
1. Présentation
Dans le premier atelier de programmation, vous allez stocker des photos dans un bucket. Un événement de création de fichier est alors généré et géré par un service déployé dans Cloud Run. Le service appellera l'API Vision pour analyser l'image et enregistrer les résultats dans un datastore.

Points abordés
- Cloud Storage
- Cloud Run
- API Cloud Vision
- Cloud Firestore
2. Préparation
Configuration de l'environnement au rythme de chacun
- Connectez-vous à la console Google Cloud, puis créez un projet ou réutilisez un projet existant. (Si vous ne possédez pas encore de compte Gmail ou Google Workspace, vous devez en créer un.)



- Le nom du projet est le nom à afficher pour les participants au projet. Il s'agit d'une chaîne de caractères non utilisée par les API Google. Vous pouvez le modifier à tout moment.
- L'ID du projet doit être unique sur l'ensemble des projets Google Cloud et doit être immuable (vous ne pouvez pas le modifier une fois que vous l'avez défini). La console Cloud génère automatiquement une chaîne unique (en général, vous n'y accordez d'importance particulière). Dans la plupart des ateliers de programmation, vous devrez indiquer l'ID du projet (généralement identifié par
PROJECT_ID). Si l'ID généré ne vous convient pas, vous pouvez en générer un autre de manière aléatoire. Vous pouvez également en spécifier un et voir s'il est disponible. Après cette étape, l'ID n'est plus modifiable et restera donc le même pour toute la durée du projet. - Pour information, il existe une troisième valeur (le numéro de projet) que certaines API utilisent. Pour en savoir plus sur ces trois valeurs, consultez la documentation.
- Vous devez ensuite activer la facturation dans la console Cloud pour utiliser les ressources/API Cloud. L'exécution de cet atelier de programmation est très peu coûteuse, voire sans frais. Pour désactiver les ressources et éviter ainsi que des frais ne vous soient facturés après ce tutoriel, vous pouvez supprimer le projet ou les ressources que vous avez créées. Les nouveaux utilisateurs de Google Cloud peuvent participer au programme d'essai sans frais pour bénéficier d'un crédit de 300$.
Démarrer Cloud Shell
Bien que Google Cloud puisse être utilisé à distance depuis votre ordinateur portable, nous allons nous servir de Google Cloud Shell pour cet atelier de programmation, un environnement de ligne de commande exécuté dans le cloud.
Dans la console Google Cloud, cliquez sur l'icône Cloud Shell dans la barre d'outils supérieure :

Le provisionnement et la connexion à l'environnement prennent quelques instants seulement. Une fois l'opération terminée, le résultat devrait ressembler à ceci :

Cette machine virtuelle contient tous les outils de développement nécessaires. Elle comprend un répertoire d'accueil persistant de 5 Go et s'exécute sur Google Cloud, ce qui améliore nettement les performances du réseau et l'authentification. Vous pouvez effectuer toutes les tâches de cet atelier de programmation dans un navigateur. Vous n'avez rien à installer.
3. Activer les API
Pour cet atelier, vous allez utiliser Cloud Functions et l'API Vision. Vous devez d'abord les activer dans la console Cloud ou avec gcloud.
Pour activer l'API Vision dans la console Cloud, recherchez Cloud Vision API dans la barre de recherche :

Vous êtes redirigé vers la page de l'API Cloud Vision :

Cliquez sur le bouton ENABLE.
Vous pouvez également l'activer dans Cloud Shell à l'aide de l'outil de ligne de commande gcloud.
Dans Cloud Shell, exécutez la commande suivante :
gcloud services enable vision.googleapis.com
L'opération devrait se terminer correctement :
Operation "operations/acf.12dba18b-106f-4fd2-942d-fea80ecc5c1c" finished successfully.
Activez également Cloud Run et Cloud Build :
gcloud services enable cloudbuild.googleapis.com \ run.googleapis.com
4. Créer le bucket (console)
Créez un bucket de stockage pour les photos. Vous pouvez le faire à partir de la console Google Cloud Platform ( console.cloud.google.com) ou avec l'outil de ligne de commande gsutil depuis Cloud Shell ou votre environnement de développement local.
Accéder à Storage
Dans le menu hamburger (☰), accédez à la page Storage.

Attribuez un nom au bucket
Cliquez sur le bouton CREATE BUCKET.

Cliquez sur CONTINUE.
Choisir un lieu

Créez un bucket multirégional dans la région de votre choix (ici Europe).
Cliquez sur CONTINUE.
Sélectionner la classe de stockage par défaut

Choisissez la classe de stockage Standard pour vos données.
Cliquez sur CONTINUE.
Définir le contrôle des accès

Comme vous allez travailler avec des images accessibles au public, vous souhaitez que toutes les images stockées dans ce bucket disposent du même contrôle d'accès uniforme.
Choisissez l'option de contrôle des accès Uniform.
Cliquez sur CONTINUE.
Définir la protection/le chiffrement

Conservez la valeur par défaut (Google-managed key)), car vous n'utiliserez pas vos propres clés de chiffrement.
Cliquez sur CREATE pour finaliser la création du bucket.
Ajouter allUsers en tant que lecteur de stockage
Accédez à l'onglet Permissions :

Ajoutez un membre allUsers au bucket, avec le rôle Storage > Storage Object Viewer, comme suit :

Cliquez sur SAVE.
5. Créer le bucket (gsutil)
Vous pouvez également utiliser l'outil de ligne de commande gsutil dans Cloud Shell pour créer des buckets.
Dans Cloud Shell, définissez une variable pour le nom unique du bucket. Cloud Shell a déjà défini GOOGLE_CLOUD_PROJECT sur votre ID de projet unique. Vous pouvez l'ajouter au nom du bucket.
Exemple :
export BUCKET_PICTURES=uploaded-pictures-${GOOGLE_CLOUD_PROJECT}
Créez une zone multirégionale standard en Europe :
gsutil mb -l EU gs://${BUCKET_PICTURES}
Assurez-vous que l'accès uniforme au niveau du bucket est activé :
gsutil uniformbucketlevelaccess set on gs://${BUCKET_PICTURES}
Rendez le bucket public :
gsutil iam ch allUsers:objectViewer gs://${BUCKET_PICTURES}
Si vous accédez à la section Cloud Storage de la console, vous devriez disposer d'un bucket uploaded-pictures public :

Vérifiez que vous pouvez importer des photos dans le bucket et qu'elles sont accessibles au public, comme expliqué à l'étape précédente.
6. Tester l'accès public au bucket
Si vous revenez au navigateur de stockage, vous verrez votre bucket dans la liste, avec un accès "Public " (y compris un panneau d'avertissement vous rappelant que tout le monde a accès au contenu de ce bucket).

Votre bucket est désormais prêt à recevoir des photos.
Si vous cliquez sur le nom du bucket, vous verrez ses détails.
Vous pouvez y essayer le bouton Upload files pour vérifier que vous pouvez ajouter une image au bucket. Un pop-up de sélection de fichier vous demandera de sélectionner un fichier. Une fois sélectionné, il sera importé dans votre bucket et vous verrez à nouveau l'public qui a été automatiquement attribué à ce nouveau fichier.
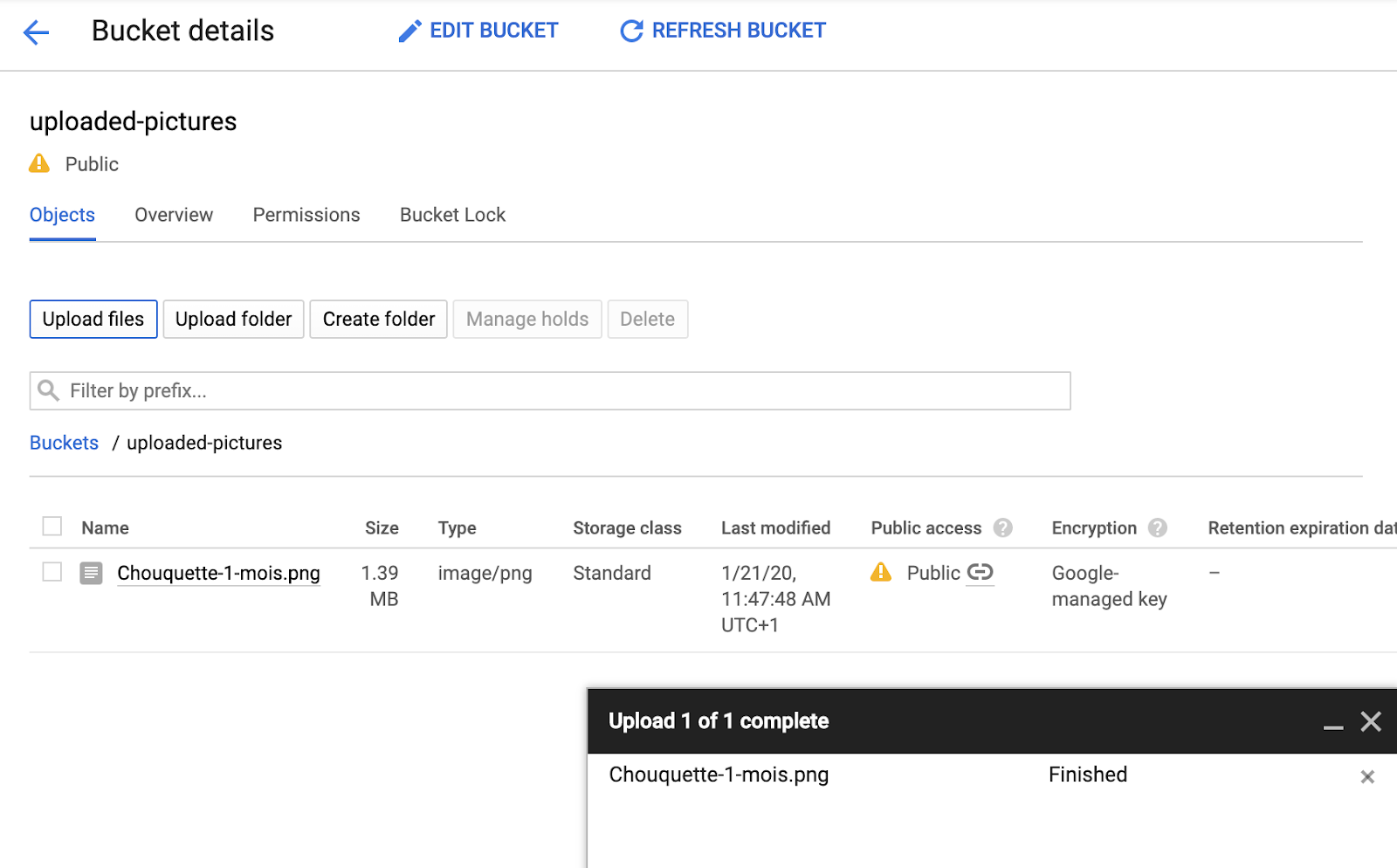
À côté du libellé d'accès Public, vous verrez également une petite icône en forme de lien. Lorsque vous cliquez dessus, votre navigateur accède à l'URL publique de cette image, qui se présente sous la forme suivante :
https://storage.googleapis.com/BUCKET_NAME/PICTURE_FILE.png
BUCKET_NAME étant le nom unique que vous avez choisi pour votre bucket, suivi du nom de fichier de votre image.
Cochez la case à côté du nom de l'image pour activer le bouton DELETE, puis supprimez cette première image.
7. Préparer la base de données
Vous allez stocker les informations sur l'image fournies par l'API Vision dans la base de données Cloud Firestore, une base de données de documents NoSQL sans serveur, cloud native, entièrement gérée et rapide. Préparez votre base de données en accédant à la section Firestore de la console Cloud :
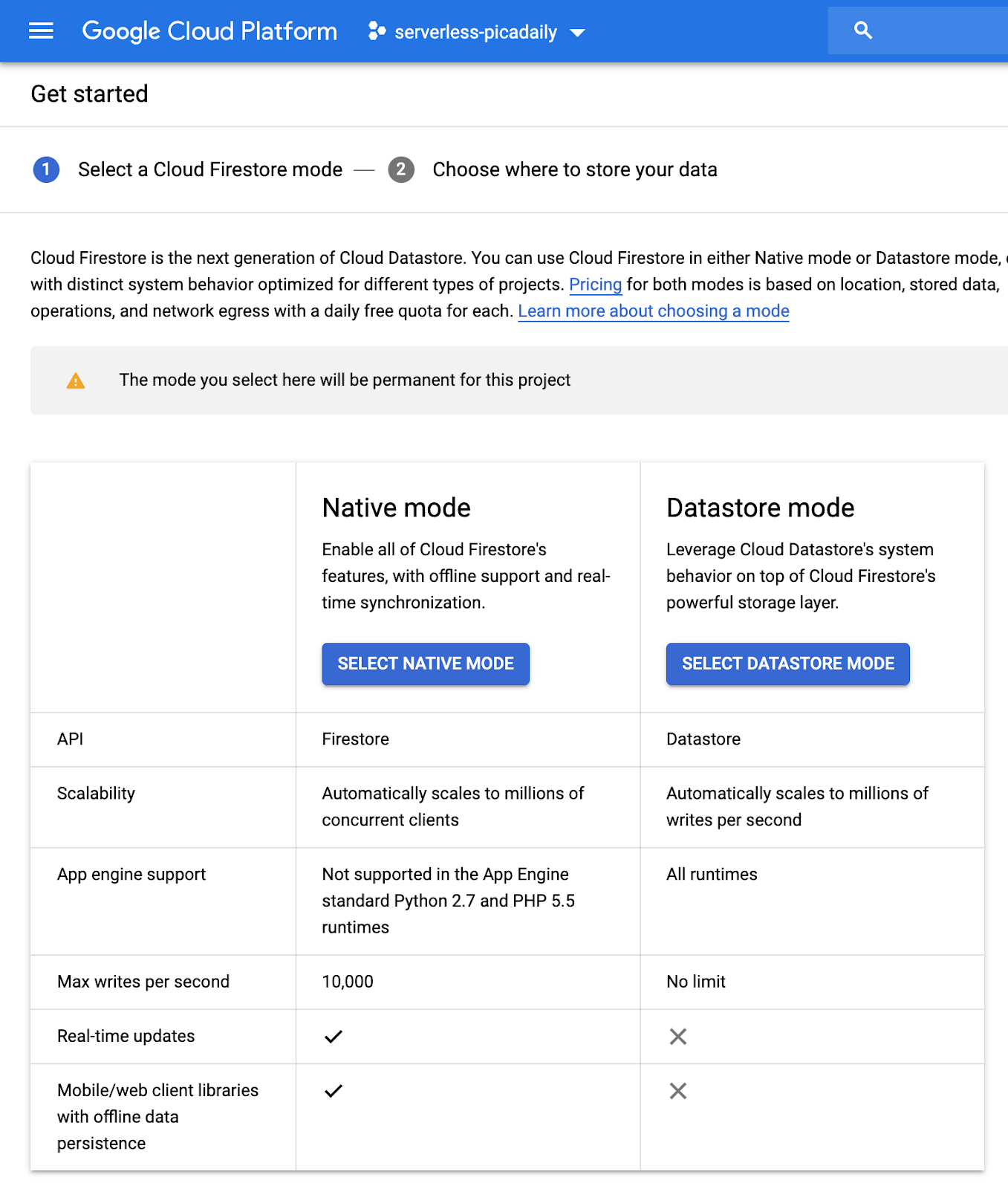
Deux options sont proposées : Native mode ou Datastore mode. Utilisez le mode natif, qui offre des fonctionnalités supplémentaires comme le fonctionnement hors connexion et la synchronisation en temps réel.
Cliquez sur SELECT NATIVE MODE.
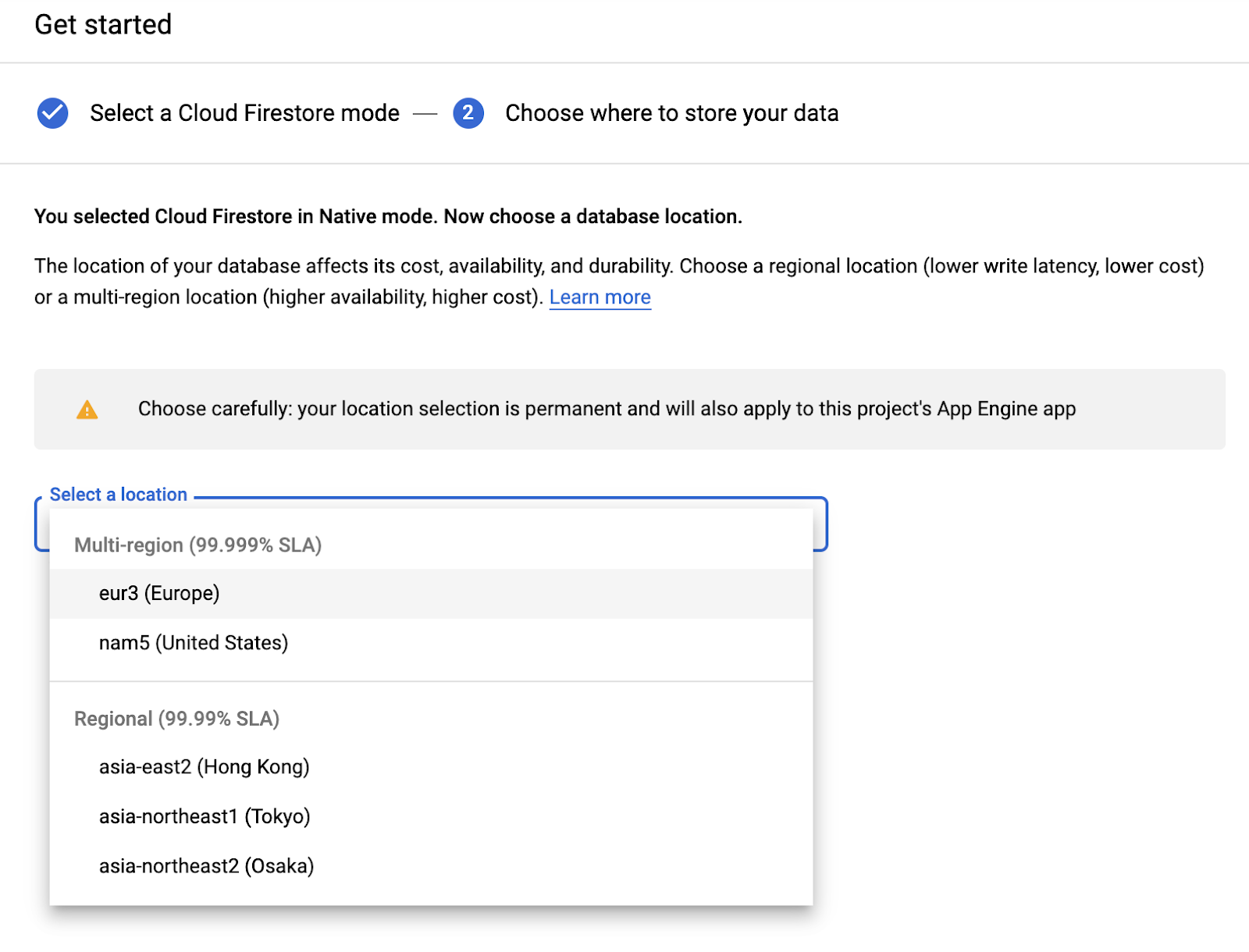
Choisissez une région multiple (ici en Europe, mais idéalement au moins la même région que votre fonction et votre bucket de stockage).
Cliquez sur le bouton CREATE DATABASE.
Une fois la base de données créée, vous devriez voir ce qui suit :
Créez une collection en cliquant sur le bouton + START COLLECTION.
Nommez la collection pictures.
Vous n'avez pas besoin de créer de document. Vous les ajouterez de manière programmatique à mesure que de nouvelles images seront stockées dans Cloud Storage et analysées par l'API Vision.
Cliquez sur Save.
Firestore crée un premier document par défaut dans la collection nouvellement créée. Vous pouvez le supprimer sans risque, car il ne contient aucune information utile :
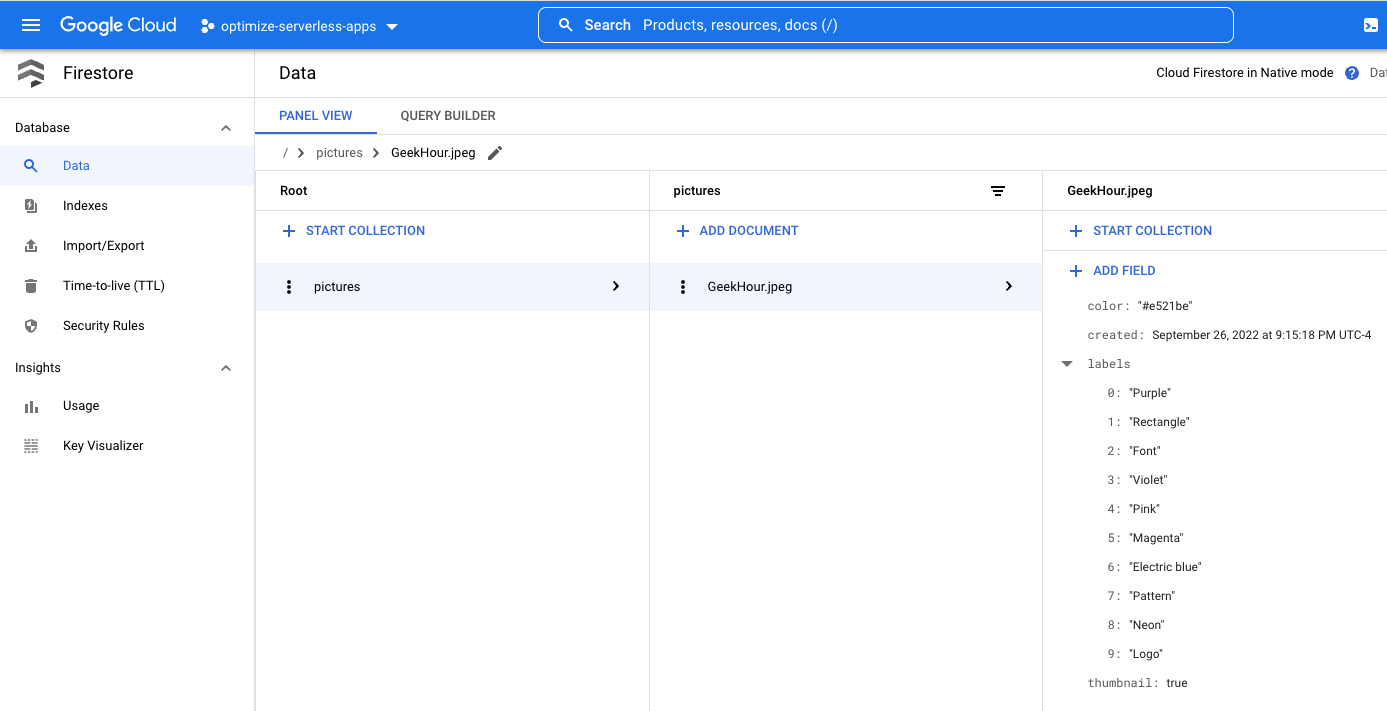
Les documents qui seront créés de manière programmatique dans notre collection contiendront quatre champs :
- name (chaîne) : nom du fichier de l'image importée, qui est également la clé du document
- labels (tableau de chaînes) : étiquettes des éléments reconnus par l'API Vision
- color (chaîne) : code hexadécimal de la couleur dominante (par exemple, #ab12ef)
- created (date) : code temporel indiquant quand les métadonnées de cette image ont été stockées.
- thumbnail (booléen) : champ facultatif qui est présent et défini sur "true" si une image miniature a été générée pour cette photo.
Comme nous allons effectuer des recherches dans Firestore pour trouver les photos qui ont des miniatures disponibles et les trier par date de création, nous devrons créer un index de recherche.
Vous pouvez créer l'index à l'aide de la commande suivante dans Cloud Shell :
gcloud firestore indexes composite create \
--collection-group=pictures \
--field-config field-path=thumbnail,order=descending \
--field-config field-path=created,order=descending
Vous pouvez également le faire depuis la console Cloud en cliquant sur Indexes dans la colonne de navigation de gauche, puis en créant un index composite comme indiqué ci-dessous :
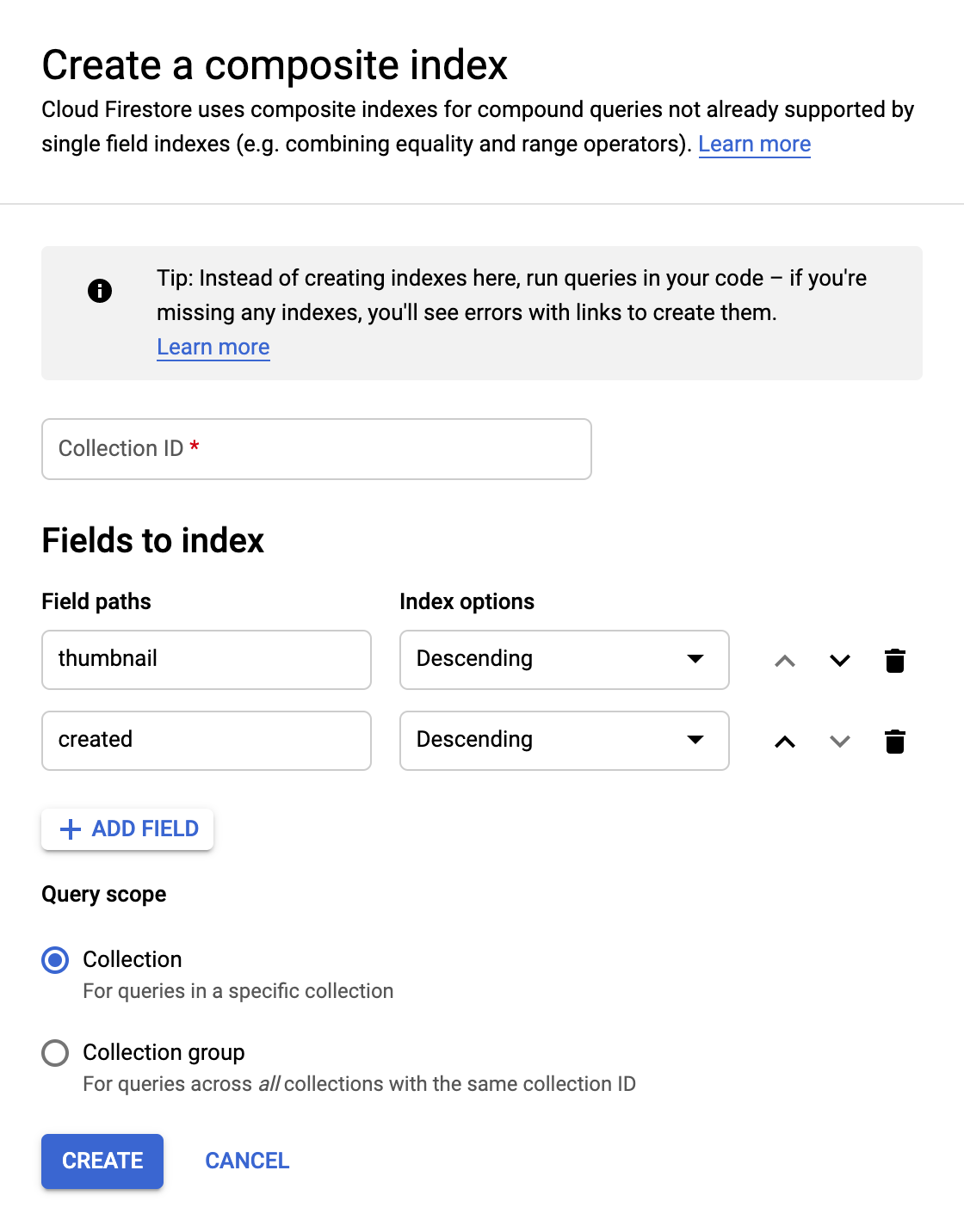
Cliquez sur Create. La création de l'index peut prendre quelques minutes.
8. Cloner le code
Clonez le code, si vous ne l'avez pas déjà fait dans l'atelier de programmation précédent :
git clone https://github.com/GoogleCloudPlatform/serverless-photosharing-workshop
Vous pouvez ensuite accéder au répertoire contenant le service pour commencer à créer l'atelier :
cd serverless-photosharing-workshop/services/image-analysis/java
Votre service utilisera la structure de fichiers suivante :
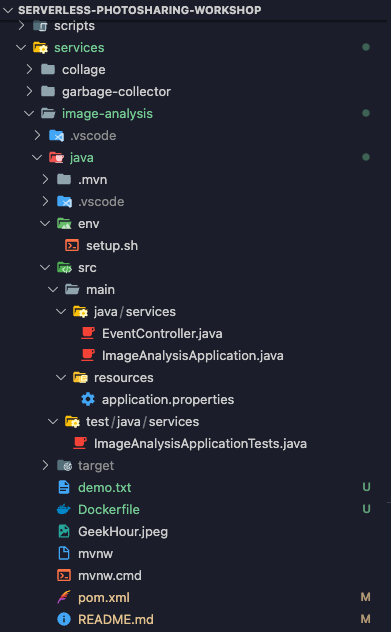
9. Explorer le code du service
Vous allez commencer par examiner comment les bibliothèques clientes Java sont activées dans pom.xml à l'aide d'une BOM :
Commencez par modifier le fichier pom.xml qui liste les dépendances de notre fonction Java. Mettez à jour le code pour ajouter la dépendance Maven de l'API Cloud Vision :
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>cloudfunctions</groupId>
<artifactId>gcs-function</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.target>11</maven.compiler.target>
<maven.compiler.source>11</maven.compiler.source>
</properties>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>com.google.cloud</groupId>
<artifactId>libraries-bom</artifactId>
<version>26.1.1</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<dependencies>
<dependency>
<groupId>com.google.cloud.functions</groupId>
<artifactId>functions-framework-api</artifactId>
<version>1.0.4</version>
<type>jar</type>
</dependency>
<dependency>
<groupId>com.google.cloud</groupId>
<artifactId>google-cloud-firestore</artifactId>
</dependency>
<dependency>
<groupId>com.google.cloud</groupId>
<artifactId>google-cloud-vision</artifactId>
</dependency>
<dependency>
<groupId>com.google.cloud</groupId>
<artifactId>google-cloud-storage</artifactId>
</dependency>
</dependencies>
La fonctionnalité est implémentée dans la classe EventController. Chaque fois qu'une nouvelle image est importée dans le bucket, le service reçoit une notification pour la traiter :
@RestController
public class EventController {
private static final Logger logger = Logger.getLogger(EventController.class.getName());
private static final List<String> requiredFields = Arrays.asList("ce-id", "ce-source", "ce-type", "ce-specversion");
@RequestMapping(value = "/", method = RequestMethod.POST)
public ResponseEntity<String> receiveMessage(
@RequestBody Map<String, Object> body, @RequestHeader Map<String, String> headers) throws IOException, InterruptedException, ExecutionException {
...
}
Le code procède à la validation des en-têtes Cloud Events :
System.out.println("Header elements");
for (String field : requiredFields) {
if (headers.get(field) == null) {
String msg = String.format("Missing expected header: %s.", field);
System.out.println(msg);
return new ResponseEntity<String>(msg, HttpStatus.BAD_REQUEST);
} else {
System.out.println(field + " : " + headers.get(field));
}
}
System.out.println("Body elements");
for (String bodyField : body.keySet()) {
System.out.println(bodyField + " : " + body.get(bodyField));
}
if (headers.get("ce-subject") == null) {
String msg = "Missing expected header: ce-subject.";
System.out.println(msg);
return new ResponseEntity<String>(msg, HttpStatus.BAD_REQUEST);
}
Une requête peut maintenant être créée et le code en préparera une à envoyer à Vision API :
try (ImageAnnotatorClient vision = ImageAnnotatorClient.create()) {
List<AnnotateImageRequest> requests = new ArrayList<>();
ImageSource imageSource = ImageSource.newBuilder()
.setGcsImageUri("gs://" + bucketName + "/" + fileName)
.build();
Image image = Image.newBuilder()
.setSource(imageSource)
.build();
Feature featureLabel = Feature.newBuilder()
.setType(Type.LABEL_DETECTION)
.build();
Feature featureImageProps = Feature.newBuilder()
.setType(Type.IMAGE_PROPERTIES)
.build();
Feature featureSafeSearch = Feature.newBuilder()
.setType(Type.SAFE_SEARCH_DETECTION)
.build();
AnnotateImageRequest request = AnnotateImageRequest.newBuilder()
.addFeatures(featureLabel)
.addFeatures(featureImageProps)
.addFeatures(featureSafeSearch)
.setImage(image)
.build();
requests.add(request);
Nous vous demandons de décrire trois fonctionnalités clés de l'API Vision :
- Détection de libellés : pour comprendre le contenu de vos photos
- Propriétés de l'image : pour fournir des attributs intéressants de l'image (nous nous intéressons à la couleur dominante de l'image)
- Recherche sécurisée : pour savoir si l'image peut être affichée sans danger (elle ne doit pas contenir de contenu réservé aux adultes, médical, suggestif ou violent)
À ce stade, nous pouvons appeler l'API Vision :
...
logger.info("Calling the Vision API...");
BatchAnnotateImagesResponse result = vision.batchAnnotateImages(requests);
List<AnnotateImageResponse> responses = result.getResponsesList();
...
Pour référence, voici à quoi ressemble la réponse de l'API Vision :
{
"faceAnnotations": [],
"landmarkAnnotations": [],
"logoAnnotations": [],
"labelAnnotations": [
{
"locations": [],
"properties": [],
"mid": "/m/01yrx",
"locale": "",
"description": "Cat",
"score": 0.9959855675697327,
"confidence": 0,
"topicality": 0.9959855675697327,
"boundingPoly": null
},
✄ - - - ✄
],
"textAnnotations": [],
"localizedObjectAnnotations": [],
"safeSearchAnnotation": {
"adult": "VERY_UNLIKELY",
"spoof": "UNLIKELY",
"medical": "VERY_UNLIKELY",
"violence": "VERY_UNLIKELY",
"racy": "VERY_UNLIKELY",
"adultConfidence": 0,
"spoofConfidence": 0,
"medicalConfidence": 0,
"violenceConfidence": 0,
"racyConfidence": 0,
"nsfwConfidence": 0
},
"imagePropertiesAnnotation": {
"dominantColors": {
"colors": [
{
"color": {
"red": 203,
"green": 201,
"blue": 201,
"alpha": null
},
"score": 0.4175916016101837,
"pixelFraction": 0.44456374645233154
},
✄ - - - ✄
]
}
},
"error": null,
"cropHintsAnnotation": {
"cropHints": [
{
"boundingPoly": {
"vertices": [
{ "x": 0, "y": 118 },
{ "x": 1177, "y": 118 },
{ "x": 1177, "y": 783 },
{ "x": 0, "y": 783 }
],
"normalizedVertices": []
},
"confidence": 0.41695669293403625,
"importanceFraction": 1
}
]
},
"fullTextAnnotation": null,
"webDetection": null,
"productSearchResults": null,
"context": null
}
Si aucune erreur n'est renvoyée, nous pouvons passer à la suite. C'est pourquoi nous avons ce bloc "if" :
if (responses.size() == 0) {
logger.info("No response received from Vision API.");
return new ResponseEntity<String>(msg, HttpStatus.BAD_REQUEST);
}
AnnotateImageResponse response = responses.get(0);
if (response.hasError()) {
logger.info("Error: " + response.getError().getMessage());
return new ResponseEntity<String>(msg, HttpStatus.BAD_REQUEST);
}
Nous allons obtenir les libellés des choses, des catégories ou des thèmes reconnus dans l'image :
List<String> labels = response.getLabelAnnotationsList().stream()
.map(annotation -> annotation.getDescription())
.collect(Collectors.toList());
logger.info("Annotations found:");
for (String label: labels) {
logger.info("- " + label);
}
Nous souhaitons connaître la couleur dominante de l'image :
String mainColor = "#FFFFFF";
ImageProperties imgProps = response.getImagePropertiesAnnotation();
if (imgProps.hasDominantColors()) {
DominantColorsAnnotation colorsAnn = imgProps.getDominantColors();
ColorInfo colorInfo = colorsAnn.getColors(0);
mainColor = rgbHex(
colorInfo.getColor().getRed(),
colorInfo.getColor().getGreen(),
colorInfo.getColor().getBlue());
logger.info("Color: " + mainColor);
}
Vérifions si l'image peut être affichée :
boolean isSafe = false;
if (response.hasSafeSearchAnnotation()) {
SafeSearchAnnotation safeSearch = response.getSafeSearchAnnotation();
isSafe = Stream.of(
safeSearch.getAdult(), safeSearch.getMedical(), safeSearch.getRacy(),
safeSearch.getSpoof(), safeSearch.getViolence())
.allMatch( likelihood ->
likelihood != Likelihood.LIKELY && likelihood != Likelihood.VERY_LIKELY
);
logger.info("Safe? " + isSafe);
}
Nous vérifions les caractéristiques "Contenu réservé aux adultes", "Parodie", "Contenu médical", "Violence" et "Contenu suggestif" pour voir si elles sont probables ou très probables.
Si le résultat de la recherche sécurisée est correct, nous pouvons stocker les métadonnées dans Firestore :
// Saving result to Firestore
if (isSafe) {
FirestoreOptions firestoreOptions = FirestoreOptions.getDefaultInstance();
Firestore pictureStore = firestoreOptions.getService();
DocumentReference doc = pictureStore.collection("pictures").document(fileName);
Map<String, Object> data = new HashMap<>();
data.put("labels", labels);
data.put("color", mainColor);
data.put("created", new Date());
ApiFuture<WriteResult> writeResult = doc.set(data, SetOptions.merge());
logger.info("Picture metadata saved in Firestore at " + writeResult.get().getUpdateTime());
}
10. Créer des images d'application avec GraalVM (facultatif)
Lors de cette étape facultative, vous allez créer un JIT(JVM) based app image, puis un AOT(Native) Java app image, à l'aide de GraalVM.
Pour exécuter la compilation, vous devez vous assurer d'avoir installé et configuré un JDK approprié et le compilateur native-image. Plusieurs options s'offrent à vous.
To start, téléchargez GraalVM 22.2.x Community Edition et suivez les instructions de la page Installation de GraalVM.
Ce processus peut être considérablement simplifié à l'aide de SDKMAN!
Pour installer la distribution JDK appropriée avec SDKman, commencez par utiliser la commande d'installation :
sdk install java 22.2.r17-grl
Indiquez à SDKman d'utiliser cette version, pour les builds JIT et AOT :
sdk use java 22.2.0.r17-grl
Installez native-image utility pour GraalVM :
gu install native-image
Dans Cloudshell, vous pouvez installer GraalVM et l'utilitaire native-image à l'aide de ces commandes simples :
# install GraalVM in your home directory cd ~ # download GraalVM wget https://github.com/graalvm/graalvm-ce-builds/releases/download/vm-22.2.0/graalvm-ce-java17-linux-amd64-22.2.0.tar.gz ls tar -xzvf graalvm-ce-java17-linux-amd64-22.2.0.tar.gz # configure Java 17 and GraalVM 22.2 echo Existing JVM: $JAVA_HOME cd graalvm-ce-java17-22.2.0 export JAVA_HOME=$PWD cd bin export PATH=$PWD:$PATH echo JAVA HOME: $JAVA_HOME echo PATH: $PATH # install the native image utility java -version gu install native-image cd ../..
Tout d'abord, définissez les variables d'environnement du projet GCP :
export GOOGLE_CLOUD_PROJECT=$(gcloud config get-value project)
Vous pouvez ensuite accéder au répertoire contenant le service pour commencer à créer l'atelier :
cd serverless-photosharing-workshop/services/image-analysis/java
Créez l'image de l'application JIT(JVM) :
./mvnw package -Pjvm
Observez le journal de compilation dans le terminal :
... [INFO] --- spring-boot-maven-plugin:2.7.3:repackage (repackage) @ image-analysis --- [INFO] Replacing main artifact with repackaged archive [INFO] ------------------------------------------------------------------------ [INFO] BUILD SUCCESS [INFO] ------------------------------------------------------------------------ [INFO] Total time: 24.009 s [INFO] Finished at: 2022-09-26T22:17:32-04:00 [INFO] ------------------------------------------------------------------------
Créez l'image AOT(native) :
./mvnw package -Pnative -DskipTests
Observez le journal de compilation dans le terminal, y compris les journaux de compilation des images natives :
Notez que la compilation prend un peu plus de temps, en fonction de la machine sur laquelle vous effectuez le test.
...
[2/7] Performing analysis... [**********] (95.4s @ 3.57GB)
23,346 (94.42%) of 24,725 classes reachable
44,625 (68.71%) of 64,945 fields reachable
163,759 (70.79%) of 231,322 methods reachable
989 classes, 1,402 fields, and 11,032 methods registered for reflection
63 classes, 69 fields, and 55 methods registered for JNI access
5 native libraries: -framework CoreServices, -framework Foundation, dl, pthread, z
[3/7] Building universe... (10.0s @ 5.35GB)
[4/7] Parsing methods... [***] (9.7s @ 3.13GB)
[5/7] Inlining methods... [***] (4.5s @ 3.29GB)
[6/7] Compiling methods... [[6/7] Compiling methods... [********] (67.6s @ 5.72GB)
[7/7] Creating image... (8.7s @ 4.59GB)
62.21MB (54.80%) for code area: 100,371 compilation units
50.98MB (44.91%) for image heap: 465,035 objects and 365 resources
337.09KB ( 0.29%) for other data
113.52MB in total
------------------------------------------------------------------------------------------------------------------------
Top 10 packages in code area: Top 10 object types in image heap:
2.36MB com.google.protobuf 12.70MB byte[] for code metadata
1.90MB i.g.xds.shaded.io.envoyproxy.envoy.config.core.v3 6.66MB java.lang.Class
1.73MB i.g.x.shaded.io.envoyproxy.envoy.config.route.v3 6.47MB byte[] for embedded resources
1.67MB sun.security.ssl 4.61MB byte[] for java.lang.String
1.54MB com.google.cloud.vision.v1 4.37MB java.lang.String
1.46MB com.google.firestore.v1 3.38MB byte[] for general heap data
1.37MB io.grpc.xds.shaded.io.envoyproxy.envoy.api.v2.core 1.96MB com.oracle.svm.core.hub.DynamicHubCompanion
1.32MB i.g.xds.shaded.io.envoyproxy.envoy.api.v2.route 1.80MB byte[] for reflection metadata
1.09MB java.util 911.80KB java.lang.String[]
1.08MB com.google.re2j 826.48KB c.o.svm.core.hub.DynamicHub$ReflectionMetadata
45.91MB for 772 more packages 6.45MB for 3913 more object types
------------------------------------------------------------------------------------------------------------------------
15.1s (6.8% of total time) in 56 GCs | Peak RSS: 7.72GB | CPU load: 4.37
------------------------------------------------------------------------------------------------------------------------
Produced artifacts:
/Users/ddobrin/work/dan/serverless-photosharing-workshop/services/image-analysis/java/target/image-analysis (executable)
/Users/ddobrin/work/dan/serverless-photosharing-workshop/services/image-analysis/java/target/image-analysis.build_artifacts.txt (txt)
========================================================================================================================
Finished generating 'image-analysis' in 3m 41s.
[INFO] ------------------------------------------------------------------------
[INFO] BUILD SUCCESS
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 03:56 min
[INFO] Finished at: 2022-09-26T22:22:29-04:00
[INFO] ------------------------------------------------------------------------
11. Créer et publier des images de conteneurs
Nous allons créer une image de conteneur en deux versions différentes : l'une en tant que JIT(JVM) image et l'autre en tant que AOT(Native) Java image.
Tout d'abord, définissez les variables d'environnement du projet GCP :
export GOOGLE_CLOUD_PROJECT=$(gcloud config get-value project)
Créez l'image JIT(JVM) :
./mvnw package -Pjvm-image
Observez le journal de compilation dans le terminal :
[INFO] [creator] Adding layer 'process-types' [INFO] [creator] Adding label 'io.buildpacks.lifecycle.metadata' [INFO] [creator] Adding label 'io.buildpacks.build.metadata' [INFO] [creator] Adding label 'io.buildpacks.project.metadata' [INFO] [creator] Adding label 'org.opencontainers.image.title' [INFO] [creator] Adding label 'org.opencontainers.image.version' [INFO] [creator] Adding label 'org.springframework.boot.version' [INFO] [creator] Setting default process type 'web' [INFO] [creator] Saving docker.io/library/image-analysis-jvm:r17... [INFO] [creator] *** Images (03a44112456e): [INFO] [creator] docker.io/library/image-analysis-jvm:r17 [INFO] [creator] Adding cache layer 'paketo-buildpacks/syft:syft' [INFO] [creator] Adding cache layer 'cache.sbom' [INFO] [INFO] Successfully built image 'docker.io/library/image-analysis-jvm:r17' [INFO] [INFO] ------------------------------------------------------------------------ [INFO] BUILD SUCCESS [INFO] ------------------------------------------------------------------------ [INFO] Total time: 02:11 min [INFO] Finished at: 2022-09-26T13:09:34-04:00 [INFO] ------------------------------------------------------------------------
Créez l'image AOT(native) :
./mvnw package -Pnative-image
Observez le journal de compilation dans le terminal, y compris les journaux de compilation d'image native et la compression d'image à l'aide d'UPX.
Notez que la compilation prend un peu plus de temps, en fonction de la machine sur laquelle vous effectuez le test.
... [INFO] [creator] [2/7] Performing analysis... [***********] (147.6s @ 3.10GB) [INFO] [creator] 23,362 (94.34%) of 24,763 classes reachable [INFO] [creator] 44,657 (68.67%) of 65,029 fields reachable [INFO] [creator] 163,926 (70.76%) of 231,656 methods reachable [INFO] [creator] 981 classes, 1,402 fields, and 11,026 methods registered for reflection [INFO] [creator] 63 classes, 68 fields, and 55 methods registered for JNI access [INFO] [creator] 4 native libraries: dl, pthread, rt, z [INFO] [creator] [3/7] Building universe... (21.1s @ 2.66GB) [INFO] [creator] [4/7] Parsing methods... [****] (13.7s @ 4.16GB) [INFO] [creator] [5/7] Inlining methods... [***] (9.6s @ 4.20GB) [INFO] [creator] [6/7] Compiling methods... [**********] (107.6s @ 3.36GB) [INFO] [creator] [7/7] Creating image... (14.7s @ 4.87GB) [INFO] [creator] 62.24MB (51.35%) for code area: 100,499 compilation units [INFO] [creator] 51.99MB (42.89%) for image heap: 473,948 objects and 473 resources [INFO] [creator] 6.98MB ( 5.76%) for other data [INFO] [creator] 121.21MB in total [INFO] [creator] -------------------------------------------------------------------------------- [INFO] [creator] Top 10 packages in code area: Top 10 object types in image heap: [INFO] [creator] 2.36MB com.google.protobuf 12.71MB byte[] for code metadata [INFO] [creator] 1.90MB i.g.x.s.i.e.e.config.core.v3 7.59MB byte[] for embedded resources [INFO] [creator] 1.73MB i.g.x.s.i.e.e.config.route.v3 6.66MB java.lang.Class [INFO] [creator] 1.67MB sun.security.ssl 4.62MB byte[] for java.lang.String [INFO] [creator] 1.54MB com.google.cloud.vision.v1 4.39MB java.lang.String [INFO] [creator] 1.46MB com.google.firestore.v1 3.66MB byte[] for general heap data [INFO] [creator] 1.37MB i.g.x.s.i.e.envoy.api.v2.core 1.96MB c.o.s.c.h.DynamicHubCompanion [INFO] [creator] 1.32MB i.g.x.s.i.e.e.api.v2.route 1.80MB byte[] for reflection metadata [INFO] [creator] 1.09MB java.util 910.41KB java.lang.String[] [INFO] [creator] 1.08MB com.google.re2j 826.95KB c.o.s.c.h.DynamicHu~onMetadata [INFO] [creator] 45.94MB for 776 more packages 6.69MB for 3916 more object types [INFO] [creator] -------------------------------------------------------------------------------- [INFO] [creator] 20.4s (5.6% of total time) in 81 GCs | Peak RSS: 6.75GB | CPU load: 4.53 [INFO] [creator] -------------------------------------------------------------------------------- [INFO] [creator] Produced artifacts: [INFO] [creator] /layers/paketo-buildpacks_native-image/native-image/services.ImageAnalysisApplication (executable) [INFO] [creator] /layers/paketo-buildpacks_native-image/native-image/services.ImageAnalysisApplication.build_artifacts.txt (txt) [INFO] [creator] ================================================================================ [INFO] [creator] Finished generating '/layers/paketo-buildpacks_native-image/native-image/services.ImageAnalysisApplication' in 5m 59s. [INFO] [creator] Executing upx to compress native image [INFO] [creator] Ultimate Packer for eXecutables [INFO] [creator] Copyright (C) 1996 - 2020 [INFO] [creator] UPX 3.96 Markus Oberhumer, Laszlo Molnar & John Reiser Jan 23rd 2020 [INFO] [creator] [INFO] [creator] File size Ratio Format Name [INFO] [creator] -------------------- ------ ----------- ----------- 127099880 -> 32416676 25.50% linux/amd64 services.ImageAnalysisApplication ... [INFO] [creator] ===> EXPORTING ... [INFO] [creator] Adding cache layer 'paketo-buildpacks/native-image:native-image' [INFO] [creator] Adding cache layer 'cache.sbom' [INFO] [INFO] Successfully built image 'docker.io/library/image-analysis-native:r17' ------------------------------------------------------------------------ [INFO] BUILD SUCCESS [INFO] ------------------------------------------------------------------------ [INFO] Total time: 05:28 min [INFO] Finished at: 2022-09-26T13:19:53-04:00 [INFO] ------------------------------------------------------------------------
Validez que les images ont été créées :
docker images | grep image-analysis
Ajoutez un tag aux deux images et transférez-les vers GCR :
# JIT(JVM) image
docker tag image-analysis-jvm:r17 gcr.io/${GOOGLE_CLOUD_PROJECT}/image-analysis-jvm:r17
docker push gcr.io/${GOOGLE_CLOUD_PROJECT}/image-analysis-jvm:r17
# AOT(Native) image
docker tag image-analysis-native:r17 gcr.io/${GOOGLE_CLOUD_PROJECT}/image-analysis-native:r17
docker push gcr.io/${GOOGLE_CLOUD_PROJECT}/image-analysis-native:r17
12. Déployer dans Cloud Run
Il est temps de déployer le service.
Vous allez déployer le service deux fois : une fois à l'aide de l'image JIT(JVM) et une fois à l'aide de l'image AOT(Native). Les deux déploiements de service traiteront la même image du bucket en parallèle, à des fins de comparaison.
Tout d'abord, définissez les variables d'environnement du projet GCP :
export GOOGLE_CLOUD_PROJECT=$(gcloud config get-value project)
gcloud config set project ${GOOGLE_CLOUD_PROJECT}
gcloud config set run/region
gcloud config set run/platform managed
gcloud config set eventarc/location europe-west1
Déployez l'image JIT(JVM) et observez le journal de déploiement dans la console :
gcloud run deploy image-analysis-jvm \
--image gcr.io/${GOOGLE_CLOUD_PROJECT}/image-analysis-jvm:r17 \
--region europe-west1 \
--memory 2Gi --allow-unauthenticated
...
Deploying container to Cloud Run service [image-analysis-jvm] in project [...] region [europe-west1]
✓ Deploying... Done.
✓ Creating Revision...
✓ Routing traffic...
✓ Setting IAM Policy...
Done.
Service [image-analysis-jvm] revision [image-analysis-jvm-00009-huc] has been deployed and is serving 100 percent of traffic.
Service URL: https://image-analysis-jvm-...-ew.a.run.app
Déployez l'image AOT(native) et examinez le journal de déploiement dans la console :
gcloud run deploy image-analysis-native \
--image gcr.io/${GOOGLE_CLOUD_PROJECT}/image-analysis-native:r17 \
--region europe-west1 \
--memory 2Gi --allow-unauthenticated
...
Deploying container to Cloud Run service [image-analysis-native] in project [...] region [europe-west1]
✓ Deploying... Done.
✓ Creating Revision...
✓ Routing traffic...
✓ Setting IAM Policy...
Done.
Service [image-analysis-native] revision [image-analysis-native-00005-ben] has been deployed and is serving 100 percent of traffic.
Service URL: https://image-analysis-native-...-ew.a.run.app
13. Configurer des déclencheurs Eventarc
Eventarc offre une solution standardisée pour gérer le flux des changements d'état, appelés événements, entre les microservices découplés. Lorsqu'il est déclenché, Eventarc achemine ces événements via des abonnements Pub/Sub vers différentes destinations (dans ce document, consultez la section "Destinations d'événements") tout en gérant la diffusion, la sécurité, les autorisations, l'observabilité et la gestion des erreurs à votre place.
Vous pouvez créer un déclencheur Eventarc afin que votre service Cloud Run reçoive des notifications d'un événement ou d'un ensemble d'événements spécifié. En spécifiant des filtres pour le déclencheur, vous pouvez configurer le routage de l'événement, y compris la source de l'événement et le service Cloud Run cible.
Tout d'abord, définissez les variables d'environnement du projet GCP :
export GOOGLE_CLOUD_PROJECT=$(gcloud config get-value project)
gcloud config set project ${GOOGLE_CLOUD_PROJECT}
gcloud config set run/region
gcloud config set run/platform managed
gcloud config set eventarc/location europe-west1
Accordez le rôle pubsub.publisher au compte de service Cloud Storage :
SERVICE_ACCOUNT="$(gsutil kms serviceaccount -p ${GOOGLE_CLOUD_PROJECT})"
gcloud projects add-iam-policy-binding ${GOOGLE_CLOUD_PROJECT} \
--member="serviceAccount:${SERVICE_ACCOUNT}" \
--role='roles/pubsub.publisher'
Configurez des déclencheurs Eventarc pour les images de service JVM(JIT) et AOT(natif) afin de traiter l'image :
gcloud eventarc triggers list --location=eu
gcloud eventarc triggers create image-analysis-jvm-trigger \
--destination-run-service=image-analysis-jvm \
--destination-run-region=europe-west1 \
--location=eu \
--event-filters="type=google.cloud.storage.object.v1.finalized" \
--event-filters="bucket=uploaded-pictures-${GOOGLE_CLOUD_PROJECT}" \
--service-account=${PROJECT_NUMBER}-compute@developer.gserviceaccount.com
gcloud eventarc triggers create image-analysis-native-trigger \
--destination-run-service=image-analysis-native \
--destination-run-region=europe-west1 \
--location=eu \
--event-filters="type=google.cloud.storage.object.v1.finalized" \
--event-filters="bucket=uploaded-pictures-${GOOGLE_CLOUD_PROJECT}" \
--service-account=${PROJECT_NUMBER}-compute@developer.gserviceaccount.com
Notez que les deux déclencheurs ont été créés :
gcloud eventarc triggers list --location=eu
14. Tester les versions de service
Une fois les déploiements de services réussis, vous allez publier une image dans Cloud Storage, vérifier si nos services ont été appelés, ce que renvoie l'API Vision et si les métadonnées sont stockées dans Firestore.
Revenez à Cloud Storage et cliquez sur le bucket que vous avez créé au début de l'atelier :
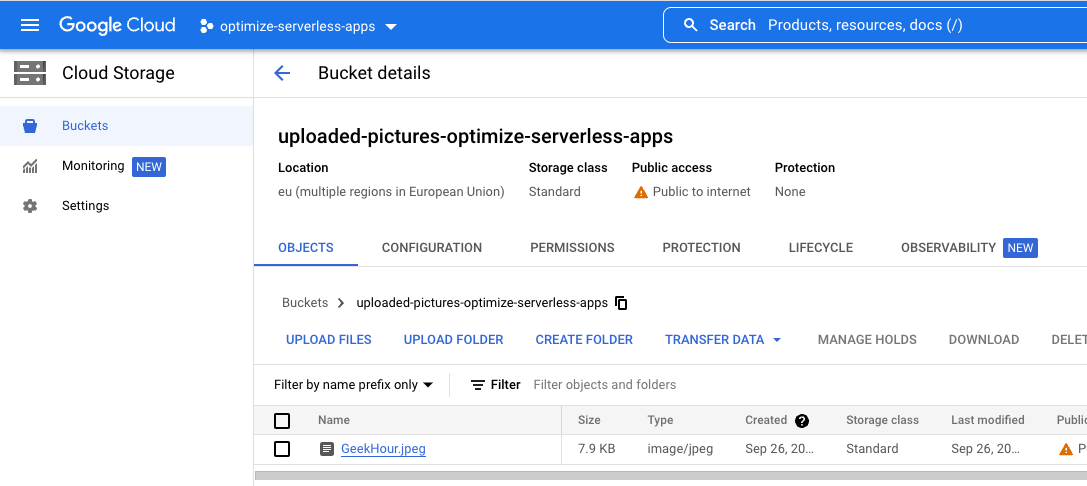
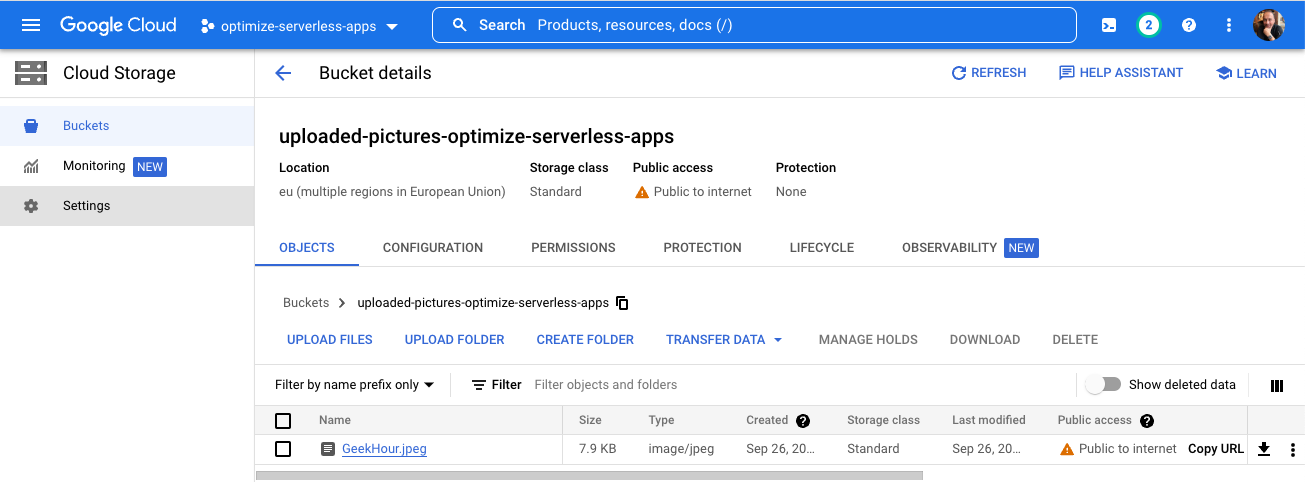
Une fois sur la page d'informations sur le bucket, cliquez sur le bouton Upload files pour importer une image.
Par exemple, une image GeekHour.jpeg est fournie avec votre code source sous /services/image-analysis/java. Sélectionnez une image, puis appuyez sur Open button :
Vous pouvez maintenant vérifier l'exécution du service, en commençant par image-analysis-jvm, puis image-analysis-native.
Dans le menu hamburger (☰), accédez au service Cloud Run > image-analysis-jvm.
Cliquez sur "Journaux" et observez le résultat :
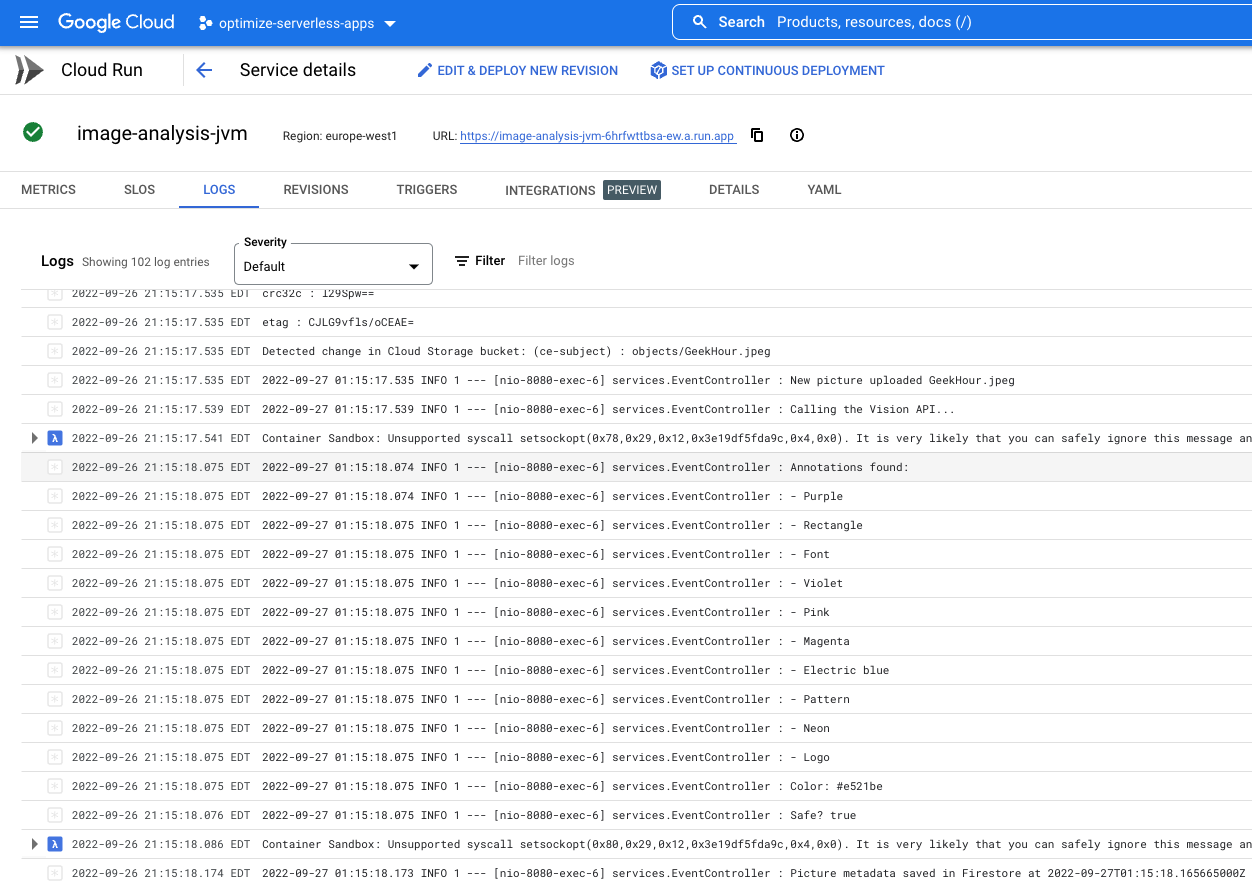
Et en effet, dans la liste des journaux, je vois que le service JIT(JVM) image-analysis-jvm a été appelé.
Les journaux indiquent le début et la fin de l'exécution du service. Entre les deux, nous pouvons voir les journaux que nous avons placés dans notre fonction avec les instructions de journalisation au niveau INFO. Nous constatons :
- les détails de l'événement qui déclenche notre fonction ;
- Résultats bruts de l'appel de l'API Vision
- les libellés trouvés dans l'image que nous avons importée ;
- Informations sur les couleurs dominantes
- Indique si l'image peut être affichée sans danger.
- Enfin, les métadonnées de l'image ont été stockées dans Firestore.
Répétez le processus pour le service image-analysis-native.
Dans le menu hamburger (☰), accédez au service Cloud Run > image-analysis-native.
Cliquez sur "Journaux" et observez le résultat :
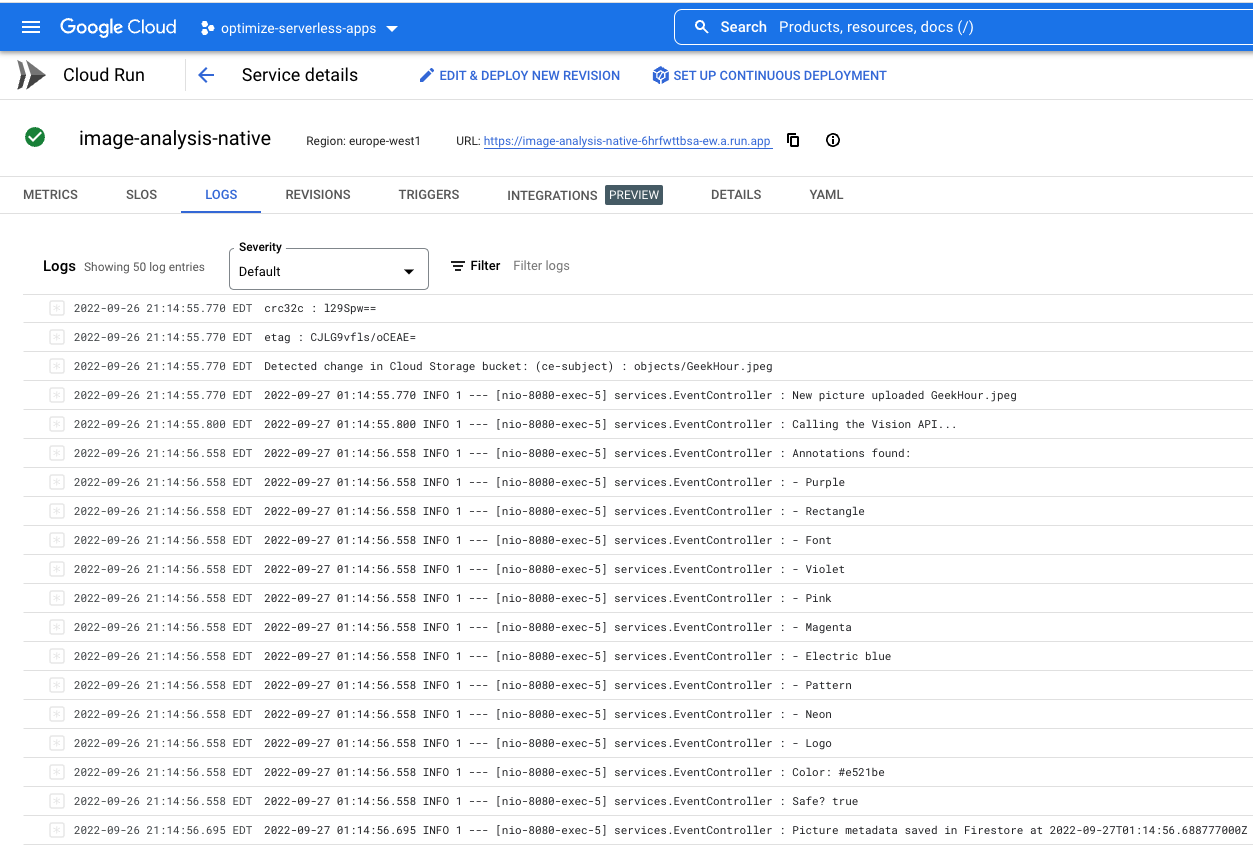
Vous devez maintenant vérifier si les métadonnées de l'image ont été stockées dans Fiorestore.
Dans le menu hamburger (☰), accédez à la section Firestore. Dans la sous-section Data (affichée par défaut), vous devriez voir la collection pictures avec un nouveau document ajouté, correspondant à l'image que vous venez d'importer :
15. Nettoyer (facultatif)
Si vous n'avez pas l'intention de continuer à suivre les autres ateliers de cette série, vous pouvez nettoyer les ressources pour limiter vos dépenses et utiliser le cloud de manière raisonnée. Vous pouvez nettoyer les ressources individuellement comme suit.
Supprimez le bucket :
gsutil rb gs://${BUCKET_PICTURES}
Supprimez la fonction :
gcloud functions delete picture-uploaded --region europe-west1 -q
Supprimez la collection Firestore en sélectionnant "Supprimer la collection" dans la collection :
Vous pouvez également supprimer l'intégralité du projet :
gcloud projects delete ${GOOGLE_CLOUD_PROJECT}
16. Félicitations !
Félicitations ! Vous avez implémenté avec succès le premier service clé du projet.
Points abordés
- Cloud Storage
- Cloud Run
- API Cloud Vision
- Cloud Firestore
- Images Java natives