
1. Przegląd
Programiści aplikacji klienckich i stron internetowych często używają narzędzi takich jak CPU Profiler w Android Studio czy narzędzia do profilowania w Chrome, aby poprawić wydajność kodu. Podobne techniki nie są jednak tak łatwo dostępne ani tak powszechnie stosowane przez osoby pracujące nad usługami backendu. Cloud Profiler udostępnia te same możliwości programistom usług niezależnie od tego, czy ich kod jest uruchamiany na platformie Google Cloud Platform, czy w innym miejscu.

Narzędzie zbiera informacje o wykorzystaniu procesora i alokacji pamięci przez aplikacje produkcyjne. Przypisuje te informacje do kodu źródłowego aplikacji, co pomaga identyfikować części aplikacji, które zużywają najwięcej zasobów, i w inny sposób wyjaśniać charakterystykę wydajności kodu. Niskie obciążenie związane z technikami zbierania danych stosowanymi przez to narzędzie sprawia, że nadaje się ono do ciągłego użytku w środowiskach produkcyjnych.
Z tego ćwiczenia z programowania dowiesz się, jak skonfigurować Cloud Profiler dla programu w Go i jakie informacje o wydajności aplikacji może on przedstawiać.
Czego się nauczysz
- Jak skonfigurować program w Go do profilowania za pomocą Cloud Profiler.
- Jak zbierać, wyświetlać i analizować dane o skuteczności za pomocą Cloud Profiler.
Czego potrzebujesz
- projekt Google Cloud Platform,
- przeglądarka, np. Chrome lub Firefox;
- Znajomość standardowych edytorów tekstu systemu Linux, takich jak Vim, EMACS lub Nano.
Jak zamierzasz korzystać z tego samouczka?
Jak oceniasz korzystanie z Google Cloud Platform?
2. Konfiguracja i wymagania
Samodzielne konfigurowanie środowiska
- Zaloguj się w konsoli Google Cloud i utwórz nowy projekt lub użyj istniejącego. Jeśli nie masz jeszcze konta Gmail ani Google Workspace, musisz je utworzyć.



Zapamiętaj identyfikator projektu, czyli unikalną nazwę we wszystkich projektach Google Cloud (podana powyżej nazwa jest już zajęta i nie będzie działać w Twoim przypadku). W dalszej części tego laboratorium będzie on nazywany PROJECT_ID.
- Następnie musisz włączyć rozliczenia w konsoli Cloud, aby korzystać z zasobów Google Cloud.
Ukończenie tego laboratorium nie powinno wiązać się z dużymi kosztami, a nawet z żadnymi. Wykonaj instrukcje z sekcji „Czyszczenie”, w której znajdziesz informacje o tym, jak wyłączyć zasoby, aby uniknąć naliczenia opłat po zakończeniu tego samouczka. Nowi użytkownicy Google Cloud mogą skorzystać z bezpłatnego okresu próbnego, w którym mają do dyspozycji środki w wysokości 300 USD.
Google Cloud Shell
Google Cloud można obsługiwać zdalnie z laptopa, ale aby uprościć konfigurację w tym module, będziemy używać Google Cloud Shell, czyli środowiska wiersza poleceń działającego w chmurze.
Aktywowanie Cloud Shell
- W konsoli Cloud kliknij Aktywuj Cloud Shell
 .
.

Jeśli uruchamiasz Cloud Shell po raz pierwszy, zobaczysz ekran pośredni (część strony widoczna po przewinięciu) z opisem tego środowiska. W takim przypadku kliknij Dalej, a ten ekran nie będzie się już wyświetlać. Ten wyświetlany jednorazowo ekran wygląda tak:

Uzyskanie dostępu do środowiska Cloud Shell i połączenie się z nim powinno zająć tylko kilka chwil.

Ta maszyna wirtualna zawiera wszystkie potrzebne narzędzia dla programistów. Zawiera również stały katalog domowy o pojemności 5 GB i działa w Google Cloud, co znacznie zwiększa wydajność sieci i usprawnia proces uwierzytelniania. Większość zadań w tym module, a być może wszystkie, możesz wykonać w przeglądarce lub na Chromebooku.
Po połączeniu z Cloud Shell zobaczysz, że uwierzytelnianie zostało już przeprowadzone, a projekt jest już ustawiony na Twój identyfikator projektu.
- Aby potwierdzić, że uwierzytelnianie zostało przeprowadzone, uruchom w Cloud Shell to polecenie:
gcloud auth list
Wynik polecenia
Credentialed Accounts
ACTIVE ACCOUNT
* <my_account>@<my_domain.com>
To set the active account, run:
$ gcloud config set account `ACCOUNT`
- Aby potwierdzić, że polecenie gcloud zna Twój projekt, uruchom w Cloud Shell to polecenie:
gcloud config list project
Wynik polecenia
[core] project = <PROJECT_ID>
Jeśli nie, możesz go ustawić za pomocą tego polecenia:
gcloud config set project <PROJECT_ID>
Wynik polecenia
Updated property [core/project].
3. Otwieranie Cloud Profiler
W konsoli Cloud otwórz interfejs Profilera, klikając „Profiler” na pasku nawigacyjnym po lewej stronie:

Możesz też użyć paska wyszukiwania w konsoli Cloud, aby przejść do interfejsu Profilera: wpisz „Cloud Profiler” i wybierz znaleziony element. W obu przypadkach powinien wyświetlić się interfejs programu profilującego z komunikatem „Brak danych do wyświetlenia” podobnym do tego poniżej. Projekt jest nowy, więc nie ma jeszcze żadnych zebranych danych profilowania.

Czas teraz coś profilować.
4. Profilowanie testu porównawczego
Użyjemy prostej syntetycznej aplikacji Go dostępnej w GitHub. W terminalu Cloud Shell, który jest nadal otwarty (i gdy w interfejsie Profilera nadal wyświetla się komunikat „Brak danych do wyświetlenia”), uruchom to polecenie:
$ go get -u github.com/GoogleCloudPlatform/golang-samples/profiler/...
Następnie przejdź do katalogu aplikacji:
$ cd ~/gopath/src/github.com/GoogleCloudPlatform/golang-samples/profiler/hotapp
Katalog zawiera plik „main.go”, który jest syntetyczną aplikacją z włączonym agentem profilowania:
main.go
...
import (
...
"cloud.google.com/go/profiler"
)
...
func main() {
err := profiler.Start(profiler.Config{
Service: "hotapp-service",
DebugLogging: true,
MutexProfiling: true,
})
if err != nil {
log.Fatalf("failed to start the profiler: %v", err)
}
...
}
Agent profilowania domyślnie zbiera profile procesora, sterty i wątków. Ten kod umożliwia zbieranie profili mutexów (nazywanych też „konfliktami”).
Teraz uruchom program:
$ go run main.go
Podczas działania programu agent profilujący będzie okresowo zbierać profile 5 skonfigurowanych typów. Zbieranie danych jest losowe w czasie (średnio 1 profil na minutę dla każdego typu), więc zebranie wszystkich typów może potrwać do 3 minut. Program informuje o utworzeniu profilu. Wiadomości są włączane przez flagę DebugLogging w konfiguracji powyżej. W przeciwnym razie agent działa w trybie cichym:
$ go run main.go 2018/03/28 15:10:24 profiler has started 2018/03/28 15:10:57 successfully created profile THREADS 2018/03/28 15:10:57 start uploading profile 2018/03/28 15:11:19 successfully created profile CONTENTION 2018/03/28 15:11:30 start uploading profile 2018/03/28 15:11:40 successfully created profile CPU 2018/03/28 15:11:51 start uploading profile 2018/03/28 15:11:53 successfully created profile CONTENTION 2018/03/28 15:12:03 start uploading profile 2018/03/28 15:12:04 successfully created profile HEAP 2018/03/28 15:12:04 start uploading profile 2018/03/28 15:12:04 successfully created profile THREADS 2018/03/28 15:12:04 start uploading profile 2018/03/28 15:12:25 successfully created profile HEAP 2018/03/28 15:12:25 start uploading profile 2018/03/28 15:12:37 successfully created profile CPU ...
Interfejs użytkownika zaktualizuje się wkrótce po zebraniu pierwszego profilu. Po tym czasie nie będzie się ona automatycznie aktualizować, więc aby zobaczyć nowe dane, musisz ręcznie odświeżyć interfejs Profilera. Aby to zrobić, kliknij dwukrotnie przycisk Teraz w selektorze przedziału czasu:

Po odświeżeniu interfejsu zobaczysz coś takiego:
Selektor typów profili wyświetla 5 dostępnych typów profili:
Przyjrzyjmy się teraz poszczególnym typom profili i ważnym funkcjom interfejsu, a potem przeprowadźmy kilka eksperymentów. Na tym etapie nie potrzebujesz już terminala Cloud Shell, więc możesz go zamknąć, naciskając CTRL-C i wpisując „exit”.
5. Analizowanie danych profilera
Zebraliśmy już trochę danych, więc przyjrzyjmy się im bliżej. Używamy syntetycznej aplikacji (źródło jest dostępne w Githubie), która symuluje zachowania typowe dla różnych rodzajów problemów z wydajnością w wersji produkcyjnej.
Kod wymagający dużej mocy obliczeniowej procesora
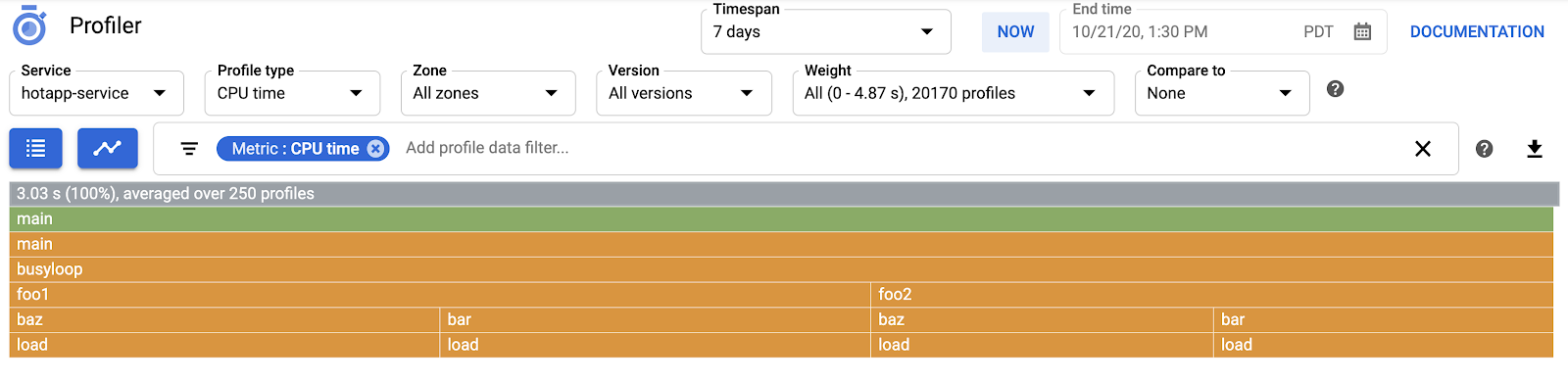
Wybierz typ profilu procesora. Po wczytaniu interfejsu zobaczysz na wykresie płomieniowym 4 bloki liści dla funkcji load, które łącznie odpowiadają za całe zużycie procesora:

Ta funkcja została specjalnie napisana tak, aby zużywać dużo cykli procesora przez uruchamianie ciasnej pętli:
main.go
func load() {
for i := 0; i < (1 << 20); i++ {
}
}
Funkcja jest wywoływana pośrednio z funkcji busyloop() za pomocą 4 ścieżek wywołań: busyloop → {foo1, foo2} → {bar, baz} → load. Szerokość pola funkcji reprezentuje względny koszt określonej ścieżki wywołania. W tym przypadku wszystkie 4 ścieżki mają podobny koszt. W prawdziwym programie warto skupić się na optymalizacji ścieżek połączeń, które mają największe znaczenie pod względem skuteczności. Wykres płomieniowy, który wizualnie podkreśla bardziej kosztowne ścieżki za pomocą większych pól, ułatwia ich identyfikację.
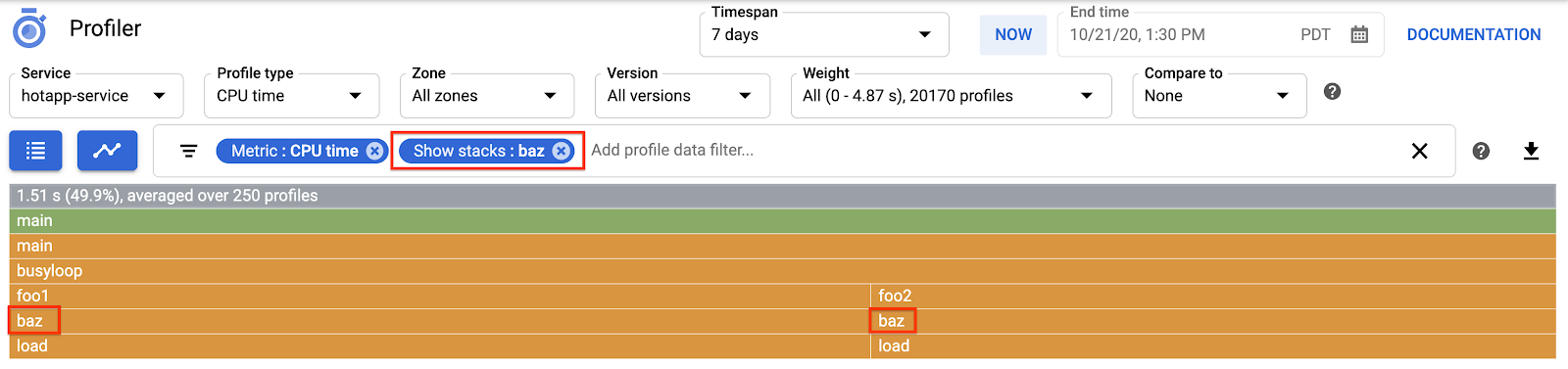
Aby jeszcze bardziej doprecyzować wyświetlanie, możesz użyć filtra danych profilu. Spróbuj na przykład dodać filtr „Pokaż stosy”, podając „baz” jako ciąg filtra. Powinien pojawić się ekran podobny do tego na zrzucie poniżej, na którym widoczne są tylko 2 z 4 ścieżek połączeń z load(). Te 2 ścieżki są jedynymi, które przechodzą przez funkcję z ciągiem znaków „baz” w nazwie. Takie filtrowanie jest przydatne, gdy chcesz skupić się na części większego programu (np. dlatego, że jesteś właścicielem tylko jego części).
Kod wymagający dużej ilości pamięci
Teraz przełącz się na typ profilu „Heap”. Pamiętaj, aby usunąć wszystkie filtry utworzone w poprzednich eksperymentach. Powinien pojawić się wykres płomieniowy, na którym allocImpl, wywoływany przez alloc, jest wyświetlany jako główny odbiorca pamięci w aplikacji:
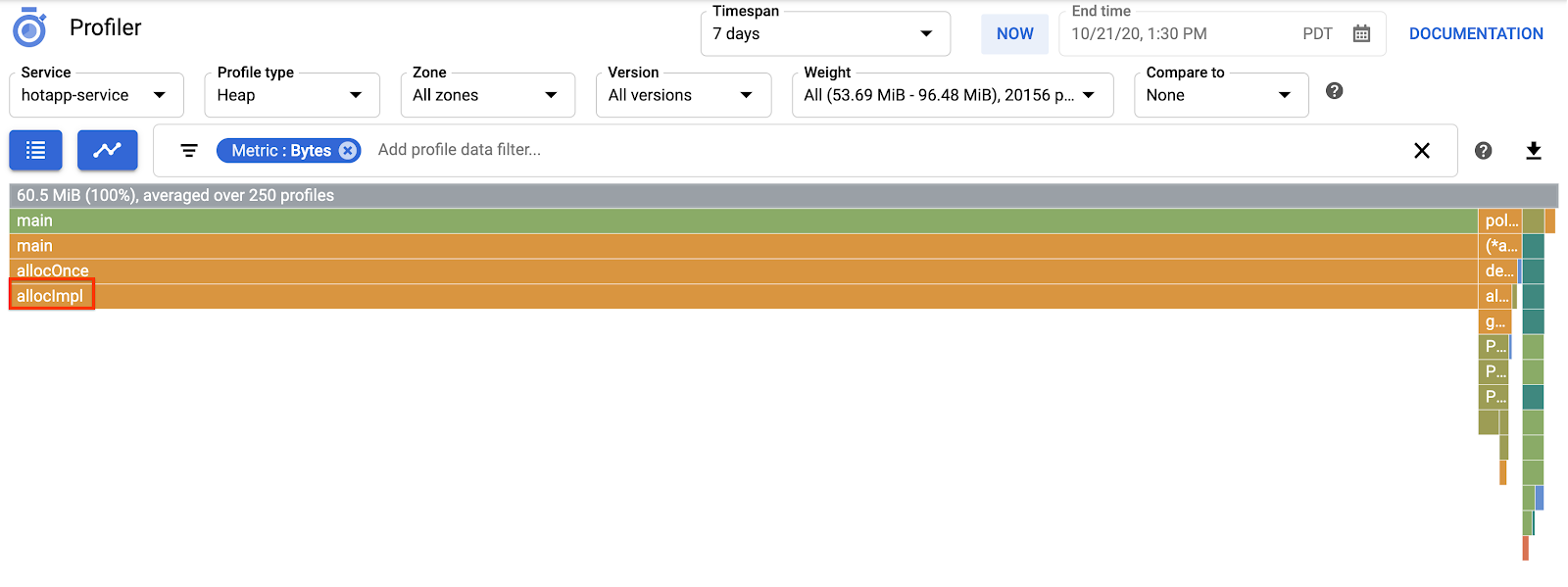
Tabela podsumowania nad wykresem płomieniowym wskazuje, że łączna ilość używanej pamięci w aplikacji wynosi średnio ok.57,4 MiB, a większość z niej jest przydzielana przez funkcję allocImpl. Nie jest to zaskakujące, biorąc pod uwagę implementację tej funkcji:
main.go
func allocImpl() {
// Allocate 64 MiB in 64 KiB chunks
for i := 0; i < 64*16; i++ {
mem = append(mem, make([]byte, 64*1024))
}
}
Funkcja jest wykonywana raz, przydzielając 64 MiB w mniejszych fragmentach, a następnie przechowując wskaźniki do tych fragmentów w zmiennej globalnej, aby chronić je przed odzyskiwaniem pamięci. Pamiętaj, że ilość pamięci podana przez profiler jest nieco inna niż 64 MiB: profiler sterty Go to narzędzie statystyczne, więc pomiary są mało obciążające, ale nie są dokładne co do bajta. Nie zdziw się, jeśli zobaczysz taką różnicę (ok. 10%).
Kod wymagający dużej liczby operacji wejścia/wyjścia
Jeśli w selektorze typu profilu wybierzesz „Wątki”, wyświetli się wykres płomieniowy, na którym większość szerokości zajmują funkcje wait i waitImpl:

Z podsumowania nad wykresem płomieniowym wynika, że 100 rutyn ma rosnący stos wywołań od funkcji wait. Jest to prawidłowe, ponieważ kod, który inicjuje te oczekiwania, wygląda tak:
main.go
func main() {
...
// Simulate some waiting goroutines.
for i := 0; i < 100; i++ {
go wait()
}
Ten typ profilu jest przydatny do sprawdzania, czy program nie spędza nieoczekiwanie dużo czasu na oczekiwaniu (np. na operacje wejścia-wyjścia). Takie stosy wywołań nie są zwykle próbkowane przez profiler procesora, ponieważ nie zużywają znaczącej części czasu procesora. W przypadku profili wątków często warto używać filtrów „Ukryj stosy” – na przykład, aby ukryć wszystkie stosy kończące się wywołaniem funkcji gopark,, ponieważ są to często bezczynne procedury goroutine, które są mniej interesujące niż te, które czekają na operacje wejścia/wyjścia.
Typ profilu wątków może też pomóc w zidentyfikowaniu punktów w programie, w których wątki długo czekają na mutex należący do innej części programu, ale do tego celu bardziej przydatny jest następujący typ profilu.
Kod wymagający dużej liczby operacji
Typ profilu rywalizacji określa najbardziej „pożądane” blokady w programie. Ten typ profilu jest dostępny w przypadku programów w Go, ale musi być jawnie włączony przez podanie wartości „MutexProfiling: true” w kodzie konfiguracji agenta. Kolekcja działa poprzez rejestrowanie (w ramach rodzaju danych „Contentions”) liczby przypadków, w których określona blokada, odblokowywana przez gorutynę A, miała inną gorutynę B oczekującą na odblokowanie. Rejestruje też (w ramach danych „Opóźnienie”) czas, przez jaki zablokowana gorutyna czekała na blokadę. W tym przykładzie jest jeden stos rywalizacji, a łączny czas oczekiwania na blokadę wynosił 10,5 sekundy:

Kod, który generuje ten profil, składa się z 4 gorutyn walczących o muteks:
main.go
func contention(d time.Duration) {
contentionImpl(d)
}
func contentionImpl(d time.Duration) {
for {
mu.Lock()
time.Sleep(d)
mu.Unlock()
}
}
...
func main() {
...
for i := 0; i < 4; i++ {
go contention(time.Duration(i) * 50 * time.Millisecond)
}
}
6. Podsumowanie
Z tego modułu dowiesz się, jak skonfigurować program w Go do używania z Cloud Profiler. Dowiedziałeś się też, jak za pomocą tego narzędzia zbierać, wyświetlać i analizować dane o skuteczności. Możesz teraz wykorzystać nową umiejętność w przypadku rzeczywistych usług działających w Google Cloud Platform.
7. Gratulacje!
Wiesz już, jak skonfigurować i używać Cloud Profiler.
Więcej informacji
- Cloud Profiler: https://cloud.google.com/profiler/
- Pakiet Go runtime/pprof używany przez Cloud Profiler: https://golang.org/pkg/runtime/pprof/
Licencja
To zadanie jest licencjonowane na podstawie ogólnej licencji Creative Commons Attribution 2.0.