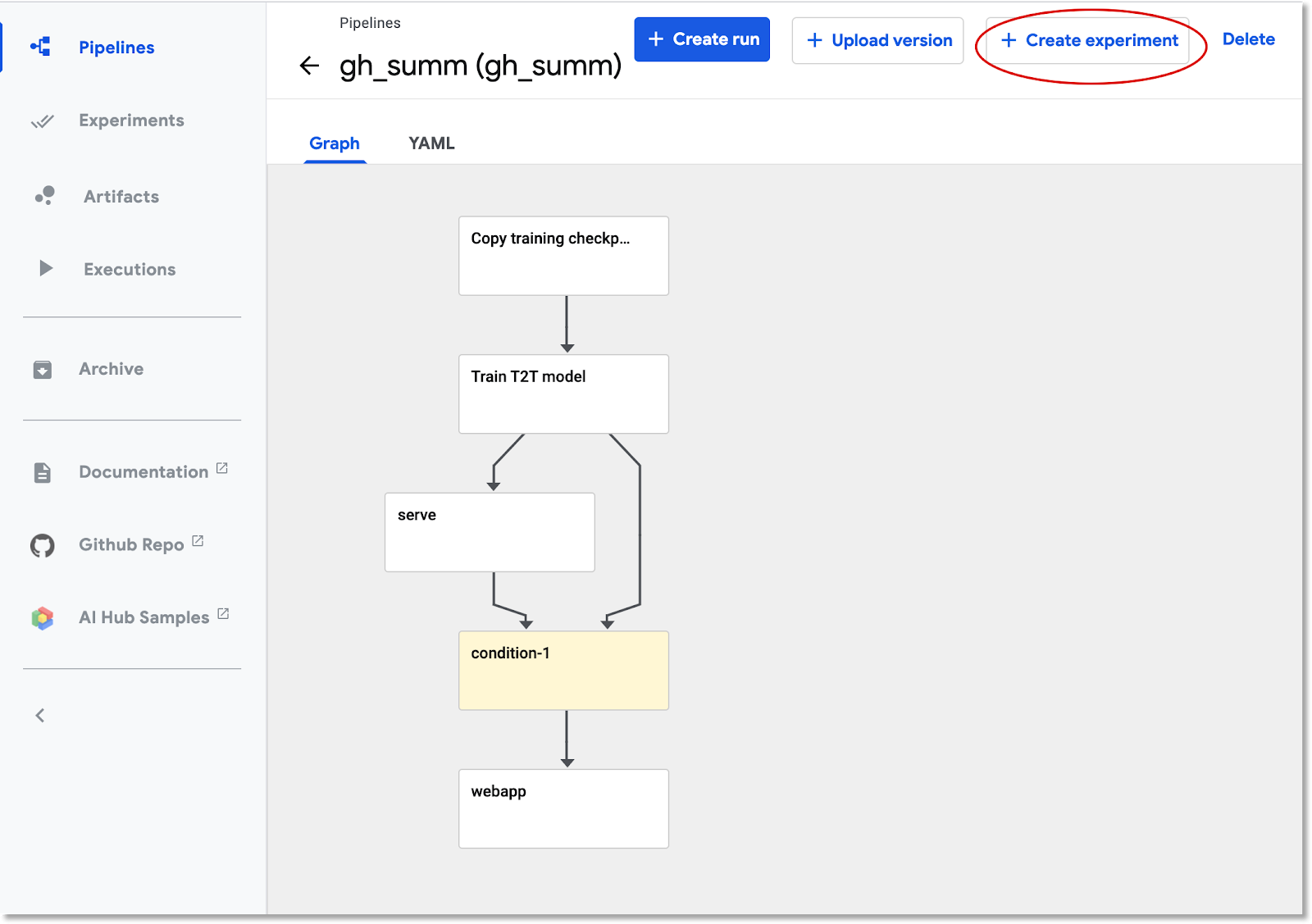
נותנים שם לניסוי (למשל, אותו שם כמו של צינור העיבוד, gh_summ) ואז לוחצים על Next (הבא) כדי ליצור אותו.

יוצג דף שבו אפשר להזין את הפרמטרים להרצה ולהתחיל אותה.
כדי למלא את הפרמטרים, כדאי להריץ את הפקודות הבאות ב-Cloud Shell.
gcloud config get-value project
echo "gs://${BUCKET_NAME}/codelab"
השם של הריצה יאוכלס אוטומטית, אבל אפשר לתת לו שם אחר אם רוצים.
לאחר מכן ממלאים שלושה שדות של פרמטרים:
project- (אופציונלי)
github-token working-dir
בשדה working-dir, מזינים נתיב כלשהו מתחת לקטגוריית GCS שיצרתם. כוללים את הקידומת gs://. בשדה github-token, מזינים את האסימון שיצרתם קודם (אם יצרתם אסימון), או משאירים את מחרוזת ה-placeholder כמו שהיא (אם לא יצרתם אסימון).

אחרי שממלאים את השדות, לוחצים על התחלה ואז על ההרצה שמופיעה ברשימה כדי לראות את הפרטים שלה. בזמן ששלב מסוים בצינור העברת הנתונים פועל, אפשר ללחוץ עליו כדי לקבל מידע נוסף לגביו, כולל הצגת היומנים של ה-pod שלו. (אפשר גם לראות את היומנים של שלב בצינור דרך הקישור ליומנים שלו ב-Cloud Logging (Stackdriver), גם אם צומת האשכול נהרס).

הצגת ההגדרה של צינור עיבוד הנתונים
בזמן שהצינור פועל, כדאי להתעמק בדרך שבה הוא בנוי ובמה שהוא עושה. פרטים נוספים זמינים בקטע נספח של ה-codelab.
הצגת מידע על אימון המודל ב-TensorBoard
אחרי ששלב האימון מסתיים, בוחרים בכרטיסייה Visualizations (הדמיות) ולוחצים על הלחצן הכחול Start TensorBoard (הפעלת TensorBoard). כשהוא מוכן, לוחצים על Open Tensorboard (פתיחת TensorBoard).

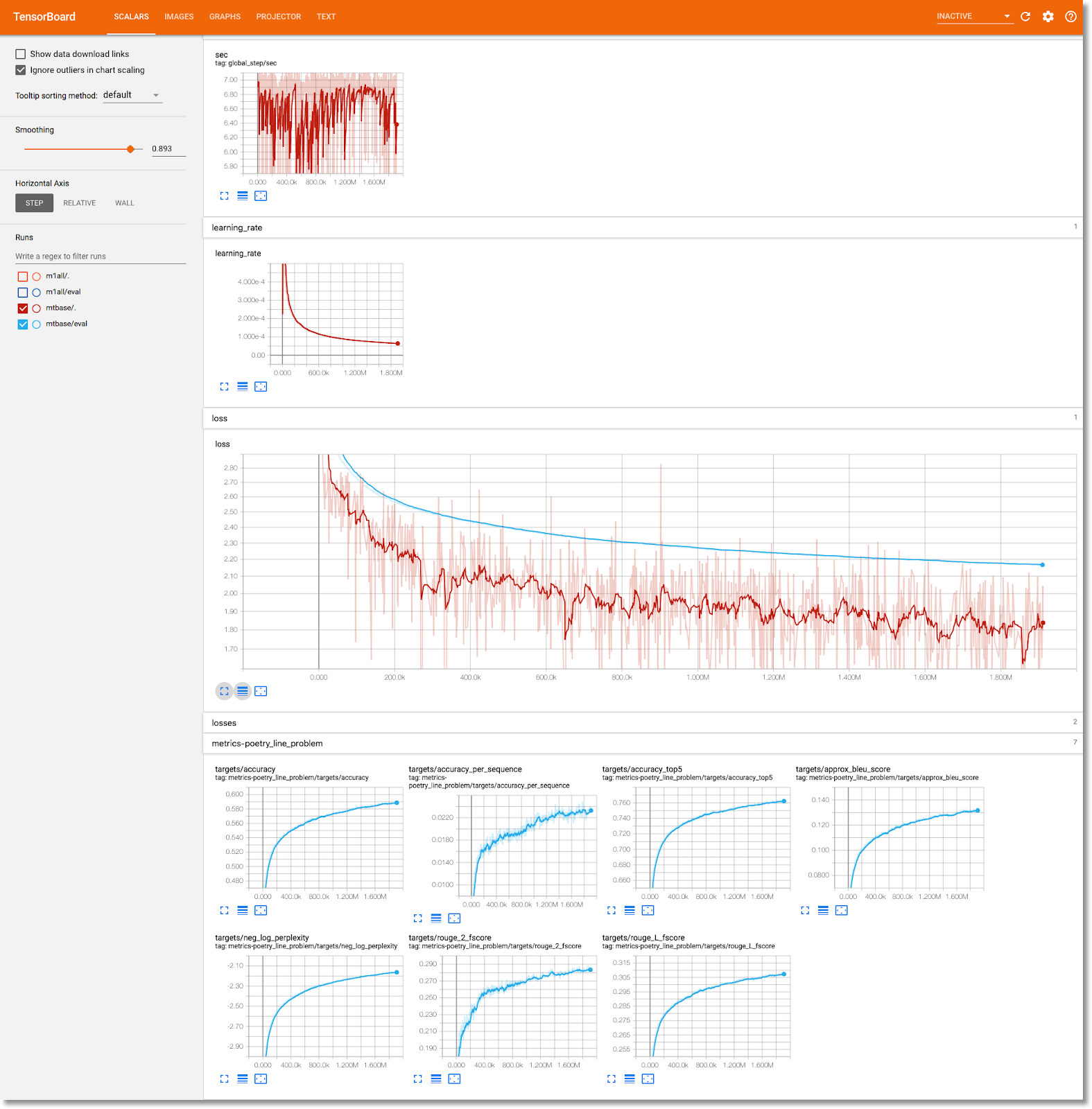
הסבר על מרכז הבקרה של Artifacts and Executions
מערכת Kubeflow Pipelines מתעדת באופן אוטומטי מטא-נתונים לגבי שלבי הצינור בזמן שהצינור פועל. המערכת מתעדת את המידע על ארטיפקטים ועל הפעלה. כדי לקבל מידע נוסף, לוחצים על הערכים האלה בסרגל הניווט הימני של מרכז הבקרה.
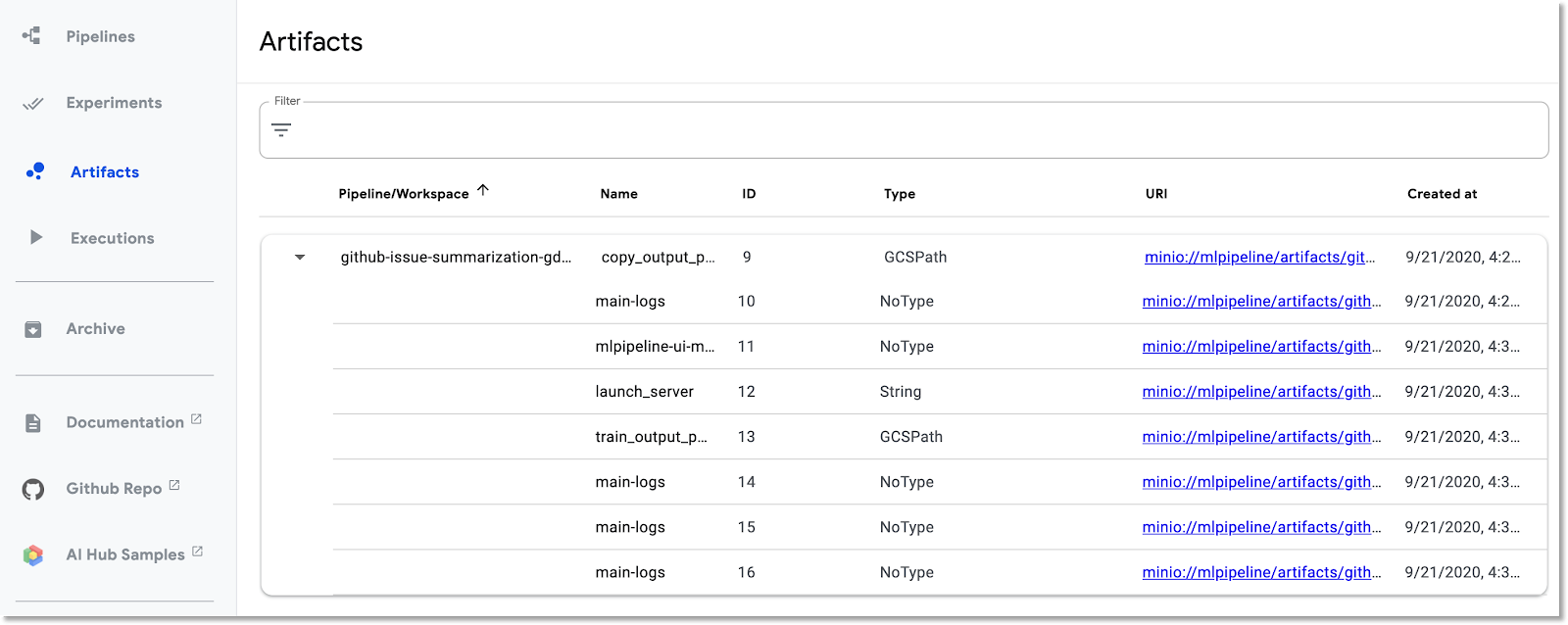
במקרה של ארטיפקטים, אפשר לראות גם חלונית סקירה כללית וגם חלונית של כלי מחקר של שרשרת היוחסין.


להציג את אפליקציית האינטרנט שנוצרה על ידי צינור עיבוד הנתונים וליצור כמה תחזיות
השלב האחרון בצינור הוא פריסה של אפליקציית אינטרנט שמספקת ממשק משתמש לשליחת שאילתות למודל שעבר אימון – המודל מוגש באמצעות TF Serving – כדי ליצור תחזיות.
אחרי שהצינור יסיים את הפעולה, מתחברים לאפליקציית האינטרנט באמצעות הפניית יציאה אל השירות שלה (אנחנו מפנים יציאה כי במסגרת ה-codelab הזה, שירות אפליקציית האינטרנט לא מוגדר עם נקודת קצה חיצונית).
כדי למצוא את שם השירות, מריצים את הפקודה הבאה ב-Cloud Shell:
kubectl get services
מחפשים ברשימה שם של שירות כמו ghsumm-*-webappsvc.
לאחר מכן, ב-Cloud Shell, מעבירים את היציאה לשירות הזה באופן הבא, משנים את הפקודה הבאה כדי להשתמש בשם של webappsvc:
kubectl port-forward svc/ghsumm-xxxxx-webappsvc 8080:80
אחרי שהעברת הפורטים פועלת, לוחצים על סמל התצוגה המקדימה מעל חלונית Cloud Shell, ובתפריט הנפתח לוחצים על 'תצוגה מקדימה בפורט 8080'.
בכרטיסייה חדשה אמור להופיע דף כמו זה:

לוחצים על הכפתור Populate Random Issue (מילוי בעיה אקראית) כדי לאחזר בלוק טקסט. לוחצים על יצירת כותרת כדי להפעיל את המודל המאומן ולהציג חיזוי.
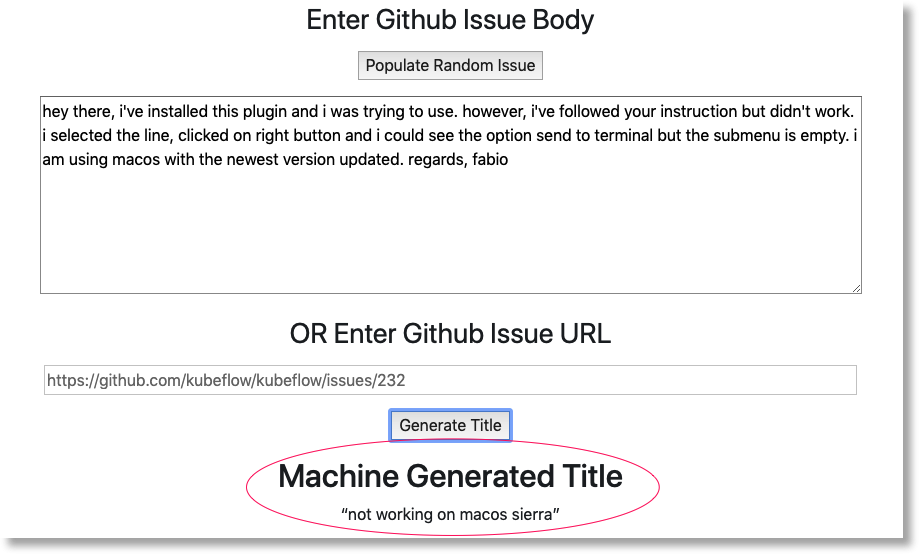
אם פרמטרי צינור העיבוד כוללים אסימון GitHub תקין, אפשר גם להזין כתובת URL של GitHub בשדה השני ואז ללחוץ על 'יצירת שם'. אם לא הגדרתם טוקן GitHub תקין, אתם יכולים להשתמש רק בשדה Populate Random Issue (מילוי בעיה אקראית).
4. הפעלת צינור עיבוד נתונים מ-AI Platform Notebook
אפשר גם להגדיר ולהריץ באופן אינטראקטיבי צינורות של Kubeflow ממחברת Jupyter באמצעות KFP SDK. AI Platform Notebooks, שבה נשתמש ב-codelab הזה, הופכת את התהליך לפשוט מאוד.
יצירת מופע של Notebook
ניצור מופע של מחברת מ-Cloud Shell באמצעות ה-API שלו. (לחלופין, אפשר ליצור מחברת דרך Cloud Console. מידע נוסף זמין במאמרי העזרה בנושא .
מגדירים את משתני הסביבה הבאים ב-Cloud Shell:
export INSTANCE_NAME="kfp-ghsumm" export VM_IMAGE_PROJECT="deeplearning-platform-release" export VM_IMAGE_FAMILY="tf2-2-3-cpu" export MACHINE_TYPE="n1-standard-4" export LOCATION="us-central1-c"
לאחר מכן, מריצים את הפקודה ליצירת מופע של מחברת מ-Cloud Shell:
gcloud beta notebooks instances create $INSTANCE_NAME \ --vm-image-project=$VM_IMAGE_PROJECT \ --vm-image-family=$VM_IMAGE_FAMILY \ --machine-type=$MACHINE_TYPE --location=$LOCATION
כשמריצים את הפקודה הזו בפעם הראשונה, יכול להיות שתתבקשו להפעיל את notebooks API בפרויקט. אם כן, צריך להשיב 'y'.
אחרי כמה דקות, שרת המחברת יפעל. אפשר לראות את מופעי המחברת ברשימה במסוף Cloud.

העלאה של מחברת Codelab
אחרי שיוצרים את מופע המחברת, לוחצים על הקישור הזה כדי להעלות את מחברת Jupyter של ה-codelab. בוחרים את מופע המחברת שרוצים להשתמש בו. ה-notebook ייפתח אוטומטית.
הפעלת ה-Notebook
פועלים לפי ההוראות במחברת כדי להשלים את שאר שיעור ה-Lab. שימו לב שבחלק 'הגדרה' של המחברת, תצטרכו למלא את הערכים שלכם לפני שתריצו את שאר המחברת.
(אם אתם משתמשים בפרויקט משלכם, אל תשכחו לחזור ולבצע את השלבים שבקטע 'ניקוי' במעבדה הזו).
5. הסרת המשאבים
אם אתם משתמשים בחשבון זמני של Codelab, אתם לא צריכים לעשות את זה, אבל אם אתם משתמשים בפרויקט משלכם, כדאי להסיר את ההתקנה של Pipelines ואת המחברת.
הסרת אשכול GKE של Pipelines
אפשר למחוק את אשכול הצינורות ממסוף Cloud. (יש לכם אפשרות פשוט למחוק את ההתקנה של Pipelines אם אתם רוצים לעשות שימוש חוזר באשכול GKE).
מחיקת מכונת AI Notebook
אם הפעלתם את החלק 'מחברת' של ה-codelab, תוכלו למחוק או להפסיק את מופע המחברת מ-Cloud Console.
אופציונלי: מסירים את הטוקן של GitHub
עוברים אל https://github.com/settings/tokens ומסירים את הטוקן שנוצר.
6. נספחים
סקירת הקוד
הגדרת צינור עיבוד הנתונים
הצינור שבו נעשה שימוש ב-codelab הזה מוגדר כאן.
בואו נראה איך הוא מוגדר ואיך מוגדרים הרכיבים שלו (השלבים). בהמשך נציג כמה מהנקודות החשובות, אבל פרטים נוספים מופיעים בתיעוד.
השלבים בצינור Kubeflow מבוססים על קונטיינרים. כשיוצרים צינור עיבוד נתונים, אפשר להשתמש ברכיבים מוכנים מראש עם קובצי אימג' של קונטיינרים שכבר נוצרו, או ליצור רכיבים משלכם. ב-Codelab הזה בנינו משלנו.
ארבעה מהשלבים בצינור מוגדרים מתוך רכיבים שאפשר לעשות בהם שימוש חוזר, שאפשר לגשת אליהם דרך קבצי הגדרת הרכיבים. בקטע הקוד הראשון, אנחנו ניגשים לקובצי ההגדרות של הרכיבים האלה באמצעות כתובת ה-URL שלהם, ומשתמשים בהגדרות האלה כדי ליצור 'פעולות' שנשתמש בהן כדי ליצור שלב בצינור.
import kfp.dsl as dsl
import kfp.gcp as gcp
import kfp.components as comp
...
copydata_op = comp.load_component_from_url(
'https://raw.githubusercontent.com/kubeflow/examples/master/github_issue_summarization/pipelines/components/t2t/datacopy_component.yaml'
)
train_op = comp.load_component_from_url(
'https://raw.githubusercontent.com/kubeflow/examples/master/github_issue_summarization/pipelines/components/t2t/train_component.yaml'
)
בהמשך מופיעה אחת מהגדרות הרכיבים, עבור פעולת ההדרכה, בפורמט yaml. אפשר לראות שהוגדרו לו קלט, פלט, קובץ אימג' של קונטיינר וארגומנטים של נקודת הכניסה לקונטיינר.
name: Train T2T model
description: |
A Kubeflow Pipeline component to train a Tensor2Tensor
model
metadata:
labels:
add-pod-env: 'true'
inputs:
- name: train_steps
description: '...'
type: Integer
default: 2019300
- name: data_dir
description: '...'
type: GCSPath
- name: model_dir
description: '...'
type: GCSPath
- name: action
description: '...'
type: String
- name: deploy_webapp
description: '...'
type: String
outputs:
- name: launch_server
description: '...'
type: String
- name: train_output_path
description: '...'
type: GCSPath
- name: MLPipeline UI metadata
type: UI metadata
implementation:
container:
image: gcr.io/google-samples/ml-pipeline-t2ttrain:v3ap
args: [
--data-dir, {inputValue: data_dir},
--action, {inputValue: action},
--model-dir, {inputValue: model_dir},
--train-steps, {inputValue: train_steps},
--deploy-webapp, {inputValue: deploy_webapp},
--train-output-path, {outputPath: train_output_path}
]
env:
KFP_POD_NAME: "{{pod.name}}"
fileOutputs:
launch_server: /tmp/output
MLPipeline UI metadata: /mlpipeline-ui-metadata.json
אפשר גם להגדיר שלב בצינור באמצעות ה-constructor dsl.ContainerOp, כפי שמוסבר בהמשך.
בהמשך מופיע רוב ההגדרה של צינור הנתונים. אנחנו מגדירים את נתוני הקלט של צינור העיבוד (ואת ערכי ברירת המחדל שלהם). לאחר מכן מגדירים את השלבים בצינור. ברוב המקרים אנחנו משתמשים ב-ops שהוגדר למעלה, אבל אנחנו גם מגדירים שלב serve בשורה באמצעות ContainerOp, ומציינים ישירות את קובץ אימג' של קונטיינר ואת ארגומנטי נקודת הכניסה.
אפשר לראות שהשלבים train, log_model ו-serve ניגשים לפלט משלבים קודמים כקלט. מידע נוסף על הגדרת המיקום זמין כאן.
@dsl.pipeline(
name='Github issue summarization',
description='Demonstrate Tensor2Tensor-based training and TF-Serving'
)
def gh_summ( #pylint: disable=unused-argument
train_steps: 'Integer' = 2019300,
project: str = 'YOUR_PROJECT_HERE',
github_token: str = 'YOUR_GITHUB_TOKEN_HERE',
working_dir: 'GCSPath' = 'gs://YOUR_GCS_DIR_HERE',
checkpoint_dir: 'GCSPath' = 'gs://aju-dev-demos-codelabs/kubecon/model_output_tbase.bak2019000/',
deploy_webapp: str = 'true',
data_dir: 'GCSPath' = 'gs://aju-dev-demos-codelabs/kubecon/t2t_data_gh_all/'
):
copydata = copydata_op(
data_dir=data_dir,
checkpoint_dir=checkpoint_dir,
model_dir='%s/%s/model_output' % (working_dir, dsl.RUN_ID_PLACEHOLDER),
action=COPY_ACTION,
)
train = train_op(
data_dir=data_dir,
model_dir=copydata.outputs['copy_output_path'],
action=TRAIN_ACTION, train_steps=train_steps,
deploy_webapp=deploy_webapp
)
serve = dsl.ContainerOp(
name='serve',
image='gcr.io/google-samples/ml-pipeline-kubeflow-tfserve:v6',
arguments=["--model_name", 'ghsumm-%s' % (dsl.RUN_ID_PLACEHOLDER,),
"--model_path", train.outputs['train_output_path']
]
)
train.set_gpu_limit(1)
שימו לב שנדרש להריץ את שלב ה-train (אימון) בצומת באשכול שיש בו לפחות GPU אחד זמין.
train.set_gpu_limit(1)
השלב האחרון בצינור, שמוגדר גם הוא בתוך השורה, הוא שלב מותנה. היא תפעל אחרי שהשלב serve יסתיים, רק אם הפלט של שלב האימון launch_server הוא המחרוזת true. הוא מפעיל את 'אפליקציית האינטרנט לחיזוי', שבה השתמשנו כדי לבקש סיכומים של בעיות מהמודל המאומן T2T.
with dsl.Condition(train.outputs['launch_server'] == 'true'):
webapp = dsl.ContainerOp(
name='webapp',
image='gcr.io/google-samples/ml-pipeline-webapp-launcher:v1',
arguments=["--model_name", 'ghsumm-%s' % (dsl.RUN_ID_PLACEHOLDER,),
"--github_token", github_token]
)
webapp.after(serve)
הגדרות של קובצי אימג' של קונטיינרים של רכיבים
במסמכי התיעוד של Kubeflow Pipeline מפורטות כמה שיטות מומלצות ליצירת רכיבים משלכם. כחלק מהתהליך, תצטרכו להגדיר ולבנות קובץ אימג' של קונטיינר. כאן אפשר לראות את השלבים של צינור הנתונים של ה-codelab הזה. ההגדרות של Dockerfile נמצאות בספריות המשנה containers, לדוגמה כאן.
שימוש במכונות וירטואליות שניתן להפסיק את הפעולה שלהן עם יחידות GPU לאימון
מכונות וירטואליות שניתן להפסיק הן מופעים של מכונות וירטואליות של Compute Engine שפועלות למשך 24 שעות לכל היותר, ואין לגביהן ערבויות זמינות. המחיר של מכונות וירטואליות שניתן להפסיק הוא נמוך יותר מהמחיר של מכונות וירטואליות רגילות ב-Compute Engine.
ב-Google Kubernetes Engine (GKE), קל להגדיר אשכול או מאגר צמתים שמשתמשים במכונות וירטואליות שניתנות להפסקת פעולה. אפשר להגדיר מאגר צמתים כזה עם מעבדי GPU שמצורפים למכונות שניתנות להפסקת פעולה. הם פועלים כמו צמתים רגילים עם GPU, אבל ה-GPU נשמר רק למשך חיי המופע.
כדי להגדיר מאגר צמתים זמני עם GPU לאשכול, מריצים פקודה שדומה לפקודה הבאה, עורכים את הפקודה עם שם האשכול והאזור, ומשנים את סוג המאיץ והמספר שלו בהתאם לדרישות. אפשר גם להגדיר את מאגר הצמתים כך שיתבצע בו שינוי גודל אוטומטי על סמך עומסי העבודה הנוכחיים.
gcloud container node-pools create preemptible-gpu-pool \
--cluster=<your-cluster-name> \
--zone <your-cluster-zone> \
--enable-autoscaling --max-nodes=4 --min-nodes=0 \
--machine-type n1-highmem-8 \
--preemptible \
--node-taints=preemptible=true:NoSchedule \
--scopes cloud-platform --verbosity error \
--accelerator=type=nvidia-tesla-k80,count=4
אפשר גם להגדיר מאגר צמתים דרך Cloud Console.
הגדרת צינור עיבוד נתונים של Kubeflow שמשתמש בצמתים ניתנים להפסקת פעולה ב-GKE
אם אתם מריצים את Kubeflow ב-GKE, עכשיו קל יותר להגדיר ולהריץ Kubeflow Pipelines שבהם שלב אחד או יותר בצינור (רכיבים) פועלים בצמתים שניתן לקטוע, וכך להפחית את העלות של הרצת משימה. כדי להשתמש במכונות וירטואליות שניתן להפסיק את הפעולה שלהן ולקבל תוצאות נכונות, השלבים שאתם מזהים כשלבים שניתן להפסיק את הפעולה שלהם צריכים להיות אידמפוטנטיים (כלומר, אם מריצים שלב כמה פעמים, התוצאה תהיה זהה), או שהם צריכים לבצע צ'קפוינט של העבודה כדי שאם תהיה הפרעה, השלב יוכל להמשיך מהמקום שבו הוא הפסיק.
כשמגדירים Kubeflow Pipeline, אפשר לציין ששלב מסוים יפעל על צומת שניתן להפסיק את הפעולה שלו. כדי לעשות זאת, משנים את האופרטור באופן הבא:
your_pipelines_op.apply(gcp.use_preemptible_nodepool())
פרטים נוספים זמינים במסמכי התיעוד.
סביר להניח שתרצו גם לנסות שוב את השלב מספר פעמים אם הצומת נדחק. כך עושים זאת – כאן מציינים 5 ניסיונות חוזרים.
your_pipelines_op.set_gpu_limit(1).apply(gcp.use_preemptible_nodepool()).set_retry(5)
נסו לערוך את צינור עיבוד הנתונים של Kubeflow שבו השתמשנו ב-Codelab הזה כדי להריץ את שלב האימון ב-VM זמני.
משנים את השורה הבאה במפרט של צינור העיבוד כך שתשתמש בנוסף במאגר צמתים שניתן להפסיק (חשוב לוודא שיצרתם מאגר כזה כמו שצוין למעלה), ותנסה שוב 5 פעמים:
train.set_gpu_limit(1)
לאחר מכן, קומפלו מחדש את צינור העיבוד, מעלים את הגרסה החדשה (נותנים לה שם חדש) ומריצים את הגרסה החדשה של צינור העיבוד.