
1. Giriş
| Kubeflow, Kubernetes için bir makine öğrenimi araç setidir. Proje, Kubernetes'te makine öğrenimi (ML) iş akışlarının dağıtımını basit, taşınabilir ve ölçeklenebilir hale getirmeye odaklanmıştır. Amaç, makine öğrenimi için çeşitli altyapılara sınıfının en iyisi olan açık kaynaklı sistemler dağıtmanın kolay bir yolunu sağlamaktır. |
| Makine öğrenimi iş akışı; veri hazırlama ve analizinden eğitime, değerlendirmeye, dağıtıma ve daha fazlasına kadar birbirine bağımlı birçok adım içerebilir. Bu süreçleri geçici olarak (ör. bir dizi not defteri veya komut dosyasıyla) oluşturmak ve izlemek zordur. Ayrıca denetim ve tekrarlanabilirlik gibi konular giderek daha sorunlu hale gelir. Kubeflow Pipelines (KFP), izleme, denetim, sürüm takibi ve tekrarlanabilirlik özellikleriyle birlikte sağlam ve tekrarlanabilir makine öğrenimi işlem hatları dağıtmanın bir yolunu sunarak bu sorunları çözmeye yardımcı olur. Cloud AI Pipelines, KFP kurulumunu kolaylaştırır. |


Ne oluşturacaksınız?
Bu codelab'de, bir modeli eğitmek ve sunmak için Kubeflow Pipelines'ı kullanarak GitHub sorunlarını özetleyen bir web uygulaması oluşturacaksınız. Kubeflow Examples deposundaki bir örneğe dayanmaktadır. İşlem tamamlandığında altyapınızda şunlar bulunur:
- Kubeflow Pipelines'ın yüklü olduğu bir Google Kubernetes Engine (GKE) kümesi (Cloud AI Pipelines aracılığıyla).
- GPU'larda Tensor2Tensor modeli eğiten bir işlem hattı
- Eğitilmiş modelden tahminler sağlayan bir yayın container'ı
- GitHub sorunlarıyla ilgili özetler sağlamak için tahminleri yorumlayan bir kullanıcı arayüzü
- Kubeflow Pipelines (KFP) SDK'sını kullanarak sıfırdan ardışık düzen oluşturan bir not defteri
Neler öğreneceksiniz?
Oluşturacağınız ardışık düzen, GitHub sorun verileri üzerinde Tensor2Tensor modelini eğiterek sorun gövdelerinden sorun başlıklarını tahmin etmeyi öğrenir. Ardından, eğitilen modeli dışa aktarır ve dışa aktarılan modeli Tensorflow Serving'i kullanarak dağıtır. Ardışık düzenin son adımında, model tahminlerini almak için TF-Serving örneğiyle etkileşimde bulunan bir web uygulaması başlatılır.
- GKE kümesine Kubeflow Pipelines'ı yükleme
- Kubeflow Pipelines kullanarak ML iş akışlarını oluşturma ve çalıştırma
- AI Platform Notebooks'ta ardışık düzenleri tanımlama ve çalıştırma
Gerekenler
- Kubernetes ile ilgili temel bilgiler faydalı olacaktır ancak zorunlu değildir.
- Sahip izinlerine sahip olduğunuz etkin bir GCP projesi
- (İsteğe bağlı) GitHub hesabı
- Google Cloud Platform (GCP) Console'da bulunan Google Cloud Shell'e erişim
2. Kurulum
Cloud Shell
Tarayıcıda GCP Console'u ziyaret edin ve proje kimlik bilgilerinizle giriş yapın:
Gerekirse "Proje seç"i tıklayarak codelab projenizle çalıştığınızdan emin olun.

Ardından, Cloud Shell'i başlatmak için konsolun sağ üst kısmındaki "Cloud Shell'i Etkinleştir" simgesini tıklayın.

Cloud Shell'i başlattığınızda, kullanmak üzere ayarlandığı projenin adını gösterir. Bu ayarın doğru olup olmadığını kontrol edin.
Proje kimliğinizi bulmak için GCP Console'un Ana Sayfa panelini ziyaret edin. Ekran boşsa gösterge tablosu oluşturmak için istemde "Evet"i tıklayın.

Ardından, Cloud Shell terminalinde gcloud aracını doğru projeyi kullanacak şekilde yapılandırmak için gerekirse şu komutları çalıştırın:
export PROJECT_ID=<your_project_id>
gcloud config set project ${PROJECT_ID}
Storage paketi oluşturma
Ardışık düzen dosyalarını depolamak için bir Cloud Storage paketi oluşturun. Global olarak benzersiz bir kimlik kullanmanız gerektiğinden proje kimliğinizi içeren bir paket adı tanımlamanız kolaylık sağlar. gsutil mb (make bucket) komutunu kullanarak paketi oluşturun:
export PROJECT_ID=<your_project_id>
export BUCKET_NAME=kubeflow-${PROJECT_ID}
gsutil mb gs://${BUCKET_NAME}
Alternatif olarak, GCP Console üzerinden de paket oluşturabilirsiniz.
İsteğe bağlı**: GitHub jetonu oluşturma**
Bu codelab, herkese açık verileri almak için GitHub API'yi çağırır. Özellikle çok sayıda anonimleştirilmiş isteğin GitHub API'lerine gönderildiği etkinliklerde hız sınırlamasıyla karşılaşmamak için izinsiz bir erişim jetonu ayarlayın. Bu işlem yalnızca sizi anonim kullanıcı yerine bireysel kullanıcı olarak yetkilendirmek için yapılır.
- https://github.com/settings/tokens adresine gidin ve kapsam içermeyen yeni bir jeton oluşturun.
- Güvenli bir yerde saklayın. Kaybederseniz silip yenisini oluşturmanız gerekir.
Bu adımı atlarsanız laboratuvar çalışmaya devam eder. Ancak modelinizi test etmek için giriş verileri oluşturma seçenekleriniz biraz daha sınırlı olur.
İsteğe bağlı: Faydalı kontrol panellerini sabitleme
GCP Console'da, daha kolay erişim için Kubernetes Engine ve Storage kontrol panellerini sabitleyin.

AI Platform Pipelines (Barındırılan Kubeflow Pipelines) yüklemesi oluşturma
KFP'nin yüklü olduğu bir GKE örneği oluşturmak için buradaki "Başlamadan önce" ve "Örneğinizi oluşturma" bölümlerindeki talimatları uygulayın. Belgelerde belirtildiği gibi Aşağıdaki Cloud API'lere erişim izni ver kutusunu işaretlediğinizden emin olun. (Aksi takdirde örnek işlem hattı başarıyla çalışmaz.) Yükleme ad alanını default olarak bırakın.
Nvidia K80'leri destekleyen bir bölge seçmeniz gerekir. Varsayılan olarak us-central1-a veya us-central1-c'yi kullanabilirsiniz.
Yükleme tamamlandıktan sonra, yüklemeniz için AI Pipelines kontrol panelinde listelenen GKE küme adını ve bölgeyi not edin. Kolaylık sağlamak için ortam değişkenlerini bu değerlere ayarlayın.

export ZONE=<your zone> export CLUSTER_NAME=<your cluster name>
kubectl'i yeni GKE kümenizin kimlik bilgilerini kullanacak şekilde ayarlama
GKE kümesi oluşturulduktan sonra Cloud Shell'de aşağıdaki komutu çalıştırarak kubectl aracını yeni kümenin kimlik bilgilerini kullanacak şekilde yapılandırın:
gcloud container clusters get-credentials ${CLUSTER_NAME} \
--project ${PROJECT_ID} \
--zone ${ZONE}
Alternatif olarak, GKE sayfasını ziyaret etmek için Yapay Zeka İşlem Hatları kontrol panelinde kümenin adını tıklayın, ardından sayfanın üst kısmındaki "Bağlan"ı tıklayın. Açılan pop-up pencerede komutu Cloud Shell'inize yapıştırın.
Bu işlem, kümenizle etkileşimde bulunabilmeniz için kubectl bağlamınızı yapılandırır. Yapılandırmayı doğrulamak için aşağıdaki komutu çalıştırın:
kubectl get nodes -o wide
Durumu "Ready" olan düğümlerin yanı sıra düğüm yaşı, sürümü, harici IP adresi, işletim sistemi görüntüsü, çekirdek sürümü ve kapsayıcı çalışma zamanı hakkında diğer bilgileri görürsünüz.
Nvidia sürücüsünü GPU özellikli düğüm havuzlarına yüklemek için kümeyi yapılandırma
Ardından, kümeye bir daemonset uygulayacağız. Bu, Nvidia sürücüsünü GPU özellikli tüm küme düğümlerine yükleyecektir:
kubectl apply -f https://raw.githubusercontent.com/GoogleCloudPlatform/container-engine-accelerators/master/nvidia-driver-installer/cos/daemonset-preloaded.yaml
Ardından, KFP bileşenlerine yeni Kubernetes kaynakları oluşturma izni veren aşağıdaki komutu çalıştırın:
kubectl create clusterrolebinding sa-admin --clusterrole=cluster-admin --serviceaccount=kubeflow:pipeline-runner
GPU düğüm havuzu oluşturma
Ardından, boyutu 1 olan bir GPU düğüm havuzu oluştururuz:
gcloud container node-pools create gpu-pool \
--cluster=${CLUSTER_NAME} \
--zone ${ZONE} \
--num-nodes=1 \
--machine-type n1-highmem-8 \
--scopes cloud-platform --verbosity error \
--accelerator=type=nvidia-tesla-k80,count=1
3. Ardışık düzenleri gösterge tablosundan ardışık düzen çalıştırma
Ardışık düzen kontrol panelini açma
Cloud Console'da henüz orada değilseniz Pipelines paneline gidin. Ardından, yüklemeniz için "OPEN PIPELINES DASHBOARD" (KANAL İŞLEME SÜREÇLERİ PANO AÇ) seçeneğini ve sol menü çubuğunda Pipelines'ı (Kanal İşleme Süreçleri) tıklayın. Yükleme hatası alırsanız sekmeyi yenileyin. Aşağıdaki gibi yeni bir sayfa görmeniz gerekir:
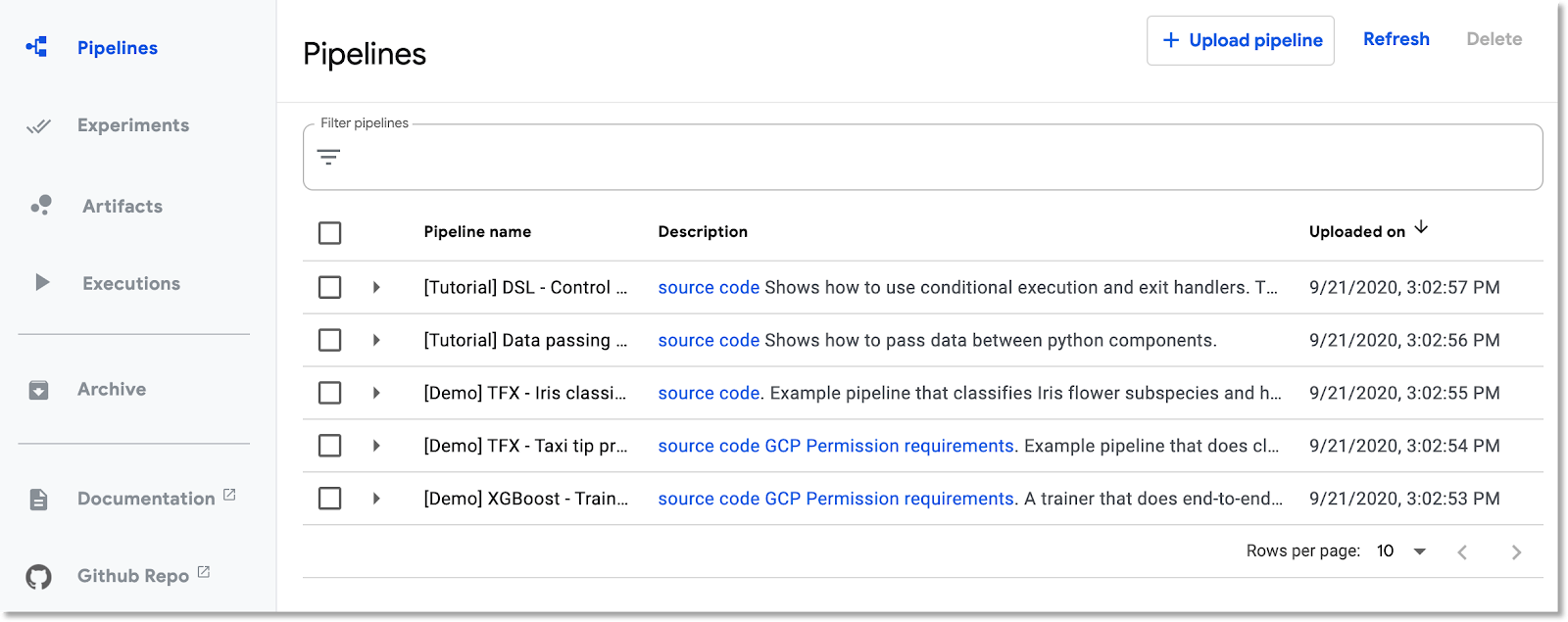
Ardışık düzen açıklaması
Çalıştıracağınız ardışık düzenin çeşitli adımları vardır (ayrıntılar için bu codelab'in Ek bölümüne bakın):
- Mevcut bir model kontrol noktası, paketinize kopyalanır.
- Tensor2Tensor modeli, önceden işlenmiş veriler kullanılarak eğitilir.
- Eğitim, ilk adımda kopyalanan mevcut model kontrol noktasından başlar ve birkaç yüz adım daha devam eder. (Codelab sırasında tam olarak eğitmek çok uzun sürer.)
- Eğitim tamamlandığında, işlem hattı adımı modeli TensorFlow Serving tarafından sunulmaya uygun bir biçimde dışa aktarır.
- Bu model kullanılarak bir TensorFlow Serving örneği dağıtılır.
- Tahminleri almak için sunulan modelle etkileşim kurmaya yönelik bir web uygulaması başlatılır.
Ardışık düzeni indirip derleme
Bu bölümde, bir işlem hattı tanımının nasıl derleneceğini göreceğiz. Yapmamız gereken ilk şey KFP SDK'sını yüklemektir. Cloud Shell'de aşağıdaki komutu çalıştırın:
pip3 install -U kfp
İşlem hattı tanım dosyasını indirmek için Cloud Shell'den şu komutu çalıştırın:
curl -O https://raw.githubusercontent.com/amygdala/kubeflow-examples/ghsumm/github_issue_summarization/pipelines/example_pipelines/gh_summ_hosted_kfp.py
Ardından, ardışık düzen tanım dosyasını şu şekilde çalıştırarak derleyin:
python3 gh_summ_hosted_kfp.py
Sonuç olarak gh_summ_hosted_kfp.py.tar.gz dosyası gösterilir.
Derlenmiş ardışık düzeni yükleme
Kubeflow Pipelines web kullanıcı arayüzünde Upload pipeline'ı (Yükleme hattı) tıklayın ve Import by URL'yi (URL ile içe aktar) seçin. Aşağıdaki URL'yi kopyalayıp yapıştırın. Bu URL, az önce derlediğiniz işlem hattına yönlendirir. (Cloud Shell'den dosya yüklemek için birkaç ek adım gerekir. Bu nedenle, kısa yolu kullanıyoruz.)
İşlem hattına bir ad verin (ör. gh_summ).

Ardışık düzeni çalıştırma
Listede yüklenen işlem hattını tıklayın. Bu işlem, işlem hattının statik grafiğini görüntülemenizi sağlar. Ardından, işlem hattını kullanarak yeni bir deneme oluşturmak için Deneme oluştur'u tıklayın. Deneme, semantik olarak ilişkili çalıştırmaları birlikte gruplandırmanın bir yoludur.

Denemeye bir ad verin (ör. işlem hattıyla aynı ad, gh_summ) ve oluşturmak için İleri'yi tıklayın.

Bu işlem, bir çalıştırma için parametreleri girebileceğiniz ve çalıştırmayı başlatabileceğiniz bir sayfayı açar.
Parametreleri doldurmaya yardımcı olması için Cloud Shell'de aşağıdaki komutları yürütmek isteyebilirsiniz.
gcloud config get-value project
echo "gs://${BUCKET_NAME}/codelab"
Çalıştırma adı otomatik olarak doldurulur ancak isterseniz farklı bir ad verebilirsiniz.
Ardından üç parametre alanını doldurun:
project- (isteğe bağlı)
github-token working-dir
Çalışma dizini için oluşturduğunuz GCS paketinin altında bir yol girin. "gs://" önekini ekleyin. github-token alanı için, daha önce isteğe bağlı olarak oluşturduğunuz jetonu girin veya jeton oluşturmadıysanız yer tutucu dizesini olduğu gibi bırakın.
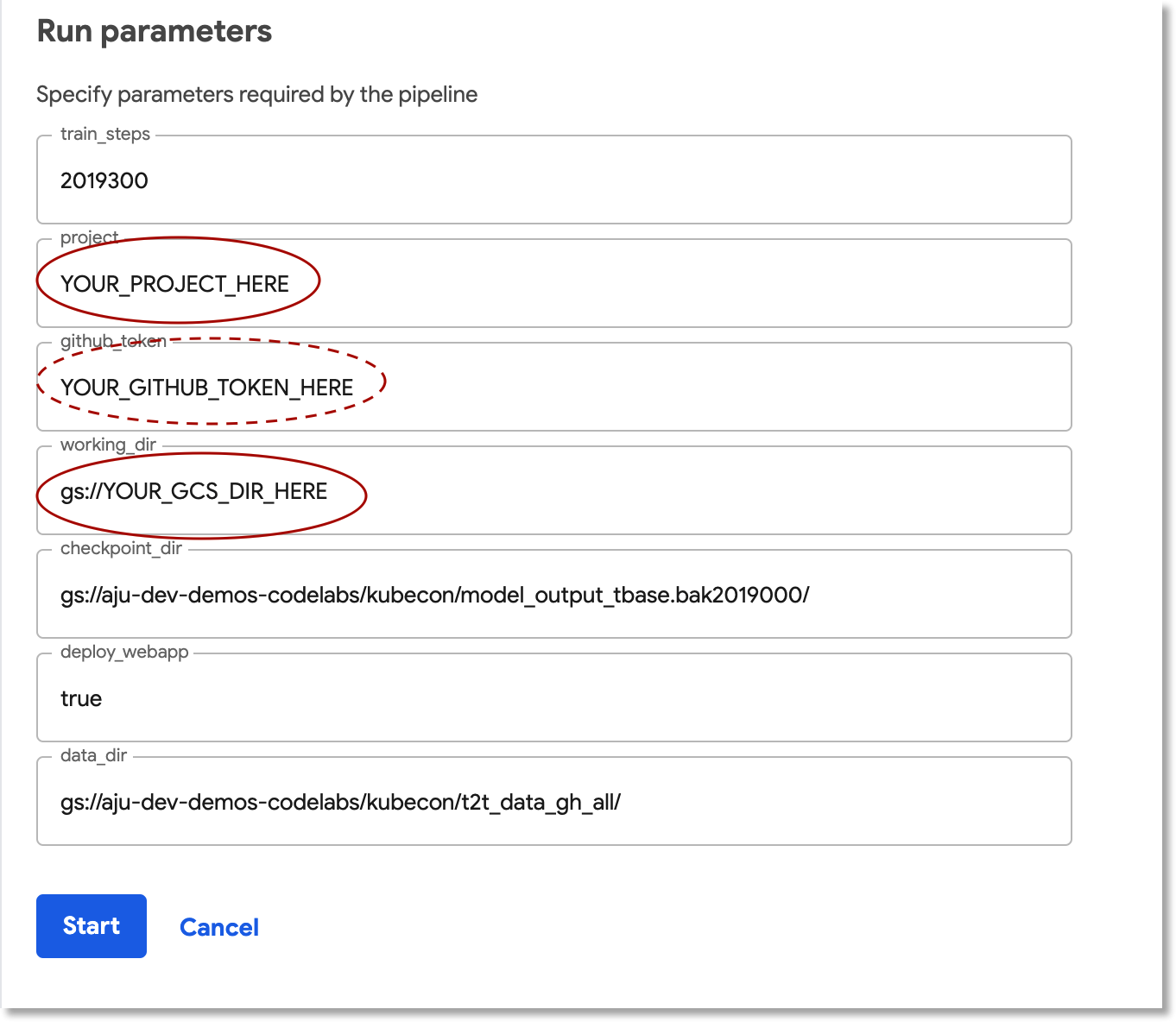
Alanları doldurduktan sonra Başlat'ı tıklayın, ardından listelenen çalıştırmayı tıklayarak ayrıntılarını görüntüleyin. Belirli bir ardışık düzen adımı çalışırken bu adımı tıklayarak pod günlüklerini görüntüleme de dahil olmak üzere daha fazla bilgi edinebilirsiniz. (Küme düğümü kapatılmış olsa bile bir işlem hattı adımının günlüklerini, Cloud Logging (Stackdriver) günlüklerine giden bağlantı üzerinden de görüntüleyebilirsiniz.)

İşlem hattı tanımını görüntüleme
İşlem hattı çalışırken nasıl oluşturulduğunu ve ne yaptığını daha yakından inceleyebilirsiniz. Codelab'in Ekler bölümünde daha ayrıntılı bilgi verilmektedir.
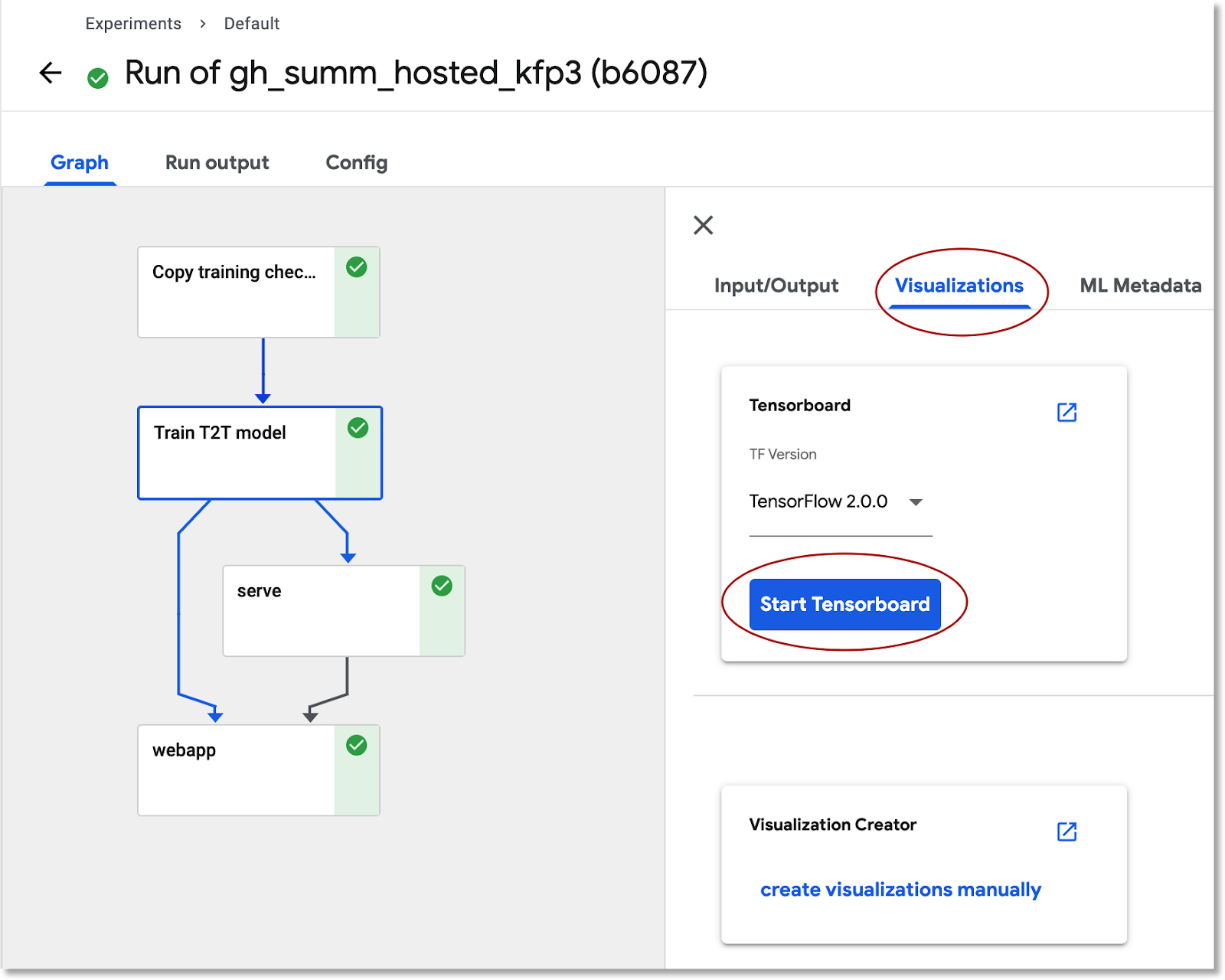
TensorBoard'da model eğitimi bilgilerini görüntüleme
Eğitim adımı tamamlandıktan sonra bu adımın Görselleştirmeler sekmesini seçin, mavi TensorBoard'u Başlat düğmesini tıklayın, hazır olduğunda ise TensorBoard'u Aç'ı tıklayın.

Artifacts and Executions (Yapılar ve Yürütmeler) kontrol panelini keşfedin
Kubeflow Pipelines, bir ardışık düzen yürütülürken ardışık düzen adımlarıyla ilgili meta verileri otomatik olarak günlüğe kaydeder. Hem Artifact hem de Execution bilgileri kaydedilir. Daha fazla bilgi edinmek için gösterge tablosunun sol gezinme çubuğundaki bu girişleri tıklayın.

Artifacts için hem genel bakış panelini hem de Lineage Explorer panelini görüntüleyebilirsiniz.


Ardışık düzen tarafından oluşturulan web uygulamasını açma ve bazı tahminlerde bulunma
Ardışık düzenin son adımında, eğitilmiş modele sorgu göndermek için bir kullanıcı arayüzü sağlayan bir web uygulaması dağıtılır. Bu uygulama, TF Serving aracılığıyla sunulan tahminler oluşturur.
İşlem hattı tamamlandıktan sonra, hizmetine bağlantı noktası yönlendirme yaparak web uygulamasına bağlanın (Bu codelab'de web uygulaması hizmeti harici bir uç nokta içerecek şekilde ayarlanmadığı için bağlantı noktası yönlendirme yapıyoruz).
Cloud Shell'de şu komutu çalıştırarak hizmet adını bulun:
kubectl get services
Listede ghsumm-*-webappsvc gibi bir hizmet adı arayın.
Ardından, Cloud Shell'de bu hizmete aşağıdaki gibi bağlantı noktası yönlendirmesi yapın. Aşağıdaki komutu, webappsvc'nizin adını kullanacak şekilde değiştirin:
kubectl port-forward svc/ghsumm-xxxxx-webappsvc 8080:80
Bağlantı noktası yönlendirme işlemi çalıştıktan sonra Cloud Shell bölmesinin üzerindeki "önizleme" simgesini tıklayın ve açılır listede "8080 numaralı bağlantı noktasında önizle"yi tıklayın.

Yeni sekmede aşağıdaki gibi bir sayfa açılır:

Bir metin bloğunu almak için Rastgele Sorun Doldur düğmesini tıklayın. Eğitilmiş modeli çağırmak ve bir tahmin görüntülemek için Başlık Oluştur'u tıklayın.

Ardışık düzen parametrelerinizde geçerli bir GitHub jetonu varsa alternatif olarak ikinci alana bir GitHub URL'si girip "Başlık Oluştur"u tıklamayı deneyebilirsiniz. Geçerli bir GitHub jetonu ayarlamadıysanız yalnızca "Rastgele Sorun Doldur" alanını kullanın.
4. AI Platform Notebooks'tan ardışık düzen çalıştırma
Ayrıca, KFP SDK'yı kullanarak Kubeflow Pipelines'ı Jupyter not defterinden etkileşimli olarak tanımlayıp çalıştırabilirsiniz. Bu codelab'de kullanacağımız AI Platform Notebooks, bu işlemi çok kolay hale getirir.
Not defteri örneği oluşturma
API'sini kullanarak Cloud Shell'den bir not defteri örneği oluşturacağız. (Alternatif olarak, Cloud Console üzerinden de not defteri oluşturabilirsiniz. Daha fazla bilgi için dokümanları inceleyin.
Cloud Shell'de aşağıdaki ortam değişkenlerini ayarlayın:
export INSTANCE_NAME="kfp-ghsumm" export VM_IMAGE_PROJECT="deeplearning-platform-release" export VM_IMAGE_FAMILY="tf2-2-3-cpu" export MACHINE_TYPE="n1-standard-4" export LOCATION="us-central1-c"
Ardından, Cloud Shell'den not defteri örneğini oluşturma komutunu çalıştırın:
gcloud beta notebooks instances create $INSTANCE_NAME \ --vm-image-project=$VM_IMAGE_PROJECT \ --vm-image-family=$VM_IMAGE_FAMILY \ --machine-type=$MACHINE_TYPE --location=$LOCATION
Bu komutu ilk kez çalıştırdığınızda projeniz için notebooks API'yi etkinleştirmeniz istenebilir. Yanıtınız evet ise "y" yazın.
Birkaç dakika sonra not defteri sunucunuz çalışır duruma gelir. Not defteri örneklerinizin Cloud Console'da listelendiğini görebilirsiniz.

Codelab not defterini yükleme
Not defteri örneği oluşturulduktan sonra, codelab'in Jupyter not defterini yüklemek için bu bağlantıyı tıklayın. Kullanılacak not defteri örneğini seçin. Not defteri otomatik olarak açılır.
Not defterini yürütme
Laboratuvarın geri kalanında not defterindeki talimatları uygulayın. Not defterinin "Kurulum" bölümünde, not defterinin geri kalanını çalıştırmadan önce kendi değerlerinizi girmeniz gerekir.
(Kendi projenizi kullanıyorsanız bu laboratuvarın "Temizleme" bölümüne dönüp bu bölümü yapmayı unutmayın.)
5. Temizleme
Geçici bir codelab hesabı kullanıyorsanız bunu yapmanız gerekmez ancak kendi projenizi kullanıyorsanız Pipelines yüklemenizi ve not defterinizi kaldırmak isteyebilirsiniz.
Pipelines GKE kümesini kapatma
Ardışık düzenler kümesini Cloud Console'dan silebilirsiniz. (GKE kümesini yeniden kullanmak istiyorsanız yalnızca Pipelines yüklemesini silebilirsiniz.)
AI Notebook örneğini silme
Codelab'in "Notebook" bölümünü çalıştırdıysanız Cloud Console'dan not defteri örneğini SİLEBİLİR veya DURDURABİLİRSİNİZ.
İsteğe bağlı: GitHub jetonunu kaldırma
https://github.com/settings/tokens adresine gidin ve oluşturulan jetonu kaldırın.
6. Ekler
Koda göz atma
Ardışık düzeni tanımlama
Bu codelab'de kullanılan işlem hattı burada tanımlanmıştır.
Bu metriğin nasıl tanımlandığına ve bileşenlerinin (adımlarının) nasıl tanımlandığına göz atalım. Bazı önemli noktaları ele alacağız ancak daha fazla ayrıntı için belgeleri inceleyin.
Kubeflow ardışık düzeni adımları container tabanlıdır. Bir işlem hattı oluştururken, önceden oluşturulmuş container görüntüleriyle önceden oluşturulmuş bileşenleri kullanabilir veya kendi bileşenlerinizi oluşturabilirsiniz. Bu codelab için kendi kodumuzu oluşturduk.
Dört işlem hattı adımı, bileşen tanımlama dosyaları aracılığıyla erişilen yeniden kullanılabilir bileşenlerden tanımlanır. Bu ilk kod snippet'inde, bu bileşen tanımı dosyalarına URL'leri üzerinden erişiyoruz ve bu tanımları, bir işlem hattı adımı oluşturmak için kullanacağımız "işlemler" oluşturmak üzere kullanıyoruz.
import kfp.dsl as dsl
import kfp.gcp as gcp
import kfp.components as comp
...
copydata_op = comp.load_component_from_url(
'https://raw.githubusercontent.com/kubeflow/examples/master/github_issue_summarization/pipelines/components/t2t/datacopy_component.yaml'
)
train_op = comp.load_component_from_url(
'https://raw.githubusercontent.com/kubeflow/examples/master/github_issue_summarization/pipelines/components/t2t/train_component.yaml'
)
Aşağıda, eğitim işlemi için bileşen tanımlarından biri yaml biçiminde verilmiştir. Girişlerinin, çıkışlarının, container görüntüsünün ve container giriş noktası bağımsız değişkenlerinin tanımlandığını görebilirsiniz.
name: Train T2T model
description: |
A Kubeflow Pipeline component to train a Tensor2Tensor
model
metadata:
labels:
add-pod-env: 'true'
inputs:
- name: train_steps
description: '...'
type: Integer
default: 2019300
- name: data_dir
description: '...'
type: GCSPath
- name: model_dir
description: '...'
type: GCSPath
- name: action
description: '...'
type: String
- name: deploy_webapp
description: '...'
type: String
outputs:
- name: launch_server
description: '...'
type: String
- name: train_output_path
description: '...'
type: GCSPath
- name: MLPipeline UI metadata
type: UI metadata
implementation:
container:
image: gcr.io/google-samples/ml-pipeline-t2ttrain:v3ap
args: [
--data-dir, {inputValue: data_dir},
--action, {inputValue: action},
--model-dir, {inputValue: model_dir},
--train-steps, {inputValue: train_steps},
--deploy-webapp, {inputValue: deploy_webapp},
--train-output-path, {outputPath: train_output_path}
]
env:
KFP_POD_NAME: "{{pod.name}}"
fileOutputs:
launch_server: /tmp/output
MLPipeline UI metadata: /mlpipeline-ui-metadata.json
Ayrıca, aşağıda göreceğimiz gibi dsl.ContainerOp oluşturucusu aracılığıyla bir işlem hattı adımı da tanımlayabilirsiniz.
Aşağıda, işlem hattı tanımının büyük bir kısmı yer almaktadır. İşlem hattı girişlerini (ve varsayılan değerlerini) tanımlıyoruz. Ardından ardışık düzen adımlarını tanımlarız. Çoğu için yukarıda tanımlanan "işlemler"i kullanıyoruz ancak ContainerOp aracılığıyla satır içi bir "sunma" adımı da tanımlayarak kapsayıcı görüntüsünü ve giriş noktası bağımsız değişkenlerini doğrudan belirtiyoruz.
train, log_model ve serve adımlarının, önceki adımların çıkışlarına giriş olarak eriştiğini görebilirsiniz. Bu durumun nasıl belirtildiği hakkında daha fazla bilgiyi burada bulabilirsiniz.
@dsl.pipeline(
name='Github issue summarization',
description='Demonstrate Tensor2Tensor-based training and TF-Serving'
)
def gh_summ( #pylint: disable=unused-argument
train_steps: 'Integer' = 2019300,
project: str = 'YOUR_PROJECT_HERE',
github_token: str = 'YOUR_GITHUB_TOKEN_HERE',
working_dir: 'GCSPath' = 'gs://YOUR_GCS_DIR_HERE',
checkpoint_dir: 'GCSPath' = 'gs://aju-dev-demos-codelabs/kubecon/model_output_tbase.bak2019000/',
deploy_webapp: str = 'true',
data_dir: 'GCSPath' = 'gs://aju-dev-demos-codelabs/kubecon/t2t_data_gh_all/'
):
copydata = copydata_op(
data_dir=data_dir,
checkpoint_dir=checkpoint_dir,
model_dir='%s/%s/model_output' % (working_dir, dsl.RUN_ID_PLACEHOLDER),
action=COPY_ACTION,
)
train = train_op(
data_dir=data_dir,
model_dir=copydata.outputs['copy_output_path'],
action=TRAIN_ACTION, train_steps=train_steps,
deploy_webapp=deploy_webapp
)
serve = dsl.ContainerOp(
name='serve',
image='gcr.io/google-samples/ml-pipeline-kubeflow-tfserve:v6',
arguments=["--model_name", 'ghsumm-%s' % (dsl.RUN_ID_PLACEHOLDER,),
"--model_path", train.outputs['train_output_path']
]
)
train.set_gpu_limit(1)
"Eğitme" adımının, kümede en az 1 GPU'nun kullanılabildiği bir düğümde çalıştırılması gerektiğini unutmayın.
train.set_gpu_limit(1)
Aynı satırda da tanımlanan işlem hattındaki son adım koşulludur. Yalnızca eğitim adımının launch_server çıkışı "true" dizesi ise "serve" adımı tamamlandıktan sonra çalışır. Eğitilmiş T2T modelinden sorun özetleri istemek için kullandığımız "tahmin web uygulamasını" başlatır.
with dsl.Condition(train.outputs['launch_server'] == 'true'):
webapp = dsl.ContainerOp(
name='webapp',
image='gcr.io/google-samples/ml-pipeline-webapp-launcher:v1',
arguments=["--model_name", 'ghsumm-%s' % (dsl.RUN_ID_PLACEHOLDER,),
"--github_token", github_token]
)
webapp.after(serve)
Bileşen kapsayıcı görüntüsü tanımları
Kubeflow Pipeline belgelerinde, kendi bileşenlerinizi oluşturmayla ilgili bazı en iyi uygulamalar açıklanmaktadır. Bu süreç kapsamında bir container görüntüsü tanımlamanız ve oluşturmanız gerekir. Bu codelab'in işlem hattındaki bileşen adımlarını burada görebilirsiniz. Dockerfile tanımları containers alt dizinlerindedir (ör. burada).
Eğitim için GPU'lu öncelikli sanal makineleri kullanma
Öncelikli sanal makineler, en fazla 24 saat süren ve kullanılabilirlik garantisi sağlamayan Compute Engine VM örnekleridir. Öncelikli sanal makinelerin fiyatı, standart Compute Engine sanal makinelerinin fiyatından daha düşüktür.
Google Kubernetes Engine (GKE) ile öncelikli olarak sonlandırılabilen VM'leri kullanan bir küme veya düğüm havuzu oluşturmak kolaydır. Bu tür bir düğüm havuzunu öncelikli örneklere bağlı GPU'larla oluşturabilirsiniz. Bunlar, normal GPU özellikli düğümlerle aynı şekilde çalışır ancak GPU'lar yalnızca örnek ömrü boyunca kalıcı olur.
Aşağıdakine benzer bir komut çalıştırarak, aşağıdaki komutu küme adınız ve bölgenizle düzenleyerek ve hızlandırıcı türünü ve sayısını gereksinimlerinize göre ayarlayarak kümeniz için öncelikli, GPU özellikli bir düğüm havuzu oluşturabilirsiniz. İsteğe bağlı olarak, düğüm havuzunu mevcut iş yüklerine göre otomatik ölçeklenecek şekilde tanımlayabilirsiniz.
gcloud container node-pools create preemptible-gpu-pool \
--cluster=<your-cluster-name> \
--zone <your-cluster-zone> \
--enable-autoscaling --max-nodes=4 --min-nodes=0 \
--machine-type n1-highmem-8 \
--preemptible \
--node-taints=preemptible=true:NoSchedule \
--scopes cloud-platform --verbosity error \
--accelerator=type=nvidia-tesla-k80,count=4
Ayrıca Cloud Console üzerinden de bir düğüm havuzu oluşturabilirsiniz.
Öncelikli GKE düğümlerini kullanan bir Kubeflow ardışık düzeni tanımlama
Kubeflow'u GKE'de çalıştırıyorsanız artık bir veya daha fazla ardışık düzen adımının (bileşen) öncelikli düğümlerde çalıştırıldığı Kubeflow ardışık düzenlerini tanımlayıp çalıştırmak kolaydır. Bu sayede iş çalıştırma maliyeti düşer. Öncelikli sanal makinelerin doğru sonuçlar vermesi için öncelikli olarak tanımladığınız adımlar idempotent olmalıdır (yani bir adımı birden çok kez çalıştırdığınızda aynı sonuç elde edilir) veya kesintiye uğraması durumunda kaldığı yerden devam edebilmesi için çalışmayı kontrol noktasına almalıdır.
Kubeflow Pipeline tanımlarken, belirli bir adımın öncelikli olmayan bir düğümde çalışması gerektiğini belirtmek için işlemi şu şekilde değiştirebilirsiniz:
your_pipelines_op.apply(gcp.use_preemptible_nodepool())
Ayrıntılar için belgeleri inceleyin.
Düğüm önceden boşaltılırsa adımı belirli sayıda tekrar denemek de isteyebilirsiniz. Bunu aşağıdaki gibi yapabilirsiniz. Burada 5 yeniden deneme belirtiyoruz.
your_pipelines_op.set_gpu_limit(1).apply(gcp.use_preemptible_nodepool()).set_retry(5)
Bu codelab'de kullandığımız Kubeflow işlem hattını eğitim adımını öncelikli sanal makinede çalıştıracak şekilde düzenlemeyi deneyin.
Aşağıdaki satırı, işlem hattı spesifikasyonunda, öncelikli olmayan bir düğüm havuzunu da kullanacak şekilde değiştirin (yukarıda belirtildiği gibi bir düğüm havuzu oluşturduğunuzdan emin olun) ve 5 kez yeniden deneyin:
train.set_gpu_limit(1)
Ardından, ardışık düzeni yeniden derleyin, yeni sürümü yükleyin (yeni bir ad verin) ve ardışık düzenin yeni sürümünü çalıştırın.