
درباره این codelab
1. نمای کلی

Natural Language API به شما امکان می دهد با استفاده از یادگیری ماشینی Google اطلاعات را از متن بدون ساختار استخراج کنید. در این آموزش، شما بر روی استفاده از کتابخانه کلاینت پایتون آن تمرکز خواهید کرد.
چیزی که یاد خواهید گرفت
- چگونه محیط خود را تنظیم کنیم
- نحوه انجام تحلیل احساسات
- نحوه انجام تجزیه و تحلیل موجودیت
- نحوه انجام تحلیل نحوی
- نحوه انجام طبقه بندی محتوا
- نحوه انجام تعدیل متن
آنچه شما نیاز دارید
نظرسنجی
چگونه از این آموزش استفاده خواهید کرد؟
تجربه خود را با پایتون چگونه ارزیابی می کنید؟
تجربه خود را با خدمات Google Cloud چگونه ارزیابی می کنید؟
2. راه اندازی و الزامات
تنظیم محیط خود به خود
- به Google Cloud Console وارد شوید و یک پروژه جدید ایجاد کنید یا از یک موجود استفاده مجدد کنید. اگر قبلاً یک حساب Gmail یا Google Workspace ندارید، باید یک حساب ایجاد کنید .

- نام پروژه نام نمایشی برای شرکت کنندگان این پروژه است. این یک رشته کاراکتری است که توسط API های Google استفاده نمی شود. همیشه می توانید آن را به روز کنید.
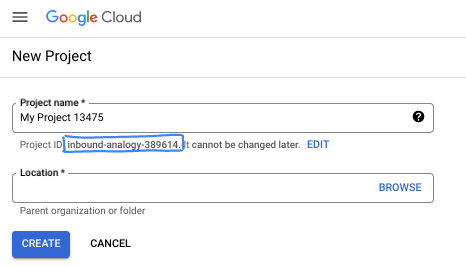
- شناسه پروژه در تمام پروژههای Google Cloud منحصربهفرد است و تغییرناپذیر است (پس از تنظیم نمیتوان آن را تغییر داد). Cloud Console به طور خودکار یک رشته منحصر به فرد تولید می کند. معمولاً برای شما مهم نیست که چیست. در اکثر کدها، باید شناسه پروژه خود را ارجاع دهید (معمولاً با نام
PROJECT_IDشناخته می شود). اگر شناسه تولید شده را دوست ندارید، ممکن است یک شناسه تصادفی دیگر ایجاد کنید. از طرف دیگر، میتوانید خودتان را امتحان کنید، و ببینید آیا در دسترس است یا خیر. پس از این مرحله نمی توان آن را تغییر داد و در طول مدت پروژه باقی می ماند. - برای اطلاع شما، یک مقدار سوم وجود دارد، یک شماره پروژه ، که برخی از API ها از آن استفاده می کنند. در مورد هر سه این مقادیر در مستندات بیشتر بیاموزید.
- در مرحله بعد، برای استفاده از منابع Cloud/APIها باید صورتحساب را در کنسول Cloud فعال کنید . اجرا کردن از طریق این کد لبه هزینه زیادی نخواهد داشت. برای خاموش کردن منابع برای جلوگیری از تحمیل صورتحساب فراتر از این آموزش، میتوانید منابعی را که ایجاد کردهاید حذف کنید یا پروژه را حذف کنید. کاربران جدید Google Cloud واجد شرایط برنامه آزمایشی رایگان 300 دلاری هستند.
Cloud Shell را راه اندازی کنید
در حالی که Google Cloud را می توان از راه دور از لپ تاپ شما کار کرد، در این کد لبه از Cloud Shell استفاده خواهید کرد، یک محیط خط فرمان که در Cloud اجرا می شود.
Cloud Shell را فعال کنید
- از Cloud Console، روی Activate Cloud Shell کلیک کنید
 .
.

اگر این اولین باری است که Cloud Shell را راه اندازی می کنید، با یک صفحه میانی روبرو می شوید که آن را توصیف می کند. اگر با یک صفحه میانی مواجه شدید، روی Continue کلیک کنید.
تهیه و اتصال به Cloud Shell فقط باید چند لحظه طول بکشد.

این ماشین مجازی با تمام ابزارهای توسعه مورد نیاز بارگذاری شده است. این یک فهرست اصلی 5 گیگابایتی دائمی ارائه میکند و در Google Cloud اجرا میشود، که عملکرد و احراز هویت شبکه را بسیار افزایش میدهد. بسیاری از کارهای شما، اگر نه همه، در این کد لبه با مرورگر قابل انجام است.
پس از اتصال به Cloud Shell، باید ببینید که احراز هویت شده اید و پروژه به ID پروژه شما تنظیم شده است.
- برای تایید احراز هویت، دستور زیر را در Cloud Shell اجرا کنید:
gcloud auth list
خروجی فرمان
Credentialed Accounts
ACTIVE ACCOUNT
* <my_account>@<my_domain.com>
To set the active account, run:
$ gcloud config set account `ACCOUNT`
- دستور زیر را در Cloud Shell اجرا کنید تا تأیید کنید که دستور gcloud از پروژه شما اطلاع دارد:
gcloud config list project
خروجی فرمان
[core] project = <PROJECT_ID>
اگر اینطور نیست، می توانید آن را با این دستور تنظیم کنید:
gcloud config set project <PROJECT_ID>
خروجی فرمان
Updated property [core/project].
3. راه اندازی محیط
قبل از شروع استفاده از Natural Language API، دستور زیر را در Cloud Shell اجرا کنید تا API فعال شود:
gcloud services enable language.googleapis.com
شما باید چیزی شبیه به این را ببینید:
Operation "operations/..." finished successfully.
اکنون، می توانید از API زبان طبیعی استفاده کنید!
به فهرست اصلی خود بروید:
cd ~
یک محیط مجازی پایتون برای جداسازی وابستگی ها ایجاد کنید:
virtualenv venv-language
فعال کردن محیط مجازی:
source venv-language/bin/activate
کتابخانه مشتری IPython، Pandas و Natural Language API را نصب کنید:
pip install ipython pandas tabulate google-cloud-language
شما باید چیزی شبیه به این را ببینید:
... Installing collected packages: ... pandas ... ipython ... google-cloud-language Successfully installed ... google-cloud-language-2.11.0 ...
اکنون، شما آماده استفاده از کتابخانه مشتری API زبان طبیعی هستید!
در مراحل بعدی، از یک مفسر تعاملی پایتون به نام IPython استفاده خواهید کرد که در مرحله قبل آن را نصب کردید. یک جلسه را با اجرای ipython در Cloud Shell شروع کنید:
ipython
شما باید چیزی شبیه به این را ببینید:
Python 3.9.2 (default, Feb 28 2021, 17:03:44) Type 'copyright', 'credits' or 'license' for more information IPython 8.15.0 -- An enhanced Interactive Python. Type '?' for help. In [1]:
4. تحلیل احساسات
تحلیل احساسات متن داده شده را بررسی می کند و نظرات عاطفی غالب در متن را شناسایی می کند، به ویژه برای تعیین احساسات ابراز شده به عنوان مثبت، منفی یا خنثی، هم در سطح جمله و هم در سند. با روش analyze_sentiment انجام می شود که AnalyzeSentimentResponse را برمی گرداند.
کد زیر را در جلسه IPython خود کپی کنید:
from google.cloud import language
def analyze_text_sentiment(text: str) -> language.AnalyzeSentimentResponse:
client = language.LanguageServiceClient()
document = language.Document(
content=text,
type_=language.Document.Type.PLAIN_TEXT,
)
return client.analyze_sentiment(document=document)
def show_text_sentiment(response: language.AnalyzeSentimentResponse):
import pandas as pd
columns = ["score", "sentence"]
data = [(s.sentiment.score, s.text.content) for s in response.sentences]
df_sentence = pd.DataFrame(columns=columns, data=data)
sentiment = response.document_sentiment
columns = ["score", "magnitude", "language"]
data = [(sentiment.score, sentiment.magnitude, response.language)]
df_document = pd.DataFrame(columns=columns, data=data)
format_args = dict(index=False, tablefmt="presto", floatfmt="+.1f")
print(f"At sentence level:\n{df_sentence.to_markdown(**format_args)}")
print()
print(f"At document level:\n{df_document.to_markdown(**format_args)}")
تجزیه و تحلیل انجام دهید:
# Input
text = """
Python is a very readable language, which makes it easy to understand and maintain code.
It's simple, very flexible, easy to learn, and suitable for a wide variety of tasks.
One disadvantage is its speed: it's not as fast as some other programming languages.
"""
# Send a request to the API
analyze_sentiment_response = analyze_text_sentiment(text)
# Show the results
show_text_sentiment(analyze_sentiment_response)
شما باید یک خروجی مانند زیر ببینید:
At sentence level:
score | sentence
---------+------------------------------------------------------------------------------------------
+0.8 | Python is a very readable language, which makes it easy to understand and maintain code.
+0.9 | It's simple, very flexible, easy to learn, and suitable for a wide variety of tasks.
-0.4 | One disadvantage is its speed: it's not as fast as some other programming languages.
At document level:
score | magnitude | language
---------+-------------+------------
+0.4 | +2.2 | en
یک لحظه برای آزمایش جملات خود وقت بگذارید.
خلاصه
در این مرحله شما قادر به انجام تحلیل احساسات بر روی یک رشته متن هستید!
5. تجزیه و تحلیل موجودیت
تجزیه و تحلیل موجودیت، متن داده شده را برای موجودیت های شناخته شده (اسم های خاص مانند شخصیت های عمومی، نشانه ها، و غیره) بررسی می کند و اطلاعات مربوط به آن موجودیت ها را برمی گرداند. با متد analyze_entities انجام می شود که یک AnalyzeEntitiesResponse را برمی گرداند.
کد زیر را در جلسه IPython خود کپی کنید:
from google.cloud import language
def analyze_text_entities(text: str) -> language.AnalyzeEntitiesResponse:
client = language.LanguageServiceClient()
document = language.Document(
content=text,
type_=language.Document.Type.PLAIN_TEXT,
)
return client.analyze_entities(document=document)
def show_text_entities(response: language.AnalyzeEntitiesResponse):
import pandas as pd
columns = ("name", "type", "salience", "mid", "wikipedia_url")
data = (
(
entity.name,
entity.type_.name,
entity.salience,
entity.metadata.get("mid", ""),
entity.metadata.get("wikipedia_url", ""),
)
for entity in response.entities
)
df = pd.DataFrame(columns=columns, data=data)
print(df.to_markdown(index=False, tablefmt="presto", floatfmt=".0%"))
تجزیه و تحلیل انجام دهید:
# Input
text = """Guido van Rossum is best known as the creator of Python,
which he named after the Monty Python comedy troupe.
He was born in Haarlem, Netherlands.
"""
# Send a request to the API
analyze_entities_response = analyze_text_entities(text)
# Show the results
show_text_entities(analyze_entities_response)
شما باید یک خروجی مانند زیر ببینید:
name | type | salience | mid | wikipedia_url ------------------+--------------+------------+-----------+------------------------------------------------------------- Guido van Rossum | PERSON | 50% | /m/01h05c | https://en.wikipedia.org/wiki/Guido_van_Rossum Python | ORGANIZATION | 38% | /m/05z1_ | https://en.wikipedia.org/wiki/Python_(programming_language) creator | PERSON | 5% | | Monty Python | PERSON | 3% | /m/04sd0 | https://en.wikipedia.org/wiki/Monty_Python comedy troupe | PERSON | 2% | | Haarlem | LOCATION | 1% | /m/0h095 | https://en.wikipedia.org/wiki/Haarlem Netherlands | LOCATION | 1% | /m/059j2 | https://en.wikipedia.org/wiki/Netherlands
چند لحظه وقت بگذارید و جملات خود را با ذکر موجودیت های دیگر آزمایش کنید.
خلاصه
در این مرحله توانستید آنالیز موجودیت را انجام دهید!
6. تحلیل نحوی
تجزیه و تحلیل نحوی اطلاعات زبانی را استخراج می کند، متن داده شده را به مجموعه ای از جملات و نشانه ها تقسیم می کند (به طور کلی بر اساس مرزهای کلمه)، تجزیه و تحلیل بیشتری را در مورد آن نشانه ها ارائه می دهد. با متد analyze_syntax انجام می شود که AnalyzeSyntaxResponse برمی گرداند.
کد زیر را در جلسه IPython خود کپی کنید:
from typing import Optional
from google.cloud import language
def analyze_text_syntax(text: str) -> language.AnalyzeSyntaxResponse:
client = language.LanguageServiceClient()
document = language.Document(
content=text,
type_=language.Document.Type.PLAIN_TEXT,
)
return client.analyze_syntax(document=document)
def get_token_info(token: Optional[language.Token]) -> list[str]:
parts = [
"tag",
"aspect",
"case",
"form",
"gender",
"mood",
"number",
"person",
"proper",
"reciprocity",
"tense",
"voice",
]
if not token:
return ["token", "lemma"] + parts
text = token.text.content
lemma = token.lemma if token.lemma != token.text.content else ""
info = [text, lemma]
for part in parts:
pos = token.part_of_speech
info.append(getattr(pos, part).name if part in pos else "")
return info
def show_text_syntax(response: language.AnalyzeSyntaxResponse):
import pandas as pd
tokens = len(response.tokens)
sentences = len(response.sentences)
columns = get_token_info(None)
data = (get_token_info(token) for token in response.tokens)
df = pd.DataFrame(columns=columns, data=data)
# Remove empty columns
empty_columns = [col for col in df if df[col].eq("").all()]
df.drop(empty_columns, axis=1, inplace=True)
print(f"Analyzed {tokens} token(s) from {sentences} sentence(s):")
print(df.to_markdown(index=False, tablefmt="presto"))
تجزیه و تحلیل انجام دهید:
# Input
text = """Guido van Rossum is best known as the creator of Python.
He was born in Haarlem, Netherlands.
"""
# Send a request to the API
analyze_syntax_response = analyze_text_syntax(text)
# Show the results
show_text_syntax(analyze_syntax_response)
شما باید یک خروجی مانند زیر ببینید:
Analyzed 20 token(s) from 2 sentence(s): token | lemma | tag | case | gender | mood | number | person | proper | tense | voice -------------+---------+-------+------------+-----------+------------+----------+----------+----------+---------+--------- Guido | | NOUN | | | | SINGULAR | | PROPER | | van | | NOUN | | | | SINGULAR | | PROPER | | Rossum | | NOUN | | | | SINGULAR | | PROPER | | is | be | VERB | | | INDICATIVE | SINGULAR | THIRD | | PRESENT | best | well | ADV | | | | | | | | known | know | VERB | | | | | | | PAST | as | | ADP | | | | | | | | the | | DET | | | | | | | | creator | | NOUN | | | | SINGULAR | | | | of | | ADP | | | | | | | | Python | | NOUN | | | | SINGULAR | | PROPER | | . | | PUNCT | | | | | | | | He | | PRON | NOMINATIVE | MASCULINE | | SINGULAR | THIRD | | | was | be | VERB | | | INDICATIVE | SINGULAR | THIRD | | PAST | born | bear | VERB | | | | | | | PAST | PASSIVE in | | ADP | | | | | | | | Haarlem | | NOUN | | | | SINGULAR | | PROPER | | , | | PUNCT | | | | | | | | Netherlands | | NOUN | | | | SINGULAR | | PROPER | | . | | PUNCT | | | | | | | |
چند لحظه وقت بگذارید و جملات خود را با سایر ساختارهای نحوی آزمایش کنید.
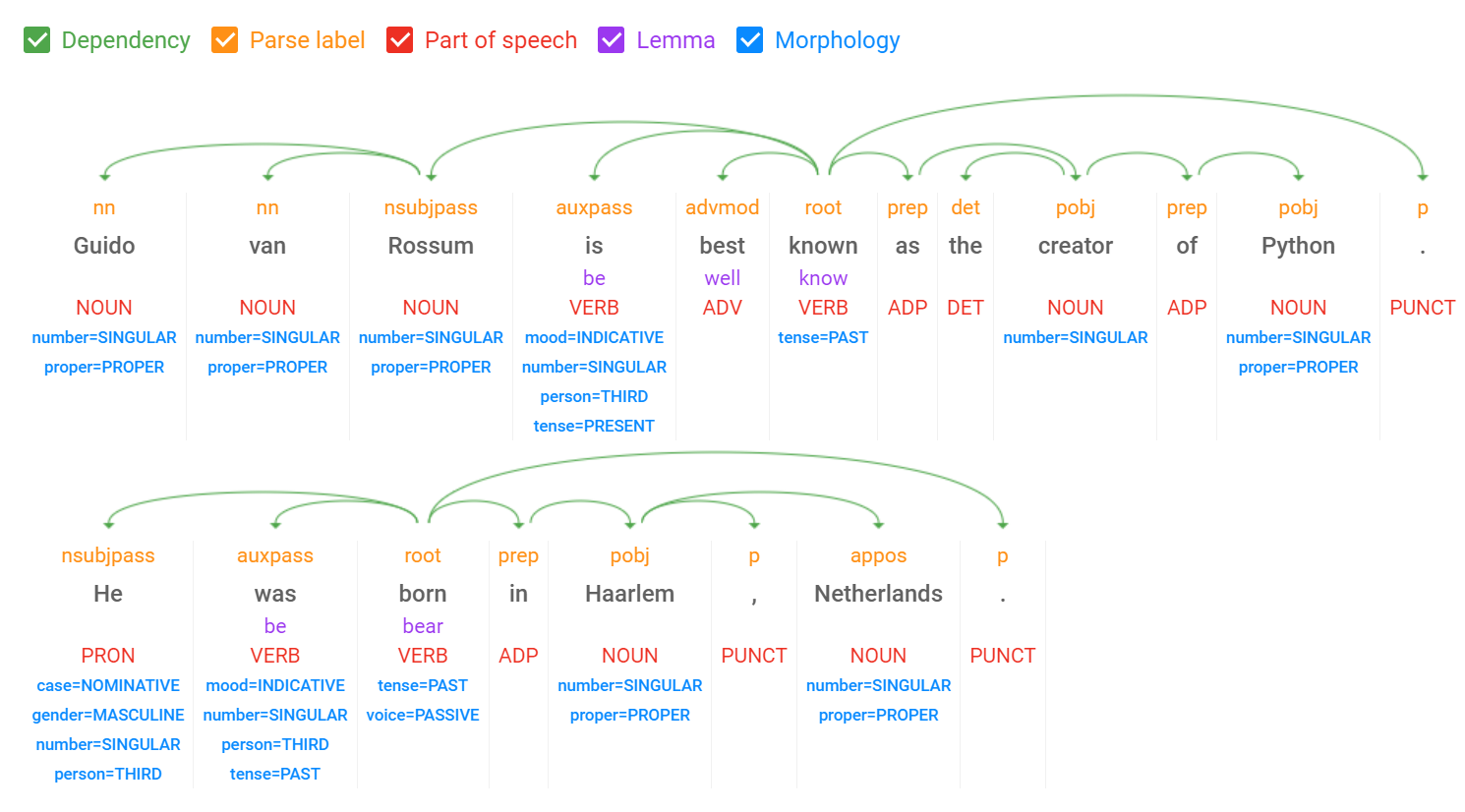
اگر عمیقتر در بینشهای پاسخ فرو بروید، روابط بین نشانهها را نیز خواهید یافت. در اینجا یک تفسیر بصری است که تجزیه و تحلیل کامل نحوی را برای این مثال نشان می دهد، یک اسکرین شات از نسخه نمایشی زبان طبیعی آنلاین:
خلاصه
در این مرحله توانستید آنالیز سینتکس را انجام دهید!
7. طبقه بندی محتوا
طبقهبندی محتوا یک سند را تجزیه و تحلیل میکند و فهرستی از دستهبندیهای محتوا را که برای متن یافت شده در سند اعمال میشود، برمیگرداند. با متد classify_text انجام می شود که یک ClassifyTextResponse برمی گرداند.
کد زیر را در جلسه IPython خود کپی کنید:
from google.cloud import language
def classify_text(text: str) -> language.ClassifyTextResponse:
client = language.LanguageServiceClient()
document = language.Document(
content=text,
type_=language.Document.Type.PLAIN_TEXT,
)
return client.classify_text(document=document)
def show_text_classification(text: str, response: language.ClassifyTextResponse):
import pandas as pd
columns = ["category", "confidence"]
data = ((category.name, category.confidence) for category in response.categories)
df = pd.DataFrame(columns=columns, data=data)
print(f"Text analyzed:\n{text}")
print(df.to_markdown(index=False, tablefmt="presto", floatfmt=".0%"))
تجزیه و تحلیل انجام دهید:
# Input
text = """Python is an interpreted, high-level, general-purpose programming language.
Created by Guido van Rossum and first released in 1991, Python's design philosophy
emphasizes code readability with its notable use of significant whitespace.
"""
# Send a request to the API
classify_text_response = classify_text(text)
# Show the results
show_text_classification(text, classify_text_response)
شما باید یک خروجی مانند زیر ببینید:
Text analyzed: Python is an interpreted, high-level, general-purpose programming language. Created by Guido van Rossum and first released in 1991, Python's design philosophy emphasizes code readability with its notable use of significant whitespace. category | confidence --------------------------------------+-------------- /Computers & Electronics/Programming | 99% /Science/Computer Science | 99%
چند لحظه وقت بگذارید و جملات خود را در رابطه با مقوله های دیگر آزمایش کنید. توجه داشته باشید که باید یک بلوک متنی (سند) با حداقل بیست نشانه (کلمات و علائم نقطه گذاری) تهیه کنید.
خلاصه
در این مرحله توانستید طبقه بندی محتوا را انجام دهید!
8. تعدیل متن
با استفاده از آخرین مدل پایه Google PalM 2 ، تعدیل متن طیف وسیعی از محتوای مضر را شناسایی میکند، از جمله سخنان مشوق عداوت، قلدری، و آزار جنسی. با متد moderate_text انجام می شود که یک ModerateTextResponse برمی گرداند.
کد زیر را در جلسه IPython خود کپی کنید:
from google.cloud import language
def moderate_text(text: str) -> language.ModerateTextResponse:
client = language.LanguageServiceClient()
document = language.Document(
content=text,
type_=language.Document.Type.PLAIN_TEXT,
)
return client.moderate_text(document=document)
def show_text_moderation(text: str, response: language.ModerateTextResponse):
import pandas as pd
def confidence(category: language.ClassificationCategory) -> float:
return category.confidence
columns = ["category", "confidence"]
categories = sorted(response.moderation_categories, key=confidence, reverse=True)
data = ((category.name, category.confidence) for category in categories)
df = pd.DataFrame(columns=columns, data=data)
print(f"Text analyzed:\n{text}")
print(df.to_markdown(index=False, tablefmt="presto", floatfmt=".0%"))
تجزیه و تحلیل انجام دهید:
# Input
text = """I have to read Ulysses by James Joyce.
I'm a little over halfway through and I hate it.
What a pile of garbage!
"""
# Send a request to the API
response = moderate_text(text)
# Show the results
show_text_moderation(text, response)
شما باید یک خروجی مانند زیر ببینید:
Text analyzed: I have to read Ulysses by James Joyce. I'm a little over halfway through and I hate it. What a pile of garbage! category | confidence -----------------------+-------------- Toxic | 67% Insult | 58% Profanity | 53% Violent | 48% Illicit Drugs | 29% Religion & Belief | 27% Politics | 22% Death, Harm & Tragedy | 21% Finance | 18% Derogatory | 14% Firearms & Weapons | 11% Health | 10% Legal | 10% War & Conflict | 7% Public Safety | 5% Sexual | 4%
یک لحظه برای آزمایش جملات خود وقت بگذارید.
خلاصه
در این مرحله توانستید تعدیل متن را انجام دهید!
9. تبریک می گویم!
شما یاد گرفتید که چگونه از API زبان طبیعی با استفاده از پایتون استفاده کنید!
پاک کن
برای پاکسازی محیط توسعه خود، از Cloud Shell:
- اگر هنوز در جلسه IPython خود هستید، به پوسته برگردید:
exit - استفاده از محیط مجازی پایتون را متوقف کنید:
deactivate - پوشه محیط مجازی خود را حذف کنید:
cd ~ ; rm -rf ./venv-language
برای حذف پروژه Google Cloud خود از Cloud Shell:
- شناسه پروژه فعلی خود را بازیابی کنید:
PROJECT_ID=$(gcloud config get-value core/project) - مطمئن شوید که این پروژه ای است که می خواهید حذف کنید:
echo $PROJECT_ID - پروژه را حذف کنید:
gcloud projects delete $PROJECT_ID
بیشتر بدانید
- نسخه ی نمایشی را در مرورگر خود آزمایش کنید: https://cloud.google.com/natural-language#natural-language-api-demo
- مستندات زبان طبیعی: https://cloud.google.com/natural-language/docs
- پایتون در Google Cloud: https://cloud.google.com/python
- کتابخانه های کلاود کلاینت برای پایتون: https://github.com/googleapis/google-cloud-python
مجوز
این اثر تحت مجوز Creative Commons Attribution 2.0 Generic مجوز دارد.