
1. Введение
| Kubeflow — это набор инструментов для машинного обучения в Kubernetes . Проект посвящен упрощению, переносимости и масштабируемости развертывания рабочих процессов машинного обучения (ML) в Kubernetes. Цель — предоставить простой способ развертывания лучших в своем классе систем с открытым исходным кодом для машинного обучения на различных инфраструктурах. |
| Рабочий процесс машинного обучения может включать множество взаимозависимых этапов: от подготовки и анализа данных до обучения, оценки, развертывания и многого другого. Сложно организовать и отслеживать эти процессы произвольно — например, в наборе блокнотов или скриптов — и такие вопросы, как аудит и воспроизводимость, становятся все более проблематичными. Kubeflow Pipelines (KFP) помогает решить эти проблемы, предоставляя способ развертывания надежных, воспроизводимых конвейеров машинного обучения, а также мониторинг, аудит, отслеживание версий и воспроизводимость. Cloud AI Pipelines упрощает настройку KFP. |


Что вы построите
В этом практическом занятии вы создадите веб-приложение, которое будет суммировать проблемы GitHub, используя конвейеры Kubeflow для обучения и запуска модели. Оно основано на примере из репозитория Kubeflow Examples . После завершения ваша инфраструктура будет включать в себя:
- Кластер Google Kubernetes Engine (GKE) с установленными Kubeflow Pipelines (через Cloud AI Pipelines ).
- Конвейер обработки данных для обучения модели Tensor2Tensor на графических процессорах.
- Контейнер для подачи блюд, отображающий прогнозы, полученные с помощью обученной модели.
- Пользовательский интерфейс, который интерпретирует прогнозы для предоставления сводных данных по задачам GitHub.
- Блокнот, создающий конвейер обработки данных с нуля с использованием SDK Kubeflow Pipelines (KFP).
Что вы узнаете
Созданный вами конвейер обучает модель Tensor2Tensor на данных о задачах GitHub, обучаясь предсказывать заголовки задач по их содержанию. Затем он экспортирует обученную модель и развертывает ее с помощью TensorFlow Serving . На заключительном этапе конвейера запускается веб-приложение, которое взаимодействует с экземпляром TF-Serving для получения прогнозов модели.
- Как установить Kubeflow Pipelines в кластере GKE
- Как создавать и запускать рабочие процессы машинного обучения с помощью конвейеров Kubernetes
- Как определять и запускать конвейеры обработки данных из блокнота платформы ИИ
Что вам понадобится
- Базовое понимание Kubernetes будет полезным, но не обязательным.
- Активный проект GCP, для которого у вас есть права владельца.
- (Необязательно) Аккаунт GitHub
- Доступ к оболочке Google Cloud Shell , доступной в консоли Google Cloud Platform (GCP).
2. Настройка
Облачная оболочка
Откройте консоль GCP в браузере и войдите в систему, используя учетные данные своего проекта:
При необходимости нажмите «Выбрать проект», чтобы начать работу с вашим проектом из Codelab.

Затем нажмите значок «Активировать Cloud Shell» в правом верхнем углу консоли, чтобы запустить Cloud Shell .

При запуске Cloud Shell отобразится название проекта, который будет использоваться. Убедитесь, что эта настройка верна.
Чтобы найти идентификатор своего проекта, перейдите на главную панель консоли GCP. Если экран пуст, нажмите «Да» в появившемся окне, чтобы создать панель мониторинга.

Затем в терминале Cloud Shell при необходимости выполните следующие команды, чтобы настроить gcloud для использования правильного проекта:
export PROJECT_ID=<your_project_id>
gcloud config set project ${PROJECT_ID}
Создайте хранилище (сумку для хранения).
Создайте корзину Cloud Storage для хранения файлов конвейера. Вам потребуется использовать глобально уникальный идентификатор, поэтому удобно указать имя корзины, включающее идентификатор вашего проекта. Создайте корзину с помощью команды gsutil mb (make bucket):
export PROJECT_ID=<your_project_id>
export BUCKET_NAME=kubeflow-${PROJECT_ID}
gsutil mb gs://${BUCKET_NAME}
В качестве альтернативы, вы можете создать хранилище через консоль GCP .
Необязательно**: Создайте токен GitHub**
В этом практическом задании используется API GitHub для получения общедоступных данных. Чтобы избежать ограничений скорости запросов, особенно в случаях, когда к API GitHub отправляется большое количество анонимизированных запросов, настройте токен доступа без каких-либо разрешений. Это необходимо просто для авторизации вас как отдельного пользователя, а не как анонимного.
- Перейдите по ссылке https://github.com/settings/tokens и сгенерируйте новый токен без ограничений по области действия (scopes).
- Сохраните его в надёжном месте. Если вы его потеряете, вам придётся удалить и создать новый.
Если вы пропустите этот шаг, лабораторная работа все равно будет работать – просто ваши возможности по генерации входных данных для тестирования модели будут несколько ограничены.
Дополнительно: Закрепить полезные панели мониторинга
В консоли GCP закрепите панели мониторинга Kubernetes Engine и Storage для более удобного доступа.

Создайте установку AI Platform Pipelines (Hosted Kubeflow Pipelines).
Следуйте инструкциям в разделах «Перед началом работы» и «Настройка экземпляра», чтобы настроить экземпляр GKE с установленным KFP. Обязательно установите флажок « Разрешить доступ к следующим облачным API», как указано в документации. (В противном случае пример конвейера не будет успешно запущен). Оставьте пространство имен установки по default .
Вам потребуется выбрать зону, поддерживающую Nvidia k80. В качестве зоны по умолчанию можно использовать us-central1-a или us-central1-c .
Запомните имя кластера GKE и зону, указанные для вашей установки на панели мониторинга AI Pipelines после завершения установки, и для удобства установите переменные среды в соответствии с этими значениями.

export ZONE=<your zone> export CLUSTER_NAME=<your cluster name>
Настройте kubectl для использования учетных данных вашего нового кластера GKE.
После создания кластера GKE настройте kubectl для использования учетных данных нового кластера, выполнив следующую команду в Cloud Shell:
gcloud container clusters get-credentials ${CLUSTER_NAME} \
--project ${PROJECT_ID} \
--zone ${ZONE}
В качестве альтернативы, щелкните по названию кластера на панели управления AI Pipelines, чтобы перейти на его страницу в GKE, затем нажмите «Подключиться» в верхней части страницы. Из всплывающего окна вставьте команду в свою оболочку Cloud Shell.
Это настраивает контекст kubectl , позволяя вам взаимодействовать с кластером. Для проверки конфигурации выполните следующую команду:
kubectl get nodes -o wide
Вы должны увидеть узлы со статусом " Ready ", а также другую информацию о возрасте узла, версии, внешнем IP-адресе, образе ОС, версии ядра и среде выполнения контейнера.
Настройте кластер для установки драйвера Nvidia на пулы узлов с поддержкой графических процессоров.
Далее мы применим к кластеру DaemonSet , который установит драйвер Nvidia на все узлы кластера с поддержкой графических процессоров:
kubectl apply -f https://raw.githubusercontent.com/GoogleCloudPlatform/container-engine-accelerators/master/nvidia-driver-installer/cos/daemonset-preloaded.yaml
Затем выполните следующую команду, которая предоставит компонентам KFP разрешение на создание новых ресурсов Kubernetes:
kubectl create clusterrolebinding sa-admin --clusterrole=cluster-admin --serviceaccount=kubeflow:pipeline-runner
Создайте пул узлов GPU.
Затем мы настроим пул узлов GPU размером 1:
gcloud container node-pools create gpu-pool \
--cluster=${CLUSTER_NAME} \
--zone ${ZONE} \
--num-nodes=1 \
--machine-type n1-highmem-8 \
--scopes cloud-platform --verbosity error \
--accelerator=type=nvidia-tesla-k80,count=1
3. Запустите конвейер с панели управления «Конвейеры».
Откройте панель управления «Конвейеры».
В консоли Cloud перейдите в панель Pipelines , если вы еще там не находитесь. Затем нажмите « ОТКРЫТЬ ПАНЕЛЬ УПРАВЛЕНИЯ PIPELINES » для вашей установки и выберите Pipelines в левой строке меню. Если вы получили ошибку загрузки, обновите вкладку. Вы должны увидеть новую страницу, похожую на эту:

Описание конвейера
Конвейер выполнения, который вы будете запускать, состоит из нескольких этапов (подробности см. в Приложении к данному практическому заданию):
- Существующая контрольная точка модели копируется в ваш бакет.
- Модель Tensor2Tensor обучается с использованием предварительно обработанных данных.
- Обучение начинается с существующей контрольной точки модели, скопированной на первом шаге, а затем продолжается еще несколько сотен шагов. (Полное обучение модели в рамках практического занятия заняло бы слишком много времени).
- После завершения обучения на этапе конвейера модель экспортируется в формате, подходящем для развертывания с помощью TensorFlow Serving .
- Экземпляр TensorFlow-Serving развертывается с использованием этой модели.
- Для взаимодействия с предоставленной моделью и получения прогнозов запускается веб-приложение.
Загрузите и скомпилируйте конвейер обработки данных.
В этом разделе мы рассмотрим, как скомпилировать определение конвейера. Первым делом нам нужно установить KFP SDK. Выполните следующие действия в Cloud Shell:
pip3 install -U kfp
Чтобы загрузить файл определения конвейера, выполните следующую команду в Cloud Shell:
curl -O https://raw.githubusercontent.com/amygdala/kubeflow-examples/ghsumm/github_issue_summarization/pipelines/example_pipelines/gh_summ_hosted_kfp.py
Затем скомпилируйте файл определения конвейера, запустив его следующим образом:
python3 gh_summ_hosted_kfp.py
В результате вы увидите файл gh_summ_hosted_kfp.py.tar.gz .
Загрузите скомпилированный конвейер.
В веб-интерфейсе Kubeflow Pipelines нажмите «Загрузить конвейер» и выберите «Импорт по URL» . Скопируйте и вставьте следующий URL, который указывает на тот же конвейер, который вы только что скомпилировали. (Загрузка файла из Cloud Shell требует нескольких дополнительных шагов, поэтому мы используем упрощенный вариант).
Присвойте конвейеру имя (например gh_summ ).
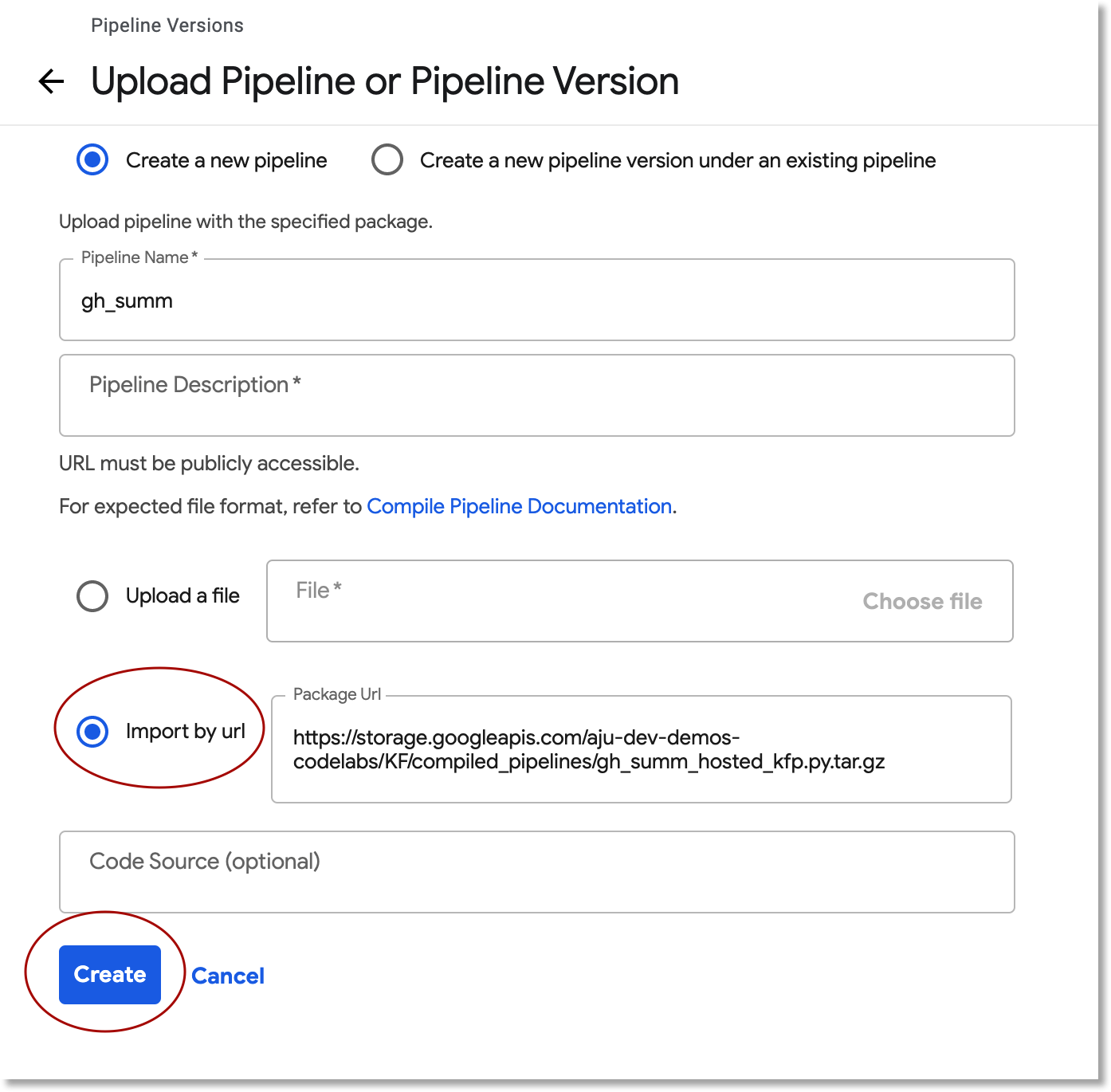
Запустите конвейер
Щелкните по загруженному конвейеру в списке — это позволит просмотреть статический график конвейера — затем нажмите «Создать эксперимент» , чтобы создать новый эксперимент с использованием этого конвейера. Эксперимент — это способ сгруппировать семантически связанные запуски.
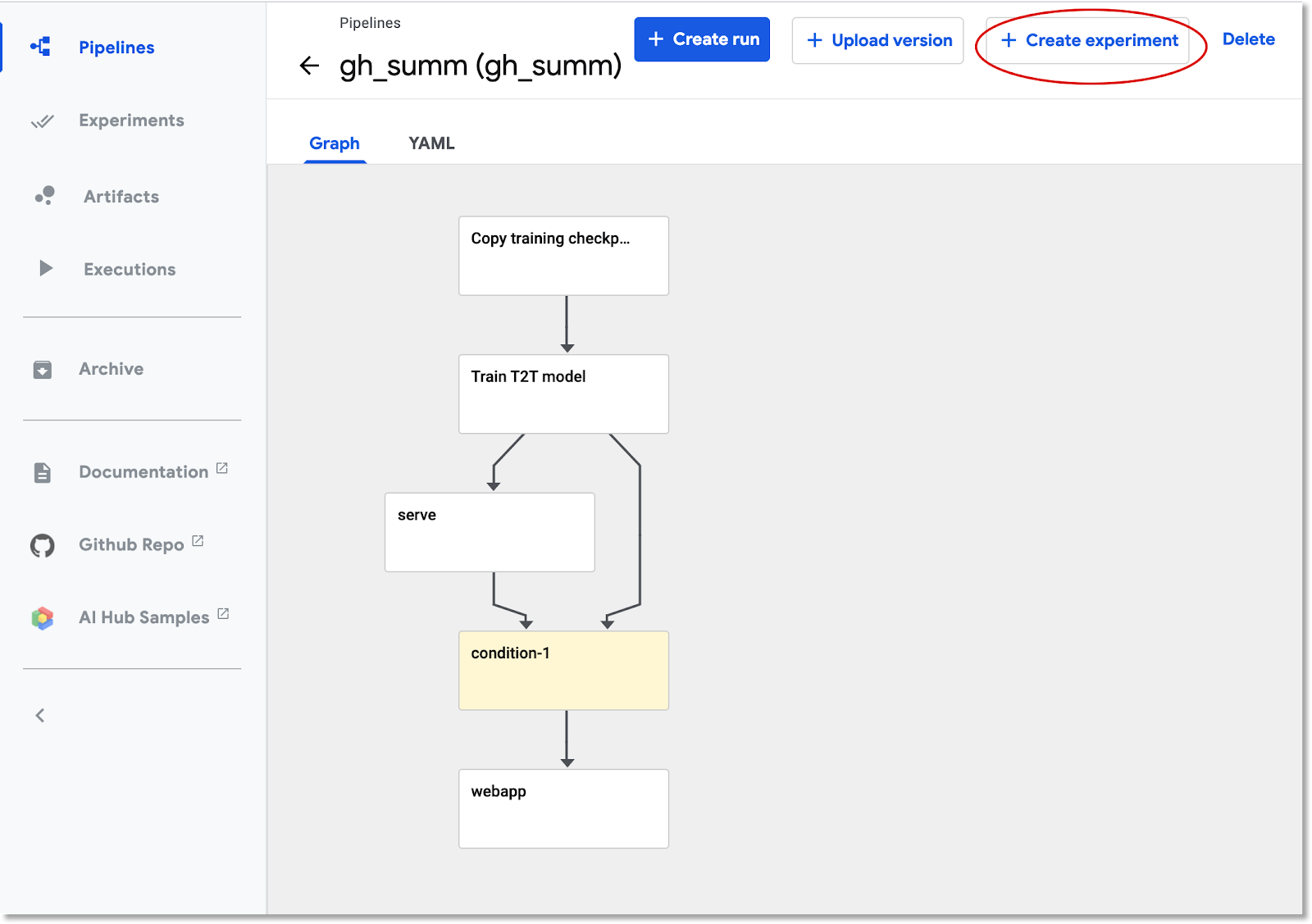
Присвойте эксперименту имя (например, такое же, как у конвейера, gh_summ ), затем нажмите «Далее» , чтобы создать его.

Откроется страница, где вы сможете ввести параметры запуска и начать его.
Для заполнения параметров вам может потребоваться выполнить следующие команды в Cloud Shell.
gcloud config get-value project
echo "gs://${BUCKET_NAME}/codelab"
Имя для запуска будет заполнено автоматически, но при желании вы можете задать другое имя.
Затем заполните три поля параметров:
-
project - (необязательный)
github-token -
working-dir
В поле "Рабочая директория" укажите путь к созданному вами сегменту GCS. Включите префикс " gs:// ". В поле github-token введите либо токен, который вы сгенерировали ранее (по желанию), либо оставьте строку-заполнитель как есть, если вы не генерировали токен.

После заполнения полей нажмите «Запустить» , затем щелкните по указанному запуску, чтобы просмотреть его подробности. Во время выполнения конкретного шага конвейера вы можете щелкнуть по нему, чтобы получить дополнительную информацию о нем, включая просмотр логов пода . (Вы также можете просмотреть логи шага конвейера по ссылке на его логи Cloud Logging (Stackdriver) , даже если узел кластера был отключен).

Просмотрите определение конвейера
Во время работы конвейера вы можете внимательнее изучить его структуру и выполняемые функции. Более подробная информация приведена в разделе «Приложение» к практическому руководству.
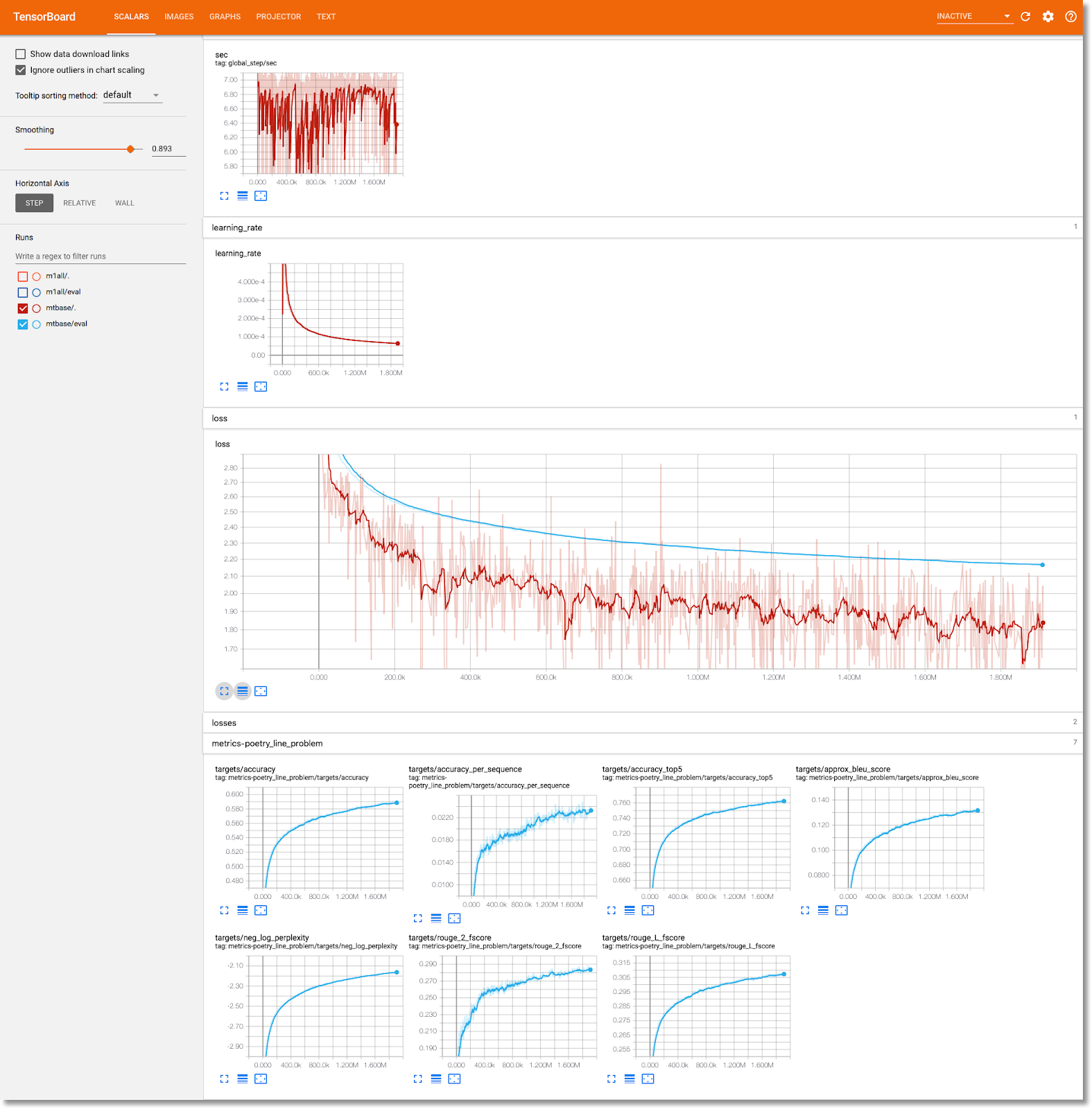
Просмотрите информацию об обучении модели в TensorBoard.
После завершения этапа обучения выберите вкладку «Визуализация» и нажмите синюю кнопку «Запустить TensorBoard» , а затем, когда он будет готов, нажмите «Открыть Tensorboard» .
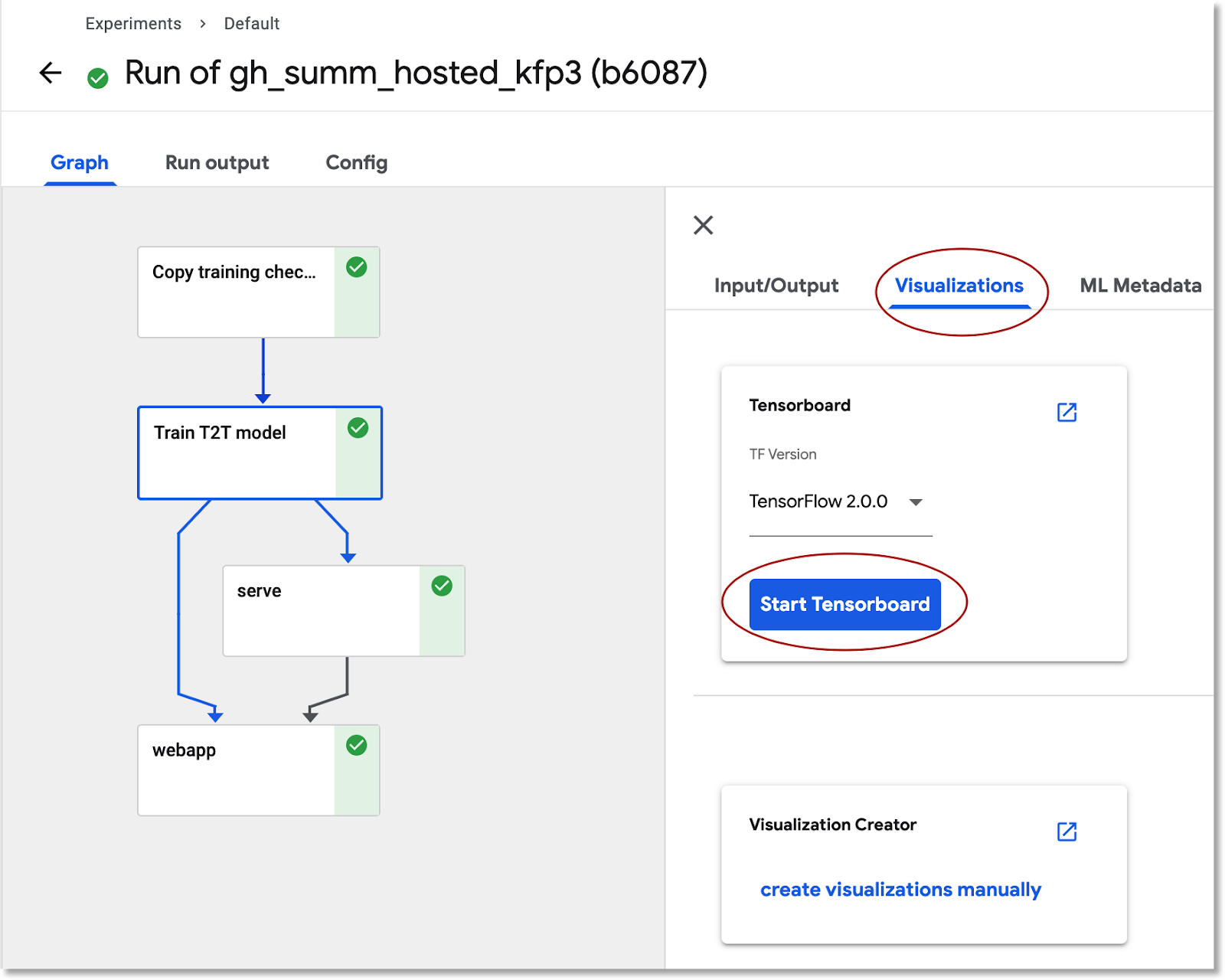
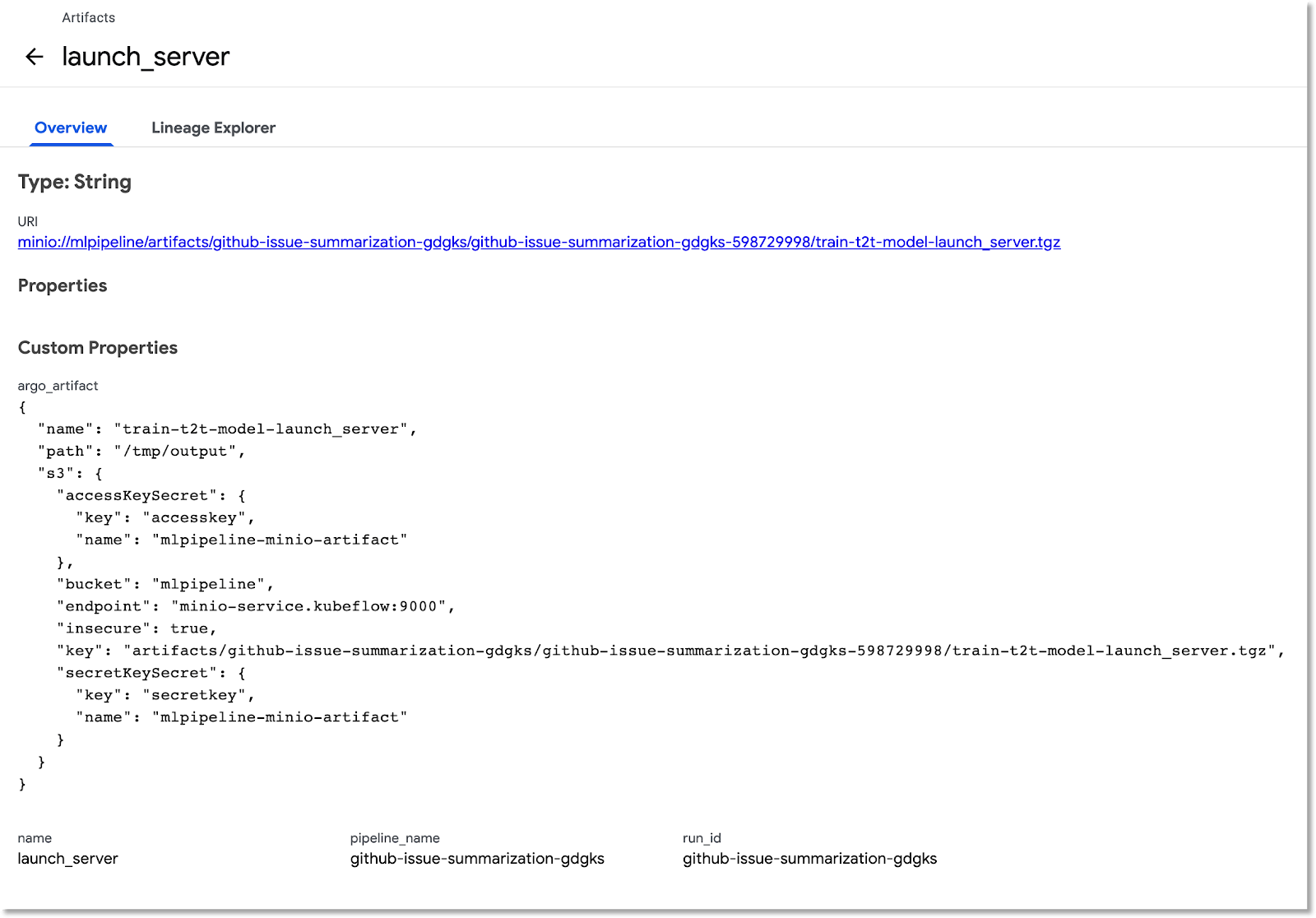
Изучите панель мониторинга артефактов и выполнений.
Kubeflow Pipelines автоматически регистрирует метаданные о шагах конвейера по мере его выполнения. Записывается информация как об артефактах , так и о выполнении . Щелкните по этим записям в левой панели навигации панели управления, чтобы получить более подробную информацию.

Для артефактов вы можете просмотреть как обзорную панель, так и панель «Исследователь родословной».

Запустите веб-приложение, созданное конвейером обработки данных, и сделайте несколько прогнозов.
На последнем этапе конвейера развертывается веб-приложение, которое предоставляет пользовательский интерфейс для запроса к обученной модели — предоставляемой через TF Serving — для выполнения прогнозов.
После завершения конвейера подключитесь к веб-приложению, перенаправив порты на его сервис (мы используем перенаправление портов, потому что для данного практического задания веб-приложение не настроено на внешнюю конечную точку).
Чтобы узнать имя сервиса, выполните следующую команду в Cloud Shell:
kubectl get services
Найдите в списке сервис с именем, похожим на: ghsumm-*-webappsvc .
Затем в Cloud Shell настройте переадресацию портов на этот сервис следующим образом, изменив следующую команду, чтобы использовать имя вашего webappsvc :
kubectl port-forward svc/ghsumm-xxxxx-webappsvc 8080:80
После запуска переадресации портов щелкните значок «предварительный просмотр» над панелью Cloud Shell, а в раскрывающемся списке выберите «Предварительный просмотр на порту 8080».

В новой вкладке должна открыться страница, похожая на эту:

Нажмите кнопку «Заполнить случайный выпуск» , чтобы получить блок текста. Нажмите кнопку «Сгенерировать заголовок» , чтобы вызвать обученную модель и отобразить прогноз.

Если в параметрах вашего конвейера был указан действительный токен GitHub, вы можете попробовать ввести URL-адрес GitHub во второе поле, а затем нажать «Сгенерировать заголовок». Если вы не указали действительный токен GitHub, используйте только поле «Заполнить случайную задачу».
4. Запустите конвейер обработки данных из блокнота платформы ИИ.
Вы также можете интерактивно определять и запускать конвейеры Kubeflow из блокнота Jupyter, используя SDK KFP. AI Platform Notebooks , который мы будем использовать для этого практического занятия, значительно упрощает этот процесс.
Создайте экземпляр блокнота.
Мы создадим экземпляр блокнота из Cloud Shell, используя его API. (В качестве альтернативы вы можете создать блокнот через Cloud Console . Дополнительную информацию см. в документации).
В оболочке Cloud Shell установите следующие переменные среды:
export INSTANCE_NAME="kfp-ghsumm" export VM_IMAGE_PROJECT="deeplearning-platform-release" export VM_IMAGE_FAMILY="tf2-2-3-cpu" export MACHINE_TYPE="n1-standard-4" export LOCATION="us-central1-c"
Затем в оболочке Cloud Shell выполните команду для создания экземпляра блокнота:
gcloud beta notebooks instances create $INSTANCE_NAME \ --vm-image-project=$VM_IMAGE_PROJECT \ --vm-image-family=$VM_IMAGE_FAMILY \ --machine-type=$MACHINE_TYPE --location=$LOCATION
При первом запуске этой команды вас могут попросить включить API notebooks для вашего проекта. В этом случае ответьте « y ».
Через несколько минут ваш сервер Notebook будет запущен и начнет работу. Вы сможете увидеть список своих экземпляров Notebook в консоли Cloud .

Загрузите блокнот Codelab.
После создания экземпляра блокнота нажмите эту ссылку , чтобы загрузить блокнот Jupyter из учебного модуля. Выберите нужный экземпляр блокнота. Блокнот откроется автоматически.
Запустите блокнот
Для выполнения оставшейся части лабораторной работы следуйте инструкциям в блокноте . Обратите внимание, что в разделе «Настройка» блокнота вам необходимо будет ввести свои собственные значения, прежде чем запускать остальную часть блокнота.
(Если вы используете собственный проект, не забудьте вернуться и выполнить раздел «Уборка» этой лабораторной работы).
5. Уборка
Если вы используете временную учетную запись Codelab, вам это делать не нужно, но если вы используете собственный проект, возможно, вам стоит удалить установку Pipelines и Notebook.
Вывести из строя кластер Pipelines GKE
Вы можете удалить кластер Pipelines из Cloud Console . (Если вы хотите повторно использовать кластер GKE, у вас есть возможность удалить только установку Pipelines).
Удалите экземпляр AI Notebook.
Если вы выполняли часть практического задания, посвященную "блокноту", вы можете удалить или остановить экземпляр блокнота из облачной консоли .
(Необязательно) Удалите токен GitHub
Перейдите по ссылке https://github.com/settings/tokens и удалите сгенерированный токен.
6. Приложения
Взгляд на код
Определение конвейера
Конвейер обработки данных, используемый в этом практическом занятии, описан здесь .
Давайте рассмотрим, как это определяется, а также как определяются его компоненты (шаги). Мы затронем некоторые основные моменты, но для получения более подробной информации обратитесь к документации .
Шаги конвейера Kubeflow основаны на контейнерах. При создании конвейера вы можете использовать предварительно созданные компоненты с уже готовыми образами контейнеров или создавать собственные компоненты. Для этого практического занятия мы создали свои собственные компоненты.
Четыре этапа конвейера определены на основе многократно используемых компонентов , доступ к которым осуществляется через файлы определения компонентов . В этом первом фрагменте кода мы обращаемся к этим файлам определения компонентов по их URL-адресу и используем эти определения для создания «операций», которые мы будем использовать для создания этапа конвейера.
import kfp.dsl as dsl
import kfp.gcp as gcp
import kfp.components as comp
...
copydata_op = comp.load_component_from_url(
'https://raw.githubusercontent.com/kubeflow/examples/master/github_issue_summarization/pipelines/components/t2t/datacopy_component.yaml'
)
train_op = comp.load_component_from_url(
'https://raw.githubusercontent.com/kubeflow/examples/master/github_issue_summarization/pipelines/components/t2t/train_component.yaml'
)
Ниже приведено одно из определений компонента для операции обучения в формате YAML. Вы можете видеть, что определены его входные и выходные данные, образ контейнера и аргументы точки входа контейнера.
name: Train T2T model
description: |
A Kubeflow Pipeline component to train a Tensor2Tensor
model
metadata:
labels:
add-pod-env: 'true'
inputs:
- name: train_steps
description: '...'
type: Integer
default: 2019300
- name: data_dir
description: '...'
type: GCSPath
- name: model_dir
description: '...'
type: GCSPath
- name: action
description: '...'
type: String
- name: deploy_webapp
description: '...'
type: String
outputs:
- name: launch_server
description: '...'
type: String
- name: train_output_path
description: '...'
type: GCSPath
- name: MLPipeline UI metadata
type: UI metadata
implementation:
container:
image: gcr.io/google-samples/ml-pipeline-t2ttrain:v3ap
args: [
--data-dir, {inputValue: data_dir},
--action, {inputValue: action},
--model-dir, {inputValue: model_dir},
--train-steps, {inputValue: train_steps},
--deploy-webapp, {inputValue: deploy_webapp},
--train-output-path, {outputPath: train_output_path}
]
env:
KFP_POD_NAME: "{{pod.name}}"
fileOutputs:
launch_server: /tmp/output
MLPipeline UI metadata: /mlpipeline-ui-metadata.json
Также можно определить шаг конвейера с помощью конструктора dsl.ContainerOp , как мы увидим ниже.
Ниже приведена основная часть определения конвейера. Мы определяем входные параметры конвейера (и их значения по умолчанию). Затем мы определяем шаги конвейера. Для большинства из них мы используем описанные выше «операции», но также определяем шаг «обслуживание» непосредственно через ContainerOp , указывая напрямую аргументы образа контейнера и точки входа.
Как видите, этапы train , log_model и serve используют выходные данные предыдущих этапов в качестве входных. Подробнее о том, как это задается, можно прочитать здесь .
@dsl.pipeline(
name='Github issue summarization',
description='Demonstrate Tensor2Tensor-based training and TF-Serving'
)
def gh_summ( #pylint: disable=unused-argument
train_steps: 'Integer' = 2019300,
project: str = 'YOUR_PROJECT_HERE',
github_token: str = 'YOUR_GITHUB_TOKEN_HERE',
working_dir: 'GCSPath' = 'gs://YOUR_GCS_DIR_HERE',
checkpoint_dir: 'GCSPath' = 'gs://aju-dev-demos-codelabs/kubecon/model_output_tbase.bak2019000/',
deploy_webapp: str = 'true',
data_dir: 'GCSPath' = 'gs://aju-dev-demos-codelabs/kubecon/t2t_data_gh_all/'
):
copydata = copydata_op(
data_dir=data_dir,
checkpoint_dir=checkpoint_dir,
model_dir='%s/%s/model_output' % (working_dir, dsl.RUN_ID_PLACEHOLDER),
action=COPY_ACTION,
)
train = train_op(
data_dir=data_dir,
model_dir=copydata.outputs['copy_output_path'],
action=TRAIN_ACTION, train_steps=train_steps,
deploy_webapp=deploy_webapp
)
serve = dsl.ContainerOp(
name='serve',
image='gcr.io/google-samples/ml-pipeline-kubeflow-tfserve:v6',
arguments=["--model_name", 'ghsumm-%s' % (dsl.RUN_ID_PLACEHOLDER,),
"--model_path", train.outputs['train_output_path']
]
)
train.set_gpu_limit(1)
Обратите внимание, что для выполнения этапа «обучение» требуется узел в кластере, имеющий как минимум 1 доступный графический процессор.
train.set_gpu_limit(1)
Последний шаг в конвейере — также определенный непосредственно в коде — является условным. Он будет выполнен после завершения шага « serve » только в том случае, если вывод launch_server на этапе обучения имеет значение строки «true». Он запускает «веб-приложение прогнозирования», которое мы использовали для запроса сводных данных по проблемам у обученной модели T2T.
with dsl.Condition(train.outputs['launch_server'] == 'true'):
webapp = dsl.ContainerOp(
name='webapp',
image='gcr.io/google-samples/ml-pipeline-webapp-launcher:v1',
arguments=["--model_name", 'ghsumm-%s' % (dsl.RUN_ID_PLACEHOLDER,),
"--github_token", github_token]
)
webapp.after(serve)
Определения образов контейнеров компонентов
В документации Kubeflow Pipeline описаны некоторые рекомендации по созданию собственных компонентов. В рамках этого процесса вам потребуется определить и создать образ контейнера. Шаги создания компонентов для конвейера из этого практического занятия можно посмотреть здесь . Определения Dockerfile находятся в подкаталогах containers , например, здесь .
Используйте виртуальные машины с возможностью вытеснения с помощью графических процессоров для обучения.
Виртуальные машины с возможностью вытеснения — это экземпляры виртуальных машин Compute Engine , которые работают максимум 24 часа и не гарантируют доступности. Стоимость виртуальных машин с возможностью вытеснения ниже, чем у стандартных виртуальных машин Compute Engine.
С помощью Google Kubernetes Engine (GKE) легко настроить кластер или пул узлов , использующий виртуальные машины с возможностью вытеснения . Вы можете настроить такой пул узлов с графическими процессорами (GPU), подключенными к вытесняемым экземплярам . Они работают так же, как и обычные узлы с поддержкой GPU, но GPU сохраняются только на время жизни экземпляра.
Вы можете настроить пул узлов с возможностью вытеснения и поддержкой графических процессоров для вашего кластера, выполнив команду, аналогичную следующей, отредактировав ее, указав имя кластера и зону, а также настроив тип и количество ускорителей в соответствии с вашими требованиями. При желании вы можете настроить автоматическое масштабирование пула узлов в зависимости от текущей рабочей нагрузки.
gcloud container node-pools create preemptible-gpu-pool \
--cluster=<your-cluster-name> \
--zone <your-cluster-zone> \
--enable-autoscaling --max-nodes=4 --min-nodes=0 \
--machine-type n1-highmem-8 \
--preemptible \
--node-taints=preemptible=true:NoSchedule \
--scopes cloud-platform --verbosity error \
--accelerator=type=nvidia-tesla-k80,count=4
Вы также можете настроить пул узлов через консоль Cloud Console .
Определение конвейера Kubeflow, использующего вытесняемые узлы GKE.
Если вы используете Kubeflow в GKE, теперь легко определять и запускать конвейеры Kubeflow, в которых один или несколько шагов (компонентов) конвейера выполняются на вытесняемых узлах , что снижает стоимость выполнения задания. Для корректного использования вытесняемых виртуальных машин шаги, которые вы определяете как вытесняемые, должны быть либо идемпотентными (то есть, если вы запустите шаг несколько раз, он даст тот же результат), либо должны иметь функцию контрольных точек, позволяющую шагу продолжить выполнение с того места, где он был прерван.
При определении конвейера Kubeflow можно указать, что данный шаг должен выполняться на узле, который можно вытеснить, изменив операцию следующим образом:
your_pipelines_op.apply(gcp.use_preemptible_nodepool())
Подробности см. в документации .
Вероятно, вам также потребуется повторить этот шаг несколько раз, если узел будет вытеснен. Это можно сделать следующим образом — здесь мы указываем 5 повторных попыток.
your_pipelines_op.set_gpu_limit(1).apply(gcp.use_preemptible_nodepool()).set_retry(5)
Попробуйте отредактировать конвейер Kubeflow, который мы использовали в этом практическом занятии, чтобы запустить этап обучения на виртуальной машине с возможностью прерывания .
Измените следующую строку в спецификации конвейера, чтобы дополнительно использовать пул узлов с возможностью прерывания (убедитесь, что вы создали его, как указано выше) и повторить попытку 5 раз:
train.set_gpu_limit(1)
Затем перекомпилируйте конвейер, загрузите новую версию (присвойте ей новое имя) и запустите новую версию конвейера.