
1. Pengantar
| Kubeflow adalah toolkit Machine Learning untuk Kubernetes. Project ini ditujukan untuk menyederhanakan, mempermudah, dan menskalakan deployment alur kerja Machine Learning (ML) di Kubernetes. Tujuannya adalah menyediakan cara mudah untuk men-deploy sistem open source terbaik untuk ML ke berbagai infrastruktur. |
| Alur kerja machine learning dapat melibatkan banyak langkah dengan saling bergantung satu sama lain, mulai dari persiapan dan analisis data, hingga pelatihan, evaluasi, deployment, dan lainnya. Sulit untuk menyusun dan melacak proses ini secara ad-hoc—misalnya, dalam serangkaian notebook atau skrip—dan hal-hal seperti audit dan reproduksibilitas menjadi semakin bermasalah.Kubeflow Pipelines (KFP) membantu menyelesaikan masalah ini dengan menyediakan cara untuk men-deploy pipeline machine learning yang andal dan dapat diulang bersama dengan pemantauan, audit, pelacakan versi, dan reproduksibilitas. Cloud AI Pipelines mempermudah penyiapan penginstalan KFP. |


Yang akan Anda bangun
Dalam codelab ini, Anda akan mem-build aplikasi web yang meringkas masalah GitHub menggunakan Kubeflow Pipelines untuk melatih dan menayangkan model. Contoh ini didasarkan pada contoh di repositori Contoh Kubeflow. Setelah selesai, infrastruktur Anda akan berisi:
- Cluster Google Kubernetes Engine (GKE) dengan Kubeflow Pipelines yang diinstal (melalui Cloud AI Pipelines).
- Pipeline yang melatih model Tensor2Tensor di GPU
- Container penyajian yang memberikan prediksi dari model terlatih
- UI yang menafsirkan prediksi untuk memberikan ringkasan masalah GitHub
- Notebook yang membuat pipeline dari awal menggunakan Kubeflow Pipelines (KFP) SDK
Yang akan Anda pelajari
Pipeline yang akan Anda buat melatih model Tensor2Tensor pada data masalah GitHub, dengan mempelajari cara memprediksi judul masalah dari isi masalah. Kemudian, model terlatih diekspor dan di-deploy menggunakan Tensorflow Serving. Langkah terakhir dalam pipeline meluncurkan aplikasi web, yang berinteraksi dengan instance TF-Serving untuk mendapatkan prediksi model.
- Cara menginstal Kubeflow Pipelines di cluster GKE
- Cara membangun dan menjalankan alur kerja ML menggunakan Kubeflow Pipelines
- Cara menentukan dan menjalankan pipeline dari AI Platform Notebook
Yang Anda butuhkan
- Pemahaman dasar tentang Kubernetes akan sangat membantu, tetapi tidak wajib
- Project GCP aktif yang izin Pemiliknya Anda miliki
- (Opsional) Akun GitHub
- Akses ke Google Cloud Shell, yang tersedia di Google Cloud Platform (GCP) Console
2. Penyiapan
Cloud Shell
Buka GCP Console di browser dan login dengan kredensial project Anda:
Klik "Select a project" jika perlu, sehingga Anda mengerjakan project codelab Anda.

Kemudian, klik ikon "Activate Cloud Shell" di kanan atas konsol untuk memulai Cloud Shell.

Saat Anda memulai Cloud Shell, Cloud Shell akan memberi tahu Anda nama project yang ditetapkan untuk digunakan. Pastikan setelan ini sudah benar.
Untuk menemukan project ID Anda, buka panel Beranda Konsol GCP. Jika layar kosong, klik 'Ya' pada perintah untuk membuat dasbor.
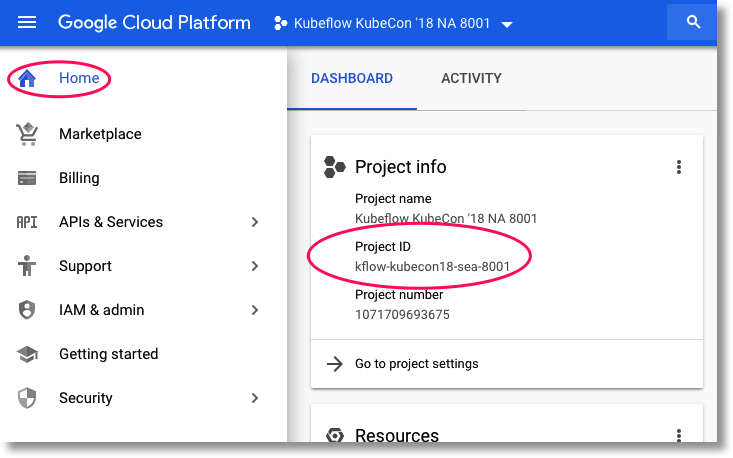
Kemudian, di terminal Cloud Shell, jalankan perintah ini jika perlu untuk mengonfigurasi gcloud agar menggunakan project yang benar:
export PROJECT_ID=<your_project_id>
gcloud config set project ${PROJECT_ID}
Membuat bucket penyimpanan
Buat bucket Cloud Storage untuk menyimpan file pipeline. Anda harus menggunakan ID yang unik secara global, jadi sebaiknya tentukan nama bucket yang menyertakan project ID Anda. Buat bucket menggunakan perintah gsutil mb (buat bucket):
export PROJECT_ID=<your_project_id>
export BUCKET_NAME=kubeflow-${PROJECT_ID}
gsutil mb gs://${BUCKET_NAME}
Atau, Anda dapat membuat bucket melalui Konsol GCP.
Opsional**: Buat token GitHub**
Codelab ini memanggil GitHub API untuk mengambil data yang tersedia secara publik. Untuk mencegah pembatasan kecepatan, terutama pada acara yang mengirimkan sejumlah besar permintaan anonim ke GitHub API, siapkan token akses tanpa izin. Tujuannya hanya untuk mengizinkan Anda sebagai individu, bukan pengguna anonim.
- Buka https://github.com/settings/tokens dan buat token baru tanpa cakupan.
- Simpan di tempat yang aman. Jika Anda kehilangannya, Anda harus menghapus dan membuat yang baru.
Jika Anda melewati langkah ini, lab akan tetap berfungsi – hanya saja opsi Anda untuk membuat data input guna menguji model akan sedikit lebih terbatas.
Opsional: Sematkan dasbor yang berguna
Di konsol GCP, sematkan dasbor Kubernetes Engine dan Storage untuk akses yang lebih mudah.

Buat penginstalan AI Platform Pipelines (Kubeflow Pipelines yang Dihosting)
Ikuti petunjuk di bagian 'Sebelum memulai' dan 'Siapkan instance Anda' di sini untuk menyiapkan instance GKE dengan KFP yang terinstal. Pastikan untuk mencentang kotak Izinkan akses ke Cloud API berikut seperti yang ditunjukkan dalam dokumentasi. (Jika tidak, contoh pipeline tidak akan berhasil dijalankan). Biarkan namespace penginstalan sebagai default.
Anda harus memilih zona yang mendukung Nvidia k80. Anda dapat menggunakan us-central1-a atau us-central1-c sebagai default.
Catat nama cluster dan zona GKE yang tercantum untuk penginstalan Anda di dasbor AI Pipelines setelah penginstalan selesai, dan untuk mempermudah, tetapkan variabel lingkungan ke nilai ini.

export ZONE=<your zone> export CLUSTER_NAME=<your cluster name>
Siapkan kubectl untuk menggunakan kredensial cluster GKE baru Anda
Setelah cluster GKE dibuat, konfigurasi kubectl untuk menggunakan kredensial cluster baru dengan menjalankan perintah berikut di Cloud Shell Anda:
gcloud container clusters get-credentials ${CLUSTER_NAME} \
--project ${PROJECT_ID} \
--zone ${ZONE}
Atau, klik nama cluster di dasbor AI Pipelines untuk membuka halaman GKE-nya, lalu klik "Connect" di bagian atas halaman. Dari pop-up, tempel perintah ke Cloud Shell Anda.
Perintah ini mengonfigurasi konteks kubectl sehingga Anda dapat berinteraksi dengan cluster. Untuk memverifikasi konfigurasi, jalankan perintah berikut:
kubectl get nodes -o wide
Anda akan melihat node yang tercantum dengan status "Ready", dan informasi lain tentang usia node, versi, alamat IP eksternal, image OS, versi kernel, dan runtime container.
Mengonfigurasi cluster untuk menginstal driver Nvidia di node pool yang mendukung GPU
Selanjutnya, kita akan menerapkan daemonset ke cluster, yang akan menginstal driver Nvidia di node cluster yang mendukung GPU:
kubectl apply -f https://raw.githubusercontent.com/GoogleCloudPlatform/container-engine-accelerators/master/nvidia-driver-installer/cos/daemonset-preloaded.yaml
Kemudian, jalankan perintah berikut, yang memberikan izin kepada komponen KFP untuk membuat resource Kubernetes baru:
kubectl create clusterrolebinding sa-admin --clusterrole=cluster-admin --serviceaccount=kubeflow:pipeline-runner
Membuat node pool GPU
Kemudian, kita akan menyiapkan node pool GPU dengan ukuran 1:
gcloud container node-pools create gpu-pool \
--cluster=${CLUSTER_NAME} \
--zone ${ZONE} \
--num-nodes=1 \
--machine-type n1-highmem-8 \
--scopes cloud-platform --verbosity error \
--accelerator=type=nvidia-tesla-k80,count=1
3. Menjalankan pipeline dari dasbor Pipelines
Buka dasbor Pipelines
Di Konsol Cloud, buka panel Pipelines jika Anda belum membukanya. Kemudian, klik "OPEN PIPELINES DASHBOARD" untuk penginstalan Anda, lalu klik Pipelines di panel menu kiri. Jika Anda mengalami error pemuatan, muat ulang tab. Anda akan melihat halaman baru seperti ini:

Deskripsi pipeline
Pipeline yang akan Anda jalankan memiliki beberapa langkah (lihat Lampiran codelab ini untuk mengetahui detailnya):
- Checkpoint model yang ada disalin ke bucket Anda.
- Model Tensor2Tensor dilatih menggunakan data yang telah diproses sebelumnya.
- Pelatihan dimulai dari titik pemeriksaan model yang ada yang disalin pada langkah pertama, lalu dilatih untuk beberapa ratus langkah lagi. (Pelatihan penuh akan memerlukan waktu terlalu lama selama codelab).
- Setelah pelatihan selesai, langkah pipeline akan mengekspor model dalam bentuk yang sesuai untuk inferensi oleh TensorFlow Serving.
- Instance TensorFlow Serving di-deploy menggunakan model tersebut.
- Aplikasi web diluncurkan untuk berinteraksi dengan model yang ditayangkan guna mengambil prediksi.
Mendownload dan mengompilasi pipeline
Di bagian ini, kita akan melihat cara mengompilasi definisi pipeline. Hal pertama yang perlu kita lakukan adalah menginstal KFP SDK. Jalankan perintah berikut di Cloud Shell:
pip3 install -U kfp
Untuk mendownload file definisi pipeline, jalankan perintah ini dari Cloud Shell:
curl -O https://raw.githubusercontent.com/amygdala/kubeflow-examples/ghsumm/github_issue_summarization/pipelines/example_pipelines/gh_summ_hosted_kfp.py
Kemudian, kompilasi file definisi pipeline dengan menjalankannya seperti ini:
python3 gh_summ_hosted_kfp.py
Anda akan melihat file gh_summ_hosted_kfp.py.tar.gz muncul sebagai hasilnya.
Mengupload pipeline yang dikompilasi
Di UI web Kubeflow Pipelines, klik Upload pipeline, lalu pilih Import by URL. Salin, lalu tempel URL berikut, yang mengarah ke pipeline yang sama yang baru saja Anda kompilasi. (Ada beberapa langkah tambahan untuk mengupload file dari Cloud Shell, jadi kita akan menggunakan cara pintas).
Beri nama pipeline (misalnya, gh_summ).

Menjalankan pipeline
Klik pipeline yang diupload dalam daftar —ini memungkinkan Anda melihat grafik statis pipeline— lalu klik Buat eksperimen untuk membuat Eksperimen baru menggunakan pipeline. Eksperimen adalah cara untuk mengelompokkan operasi yang terkait secara semantik.

Beri nama Eksperimen (misalnya, nama yang sama dengan pipeline, gh_summ), lalu klik Next untuk membuat.
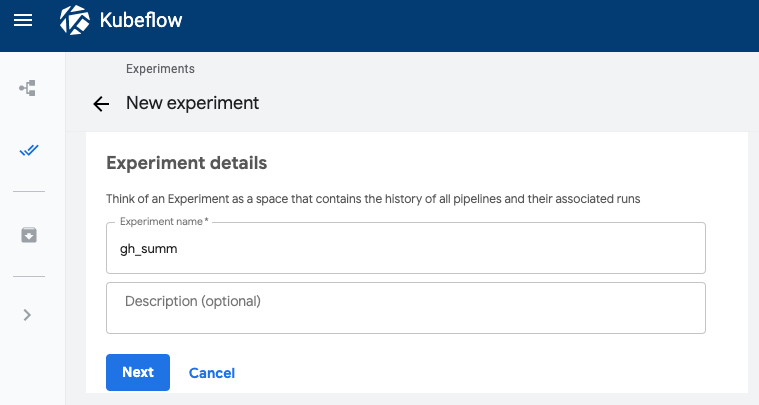
Tindakan ini akan membuka halaman tempat Anda dapat memasukkan parameter untuk Run dan memulainya.
Anda dapat menjalankan perintah berikut di Cloud Shell untuk membantu mengisi parameter.
gcloud config get-value project
echo "gs://${BUCKET_NAME}/codelab"
Nama Run akan otomatis diisi, tetapi Anda dapat memberikan nama yang berbeda jika ingin.
Kemudian, isi tiga kolom parameter:
project- (opsional)
github-token working-dir
Untuk working-dir, masukkan beberapa jalur di bucket GCS yang Anda buat. Sertakan awalan 'gs://'. Untuk kolom github-token, masukkan token yang Anda buat sebelumnya secara opsional, atau biarkan string placeholder apa adanya jika Anda tidak membuat token.

Setelah mengisi kolom, klik Start, lalu klik proses yang tercantum untuk melihat detailnya. Saat langkah pipeline tertentu berjalan, Anda dapat mengkliknya untuk mendapatkan informasi selengkapnya, termasuk melihat log pod-nya. (Anda juga dapat melihat log untuk langkah pipeline melalui link ke log Cloud Logging (Stackdriver), meskipun node cluster telah dihentikan).

Melihat definisi pipeline
Saat pipeline berjalan, Anda mungkin ingin melihat lebih dekat cara penyusunannya dan apa yang dilakukannya. Ada detail selengkapnya di bagian Lampiran codelab.
Melihat informasi pelatihan model di TensorBoard
Setelah langkah pelatihan selesai, pilih tab Visualisasi dan klik tombol Mulai TensorBoard berwarna biru, lalu setelah siap, klik Buka Tensorboard.


Menjelajahi dasbor Artefak dan Eksekusi
Kubeflow Pipelines secara otomatis mencatat metadata tentang langkah-langkah pipeline saat pipeline dijalankan. Informasi Artefak dan Eksekusi dicatat. Klik entri ini di panel navigasi kiri dasbor untuk mempelajari lebih lanjut.
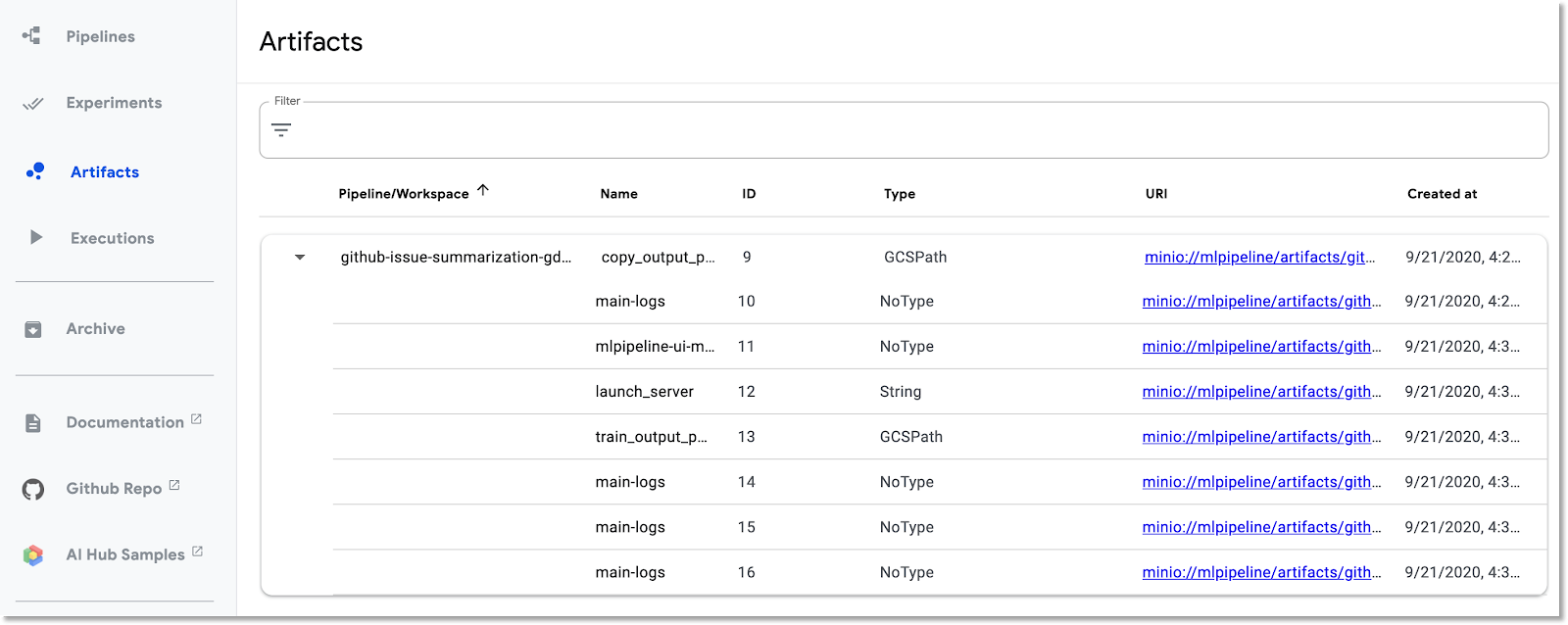
Untuk Artefak, Anda dapat melihat panel ringkasan dan panel Lineage Explorer.


Buka aplikasi web yang dibuat oleh pipeline dan buat beberapa prediksi
Langkah terakhir dalam pipeline men-deploy aplikasi web, yang menyediakan UI untuk membuat kueri model terlatih — yang ditayangkan melalui TF Serving — untuk membuat prediksi.
Setelah pipeline selesai, hubungkan ke aplikasi web dengan port-forwarding ke layanan-nya (kita melakukan port-forwarding karena, untuk codelab ini, layanan aplikasi web tidak disiapkan untuk memiliki endpoint eksternal).
Temukan nama layanan dengan menjalankan perintah ini di Cloud Shell:
kubectl get services
Cari nama layanan seperti ini: ghsumm-*-webappsvc dalam daftar.
Kemudian, di Cloud Shell, teruskan port ke layanan tersebut sebagai berikut, dengan mengubah perintah berikut untuk menggunakan nama webappsvc Anda:
kubectl port-forward svc/ghsumm-xxxxx-webappsvc 8080:80
Setelah penerusan port berjalan, klik ikon 'preview' di atas panel Cloud Shell, lalu di dropdown, klik "Preview on port 8080".

Anda akan melihat halaman seperti ini muncul di tab baru:

Klik tombol Populate Random Issue untuk mengambil blok teks. Klik Generate Title untuk memanggil model terlatih dan menampilkan prediksi.

Jika parameter pipeline Anda menyertakan token GitHub yang valid, Anda dapat mencoba memasukkan URL GitHub di kolom kedua, lalu mengklik "Buat Judul". Jika Anda tidak menyiapkan token GitHub yang valid, gunakan hanya kolom "Isi Masalah Acak".
4. Menjalankan pipeline dari AI Platform Notebook
Anda juga dapat secara interaktif menentukan dan menjalankan Kubeflow Pipelines dari notebook Jupyter menggunakan KFP SDK. AI Platform Notebooks, yang akan kita gunakan untuk codelab ini, membuatnya menjadi sangat mudah.
Membuat instance notebook
Kita akan membuat instance notebook dari Cloud Shell menggunakan API-nya. (Atau, Anda dapat membuat notebook melalui Konsol Cloud. Lihat dokumentasi untuk informasi selengkapnya).
Tetapkan variabel lingkungan berikut di Cloud Shell:
export INSTANCE_NAME="kfp-ghsumm" export VM_IMAGE_PROJECT="deeplearning-platform-release" export VM_IMAGE_FAMILY="tf2-2-3-cpu" export MACHINE_TYPE="n1-standard-4" export LOCATION="us-central1-c"
Kemudian, dari Cloud Shell, jalankan perintah untuk membuat instance notebook:
gcloud beta notebooks instances create $INSTANCE_NAME \ --vm-image-project=$VM_IMAGE_PROJECT \ --vm-image-family=$VM_IMAGE_FAMILY \ --machine-type=$MACHINE_TYPE --location=$LOCATION
Saat pertama kali menjalankan perintah ini, Anda mungkin diminta untuk mengaktifkan API notebooks untuk project Anda. Balas ‘y' jika ya.
Setelah beberapa menit, server notebook Anda akan aktif dan berjalan. Anda dapat melihat instance Notebook Anda tercantum di Konsol Cloud.

Mengupload notebook codelab
Setelah instance notebook dibuat, klik link ini untuk mengupload notebook Jupyter codelab. Pilih instance notebook yang akan digunakan. Notebook akan otomatis dibuka.
Jalankan notebook
Ikuti petunjuk di notebook untuk sisa lab. Perhatikan bahwa di bagian "Setup" pada notebook, Anda harus mengisi nilai Anda sendiri sebelum menjalankan bagian notebook lainnya.
(Jika Anda menggunakan project sendiri, jangan lupa untuk kembali dan melakukan bagian "Pembersihan" di lab ini).
5. Pembersihan
Anda tidak perlu melakukan hal ini jika menggunakan akun codelab sementara, tetapi Anda dapat menghapus penginstalan Pipelines dan Notebook jika menggunakan project Anda sendiri.
Menonaktifkan cluster GKE Pipelines
Anda dapat menghapus cluster Pipelines dari Konsol Cloud. (Anda memiliki opsi untuk menghapus penginstalan Pipelines saja jika ingin menggunakan kembali cluster GKE).
Menghapus instance AI Notebook
Jika Anda menjalankan bagian "Notebook" dari codelab, Anda dapat MENGHAPUS atau MENGHENTIKAN instance notebook dari Cloud Console.
Opsional: Menghapus token GitHub
Buka https://github.com/settings/tokens dan hapus token yang dibuat.
6. Lampiran
Melihat kode
Menentukan pipeline
Pipeline yang digunakan dalam codelab ini ditentukan di sini.
Mari kita lihat cara penentuannya, serta cara penentuan komponennya (langkah). Kami akan membahas beberapa poin penting, tetapi lihat dokumentasi untuk mengetahui detail selengkapnya.
Langkah-langkah Kubeflow Pipeline berbasis container. Saat membuat pipeline, Anda dapat menggunakan komponen bawaan, dengan image container yang sudah dibuat, atau membuat komponen Anda sendiri. Untuk codelab ini, kita telah membuat sendiri.
Empat langkah pipeline ditentukan dari komponen yang dapat digunakan kembali, yang diakses melalui file definisi komponen. Dalam cuplikan kode pertama ini, kita mengakses file definisi komponen ini melalui URL-nya, dan menggunakan definisi ini untuk membuat 'ops' yang akan kita gunakan untuk membuat langkah pipeline.
import kfp.dsl as dsl
import kfp.gcp as gcp
import kfp.components as comp
...
copydata_op = comp.load_component_from_url(
'https://raw.githubusercontent.com/kubeflow/examples/master/github_issue_summarization/pipelines/components/t2t/datacopy_component.yaml'
)
train_op = comp.load_component_from_url(
'https://raw.githubusercontent.com/kubeflow/examples/master/github_issue_summarization/pipelines/components/t2t/train_component.yaml'
)
Di bawah ini adalah salah satu definisi komponen, untuk operasi pelatihan, dalam format YAML. Anda dapat melihat bahwa input, output, image container, dan argumen entrypoint container-nya telah ditentukan.
name: Train T2T model
description: |
A Kubeflow Pipeline component to train a Tensor2Tensor
model
metadata:
labels:
add-pod-env: 'true'
inputs:
- name: train_steps
description: '...'
type: Integer
default: 2019300
- name: data_dir
description: '...'
type: GCSPath
- name: model_dir
description: '...'
type: GCSPath
- name: action
description: '...'
type: String
- name: deploy_webapp
description: '...'
type: String
outputs:
- name: launch_server
description: '...'
type: String
- name: train_output_path
description: '...'
type: GCSPath
- name: MLPipeline UI metadata
type: UI metadata
implementation:
container:
image: gcr.io/google-samples/ml-pipeline-t2ttrain:v3ap
args: [
--data-dir, {inputValue: data_dir},
--action, {inputValue: action},
--model-dir, {inputValue: model_dir},
--train-steps, {inputValue: train_steps},
--deploy-webapp, {inputValue: deploy_webapp},
--train-output-path, {outputPath: train_output_path}
]
env:
KFP_POD_NAME: "{{pod.name}}"
fileOutputs:
launch_server: /tmp/output
MLPipeline UI metadata: /mlpipeline-ui-metadata.json
Anda juga dapat menentukan langkah pipeline melalui konstruktor dsl.ContainerOp, seperti yang akan kita lihat di bawah.
Berikut adalah sebagian besar definisi pipeline. Kita akan menentukan input pipeline (dan nilai defaultnya). Kemudian, kita akan menentukan langkah-langkah pipeline. Untuk sebagian besar, kita menggunakan'ops' yang ditentukan di atas, tetapi kita juga menentukan langkah'serve' secara inline melalui ContainerOp, dengan menentukan image container dan argumen entrypoint secara langsung.
Anda dapat melihat bahwa langkah train, log_model, dan serve mengakses output dari langkah sebelumnya sebagai input. Anda dapat membaca selengkapnya tentang cara penentuannya di sini.
@dsl.pipeline(
name='Github issue summarization',
description='Demonstrate Tensor2Tensor-based training and TF-Serving'
)
def gh_summ( #pylint: disable=unused-argument
train_steps: 'Integer' = 2019300,
project: str = 'YOUR_PROJECT_HERE',
github_token: str = 'YOUR_GITHUB_TOKEN_HERE',
working_dir: 'GCSPath' = 'gs://YOUR_GCS_DIR_HERE',
checkpoint_dir: 'GCSPath' = 'gs://aju-dev-demos-codelabs/kubecon/model_output_tbase.bak2019000/',
deploy_webapp: str = 'true',
data_dir: 'GCSPath' = 'gs://aju-dev-demos-codelabs/kubecon/t2t_data_gh_all/'
):
copydata = copydata_op(
data_dir=data_dir,
checkpoint_dir=checkpoint_dir,
model_dir='%s/%s/model_output' % (working_dir, dsl.RUN_ID_PLACEHOLDER),
action=COPY_ACTION,
)
train = train_op(
data_dir=data_dir,
model_dir=copydata.outputs['copy_output_path'],
action=TRAIN_ACTION, train_steps=train_steps,
deploy_webapp=deploy_webapp
)
serve = dsl.ContainerOp(
name='serve',
image='gcr.io/google-samples/ml-pipeline-kubeflow-tfserve:v6',
arguments=["--model_name", 'ghsumm-%s' % (dsl.RUN_ID_PLACEHOLDER,),
"--model_path", train.outputs['train_output_path']
]
)
train.set_gpu_limit(1)
Perhatikan bahwa kita memerlukan langkah'train' untuk dijalankan di node dalam cluster yang memiliki setidaknya 1 GPU yang tersedia.
train.set_gpu_limit(1)
Langkah terakhir dalam pipeline—yang juga ditentukan sebaris—bersifat kondisional. Langkah ini akan berjalan setelah langkah 'serve' selesai, hanya jika output langkah pelatihan launch_server adalah string 'true'. Aplikasi ini meluncurkan 'aplikasi web prediksi', yang kita gunakan untuk meminta ringkasan masalah dari model T2T yang telah dilatih.
with dsl.Condition(train.outputs['launch_server'] == 'true'):
webapp = dsl.ContainerOp(
name='webapp',
image='gcr.io/google-samples/ml-pipeline-webapp-launcher:v1',
arguments=["--model_name", 'ghsumm-%s' % (dsl.RUN_ID_PLACEHOLDER,),
"--github_token", github_token]
)
webapp.after(serve)
Definisi image container komponen
Dokumentasi Kubeflow Pipeline menjelaskan beberapa praktik terbaik untuk membuat komponen Anda sendiri. Sebagai bagian dari proses ini, Anda perlu menentukan dan membuat image container. Anda dapat melihat langkah-langkah komponen untuk pipeline codelab ini di sini. Definisi Dockerfile ada di subdirektori containers, misalnya di sini.
Menggunakan VM yang dapat di-preempt dengan GPU untuk pelatihan
Preemptible VM adalah instance VM Compute Engine yang berlangsung maksimal 24 jam dan tidak memberikan jaminan ketersediaan. Harga preemptible VM lebih rendah daripada VM Compute Engine standar.
Dengan Google Kubernetes Engine (GKE), Anda dapat dengan mudah menyiapkan cluster atau node pool yang menggunakan VM yang dapat di-preempt. Anda dapat menyiapkan node pool tersebut dengan GPU yang terpasang pada instance preemptible. Cara kerjanya sama seperti node reguler yang mendukung GPU, tetapi GPU hanya bertahan selama masa pakai instance.
Anda dapat menyiapkan node pool yang dapat di-preempt dan mendukung GPU untuk cluster dengan menjalankan perintah yang mirip dengan berikut, mengedit perintah berikut dengan nama dan zona cluster, serta menyesuaikan jenis dan jumlah akselerator sesuai dengan persyaratan Anda. Anda dapat secara opsional menentukan node pool untuk melakukan penskalaan otomatis berdasarkan workload saat ini.
gcloud container node-pools create preemptible-gpu-pool \
--cluster=<your-cluster-name> \
--zone <your-cluster-zone> \
--enable-autoscaling --max-nodes=4 --min-nodes=0 \
--machine-type n1-highmem-8 \
--preemptible \
--node-taints=preemptible=true:NoSchedule \
--scopes cloud-platform --verbosity error \
--accelerator=type=nvidia-tesla-k80,count=4
Anda juga dapat menyiapkan kumpulan node melalui Cloud Console.
Menentukan Pipeline Kubeflow yang menggunakan node GKE preemptible
Jika Anda menjalankan Kubeflow di GKE, kini Anda dapat dengan mudah menentukan dan menjalankan Kubeflow Pipelines yang memiliki satu atau beberapa langkah pipeline (komponen) yang berjalan di node preemptible, sehingga mengurangi biaya menjalankan tugas. Agar penggunaan VM preemptible memberikan hasil yang benar, langkah-langkah yang Anda identifikasi sebagai preemptible harus idempotent (yaitu, jika Anda menjalankan langkah beberapa kali, hasilnya akan sama), atau harus melakukan checkpoint pekerjaan sehingga langkah tersebut dapat melanjutkan dari tempat terakhirnya jika terganggu.
Saat menentukan Pipeline Kubeflow, Anda dapat menunjukkan bahwa langkah tertentu harus dijalankan di node yang dapat di-preempt dengan mengubah op seperti ini:
your_pipelines_op.apply(gcp.use_preemptible_nodepool())
Lihat dokumentasi untuk mengetahui detailnya.
Anda mungkin juga ingin mencoba ulang langkah tersebut beberapa kali jika node di-preempt. Anda dapat melakukannya sebagai berikut—di sini, kita menentukan 5 percobaan ulang.
your_pipelines_op.set_gpu_limit(1).apply(gcp.use_preemptible_nodepool()).set_retry(5)
Coba edit pipeline Kubeflow yang kita gunakan dalam codelab ini untuk menjalankan langkah pelatihan di VM yang dapat di-preempt.
Ubah baris berikut dalam spesifikasi pipeline untuk menggunakan nodepool yang dapat di-preempt secara tambahan (pastikan Anda telah membuatnya seperti yang ditunjukkan di atas), dan untuk mencoba lagi 5 kali:
train.set_gpu_limit(1)
Kemudian, kompilasi ulang pipeline, upload versi baru (beri nama baru), lalu jalankan pipeline versi baru.