
1. Wprowadzenie
| Kubeflow to zestaw narzędzi do uczenia maszynowego w Kubernetes. Projekt ma na celu uproszczenie, przenośność i skalowalność wdrażania przepływów pracy związanych z uczeniem maszynowym (ML) w Kubernetes. Celem jest zapewnienie prostego sposobu wdrażania najlepszych w swojej klasie systemów open source do uczenia maszynowego w różnych infrastrukturach. |
| Proces uczenia maszynowego może obejmować wiele kroków, które są od siebie zależne, od przygotowania i analizy danych po trenowanie, ocenę, wdrażanie i inne. Trudno jest tworzyć i śledzić te procesy w sposób doraźny, np. w zbiorze notatników lub skryptów, a takie kwestie jak audytowanie i powtarzalność stają się coraz bardziej problematyczne.Kubeflow Pipelines (KFP) pomaga rozwiązać te problemy, umożliwiając wdrażanie niezawodnych, powtarzalnych potoków uczenia maszynowego wraz z monitorowaniem, audytowaniem, śledzeniem wersji i powtarzalnością. Cloud AI Pipelines ułatwia konfigurację instalacji KFP. |


Co utworzysz
W ramach tych ćwiczeń z programowania utworzysz aplikację internetową, która podsumowuje problemy w GitHubie za pomocą Kubeflow Pipelines do trenowania i obsługi modelu. Opiera się on na przykładzie z repozytorium przykładów Kubeflow. Po zakończeniu tego procesu Twoja infrastruktura będzie zawierać:
- Klaster Google Kubernetes Engine (GKE) z zainstalowanym Kubeflow Pipelines (za pomocą Cloud AI Pipelines).
- potok, który trenuje model Tensor2Tensor na procesorach graficznych;
- kontener obsługujący, który udostępnia prognozy z wytrenowanego modelu;
- Interfejs, który interpretuje prognozy, aby dostarczać podsumowania problemów w GitHubie.
- Notatnik, który tworzy potok od zera za pomocą pakietu Kubeflow Pipelines (KFP) SDK
Czego się nauczysz
Potok, który utworzysz, będzie trenować model Tensor2Tensor na podstawie danych o problemach w GitHubie. Model nauczy się przewidywać tytuły problemów na podstawie ich treści. Następnie eksportuje wytrenowany model i wdraża go za pomocą Tensorflow Serving. Ostatni krok w potoku uruchamia aplikację internetową, która wchodzi w interakcję z instancją TF-Serving, aby uzyskać prognozy modelu.
- Jak zainstalować Kubeflow Pipelines w klastrze GKE
- Tworzenie i uruchamianie przepływów pracy związanych z uczeniem maszynowym za pomocą Kubeflow Pipelines
- Jak definiować i uruchamiać potoki z notatnika AI Platform
Czego potrzebujesz
- Podstawowa znajomość Kubernetes będzie pomocna, ale nie jest konieczna.
- aktywny projekt GCP, do którego masz uprawnienia właściciela;
- (Opcjonalnie) konto GitHub
- Dostęp do Google Cloud Shell, dostępnego w konsoli Google Cloud Platform (GCP).
2. Konfiguracja
Cloud Shell
Otwórz konsolę GCP w przeglądarce i zaloguj się, podając dane logowania do projektu:
W razie potrzeby kliknij „Wybierz projekt”, aby pracować nad projektem związanym z samouczkiem.

Następnie kliknij ikonę „Aktywuj Cloud Shell” w prawym górnym rogu konsoli, aby uruchomić Cloud Shell.
Po uruchomieniu Cloud Shell wyświetli nazwę projektu, którego będzie używać. Sprawdź, czy to ustawienie jest prawidłowe.
Aby znaleźć identyfikator projektu, otwórz panel Główna w konsoli GCP. Jeśli ekran jest pusty, kliknij „Tak” w odpowiedzi na pytanie, czy chcesz utworzyć panel.

Następnie w terminalu Cloud Shell uruchom te polecenia, aby w razie potrzeby skonfigurować gcloud do używania właściwego projektu:
export PROJECT_ID=<your_project_id>
gcloud config set project ${PROJECT_ID}
Tworzenie zasobnika na dane
Utwórz zasobnik Cloud Storage do przechowywania plików potoku. Musisz użyć globalnie unikalnego identyfikatora, więc wygodnie jest zdefiniować nazwę zasobnika, która zawiera identyfikator projektu. Utwórz zasobnik za pomocą polecenia gsutil mb (make bucket):
export PROJECT_ID=<your_project_id>
export BUCKET_NAME=kubeflow-${PROJECT_ID}
gsutil mb gs://${BUCKET_NAME}
Możesz też utworzyć zasobnik w konsoli GCP.
Opcjonalnie: utwórz token GitHub
W tym ćwiczeniu z programowania wywołujemy interfejs GitHub API, aby pobrać dane dostępne publicznie. Aby zapobiec ograniczeniu liczby żądań, zwłaszcza podczas wydarzeń, w których do interfejsów API GitHub wysyłana jest duża liczba anonimizowanych żądań, skonfiguruj token dostępu bez uprawnień. Chodzi o to, aby potwierdzić, że jesteś osobą fizyczną, a nie anonimowym użytkownikiem.
- Otwórz https://github.com/settings/tokens i wygeneruj nowy token bez zakresów.
- Zapisz go w bezpiecznym miejscu. Jeśli go utracisz, musisz go usunąć i utworzyć nowy.
Jeśli pominiesz ten krok, laboratorium nadal będzie działać, ale będziesz mieć nieco mniejsze możliwości generowania danych wejściowych do testowania modelu.
Opcjonalnie: Przypinanie przydatnych paneli
W konsoli GCP przypnij panele Kubernetes Engine i Pamięć, aby ułatwić sobie dostęp do nich.

Tworzenie instalacji potoków AI Platform (hostowanych potoków Kubeflow)
Aby skonfigurować instancję GKE z zainstalowanym KFP, postępuj zgodnie z instrukcjami w sekcjach „Zanim zaczniesz” i „Konfigurowanie instancji” tutaj. Pamiętaj, aby zaznaczyć pole Zezwól na dostęp do tych interfejsów Cloud API, jak wskazano w dokumentacji. (Jeśli tego nie zrobisz, przykładowy potok nie zostanie uruchomiony). Pozostaw przestrzeń nazw instalacji jako default.
Musisz wybrać strefę, która obsługuje karty Nvidia K80. Jako domyślne możesz użyć stref us-central1-a lub us-central1-c.
Po zakończeniu instalacji zanotuj nazwę klastra i strefę GKE wymienione w panelu AI Pipelines. Aby ułatwić sobie pracę, ustaw zmienne środowiskowe na te wartości.

export ZONE=<your zone> export CLUSTER_NAME=<your cluster name>
Konfigurowanie narzędzia kubectl do korzystania z nowych danych logowania klastra GKE
Po utworzeniu klastra GKE skonfiguruj kubectl tak, aby używał danych logowania nowego klastra. W tym celu uruchom w Cloud Shell to polecenie:
gcloud container clusters get-credentials ${CLUSTER_NAME} \
--project ${PROJECT_ID} \
--zone ${ZONE}
Możesz też kliknąć nazwę klastra w panelu AI Pipelines, aby otworzyć jego stronę GKE, a następnie kliknąć „Połącz” u góry strony. W wyskakującym okienku wklej polecenie do Cloud Shell.
Konfiguruje to kontekst kubectl, dzięki czemu możesz wchodzić w interakcje z klastrem. Aby sprawdzić konfigurację, uruchom to polecenie:
kubectl get nodes -o wide
Powinny się wyświetlić węzły ze stanem „Ready” oraz inne informacje o wieku węzła, wersji, zewnętrznym adresie IP, obrazie systemu operacyjnego, wersji jądra i środowisku wykonawczym kontenera.
Skonfiguruj klaster tak, aby instalował sterownik Nvidia w pulach węzłów z włączoną obsługą GPU
Następnie zastosujemy w klastrze daemonset, który zainstaluje sterownik Nvidia we wszystkich węzłach klastra z włączoną obsługą GPU:
kubectl apply -f https://raw.githubusercontent.com/GoogleCloudPlatform/container-engine-accelerators/master/nvidia-driver-installer/cos/daemonset-preloaded.yaml
Następnie uruchom to polecenie, które przyznaje komponentom KFP uprawnienia do tworzenia nowych zasobów Kubernetes:
kubectl create clusterrolebinding sa-admin --clusterrole=cluster-admin --serviceaccount=kubeflow:pipeline-runner
Tworzenie puli węzłów GPU
Następnie skonfigurujemy pulę węzłów GPU o rozmiarze 1:
gcloud container node-pools create gpu-pool \
--cluster=${CLUSTER_NAME} \
--zone ${ZONE} \
--num-nodes=1 \
--machine-type n1-highmem-8 \
--scopes cloud-platform --verbosity error \
--accelerator=type=nvidia-tesla-k80,count=1
3. Uruchamianie potoku z poziomu panelu Potoki
Otwórz panel potoków
Jeśli nie jest jeszcze otwarty, w Cloud Console otwórz panel Pipelines. Następnie kliknij „OTWÓRZ PANEL POTOKÓW” w przypadku swojej instalacji i na pasku menu po lewej stronie kliknij Potoki. Jeśli pojawi się błąd wczytywania, odśwież kartę. Powinna pojawić się nowa strona podobna do tej:

Opis potoku
Potok, który uruchomisz, składa się z kilku kroków (szczegóły znajdziesz w dodatku do tego ćwiczenia):
- Istniejący punkt kontrolny modelu zostanie skopiowany do zasobnika.
- Model Tensor2Tensor jest trenowany na podstawie wstępnie przetworzonych danych.
- Trenowanie rozpoczyna się od istniejącego punktu kontrolnego modelu skopiowanego w pierwszym kroku, a następnie trwa jeszcze kilkaset kroków. (Pełne wytrenowanie modelu podczas ćwiczenia trwałoby zbyt długo).
- Po zakończeniu trenowania krok potoku eksportuje model w formie odpowiedniej do udostępniania przez TensorFlow Serving.
- Instancja TensorFlow Serving jest wdrażana przy użyciu tego modelu.
- Uruchamiana jest aplikacja internetowa, która umożliwia interakcję z obsługiwanym modelem w celu uzyskania prognoz.
Pobieranie i kompilowanie potoku
W tej sekcji dowiesz się, jak skompilować definicję potoku. Najpierw musimy zainstalować pakiet KFP SDK. Uruchom w Cloud Shell to polecenie:
pip3 install -U kfp
Aby pobrać plik definicji potoku, uruchom to polecenie w Cloud Shell:
curl -O https://raw.githubusercontent.com/amygdala/kubeflow-examples/ghsumm/github_issue_summarization/pipelines/example_pipelines/gh_summ_hosted_kfp.py
Następnie skompiluj plik definicji potoku, uruchamiając go w ten sposób:
python3 gh_summ_hosted_kfp.py
W wynikach wyszukiwania pojawi się plik gh_summ_hosted_kfp.py.tar.gz.
Prześlij skompilowany potok
W interfejsie Kubeflow Pipelines kliknij Upload pipeline (Prześlij potok) i wybierz Import by URL (Importuj przez URL). Skopiuj i wklej ten adres URL, który wskazuje ten sam potok, który został właśnie skompilowany. (Przesłanie pliku z Cloud Shell wymaga kilku dodatkowych kroków, więc wybieramy skrót).
Nadaj potokowi nazwę (np. gh_summ).

Uruchom potok
Na liście kliknij przesłany potok – dzięki temu możesz wyświetlić jego statyczny wykres – a następnie kliknij Utwórz eksperyment, aby utworzyć nowy eksperyment za pomocą potoku. Eksperyment to sposób na grupowanie semantycznie powiązanych uruchomień.

Nadaj eksperymentowi nazwę (np. taką samą jak potok, gh_summ), a potem kliknij Dalej, aby go utworzyć.

Wyświetli się strona, na której możesz wpisać parametry uruchomienia i je rozpocząć.
Aby ułatwić sobie wypełnianie parametrów, możesz wykonać te polecenia w Cloud Shell.
gcloud config get-value project
echo "gs://${BUCKET_NAME}/codelab"
Nazwa uruchomienia zostanie wypełniona automatycznie, ale możesz ją zmienić.
Następnie wypełnij 3 pola parametrów:
project- (opcjonalnie)
github-token working-dir
W przypadku katalogu roboczego wpisz ścieżkę w utworzonym zasobniku GCS. Dołącz prefiks „gs://”. W polu github-token wpisz token, który opcjonalnie został wygenerowany wcześniej, lub pozostaw ciąg zastępczy bez zmian, jeśli token nie został wygenerowany.

Po wypełnieniu pól kliknij Start, a potem kliknij wymienione uruchomienie, aby wyświetlić jego szczegóły. Gdy dany krok potoku jest uruchomiony, możesz go kliknąć, aby uzyskać więcej informacji, w tym wyświetlić logi poda. (Logi kroku potoku możesz też wyświetlić, klikając link do logów Cloud Logging (Stackdriver), nawet jeśli węzeł klastra został zlikwidowany).
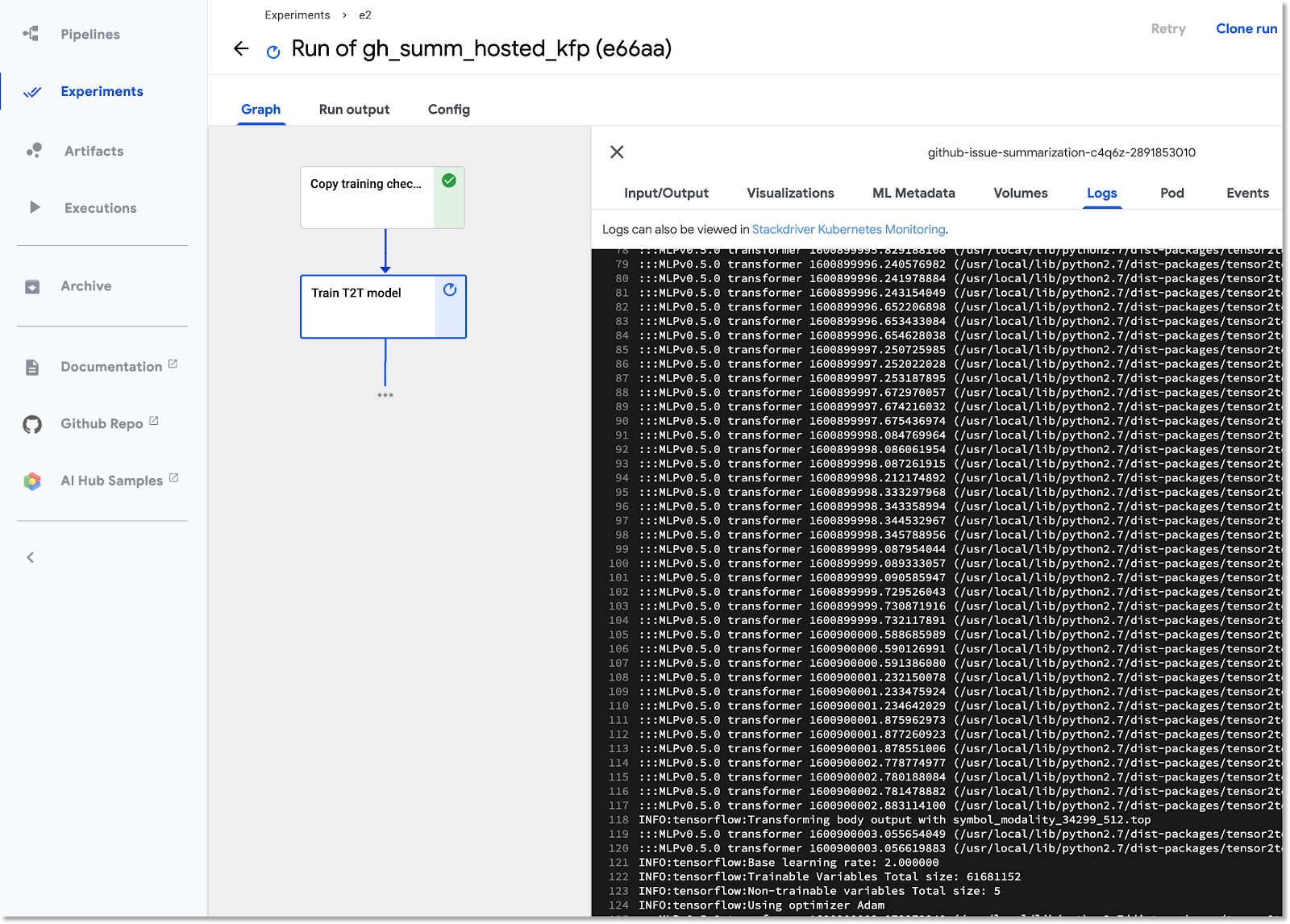
Wyświetl definicję potoku
Podczas działania potoku możesz przyjrzeć się bliżej jego strukturze i działaniu. Więcej informacji znajdziesz w sekcji Dodatek w tym samouczku.
Wyświetlanie informacji o trenowaniu modelu w TensorBoard
Po zakończeniu etapu trenowania wybierz kartę Wizualizacje i kliknij niebieski przycisk Uruchom TensorBoard. Gdy będzie gotowy, kliknij Otwórz TensorBoard.


Poznaj panel Artefakty i wykonania
Kubeflow Pipelines automatycznie rejestruje metadane dotyczące kroków potoku podczas jego wykonywania. Rejestrowane są informacje o artefakcie i wykonaniu. Aby dowiedzieć się więcej, kliknij te pozycje na pasku nawigacyjnym po lewej stronie panelu.
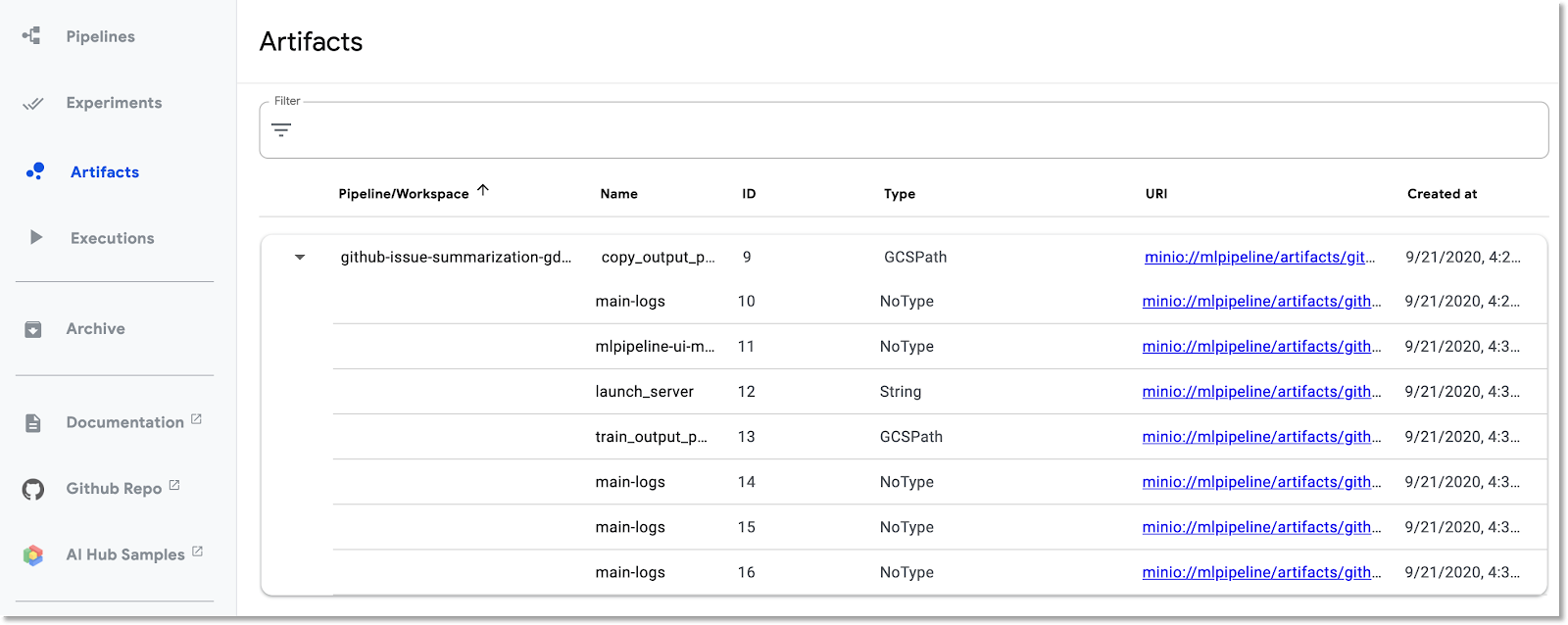
W przypadku artefaktów możesz wyświetlić zarówno panel przeglądu, jak i panel eksploratora pochodzenia.


Wyświetl aplikację internetową utworzoną przez potok i dokonaj kilku prognoz
Ostatni etap potoku wdraża aplikację internetową, która udostępnia interfejs do wysyłania zapytań do wytrenowanego modelu (obsługiwanego przez TF Serving) w celu generowania prognoz.
Po zakończeniu działania potoku połącz się z aplikacją internetową, przekierowując porty do jej usługi (przekierowujemy porty, ponieważ w tym laboratorium usługa aplikacji internetowej nie jest skonfigurowana tak, aby miała zewnętrzny punkt końcowy).
Aby znaleźć nazwę usługi, uruchom to polecenie w Cloud Shell:
kubectl get services
Na liście poszukaj nazwy usługi, np. ghsumm-*-webappsvc.
Następnie w Cloud Shell przekieruj port do tej usługi w ten sposób: zmień to polecenie, aby użyć nazwy webappsvc:
kubectl port-forward svc/ghsumm-xxxxx-webappsvc 8080:80
Gdy przekierowanie portów będzie działać, kliknij ikonę „podgląd” nad panelem Cloud Shell, a w menu kliknij „Podgląd na porcie 8080”.

W nowej karcie powinna się otworzyć strona podobna do tej:

Aby pobrać blok tekstu, kliknij przycisk Wypełnij losowy problem. Kliknij Wygeneruj tytuł, aby wywołać wytrenowany model i wyświetlić prognozę.
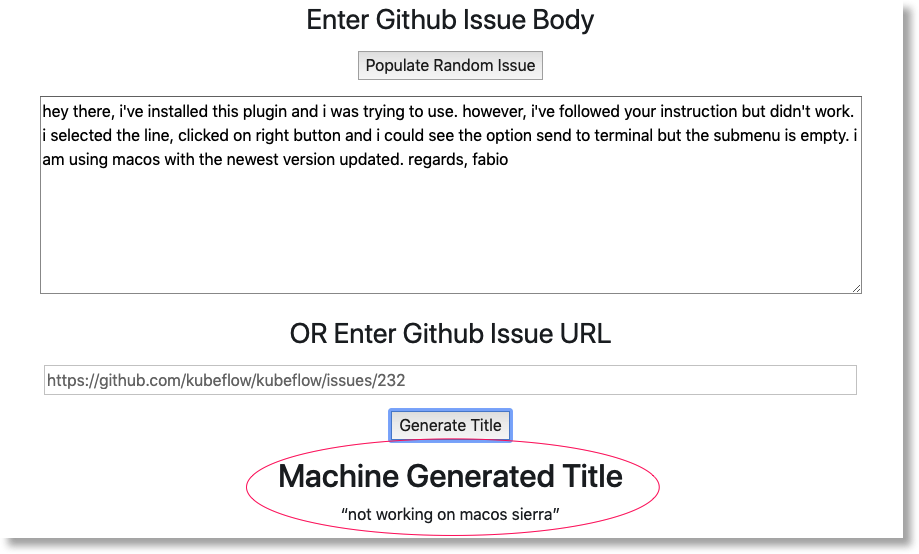
Jeśli parametry potoku zawierały prawidłowy token GitHub, możesz też spróbować wpisać adres URL GitHub w drugim polu, a następnie kliknąć „Wygeneruj tytuł”. Jeśli nie masz skonfigurowanego prawidłowego tokena GitHub, używaj tylko pola „Populate Random Issue” (Wypełnij losowy problem).
4. Uruchamianie potoku z notatnika AI Platform
Możesz też interaktywnie definiować i uruchamiać potoki Kubeflow z poziomu notatnika Jupyter za pomocą pakietu KFP SDK. Notatniki AI Platform, których użyjemy w tych ćwiczeniach z programowania, bardzo ułatwiają to zadanie.
utworzyć instancję notatnika.
Za pomocą interfejsu API Cloud Shell utworzymy instancję notatnika. (Możesz też utworzyć notatnik w konsoli Cloud. Więcej informacji znajdziesz w dokumentacji.
W Cloud Shell ustaw te zmienne środowiskowe:
export INSTANCE_NAME="kfp-ghsumm" export VM_IMAGE_PROJECT="deeplearning-platform-release" export VM_IMAGE_FAMILY="tf2-2-3-cpu" export MACHINE_TYPE="n1-standard-4" export LOCATION="us-central1-c"
Następnie w Cloud Shell uruchom polecenie utworzenia instancji notatnika:
gcloud beta notebooks instances create $INSTANCE_NAME \ --vm-image-project=$VM_IMAGE_PROJECT \ --vm-image-family=$VM_IMAGE_FAMILY \ --machine-type=$MACHINE_TYPE --location=$LOCATION
Gdy uruchomisz to polecenie po raz pierwszy, może pojawić się prośba o włączenie interfejsu notebooks API w projekcie. Jeśli tak, odpowiedz „y”.
Po kilku minutach serwer notatnika będzie gotowy do działania. Instancje notatnika są wyświetlane w konsoli Cloud.

Prześlij notatnik z ćwiczeniami z programowania
Po utworzeniu instancji notatnika kliknij ten link, aby przesłać notatnik Jupyter z samouczka. Wybierz instancję notatek, której chcesz użyć. Notatnik otworzy się automatycznie.
Uruchomienie notatnika
Postępuj zgodnie z instrukcjami w notatniku przez resztę modułu. Pamiętaj, że w sekcji „Konfiguracja” notatnika musisz wpisać własne wartości, zanim uruchomisz pozostałą część notatnika.
(Jeśli używasz własnego projektu, nie zapomnij wrócić i wykonać sekcji „Zwalnianie miejsca” tego modułu).
5. Czyszczenie danych
Nie musisz tego robić, jeśli używasz tymczasowego konta codelab, ale jeśli korzystasz z własnego projektu, możesz usunąć instalację Pipelines i notatnik.
Wyłączanie klastra GKE Pipelines
Klaster potoków możesz usunąć w konsoli Cloud. (Jeśli chcesz ponownie użyć klastra GKE, możesz po prostu usunąć instalację Pipelines).
Usuń instancję AI Notebook
Jeśli wykonasz część „Notebook” z tego przewodnika, możesz USUNĄĆ lub ZATRZYMAĆ instancję notatnika w Cloud Console.
Opcjonalnie: usuń token GitHub
Otwórz https://github.com/settings/tokens i usuń wygenerowany token.
6. Dodatki
Przyjrzyjmy się kodowi
Definiowanie potoku
Potok używany w tym samouczku jest zdefiniowany tutaj.
Przyjrzyjmy się jego definicji oraz definicjom jego komponentów (kroków). Omówimy najważniejsze kwestie, ale więcej szczegółów znajdziesz w dokumentacji.
Kroki potoku Kubeflow są oparte na kontenerach. Podczas tworzenia potoku możesz używać gotowych komponentów z utworzonymi już obrazami kontenerów lub tworzyć własne komponenty. Na potrzeby tego ćwiczenia stworzyliśmy własną.
Cztery kroki potoku są zdefiniowane na podstawie komponentów wielokrotnego użytku, do których dostęp uzyskuje się za pomocą plików definicji komponentów. W tym pierwszym fragmencie kodu uzyskujemy dostęp do plików definicji komponentów za pomocą ich adresów URL i używamy tych definicji do tworzenia „operacji”, których użyjemy do utworzenia kroku potoku.
import kfp.dsl as dsl
import kfp.gcp as gcp
import kfp.components as comp
...
copydata_op = comp.load_component_from_url(
'https://raw.githubusercontent.com/kubeflow/examples/master/github_issue_summarization/pipelines/components/t2t/datacopy_component.yaml'
)
train_op = comp.load_component_from_url(
'https://raw.githubusercontent.com/kubeflow/examples/master/github_issue_summarization/pipelines/components/t2t/train_component.yaml'
)
Poniżej znajduje się jedna z definicji komponentów, w tym przypadku operacji trenowania, w formacie YAML. Widać, że zdefiniowane są dane wejściowe, wyjściowe, obraz kontenera i argumenty punktu wejścia kontenera.
name: Train T2T model
description: |
A Kubeflow Pipeline component to train a Tensor2Tensor
model
metadata:
labels:
add-pod-env: 'true'
inputs:
- name: train_steps
description: '...'
type: Integer
default: 2019300
- name: data_dir
description: '...'
type: GCSPath
- name: model_dir
description: '...'
type: GCSPath
- name: action
description: '...'
type: String
- name: deploy_webapp
description: '...'
type: String
outputs:
- name: launch_server
description: '...'
type: String
- name: train_output_path
description: '...'
type: GCSPath
- name: MLPipeline UI metadata
type: UI metadata
implementation:
container:
image: gcr.io/google-samples/ml-pipeline-t2ttrain:v3ap
args: [
--data-dir, {inputValue: data_dir},
--action, {inputValue: action},
--model-dir, {inputValue: model_dir},
--train-steps, {inputValue: train_steps},
--deploy-webapp, {inputValue: deploy_webapp},
--train-output-path, {outputPath: train_output_path}
]
env:
KFP_POD_NAME: "{{pod.name}}"
fileOutputs:
launch_server: /tmp/output
MLPipeline UI metadata: /mlpipeline-ui-metadata.json
Krok potoku możesz też zdefiniować za pomocą konstruktora dsl.ContainerOp, jak pokazano poniżej.
Poniżej znajduje się większość definicji potoku. Określamy dane wejściowe potoku (i ich wartości domyślne). Następnie definiujemy kroki potoku. W większości przypadków używamy zdefiniowanych powyżej operacji, ale definiujemy też krok „serve” w linii za pomocą ContainerOp, bezpośrednio określając obraz kontenera i argumenty punktu wejścia.
Widać, że kroki train, log_model i serve korzystają z danych wyjściowych z poprzednich kroków jako danych wejściowych. Więcej informacji o tym, jak to jest określone, znajdziesz tutaj.
@dsl.pipeline(
name='Github issue summarization',
description='Demonstrate Tensor2Tensor-based training and TF-Serving'
)
def gh_summ( #pylint: disable=unused-argument
train_steps: 'Integer' = 2019300,
project: str = 'YOUR_PROJECT_HERE',
github_token: str = 'YOUR_GITHUB_TOKEN_HERE',
working_dir: 'GCSPath' = 'gs://YOUR_GCS_DIR_HERE',
checkpoint_dir: 'GCSPath' = 'gs://aju-dev-demos-codelabs/kubecon/model_output_tbase.bak2019000/',
deploy_webapp: str = 'true',
data_dir: 'GCSPath' = 'gs://aju-dev-demos-codelabs/kubecon/t2t_data_gh_all/'
):
copydata = copydata_op(
data_dir=data_dir,
checkpoint_dir=checkpoint_dir,
model_dir='%s/%s/model_output' % (working_dir, dsl.RUN_ID_PLACEHOLDER),
action=COPY_ACTION,
)
train = train_op(
data_dir=data_dir,
model_dir=copydata.outputs['copy_output_path'],
action=TRAIN_ACTION, train_steps=train_steps,
deploy_webapp=deploy_webapp
)
serve = dsl.ContainerOp(
name='serve',
image='gcr.io/google-samples/ml-pipeline-kubeflow-tfserve:v6',
arguments=["--model_name", 'ghsumm-%s' % (dsl.RUN_ID_PLACEHOLDER,),
"--model_path", train.outputs['train_output_path']
]
)
train.set_gpu_limit(1)
Pamiętaj, że wymagamy, aby krok „train” był wykonywany na węźle w klastrze, który ma co najmniej 1 dostępny procesor GPU.
train.set_gpu_limit(1)
Ostatni krok w potoku, również zdefiniowany w tekście, jest warunkowy. Zostanie ona uruchomiona po zakończeniu kroku „serve”, ale tylko wtedy, gdy dane wyjściowe kroku szkolenia launch_server to ciąg znaków „true”. Uruchamia „aplikację internetową do prognozowania”, której używaliśmy do wysyłania do wytrenowanego modelu T2T próśb o podsumowania problemów.
with dsl.Condition(train.outputs['launch_server'] == 'true'):
webapp = dsl.ContainerOp(
name='webapp',
image='gcr.io/google-samples/ml-pipeline-webapp-launcher:v1',
arguments=["--model_name", 'ghsumm-%s' % (dsl.RUN_ID_PLACEHOLDER,),
"--github_token", github_token]
)
webapp.after(serve)
Definicje obrazu kontenera komponentu
Dokumentacja Kubeflow Pipeline zawiera sprawdzone metody tworzenia własnych komponentów. W ramach tego procesu musisz zdefiniować i skompilować obraz kontenera. Komponenty potoku tego laboratorium znajdziesz tutaj. Definicje plików Dockerfile znajdują się w containers podkatalogach, np. tutaj.
Używanie maszyn wirtualnych z możliwością wywłaszczania z procesorami GPU do trenowania
Maszyny wirtualne z możliwością wywłaszczania to instancje maszyn wirtualnych Compute Engine, które działają maksymalnie przez 24 godziny i nie gwarantują dostępności. Cena maszyn wirtualnych z wyprzedzeniem jest niższa niż w przypadku standardowych maszyn wirtualnych Compute Engine.
Dzięki Google Kubernetes Engine (GKE) możesz łatwo skonfigurować klaster lub pulę węzłów korzystającą z maszyn wirtualnych z możliwością wywłaszczenia. Taką pulę węzłów możesz skonfigurować za pomocą procesorów graficznych dołączonych do instancji z wyprzedzeniem. Działają one tak samo jak zwykłe węzły z obsługą GPU, ale układy GPU są dostępne tylko przez cały okres istnienia instancji.
Aby skonfigurować w klastrze pulę węzłów z możliwością wywłaszczenia i obsługą GPU, uruchom polecenie podobne do tego poniżej. Zmień w nim nazwę klastra i strefę oraz dostosuj typ i liczbę akceleratorów do swoich potrzeb. Opcjonalnie możesz zdefiniować pulę węzłów, która ma być automatycznie skalowana na podstawie bieżących zadań.
gcloud container node-pools create preemptible-gpu-pool \
--cluster=<your-cluster-name> \
--zone <your-cluster-zone> \
--enable-autoscaling --max-nodes=4 --min-nodes=0 \
--machine-type n1-highmem-8 \
--preemptible \
--node-taints=preemptible=true:NoSchedule \
--scopes cloud-platform --verbosity error \
--accelerator=type=nvidia-tesla-k80,count=4
Pule węzłów możesz też skonfigurować w konsoli Cloud.
Definiowanie potoku Kubeflow, który korzysta z węzłów GKE z możliwością wywłaszczania
Jeśli używasz Kubeflow w GKE, możesz teraz łatwo definiować i uruchamiać potoki Kubeflow, w których co najmniej 1 krok potoku (komponent) działa na węzłach z możliwością wywłaszczenia, co zmniejsza koszt uruchomienia zadania. Aby użycie maszyn wirtualnych z możliwością wywłaszczania dało prawidłowe wyniki, kroki, które uznasz za możliwe do wywłaszczania, powinny być idempotentne (czyli jeśli wykonasz krok kilka razy, uzyskasz ten sam wynik) lub powinny zapisywać punkty kontrolne, aby w razie przerwania można było wznowić działanie od miejsca, w którym zostało ono przerwane.
Podczas definiowania potoku Kubeflow możesz wskazać, że dany krok powinien być uruchamiany na węźle z możliwością wywłaszczenia, modyfikując operację w ten sposób:
your_pipelines_op.apply(gcp.use_preemptible_nodepool())
Szczegóły znajdziesz w dokumentacji.
Prawdopodobnie będziesz też chcieć ponowić krok kilka razy, jeśli węzeł zostanie przerwany. Możesz to zrobić w ten sposób – w tym przypadku określamy 5 ponownych prób.
your_pipelines_op.set_gpu_limit(1).apply(gcp.use_preemptible_nodepool()).set_retry(5)
Spróbuj edytować potok Kubeflow, którego użyliśmy w tym ćwiczeniu z programowania, aby uruchomić krok trenowania na maszynie wirtualnej z możliwością wywłaszczania.
Zmień ten wiersz w specyfikacji potoku, aby dodatkowo używać puli węzłów z możliwością wywłaszczania (upewnij się, że została ona utworzona zgodnie z instrukcjami powyżej) i ponawiać próbę 5 razy:
train.set_gpu_limit(1)
Następnie ponownie skompiluj potok, prześlij nową wersję (nadaj jej nową nazwę) i uruchom nową wersję potoku.