
1. Introdução
| O Kubeflow é um kit de ferramentas de machine learning para Kubernetes. O objetivo do projeto é fazer com que as implantações de fluxos de trabalho de machine learning (ML) no Kubernetes sejam simples, portáteis e escalonáveis. A meta é oferecer uma maneira simples de implantar os melhores sistemas de código aberto para ML em infraestruturas diversas. |
| Um fluxo de trabalho de machine learning pode envolver muitas etapas com dependências entre si, desde a preparação e análise de dados até o treinamento, a avaliação, a implantação e muito mais. É difícil criar e rastrear esses processos de maneira ad hoc, por exemplo, em um conjunto de notebooks ou scripts, e coisas como auditoria e reprodutibilidade se tornam cada vez mais problemáticas.O Kubeflow Pipelines (KFP) ajuda a resolver esses problemas oferecendo uma maneira de implantar pipelines de machine learning robustos e repetíveis com monitoramento, auditoria, rastreamento de versões e reprodutibilidade. Com os pipelines de IA do Google Cloud, é fácil configurar uma instalação do KFP. |


O que você vai criar
Neste codelab, você vai criar um app da Web que resume os problemas do GitHub usando o Kubeflow Pipelines para treinar e veicular um modelo. Ele é baseado em um exemplo no repositório de exemplos do Kubeflow. Ao final do processo, a infraestrutura terá:
- Um cluster do Google Kubernetes Engine (GKE) com o Kubeflow Pipelines instalado (via IA do Google Cloud Pipelines).
- Um pipeline que treina um modelo Tensor2Tensor em GPUs
- Um contêiner de exibição que gera previsões do modelo treinado
- Uma interface que interpreta as previsões para gerar resumos dos problemas do GitHub
- Um notebook que cria um pipeline do zero usando o SDK do Kubeflow Pipelines (KFP).
O que você vai aprender
O pipeline que você vai criar treina um modelo Tensor2Tensor com dados de problemas do GitHub, aprendendo a prever títulos de problemas com base nos corpos deles. Em seguida, ele exporta e implanta o modelo treinado usando o Tensorflow Serving. A etapa final do pipeline inicia um app da Web, que interage com a instância do TF-Serving para receber previsões do modelo.
- Como instalar o Kubeflow Pipelines em um cluster do GKE
- Como criar e executar fluxos de trabalho de ML usando o Kubeflow Pipelines
- Como definir e executar pipelines em um notebook do AI Platform
O que é necessário
- É útil, mas não obrigatório, ter noções básicas do Kubernetes.
- Um projeto do GCP ativo em que você tem permissões de proprietário
- (Opcional) Uma conta do GitHub
- Acesso ao Google Cloud Shell, disponível no Console do Google Cloud Platform (GCP)
2. Configuração
Cloud Shell
Acesse o Console do GCP no navegador e faça login com as credenciais do projeto:
Clique em "Selecionar um projeto", se necessário, para trabalhar com o projeto do codelab.

Em seguida, clique no ícone "Ativar o Cloud Shell" no canto superior direito do console para iniciar um Cloud Shell.

Quando você iniciar o Cloud Shell, ele vai informar o nome do projeto que está configurado para usar. Verifique se essa configuração está correta.
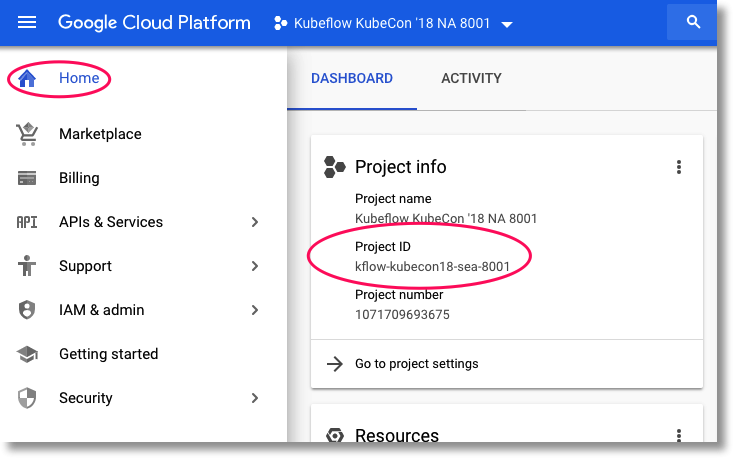
Para encontrar o ID do projeto, acesse o painel "Página inicial" do Console do GCP. Se a tela estiver vazia, clique em "Sim" no comando para criar um painel.
Em seguida, no terminal do Cloud Shell, execute estes comandos, se necessário, para configurar gcloud e usar o projeto correto:
export PROJECT_ID=<your_project_id>
gcloud config set project ${PROJECT_ID}
Crie um bucket de armazenamento
Crie um bucket do Cloud Storage para armazenar os arquivos do pipeline. Você precisará usar um ID exclusivo globalmente. Por isso, é conveniente definir um nome de bucket que inclua o ID do projeto. Crie o bucket usando o comando gsutil mb (criar bucket):
export PROJECT_ID=<your_project_id>
export BUCKET_NAME=kubeflow-${PROJECT_ID}
gsutil mb gs://${BUCKET_NAME}
Como alternativa, é possível criar um bucket pelo console do GCP.
Opcional**: crie um token do GitHub**
Este codelab chama a API do GitHub para recuperar dados disponíveis publicamente. Para evitar a limitação de taxa, principalmente em eventos em que um grande número de solicitações anônimas é enviado às APIs do GitHub, configure um token de acesso sem permissões. Isso serve somente para autorizar você como indivíduo em vez de usuário anônimo.
- Navegue até https://github.com/settings/tokens e gere um novo token sem escopos.
- Salve em um lugar seguro. Se você perder a chave, será necessário excluir e criar outra.
Se você pular esta etapa, o laboratório ainda vai funcionar, mas suas opções de geração de dados de entrada para testar o modelo serão um pouco mais limitadas.
Opcional: Fixar painéis úteis
No console do GCP, fixe os painéis Kubernetes Engine e Storage para facilitar o acesso.

Criar uma instalação do AI Platform Pipelines (pipelines hospedados do Kubeflow)
Siga as instruções nas seções "Antes de começar" e "Configurar sua instância" aqui para configurar uma instância do GKE com o KFP instalado. Não se esqueça de marcar a caixa Permitir acesso às seguintes APIs do Cloud, conforme indicado na documentação. Caso contrário, o pipeline de exemplo não será executado. Deixe o namespace de instalação como default.
Escolha uma zona compatível com Nvidia k80s. Você pode usar us-central1-a ou us-central1-c como padrões.
Anote o nome do cluster e a zona do GKE listados para sua instalação no painel do AI Pipelines após a conclusão da instalação. Para sua conveniência, defina variáveis de ambiente com esses valores.

export ZONE=<your zone> export CLUSTER_NAME=<your cluster name>
Configurar o kubectl para usar as credenciais do novo cluster do GKE
Depois que o cluster do GKE for criado, configure o kubectl para usar as credenciais do novo cluster executando o seguinte comando no Cloud Shell:
gcloud container clusters get-credentials ${CLUSTER_NAME} \
--project ${PROJECT_ID} \
--zone ${ZONE}
Como alternativa, clique no nome do cluster no painel do AI Pipelines para acessar a página do GKE e clique em "Conectar" na parte de cima da página. No pop-up, cole o comando no Cloud Shell.
Isso configura o contexto do kubectl para que você possa interagir com o cluster. Para verificar a configuração, execute o seguinte comando:
kubectl get nodes -o wide
Os nós vão aparecer com o status "Ready" e outras informações sobre idade, versão, endereço IP externo, imagem do SO, versão do kernel e ambiente de execução do contêiner.
Configure o cluster para instalar o driver da Nvidia em pools de nós ativados para GPU
Em seguida, vamos aplicar um daemonset ao cluster, que vai instalar o driver da Nvidia em todos os nós do cluster ativados para GPU:
kubectl apply -f https://raw.githubusercontent.com/GoogleCloudPlatform/container-engine-accelerators/master/nvidia-driver-installer/cos/daemonset-preloaded.yaml
Em seguida, execute o comando a seguir, que concede aos componentes do KFP permissão para criar novos recursos do Kubernetes:
kubectl create clusterrolebinding sa-admin --clusterrole=cluster-admin --serviceaccount=kubeflow:pipeline-runner
Crie um pool de nós de GPU.
Em seguida, vamos configurar um pool de nós de GPU com tamanho 1:
gcloud container node-pools create gpu-pool \
--cluster=${CLUSTER_NAME} \
--zone ${ZONE} \
--num-nodes=1 \
--machine-type n1-highmem-8 \
--scopes cloud-platform --verbosity error \
--accelerator=type=nvidia-tesla-k80,count=1
3. Executar um pipeline no painel "Pipelines"
Abra o painel "Pipelines".
No console do Cloud, acesse o painel "Pipelines" se ainda não tiver feito isso. Em seguida, clique em ABRIR PAINEL DE PIPELINES para sua instalação e em Pipelines na barra de menus à esquerda. Se você receber um erro de carregamento, atualize a guia. Uma nova página como esta vai aparecer:

Descrição do pipeline
O pipeline que você vai executar tem várias etapas. Consulte o apêndice deste codelab para mais detalhes:
- Um checkpoint de modelo existente é copiado para seu bucket.
- Um modelo Tensor2Tensor é treinado usando dados pré-processados.
- O treinamento começa com o ponto de verificação do modelo atual copiado na primeira etapa e continua por mais algumas centenas de etapas. Levaria muito tempo para treinar totalmente durante o codelab.
- Quando o treinamento termina, a etapa do pipeline exporta o modelo em um formato adequado para disponibilização pelo TensorFlow Serving.
- Uma instância do TensorFlow Serving é implantada usando esse modelo.
- Um app da Web é iniciado para interagir com o modelo veiculado e recuperar previsões.
Fazer o download e compilar o pipeline
Nesta seção, vamos aprender a compilar uma definição de pipeline. Primeiro, precisamos instalar o SDK do KFP. Execute o seguinte no Cloud Shell:
pip3 install -U kfp
Para fazer o download do arquivo de definição do pipeline, execute este comando no Cloud Shell:
curl -O https://raw.githubusercontent.com/amygdala/kubeflow-examples/ghsumm/github_issue_summarization/pipelines/example_pipelines/gh_summ_hosted_kfp.py
Em seguida, compile o arquivo de definição do pipeline executando-o desta forma:
python3 gh_summ_hosted_kfp.py
O arquivo gh_summ_hosted_kfp.py.tar.gz vai aparecer.
Fazer upload do pipeline compilado
Na interface da Web do Kubeflow Pipelines, clique em Enviar pipeline e selecione Importar por URL. Copie e cole o seguinte URL, que aponta para o mesmo pipeline que você acabou de compilar. Fazer upload de um arquivo do Cloud Shell exige algumas etapas extras, então vamos usar um atalho.
Dê um nome ao pipeline (por exemplo, gh_summ).

Executar o pipeline
Clique no pipeline enviado na lista para ver o gráfico estático dele e, em seguida, clique em Criar experimento para criar um novo Experimento usando o pipeline. Um experimento é uma forma de agrupar execuções semanticamente relacionadas.

Dê um nome ao experimento (por exemplo, o mesmo nome do pipeline, gh_summ) e clique em Próxima para criar.

Isso vai abrir uma página em que você pode inserir os parâmetros de uma execução e iniciá-la.
Execute os comandos a seguir no Cloud Shell para ajudar a preencher os parâmetros.
gcloud config get-value project
echo "gs://${BUCKET_NAME}/codelab"
O nome da execução será preenchido automaticamente, mas você pode dar um nome diferente se quiser.
Em seguida, preencha três campos de parâmetros:
project- (opcional)
github-token working-dir
Para o working-dir, insira um caminho no bucket do GCS que você criou. Inclua o prefixo "gs://". No campo github-token, insira o token que você gerou antes ou deixe a string de marcador de posição no estado em que se encontra se não tiver gerado um token.

Depois de preencher os campos, clique em Iniciar e na execução listada para ver os detalhes. Enquanto uma determinada etapa do pipeline está em execução, é possível clicar nela para receber mais informações, incluindo os registros do pod. Também é possível conferir os registros de uma etapa do pipeline pelo link para os registros do Cloud Logging (Stackdriver), mesmo que o nó do cluster tenha sido desativado.

Ver a definição do pipeline
Enquanto o pipeline está em execução, você pode analisar melhor como ele é montado e o que está fazendo. Há mais detalhes na seção Apêndice do codelab.
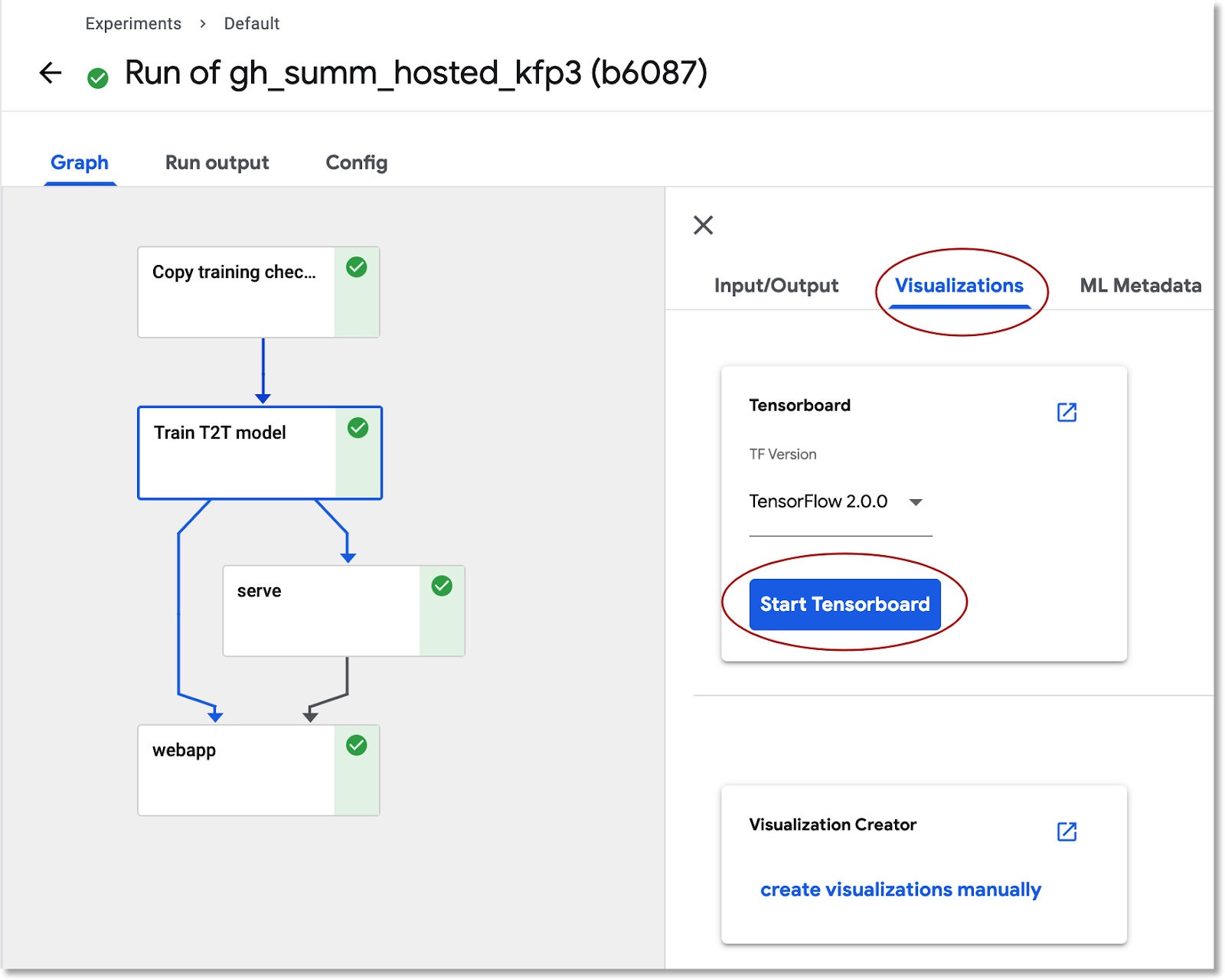
Ver informações de treinamento de modelo no TensorBoard
Quando a etapa de treinamento for concluída, selecione a guia Visualizações e clique no botão azul Iniciar o TensorBoard. Quando estiver pronto, clique em Abrir o TensorBoard.

Conheça o painel "Artefatos e execuções"
O Kubeflow Pipelines registra automaticamente metadados sobre as etapas do pipeline à medida que ele é executado. As informações de artefato e execução são registradas. Clique nessas entradas na barra de navegação à esquerda do painel para saber mais.

Para artefatos, é possível conferir um painel de visão geral e um painel do Lineage Explorer.

Abra o web app criado pelo pipeline e faça algumas previsões
A última etapa do pipeline implanta um app da Web, que fornece uma interface para consultar o modelo treinado (disponibilizado via TF Serving) e fazer previsões.
Depois que o pipeline for concluído, conecte-se ao app da Web por encaminhamento de porta para o serviço dele. Estamos fazendo o encaminhamento de porta porque, para este codelab, o serviço do app da Web não está configurado para ter um endpoint externo.
Para encontrar o nome do serviço, execute este comando no Cloud Shell:
kubectl get services
Procure um nome de serviço como este: ghsumm-*-webappsvc na lista.
Em seguida, no Cloud Shell, encaminhe a porta para esse serviço da seguinte maneira, mudando o comando abaixo para usar o nome do seu webappsvc:
kubectl port-forward svc/ghsumm-xxxxx-webappsvc 8080:80
Quando o encaminhamento de porta estiver em execução, clique no ícone "Visualizar" acima do painel do Cloud Shell e, no menu suspenso, clique em "Visualizar na porta 8080".

Uma página como esta vai aparecer em uma nova guia:
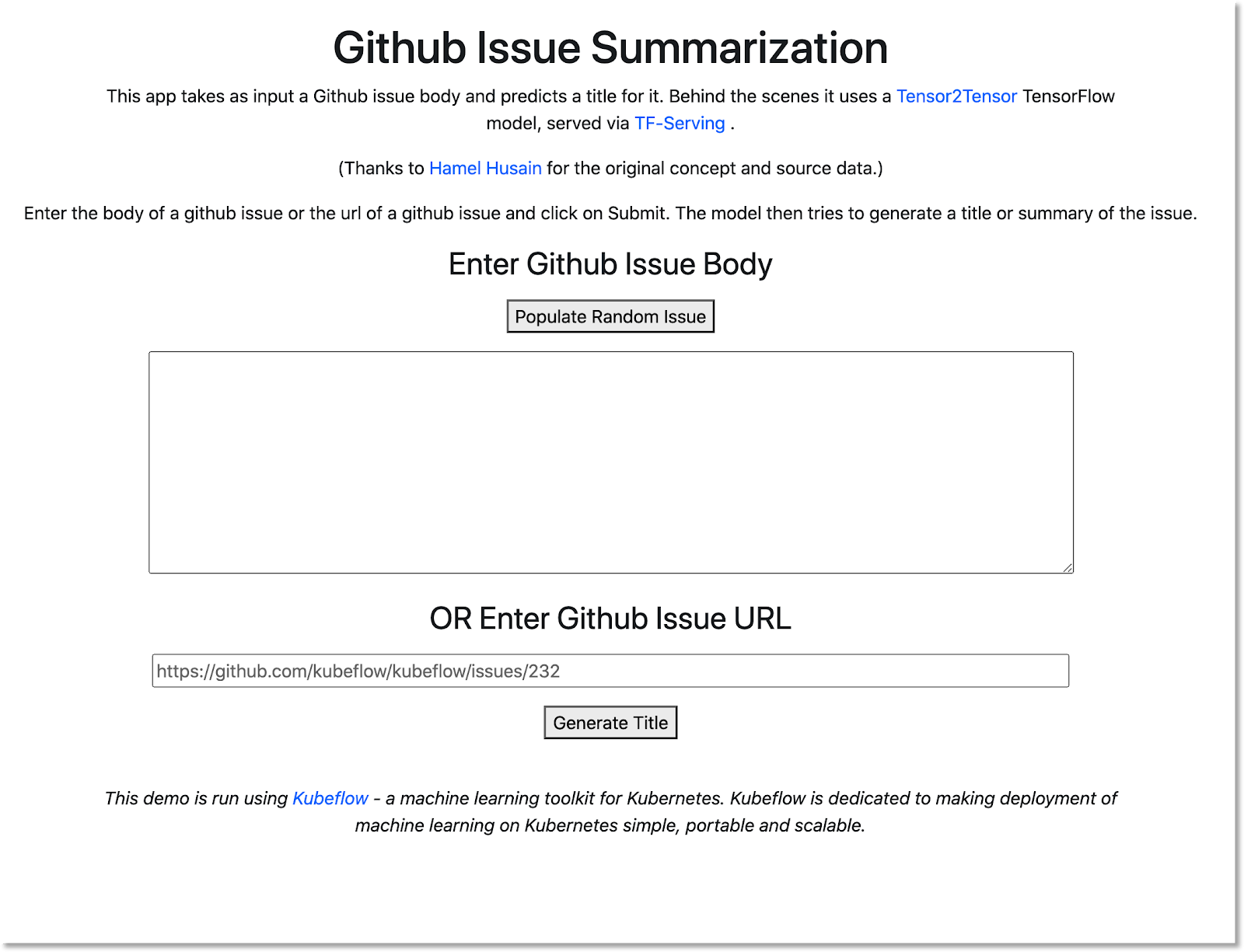
Clique no botão Populate Random Issue para recuperar um bloco de texto. Clique em Gerar título para chamar o modelo treinado e mostrar uma previsão.

Se os parâmetros do pipeline incluírem um token do GitHub válido, você poderá inserir um URL do GitHub no segundo campo e clicar em "Gerar título". Se você não configurou um token do GitHub válido, use apenas o campo "Preencher problema aleatório".
4. Executar um pipeline em um notebook da AI Platform
Também é possível definir e executar pipelines do Kubeflow de maneira interativa em um notebook Jupyter usando o SDK do KFP. O AI Platform Notebooks, que vamos usar neste codelab, simplifica muito esse processo.
Criar uma instância de notebook
Vamos criar uma instância de notebook no Cloud Shell usando a API dele. Como alternativa, é possível criar um notebook pelo Cloud Console. Consulte a documentação para mais informações.
Defina as seguintes variáveis de ambiente no Cloud Shell:
export INSTANCE_NAME="kfp-ghsumm" export VM_IMAGE_PROJECT="deeplearning-platform-release" export VM_IMAGE_FAMILY="tf2-2-3-cpu" export MACHINE_TYPE="n1-standard-4" export LOCATION="us-central1-c"
Em seguida, no Cloud Shell, execute o comando para criar a instância de notebook:
gcloud beta notebooks instances create $INSTANCE_NAME \ --vm-image-project=$VM_IMAGE_PROJECT \ --vm-image-family=$VM_IMAGE_FAMILY \ --machine-type=$MACHINE_TYPE --location=$LOCATION
Na primeira vez que você executar esse comando, talvez seja necessário ativar a API notebooks no seu projeto. Responda "y" se for o caso.
Depois de alguns minutos, o servidor de notebook vai estar funcionando. É possível ver as instâncias de notebook listadas no Console do Cloud.

Fazer upload do notebook do codelab
Depois que a instância do notebook for criada, clique neste link para fazer upload do notebook Jupyter do codelab. Selecione a instância de notebook a ser usada. O notebook será aberto automaticamente.
Executar o notebook
Siga as instruções no notebook para o restante do laboratório. Na parte "Configuração" do notebook, você precisa preencher seus próprios valores antes de executar o restante do notebook.
Se você estiver usando seu próprio projeto, não se esqueça de voltar e fazer a seção "Limpeza" deste laboratório.
5. Limpar
Não é necessário fazer isso se você estiver usando uma conta temporária do codelab, mas talvez queira desativar a instalação do Notebook e do Pipelines se estiver usando seu próprio projeto.
Desativar o cluster do GKE do Pipelines
É possível excluir o cluster do Pipelines no Console do Cloud. Você pode excluir apenas a instalação do Pipelines se quiser reutilizar o cluster do GKE.
Excluir a instância do AI Notebook
Se você executou a parte "Notebook" do codelab, é possível EXCLUIR ou PARAR a instância do notebook no Console do Cloud.
Opcional: remova o token do GitHub
Navegue até https://github.com/settings/tokens e remova o token gerado.
6. Anexos
Analisando o código
Definir o pipeline
O pipeline usado neste codelab está definido aqui.
Vamos ver como ele é definido e como os componentes (etapas) são definidos. Vamos abordar alguns destaques, mas consulte a documentação para mais detalhes.
As etapas do pipeline do Kubeflow são baseadas em contêineres. Ao criar um pipeline, é possível usar componentes pré-criados, com imagens de contêiner já criadas, ou criar seus próprios componentes. Neste codelab, criamos o nosso.
Quatro das etapas do pipeline são definidas com componentes reutilizáveis, acessados pelos arquivos de definição de componentes. Neste primeiro snippet de código, acessamos esses arquivos de definição de componente pelo URL e usamos essas definições para criar "ops" que serão usadas para criar uma etapa de pipeline.
import kfp.dsl as dsl
import kfp.gcp as gcp
import kfp.components as comp
...
copydata_op = comp.load_component_from_url(
'https://raw.githubusercontent.com/kubeflow/examples/master/github_issue_summarization/pipelines/components/t2t/datacopy_component.yaml'
)
train_op = comp.load_component_from_url(
'https://raw.githubusercontent.com/kubeflow/examples/master/github_issue_summarization/pipelines/components/t2t/train_component.yaml'
)
Confira abaixo uma das definições de componente, para a operação de treinamento, no formato YAML. É possível ver que as entradas, saídas, imagem do contêiner e argumentos do ponto de entrada do contêiner estão definidos.
name: Train T2T model
description: |
A Kubeflow Pipeline component to train a Tensor2Tensor
model
metadata:
labels:
add-pod-env: 'true'
inputs:
- name: train_steps
description: '...'
type: Integer
default: 2019300
- name: data_dir
description: '...'
type: GCSPath
- name: model_dir
description: '...'
type: GCSPath
- name: action
description: '...'
type: String
- name: deploy_webapp
description: '...'
type: String
outputs:
- name: launch_server
description: '...'
type: String
- name: train_output_path
description: '...'
type: GCSPath
- name: MLPipeline UI metadata
type: UI metadata
implementation:
container:
image: gcr.io/google-samples/ml-pipeline-t2ttrain:v3ap
args: [
--data-dir, {inputValue: data_dir},
--action, {inputValue: action},
--model-dir, {inputValue: model_dir},
--train-steps, {inputValue: train_steps},
--deploy-webapp, {inputValue: deploy_webapp},
--train-output-path, {outputPath: train_output_path}
]
env:
KFP_POD_NAME: "{{pod.name}}"
fileOutputs:
launch_server: /tmp/output
MLPipeline UI metadata: /mlpipeline-ui-metadata.json
Também é possível definir uma etapa do pipeline usando o construtor dsl.ContainerOp, como veremos abaixo.
Confira abaixo a maior parte da definição do pipeline. Estamos definindo as entradas do pipeline (e os valores padrão delas). Em seguida, definimos as etapas do pipeline. Para a maioria, usamos as "ops" definidas acima, mas também definimos uma etapa "serve" inline via ContainerOp, especificando diretamente a imagem do contêiner e os argumentos de ponto de entrada.
É possível ver que as etapas train, log_model e serve estão acessando saídas de etapas anteriores como entradas. Leia mais sobre como isso é especificado aqui.
@dsl.pipeline(
name='Github issue summarization',
description='Demonstrate Tensor2Tensor-based training and TF-Serving'
)
def gh_summ( #pylint: disable=unused-argument
train_steps: 'Integer' = 2019300,
project: str = 'YOUR_PROJECT_HERE',
github_token: str = 'YOUR_GITHUB_TOKEN_HERE',
working_dir: 'GCSPath' = 'gs://YOUR_GCS_DIR_HERE',
checkpoint_dir: 'GCSPath' = 'gs://aju-dev-demos-codelabs/kubecon/model_output_tbase.bak2019000/',
deploy_webapp: str = 'true',
data_dir: 'GCSPath' = 'gs://aju-dev-demos-codelabs/kubecon/t2t_data_gh_all/'
):
copydata = copydata_op(
data_dir=data_dir,
checkpoint_dir=checkpoint_dir,
model_dir='%s/%s/model_output' % (working_dir, dsl.RUN_ID_PLACEHOLDER),
action=COPY_ACTION,
)
train = train_op(
data_dir=data_dir,
model_dir=copydata.outputs['copy_output_path'],
action=TRAIN_ACTION, train_steps=train_steps,
deploy_webapp=deploy_webapp
)
serve = dsl.ContainerOp(
name='serve',
image='gcr.io/google-samples/ml-pipeline-kubeflow-tfserve:v6',
arguments=["--model_name", 'ghsumm-%s' % (dsl.RUN_ID_PLACEHOLDER,),
"--model_path", train.outputs['train_output_path']
]
)
train.set_gpu_limit(1)
A etapa "train" precisa ser executada em um nó do cluster que tenha pelo menos uma GPU disponível.
train.set_gpu_limit(1)
A etapa final do pipeline, também definida inline, é condicional. Ele será executado depois que a etapa "serve" for concluída, somente se a saída da etapa de treinamento launch_server for a string "true". Ele inicia o "app da Web de previsão", que usamos para solicitar resumos de problemas do modelo T2T treinado.
with dsl.Condition(train.outputs['launch_server'] == 'true'):
webapp = dsl.ContainerOp(
name='webapp',
image='gcr.io/google-samples/ml-pipeline-webapp-launcher:v1',
arguments=["--model_name", 'ghsumm-%s' % (dsl.RUN_ID_PLACEHOLDER,),
"--github_token", github_token]
)
webapp.after(serve)
As definições de imagem do contêiner de componentes
A documentação do Kubeflow Pipelines descreve algumas práticas recomendadas para criar seus próprios componentes. Como parte desse processo, você precisará definir e criar uma imagem do contêiner. Confira as etapas do componente para o pipeline deste codelab aqui. As definições do Dockerfile estão nos subdiretórios containers, por exemplo, aqui.
Usar VMs preemptivas com GPUs para treinamento
As VMs preemptivas são instâncias de VM do Compute Engine com duração de, no máximo, 24 horas e que não oferecem garantias de disponibilidade. O preço das VMs preemptivas é menor do que o das VMs padrão do Compute Engine.
Com o Google Kubernetes Engine (GKE), é fácil configurar um cluster ou um pool de nós que usa VMs preemptivas. É possível configurar um pool de nós com GPUs anexadas às instâncias preemptivas. Eles funcionam da mesma forma que os nós comuns ativados para GPU, mas as GPUs persistem apenas durante a vida útil da instância.
É possível configurar um pool de nós preemptivo e ativado para GPU no cluster executando um comando semelhante ao seguinte, editando o comando com o nome e a zona do cluster e ajustando o tipo e a contagem de aceleradores de acordo com seus requisitos. Você pode definir o escalonamento automático do pool de nós com base nas cargas de trabalho atuais.
gcloud container node-pools create preemptible-gpu-pool \
--cluster=<your-cluster-name> \
--zone <your-cluster-zone> \
--enable-autoscaling --max-nodes=4 --min-nodes=0 \
--machine-type n1-highmem-8 \
--preemptible \
--node-taints=preemptible=true:NoSchedule \
--scopes cloud-platform --verbosity error \
--accelerator=type=nvidia-tesla-k80,count=4
Também é possível configurar um pool de nós pelo Console do Cloud.
Definir um pipeline do Kubeflow que usa os nós preemptivos do GKE
Se você estiver executando o Kubeflow no GKE, agora é fácil definir e executar pipelines do Kubeflow em que uma ou mais etapas do pipeline (componentes) são executadas em nós preemptíveis, reduzindo o custo de execução de um job. Para que o uso de VMs preemptivas forneça resultados corretos, as etapas identificadas como preemptivas precisam ser idempotentes (ou seja, se você executar uma etapa várias vezes, ela terá o mesmo resultado) ou fazer checkpoint do trabalho para que a etapa possa continuar de onde parou se for interrompida.
Ao definir um pipeline do Kubeflow, você pode indicar que uma determinada etapa deve ser executada em um nó preemptível modificando a operação desta forma:
your_pipelines_op.apply(gcp.use_preemptible_nodepool())
Consulte a documentação para mais detalhes.
Presumivelmente, você também vai querer repetir a etapa algumas vezes se o nó for interrompido. Você pode fazer isso da seguinte maneira. Aqui, estamos especificando cinco novas tentativas.
your_pipelines_op.set_gpu_limit(1).apply(gcp.use_preemptible_nodepool()).set_retry(5)
Tente editar o pipeline do Kubeflow que usamos neste codelab para executar a etapa de treinamento em uma VM preemptiva.
Mude a seguinte linha na especificação do pipeline para usar também um pool de nós preemptivo (verifique se você criou um conforme indicado acima) e para tentar novamente cinco vezes:
train.set_gpu_limit(1)
Em seguida, recompile o pipeline, faça upload da nova versão (dê um novo nome a ela) e execute a nova versão do pipeline.