
1. Einführung
Übersicht
In diesem Lab stellen Sie einen produktionsreifen ADK-Agenten (Agent Development Kit) mit einem GPU-beschleunigten Gemma-Backend bereit. Der Schwerpunkt liegt auf kritischen Bereitstellungsmustern: Einrichten von GPU-fähigen Cloud Run-Diensten, Integrieren von Modell-Back-Ends mit ADK-Agents und Beobachten des Autoscaling-Verhaltens unter Last.
Aufgaben
In diesem Lab konzentrieren Sie sich auf die kritischen Aspekte der Produktionsbereitstellung:
- Gemma mit GPU in Cloud Run bereitstellen – Hochleistungsfähiges Gemma-Modell-Backend einrichten
- Gemma-Bereitstellung in einen ADK-Agenten einbinden – Agenten mit dem GPU-beschleunigten Modell verbinden
- Mit der ADK-Weboberfläche testen: Prüfen Sie, ob Ihr Konversations-Agent richtig funktioniert.
- Elastizitätstests durchführen: Beobachten Sie, wie die beiden Cloud Run-Instanzen die Last bewältigen.
Der Schwerpunkt liegt auf Mustern für die Produktionsbereitstellung und nicht auf der Entwicklung umfangreicher Agents.
Lerninhalte
- GPU-beschleunigte Gemma-Modelle für die Produktion in Cloud Run bereitstellen
- Externe Modellbereitstellungen in ADK-Agenten einbinden
- Produktionsreife KI-Agentenbereitstellungen konfigurieren und testen
- Cloud Run-Verhalten bei Last verstehen
- Beobachten, wie mehrere Cloud Run-Instanzen bei Trafficspitzen zusammenarbeiten
- Elastizitätstests zur Validierung der Leistung durchführen
2. Projekt einrichten
- Wenn Sie noch kein Google-Konto haben, müssen Sie ein Google-Konto erstellen.
- Verwenden Sie stattdessen ein privates Konto. Bei Arbeitskonten und Konten von Bildungseinrichtungen kann es Einschränkungen geben, die verhindern, dass Sie die für dieses Lab erforderlichen APIs aktivieren.
- Melden Sie sich in der Google Cloud Console an.
- Aktivieren Sie die Abrechnung in der Cloud Console.
- Die Kosten für Cloud-Ressourcen für dieses Lab sollten weniger als 1 $betragen.
- Sie können die Schritte am Ende dieses Labs ausführen, um Ressourcen zu löschen und so weitere Kosten zu vermeiden.
- Neue Nutzer haben Anspruch auf die kostenlose Testversion mit einem Guthaben von 300$.
- Erstellen Sie ein neues Projekt oder verwenden Sie ein vorhandenes Projekt wieder.
- Wenn Sie eine Fehlermeldung zum Projektkontingent sehen, verwenden Sie ein vorhandenes Projekt wieder oder löschen Sie ein vorhandenes Projekt, um ein neues zu erstellen.
3. Cloud Shell-Editor öffnen
- Klicken Sie auf diesen Link, um direkt zum Cloud Shell-Editor zu gelangen.
- Wenn Sie heute an irgendeinem Punkt zur Autorisierung aufgefordert werden, klicken Sie auf Autorisieren, um fortzufahren.
- Wenn das Terminal nicht unten auf dem Bildschirm angezeigt wird, öffnen Sie es:
- Klicken Sie auf Ansehen.
- Klicken Sie auf Terminal
 .
.
- Legen Sie im Terminal Ihr Projekt mit diesem Befehl fest:
- Format:
gcloud config set project [PROJECT_ID] - Beispiel:
gcloud config set project lab-project-id-example - Wenn Sie sich nicht an Ihre Projekt-ID erinnern können,
- Sie können alle Ihre Projekt-IDs mit folgendem Befehl auflisten:
gcloud projects list | awk '/PROJECT_ID/{print $2}'
- Sie können alle Ihre Projekt-IDs mit folgendem Befehl auflisten:
- Format:
- Es sollte folgende Meldung angezeigt werden:
Updated property [core/project].
WARNINGsehen undDo you want to continue (Y/n)?gefragt werden, haben Sie die Projekt-ID wahrscheinlich falsch eingegeben. Drücken Sien, dannEnterund versuchen Sie, den Befehlgcloud config set projectnoch einmal auszuführen.
4. APIs aktivieren und Standardregion festlegen
Bevor wir Cloud Run-Dienste mit GPU-Unterstützung bereitstellen können, müssen wir die erforderlichen Google Cloud-APIs aktivieren und Ihre Projekteinstellungen konfigurieren.
- Aktivieren Sie die APIs im Terminal:
gcloud services enable \
run.googleapis.com \
artifactregistry.googleapis.com \
cloudbuild.googleapis.com \
aiplatform.googleapis.com
Wenn Sie zur Autorisierung aufgefordert werden, klicken Sie auf Autorisieren, um fortzufahren.
Es kann einige Minuten dauern, bis dieser Befehl ausgeführt wird. Wenn die Ausführung erfolgreich war, erhalten Sie eine Meldung, die ungefähr so aussieht:
Operation "operations/acf.p2-73d90d00-47ee-447a-b600" finished successfully.
- Legen Sie Ihre standardmäßige Cloud Run-Region fest.
gcloud config set run/region europe-west4
5. Python-Projekt vorbereiten
Richten wir den Startcode ein, der die grundlegende Struktur für unser Gemma-Backend und unsere ADK-Agent-Dienste enthält.
- Klonen Sie das Starter-Repository:
cd ~ npx -y giget@latest gh+git:GoogleCloudPlatform/devrel-demos/agents/accelerate-ai-with-cloud-run/accelerate-ai-lab3-starter accelerate-ai-lab3-starter cd accelerate-ai-lab3-starter - Sehen Sie sich die Projektstruktur an:
ls -Raccelerate-ai-lab3-starter/ ├── README.md # Project overview ├── ollama-backend/ # Ollama backend (separate deployment) │ └── Dockerfile # Backend container (🚧 to implement) └── adk-agent/ # ADK agent (separate deployment) ├── pyproject.toml # Python dependencies (✅ completed) ├── server.py # FastAPI server (🚧 to implement) ├── Dockerfile # Container config (🚧 to implement) ├── elasticity_test.py # Elasticity testing (🚧 to implement) └── production_agent/ # Agent implementation ├── __init__.py # Package init (✅ completed) └── agent.py # Agent logic (🚧 to implement)
6. Überblick über die Architektur
Bevor wir mit der Implementierung beginnen, sehen wir uns die Architektur mit zwei Diensten an:
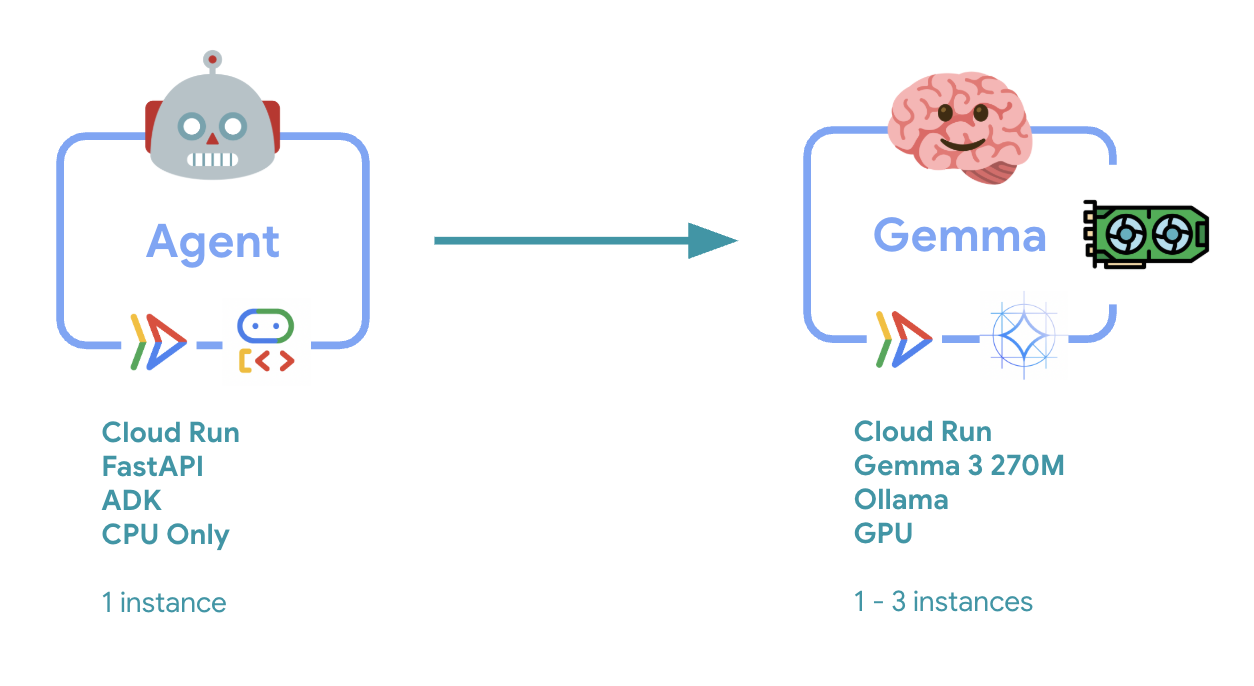
Wichtiger Hinweis: Während des Elastizitätstests verarbeiten beide Dienste die Arbeitslast unabhängig voneinander. Das GPU-Backend (Engpassdienst) verwendet seine GPU, um die Last zu bewältigen, während der ADK-Agent seine CPU verwendet, um die nicht ressourcenintensiven Anfragen zu verarbeiten.
7. Gemma-Backend in Cloud Run mit GPU bereitstellen
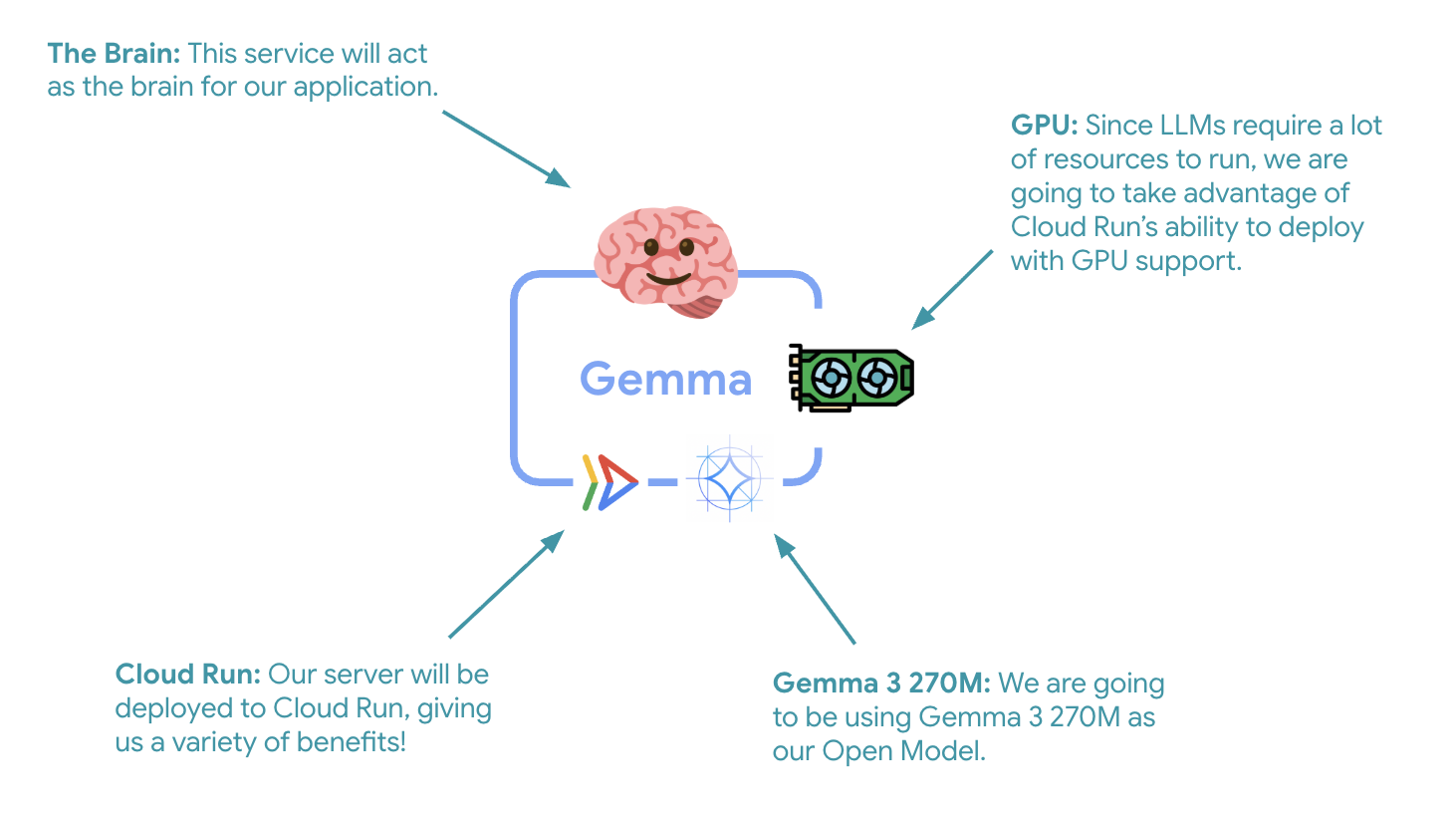
Der erste wichtige Schritt ist die Bereitstellung eines GPU-beschleunigten Gemma-Modells, das als Gehirn für Ihren ADK-Agenten dient. Ein entkoppeltes, bereitgestelltes LLM kann in Architekturen von Vorteil sein, in denen Sie ein separates, abgestimmtes Modell oder eine isolierte Skalierung benötigen.
- Wechseln Sie zum Ollama-Backend-Verzeichnis:
cd ollama-backend - Öffnen Sie das Ollama-Dockerfile und implementieren Sie es:
cloudshell edit DockerfileFROM ollama/ollama:latest # Listen on all interfaces, port 8080 ENV OLLAMA_HOST 0.0.0.0:8080 # Store model weight files in /models ENV OLLAMA_MODELS /models # Reduce logging verbosity ENV OLLAMA_DEBUG false # Never unload model weights from the GPU ENV OLLAMA_KEEP_ALIVE -1 # Store the model weights in the container image ENV MODEL gemma3:270m RUN ollama serve & sleep 5 && ollama pull $MODEL # Start Ollama ENTRYPOINT ["ollama", "serve"]- Verwendet das offizielle Ollama-Image als Grundlage
- Legt
OLLAMA_HOSTfest, um Verbindungen von jeder IP-Adresse zu akzeptieren. - Port 8080 wird freigegeben
- Gemma-Backend mit GPU-Unterstützung bereitstellen:
gcloud run deploy ollama-gemma3-270m-gpu \
--source . \
--region europe-west4 \
--concurrency 7 \
--cpu 8 \
--set-env-vars OLLAMA_NUM_PARALLEL=4 \
--gpu 1 \
--gpu-type nvidia-l4 \
--max-instances 1 \
--memory 16Gi \
--allow-unauthenticated \
--no-cpu-throttling \
--no-gpu-zonal-redundancy \
--timeout 600 \
--labels dev-tutorial=codelab-agent-gpu
Wenn Sie die Meldung „Deploying from source requires an Artifact Registry Docker repository to store built containers. Wenn Sie die Meldung „A repository named [cloud-run-source-deploy] in region [europe-west4] will be created.“ (Ein Repository mit dem Namen [cloud-run-source-deploy] wird in der Region [europe-west4] erstellt.) sehen, fahren Sie fort.
⚙️ Schlüsselkonfiguration:
- GPU: NVIDIA L4 wurde aufgrund des hervorragenden Preis-Leistungs-Verhältnisses für Inferenzarbeitslasten ausgewählt. Die L4 bietet 24 GB GPU-Speicher und optimierte Tensor-Operationen und eignet sich daher ideal für Modelle mit 270 Millionen Parametern wie Gemma.
- Arbeitsspeicher: 16 GB Arbeitsspeicher für das Laden von Modellen, CUDA-Vorgänge und die Arbeitsspeicherverwaltung von Ollama
- CPU: 8 Kerne für die optimale Verarbeitung von E/A und Vorverarbeitungsaufgaben
- Gleichzeitigkeit: 7 Anfragen pro Instanz sorgen für ein ausgewogenes Verhältnis zwischen Durchsatz und GPU-Arbeitsspeichernutzung.
- Zeitlimit: 600 Sekunden für das erste Laden des Modells und den Containerstart
💰 Kosten: GPU-Instanzen sind deutlich teurer als reine CPU-Instanzen (ca. 2–4$pro Stunde im Vergleich zu ca. 0,10$pro Stunde). Mit der Einstellung --max-instances 1 können Sie die Kosten im Blick behalten, da unnötige Skalierungen von GPU-Instanzen verhindert werden.
- Warten Sie, bis die Bereitstellung abgeschlossen ist, und notieren Sie sich die Dienst-URL:
export OLLAMA_URL=$(gcloud run services describe ollama-gemma3-270m-gpu \ --region=europe-west4 \ --format='value(status.url)') echo "🎉 Gemma backend deployed at: $OLLAMA_URL"
8. ADK-Agent-Integration implementieren
Erstellen wir nun einen minimalen ADK-Agenten, der eine Verbindung zu Ihrem bereitgestellten Gemma-Backend herstellt.
- Rufen Sie das ADK-Agent-Verzeichnis auf:
cd ../adk-agent - Öffnen und implementieren Sie die Agent-Konfiguration:
cloudshell edit production_agent/agent.pyimport os from pathlib import Path from dotenv import load_dotenv from google.adk.agents import Agent from google.adk.models.lite_llm import LiteLlm import google.auth # Load environment variables root_dir = Path(__file__).parent.parent dotenv_path = root_dir / ".env" load_dotenv(dotenv_path=dotenv_path) # Configure Google Cloud try: _, project_id = google.auth.default() os.environ.setdefault("GOOGLE_CLOUD_PROJECT", project_id) except Exception: pass os.environ.setdefault("GOOGLE_CLOUD_LOCATION", "europe-west4") # Configure model connection gemma_model_name = os.getenv("GEMMA_MODEL_NAME", "gemma3:270m") api_base = os.getenv("OLLAMA_API_BASE", "localhost:10010") # Location of Ollama server # Production Gemma Agent - GPU-accelerated conversational assistant production_agent = Agent( model=LiteLlm(model=f"ollama_chat/{gemma_model_name}", api_base=api_base), name="production_agent", description="A production-ready conversational assistant powered by GPU-accelerated Gemma.", instruction="""You are 'Gem', a friendly, knowledgeable, and enthusiastic zoo tour guide. Your main goal is to make a zoo visit more fun and educational for guests by answering their questions. You can provide general information and interesting facts about different animal species, such as: - Their natural habitats and diet. 🌲🍓 - Typical lifespan and behaviors. - Conservation status and unique characteristics. IMPORTANT: You do NOT have access to any tools. This means you cannot look up real-time, specific information about THIS zoo. You cannot provide: - The names or ages of specific animals currently at the zoo. - The exact location or enclosure for an animal. - The daily schedule for feedings or shows. Always answer based on your general knowledge about the animal kingdom. Keep your tone cheerful, engaging, and welcoming for visitors of all ages. 🦁✨""", tools=[], # Gemma focuses on conversational capabilities ) # Set as root agent root_agent = production_agent- Verbindung zu Ihrem bereitgestellten Gemma-Backend über LiteLLM
- Erstellt einen einfachen Konversations-Agenten
- Google Cloud-Integration konfigurieren
- FastAPI-Server öffnen und implementieren:
cloudshell edit server.pyimport os from dotenv import load_dotenv from fastapi import FastAPI from google.adk.cli.fast_api import get_fast_api_app # Load environment variables load_dotenv() AGENT_DIR = os.path.dirname(os.path.abspath(__file__)) app_args = {"agents_dir": AGENT_DIR, "web": True} # Create FastAPI app with ADK integration app: FastAPI = get_fast_api_app(**app_args) # Update app metadata app.title = "Production ADK Agent - Lab 3" app.description = "Gemma agent with GPU-accelerated backend" app.version = "1.0.0" @app.get("/health") def health_check(): return {"status": "healthy", "service": "production-adk-agent"} @app.get("/") def root(): return { "service": "Production ADK Agent - Lab 3", "description": "GPU-accelerated Gemma agent", "docs": "/docs", "health": "/health" } if __name__ == "__main__": import uvicorn uvicorn.run(app, host="0.0.0.0", port=8080, log_level="info")- Erstellt einen FastAPI-Server mit ADK-Integration
- Aktiviert die Weboberfläche für Tests
- Stellt Endpunkte für Systemdiagnosen bereit
- Öffnen und implementieren Sie das Dockerfile:
cloudshell edit DockerfileFROM python:3.13-slim # Copy uv from the official image COPY --from=ghcr.io/astral-sh/uv:latest /uv /usr/local/bin/uv # Install system dependencies RUN apt-get update && apt-get install -y curl && rm -rf /var/lib/apt/lists/* # Set working directory WORKDIR /app # Copy all files COPY . . # Install Python dependencies RUN uv sync # Expose port EXPOSE 8080 # Run the application CMD ["uv", "run", "uvicorn", "server:app", "--host", "0.0.0.0", "--port", "8080"]- uv: Moderner Python-Paketmanager, der 10- bis 100-mal schneller als pip ist. Es wird ein globaler Cache und parallele Downloads verwendet, wodurch sich die Container-Build-Zeiten erheblich verkürzen.
- Python 3.13-slim: Die aktuelle Python-Version mit minimalen Systemabhängigkeiten, wodurch die Containergröße und die Angriffsfläche reduziert werden.
- Build in mehreren Phasen: Durch das Kopieren von uv aus dem offiziellen Image wird sichergestellt, dass wir das neueste optimierte Binärprogramm erhalten.
9. Umgebung konfigurieren und Agent bereitstellen
Als Nächstes konfigurieren wir den ADK-Agenten, damit er eine Verbindung zu Ihrem bereitgestellten Gemma-Backend herstellt, und stellen ihn als Cloud Run-Dienst bereit. Dazu müssen Sie Umgebungsvariablen einrichten und den Agent mit der richtigen Konfiguration bereitstellen.
- Umgebungskonfiguration einrichten:
cat << EOF > .env GOOGLE_CLOUD_PROJECT=$(gcloud config get-value project) GOOGLE_CLOUD_LOCATION=europe-west4 GEMMA_MODEL_NAME=gemma3:270m OLLAMA_API_BASE=$OLLAMA_URL EOF
Umgebungsvariablen in Cloud Run
Umgebungsvariablen sind Schlüssel/Wert-Paare, mit denen Ihre Anwendung zur Laufzeit konfiguriert wird. Sie sind besonders nützlich für:
- API-Endpunkte und Dienst-URLs (z. B. unser Ollama-Backend)
- Konfiguration, die sich zwischen Umgebungen (Entwicklung, Staging, Produktion) ändert
- Vertrauliche Daten, die nicht fest codiert werden sollten
ADK-Agent bereitstellen:
export PROJECT_ID=$(gcloud config get-value project)
gcloud run deploy production-adk-agent \
--source . \
--region europe-west4 \
--allow-unauthenticated \
--memory 4Gi \
--cpu 2 \
--max-instances 1 \
--concurrency 50 \
--timeout 300 \
--set-env-vars GOOGLE_CLOUD_PROJECT=$PROJECT_ID \
--set-env-vars GOOGLE_CLOUD_LOCATION=europe-west4 \
--set-env-vars GEMMA_MODEL_NAME=gemma3:270m \
--set-env-vars OLLAMA_API_BASE=$OLLAMA_URL \
--labels dev-tutorial=codelab-agent-gpu
⚙️ Schlüsselkonfiguration:
- Autoscaling: Auf 1 Instanz festgelegt (einfache Anfragenbearbeitung)
- Gleichzeitigkeit: 50 Anfragen pro Instanz
- Arbeitsspeicher: 4 GB für den ADK-Agent
- Umgebung: Stellt eine Verbindung zu Ihrem Gemma-Backend her.
🔒 Sicherheitshinweis: In diesem Lab wird der Einfachheit halber --allow-unauthenticated verwendet. In der Produktion sollten Sie die richtige Authentifizierung mit folgenden Methoden implementieren:
- Dienst-zu-Dienst-Authentifizierung mit Dienstkonten in Cloud Run
- IAM-Richtlinien (Identity and Access Management)
- API-Schlüssel oder OAuth für externen Zugriff
gcloud run services add-iam-policy-bindingzur Zugriffssteuerung verwenden
Rufen Sie die Dienst-URL Ihres Agents ab:
export AGENT_URL=$(gcloud run services describe production-adk-agent \
--region=europe-west4 \
--format='value(status.url)')
echo "🎉 ADK Agent deployed at: $AGENT_URL"
✅ Best Practices für Umgebungsvariablen basierend auf der Dokumentation zu Umgebungsvariablen in Cloud Run:
- Reservierte Variablen vermeiden: Legen Sie
PORTnicht fest. Wenn Sie die Umgebungsvariable ändern müssen, verwenden Sie stattdessen das Flag „–port“. Verwenden Sie auch keine Variablen, die mitX_GOOGLE_beginnen. - Aussagekräftige Namen verwenden: Fügen Sie Ihren Variablen ein Präfix hinzu, um Konflikte zu vermeiden (z. B.
GEMMA_MODEL_NAMEstattMODEL). - Kommas maskieren: Wenn Ihre Werte Kommas enthalten, verwenden Sie ein anderes Trennzeichen:
--set-env-vars "^@^KEY1=value1,value2@KEY2=..." - Aktualisieren und Ersetzen: Mit
--update-env-varskönnen Sie bestimmte Variablen hinzufügen oder ändern, ohne andere zu beeinträchtigen.
Variablen in Cloud Run festlegen:
- Aus Datei:
gcloud run deploy SERVICE_NAME --env-vars-file .env --labels dev-tutorial codelab-adk(lädt mehrere Variablen aus einer Datei) - Mehrere Flags: Wiederholen Sie
--set-env-varsfür komplexe Werte, die nicht durch Kommas getrennt werden können.
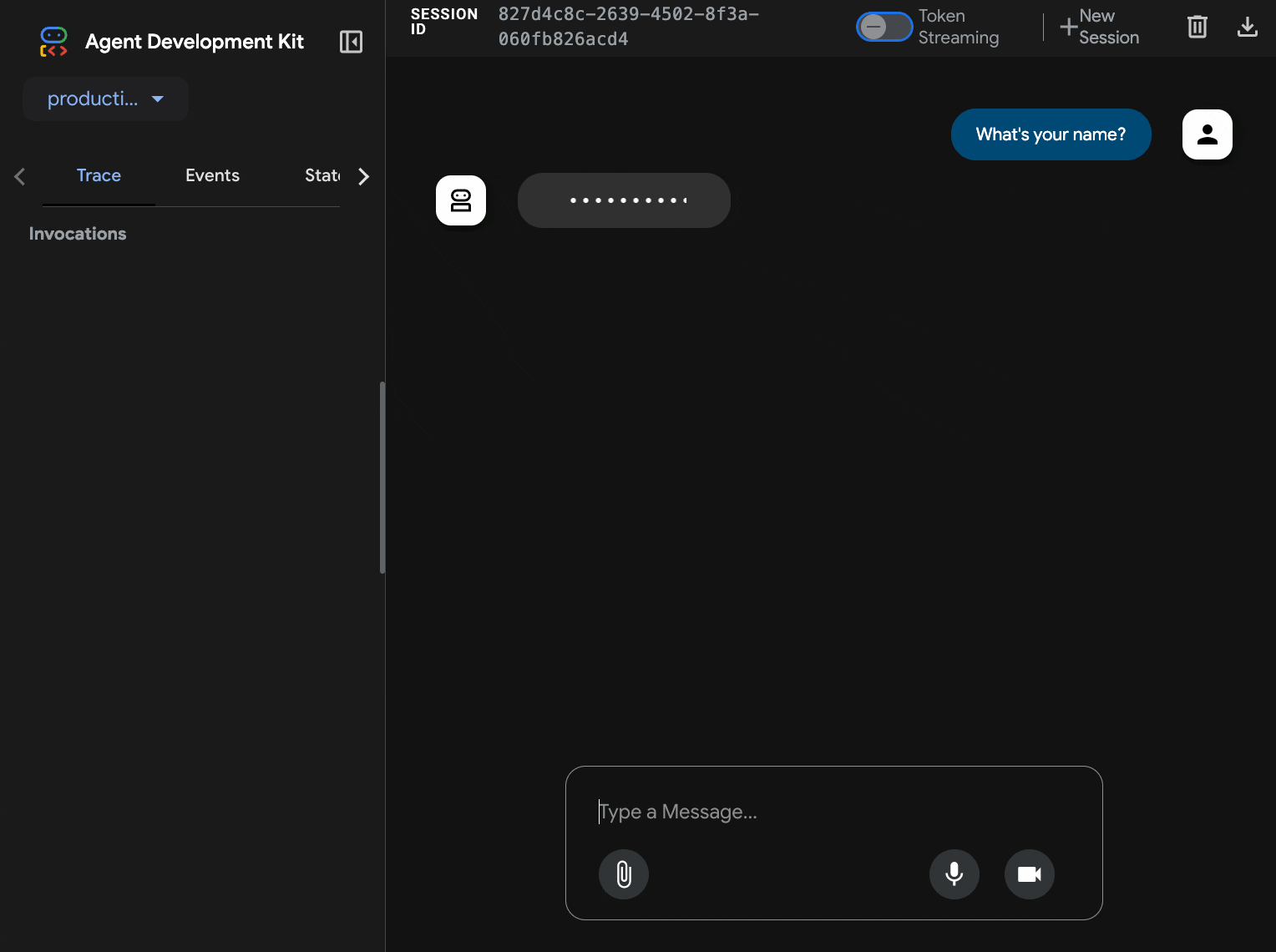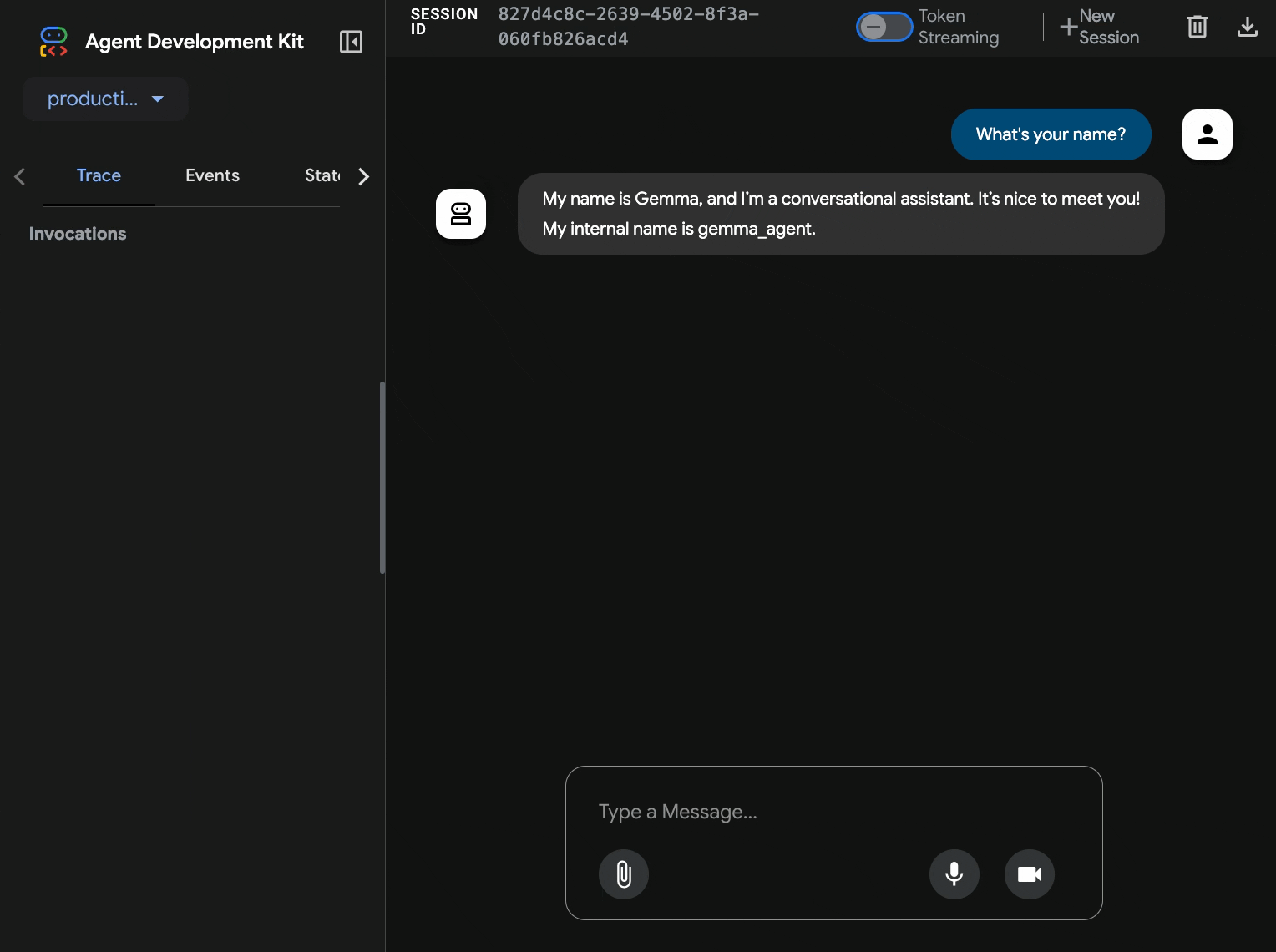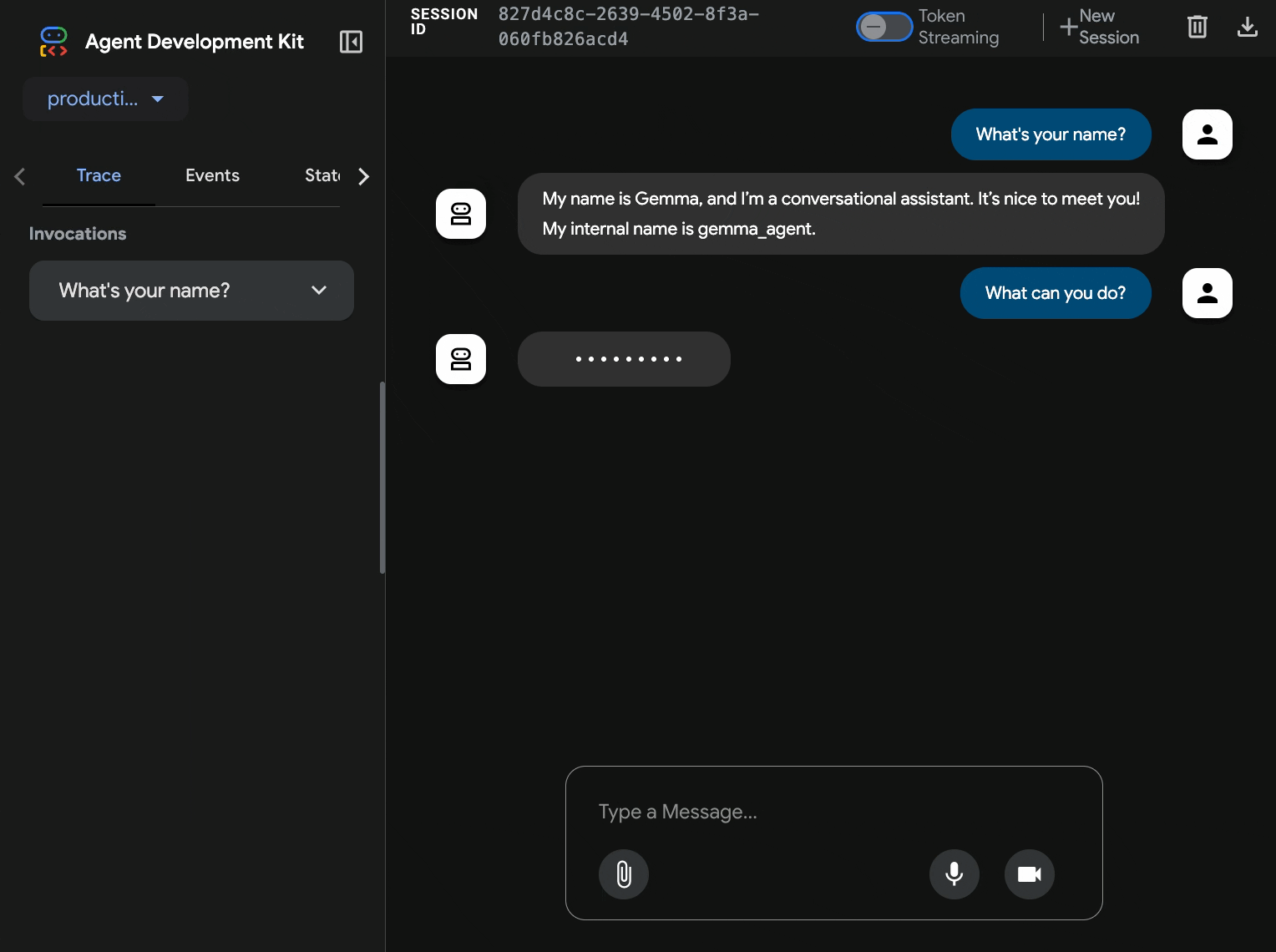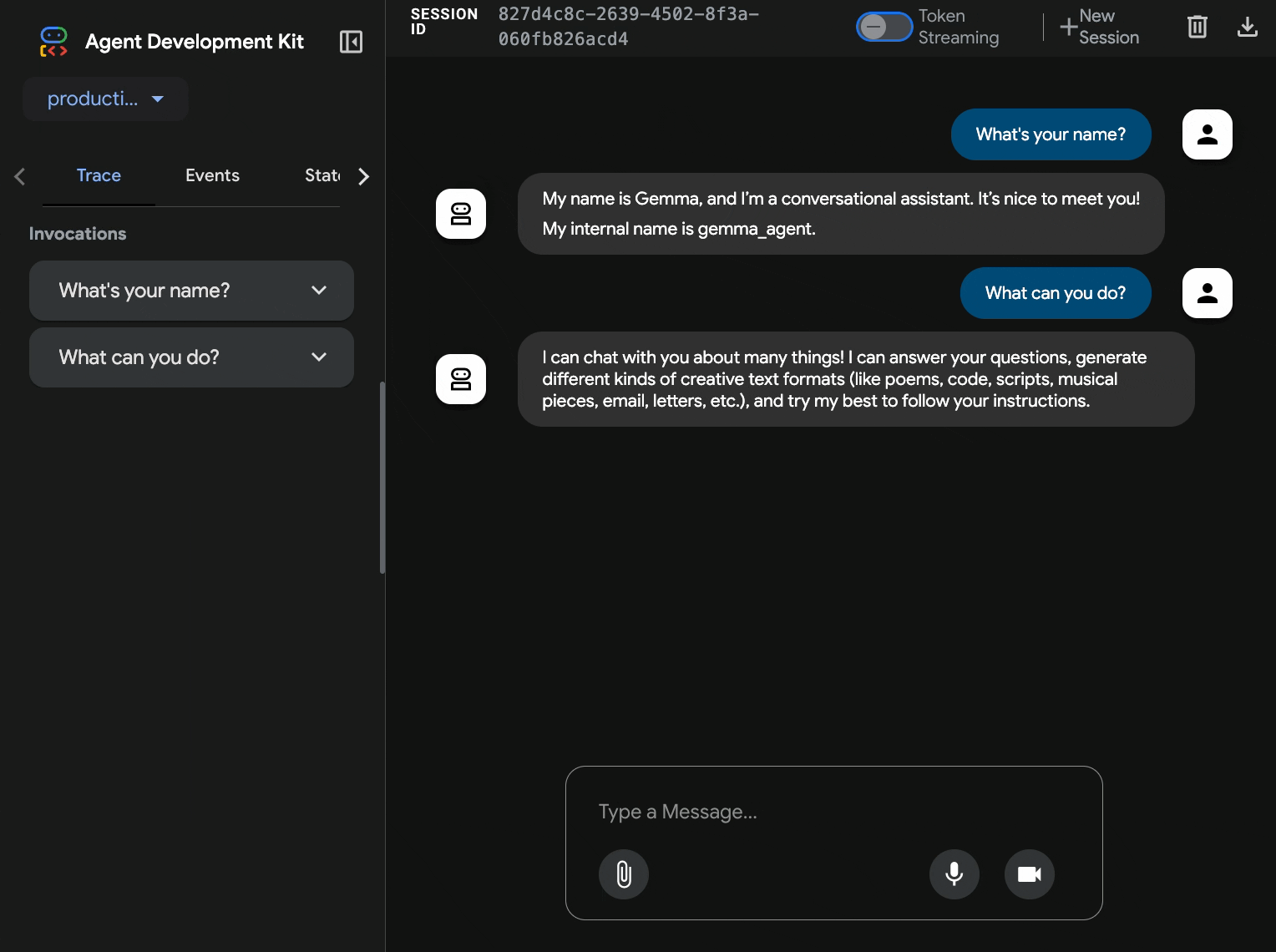
10. Mit der ADK-Weboberfläche testen
Nachdem beide Dienste bereitgestellt wurden, müssen Sie prüfen, ob Ihr ADK-Agent erfolgreich mit dem GPU-beschleunigten Gemma-Backend kommunizieren und auf Nutzeranfragen reagieren kann.
- Testen Sie den Endpunkt für die Systemdiagnose:
curl $AGENT_URL/health{ "status": "healthy", "service": "production-adk-agent" } - Sie können mit Ihrem Agent interagieren, indem Sie die URL für Ihr
production-adk-agentin einen neuen Browsertab eingeben. Sie sollten jetzt die ADK-Weboberfläche sehen. - Testen Sie Ihren Agenten mit diesen Beispielkonversationen:
- „Wovon ernähren sich Rote Pandas in der Wildnis?“
- „Kannst du mir einen interessanten Fakt über Schneeleoparden erzählen?“
- „Warum sind Pfeilgiftfrösche so bunt?“
- „Wo finde ich das neue Babykänguru im Zoo?“
- Der Agent antwortet mit Ihrem bereitgestellten Gemma-Modell. Sie können dies überprüfen, indem Sie die Logs für Ihren bereitgestellten Gemma-Dienst ansehen. Das machen wir im nächsten Abschnitt.
- Antworten werden vom GPU-beschleunigten Backend generiert.
- Die Weboberfläche bietet eine übersichtliche Chat-Umgebung.
11. Elastizitätstest implementieren und ausführen
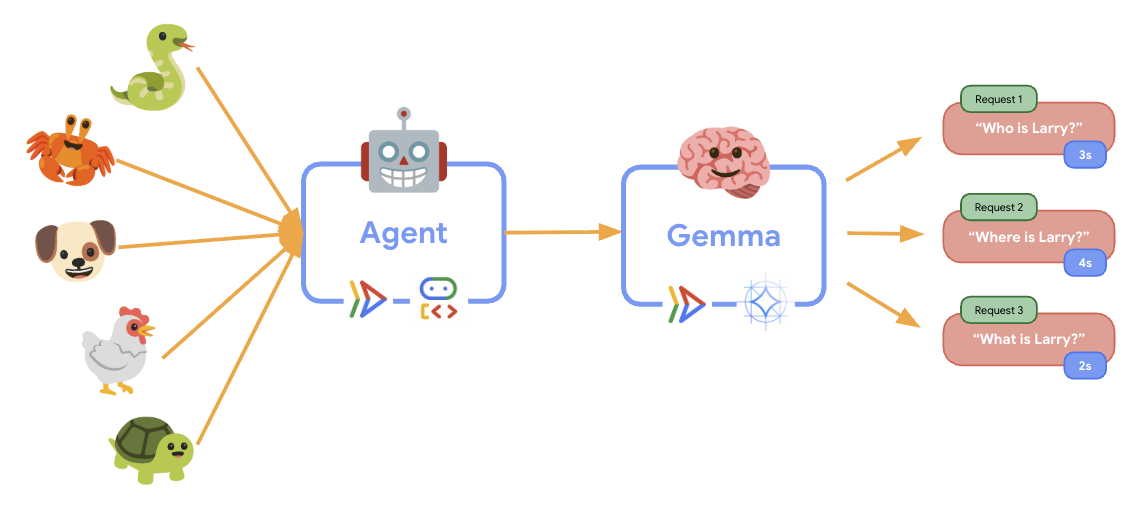
Um zu verstehen, wie Ihre Produktionsbereitstellung mit realem Traffic umgeht, führen wir einen Elastizitätstest durch, bei dem die Fähigkeit des Systems getestet wird, sich an eine höhere „simulierte“ Produktionsarbeitslast anzupassen.
- Öffnen und implementieren Sie das Script für Elastizitätstests:
cloudshell edit elasticity_test.pyimport random import uuid from locust import HttpUser, task, between class ProductionAgentUser(HttpUser): """Elasticity test user for the Production ADK Agent.""" wait_time = between(1, 3) # Faster requests to trigger scaling def on_start(self): """Set up user session when starting.""" self.user_id = f"user_{uuid.uuid4()}" self.session_id = f"session_{uuid.uuid4()}" # Create session for the Gemma agent using proper ADK API format session_data = {"state": {"user_type": "elasticity_test_user"}} self.client.post( f"/apps/production_agent/users/{self.user_id}/sessions/{self.session_id}", headers={"Content-Type": "application/json"}, json=session_data, ) @task(4) def test_conversations(self): """Test conversational capabilities - high frequency.""" topics = [ "What do red pandas typically eat in the wild?", "Can you tell me an interesting fact about snow leopards?", "Why are poison dart frogs so brightly colored?", "Where can I find the new baby kangaroo in the zoo?", "What is the name of your oldest gorilla?", "What time is the penguin feeding today?" ] # Use proper ADK API format for sending messages message_data = { "app_name": "production_agent", "user_id": self.user_id, "session_id": self.session_id, "new_message": { "role": "user", "parts": [{ "text": random.choice(topics) }] } } self.client.post( "/run", headers={"Content-Type": "application/json"}, json=message_data, ) @task(1) def health_check(self): """Test the health endpoint.""" self.client.get("/health")- Sitzungserstellung: Das richtige ADK-API-Format wird mit POST an
/apps/production_agent/users/{user_id}/sessions/{session_id}verwendet. Nachdem Sie einsession_idund einuser_iderstellt haben, kann eine Anfrage an den Agenten gesendet werden. - Nachrichtenformat: Entspricht der ADK-Spezifikation mit
app_name,user_id,session_idund strukturiertemnew_message-Objekt - Conversation Endpoint: Verwendet den
/run-Endpunkt, um alle Ereignisse gleichzeitig zu erfassen (empfohlen für Lasttests) - Realistic Load (Realistische Auslastung): Erstellt eine dialogorientierte Auslastung mit kürzeren Wartezeiten.
- Sitzungserstellung: Das richtige ADK-API-Format wird mit POST an
- Installieren Sie die Abhängigkeiten:
uv sync - Locust ist ein Open-Source-Tool für Lasttests, das in Python geschrieben wurde und für Leistungs- und Lasttests von Webanwendungen und anderen Systemen entwickelt wurde. Das Hauptmerkmal ist, dass Testszenarien und Nutzerverhalten mit Standard-Python-Code definiert werden. Das bietet im Vergleich zu Tools, die auf grafischen Benutzeroberflächen oder domänenspezifischen Sprachen basieren, eine hohe Flexibilität und Ausdrucksstärke. Wir verwenden Locust, um Nutzertraffic für unsere Dienste zu simulieren.Führen Sie den Test aus.
uv run locust -f elasticity_test.py \ -H $AGENT_URL \ --headless \ -t 60s \ -u 20 \ -r 5- Dauer: 60 Sekunden
- Nutzer: 20 gleichzeitige Nutzer
- Spawn-Rate: 5 Nutzer pro Sekunde
- Ziel: Autoscaling für beide Dienste auslösen
12. Autoscaling-Verhalten beobachten
Während des Elastizitätstests können Sie beobachten, wie Cloud Run höhere Arbeitslasten unterstützt. Hier sehen Sie die wichtigsten architektonischen Vorteile der Trennung des ADK-Agents vom GPU-Backend.
Beobachten Sie während des Elastizitätstests in der Console, wie die beiden Cloud Run-Dienste den Traffic verarbeiten.
- Öffnen Sie die Cloud Console und rufen Sie
- auf.
- „Cloud Run“ → „production-adk-agent“ → „Messwerte“
- „Cloud Run“ → „ollama-gemma3-270m-gpu“ → „Messwerte“
👀 Worauf Sie achten sollten:
🤖 ADK-Agent-Dienst:
- Sollte bei steigendem Traffic konstant bei 1 Instanz bleiben
- Spitzen bei CPU- und Arbeitsspeichernutzung bei hohem Traffic
- Effiziente Sitzungsverwaltung und effizientes Anfragerouting
🎮 Gemma Backend Service (Engpass):
- Sollte bei steigendem Traffic konstant bei 1 Instanz bleiben
- Die GPU-Auslastung steigt unter Last deutlich an.
- Dieser Dienst wird aufgrund der GPU-intensiven Modellinferenz zum Engpass.
- Die Zeiten für den Modellrückschluss bleiben aufgrund der GPU-Beschleunigung konstant.
💡 Wichtige Statistiken:
- Beide Dienste bleiben konsistent und werden nicht skaliert, da wir die maximale Anzahl von Instanzen auf
1festgelegt haben. - Beide Dienste werden unabhängig voneinander skaliert, basierend auf ihren individuellen Lasteigenschaften.
- Die GPU trägt dazu bei, die Leistung bei unterschiedlichen Lastbedingungen aufrechtzuerhalten.
13. Fazit
Glückwunsch! Sie haben einen produktionsreifen ADK-Agenten mit einem GPU-beschleunigten Gemma-Backend bereitgestellt und dabei eine simulierte Produktionsarbeitslast getestet.
✅ Was Sie erreicht haben
- ✅ GPU-beschleunigtes Gemma-Modell-Backend in Cloud Run bereitgestellt
- ✅ Sie haben einen ADK-Agenten erstellt und bereitgestellt, der in das Gemma-Backend integriert ist.
- ✅ Agent über die ADK-Weboberfläche getestet
- ✅ Autoscaling-Verhalten bei zwei koordinierten Cloud Run-Diensten beobachtet
💡 Wichtige Erkenntnisse aus diesem Lab
- 🎮 GPU-Beschleunigung: Die NVIDIA L4-GPU verbessert die Leistung der Modellinferenz erheblich.
- 🔗 Dienstkoordination: Zwei Cloud Run-Dienste können nahtlos zusammenarbeiten.
- 📈 Unabhängige Skalierung: Jeder Dienst wird basierend auf seinen individuellen Lasteigenschaften skaliert.
- 🚀 Produktionsbereitschaft: Die Architektur kann reale Traffic-Muster effektiv verarbeiten.
🔄 Nächste Schritte
- Mit verschiedenen Lastmustern experimentieren und das Skalierungsverhalten beobachten
- Verschiedene Gemma-Modellgrößen ausprobieren (Arbeitsspeicher und GPU entsprechend anpassen)
- Monitoring und Benachrichtigungen für Produktionsbereitstellungen implementieren
- Multiregionale Bereitstellungen für globale Verfügbarkeit
🧹 Bereinigen
Löschen Sie die Ressourcen, wenn Sie fertig sind, um Gebühren zu vermeiden:
gcloud run services delete production-adk-agent --region=europe-west4
gcloud run services delete ollama-gemma3-270m-gpu --region=europe-west4
📖 Ressourcen
- Starter-Repository
- Vollständige Lösung
- Google ADK-Dokumentation
- ADK-Testleitfaden: Vollständige Referenz für ADK-API-Endpunkte und Testmuster
- Lasttests in Cloud Run
- Dokumentation zum Agent Development Kit (ADK)
- Cloud Run-Dokumentation zu GPUs
- Ollama Model Library
- Google Cloud Trace-Dokumentation
- Best Practices für die Sicherheit von Cloud Run
- UV Python Package Manager
- Locust Load Testing Framework